
Abstract
Diffusion magnetic resonance imaging (diffusion MRI) is a non-invasive microstructure assessment technique. Scalar measures, such as FA (fractional anisotropy) and MD (mean diffusivity), quantifying micro-structural tissue properties can be obtained using diffusion models and data processing pipelines. However, it is costly and time consuming to collect high quality diffusion data. Here, we therefore demonstrate how Generative Adversarial Networks (GANs) can be used to generate synthetic diffusion scalar measures from structural T1-weighted images in a single optimized step. Specifically, we train the popular CycleGAN model to learn to map a T1 image to FA or MD, and vice versa. As an application, we show that synthetic FA images can be used as a target for non-linear registration, to correct for geometric distortions common in diffusion MRI.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Diffusion MRI is a non-invasive technique used for studying brain tissue microstructures. Diffusion-derived scalar maps provide rich information about microstructural characterization, but there are two major bottlenecks in obtaining these scalar maps. First, it is expensive and time consuming to acquire high quality diffusion data. Second, the accuracy of the diffusion-derived scalar maps relies on elaborate diffusion data processing pipelines, including preprocessing (head motion, eddy current distortion and susceptibility-induced distortion corrections), diffusion model fitting and diffusion scalar calculation. Small errors occurring at any of these steps can contribute to the bias of the diffusion-derived scalars. For some advanced diffusion models e.g. mean apparent propagator (MAP) MRI [10], processing of a single slice of the brain can take hours to finish.
Generative Adversarial Networks (GANs) is one of the most important ideas in machine learning in the last 20 years [6]. GANs have already been widely used for medical image processing applications, such as denoising, reconstruction, segmentation, detection, classification and image synthesis. However, GANs for medical image translation are still rather unexplored, especially for cross-modality translation of MR images [7].
Implementations of CycleGAN and unsupervised image-to-image translation (UNIT) for 2D T1-T2 translation were reported in [13], and results showed that visually realistic synthetic T1 and T2 images can be generated from the other modality, proven via a perceptual study. In [2] a conditional GAN was proposed to do the translation between T1 and T2 images, in which a probabilistic GAN (PGAN) and a CycleGAN were trained for paired and unpaired source-target images, respectively. The proposed GAN demonstrated visually and quantitatively accurate translations for both healthy subjects and glioma patients. A patch-based conditional GAN [9] was proposed to generate magnetic resonance angiography (MRA) images from T1 and T2 images jointly. Steerable filter responses were incorporated in the loss function to extract directional features of the vessel structure. MR image translation based on downsampled images was investigated in [3], to reduce scan time. Three different types of input were fed to the GANs: downsampled target images, downsampled source images, and downsampled target and source images jointly. It was demonstrated that the GAN with the combination of downsampled target and source images as the input outperformed its two competitors in reconstructing higher resolution images, which resulted in a reduction of the scan time up to a factor of 50. A 3D conditional GAN [15] was applied to synthesize FLAIR images from T1, and the synthetic FLAIR images improved brain tumor segmentation, compared with using only T1 images.
In this work, we explored the possibility to generate diffusion scalar maps from structural MR images. We propose a new application of CycleGAN [16]; to translate T1 images to diffusion-derived scalar maps. To the best of our knowledge, this is the first study of GAN-based MR image translation between structural space and diffusion space. Both qualitative and quantitative evaluations of generated images were carried out in order to assess effectiveness of the method. We also show how synthetic FA images can be used as a target for non-linear registration, to correct for geometric distortions common in diffusion MRI.
2 Theory
2.1 Diffusion Tensor Model
In a diffusion experiment, the diffusion-weighted signal \(S_i\) of the ith measurement for one voxel is modeled by
where \(S_0\) is the signal without diffusion weighting, b is the diffusion weighting factor, \(\mathbf {D}=\begin{bmatrix} D_{xx}&D_{xy}&D_{xz} \\ D_{xy}&D_{yy}&D_{yz} \\ D_{xz}&D_{yz}&D_{zz} \end{bmatrix}\) is the diffusion tensor in the form of a \(3 \times 3\) positive definite matrix, \(\mathbf {g}_i\) is a \(3 \times 1\) unit vector of the gradient direction, and T is the total number of measurements. Mean diffusivity (MD) and fractional anisotropy (FA) can be calculated from the estimated tensor, according to
where \(\lambda _1\), \(\lambda _2\) and \(\lambda _3\) are the three eigenvalues of the diffusion tensor \(\mathbf {D}\). In our case weighted least squares was used to estimate the diffusion tensor.
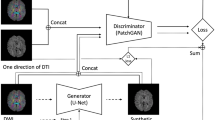
2.2 CycleGAN
A CycleGAN [16] can be trained using two unpaired groups of images, to translate images between domain A and domain B. A CycleGAN consists of four main components, two generators (\(G_{A2B}\) and \(G_{B2A}\)) and two discriminators (\(D_A\) and \(D_B\)). The two generators synthesize domain A/B images based on domain B/A. The two discriminators are making the judgement if the input images belong to domain A/B. The translation between the two image domains is guaranteed by
where \(I_A\) and \(I_B\) are two images of domain A and B. The loss function contains two terms: adversarial loss and cycle loss, and can be written as [16]
The adversarial loss encourages the discriminators to approve the images of the corresponding groups, and reject the images that are generated by the corresponding generators. The generators are also encouraged to generate images that can fool the corresponding discriminators. The cycle loss guarantees that the image can be reconstructed from the other domain, as stated in Eq. 5. The total loss is the sum of the adversarial loss and the cycle loss, i.e.
2.3 Similarity Measure
The widely used structural similarity (SSIM) measure [4, 14] was used to quantify the accuracy of the image translations. SSIM can measure local structural similarity between two images. The SSIM quantifies the degree of similarity of two images based on the impact of three characteristics: luminance, contrast and structure. The SSIM of pixel (x, y) in images A and B can be calculated as [12]
where \(w_A\) and \(w_B\) are local neighborhoods centered at (x, y) in images A and B, \(\mu _{w_A}\) and \(\mu _{w_B}\) are the local means, \(\sigma _{w_A}\) and \(\sigma _{w_B}\) are the local standard deviations, \(\sigma _{w_Aw_B}\) is the covariance, \(c_1\) and \(c_2\) are two variables to stabilize the division. The mean SSIM (\(MSSIM=SSIM/N_{voxel}\)) within the brain area can be used as a global measure of the similarity between the synthetic image and the ground truth.
3 Data
We used diffusion and T1 images from the Human Connectome Project (HCP)Footnote 1 [5, 11] for 1065 healthy subjects. The data were collected using a customized Siemens 3T Connectome scanner. The diffusion data were acquired with 3 different b-values (1000, 2000, and 3000 s/mm\(^2\)) and have already been pre-processed for gradient nonlinearity correction, motion correction and eddy current correction. The diffusion data consist of 18 non-diffusion weighted volumes (b = 0) and 90 volumes for each b-value, which yields 288 volumes of \(145 \times 174 \times 145\) voxels with an 1.25 mm isotropic voxel size. The T1 data was acquired with a \(320 \times 320\) matrix size and \(0.7 \times 0.7 \times 0.7\) mm isotropic voxel size, and then downsampled by us to the same resolution as the diffusion data.
4 Methods
Diffusion tensor fitting and MAP-MRI fitting were implemented using C++ and the code is available on GithubFootnote 2. We used a Keras implementation of 2D CycleGAN, originating from the work by [13], which is also available on GithubFootnote 3. The statistics analysis was performed in MATLAB (R2018a, The MathWorks, Inc., Natick, Massachusetts, United States).
We followed the network architecture design given in the original CyceGAN paper [16]. We used 2 feature extraction convolutional layers, 9 residual blocks and 3 deconvolutional layers for the generators. For the discriminators we used 4 feature extraction convolutional layers and a final layer to produce a one-dimensional output. We trained the network with a learning rate of 0.0004. We kept the same learning rate for the first half of the training, and linearly decayed the learning rate to zero over the second half. A total of 1000 subjects were used for training, and 65 subjects were used for testing. An Nvidia Titan X Pascal graphics card was used to train the network. The experiment protocols and training times are summarized in Table 1.
5 Results
5.1 Synthetic FA and MD
Figure 1(a) shows the qualitative results of T1-to-FA image translation for 4 test subjects. The results show a good match between the synthetic FA images and their ground truth, for both texture of white matter tracts and global content. However, when compared with the ground truth, it is observed that the synthetic FA images have a reduced level of details on white matter tracts. The difference image shows the absolute error between synthetic and real FA images. Results of T1-to-MD image translation are shown in Fig. 1(b). The synthetic MD images demonstrate great visual similarity to the ground truth. The CSF region and its boundaries are accurately synthesized.

T1-to-FA/MD image translation results for 4 subjects. First row: True T1 images, second row: true FA images, third row: synthetic FA images, fourth row: Difference of true and synthetic FA.

MSSIM results of FA and MD for Experiment 1, 2 and 3. Experiment 1: training on 1000 subjects, 1 slice per subject, and test on 65 subjects, 1 slice per subject. The mean MSSIM of synthetic FA and MD across subjects are 0.839 and 0.937, respectively. Experiment 2: training on 1000 subjects, 1 slice per subject, and test on 65 subjects, 17 slices per subject. The mean MSSIM of synthetic FA and MD across slices are 0.818 and 0.940, respectively. Experiment 3: training on 1000 subjects, 17 slices per subject, and test on 65 subjects, 17 slices per subject. The mean MSSIM of synthetic FA and MD across slices are 0.861 and 0.948, respectively. Plots show that synthetic MD images demonstrate higher accuracy compared to synthetic FA, and that using a higher number of training slices mostly helps FA synthesis.
Figure 2(a) shows the MSSIM of synthetic FA and MD images for the 65 test subjects. MSSIM values showed high consistency among the different test subjects. The mean±std intervals of the MSSIM are \(0.839 \pm 0.014\) and \(0.937 \pm 0.008\) for synthetic FA and MD images, respectively. The MSSIM results for synthetic MD are higher compared to synthetic FA. This may be partly due to that FA images contain richer structure information, thus it is more difficult to synthesize (since FA is more non-linear than MD). Figure 2(b) and (c) show the MSSIM of synthetic FA and MD images for the 17 slices. It can been that the MSSIM result is sensitive to the slice position, and that a higher number of training slices leads to higher MSSIM results for the synthetic FA and MD maps.

FA LR: FA map from data with left to right phase encoding direction. FA RL: FA map from data with right to left phase encoding direction. FA synthetic: FA map from CycleGAN. FA LR registered: FA LR non-linearly registered to synthetic FA. FA topup: FA map from EPI distortion corrected data (seen as gold standard). The benefit of using non-linear registration for distortion correction, instead of topup, is that the scan time is reduced by a factor 2.
5.2 Non-linear Registration for Distortion Correction
EPI distortions can be corrected by the FSL function topup, for data acquired with at least two phase encoding directions. However, it is hard to correct for EPI distortions for data acquired with a single phase encoding direction. A potential approach would be to generate a synthetic FA map from the undistorted T1 image, and then (non-linearly) register the distorted FA map to the undistorted synthetic one. This transform can then be applied to all other diffusion scalar maps. The FA map from EPI distortion corrected data (using topup) can be regarded as the gold standard. We used FNIRT in FSL to perform the non-linear registration. Figure 3 shows various FA maps for one test subject. The FA map from the proposed approach provides a result which is very similar to the gold standard. The benefit of our approach is that the scan time can be reduced a factor 2, by acquiring data using a single phase encoding direction. It is of course theoretically possible to register the distorted FA image directly to the undistorted T1 image, but non-linear registration of images with different intensity can be rather challenging.
6 Discussion
Translation between structural and diffusion images has been shown using CycleGAN. The synthetic FA and MD images are remarkably similar to their ground truth. Quantitative evaluation using MSSIM of 65 test subjects shows that the trained CycleGAN works well for all test subjects, and that training using a larger number of slices improves the results.
While the synthetic FA images appear realistic, the training of the GAN will depend on the training data used. For example, if the GAN is trained using data from healthy controls it is likely that the GAN will be biased for brain tumor patients, and for example remove existing tumors [1].
Future research may focus on creating other diffusion-derived scalar maps from more advanced diffusion models, such as mean apparent propagator (MAP) MRI. In this work, we have only used 2D CycleGAN, but it has been reported that 3D GANs using spatial information [8] across slices yield better mappings between two domains (at the cost of a higher memory consumption and a higher computational cost). A comparison study of image translation using 2D and 3D GANs is thus worth looking into.
Notes
- 1.
Data collection and sharing for this project was provided by the Human Connectome Project (U01-MH93765) (HCP; Principal Investigators: Bruce Rosen, M.D., Ph.D., Arthur W. Toga, Ph.D., Van J.Weeden, MD). HCP funding was provided by the National Institute of Dental and Craniofacial Research (NIDCR), the National Institute of Mental Health (NIMH), and the National Institute of Neurological Disorders and Stroke (NINDS). HCP data are disseminated by the Laboratory of Neuro Imaging at the University of Southern California.
- 2.
- 3.
References
Cohen, J.P., Luck, M., Honari, S.: Distribution matching losses can hallucinate features in medical image translation. arXiv preprint arXiv:1805.08841v3 (2018)
Dar, S.U.H., Yurt, M., Karacan, L., Erdem, A., Erdem, E., Çukur, T.: Image synthesis in multi-contrast MRI with conditional generative adversarial networks. arXiv preprint arXiv:1802.01221 (2018)
Dar, S.U.H., Yurt, M., Shahdloo, M., Ildız, M.E., Çukur, T.: Synergistic reconstruction and synthesis via generative adversarial networks for accelerated multi-contrast MRI. arXiv preprint arXiv:1805.10704 (2018)
Emami, H., Dong, M., Nejad-Davarani, S.P., Glide-Hurst, C.: Generating synthetic CTs from magnetic resonance images using generative adversarial networks. Med. Phys. 45, 3627–3636 (2018)
Glasser, M.F., et al.: The minimal preprocessing pipelines for the human connectome project. Neuroimage 80, 105–124 (2013)
Goodfellow, I., et al.: Generative adversarial nets. In: Advances in Neural Information Processing Systems, pp. 2672–2680 (2014)
Kazeminia, S., et al.: GANs for medical image analysis. arXiv preprint arXiv:1809.06222 (2018)
Nie, D., et al.: Medical image synthesis with context-aware generative adversarial networks. In: International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 417–425 (2017)
Olut, S., Sahin, Y.H., Demir, U., Unal, G.: Generative adversarial training for MRA image synthesis using multi-contrast MRI. In: International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 147–154 (2018)
Özarslan, E., et al.: Mean apparent propagator (MAP) MRI: a novel diffusion imaging method for mapping tissue microstructure. NeuroImage 78, 16–32 (2013)
Van Essen, D.C., et al.: The WU-Minn human connectome project: an overview. Neuroimage 80, 62–79 (2013)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 600–612 (2004)
Welander, P., Karlsson, S., Eklund, A.: Generative adversarial networks for image-to-image translation on multi-contrast MR images-a comparison of CycleGAN and UNIT. arXiv preprint arXiv:1806.07777 (2018)
Wolterink, J.M., Dinkla, A.M., Savenije, M.H., Seevinck, P.R., van den Berg, C.A., Išgum, I.: Deep MR to CT synthesis using unpaired data. In: International Workshop on Simulation and Synthesis in Medical Imaging, pp. 14–23 (2017)
Yu, B., Zhou, L., Wang, L., Fripp, J., Bourgeat, P.: 3D cGAN based cross-modality MR image synthesis for brain tumor segmentation. In: IEEE 15th International Symposium on Biomedical Imaging, pp. 626–630 (2018)
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. arXiv preprint arXiv:1703.10593v5 (2017)
Acknowledgements
This study was supported by Swedish research council grants 2015-05356 and 2017-04889. Funding was also provided by the Center for Industrial Information Technology (CENIIT) at Linköping University, the Knut and Alice Wallenberg foundation project “Seeing organ function”, Analytic Imaging Diagnostics Arena (AIDA) and the ITEA3/VINNOVA funded project “Intelligence based iMprovement of Personalized treatment And Clinical workflow supporT” (IMPACT). The Nvidia Corporation, who donated the Nvidia Titan X Pascal graphics card used to train the GANs, is also acknowledged.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Gu, X., Knutsson, H., Nilsson, M., Eklund, A. (2019). Generating Diffusion MRI Scalar Maps from T1 Weighted Images Using Generative Adversarial Networks. In: Felsberg, M., Forssén, PE., Sintorn, IM., Unger, J. (eds) Image Analysis. SCIA 2019. Lecture Notes in Computer Science(), vol 11482. Springer, Cham. https://doi.org/10.1007/978-3-030-20205-7_40
Download citation
DOI: https://doi.org/10.1007/978-3-030-20205-7_40
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-20204-0
Online ISBN: 978-3-030-20205-7
eBook Packages: Computer ScienceComputer Science (R0)
