
Abstract
This paper examines the efficacy of incrementally updateable learners under the Active Learning concept, a well-known iterative semi-supervised scheme where the initially collected instances, usually a few, are augmented by the combined actions of both the chosen base learner and the human factor. Instead of exploiting conventional batch-mode learners and refining them at the end of each iteration, we introduce the use of incremental ones, so as to apply favorable query strategies and detect the most informative instances before they are provided to the human factor for annotating them. Our assumption about the benefits of this kind of combination into a suitable framework is verified by the achieved classification accuracy against the baseline strategy of Random Sampling and the corresponding learning behavior of the batch-mode approaches over numerous benchmark datasets, under the pool-based scenario. The measured time reveals also a faster response of the proposed framework, since each constructed classification model into the core of Active Learning concept is built partially, updating the existing information without ignoring the already processed data. Finally, all the conducted comparisons are presented along with the appropriate statistical testing processes, so as to verify our claim.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Today, more and more applications from various scientific domains produce large volumes of data, changing the needs of current predictive mechanisms that mainly stem from the Machine Learning (ML) field. Since time and memory constitute the two main factors that highly define the performance of intelligent algorithms, especially when they tackle with problems over the era of Big Data, data scientists and ML/data engineers have to prioritize the structure of new predictive tools according to these specifications [1]. Incremental learning is the answer of the ML community to such kind of issues, where the principal idea is to update an existing or a previously built learning model by exploiting the newly available data, reducing the total time demands while possibly producing less accurate models [2].
Besides the simple approach, according to which vast amounts of labeled data (L) are provided or are reaching into data streams, a more realistic scenario has to cope with the shortage of L, in contrast with high enough volumes of unlabeled data (U). One representative reason why this may happen is the fact that in several real-world applications (e.g. in medicine tasks or in long-term experiments) the final state of the target variable may demand large time periods to be verified or to converge. Another reason is the inherit complexity of the data. In case of text-mining and nature language processing, numerous articles, chapters and posts on social media are freely available through web. However because of the complex structure that may characterize these sources – such as the complicated or unexplored semantic meanings on languages other than English – neither the automated solutions produce always decent learning results nor the choice of manually scanning by human entities could be time efficient [3].
In order to handle this phenomenon, a new kind of algorithms has been raised, often called as Semi-Supervised Learning (SSL) or, even more generic, as Partially-Supervised Learning (PSL), where the former category is contained into the latter [4]. The ambition of PSL algorithms is to exploit the existing labeled instances (li) along with the collected unlabeled examples (ui) and construct a model that maps the unknown instances with the target variable better than the corresponding model, which is based exclusively on the L subset. One main division among PSL algorithms depends on the way that the corresponding ui are getting labeled before they are merged into the L subset, so as to contribute over the increase of the predictive performance of the whole algorithm. While in SSL algorithms this process is automated usually by a base learner, Active Learning (AL) algorithms are differentiated since a human oracle is inserted into the learning process and is responsible for assigning the selected by a criterion ui with accurate enough decisions [5]. Although in several domains, only human experts could be exploited, it has been studied and generally verified that the decisions of numerous simple-users tend to converge over these produced by the human specialists in domains like sound/music signal categorization [6]. This means that a large aspect of applications could be satisfied through AL approaches without consuming much humans’ expert effort, a fact that might convert this kind of solution into a non-affordable one.
Our ambition in this work is to investigate the benefits of exploiting incremental learners (IncL) under a simple AL scheme that follows pool-based scenario. Thus, IncL would be responsible for detecting the most suitable ui, as well as for exporting the final decisions. The main rivals here are both the AL method whose query strategy coincides with a random selection of ui and the supervised scenario, where the same base learner has been trained based on the full dataset incrementally, as well as the same approaches trained under batch-mode operation. The amount of the initial L plays a crucial role producing per each different value a new variant of each exported algorithm from the proposed framework. More comments are presented in the corresponding paragraph.
To sum up, in Sect. 2, a number of related works are presented briefly, regarding mainly recent publications over incremental learning task and secondly with AL. Section 3 contains a description of the selected optimizer that injects the desired asset of incrementally update over underlying linear classifiers along with the necessary information about the proposed AL framework, while Sect. 4 includes more technical information, as well as information about the examined datasets and the conducted experiments. Finally, this work finishes with the conclusory Section that discusses the posed ambitions and highlights future work.
2 Related Work
2.1 Incremental Learning
Incremental learning refers to online learning strategies applicable to real-life streaming scenarios [7] with limited memory resources. So far, IncL is widely used ranging from Big Data and Internet of Things technology [7] to outlier detection for surveillance systems. One of the most popular areas in IncL is image/video data processing. Typical case scenarios are object detection [8] and recognition [9], image segmentation [10] and classification [11], surveillance [12], visual tracking [13] and prediction [14].
Moreover, the inherit nature of data in robotics make online learning an appropriate approach for mining the streaming signals [15]. In another study [16] an incremental image semantics learning framework is proposed. The proposed framework aims to learn image semantics from scratch (without a priory knowledge) and enrich the knowledge incrementally with human-robot interactions based on a teaching-and-learning procedure. Khan et al. [17] present a mechanism to build a consistent topological map for self-localization robotics applications. The proposed appearance-based loop closure detection mechanism builds a binary vocabulary consisting of visual words in an online, incremental manner by tracking features between consecutive video frames to incorporate pose invariance. In another relevant study [18], authors propose a new method to incrementally learn end-effector and null-space motions via kinesthetic teaching allowing the robot to execute complex tasks and to adapt its behavior to dynamic environments. The authors combine IncL with a customized multi-priority kinematic controller to guarantee a smooth human-robot interaction. Another rapidly emerging domain, which utilizes this concept, is robotic automotive [19].
2.2 Active Learning
However, all of the above applications require lots of labelled data and usually data labelling is difficult, time-consuming, and/or expensive to obtain. Active learning systems attempt to overcome the labeling bottleneck by asking queries in the form of ui to be labeled by an oracle, aiming to significantly reduce the cardinality of L subset that is needed. Active learning is still being heavily researched, under either more theoretical approaches or more experimental ones.
The last years, several attempts have been made to combine AL with Deep Learning (DL) concept, especially targeting specific applications that demand much computational power. Hence, ML researchers have begun searching the benefits of using CNNs and LSTMs and how to improve their efficiency when are applied along with AL frameworks [20, 21]. There is also research being done on implementing Generative Adversarial Networks (GANs) into the this kind of tasks [22]. With the increasing interest into deep reinforcement learning, researchers are trying to reframe AL as such a problem [23]. Also, there are papers which try to learn AL strategies via a meta-learning setting [24]. This does not mean that products of ML or more simple probabilistic base learners have been ignored by the corresponding community. On the contrary, a recent demonstration examines the chance of achieving fast and non-myopic AL strategy in context of binary classification datasets [25].
3 Proposed Framework
In order to conduct our investigation, a series of properties have to be defined for formulating the corresponding framework, under which our experiments will be executed. To be more specific, the base learner that is used in the core of the proposed framework is based on regularized linear models manipulated by Stochastic Gradient Descent (SGD) learning [26]. A more in-depth analysis follows subsequently, into this Section.
The same learner is used into both the selected Query strategy of AL framework and the stage of building the final classifier, after having augmented the L subset during each one of the k executed iterations. As it concerns the Query strategy, Uncertainty Sampling (UncS) approach has been selected in the context of this work, favoring the integration of the AL framework with probabilistic classifiers and boosting also the time response of each produced approach [27, 28]. Analog to the metric that is applied into the UncS approach, a number of variants can be produced. Finally, the human factor is replaced by an ideal oracle (Horacle) that exports always the correct decision about the label of each asked instance, playing the role of annotator.
The last generic parameter that has to be set is the Labeled Ratio value – usually depicted as R – and measured in percentage values. This factor defines the amount of the initially li in comparison with the total amount of both li and ui. Its formula is:
It is prominent that by acting under small R values, only a small part of the totally available information is provided initially to the AL framework. Hence, the predictions of the base learner are based on poor L subsets that may not reveal useful insights of the specific problem that is tackled, harnessing the achievement of accurate classification behaviors. Thus, the quadruple that defines each product of the proposed framework consists of the base learner, the specific metric of UncS, the number of iterations and the Labeled Ratio value. Its notation hereinafter would be (base-cl, UncSmetric, k, R). The obtained learning behavior of such an algorithm, according to our assumptions, would depict the ability of the selected base learner to operate efficiently under a fast and confident Query strategy to choose among a pool of ui, over which will be trained incrementally for k iterations, before exporting a final classifier, based initially on an amount of labeled instances that is defined by R parameter.
Gradient descent (GD) is by far the most popular optimization strategy, used in ML and DL at the moment. It is an optimization algorithm, based on a convex function, that tweaks its parameters iteratively to minimize a given cost function to its local minimum. In a simple supervised learning setup, each training example is composed of an arbitrary input x and a scalar output y in the form (x, y). For our ML model, we choose a family G of functions such as \( y \cong g_{w} \left( x \right) + b \), with w being a weighted vector and b an intercept term, which is necessary for obtaining better fit. Consequently, our goal is to minimize a cost function \( \varPsi \left( {\hat{y}, y} \right) = \varPsi \left( {g_{w} \left( x \right), y} \right) \) that measures the cost of predicting \( \hat{y} \) given the actual outcome \( y \) (or yactual) averaged on the training examples n. In other words, we seek to find a solution to the following problem:
The cost function \( \left( {E_{n} } \right) \) of Eq. 2 depends mainly on loss function (l) and the regularization term \( Reg\left( w \right) \). The multiplicative constant α refers to a non-negative hyperparameter. Following the original GD process, the minimization of Eq. 2 is taking place updating the next two formulas per each iteration t:
where the positive scalar η is called the learning rate or step size. In order, for the algorithm, to achieve linear convergence sufficient regularity assumptions should be made, while the initial estimate w0 should be close enough to the optimum and the gain η sufficiently small. It is important to highlight that the evaluation of n derivatives is required at each step. So, the per-iteration computational cost scales linearly with the training data set size n, making the algorithm inapplicable to huge datasets. Thus, the stochastic (SGD) version of the algorithm is used instead, which offers a lighter-weight solution. More specifically, at each iteration, the SDG randomly picks an example and calculates the gradient for this specific example:
In other words, SGD approximates the actual gradient using only one data point, saving a lot of time compared to summing over all data. SGD often converges much faster compared to GD but the error function is not as well minimized as in the case of GD. However, in most cases, the close approximation calculated by SGD for the parameter values are enough because they reach the optimal values and keep oscillating there. Another advantage of SGD is its ability to process the incoming data online in a deployed system, since no memory of the previous randomly chosen examples is necessary. In such a situation, the SGD directly optimizes the expected risk, since the examples are randomly drawn from the ground truth distribution [29].
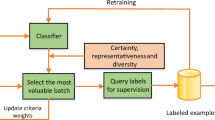
As it concerns \( Reg\left( w \right) \) term, three different choices are generally used in the literature: l1 norm that favors sparse solutions, l2 norm that is the most usual met and elastic net (elnet), that is formatted by a convex combination of the previous two norms and offers sparsity with better stabilization than simple l1 norm [30]. Before introducing the proposed framework through suitable pseudocode, we have to define the amount of the ui examples that should be mined per iteration. Although many approaches prefer to mine only one example per time, leading probably to more accurate actively trained classifier but clearly demanding much more computational resources because of the large amount of iterations that should be executed under a specific budget plan (B), a heuristic method is applied here: the questioned quantity of mined instances per iteration is computed by dividing the initial size of L subset with the number of executed iterations k. Thus, after k steps, the finally augmented training set will enumerate to the double number of instances. Additionally, since each ui is defined by a pair of (xf×1, y), where the scalar y value is not known, the assumed human oracle is defined as a function such that Horacle: Rf → yactual, where f parameter denotes the dimensionality of each dataset. The corresponding pseudocode follows here (Fig. 1):

Pseudocode of the proposed Incremental Active Learning framework
4 Experimental Procedure and Results
In order to verify the efficacy of the proposed AL framework, 19 binary datasets have been selected by UCI dataset. Their details are described in Table 1, along with the corresponding cardinality of initial training set (L0) for all the selected R-based scenarios: 5%, 15% and 25%. Moving further, all the conducted experiments are implemented using the libact library [31] that supports AL pool-based approaches via well-known python libraries [32]. Thus, 3 different metrics have been inserted into Query Strategy of the proposed framework: Smallest Margin (sm), Least Confident (lc) and Entropy (ent), apart from Random Sampling (random) variant, which constitutes the baseline strategy of AL concept. Moreover, each Supervised approach is included into our comparisons, so as to verify both the relative improvement and the corresponding importance of the implemented algorithms per both R-based case and operation mode.
Regarding the base learners that would be combined with SGD optimizer, 6 different approaches are presented here. This means that 2 different choices of base-cl parameter were made, along with all the 3 regularization terms that were referred. To be more specific, and at the same time following the notation of scikit-learn library [32], the corresponding loss functions, using their default properties, are:
-
base-cl = ‘log’, which implements the well-known Logistic Regression learner, whose output is filtered appropriately so as to be used in classification tasks [33],
-
base-cl = ‘mhuber’ (or ‘modified huber’), which implements a smoothed hinge loss function that is equivalent to quadratically smoothed Support Vector Machine (SVM) with gamma parameter equals to 2, offering robust behavior to outliers.
To begin with, a comparison of the time response of the exploited IncL against their corresponding batch-mode variants is presented. Thus, all the 12 supervised algorithms, either incrementally updated or operating under batch-mode, are measured regarding their execution time during 10-fold cross validation (10-CV) procedure, along with two approaches that are based on the well-known Naive Bayes (NB) algorithm, so as to compare the exploited learners with algorithms that are popular for their simplicity and support also incremental update. Because of lack of space, only a sample of the produced results will be presented here. An appropriate link with the full volume of our results is provided in the end of this Section. From the depicted results, it is observed a speed-up of at least 20% for the incremental SGD-based learners, while their time performance is comparable with the MNB. Similar kind of improvement is also met into the proposed framework. A quad-core machine (Intel Core Q9300, 2.50 GHz, 8 GB RAM) was used.
As it concerns the classification accuracy that was scored by the selected algorithms, the number of iterations has been fixed equal to 15. This value has been selected via empirical process. However, its tuning could provide better results, compromising the spent human effort and the available B. The next Table presents only the averaged accuracies over the 19 selected datasets, so as to compare the achieved accuracy per actively trained classifier against random strategy and the corresponding supervised variant that uses the whole dataset. The format of the next Table enables the direct comparison of IncL and batch-based approaches. The accuracy of the best performed metric per R-based scenario and same base-learner, independently of its operation mode, is highlighted in bold format. Only two R-scenarios have been included in Table 2.
It is evident that the incrementally based algorithms obtain a superior learning behavior against the conventional batch-mode operating approaches, since in all cases they outperformed the latter approaches. For providing a more detailed insight of the obtained results concerning the produced AL algorithms of the proposed framework, we notice that: in all the 90 1-vs-1 comparison between IncL and batch-based learner the former prevailed, sm metric was ranked as the best metric in 13 out of 18 cases, UncS strategy outperformed random sampling in 33 out of 54 cases, while the Supervised approaches were also outreached 22 times, regarding the incremental scenario. Keeping in mind that the proposed algorithms consume less computational resources, it seems that this kind of combination leads to more remarkable ML tools, regarding both the aspects of accuracy and time efficacy (Table 3).
The statistical verification of the produced results is visualized through CD diagrams. According to this method, appropriate rankings are provided to a post-hoc test, in our case the Bonferroni-Dunn, computed by Friedman statistical test, and corresponding critical differences are computed for significance level equal to 0.05 [34]. Every algorithm that is connected via a horizontal line to another one, depicts that their learning behavior did not present significant difference Fig. 2.
For obtaining a more explanatory view of these comparisons, a series of violin plots has been selected to highlight the differences of the IncL and batch-mode algorithms. Through this tactic, the distribution of the scored classification accuracies is visualized, along with the average and the quartile values. In Fig. 3, the corresponding algorithms that use ‘elnet’ regularization term are presented. The complete results are provided in https://github.com/terry07/ke80537.

A CD diagram for mhuber-based learners and ‘elnet’ as regularization term for R = 25%.
5 Conclusions and Future Work
This work constitutes a primal product of our research in involving IncL under SSL schemes so as to compensate the iterative character of the latter, by exploiting the beneficial refinement assets of the former, regarding the base learner. Our results over a wide range of binary datasets prove the remarkable classification accuracy that was achieved in case of AL concept, based on 3 amounts of labeled examples and relying on an ideal human oracle for annotation stage. The common factor over all these experiments was the use of SGD method that injects its incremental property over the linear learners that are applied. Three different regularization terms were also used, creating a series of SGD-based learners, whose learning behavior outperformed the baseline of Random Sampling strategy and the corresponding conventional batch-based methods, in the majority of the examined cases, while their performance, mainly under the Smallest Margin metric into Uncs strategy, was similar enough with their supervised rival.

A violin plot of log-based learners and ‘elnet’ as regularization term for R = 5%.
The next steps are oriented towards both the examination of multiclass datasets and binary datasets that come from more specific tasks, like intrusion detections that suffers from distribution drifting [35] or text classification [36]. Furthermore, a larger variety of AL query strategies could be applied, exploiting either more sophisticated ML techniques [37] or margin-based queries that perform robustness over noisy input data [38]. Moreover, the scheme of ALBL (Active Learning By Learning) [39] could be a really promising solution, where a number of AL strategies are evaluated through a meta-learning stage. Finally, combination of SSL and AL strategies seems a powerful combination [40], reducing heavily human effort, since only a small number of iterations could be selected to ask feedback, while the incremental asset could be retained.
References
Domingos, P., Hulten, G.: Mining high-speed data streams. In: KDD, pp. 71–80 (2000)
Pratama, M., Anavatti, Sreenatha G., Lughofer, E.: An incremental classifier from data streams. In: Likas, A., Blekas, K., Kalles, D. (eds.) SETN 2014. LNCS (LNAI), vol. 8445, pp. 15–28. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-07064-3_2
Mahmoud, M.: Semi-supervised keyword spotting in Arabic speech using self-training ensembles (2015)
Schwenker, F., Trentin, E.: Pattern classification and clustering: A review of partially supervised learning approaches. Pattern Recogn. Lett. 37, 4–14 (2014)
Aggarwal, C.C., Kong, X., Gu, Q., Han, J., Yu, P.S.: Active learning: a survey. In: Data Classification: Algorithms and Applications, pp. 571–605 (2014)
Zhang, Z., Cummins, N., Schuller, B.: Advanced data exploitation in speech analysis. IEEE Signal Process. Mag. 34, 107–129 (2017)
Hoens, T.R., Polikar, R., Chawla, N.V.: Learning from streaming data with concept drift and imbalance: an overview. Prog. Artif. Intell. 1, 89–101 (2012)
Dou, J., Li, J., Qin, Q., Tu, Z.: Moving object detection based on incremental learning low rank representation and spatial constraint. Neurocomputing. 168, 382–400 (2015)
Bai, X., Ren, P., Zhang, H., Zhou, J.: An incremental structured part model for object recognition. Neurocomputing. 154, 189–199 (2015)
Tasar, O., Tarabalka, Y., Alliez, P.: Incremental learning for semantic segmentation of large-scale remote sensing data. CoRR. abs/1810.1 (2018)
Ristin, M., Guillaumin, M., Gall, J., Van Gool, L.: Incremental learning of random forests for large-scale image classification. IEEE Trans. Pattern Anal. Mach. Intell. 38, 490–503 (2016)
Shin, G., Yooun, H., Shin, D., Shin, D.: Incremental learning method for cyber intelligence, surveillance, and reconnaissance in closed military network using converged IT techniques. Soft. Comput. 22, 6835–6844 (2018)
Dou, J., Li, J., Qin, Q., Tu, Z.: Robust visual tracking based on incremental discriminative projective non-negative matrix factorization. Neurocomputing 166, 210–228 (2015)
Wibisono, A., Jatmiko, W., Wisesa, H.A., Hardjono, B., Mursanto, P.: Traffic big data prediction and visualization using fast incremental model trees-drift detection (FIMT-DD). Knowl. Based Syst. 93, 33–46 (2016)
Wang, M., Wang, C.: Learning from adaptive neural dynamic surface control of strict-feedback systems. IEEE Trans. Neural Netw. Learn. Syst. 26, 1247–1259 (2015)
Zhang, H., Wu, P., Beck, A., Zhang, Z., Gao, X.: Adaptive incremental learning of image semantics with application to social robot. Neurocomputing 173, 93–101 (2016)
Khan, S., Wollherr, D.: IBuILD: incremental bag of binary words for appearance based loop closure detection. In: 2015 IEEE International Conference on Robotics and Automation (ICRA), pp. 5441–5447. IEEE (2015)
Saveriano, M., An, S., Lee, D.: Incremental kinesthetic teaching of end-effector and null-space motion primitives. In: 2015 IEEE International Conference on Robotics and Automation (ICRA), pp. 3570–3575. IEEE (2015)
Thrun, S.: Toward robotic cars. Commun. ACM 53, 99 (2010)
Shen, Y., Yun, H., Lipton, Z.C., Kronrod, Y., Anandkumar, A.: Deep active learning for named entity recognition. In: Blunsom, P., et al. (eds.) Proceedings of the 2nd Workshop on Representation Learning for NLP, Rep4NLP@ACL 2017, Vancouver, Canada, 3 August 2017, pp. 252–256. Association for Computational Linguistics (2017)
Sener, O., Savarese, S.: Active learning for convolutional neural networks: a core-set approach. In: International Conference on Learning Representations (2018)
Liu, Y., et al.: Generative adversarial active learning for unsupervised outlier detection. CoRR. abs/1809.1 (2018)
Fang, M., Li, Y., Cohn, T.: Learning how to active learn: a deep reinforcement learning approach. In: Palmer, M., Hwa, R., Riedel, S. (eds.) EMNLP 2017, Copenhagen, Denmark, pp. 595–605. Association for Computational Linguistics (2017)
Contardo, G., Denoyer, L., Artières, T.: A meta-learning approach to one-step active-learning. In: Brazdil, P., Vanschoren, J., Hutter, F., and Hoos, H. (eds.) AutoML@PKDD/ECML, pp. 28–40. CEUR-WS.org (2017)
Krempl, G., Kottke, D., Lemaire, V.: Optimised probabilistic active learning (OPAL): for fast, non-myopic, cost-sensitive active classification. Mach. Learn. 100, 449–476 (2015)
Zhang, T.: Solving large scale linear prediction problems using stochastic gradient descent Algorithms. In: ICML, pp. 919–926 (2004)
Settles, B.: Active Learning. Morgan & Claypool Publishers, San Rafael (2012)
Sharma, M., Bilgic, M.: Evidence-based uncertainty sampling for active learning. Data Min. Knowl. Discov. 31, 164–202 (2017)
Tsuruoka, Y., Tsujii, J., Ananiadou, S.: Stochastic gradient descent training for L1-regularized log-linear models with cumulative penalty. In: ACL/IJCNLP, pp. 477–485 (2009)
Zou, H., Hastie, T.: Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B. 67, 301–320 (2005)
Yang, Y.-Y., Lee, S.-C., Chung, Y.-A., Wu, T.-E., Chen, S.-A., Lin, H.-T.: libact: Pool-based active learning in Python (2017)
Buitinck, L., et al.: API design for machine learning software: experiences from the scikit-learn project. In: CoRR abs/1309.0238 (2013)
Harrell, F.E.: Regression Modeling Strategies. Springer, New York (2015). https://doi.org/10.1007/978-3-319-19425-7
Hastie, T., Tibshirani, R., Friedman, J.: The Elements of Statistical Learning. Springer, Heidelberg (2009). https://doi.org/10.1007/978-0-387-84858-7
Xiang, Z., Xiao, Z., Wang, D., Georges, H.M.: Incremental semi-supervised kernel construction with self-organizing incremental neural network and application in intrusion detection. J. Intell. Fuzzy Syst. 31, 815–823 (2016)
Lin, Y., Jiang, X., Li, Y., Zhang, J., Cai, G.: Semi-supervised collective extraction of opinion target and opinion word from online reviews based on active labeling. J. Intell. Fuzzy Syst. 33, 3949–3958 (2017)
Akusok, A., Eirola, E., Miche, Y., Gritsenko, A.: Advanced Query Strategies for Active Learning with Extreme Learning Machine. In: ESANN, pp. 105–110 (2017)
Wang, Y., Singh, A.: Noise-adaptive margin-based active learning for multi-dimensional data. CoRR. abs/1406.5 (2014)
Hsu, W.-N., Lin, H.-T.: Active learning by learning. In: Bonet, B., Koenig, S. (eds.) Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, 25–30 January 2015, Austin, Texas, USA, pp. 2659–2665. AAAI Press (2015)
Zhao, J., Liu, N., Malov, A.: Safe semi-supervised classification algorithm combined with active learning sampling strategy. J. Intell. Fuzzy Syst. 35, 4001–4010 (2018)
Acknowledgements
This research is implemented through the Operational Program Human Resources Development, Education and Lifelong Learning and is co-financed by the European Union (European Social Fund) and Greek national funds.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 IFIP International Federation for Information Processing
About this paper

Cite this paper
Karlos, S., Kanas, V.G., Fazakis, N., Aridas, C., Kotsiantis, S. (2019). Investigating the Benefits of Exploiting Incremental Learners Under Active Learning Scheme. In: MacIntyre, J., Maglogiannis, I., Iliadis, L., Pimenidis, E. (eds) Artificial Intelligence Applications and Innovations. AIAI 2019. IFIP Advances in Information and Communication Technology, vol 559. Springer, Cham. https://doi.org/10.1007/978-3-030-19823-7_3
Download citation
DOI: https://doi.org/10.1007/978-3-030-19823-7_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-19822-0
Online ISBN: 978-3-030-19823-7
eBook Packages: Computer ScienceComputer Science (R0)