
Abstract
A new method for discussing the relationship between CO2 emissions and bilateral FDI is proposed using grey systems theory. CO2 emissions and bilateral FDI, GDP are separately regarded as the input to, and output of, a grey system to establish a grey multivariable Verhulst model, GVM(1,N). To improve the prediction accuracy, the residual modification model are combined to the original GVM(1,N) model. Based on data relating to CO2 emissions and bilateral FDI, GDP in China from 2001 to 2014, empirical research shows that the bilateral FDI help reduce CO2 emissions, whereas the GDP results in CO2 emissions.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Since the introduction of China’s “Reform and Opening Up” policy, the Chinese government has make great effort to market-oriented reform and the “go out and bring in” strategy [1]. The amount of inward foreign direct investment (IFDI) grew explosively, and now China has become the second largest IFDI host country (behind America) all over the world. Meanwhile, with the rapid economic development, China is gradually transit from FDI recipient to FDI investor. The total amount of outward foreign direct investment (OFDI) is increasing continuously, especially since the proposal of the Belt and Road initiative. There is no doubt that bilateral FDI are the engine and a kind of catalyst for China in economic development. However, for those emerging economies like China, low standards of environmental regulations, cheap labor and energy costs are always used as incentives to attract IFDI. Along with the urgent need of economic development, IFDI brings a series of environmental problems to host country, such as CO2 emissions. On the other hand, China’s OFDI will also have an impact on home country’s CO2 emissions, whereas the results of the relationship between OFDI and CO2 are still confused. Since the CO2 emissions must be taken into account for sustainable development in China, this leads to an important issue related to how to accurately predict CO2 emissions considering bilateral FDI.
Many forecasting methods have been used to CO2 emissions forecasting, including time series analysis, spatial econometric, artificial intelligence [2,3,4,5]. Usually, the above-mentioned methods required a large number of samples to reduce the random interference caused by uncertain factors. Beyond this, econometric methods required the data conform to statistical assumptions, such as normal distribution, as well [6]. However, the data of CO2 emissions do not often satisfy the assumption, limiting the forecasting capabilities. Therefore, constructing a prediction model that works well with small samples, without making any statistical assumption is the main purpose of this paper. One of the grey prediction models, grey multivariable model GM(1,N), has drawn out attention to CO2 emissions forecasting. Compared to another widely used grey prediction GM(1,1) model, GM(1,N) model takes account the influence of N-1 relevant factors on the system to improve the prediction accuracy.
The GM(1,N) model is a first order grey multivariable prediction model, contained a system behavior variable and N-1 relevant variables. This model can analyze the effect of multiple relevant variables on the system behavior variable. To improve the simulation and prediction performance of the traditional GM(1,N) model, several improved versions have been proposed, such as a grey prediction model with convolution integral (GMC(1,N)) and an improved GM(1,N) models with optimal background values [7,8,9]. These existing grey GM(1,N) models and their improved models have linear features with regards structure [10]. However, most of the structure of a real system is non-linear. Therefore, using a linear structure of GM(1,N) model to describe or predict the behavior of a non-linear system can cause unacceptable modeling error [10].
A traditional Verhulst model is mainly used to describe the process with saturation, which is commonly used in population prediction, biological growth forecast, product economic life prediction and so on [11]. It grows slowly in the initial stage, then the growth rate increase quickly, finally, the growth changes from the high-speed to the low-speed until to the cessation of growth, so the data are being the form of S-type [12]. Grey prediction model is established on the randomicity of accumulated generating weakened sequence and the rules of system changes. The model is constructed on the basis of a qualitative analysis, so it generally has higher simulation accuracy and prediction precision, gets preferable results in application. The grey Verhulst model, GVM(1,1), is modeling on base of the raw data from accumulating generation, which expands the available range of the traditional Verhulst model to the approximate single-peak type of data. Therefore, GVM(1,1) model has been widely applied in different fields recently [13,14,15].
Referring to GVM(1,1) model, this paper proposes a grey multivariable Verhulst model, GVM(1,N), with a view to providing an effective quantitative method to forecast Chinese CO2 emissions considering the non-linear effect of bilateral FDI. In addition, the residual modification model built on residual obtained from the GVM(1,N) model could improve the prediction accuracy. The proposed improved prediction model is a two-stage procedure; the first stage uses the GVM(1,N) model to generate the predicted value, and the second stage use the traditional GM(1,1) model and Fourier series to modify the residual error, respectively. To verify the validity of the proposed prediction model, the hybrid prediction model is compared with original GVM(1,N) model in terms of prediction performance using mean absolute percentage error (MAPE).
The rest of this paper is organized as follows: the Sect. 2 is a review of the literature related to this research. Section 3 introduce the GVM(1,N) model and the proposed grey residual modification model combining GVM(1,N) with residual modification model using GM(1,1) and a Fourier series. The empirical analysis of CO2 emissions in China is presented in Sect. 4. Finally, Sect. 5 discusses the results and presents conclusion.
2 Literature Review
2.1 Forecasting China’s CO2 Emissions
As a developing country, Chinese energy consumption, especially fossil energy consumption is constantly growing with the acceleration industrialization and urbanization, hence, the future changing trend in CO2emissions is a concern: to that end, many scholars have forecast Chinese CO2 emissions from different perspectives.
For the prediction of Chinese future CO2 emissions, the most widely used model is the IPTA, which is also known as the Kaya model. Du, Wang [16] improved the IPTA model and used it to predict and analyze China’s per capita carbon emissions in three assumed scenarios up to 2050.
In addition, many scholars have used other methods to forecast Chinese carbon emissions. Zhou, Fridley [17] evaluated the efficiency of Chinese energy consumption and thought that Chinese carbon emissions would reach a peak in 2030. Gambhir, Schulz [18] used the hybrid modeling method to forecast Chinese carbon emissions in 2050. Liu, Mao [19] forecast the gross carbon dioxide emissions and their intensity in China from 2013 to 2020 using a system dynamics simulation.
From the above forecasting results, we know that the traditional EKC method and other forecasting methods have been widely used. As economic growth has a prominent non-linear impact on carbon emissions, if the prediction of carbon emissions were based on the non-linear relationship between carbon emissions and economic growth, it would not only have theoretical support but also could result in more direct policy suggestions for economic growth and environmental quality. In fact, few scholars make such an attempt at present.
2.2 Grey Forecasting Method
To solve the problem of analysis, modeling, prediction and control of uncertain system, Deng [20] proposed the use of a grey system. As this theory had obtained ideal effects of application in practice, the grey theory has been recognized by many scholars at home and abroad in recent years, and its application fields have been extended from control science to many fields such as industry, agriculture, energy, economy, management, and so on [21, 22].
Deng [20] first proposed a multivariable grey model GM(1,N), and it was used in the coordination and development of the planning of the economy, technology, and society of a city in Hubei Province. The GM(1,N) is a first-order multivariable grey model, the model contains a system behavior variable and N-1 influencing factor variables: this model can analyze the effect of multiple influencing factor variables on the behavior of the system. When the changing trends of influencing factor variables were known, we can also predict the behavior variables of the system. Liu and Lin (2006) give approximate whitening time response functions of the GM(1,N). Tien [23] showed that the approximate whitening time response function of the GM(1,N) could lead to unacceptable experimental error at times. The time response function of the GM(1,N) is not always precise and the accuracy of the model is not high. Tien [24] added a control parameter into the grey differential equation of the traditional GM(1,N), meanwhile, used the convolution integral technique to solve the whitening differential equation: the improved model was named GMC(1,N). Hsu [25] used a genetic algorithm to optimize the interpolation coefficient of the background value of the GM(1,N), and the optimization model was applied to predict the output value of the integrated circuit industry in Taiwan, to better forecasting effect. Pei, Chen [8] applied the GA-based GM(1,N) model to forecast the input-output system of Chinese high-tech industry.
3 Methodologies
In this subsection, the algorithm of the grey multivariable Verhulst model is introduced and the inherent definitions of the main parameters are briefly analyzed to gain a better understanding of the relationship between the system behavior variable and the relevant variables. Then, the improved prediction model is proposed based on combining grey multivariable Verhulst model with residual modification model, and its modeling procedure is demonstrated stepwise.
3.1 Grey Multivariable Verhulst Model
Taking into account the fact that the existing grey multivariable model cannot be used to describe the non-linear relationship between CO2 emission and bilateral FDI, this paper will introduce a Verhulst model into the most widely used grey multivariable model GM(1,N) to describe the non-linear effect that the relevant variables exert on the system behavior variable, and then we will construct the grey multivariable Verhulst model (GVM(1,N)).
Assume that \( X_{1}^{(0)} = (x_{1}^{(0)} (1),\;x_{1}^{(0)} (2), \ldots ,\;x_{1}^{(0)} (n)) \) is original data of a system characteristic sequence (or dependent variable sequence), and \( X_{i}^{(0)} = (x_{i}^{(0)} (1),\;x_{i}^{(0)} (2), \ldots ,\;x_{i}^{(0)} (n)) \), where \( i = 2,\;3, \ldots ,\;N \) are the relevant variable sequences (or independent variable sequences), which have a certain relationship with sequence \( X_{1}^{(0)} \).
Then the new sequence \( x_{i}^{(1)} = (x_{i}^{(1)} (1),\;x_{i}^{(1)} (2), \ldots ,\;x_{i}^{(1)} (n)) \) can be generated from \( X_{i}^{(0)} \) by the first order accumulated generating operation (1-AGO) as follows:
The background value, \( z_{1}^{(1)} (k) \), is the adjacent neighbor mean generated sequence of \( X_{1}^{(1)} \).
Then,
is called a grey multivariable Verhulst model, abbreviated as GVM(1,N), where \( a \) is called the development coefficient of the system, \( b_{i} \left( {x_{i}^{(1)} (k)} \right)^{2} \) the driving term, and \( b_{i} \) the driving coefficient. The corresponding whitening differential equation is written as follows:
In turn, \( a \) and \( b_{i} \) can be obtained by using the original least squares (OLS) method:
and
The approximate time response sequence of the GVM(1,N) model is given by
Finally, using the inverse accumulated generating operation (IAGO), the predicted value \( x_{k}^{(0)} \) is
Note that \( \hat{x}_{1}^{(1)} (1) = x_{1}^{(0)} (1) \) holds.
3.2 The Improved Grey Multivariable Verhulst Model
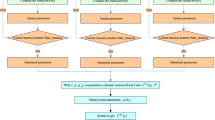
The improved grey multivariable Verhulst model uses GVM(1,N) model to generate the predicted value, after which the GM(1,1) model and the Fourier series are used to correct the residuals generated by GM(1,N), respectively, abbreviated as RGVM(1,N) and FGVM(1,N). The construction of the GMGMF can be described as follows:
Step 1: Establish a GVM(1,N) model for \( x_{i}^{(0)} \) and generate the predicted value of GVM(1,N), \( \hat{x}_{i}^{(0)} \).
Step 2: Generate the sequence of residual values \( \varepsilon_{k}^{(0)} = (\varepsilon_{2}^{(0)} ,\;\varepsilon_{3}^{(0)} , \ldots ,\;\varepsilon_{n}^{(0)} ) \) based on the following equation.
Step 3: Generating the predicted residual of \( \hat{\varepsilon }_{k}^{(0)} \) by the residual model established as GM(1,1) model (see Appendix A) and Fourier series (see Appendix B)for \( \varepsilon_{k}^{(0)} \), respectively.
Step 4: The predicted value of RGVM(1,N), and FGVM(1,N), \( x_{1}^{{'\text{(0)}}} (k) \), can be calculated as.
Figure 1 shows a procedure of the proposed residual modification model.

Procedure of Improved GVM(1, N) Model
3.3 Evaluating Prediction Accuracy
In order to compare the forecasting ability of the proposed models against different models, mean absolute percentage error (MAPE) was employed to measure prediction performance. MAPE with respect to \( x_{k}^{(0)} \) is
Lewis [26] proposed MAPE criteria for evaluating a forecasting model, where MAPE ≤ 10, 10 < MAPE ≤ 20, 20 < MAPE ≤ 50, and MAPE > 50 correspond to high, good, reasonable, and weak forecasting models, respectively.
4 Empirical Study
4.1 Variables and Data Collection
In order to predict CO2 emission in China considering the bilateral FDI using proposed RGVM(1,N) model, China’s IFDI and OFDI are taken as the relevant variables. Additionally, in accordance with previous studies, GDP is selected as the other relevant variables as well [1]. Table 1 shows the proxies used for the relevant variables and the unit.
All data collected from World Bank Development Indicators between 2001 and 2014 are shown in Table 2. The real data from 2001 to 2012 were reserved for model-fitting, and data 2013–2014 were reserved for the ex post test.
4.2 Empirical Results
Following the calculation procedures, the estimated values of the development and driving coefficients, which can be expressed as a = −0.28, b2 = 2.47 × 10−8, b3 = −1.76 × 10−5, and b4 = −1.51 × 10−4. As explained in Ding, Dang [27], the driving coefficient bi has its own actual meaning. Because b2 > 0 > b4 > b3, it can be inferred that the GDP contributed significantly to the increase CO2 in China. Parameter b3 and b4 indicate that increasing the bilateral FDI is helpful to reduce the CO2 emissions. To demonstrate the efficacy and practicability of the proposed model, original GVM(1,N), RGVM(1,N), and FGVM(1,N) are used to comparison, and the predicted results and MAPE for CO2 emissions in China are summarized in Table 3.
From Table 3, it can be found that the MAPE of the GVM(1,N), RGVM(1,N), and FGVM(1,N) models for model-fitting were 18.07%, 21.82%, and 4.09%, respectively. For ex post testing, the MAPE were 10.03%, 3.21%, and 23.05%, respectively. Obviously, both proposed RGVM(1,N) and FGVM(1,N) model are superior to the original GVM(1,N) model for model-fitting, then RGVM(1,N) model is superior to the GVM(1,N) and FGFM(1,N) models for ex post testing.
5 Discussions and Conclusion
This paper explores the relationship between CO2 emissions in China and GDP, IFDI, and OFDI based on the proposed grey multivariable Verhulst model incorporating with residual modification model using GM(1,1) and Fourier series.
The comparison of prediction results by different models reveals that the proposed RGVM(1,N) and FGVM(1,N) models perform well on China’s CO2 emissions prediction. The applicability of improved GVM(1,N) model has been proved. For the relationship between CO2 emissions and GDP, IFDI, and OFDI, the control and driving coefficients indicate that the rapid economic growth would result in larger CO2 emissions, whereas enhancing environmental protection technology via the spillover effect of IFDI, and transferring the highly polluting industries via OFDI could reduce CO2 emissions.
In summary, the improved grey multivariable Verhulst model is an effective and practical model for analyzing and predicting CO2 emissions in Mainland China. The limitation of the new proposed model deserves further attention and research in the future, such as the big error could appear in the data fluctuation. What is more, in regard to the residual modification model, our future research will concentrate on some other approaches, such as the Markov-chain, and neural network.
References
Zheng, J.J., Sheng, P.F.: The impact of foreign direct investment (FDI) on the environment: market perspectives and evidence from China. Economies, 5(8) (2017). https://doi.org/10.3390/economies5010008
Sun, W., Wang, C.F., Zhang, C.C.: Factor analysis and forecasting of CO2 emission in Hebei, using extreme learning machine based on particle swarm optimization. J. Clean. Prod. 16, 1095–1101 (2017)
Garcia-Martos, C., Rodiguez, J., Sanchez, M.J.: Modeling and forecasting fossil fuels, CO2 and electricity prices and their volatities. Appl. Energy 101, 363–375 (2013)
Chen, T.: Analyzing and forecasting the global CO2 concentration: a collaborative fuzzy-neural angent network approach. J. Appl. Res. Technol. 13(3), 364–373 (2015)
Xu, H.F., Li, Y., Huang, H.: Spatial research on the effect of financial structure on CO2 emission. Energy Procedia 118, 179–183 (2017)
Feng, S.J., et al.: Forecasting the energy consumption of China by the grey prediction model. Energy Source Part B: Econ. Plan. Policy 7, 376–389 (2012)
Tien, T.L.: The indirect measurement of tensile strength of material by the grey prediction model GMC (1, n). Meas. Sci. Technol. 16(6), 1322–1328 (2005)
Pei, L.L., et al.: The improved GM (1, N) models with optimal background values a case study of Chinese high-tech industry. J. Grey Syst. 27(3), 223–233 (2015)
Wang, Z.X., Pei, L.L.: An optimized grey dynamic model for forecasting the output of high-tech industry in China. Math. Probl. Eng. 2014, 1–7 (2014). https://doi.org/10.1155/2014/586284
Wang, Z.X., Ye, D.J.: Forecasting Chinese carbon emissions from fossil energy consumption using non-linear grey multivariable models. J. Clean. Prod. 142, 600–612 (2017)
Liu, S.F., Lin, Y.: Grey Systems: Theory and Applications. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-16158-2
Wang, Z.X., Dang, Y.G., Liu, S.F.: Unbiased grey verhulst model and its application. Syst. Eng.-Theory Pract. 29(10), 138–144 (2009)
Shaikh, F., et al.: Forecasting China’s natural gas demand based on optimized nonlinear grey models. Energy 140, 941–951 (2017)
Wang, X.Q., et al.: Grey system theory based prediction for topic trend on Internet. Eng. Appl. Artif. Intell. 29, 191–200 (2014)
Evans, M.: An alternative approach to estimating the parameters of a generalized Grey Verhulst model: an application to steel intensity of use in the UK. Expert Syst. Appl. 41(4), 1236–1244 (2014)
Du, Q., Wang, N., Che, L.: Forecasting China’s per capita carbon emissions under a new three-step economic development strategy. J. Resour. Ecol. 6(5), 318–323 (2015)
Zhou, N., Fridley, D., Khanna, N.Z.: China’s energy and emissions outlook to 2050: perspectives from bottom-up energy end-use model. Energy Policy 53, 51–62 (2013)
Gambhir, A., et al.: A hybrid modeling approach to develop scenarios for China’s carbon dioxide emissions to 2050. Energy Policy 59, 614–632 (2013)
Liu, X., et al.: How might China achieve its 2020 emissions target? A scenario analysis of energy consumption and CO2 emissions using the system dynamics model. J. Clean. Prod. 103, 401–410 (2015)
Deng, J.L.: Grey Theory. Huazhong University of Science & Technology Press, Wuhan (2002)
Liu, S.F., Lin, Y.: Grey Information: Theory and Practical Applications. Springer, London, UK (2006)
Wang, J., et al.: A historic review of management science research in China. Omega 36, 919–932 (2008)
Tien, T.L.: A research on the grey prediction model GM (1, n). Appl. Math. Comput. 218(9), 4903–4916 (2012)
Tien, T.L.: The indirect measurement of tensile strength for a higher temperature by the new model IGDMC (1, n). Measurement 41(6), 662–675 (2008)
Hsu, L.C.: Forecasting the output of integrated circuit industry using genetic algorithm based multivariable grey optimization models. Expert Syst. Appl. 36, 7898–7903 (2009)
Lewis, C.: Industrial and Business Forecasting Methods. Butterworth Scientific, London (1982)
Ding, S., et al.: Forecasting Chinese CO2 emissions from fuel combustion using a novel grey multivariable model. Expert Syst. Appl. 162, 1527–1538 (2017)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendices
Appendix A. Residual Modification Model Using GM(1,1) Model
The computational steps for constructing the residual modification using the GM(1,1) model are as follows:
Step 1: Establish a GM(1,N) model for \( X_{1}^{(0)} \). Then, generating the sequence of residual values, \( \varepsilon_{k}^{(0)} = (\varepsilon_{2}^{(0)} ,\;\varepsilon_{3}^{(0)} , \ldots ,\;\varepsilon_{n}^{(0)} ) \).
Step 2: Perform the accumulated generating operation (AGO). Identify the potential regularity hidden in \( \varepsilon_{k}^{(0)} \) using AGO to generate a new sequence, \( \varepsilon_{k}^{(1)} = (\varepsilon_{2}^{(1)} ,\;\varepsilon_{3}^{(1)} , \ldots ,\;\varepsilon_{n}^{(1)} ) \).
and \( \varepsilon_{2}^{(1)} ,\;\varepsilon_{3}^{(1)} , \ldots ,\;x_{n}^{(1)} \) can be then approximated by a first-order differential equation.
where \( a_{\varepsilon } \) and \( b_{\varepsilon } \) are the developing coefficient and control variable, respectively. The predicted value, \( \hat{\varepsilon }_{k}^{(1)} \), for \( \varepsilon_{k}^{(1)} \) can be obtained by solving the differential equation with initial condition \( \varepsilon_{2}^{(1)} = \varepsilon_{2}^{(0)} \):
Step 3: Determine the developing coefficient and control variable.\( a_{\varepsilon } \) and \( b_{\varepsilon } \) can be obtained using the ordinary least squares methods (OLS):
where
where \( z_{k}^{(1)} \) is the background value. \( \alpha \) is usually specified as 0.5.
Step 4: Perform the inverse accumulated generating operating (IAGO). Using the IAGO, the predicted value or \( \hat{\varepsilon }_{k}^{(0)} \) is
Therefore,
and note that \( \hat{\varepsilon }_{2}^{(1)} = \varepsilon_{2}^{(0)} \) holds.
Appendix B. Residual Modification Model Using Fourier Series
The computational steps for constructing the residual modification using a Fourier series are as follows:
Step 1: Generate the sequence of residual values, \( \varepsilon_{k}^{(0)} = (\varepsilon_{2}^{(0)} ,\;\varepsilon_{3}^{(0)} , \ldots ,\;\varepsilon_{n}^{(0)} ) \).
Expressed as a Fourier series, \( \varepsilon_{k}^{(0)} \) is rewritten as:
where \( F = (n - 1)/2 - 1 \) is called the minimum deployment frequency of the Fourier series and takes on only integer values. Therefore, the residual series can be rewritten as:
where
and
The parameters \( a_{0} ,\;a_{1} ,\;b_{1} ,\;a_{2} ,\;b_{2} , \ldots ,\;a_{F} ,\;b_{F} \) are obtained using the ordinary least-squares method, resulting in the following equation:
Once the parameters have been calculated, the predicted residual \( \hat{\varepsilon }_{k}^{(0)} \) is then easily obtained based on the following expression:
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Hu, YC., Jiang, H., Jiang, P., Kong, P. (2019). An Improved Grey Multivariable Verhulst Model for Predicting CO2 Emissions in China. In: Nah, FH., Siau, K. (eds) HCI in Business, Government and Organizations. Information Systems and Analytics. HCII 2019. Lecture Notes in Computer Science(), vol 11589. Springer, Cham. https://doi.org/10.1007/978-3-030-22338-0_29
Download citation
DOI: https://doi.org/10.1007/978-3-030-22338-0_29
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-22337-3
Online ISBN: 978-3-030-22338-0
eBook Packages: Computer ScienceComputer Science (R0)