
Abstract
It is usually taken for granted that Direct Manipulation is the best interaction style for inexperienced or non-expert users; moreover, this style of interaction is generally considered the best for almost every situation and user. The recent shifts in technology that we all are currently experiencing have given rise to a great deal of new kinds of users performing specific tasks in a variety of scenarios. In this paper, we focus on users who access a system occasionally, infrequently, or in an unplanned way; i.e., users who do not want or cannot afford a learning curve. We show that for them, Direct Manipulation is not always the most suitable style of interaction. We assess the advantages of guiding this kind of users, in particular through the guided interaction framework known as Goal Driven Interaction. GDI can be viewed as a superset of wizards providing support far beyond a few steps through dialogs. Indeed, GDI is an interaction style with characteristics of its own. We report a complete user test that backs up previous hypotheses. The analysis of empirical data proves that GDI is more time-efficient than DM, requiring fewer moderator assistances for the users. Post-test questionnaires confirmed that participants had a strong preference for GDI.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Interaction design process and methods
- Interaction paradigms
- Empirical studies in interaction design
- Interfaces for occasional users
1 Introduction
Interaction Style is a classic topic discussed in the mainstream HCI literature, e.g. [14, 43]. There are two main general approaches to interact with computers: the conversational world and the model world, corresponding to sequential and freely accessible dialogues, respectively. The former includes Question and Answer dialogues, Command Line interfaces, Menu-based interaction, Form Fill-in data entry, Natural Language, etcetera; text is therefore the primary tool for interaction between the user and the system in this model. The other general approach, the model world, makes use of graphics and metaphors [8] as well as tools like Windows, Icons, Menus and Pointer (WIMP), to assist the user with asynchronous and free management of objects on the screen. The Direct Manipulation (DM) [18, 42, 43] of interactive elements makes this general approach even more familiar and intuitive. Ideally, the users see and predict the behavior of well-known objects through metaphors. They then follow their natural intuition to manipulate them, receiving immediate feedback: “You don’t notice the computer because you think of yourself as doing the task, not as using the computer”, Norman [35]. However, DM-WIMP interfaces still require time to become acquainted with them. In particular, Stasko stated: “…Although GUI and WIMP interfaces are a big step past line-oriented terminals, they still have a learning curve and they can be awkward to use”.
Whatever the case may be, the success of the DM approach has eclipsed the others. These interfaces are typically assumed to be the best solution for every possible scenario, task and user. However, the massive expansion of technology has caused the appearance of new scenarios of use in addition to quite different tasks and users for them. This requires revisiting the most appropriate approach for each case. The success of the interaction depends basically upon its suitability for the final user. There are many differences between how experts and novices perceive and use software applications [13]. On the one hand, experts have the best possible mental model thanks to their experience. As opposed to novices, they require less guidance and help. On the other hand, novices are users with little or no knowledge about the system. They initially have a deficient understanding about the possibilities of the application and have to focus on how to deal with the interface [28]. To gain expertise they follow a learning curve that is usually traversed through study and repeated use of the application. Moran [28] argued that for novices learning to use the interface is more important than being able to accomplish the task: “Learning is, of course, paramount for the novice whereas the time it takes to do a task is secondary”. Interestingly, there are situations where learnability is not as important as the time elapsed in the interaction. For example, purchasing a train ticket in a self-service machine when the train is on the verge of departing. The aim here is to accomplish the transaction as quickly as possible. In such cases, learning how to use the application is not as relevant as just getting it done. Achieving the goal, i.e., getting the ticket in your hand, becomes the priority, while learning during the interaction – an action that may not even be repeated at all in the future – becomes secondary (“[the user] does not have any ambition to master the system and may prefer to be led by the hand to accomplish…”) [46]. Then, some problems arise when a system is occasionally accessed and the user does not want or cannot afford a learning curve.
At least three arguments support an explicit design of systems for these occasional users: advances in UIs, new scenarios of use, and a more ambitious inclusive design. Firstly, the evolution of Graphical User Interface (GUI) [30, 43] and the correct inclusion of multi-touch systems [5, 36, 40] have brought about new kinds of devices and new ways of interaction. Secondly, the ubiquity and the permanent on-line interconnection of mobile devices have burst into unexplored contexts of use, e.g. shopping centres, leisure facilities, museums, airports… [11, 15, 41]. These technologies have facilitated new scenarios of use where human-computer interaction (HCI) is on the move, using technology as a mean to accomplish an immediate goal. Thirdly, this increase in the heterogeneity and number of occasional users is also driven by the incorporation of the principles of Accessibility [1, 29, 47], Usability [32, 33] and Inclusive Design [12, 39].
In summary, there is a wider spectrum of users able to perform not only planned but also occasional activities. This new scenario demands simplicity, immediacy and no previous knowledge, just like when buying a transport ticket in a self-service machine, visiting a new city, designing or furnishing a room, or using an audio-guide mobile app during the visit to a museum or archaeological site. Our aim is to check with real users which kind of interface – either guided or non-guided – they prefer. The selected guided interaction style, namely Goal Driven Interaction (GDI), is introduced in Sect. 2. We compare a GDI-guided standard application for furnishing kitchens with its non-guided counterpart. In Sect. 3 we present our experiment, and in Sect. 4 we discuss the results.
2 Goals Driven Interaction
Goals Driven Interaction (GDI) [9] is conceived as a human-computer interaction style especially suitable for occasional users, that is, users who do not want or cannot afford a learning curve. This means that even if the user dealt previously with the same or analogous technology, there are a number of factors that make it unwise to rely on the user’s memory recall or implicit visual recognition as the main mechanisms to learn how to use the interface. Some of those factors could be the time elapsed since the last interaction, the difficulties users experience on learning, and, in many cases, their lack of interest [17]. It is recommended to assume that the user will have to cope with an unknown interface, with no requirement upon previous knowledge to use it. The corresponding style of interaction will be of conversational and sequential nature, even sacrificing the possibility of performing tasks in parallel as well as other typical advantages of pure DM interfaces. This does not prevent the user from deciding among alternatives. The objective here is to guide the user, step by step, in a hierarchical way along the whole interaction. Thus, hierarchically organized objectives and sub-objectives will be clearly presented to the user one at a time. The goals, once achieved, are left behind. Nevertheless, the user will have the possibility to return to past goals, via cancellation, whenever it is possible to do so. The user will be strictly guided on the “what to do” and the “how to do it,” one step at a time. This strategy constrains the freedom of the DM in a similar way to processes guided by wizards [4, 27, 45, 48]. In some sense, GDI could be viewed as a layer over pure DM, making it a kind of assisted interaction, adding control over DM: it allows the user to touch, move or briefly interact with graphic objects, but only when the guide allows for it. It could also be viewed as a super-set of wizards. Standard DM transfers the control to the user whereas GDI guides them.
The fundamentals of GDI trace back to the work of [31] devoted to the mechanisms of human reasoning for problems resolution. Their vision (as in GDI) was based on breaking up the main or general goal into a hierarchical tree of sub-goals. The branches of that tree can have different lengths depending on the degree of fragmentation in sub-goals. The leaves of the tree are elementary actions or final goals that do not require further explanations nor decomposition. Based on this work, Card, Moran and Newell [6, 7] developed one of the most important cognitive models, the Human Processing Model, whose initial paradigm consisted in conceiving the interaction as a problem resolution task. They described a psychological model of humans comprising three interactive systems: perceptive, motor and cognitive. Each one would have its own memory and its own processor. This vision of the user as an information processing system permits the description of all the activities (both physical and mental) that take part in a task. This in turn gave origin to a family of methods for modelling, specifying and evaluating a user interface: the GOMS models [20,21,22]. A GOMS (Goals, Operators, Methods, and Selection rules) model is a description of the knowledge a user must have in order to carry out tasks and thereby goals on a device; it is a representation of the “how to do it”. The aim of GDI is to preclude the user from having to devote time to acquire that knowledge. The user will not need to look anything up in any user manual, or help system, nor think about anything except navigating through the proposed steps. We only expect from the user to know the goal to achieve.
There are many versions derived from the original GOMS. In particular, Kieras [24, 25] contributed with the idea of a structured natural language, namely NGOMSL (Natural GOMS Language). These methodologies themselves are framed in a larger set of techniques enabling a hierarchical task analysis. The main goal of these techniques is the decomposition of a complex task in sub-tasks, so that the resolution method can be followed step by step. For instance, HTA [2], TAG [38], TKS [23], or the more recent CTT [37], that also includes the possibility of expressing the concurrency of the tasks. None of them were oriented to readiness but to formalization and have been discarded for our methodology. In contrast, NGOMSL presents a wide and detailed literature, as well as practical construction methods, e.g. [24, 25], that can be broadly applied. But above all, the most interesting feature of GDI is their closeness to the user’s natural language: any user can read and follow it, as a recipe. NGOMSL can be used to specify GDI interfaces but it could not qualify to model some situations and aspects of GDI. To overcome this issue the authors have extended and adapted NGOMSL, for instance by including the possibility of cancelling goals. This extended version can be used as a source specification language [9].
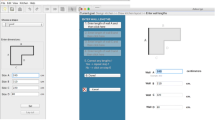
From the specification obtained applying our extension of NGOMSL is possible, after an easy compilation process, to obtain the corresponding guide of the final GDI interface, which composes the Goal Driven Area. GDA is what explicitly guides the user through the hierarchy of goals (Fig. 1). This area becomes the substitute for the typical menus and toolbars used in standard MD-WIMP, not necessary for these guided interfaces. GDA will always show the method or the selection that allows the user to accomplish the current goal. If this goal requires the user to make a selection, GDA shows the different excluding options (alternatives) that compose that selection, so that the user can choose one of them. In case the goal must be accomplished following a specific method, GDA will offer the sequence of steps that compose this method. The interface underlines the current step, which could imply the initiation of a new subgoal (and then another method or selection), or the realization of an elementary action (without methods nor selections).

Proposed layout of a GDI interface, when offering a method (on the left) or a selection (on the right)
3 GDI vs Standard DM Interfaces: A Comparative Study
At the beginning of the previous section, we explained that GDI was proposed as a way to help occasional users who do not want or cannot afford a learning curve for specific goals. Our aim has been to test this postulate with real users. To that end, a comparative study between guided and non-guided interaction has been conducted. This empirical analysis gave us objective measurements and subjective opinions. We wanted to test 2 objectively measurable hypothesis, related to time and errors, and a third subjective hypothesis, related to satisfaction.
For non-computer experts, occasional users:
-
(H1) they proceed quicker with GDI than with standard DM,
-
(H2) they make fewer errors with GDI than with standard DM,
-
(H3) they prefer GDI to standard DM.
As can be seen, the 3 pillars of usability are covered: efficiency (H1), effectivity (H2), and satisfaction (H3).
A first approach to this study was presented in [10] as “work in progress”. However, that work could only show what appeared to be a trend, since it had very few participants, and lacked analysis, discussion and statistical study about the significance of the results.
3.1 Participants
The study involved twenty volunteer participants (n = 20), a number that meets the criteria of [3, 26, 34, 44]. There were 12 females and 8 males. Their ages ranged from 10 to 52 years, with a mean age of 44 years. All subjects were unaware of the final aim of the research. They had not participated in previous usability studies nor had they received any incentives to participate in the experiment. Each participant had to use two different versions of the same application (the two types of interfaces to be compared), following a counterbalanced strategy (as we will explain later).
Table 1 summarizes the main data and characteristics of the participants, collected by means of a Background Questionnaire.
To do the recruiting and screening of the participants, the primary requirement was no previous experience with similar applications to those tested in this study. Only two exceptions were intentionally included: two participants were professionals at the task domain. Both of them had this task as part of their daily activity using similar commercial direct manipulation software packages. The other screening criterion was to discard computer expert users, as reflected in Table 1: no participant had a self-graded Computer Expertise greater than 3 on a 5–point scale. This parameter is subjective. To confirm these self-assigned values, we also asked several complementary questions: PUS, KDSK, TSE, TDK, ASL, and ORK (see Table 1). A complementary study with Eye Tracker was conducted for two of the participants. See Sect. 3.6.4 for details.
3.2 Materials and Tasks
Although other applications could be plausible, we chose for our study a familiar domain, i.e. kitchen furniture. This scenario comprises three development stages: designing, furnishing and final adjustments of a kitchen. Some of the involved tasks require extensive object manipulation, usually implemented with standard DM interfaces. These characteristics could lead us to think that this is an application especially suitable for a classic DM interaction style, making it particularly challenging for our study.
We developed two versions of the same application (in Java language), one with a GDI interface and the other with a classic DM interface (Fig. 2). Both share most of the code except for the sections in which the user interfaces are involved. Both offer the same functionality and allow the user to achieve the same goals. The DM version is inspired by the desktop version offered by IKEA [19]. Figure 2 depicts a sub-task per row for each of the stages the user goes through. The left column corresponds to the DM interface whereas the right column is related to the GDI interface. The DM interface is a plain standard WIMP application. The user first introduces the shape and the dimensions of the kitchen and then furnishes it. To this end, the user has to pick elements and position them inside the boundaries following the canonical DM way, i.e. with undo/re-do, tool-tips for buttons, right-click pop-up menus, etc.

Screenshots of the tested interfaces: (a) On the left, the DM interface; (b) On the right, the development of the same task using the GDI interface. The first pair of screenshots is related to the process of entering the dimensions of the kitchen walls. In the second pair the user is selecting and adding a window. In the third pair, the user is moving furniture around.
Regarding the three screenshots on the right column for the GDI interface, note that the user is presented with a list of actions to be read and followed. Each action is atomically performed by short DM interactions in the Working Area. The user cannot continue until the previous action is completed, as we explained in Sect. 2.
-
A screencast of a participant using GDI can be watched in https://youtu.be/4owtCVMuqc4
-
A screencast of a participant using DM is shown in https://youtu.be/QeafXLlsXzY
-
The source code for both applications is available in https://github.com/juanfal/ADICO
Each participant was given a single piece of paper containing the information shown below. It briefly described the application scenario along with the three groups of tasks chosen for the test:

3.3 Study Design
Our study used a Within-Subjects Design with one independent variable, namely the type of interaction. This independent variable has two levels: a GDI interaction and a classic DM interaction.
This Within-Subjects Design or Repeated Measures Design was necessary since we wanted each participant experienced both styles of interaction. It was important that both treatment groups exactly included the same participants. We wanted them to compare both interfaces expressing their preferences, and not to worry about personal characteristics that could bias our results.
On the other hand, in order to mitigate the potential transfer-of-learning effect caused by testing one type of interface prior to the other, a counterbalanced strategy was applied alternating the order among users. Half of the participants started with GDI, while the other half started with DM.
3.4 Measurements
3.4.1 Quantitative Measurements: Time on Task and Number of Errors
The first empirical data to be considered in this study is time on task. In this sense, we will denote as \( \texttt{T}_{\texttt{t1}} \), \( \texttt{T}_{\texttt{t2}} \), and \( \texttt{T}_{\texttt{t3}} \), the time, in seconds, that participants spent on each of the three groups of tasks, respectively. These tasks were labelled in the task sheet (Sect. 3.2) as “Task 1: Specifying how your kitchen is,” “Task 2: Choosing furniture” and “Task 3: Retouching and ordering,” respectively. TT will be the total time, i.e. the sum of \( \texttt{T}_{\texttt{t1}} \), \( \texttt{T}_{\texttt{t2}} \), and \( \texttt{T}_{\texttt{t3}} \).
The analysis of types of errors is an important and necessary complement to the timing analysis. If severe errors occurred (without the assistance of the moderator), then the time on task would be highly affected, or even worse, could prevent the user from completing the task.
Three degrees of errors have been considered, namely slight, moderate, and severe:
-
The severe or blocking error took place when the user was stuck with something in the interface, preventing them from finishing the task. The moderator always assisted users with severe mistakes in order to have them finishing all the tasks and collect the corresponding user data.
-
Moderate errors corresponded to non-blocking mistakes – not necessarily detected by the user – that could alter the outcome. In some cases, these issues could require warnings from the moderator.
-
Finally, slight errors could not be categorised as actual errors because the user could resolve them without any moderator assistance, yet perhaps spending a bit more than the typically expected time.
Table 2 displays the concrete list of errors detected during the tests including, among other things, the type of interface and the task in which they occurred.
3.4.2 Subjective Measurements
We present two sets of subjective data in this paper, collected from two types of questionnaires. The first set is composed of two identical post-test questionnaires that participants filled immediately after finishing with each interface. These post-test questionnaires ask the participant seven questions (\( \texttt{Q}_{\texttt{i}} \)). All \( \texttt{Q}_{\texttt{i}} \) questions, except for \( \texttt{Q}_{\texttt{5}} \), are scored with a numerical value (Table 7). The SUS (System Usability Scale) standard questionnaire was our first choice to use as the post-test questionnaire, but finally we decided to substitute its very generic questions for others more concrete and relevant for our study.
These questions are:
-
\( \texttt{Q}_{\texttt{1}} \): “Do you consider that the application has helped you in knowing what to do in each moment?”
-
\( \texttt{Q}_{\texttt{2}} \): “Do you consider that the application has helped you in knowing how to do it? (what you needed to do)”
-
\( \texttt{Q}_{\texttt{3}} \): “What was harder? (1) knowing what to do, (2) knowing how to get it done, (0) both easy, or (3) both hard”. The scores were chosen according to a range between the best and the worst-case scenarios.
-
\( \texttt{Q}_{\texttt{4}} \): “Would you like to have had a more complete help system inside the application interface?”
-
\( \texttt{Q}_{\texttt{5}} \): “Choose (multiple choice) types of periodicity of use you consider the application is appropriate for - Just once, - Very rarely (once a year), - Once a month, - Daily”
-
\( \texttt{Q}_{\texttt{6}} \): “Would you use a similar application for the design of your next kitchen?”
-
\( \texttt{Q}_{\texttt{7}} \): “To summarize, grade how easy the application is to use”
The second set of data comes from one unique and final comparative questionnaire that participants filled at the very end, once they had used both interfaces. This questionnaire makes them directly compare both interaction styles through the next eight questions (\( \texttt{C}_{\texttt{i}} \)):
-
\( \texttt{C}_{\texttt{1}} \): “With which interface is it easier to know what to do in each moment?”
-
\( \texttt{C}_{\texttt{2}} \): “With which interface is it easier to know how to do it?”
-
\( \texttt{C}_{\texttt{3}} \): “Which interface should include more help systems?”
-
\( \texttt{C}_{\texttt{4}} \): “Which interface is easier to use and requires less training?”
-
\( \texttt{C}_{\texttt{5}} \): “Which interface lets you work quicker?”
-
\( \texttt{C}_{\texttt{6}} \): “Which interface would you recommend to a computer professional for an occasional use?”
-
\( \texttt{C}_{\texttt{7}} \): “Which interface would you recommend to a kitchen design professional for a daily use?”
-
\( \texttt{C}_{\texttt{8}} \): “Which interface would you choose for furnishing your kitchen?”
3.5 Study Procedure
The estimated time per user (including questionnaires) ranged from 45 to 75 min. The tests were performed individually in an interference-free environment, except for the presence of the moderator. A common laptop computer was used for all the tests. This facilitated their relocation and was less intimidating and more familiar to users than any other bigger equipment. Mouse and keyboard were the input devices. The whole process of interaction was recorded from both the computer screen and the device microphone for further analysis when necessary.
Prior to the main study, a pilot experiment was carried out. It involved a group of 4 participants. This experiment allowed us to fine-tune the test procedure, the time span, and the descriptions of each task and questionnaire.
The procedure for the study followed the next steps:
-
1.
All participants signed an informed consent and were briefed about the fact that the tests were taken voluntarily, being free to leave at any time without any justification.
-
2.
The users read the moderator script to ensure that each participant received the same information about the type of test, the purpose of the study, and the testing process. This document also clarified that these tests were not intended to make any personal or psychological assessment, but were exclusively conducted for the evaluation of the involved computer interfaces. Then, the moderator answered any participant questions or concerns, if any.
-
3.
The participants filled out a preliminary background questionnaire in order to collect user characteristics, such as age, gender, computer skills, previous software knowledge, task domain knowledge, etc. This helped to check whether the participants met the screening criteria (described in Sect. 3.1)
-
4.
The users received a single-sheet document briefly describing the three groups of tasks to perform (detailed in Sect. 3.2).
-
5.
As mentioned above, in order to implement a counterbalanced strategy, each participant was asked to use both versions of the application (alternating the order after each user). The so-called Thinking Aloud technique was also applied, but in a relaxed way. The participants were not forced to explain what they were doing any time, but they were free to express themselves. The moderator tried either not to interfere at all, or to intervene only in some non-blocking situations and always in the few critical or blocking situations that took place. Specific, the moderator couldn’t answer any questions, and the users were allowed to express what they were thinking. The moderator tried not to interfere except with: (a) “severe errors”, (b) some “moderate errors”, and (c) to redirect a test. The concrete errors related to (a) and (b) and the type of assistance provided for each of them are shown in Table 2. In the last case, (c), the moderator intervened diverting a test if the user was lasting too long on it, or if they were overwhelmed not knowing how to do something. In some of these cases, we insisted we were evaluating the interface, not themselves.
Every error was systematically noted down and categorised as part of the data collection. For every user and for each type of interface, the time the participant spent on achieving each task was written down as well. The whole process of interaction was recorded with a computer screen and voice recording software for further re-examination when necessary. In this sense, all the measurements were checked (and corrected, in necessary case) according to a thoroughly analysis of the screen recordings.
-
6.
At the end of the use of each interface, but before moving on to the other, the participants filled out the corresponding post-test questionnaire (detailed in Sect. 3.4.2) on subjective and specific usability points about the interaction they have just experienced. This questionnaire covered important aspects for the final evaluation.
-
7.
Finally, the participants filled out the comparative questionnaire (detailed in Sect. 3.4.2) for comparison of both styles of interaction, requiring them to directly express their preferences.
3.6 Results
On the one hand, we have repeated measures designs with two conditions in our experiments because the same participant uses both types of interfaces. On the other hand, the data are not normally distributed, and then do not meet the requirements for parametric tests. Thus, to verify the significance of the results, the most appropriate statistical method is a non-parametric Wilcoxon paired-sample test, also known as Wilcoxon signed-rank test [49].
We next present the results in the following order: first, in Sect. 3.6.1, the quantitative performance measurements through the time on tasks and the number of errors; second, in Sect. 3.6.2, the subjective data about each interface; and, third, in Sect. 3.6.3, the personal preferences. Finally, in Sect. 3.6.4, we elaborate on the Eye Tracker experiment.
A comprehensive document including all the tables can be downloaded from http://bit.ly/2my1rYg.
3.6.1 Quantitative Empirical Measurements: Time on Task and Number of Errors
Tables 3 and 4 display the main statistics regarding time on task (\( \texttt{T}_{\texttt{t1}} \), \( \texttt{T}_{\texttt{t2}} \), \( \texttt{T}_{\texttt{t3}} \), and \( \texttt{T}_{\texttt{T}} \)) and number of errors (\( \texttt{slight} \), \( \texttt{moderate} \), and \( \texttt{severe} \)), respectively.
The corresponding Wilcoxon tests (Table 5) for \( \texttt{T}_{\texttt{t1}} \), \( \texttt{T}_{\texttt{t3}} \) and especially for \( \texttt{T}_{\texttt{T}} \), revealed significant differences (p < 0.01) in favor of GDI, namely lower time intervals using GDI than using DM. Only the test for \( \texttt{T}_{\texttt{t2}} \), a task consisting of repetitive operations, showed no significant difference between the two ways of interaction. Therefore, we may partially accept H1.
Concerning errors, the results of the Wilcoxon tests (Table 5) for the number of \( \texttt{slight} \), \( \texttt{moderate} \) and \( \texttt{severe} \) errors produce significant differences (p < 0.02) in favor of GDI: DM presents a significant increase in the number of errors when compared with GDI. Therefore, we can accept H2.
Table 6 highlights how evident these results are by pointing out some relevant percentages: first, in accordance with \( \texttt{T}_{\texttt{T}} \), 95% of users finished earlier using GDI than using the DM interface; second, 91% of the errors occurred under DM interaction versus only 9% under GDI.
3.6.2 Subjective Results from Post-tests Questionnaires
In Sect. 3.4.2 we remarked that the subjective post-test questionnaire used in this experiment included seven questions (Qi) for the participants. They answered them as soon as they finished the tasks with each type of interface.
Table 7 shows some statistics summarizing the scores of each \( \texttt{Q}_{\texttt{i}} \), except for \( \texttt{Q}_{\texttt{5}} \) (not answered with a numerical value). According to the corresponding Wilcoxon paired-sample tests, the result for each \( \texttt{Q}_{\texttt{i}} \), except for \( \texttt{Q}_{\texttt{5}} \), exhibits significant differences (p < 0.001) in the scores in favor of GDI. Therefore, we can accept H3.
Regarding \( \texttt{Q}_{\texttt{5}} \), 80% of the participants considered that the DM interface is less appropriate for one-time or occasional use. Unexpectedly, 100% of the participants, including the two professionals at the task domain, considered GDI appropriate not only for occasional use but also for frequent use. Consequently, as far as these opinions are concerned, they did not find the use of guiding obtrusive.
3.6.3 Results from the Comparative Questionnaire: the User Preference
Regarding the final questionnaire composed of eight Ci comparative questions, Table 8 shows the percentage of participants preferring one way of interaction over the other. 100% of participants were clearly in favor of GDI. This might not be surprising among unskilled users, but it is remarkable in the case of kitchen designers, who are used to more completed and sophisticated DM interfaces.
We next quote some samples of the opinions expressed by the participants:
-
“… [GDI interface] liked me a lot for its reliance explaining it all… the other system [DM] leaves you sort of lost”,
-
“It doesn’t matter you don’t know about it, the system [GDI] tells you all along what’s next”,
-
“I like it more the other [GDI], it’s much easier; this one [DM] doesn’t tell you what you have to do, you have to know it, the other guides you”
3.6.4 Results from a Short Eye Tracker Analysis
Aside from the main study, we conducted a quick and simple eye tracking experiment only for two participants randomly chosen. We did not try to draw important conclusions here but simply to know the most frequent screen regions the users were looking at with each type of interface. The algorithm k-means was executed using the statistical package R, searching for hot regions manifested through point clustering. The optimum value of k for the k-means was obtained using the elbow method. This algorithm helps to automatically find, through iterative evaluation, the optimum number of clusters for a cloud of points (see, for example, [16]). This analysis showed many more points and a larger number of clusters for the DM than for the GDI type of interface. The larger number of points logically corresponds with longer time periods spent whereas the double number of clusters (12 versus 6) is associated with higher complexity. This simply reinforced our study, but as no relevant conclusions could be drawn, it was not extended to more users. The experiment results have not been included in the final numerical analysis.
4 Discussion and Conclusions
The recent shift in technology has brought about many new kinds of users who use systems occasionally in more scenarios. These are mostly users who do not want or cannot afford a learning curve. There have been many attempts to help them while they are interacting with the system. Agents, floating help windows, tooltips, direct video demonstrations, etc., have shown us the necessity of guiding the user. These help systems are ways to support the DM appealing style, but inevitably add an extra layer of supporting material over the basic direct manipulation.
We propose GDI as the basis for a completely different approach: do not expect the user to understand and use a metaphor but guide them throughout the whole process. The help system is part of the interaction; it is integrated in the interface. The user will be closely guided on the “what to do” and the “how to do,” one step at a time, always according to their current goal. Consequently, these users do not have much freedom of action. They do not need to be familiar with graphical widgets or think what the next command should be. No previous knowledge is required, shortening significantly the learning curve, if any.
To support the previous assertions the authors have developed a real interface for each type of interaction. Then they have made occasional users choose which one they consider the best.
It was necessary to decide what kind of application could be appropriate for the study. The premises were: first, being an application suitable for an occasional use. Second, being an application for a widespread domain, valid for all ages, genders, and domain knowledge. And third, being an application that normally uses direct manipulation with different kinds of tasks. As a previous step, we verified that there are no interfaces other than classic DM interfaces available for kitchen design. This is a task mostly performed on an occasional basis. The design of a kitchen is a fairly open and well-known task that requires a lot of interactive objects for the user to manipulate.
When comparing both types of interfaces, three hypotheses, H1, H2, and H3, were established. The second hypothesis refers to the number of errors. It seemed natural to expect that guiding the users would prevent them from making mistakes, needing fewer moderator assistances. The obtained results have totally proven this hypothesis: for occasional use, users who are not computer experts make fewer errors using GDI than using DM.
Our first hypothesis refers to timing: non-expert occasional users proceed quicker with GDI than with standard DM. H1 may seem counterintuitive: following a sequence of steps seems to be slower than directly manipulate elements. However, the analysis of the collected data shows that GDI is more time-efficient than DM. The only task for which there was no significant difference was the repetitive Task 2.
The last hypothesis H3 has been first indirectly demonstrated from the answers of users in the post-test questionnaires, and then directly demonstrated from the final comparative questionnaires. These answers highlighted the fact that all the participants had a strong preference for GDI. For example, according to \( \texttt{C}_{\texttt{4}} \), 100% of them consider that GDI is easier to use and requires less training than DM. The answers to the questions \( \texttt{Q}_{\texttt{1}} \) to \( \texttt{Q}_{\texttt{4}} \) and \( \texttt{C}_{\texttt{1}} \) to \( \texttt{C}_{\texttt{3}} \) showed the users felt guided on the “what to do” and the “how to do,” which is one of the main goals of a GDI interface.
Regarding \( \texttt{Q}_{\texttt{5}} \), being a question about the prospect of using both types of interfaces in the future, we should not take it but as an indication of satisfaction and never should it be taken as an accurate prediction. Still, it was unexpected to find that all participants, professionals included, considered GDI appropriate not only for occasional but for frequent use. Moreover, 80% of the participants considered that the DM interface is appropriate neither for one-time nor occasional use.
Domain professional users provided additional unexpected results: first, they managed to do the job sooner and with fewer errors with GDI; second, they showed a preference for that style. This preference could arise from the lower quality of our DM application compared to the commercial ones. But this must have been the case for both of our interfaces, not only for the DM one. In any case, the professional users did say that our DM interface had a close resemblance to commercial ones. This feedback from professionals referred only to the way they had worked with GDI. They did not consider necessary to allude to the quality of our DM version.
One of the limitations of GDI is its unsuitability for creative users or applications with many concurrent functionalities. GDI is not appropriate for users who interact creatively with applications, in such a way that the own interaction notably inspires and influences the final result. For example, a graphics editor could not be suitable for its use with a guided interface. Other examples could be spreadsheet, word processor or powerful video editing applications.
On the other hand, the specificity of the goals in less creative tasks is of utmost importance when it comes to guiding the interaction. Booking a room in a hotel, choosing a seat for our theatre performance, or applying specific transformations to a batch of files, are some examples where GDI is definitely appropriate.
We do not try here to diminish the huge importance DM interfaces have been having for decades and will have in the future. What we show here is only that an integrated guiding system as GDI is generally a better option for users who do not want or cannot afford a learning curve, offering an alternative for designers and developers of interactive systems that have occasional users as their main target users.
References
Americans with Disabilities. Act of 1990 incorporating the changes made by the ADA Amendments Act of 2008. http://www.ada.gov/pubs/adastatute08.pdf. Accessed 01 Aug 2015
Annett, J., Duncan, K.D.: Task analysis and training design. Occup. Psychol. 41, 211–221 (1967)
Barnum, C.M.: Usability Testing Essentials: Ready, Set…Test!. Morgan Kaufmann Publishers, Burlington (2011)
Bollaert, J. Crafting a wizard. In IBM developer Works. http://www.ibm.com/developerworks/library/us-wizard. Accessed 30 May 2015
Buxton, B.: Multi-touch systems that I have known and loved. Microsoft Res. 56, 1–11 (2007)
Card, S., Moran, T., Newell, A.: Computer text-editing: an information processing analysis for a routine cognitive skill. Cogn. Psychol. 12, 32–74 (1980)
Card, S., Moran, T., Newell, A.: The Psychology of Human-Computer Interaction. Erlbaum, Hillsdale (1983)
Carroll, J.M., Thomas, J.C.: Metaphor and the cognitive representation of computing systems. IEEE Trans. Syst. Man Cybern. 12, 107–116 (1982)
Carrillo, A.L., Falgueras, J., Guevara, A.: A notation for goal driven interfaces specification. In: Navarro-Prieto, R., Vidal, J. (eds.) HCI Related Papers of Interacción, 337–344. Springer, Dordrecht (2006). https://doi.org/10.1007/1-4020-4205-1_28
Carrillo, A.L., Falgueras, J.: Goal driven interaction vs. direct manipulation, an empirical comparison. In: Proceedings of the XVI International Conference on Human Computer Interaction (Interacción 2015). ACM, New York, Article 24, 4 p. (2015)
Charland, A., Leroux, B.: Mobile application development: web vs native. Commun. ACM 54(5), 49–53 (2011)
Clarkson, J., Coleman, R. (eds.): Special Issue: Inclusive design. Appl. Ergon., part B, January 46, 233–324 (2015)
Coe, M.: Human Factors for Technical Communicators. Wiley, New York (1996)
Dix, A., Finlay, J., Abowd, G., Beale, R.: Human-Computer Interaction, 3rd edn. (Chapter 3). Pearson Education. Prentice Hall (2004)
Gong, J., Tarasewich, P.: Guidelines for handheld mobile device interface design. In: Proceedings of DSI 2004 Annual Meeting, pp. 3751–3756 (2004)
Gorakala, S.K., Usuelli, M.: Building a Recommendation System with R, pp. 15–18. Packt Publishing Ldt., Birmingham (2015)
Hollnagel, E., Woods, D.: Joint Cognitive Systems: Foundations of Cognitive Systems Engineering. CRC Press, Boca Raton (2005)
Hutchins, E.L., Hollan, J.D., Norman, D.A.: Direct manipulation interfaces. In: Norman, D.A., Draper, S.W. (eds.) User-Centered System Design, pp. 87–124. Erlbaum, Hillsdale (1986)
IKEA. http://kitchenplanner.ikea.com/US/UI/Pages/VPUI.htm. Accessed 06 Feb 2015
John, B.E., Kieras, D.E.: The GOMS family of analysis techniques: Tools for design and evaluation. Carnegie Mellon University School of Computer Science Technical Report No. CMU-CS-94-181. Also appears as the Human-Computer Interaction Institute Technical report No. CMU-HCII-94-106 (1994)
John, B.E., Kieras, D.E.: The GOMS family of user interface analysis techniques: Comparison and contrast. ACM Trans. Comput.-Hum. Interact. 3(4), 320–351 (1996)
John B.E., Kieras, D.E.: Using GOMS for user interface design and analysis: which technique? ACM Trans. Comput.-Hum. Interact. 3(4), 287–319 (1996b)
Johnson, P.: Task knowledge structures. In: Diaper, D. (ed.) Task Analysis in Human Computer Interaction. Ellis Horwood (1989)
Kieras, D.: A guide to GOMS model usability. Evaluation Using NGOMSL. In: Helander, M., Landauer, T., (eds.) The Handbook of Human-Computer Interaction, 2nd edn., pp 733–766. North-Holland, Amsterdam (1997)
Kieras, D.: Task analysis and the design of functionality. In: Tucher, A. (ed.) The computer Science and Engineering Handbook, pp. 1401–1423. CRC Inc., Boca Raton (1997)
Loranger, H.: Checklist for Planning Usability Studies. NN/g Nielsen Norman Group (2016). www.nngroup.com/articles/usability-test-checklist
Microsoft. Wizards. https://msdn.microsoft.com/en-us/library/windows/desktop/dn742503(v=vs.85).aspx. Accessed 28 May 2015
Moran, T.P.: An applied psychology of the user. Comput. Surv. 13, 1–11 (1981)
Mueller, J.P.: Accessibility for Everybody: Understanding the Section 508 Accessibility Requirements. Apress (2003)
Myers, B., Hudson, S.E., Pausch, R.: Past, present, and future of user interface software tools. ACM Trans. Comput.-Hum. Interact. (TOCHI) 7(1), 3–28 (2000)
Newell, A., Simon, H.: Human Problem Solving. Prentice-Hall, Upper Saddle River (1972)
Nielsen, J.: Usability Engineering. United States of America. Academic Press, San Diego (1993)
Nielsen, J., Budiu, R.: Mobile Usability. New Riders, Indianapolis (2012)
Nielsen, J.: Quantitative Studies: How Many Users to Test? NN/g Nielsen Norman Group. www.nngroup.com/articles/quantitative-studies-how-many-users/. Accessed 17 Nov 2015
Norman, D.A.: The Design of Everyday Things. Basic Books Inc., New York (2002)
Norman, D.A.: Natural user interfaces are not natural interactions. Interactions 17(3), 6–10 (2010)
Paternò, F.: ConcurTaskTrees: an engineered notation for task models. In: Diaper, D., Stanton, N. (eds.) The Handbook of Task Analysis for Human-Computer Interaction, Chapter 24, pp. 483–503. Lawrence Erlbaum Associates, Mahwah (2003)
Payne, S.J., Green, T.R.G.: Task action grammar: recent developments. In: Diaper, D. (ed.) Approaches to Task Analysis. Cambridge University Press (1990)
Savidis, A., Stephanidis, C.: Unified user interface design: designing universally accessible interactions. Interact. Comput. 16(2), 243–270 (2004)
Selker, T.: Touching the future. Commun. ACM 51(12), 14–16 (2008)
Sharples, M.: The design of personal mobile technologies for lifelong learning. Comput. Educ. 34(3), 177–193 (2000)
Shneiderman, B.: Direct manipulation: a step beyond programming languages. IEEE Comput. 16(8), 57–69 (1983)
Shneiderman, B., Plaisant, C., Cohen, M., Jacobs, S., Elmqvist, N., Diakopoulos, N.: Designing the User Interface: Strategies for Effective Human-Computer Interaction, 6th edn. Pearson, London (2016)
Sova, D.H., Nielsen, J.: How to Recruit Participants for Usability Studies. NN/g Nielsen Norman Group. www.nngroup.com/reports/how-to-recruit-participants-usability-studies. Accessed 28 Oct 2017
Tidwell, J.: Designing Interfaces: Patterns for Effective Interaction Design. O’Reilly Media Inc., Sebastopol (2011)
Turoff, M.: The design and evaluation of interactive systems. Section 1.4.3: “User Roles and Types”. http://web.njit.edu/~turoff/coursenotes/IS732/book/tablecon.htm. Accessed 23 May 2014
US Rehabilitation Act Amendments Section 508 (1998). http://www.section508.gov/. Accessed 01 Oct 2015
Wickham, D.P., Pupons, D., Mayhew, D.L., Stoll, T., Toley III, K.J., Rouiller, S.: Designing Effective Wizards: A Multidisciplinary Approach. Prentice Hall, Upper Saddle River (2002)
Wilcoxon, F.: Individual comparisons by ranking methods. Biometrics 1, 80–83 (1945)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 IFIP International Federation for Information Processing
About this paper

Cite this paper
Carrillo, A.L., Falgueras, J.A. (2019). GDI as an Alternative Guiding Interaction Style for Occasional Users. In: Lamas, D., Loizides, F., Nacke, L., Petrie, H., Winckler, M., Zaphiris, P. (eds) Human-Computer Interaction – INTERACT 2019. INTERACT 2019. Lecture Notes in Computer Science(), vol 11749. Springer, Cham. https://doi.org/10.1007/978-3-030-29390-1_5
Download citation
DOI: https://doi.org/10.1007/978-3-030-29390-1_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-29389-5
Online ISBN: 978-3-030-29390-1
eBook Packages: Computer ScienceComputer Science (R0)