
Abstract
The challenge of influence maximization in social networks is tackled in many settings and scenarios. However, the most explored variant is looking at how to choose a seed set of a given size, that maximizes the number of activated nodes for selected model of social influence. This has been studied mostly in the area of static networks, yet other kinds of networks, such as multilayer or temporal ones, are also in the scope of recent research. In this work we propose and evaluate the measure based on entropy, that investigates how the neighbourhood of nodes varies over time, and based on that and their activity ranks, the nodes as possible candidates for seeds are selected. This measure applied for temporal networks intends to favor nodes that vary their neighbourhood highly and, thanks to that, are good spreaders for certain influence models. The results demonstrate that for the Independent Cascade Model of social influence the introduced entropy-based metric outperforms typical seed selection heuristics for temporal networks. Moreover, compared to some other heuristics, it is fast to compute, thus can be used for fast-varying temporal networks.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Social influence maximization is a research topic that has been posed in 2003 by Kempe et al. [16]. Assuming a static social network and a given influence model, typical social influence maximization task is to choose a set of k nodes that will result with the highest influence (number of activations) across all methods. As presented in Related Work, this area has been investigated at the beginning for the case of static networks. However, recently researchers extended their interest to other kinds of networks, including multilayer [18] or temporal networks [11, 23]. This is caused by the fact, that for some applications these networks are more suitable for representing several types of processes, especially related to information diffusion. Here, an aggregated graph is not capable to represent the ordering of events, crucial for studying these processes. This is the reason why temporal networks are the model chosen in the case of modelling diffusion processes. Following this direction, the researchers exploring influence maximization area also started to investigate temporal networks [39].
In this work, we propose a method based on entropy for influence maximization in temporal networks. Entropy as a measure of diversity is capable of providing information about diversity - in this case how the neighbourhood of the nodes changes over time in a temporal network. This feature can be considered important in the area of information spreading, since a node - when activated - by changing its neighbourhood is increasing the chances of activating other nodes. Otherwise, if the neighbourhood of a node will be the same, this node usually would not contribute to the spreading process anymore after contacting its neighbours at the beginning.
The purpose of this work is to compare introduced entropy-based seed selection method against other heuristics commonly used in the area of social influence maximization. To do so, we studied the performance of the proposed method of seed selection for Independent Cascade Model of social influence using real-world datasets representing temporal networks of different kind and dynamics.
The work is organized as follows. In the next section we shortly describe the related work in the area covered by this research. Next, in Sect. 3, we present the experimental setting. Section 4 presents and discusses the results, while in Sect. 5 summary and future work directions are presented.
2 Related Work
Information spreading processes within social networks attract attention of researchers from various fields. It resulted with new sub-disciplines and research areas like network science [1]. In the background, they use theoretical models, network evolution mechanisms, multilayer and dynamic structures, methods for community detection, modeling and analysis of ongoing processes. While information spreading processes within complex networks are observed in various areas, many studies focus on their modeling and analysis.
One of the key topics is related to influence maximisation and selection of starting nodes for initialisation of spreading processes. It was defined with main goal to increase the coverage within the network with properly selected seed nodes [16]. Due to the difficulty of finding the exact solution, several heuristics, with the most effective greedy approach [16] and its extensions with adjustable computational performance [9] were proposed trough the course of last years. Apart from that, other seed selection methods were explored, including heuristics based on centrality measures [32], community seeding [38], k-shell decomposition [17], genetic algorithms [34, 35] and other solutions [10]. One of their goals is avoiding overlapping the regions of influence and increase the distance between seeds. It was a key concept behind Vote-Rank method [36] and the studies with its extensions.
Initial works in the area of information diffusion were related to static networks, and later evolved towards temporal networks. They focused on seed selection in dynamic networks and comparison of different approaches [20]. They also focused on links, changing topologies and nodes availability [14]. Recent studies focused on topological features of temporal networks figured out temporal versions of static centrality measures [26, 30, 31] and they can be used for seed selection. As a generalization of the closeness centrality for static networks, Pan and Saramäki define the temporal closeness centrality [25]. Takaguchi proposed method to represent the importance of a temporal vertex defined as temporal coverage centrality [29]. Beside the topological features, recent studies highlighted the dynamics of temporal networks as significant factor of information diffusion [12]. They showed that dynamics-sensitive centrality in temporal networks performed seeds selection much better than topological centrality. In [2] temporal sequence of retweets in Twitter cascades was used to detect a set of influential users by identifying anchor nodes. It is also worth mentioning that in parallel to temporal networks, recently information cascades in multilayer networks are also studied [4, 13, 22].
At this point, it is also important to mention that social influence is a process that is difficult to observe and measure. Individual decisions of the members of a social networks are distributed over time and rarely it is possible to observe them, as they are often internal and not directly bound with actions. This is why we often models are often used to represent the process and their parameters are often derived either based on data [8] or a number of small scale experiments conducted in real world [5, 6].
The approach presented in this study is based on Shannon’s entropy [27] that measures the amount of information. As such, the application of entropy is not a new concept in the area of complex network analysis. Most of the studies, however, focused on the predictive capabilities or global quantification of the dynamics of the network. For instance, Takaguchi et al. evaluated the predictability of the partner sequence for individuals [28]. In [37] authors proposed entropy-based measure to quantify how many typical configurations of social interactions can be expected at any given time, taking into account the history of the network dynamic processes. Shannon entropy has been also used in order to show how Twitter users are focusing on topics comparing to the entire system [33]. Another work is using measures based on entropy for analyzing the human communication dynamics and demonstrating how the complex systems stabilise over time [19]. The results presented in the last work are important to understand that the implications of stabilisation are significantly affecting the diffusion. In the case when our social circles do not change, information has less possibilities to reach different areas of the network. As a consequence, if information has limited chances to appear in some parts of the network, the same would apply to social influence. This observation was the inspiration of our work in which we wanted to find the nodes that have the most-varying neighbourhood, thus the highest chances to spread information to others. This resulted with a entropy-based measure that looks at the variability of neighbourhood, but also takes into account the overall number of different neighbours the nodes has contacted over time.
3 Entropy-Based Measure of Variability
The proposed measure for quantifying the variability of neighbourhood is using the entropy to calculate the diversity of neighbours of a given node \(v_i\) across neighbouring time windows in a temporal network. Introduced measure is focusing on finding the nodes that have the highest exchange in the neighbourhood over consecutive time windows and the values of it can be considered as a diversity of a node. However, to not to fall into specific cases, some additional factors have to be considered as well - these are discussed after introducing the definition of this measure.
The proposed entropy-based measure is expressed in the following way:
where \(e_{ij}\) is the number of all unique edges originating at node \(v_i\) and \(NB_{v_i, n, n+1}\) is the neighbourhood of a node in windows that are next to each other. Defined this way, the measure promotes the nodes that vary the neighbourhood over subsequent windows and incorporates also the size of the neighbourhood itself.
For directed networks, the neighbourhood is expressed as outgoing links, for undirected ones as all links. The last factor is promoting the variability of neighbours in such a way that the set of neighbours should be the widest, since without this element only varying the neighbours across windows next to each other would be enough to maximize the measure.
After calculating this measure for all nodes for given network settings, it has been used as the utility score for choosing seeds - top k percent of nodes have been selected as seeds and activated during window \(T_{{N/2}+1}\).
It is worth underlining that the measure is computed at the node-level and only looks at the neighbourhood of nodes, similarly to the degree-based measures. As a consequence, it has similar computational complexity that is much lower than for betweenness centrality. This makes the measure still applicable for large graphs.
4 Experimental Setting
4.1 Datasets
The experiments have been conducted using two datasets: manufacturing company email communication [24] consisting from emails sent between employees of a manufacturing company over a course of nine months and a Haggle dataset representing contacts between people measured by carried wireless devices [3]. The statistics of the datasets presented in Table 1 indicate that albeit similar in size, the datasets differ in a number of factors contributing to information diffusion, e.g. in an average degree or power law exponent. These datasets have been then converted into a temporal social network according to the model presented in the next subsection. Resulting temporal networks also significantly differ in terms of how nodes and events distribute over windows showing different nature of datasets.
4.2 Temporal Social Network
The temporal social network is based on time windows. For all the evaluated datasets, the periods they cover have been split into n windows of equal time [11]. Then, all the events within a particular window have been a source for building a temporal social network snapshot \(T_n=(V,E)\), \(n \in 1 \ldots N\) consisting from the set of nodes V and the set of directed edges E. The edge weights are defined according to the following formula:
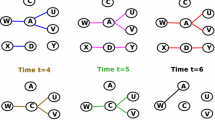
where \(\sum e_{ij}\) is the total number of contacts originated at node i to node j and \(\sum e_i\) is the total number of contacts originated at node i. All self loops were removed. Each snapshot \(T_n\) can be then considered as a static graph where events do collapse into same time frame, but since the snapshots are time-ordered, temporal aspects are preserved at a certain level of granularity. The reasons why this temporal network model was used is that it enables using established seed selection heuristic and diffusion model known for static networks. An exemplary temporal network consisting from five time windows has been shown in Fig. 1. The evaluated values of N have been the following: 8, 16, 32, 64. Half of the windows has been used for training purposes - building rankings of nodes based on evaluated methods - and half for evaluation. In case of this experiment, training purposes mean building the seed set based on the information about behaviour of nodes in the training windows and evaluating their performance is interpreted as a total number of nodes activated at the end of the influence process.
In order to verify whether the datasets chosen for evaluation are different, we investigated the number of unique nodes and number of unique events - Fig. 2 shows how these values evolve over subsequent time windows. It can be observed that whilst for the manufacturing temporal network the number of nodes in each window is relatively stable, this is not the case for Haggle network, since this value undergoes bigger changes. This also impacts the number of events.

A visualisation of a temporal network model based on windows used for experiments.

Number of nodes and number of events for each time window for evaluated datasets: manufacturing company and Haggle for 32 windows.
It should be noted that the introduced measure in this form gives more importance to the nodes that are present in consecutive time windows. Otherwise the \(NB_{v_i, n, n+1}\) of Eq. 1 will be contributing to decreasing the value of the measure for nodes that are not present on subsequent time windows. The reason why it is important to look at the presence of nodes in time windows that are next to each other is depicted in Fig. 3. Here one can see that with the increasing number of windows the number of nodes that exist in all the windows starts to drop significantly after reaching certain critical value.

The number of nodes existing in the all time windows dependent of the number of windows (the granularity of the split) for the manufacturing dataset.
4.3 Social Influence Model
The model chosen for social influence is Independent Cascade Model (IC) [7]. This model assumes that a node has a single chance of activating its neighbour expressed as a probability p. If the node will succeed, this neighbour will become activated and will be attempting to activate its neighbours in the following iterations. As the basic version of this model was proposed for static networks, in the temporal setting we added to modifications to the model: (i) exhaustion of spreading capabilities - in every snapshot \(T_n\) the iterations follow until no further activations are possible, (ii) single attempt of activation - if a node failed to activate its neighbour, in the subsequent snapshots it would not be able to try again. These extensions to the base IC model allow to adequately spread activations over the span of evaluation time windows, but at the same time - restrict from reaching all the nodes too early.
The evaluated independent cascade probabilities have been the following: 0.05, 0.1, 0.15, 0.2, whilst the seed set was the fraction of \(5\%, 10\%, 15\%\) of nodes that appeared in the training set. As the IC model is not deterministic, for each parameter combination we run a 1,000 simulations of the diffusion process. Moreover, in order to make results comparable, we followed the coordinated execution procedure introduced in [15] - the results of drawings have been the same for all the runs.
4.4 Baseline Seeding Strategies
As a reference, we did use the following baseline strategies: in-degree, out-degree and total degree centrality, closeness for the largest connected component, betweenness and random (100 drawings - averaged) seed set [1]. These measures have been computed over an aggregated graph for all events in the training set.
All the experimental parameters are presented in Table 2.
5 Results
In total, we did evaluate 672 combination of all parameters - 96 per measure, as shown in Table 2. Results presented in Fig. 4 show how the measures performed relatively to the entropy-based measure being a reference. As a measure of performance we compare the number of nodes activated at the end of the seeding process - this is a typical approach for comparing different heuristics for social influence.

The performance of evaluated measures relative to the number of activations of the entropy-based measure. Overall, the entropy-based measure has been outperforming others in \(41.5\%\) of cases, the second best-performing heuristic was out-degree with \(16.5\%\). Next: betweenness (\(13.7\%\)), closeness (\(12.05\%\)), in-degree (\(7.7\%\)), total degree (\(6.7\%\)) and random (\(2.2\%\)).
What is observed, the proposed method outperforms the others and the out-degree approach is the second leading one. The second position of out-degree is linked to two factors. Firstly, to the structure of typical social networks. Usually they follow the preferential attachment, so in the case of high degree nodes, these are linked to other nodes with high degree and so on. Secondly, the Independent Cascade Model, as name suggests, compared to some other models like linear threshold does not require any fraction of nodes for activating the neighbours, so the cascades can spark independently of each other. That is why choosing nodes with high outdegree maximizes the chances of starting in the central part of the typical social network.

The similarity of seed sets generated by different heuristics evaluated in this work, including proposed entropy-based one. The metric used for computing the similarity of seed sets is the Jaccard index.
Regarding the variability measure proposed in this work, it also contains the factor promoting the nodes with high number of neighbours (see Eq. 3), however also requires these nodes to vary its neighbours over windows. This, in turn, increases to the possibility of reaching other areas of the directed network that could not have been potentially activated by other seeding strategies.
The differences in terms of number of activated nodes between particular seeding strategies, three seeding strategies: entropy-based, out-degree and betweenness have been performing on average 5–7% better then other degree-based methods. However, among these three, the differences were smaller, on average ranging from 2.5–7% in most cases. This part of experimental analysis shows that the entropy-based measure is capable of generating well-performing seed sets.
One of the research questions we wanted to find answer on is how the seed sets differ. This would indicate whether are there similarities against the seed sets meaning that the nodes also share similar properties in terms of measures. To do so, we compared all the seed sets built by each evaluated heuristics by using the Jaccard index defined as follows:
where \(h_i\) and \(h_j\) are the heuristics that are being compared by the seed sets they generated, \(V^{h_i}\) and \(V^{h_j}\), respectively. Seed sets for each heuristic have been compared pairwise with seed sets of other heuristics for all the experimental parameters (see Table 2) and then the results have been averaged pairwise. Since the random heuristic did not provide coherent results for each run, it has not been compared against others. The results demonstrating the similarity of seed sets generated by different heuristics are presented in Fig. 5. This analysis indicates that there is only a partial similarity between seed sets generated by different heuristics and the introduced entropy-based measure is the most similar to outdegree (0.51) and betweenness (0.41). However, in general, it is observed that the similarity of seed sets is only partial and different nodes are selected for initial activation.
6 Conclusions and Future Work
In this work we proposed a method based on entropy that can be used for seed selection in temporal social networks. The method is basing on the variability of neighbourhood that leads to increasing the spread of influence in the social network. The evaluation of the method demonstrates that in many cases the results for the introduced method outperform other heuristics. Moreover, comparing to some other heuristics that require computing shortest paths in a graph, such as betweenness or closeness, introduced entropy-based measure is simple to compute.
However, it must be noted that this method of influence maximization is suited mostly for models such as Independent Cascade that do not require a committed neighbourhood for activations. Nevertheless, many real-life diffusion cascades are actually following the independent cascade schema, since members of many social networks decide upon adoption of an idea based shortly afterwards observing activities of others. This is often observed in social media where people decide whether to share a content just after being exposed to it. On the other hand, in the case of more complex decisions, these decisions could follow other models. This is why it is a necessity to understand which models apply for certain situations before deciding on the social influence seed selection method.
In the case of temporal networks, one needs to remember that there are new factors that substantially impact the process compared to static network scenario [21]. One of the most important ones relates to the seed set. Contrary to static networks, not all nodes selected for initial activation can appear in the subsequent time windows. This means that a part of the budget can be wasted if some nodes would not appear. Another aspect is the fact that some of the time windows could potentially contain a limited number of edges or, in the worst case, no edges at all. This will impact the dynamics of the spreading process. This is why when considering developing heuristics for social influence in networks, one needs to consider these factors by appropriately looking at the historical behaviour of nodes and the temporal network itself.
Regarding the future work directions, it is planned to follow a number of them. Firstly, we would like to investigate in detail how the nodes selected by the entropy-based method penetrate different areas of the network compared to other heuristics. Next, as results indicate, the seed sets provided by different heuristics only partially overlap, yet some heuristics still produced well-performing seed sets. The idea is to propose a combined mixture-based measure that will take advantage of different properties of nodes in order to be even more successful in activating others. The third direction requires investigating how the proposed measure performs for other models of social influence, e.g. linear threshold.
References
Barabási, A.L., et al.: Network Science. Cambridge University Press, Cambridge (2016)
Bhowmick, A.K., Gueuning, M., Delvenne, J.C., Lambiotte, R., Mitra, B.: Temporal sequence of retweets help to detect influential nodes in social networks. IEEE Trans. Comput. Soc. Syst. 6(3), 441–455 (2019)
Chaintreau, A., Hui, P., Crowcroft, J., Diot, C., Gass, R., Scott, J.: Impact of human mobility on opportunistic forwarding algorithms. IEEE Trans. Mob. Comput. 6(6), 606–620 (2007)
Erlandsson, F., Bródka, P., Borg, A.: Seed selection for information cascade in multilayer networks. In: Cherifi, C., Cherifi, H., Karsai, M., Musolesi, M. (eds.) COMPLEX NETWORKS 2017 2017. SCI, vol. 689, pp. 426–436. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-72150-7_35
Friedkin, N.E., Cook, K.S.: Peer group influence. Soc. Methods Res. 19(1), 122–143 (1990)
Friedkin, N.E., Johnsen, E.C.: Social Influence Network Theory: A sociological Examination of Small Group Dynamics, vol. 33. Cambridge University Press, Cambridge (2011)
Goldenberg, J., Libai, B., Muller, E.: Talk of the network: a complex systems look at the underlying process of word-of-mouth. Mark. Lett. 12(3), 211–223 (2001). https://doi.org/10.1023/A:1011122126881
Goyal, A., Bonchi, F., Lakshmanan, L.V.: Learning influence probabilities in social networks. In: Proceedings of the third ACM international conference on Web search and data mining, pp. 241–250 (2010)
Goyal, A., Lu, W., Lakshmanan, L.V.: Celf++: optimizing the greedy algorithm for influence maximization in social networks. In: Proceedings of the 20th international conference companion on World wide web, pp. 47–48. ACM (2011)
Hinz, O., Skiera, B., Barrot, C., Becker, J.U.: Seeding strategies for viral marketing: an empirical comparison. J. Mark. 75(6), 55–71 (2011)
Holme, P., Saramäki, J.: Temporal networks. Phys. Rep. 519(3), 97–125 (2012)
Huang, D.W., Yu, Z.G.: Dynamic-sensitive centrality of nodes in temporal networks. Sci. Rep. 7, 41454 (2017)
Jankowski, J., Michalski, R., Bródka, P.: A multilayer network dataset of interaction and influence spreading in a virtual world. Sci. Data 4, 170144 (2017)
Jankowski, J., Michalski, R., Kazienko, P.: Compensatory seeding in networks with varying avaliability of nodes. In: 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, ASONAM 2013, pp. 1242–1249. IEEE (2013)
Jankowski, J., et al.: Probing limits of information spread with sequential seeding. Sci. Rep. 8(1), 13996 (2018)
Kempe, D., Kleinberg, J., Tardos, É.: Maximizing the spread of influence through a social network. In: Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 137–146 (2003)
Kitsak, M., et al.: Identification of influential spreaders in complex networks. Nat. Phys. 6(11), 888 (2010)
Kivelä, M., Arenas, A., Barthelemy, M., Gleeson, J.P., Moreno, Y., Porter, M.A.: Multilayer networks. J. Complex Netw. 2(3), 203–271 (2014)
Kulisiewicz, M., Kazienko, P., Szymanski, B.K., Michalski, R.: Entropy measures of human communication dynamics. Sci. Rep. 8(1), 1–8 (2018)
Michalski, R., Kajdanowicz, T., Bródka, P., Kazienko, P.: Seed selection for spread of influence in social networks: temporal vs static approach. New Gener. Comput. 32(3–4), 213–235 (2014)
Michalski, R., Kazienko, P.: Maximizing social influence in real-world networks—the state of the art and current challenges. In: Król, D., Fay, D., Gabryś, B. (eds.) Propagation Phenomena in Real World Networks. ISRL, vol. 85, pp. 329–359. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-15916-4_14
Michalski, R., Kazienko, P., Jankowski, J.: Convince a dozen more and succeed-the influence in multi-layered social networks. In: 2013 International Conference on Signal-Image Technology & Internet-Based Systems, pp. 499–505. IEEE (2013)
Michalski, R., Palus, S., Bródka, P., Kazienko, P., Juszczyszyn, K.: Modelling social network evolution. In: Datta, A., Shulman, S., Zheng, B., Lin, S.-D., Sun, A., Lim, E.-P. (eds.) SocInfo 2011. LNCS, vol. 6984, pp. 283–286. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-24704-0_30
Nurek, M., Michalski, R.: Combining machine learning and social network analysis to reveal the organizational structures. Appl. Sci. 10(5), 1699 (2020)
Pan, R.K., Saramäki, J.: Path lengths, correlations, and centrality in temporal networks. Phys. Rev. E 84(1), 016105 (2011)
Pfitzner, R., Scholtes, I., Garas, A., Tessone, C.J., Schweitzer, F.: Betweenness preference: quantifying correlations in the topological dynamics of temporal networks. Phys. Rev. Lett. 110(19), 198701 (2013)
Shannon, C.E.: A mathematical theory of communication. Bell Syst. Tech. J. 27(3), 379–423 (1948)
Takaguchi, T., Nakamura, M., Sato, N., Yano, K., Masuda, N.: Predictability of conversation partners. Phys. Rev. X 1(1), 011008 (2011)
Takaguchi, T., Yano, Y., Yoshida, Y.: Coverage centralities for temporal networks. Eur. Phys. J. B 89(2), 1–11 (2016). https://doi.org/10.1140/epjb/e2016-60498-7
Tang, J., Scellato, S., Musolesi, M., Mascolo, C., Latora, V.: Small-world behavior in time-varying graphs. Phys. Rev. E 81(5), 055101 (2010)
Taylor, D., Myers, S.A., Clauset, A., Porter, M.A., Mucha, P.J.: Eigenvector-based centrality measures for temporal networks. Multiscale Model. Simul. 15(1), 537–574 (2017)
Wang, X., Zhang, X., Zhao, C., Yi, D.: Maximizing the spread of influence via generalized degree discount. PLoS ONE 11(10), e0164393 (2016)
Weng, L., Flammini, A., Vespignani, A., Menczer, F.: Competition among memes in a world with limited attention. Sci. Rep. 2, 335 (2012)
Weskida, M., Michalski, R.: Evolutionary algorithm for seed selection in social influence process. In: 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, ASONAM, pp. 1189–1196. IEEE (2016)
Weskida, M., Michalski, R.: Finding influentials in social networks using evolutionary algorithm. J. Comput. Sci. 31, 77–85 (2019)
Zhang, J.X., Chen, D.B., Dong, Q., Zhao, Z.D.: Identifying a set of influential spreaders in complex networks. Sci. Rep. 6, 27823 (2016)
Zhao, K., Karsai, M., Bianconi, G.: Models, entropy and information of temporal social networks. In: Holme, P., Saramäki, J. (eds.) Temporal Networks. Understanding Complex Systems, pp. 95–117. Springer, Heidelberg (2013)
Zhao, Y., Li, S., Jin, F.: Identification of influential nodes in social networks with community structure based on label propagation. Neurocomputing 210, 34–44 (2016)
Zhuang, H., Sun, Y., Tang, J., Zhang, J., Sun, X.: Influence maximization in dynamic social networks. In: 2013 IEEE 13th International Conference on Data Mining, pp. 1313–1318. IEEE (2013)
Acknowledgments
This work was supported by the National Science Centre, Poland, grant no. 2016/21/B/HS4/01562.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Michalski, R., Jankowski, J., Pazura, P. (2020). Entropy-Based Measure for Influence Maximization in Temporal Networks. In: Krzhizhanovskaya, V.V., et al. Computational Science – ICCS 2020. ICCS 2020. Lecture Notes in Computer Science(), vol 12140. Springer, Cham. https://doi.org/10.1007/978-3-030-50423-6_21
Download citation
DOI: https://doi.org/10.1007/978-3-030-50423-6_21
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-50422-9
Online ISBN: 978-3-030-50423-6
eBook Packages: Computer ScienceComputer Science (R0)