
Abstract
In this chapter we provide an overview of selected methods for the design and analysis of symmetric encryption algorithms that have recently been published. We start by discussing the practical advantages, limitations and security of the keystream generators with keyed update functions which were proposed for reducing the area cost of stream ciphers. Then we present an approach to enhancing the security of certain encryption schemes by employing a universal homophonic coding and randomized encryption paradigm.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others



1 Introduction
The concept of ubiquitous computing brings new challenges to the designers of cryptographic algorithms by introducing scenarios where classical crypto primitives are infeasible due to their costs (such as hardware price, computational time, and power and energy consumption). In this chapter we provide an overview of selected recent approaches which deal with such challenges.
An approach [27] which allows one to realize secure stream ciphers with state size beyond the bound which was previously considered to be the minimum is summarized in Sect. 3.2. The main idea is to use so-called keystream generators with keyed update functions (KSGs with KUF) where the secret key is involved not only in the initialization phase (as is common practice) but during the entire encryption process. After explaining the advantages [27] of KSGs with KUF in resisting Time Memory Data Tradeoff (TMDTO) attacks [47, 237] together with practical issues and limitations on their implementation in hardware[421], we describe the stream cipher Sprout which was designed in order to demonstrate the feasibility of the approach [27], and its improvement Plantlet where the security weaknesses of Sprout were fixed [421]. In Sect. 3.3 we present a generic attack [314] against such KSGs that implies a design criterion. Section 3.4 presents an approach to security enhancement of certain encryption schemes employing universal homophonic coding [397] and a randomized encryption paradigm [503]. The approach summarized in this section has been reported and discussed in a number of references including [413, 418, 452] and [420]. A security evaluation of this encryption scheme has been reported in [452] from an information-theoretic point of view, and a computational-complexity evaluation approach is given in [420].
2 Keystream Generators with Keyed Update Functions
2.1 Design Approach
Stream ciphers usually provide a higher throughput than block ciphers. However, due to the existence of certain TMDTO [47, 91, 237] attacks, the area size required to implement secure stream ciphers is often higher. The reason is the following. The effort of TMDTO attacks against stream ciphers is O(2σ∕2), where σ is the internal state size. Therefore, a rule of thumb says that to achieve κ-bit security level, the state size should be at least σ = 2 ⋅ κ. This results in the fact that a stream cipher requires at least 2 ⋅ κ memory gates which are the most costly hardware elements in terms of area and power-consumption. In this section we discuss an extension [27, 421] of the common design principle, which allows for secure lightweight stream ciphers with internal state size below this bound.
We start the description of the new approach for stream ciphers design by giving the definition of the KSG with KUF [27]:
Definition 1 (Keystream Generator with Keyed Update Function)
A keystream generator with a keyed update function comprises three sets, namely the key space \({\mathcal {K}}=\mathrm {GF}(2)^{\kappa }\), the IV space \({\mathcal {I}\mathcal {V}}=\mathrm {GF}(2)^{\nu }\), and the variable state space \({\mathcal {S}}=\mathrm {GF}(2)^{{\sigma }}\). Moreover, it uses the following three functions
-
an initialization function \(\mathsf {Init}:{\mathcal {I}\mathcal {V}}\times {\mathcal {K}}\rightarrow {\mathcal {S}}\)
-
an update function \(\mathsf {Upd}: {\mathcal {K}}\times {\mathcal {S}}\rightarrow {\mathcal {S}}\) such that \(\mathsf {Upd}_{{k}}:{\mathcal {S}}\rightarrow {\mathcal {S}}\), U p d k(st) := U p d(k, st), is bijective for any \({k}\in {\mathcal {K}}\), and
-
an output function \(\mathsf {Out}:{\mathcal {S}}\rightarrow \mathrm {GF}(2)\).
The internal state ST is composed of a variable part \({st}\in {\mathcal {S}}\) and a fixed part \({k}\in {\mathcal {K}}\). A KSG operates in two phases. In the initialization phase, the KSG takes as input a secret key k and a public IV iv and sets the internal state to \({st}_{0}{\,:=\,}\mathsf {Init}(iv,{k}){\,\in \,}{\mathcal {S}}\). Afterwards, the keystream generation phase executes the following operations repeatedly (for t ≥ 0):
-
1.
Output the next keystream bit z t = O u t(st t)
-
2.
Update the internal state st t to st t+1 := U p d(k, st t)
The main difference between KSGs with KUF and the KSGs traditionally used as a core of stream ciphers is that the next state is now computed not only from the current variable state st t (as is commonly done) but also from the fixed key k.
We now explain why stream ciphers built based on the KSGs with KUF have advantages in resisting TMDTO attacks over classical KSGs. The goal of the TMDTO attacker is the following: given a function \({F}:{\mathcal {N}}\rightarrow {\mathcal {N}}\) and D images y 1, …, y D of F, find a preimage for any of these points, i.e., determine a value \(x_i\in {\mathcal {N}}\) such that F(x i) = y i. Typically, these attacks consist of two phases: a precomputation (offline) phase, and a real-time (online) phase. At first the attacker precomputes a large table using the function F (offline phase). In the online phase the attacker gets D outputs of F and checks if any of these values is included in the precomputed table. In the case of success, a preimage has been found. Obviously, an attacker can increase the success probability by either precomputing more values in the offline phase or collecting more data in the online phase where the optimal trade-off is usually given as \(|{D}|=\sqrt {|{\mathcal {N}}|}\).
The goal of a TMDTO attack in the context of KSGs is to recover one internal state as this allows us to compute the complete keystream. To this end, let F Out : GF(2)σ →GF(2)σ be the function that takes the internal state st t ∈GF(2)σ at some clock t as input and outputs the σ keystream bits z t, …, z t+σ−1. Then, the attack translates to finding a preimage of F Out for a given keystream segment with the search space being \({\mathcal {N}}= {\mathcal {S}}\) and an effort of at least \(\sqrt {|{\mathcal {S}}|}=2^{{\sigma }/2}\). This implies the above-mentioned rule of selecting σ ≥ 2κ.
To understand the motivation behind the design principle given in Definition 1, we introduce the notion of keystream-equivalent states which is important for analyzing the effectiveness of a TMDTO attack. Let \({F}_{\mathsf {Out}}^{\mathrm {compl.}}\) be the function that takes as input the initial state and outputs the maximum number of keystream bits. If no bound is given by the designers, we assume that the maximum period of 2σ keystream bits is produced. An attacker is interested in any internal state that allows the keystream to be computed:
Definition 2 (Keystream-Equivalent States)
Consider a KSG with a function \({F}_{\mathsf {Out}}^{\mathrm {compl.}}\) that outputs the complete keystream. Two states \({st},{st}'\in {\mathcal {S}}\) are said to be keystream-equivalent (in short st ≡kse st′) if there exists an integer r ≥ 0 such that \({F}_{\mathsf {Out}}^{\mathrm {compl.}}(\mathsf {Upd}^r({st}))={F}_{\mathsf {Out}}^{\mathrm {compl.}}({st}')\). Here, U p d r means the r-times application of U p d.
For any state \({st}\in {\mathcal {S}}\), we denote by [st] its equivalence class, that is \( [{st}]=\{{st}'\in {\mathcal {S}}\vert {st}\equiv _{\mathrm {kse}} {st}' \} \).
Now, let us consider an arbitrary KSG with state space \({\mathcal {S}}\). As any state is a member of exactly one equivalence class, the state space can be divided into ℓ distinct equivalence classes:

Assume a TMDTO attacker who is given some keystream (z t), based on an unknown initial state st 0. In this case if none of the precomputations are done for values in \(\left [{st}_{0} \right ]\), the attack will fail. This implies that the attack effort is at least linear in the number ℓ of equivalence classes. Hence we can see that if we design a cipher such that ℓ ≥ 2κ, such a cipher will have the required security level against trade-off attacks.
Let us now take a look at the minimum time effort for a TMDTO attack against a KSG with a KUF. We make in the following the assumption that any two different states ST = (st, k) and ST′ = (st′, k′) with k ≠ k′ never produce the same keystream, that is \({F}_{\mathsf {Out}}^{\mathrm {compl.}}({ST})\not \equiv _{\mathrm {kse}} {F}_{\mathsf {Out}}^{\mathrm {compl.}}({ST}')\). Hence, we have at least 2κ different equivalence classes. As the effort grows linearly with the number of equivalence classes, we assume in favor of the attacker that we have exactly 2κ equivalence classes. This gives a minimum time complexity of 2κ. This means that, in theory, it is possible to design a cipher with a security level of κ regardless of the length σ of its variable state.
2.2 On Continuously Accessing the Key
In most cases the workflow of ciphers looks as follows. After the encryption or decryption process is started, the key is loaded from some non-volatile memory N V M into some registers, i.e., into some volatile memory V M. We call the value in V M a volatile value as it usually changes during the encryption/decryption process and the value stored in N V M, the non-volatile value or non-volatile key which remains fixed. It holds for most designs that after the key has been loaded from N V M into V M, the N V M is usually not involved anymore (unless the key schedule or the initialization process needs to be restarted). But the design approach discussed in Sect. 3.2.1 requires that the key which is stored on the device has to be accessed not only for initialization of the registers but continuously in the encryption/decryption process. The feasibility of this approach for different scenarios was investigated in [421].
It has been argued there that continuously accessing the key can impact the achievable throughput. To this end, two different cases need to be considered. The first one is when the key is set once and is never changed and the second one is when it is possible to rewrite the key. The types of N V M (e.g., MROM and PROM) which can be used in the first case, allow for efficient implementations where accessing the key bits induces no overhead. However, the key management is very difficult here. In the second case, i.e., for those types of N V M which allow the key to be rewritable (such as EEPROM and Flash), severe timing limitations for accessing the N V M may occur. In particular, it depends on how the key stored in N V M needs to be accessed. In some cases, implementation of ciphers which require continuous access to the randomly selected bits of the key stored in rewritable types of N V M may lead to a reduction of the throughput up to a factor of 50 [421]. However, designs that require sequential access to the key bits are almost unaffected, irrespective of the underlying N V M type.
With respect to area size, there is no big difference whether the key has to be read only once or continuously during encryption, since the logic for reading the key (at least once) has to be implemented anyway. Small extra logic may be needed for synchronization with an NVM cipher which should not be clocked unless key material is read from N V M.
2.3 The Stream Ciphers Sprout and Plantlet
The design principles discussed in Sect. 3.2.1 have been demonstrated by two concrete keystream generators with keyed update function, namely Sprout and Plantlet. Both ciphers have a similar structure (see Fig. 3.1) which was inspired by Grain-128a [14]. The differences are the following:
-
1.
Sprout and Plantlet have shorter internal state size compared to any of the Grain family ciphers [265]
Fig. 3.1 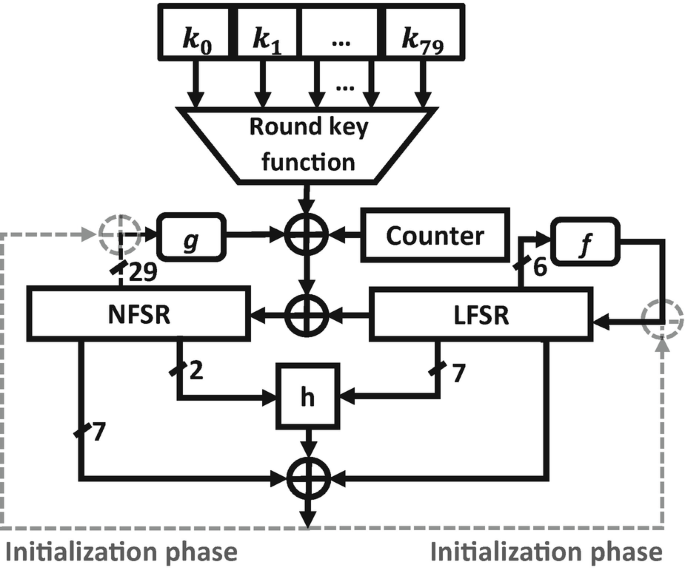
Overall structure of the Sprout and Plantlet ciphers
-
2.
They use the round key function to make the state update key-dependent
-
3.
The counter is used in the state update in order to avoid situations where shifted keys result in shifted keystreams

The design of Plantlet actually builds on Sprout but included some changes to fix several weaknesses [50, 203, 355, 387]. The main differences between Plantlet and Sprout are the following:
-
1.
Plantlet has a larger internal state size compared to Sprout. The difference was introduced in order to increase the period of the output sequences and to increase resistance against guess-and-determine attacks
-
2.
In both ciphers, the round key function cyclically steps through the key bits, which is well aligned with the performance of different types of NVM as mentioned before. However, in Sprout the key bits are only included in the NFSR update with a probability of 0.5, i.e., only if the linear combination of several state bits is equal to 1. This has been exploited by several attacks so in Plantlet the next key bit is added unconditionally at every clock-cycle.
-
3.
Plantlet uses a so-called double-layer LFSR which allows for high period and at the same time avoids the LFSR being initialized with all-zeroes
For full specifications we refer the reader to [27, 422].
Implementation Results
We used the Cadence RTL CompilerFootnote 1 for synthesis and simulation, and the technology library UMCL18G212T3 (UMC 0.18 μm process). The clock frequency was set to 100 kHz. For different memory types Sprout requires from 692 to 813 GEs, whereas Plantlet needs from 807 to 928 GEs. Note that the smallest KSG which follows the classical design approach needs at least 1162 GEs if the same tools are used for implementation [421].
Security
As already mentioned, several serious weaknesses [50, 203, 355, 387] were shown to exist in Sprout, whereas Plantlet, to the best of our knowledge, remains secure for the moment.
3 A Generic Attack Against Certain Keystream Generators with Keyed Update Functions
In this section, we describe a generic attack against the following type of Keystream Generators with a Keyed Update Function (Definition 1):
Definition 3 (KSG with Boolean Keyed Feedback Function)
Consider a KSG with a KUF as in Definition 1. Let U p d i denote the Boolean component functions of the update function U p d, that is U p d(k, st) = (U p d i(k, st))i. We call this a KSG with a Boolean KFF (Keyed Feedback Function) if only one component function depends on the secret key. That is, there is an index i ∗ such that all other component functions with index i ≠ i ∗ can be rewritten as U p d i(k, st) = U p d i(st). We call \(\mathsf {Upd}_{i^*}({k}, {st})\) the keyed feedback function and denote it by f Upd(k, st).
When we say the “feedback value”, we mean the output of the keyed feedback function f Upd(k, st). The most prominent examples of KSGs with a Boolean KUF in the literature are Sprout [27] and its successor Plantlet [421] (see Sect. 3.2.3). Even though several attacks against the cipher Sprout have been published [50, 203, 355, 387, 593], only little is known about the security of the underlying approach (see Sect. 3.2.1) in general. In the following, we explain the only existing generic attack [314] that implies a design criterion for this type of ciphers.
The attack is a guess-and-determine attack that is based on guessing internal states from the observed output. Its efficiency heavily relies on the guess capacity, which we define next:
Definition 4
For a given KSG with a Boolean KFF having a σ-bit internal state, a κ-bit key, and f Upd as its Boolean keyed feedback function, we define the average guess capacity as
The average guess capacity simply indicates how accurately we can guess the feedback value f Upd(k, st) when we know the internal state but we do not know the key. The following attack [314] applies to the case of \(\Pr \nolimits _g >1/2\) which eventually allows us to formulate a necessary design criterion.
Algorithm 1 Internal state recovery

The core of the attack is an internal state recovery algorithm (see Algorithm 1). It tests, for a given internal state whether it can consistently continue producing the observed output bits. To this end, it produces the feedback values (the outputs of the Boolean keyed feedback function) for the next states by either determining them from the output if that is possible or first checking and then guessing them. It consists of two parts: determining the feedback value is done by Algorithm 2 and checking the candidate state and then guessing the feedback value if the state survives, is achieved by Algorithm 3. It is obvious that Algorithm 2 produces only one feedback value for each clock. Similarly, Algorithm 3 first checks if a candidate state can produce the output. So, it survives with a probability of one half and the surviving states will have two successors. Hence, neither Algorithm 2 nor Algorithm 3 will propagate the total number of states to be checked.
Algorithm 2 Determine procedure

Each candidate state has successors for consecutive clocks and a set of feedback values produced by Algorithm 1. On the other hand, we count the number of mismatches for each feedback value. We say that a feedback value is a mismatch if it is not the suggested value obtained through its internal state. If the probability that the feedback value is equal to 0 (or 1) for a given state is higher than one half, then 0 (or 1) will be the suggested value of that state.
Assume we clock the generator α ter steps to check each state. Then, we expect roughly α ter∕2 mismatches for a wrong state and \(\alpha _{ter} (1-\Pr \nolimits _g)\) mismatches for a correct state. This provides us with a distinguisher to recover the correct state without knowing the key. We set a threshold value α thr, between \(\alpha _{ter} (1-\Pr \nolimits _g)\) and α ter∕2 and simply eliminate the states whose number of mismatches exceeds α thr. We expect all the wrong internal states to be eliminated for a well-chosen pair (α ter, α thr) and only the correct state is expected to survive. Theorem 1 suggests appropriate values for α ter so as to obtain a given success rate. Then we fix the threshold value accordingly, in Algorithm 1 in its third line.
Algorithm 3 Check-and-guess procedure

The performance of Algorithm 1 depends heavily on how many clocks we should go further to eliminate all the wrong states without missing the correct state. This is determined by the success rate of the algorithm which in turn is dominated by the guess capacity (Definition 4) as stated in the following Theorem 1 [314]:
Theorem 1
Let \(\Pr \nolimits _g >1/2\) be the guess capacity of a given KSG with Boolean KFF having internal state size σ. For a given 0 < 𝜖 < 1, if α ter is greater than or equal to
then the success rate of the attack in Algorithm 1 is at least 1 − 𝜖 and the number of false alarms is less than one in total.
The average guess capacity of Sprout is 0.75. Hence it is possible to recover its correct state without knowing the key by eliminating a wrong state in roughly 122 clocks [314]. Checking roughly 240 states (which are called “weak states” and loaded into a table in the precomputation phase), one can recover the key in roughly 238 encryptions [314]. On the other hand, Algorithm 1 becomes infeasible when \(\Pr \nolimits _g\) approaches 1∕2. Plantlet (Sect. 3.2.3) has a guess capacity of 1∕2, so Algorithm 1 is not applicable to Plantlet. Concluding, the attack above implies a new security criterion: the guess capacity of the feedback function of a KSG with Boolean KFF should be one half in order to avoid state recovery attacks that bypass the key.
4 Randomized Encryption Employing Homophonic Coding
4.1 Background
In [503], several approaches to including randomness in encryption techniques are discussed, mainly in the context of block and stream ciphers. Randomized encryption is described [503] as a procedure which enciphers a message by randomly choosing a ciphertext from a set of ciphertexts corresponding to the message under the current encryption key.
Homophonic coding was introduced in [249] as a source coding technique which transforms a stream of message symbols with an arbitrary frequency distribution into a uniquely decodable stream of symbols which all have the same frequency. The universal homophonic coding approach [397] is based on an invertible transformation of the source information vector with embedded random bits, and this approach does not require knowledge of the source statistics. The source information vector can be recovered from the homophonic coder output without knowledge of the random bits by passing the codeword to the decoder (inverter) and then discarding the random bits.
A number of randomized encryption techniques have been reported: In [234], a probabilistic private-key encryption scheme named LPN-C whose security can be reduced to the hardness of the LPN problem was proposed and analysed. An approach for the design of stream ciphers employing error-correction coding and certain additive noise degradation of the keystream was reported in [201]. A message is encoded before the encryption so that the decoding, after mod 2 addition of the noiseless keystream sequence and the ciphertext, provides its correct recovery. Resistance of this approach against a number of general techniques for cryptanalysis, was also considered in [201]. Joint employment of randomness and dedicated coding has been studied for enhancing the security of the following block-by-block encryption schemes: (1) in [418], where the basic keystream generator security is enhanced by employing a particular homophonic coding based on embedding of random bits; (2) in [413, 419] and [414] randomness and dedicated coding were employed for enhancing the security of the compact generators of pseudorandom vectors; (3) in [322] and [577] channel coding was employed to increase the security of a DES block cipher operating in the ciphertext feedback (CFB) mode. Also, certain issues of randomized encryption were considered in [321, 570] and [313].
4.2 Encryption and Decryption
The ciphering technique given in this section originates from the schemes reported in [322, 414, 418], and it corresponds to the randomized encryption schemes proposed and discussed in [452]. The design assumes the availability of a source of pure randomness (for example, as an efficient hardware module) and that a suitable error-correcting coding (ECC) technique is available. This availability means that the implementation complexities of the source of randomness and the ECC do not imply a heavy implementation overhead in suitable scenarios.
The scheme employs a homophonic approach for a purpose different from the ones this coding techniques were designed for. The main purpose is not just randomization of the source message vectors (the goal of homophonic coding) nor secrecy without a secret key (the goal of wire-tap channel coding) but enhancing the cryptographic security of certain encryption schemes by employing the underlying features of homophonic or wire-tap channel coding. The goal is the security enhancement of a cryptographic keystream generator for encryption by employing a dedicated coding scheme where the codewords provide additional “masking” of the keystream vectors employed for encryption. The encryption scheme in Fig. 3.2 performs modulo 2 addition of the outputs of the encoding block and the keystream generator which can be considered not only as “masking” the message vector with a vector generated by a secret key, but also as masking the keystream vector by a randomized mapping of the information vector.

Model of a security enhanced randomized encryption within the encoding-encryption paradigm: the upper part shows the transmitter, the lower part—the receiver [452]
We assume that the encryption from Fig. 3.2 employs concatenation of the following coding algorithms: (1) a universal homophonic coding [397] which performs the following mapping {0, 1}ℓ →{0, 1}m, ℓ < m, and (2) a linear block error-correction code which performs {0, 1}m →{0, 1}n, m < n, and which provides reliable communication over a binary symmetric channel with a known probability of bit complementation. Please note that any suitable binary linear block code designed to work over a binary symmetric channel with crossover probability p could be employed. There are a lot of these coding schemes reported in the literature and one which best fits into a particular implementation scenario (hardware or software oriented) could be selected. We consider a communication system displayed in Fig. 3.2 where some message \(\mathbf {a}=[a_i]_{i=1}^l \in \{0,1\}^l\) is sent to a transmitter over a noisy channel and the following operations at the transmitter and receiver.
At the Transmitter
To ensure reliable communication, a linear error-correcting encoder C ECC(⋅) is used, that maps an m-bit message to a codeword of n > m bits, using an m × n binary code generator matrix G ECC. A homophonic encoder C H(⋅) is added prior to C ECC(⋅), which requires the use of a vector \(\mathbf {u}=[u_i]_{i=1}^{m-l} \in \{0,1\}^{m-l}\) of pure randomness, i.e., each u i is the realization of a random variable U i with distribution Pr(U i = 1) = Pr(U i = 0) = 1∕2. The encoding C H(a||u) may be described by an m × m binary matrix G H such that
where G C is an (m − l) × m generator matrix for an (m, m − l) linear error-correction code C, and h 1, h 2, …, h l are l linearly independent row vectors from {0, 1}m∖C.
We get a joint encoding a ∈{0, 1}l↦C ECC(C H(a||u)) ∈{0, 1}n, which may alternatively be written as
where G = G H G ECC is an m × n binary matrix containing the two successive encoders at the transmitter.
The codeword sent is finally an encrypted version y of C ECC(C H(a||u)) given by y = y(k) = C ECC(C H(a||u)) ⊕x where \(\mathbf {x}=\mathbf {x}(\mathbf {k})=[x_i]_{i=1}^n\in \{0,1\}^n\) is a pseudorandom vector needed for encryption, which is generated by either a keystream generator, or by a block cipher working in the cipher feedback mode (CFB) as in [322] and [577]. Notice the important dependency of x = x(k) in the secret key k. Also note that, for simplicity of the exposition, the data employed for generation of the pseudorandom vectors x, which are publicly known (like a public seed and a synchronization parameter) are not explicitly shown. Finally, the model includes the assumption that the concatenation of the binary vectors x appears as a pseudorandom binary sequences and from a statistical point of view is indistinguishable from a random binary sequence.
At the Receiver
The noisy communication channel is modeled by the addition of a noise vector \(\mathbf {v}=[v_i]_{i=1}^{n}\in \{0,1\}^n\), where each v i is the realization of a random variable V i with Pr(V i = 1) = p and Pr(V i = 0) = 1 − p. The receiver obtains z = z(k) = y ⊕v = C ECC(C H(a||u)) ⊕x ⊕v and starts by decrypting y = (C ECC(C H(a||u)) ⊕x ⊕v) ⊕x = C ECC(C H(a||u)) ⊕v. He then first decodes C H(a||u). In the case of a successful decoding, he computes a using \(C_H^{-1}\) and informs the transmitter he could decode. Otherwise he asks the transmitter for a retransmission. This assumes noiseless feedback between the receiver and the transmitter.
4.3 Security Evaluation
Information-Theoretic Security
In [452], the above model of randomized encryption schemes was studied from an information-theoretic point of view. The goal was to analyze the security enhancement provided by the wiretap encoding, in terms of secret key k equivocation, that is, the uncertainty that an adversary faces about the secret key, given all the information he could collect during passive or active attacks. This analysis demonstrated a gain in unconditional security, and thus confirmed the security benefit of the additional wiretap encoder, through tight lower bounds (Lemmas 1 and 2 in [452]) and asymptotic values (Theorems 1 and 2 in [452]) of the secret key equivocation. The cost of this enhanced security is only a slight-to-moderate increase in the implementation complexity and the communications overhead. However, it also revealed that if the same secret key is used for too long, the adversary may gather large enough samples for offline cryptanalysis. The uncertainty then decreases to zero. Then starts a regime in which a computational security analysis is needed to estimate the resistance against secret key recovery, which motivated the current paper.
Computational Complexity Security
Mihaljević and Oggier [420] presents a security evaluation of the considered technique in a chosen plaintext attack scenario, which shows that the computational complexity security is lower bounded by the related LPN (Learning from Parity with Noise) complexity in both the average and worst cases. This gives guidelines for constructing a dedicated homophonic encoder which maximizes the complexity of the underlying LPN problem for a given encoding overhead.
Note
Recall that in a chosen plaintext attack (CPA) scenario, the claim that a scheme is secure in an information-theoretic sense means that even an attacker with unlimited resources for recovering the secret key, in the considered evaluation scenario, faces complete uncertainty about the secret key employed for encryption, i.e., a set of equally probable candidates for the true secret key will exist. On the other hand, a claim that an encryption scheme is secure in a computational-complexity sense means the following: Although the secret-key could be recovered in a CPA scenario, and so it is not possible to claim information-theoretic security, the computational complexity of this recovery is as hard as solving a problem which belongs to a class of proven hard problems, as the LPN problem is.
5 Conclusion and Future Directions
We have presented some advances in the design and security evaluations of some contemporary symmetric encryption techniques which provide a good trade-off between the implementation/execution complexity and the required security.
In one direction, we have demonstrated the use of keystream generators with keyed update functions to provide the same security level at much smaller hardware area costs. In particular, we have shown that the security limitations which were believed to be imposed by the size of the state can be improved to offer a much better trade-off between hardware requirements and security. In the other direction, we have described the use of homophonic encoding for security enhancement of certain randomized symmetric encryption schemes.
Also, we have discussed certain generic approaches for security evaluation of the considered encryption schemes. The encryption schemes based on keyed update functions were evaluated against a dedicated guess-and-determine attack. The randomized encryption schemes were evaluated based on generic information-theoretic and computational-complexity approaches. We believe that there is plenty of room for further work in this area, and other innovative schemes should be investigated. We have found that employment of keyed update functions and results from coding theory are particularly promising ideas for the design of advanced encryption schemes and we plan to explore them further in the near future.
References
Martin Ågren, Martin Hell, Thomas Johansson, and Willi Meier. Grain-128a: a new version of Grain-128 with optional authentication. International Journal of Wireless and Mobile Computing, 5(1):48–59, 2011.
Frederik Armknecht and Vasily Mikhalev. On lightweight stream ciphers with shorter internal states. In Gregor Leander, editor, Fast Software Encryption – FSE 2015, volume 9054 of Lecture Notes in Computer Science, pages 451–470, Istanbul, Turkey, March 8–11, 2015. Springer.
Steve Babbage. Improved “exhaustive search” attacks on stream ciphers. In European Convention on Security and Detection, pages 161–166. IET, May 1995.
Subhadeep Banik. Some results on Sprout. In INDOCRYPT 2015, volume 9462 of LNCS, pages 124–139. Springer, 2015.
Alex Biryukov and Adi Shamir. Cryptanalytic time/memory/data tradeoffs for stream ciphers. In Tatsuaki Okamoto, editor, Advances in Cryptology – ASIACRYPT 2000, volume 1976 of Lecture Notes in Computer Science, pages 1–13, Kyoto, Japan, December 3–7, 2000. Springer.
İmran Ergüler and Orhun Kara. A new approach to keystream based cryptosystems. In SASC 2008, Workshop Record,, pages 205–221. SASC, 2008.
Muhammed F. Esgin and Orhun Kara. Practical cryptanalysis of full Sprout with TMD tradeoff attacks. In Selected Areas in Cryptography - SAC 2015, pages 67–85, 2015.
Henri Gilbert, Matthew JB Robshaw, and Yannick Seurin. How to encrypt with the LPN problem. In International Colloquium on Automata, Languages, and Programming, pages 679–690. Springer, 2008.
Jovan Dj. Golíc. Cryptanalysis of alleged A5 stream cipher. In Walter Fumy, editor, Advances in Cryptology – EUROCRYPT 97, volume 1233 of Lecture Notes in Computer Science, pages 239–255. Springer, 1997.
Christoph G Günther. A universal algorithm for homophonic coding. In Workshop on the Theory and Application of of Cryptographic Techniques, pages 405–414. Springer, 1988.
Martin Hell, Thomas Johansson, Alexander Maximov, and Willi Meier. The grain family of stream ciphers. In New Stream Cipher Designs, pages 179–190. Springer, 2008.
Orhun Kara, İmran Ergüler, and Emin Anarim. A new security relation between information rate and state size of a keystream generator. Turkish Journal of Electrical Engineering & Computer Sciences, 24(3):1916–1929, 2016.
Orhun Kara and Muhammed F. Esgin. On analysis of lightweight stream ciphers with keyed update. IEEE Trans. Computers, 68(1):99–110, 2019.
Yahya S Khiabani and Shuangqing Wei. A joint shannon cipher and privacy amplification approach to attaining exponentially decaying information leakage. Information Sciences, 357:6–22, 2016.
Yahya S Khiabani, Shuangqing Wei, Jian Yuan, and Jian Wang. Enhancement of secrecy of block ciphered systems by deliberate noise. IEEE Transactions on Information Forensics and Security, 7(5):1604–1613, 2012.
Virginie Lallemand and María Naya-Plasencia. Cryptanalysis of full Sprout. In Advances in Cryptology – CRYPTO 2015, volume 9215 of LNCS, pages 663–682. Springer, 2015.
Subhamoy Maitra, Santanu Sarkar, Anubhab Baksi, and Pramit Dey. Key recovery from state information of Sprout: Application to cryptanalysis and fault attack. Cryptology ePrint Archive, Report 2015/236.
James L Massey. Some applications of source coding in cryptography. Transactions on Emerging Telecommunications Technologies, 5(4):421–430, 1994.
Miodrag J Mihaljevic. A framework for stream ciphers based on pseudorandomness, randomness and coding. In Enhancing Cryptographic Primitives with Techniques from Error Correcting Codes, pages 117–139. IOS Press, Amsterdam, The Netherlands, 2009.
Miodrag J Mihaljević. An approach for light-weight encryption employing dedicated coding. In Global Communications Conference, 2012 IEEE, pages 874–880. IEEE, 2012.
Miodrag J Mihaljević and Hideki Imai. An approach for stream ciphers design based on joint computing over random and secret data. Computing, 85(1–2):153–168, 2009.
Miodrag J Mihaljević and Hideki Imai. Employment of homophonic coding for improvement of certain encryption approaches based on the lpn problem. In Symmetric Key Encryption Workshop, SKEW, pages 16–17, 2011.
Miodrag J Mihaljević and Frédérique Oggier. Security evaluation and design elements for a class of randomised encryptions. IET Information Security, 13(1):36–47, 2019.
Vasily Mikhalev, Frederik Armknecht, and Christian Müller. On ciphers that continuously access the non-volatile key. IACR Transactions on Symmetric Cryptology, 2016(2):52–79, 2016. http://tosc.iacr.org/index.php/ToSC/article/view/565.
Vasily Mikhalev, Frederik Armknecht, and Christian Müller. On ciphers that continuously access the non-volatile key. IACR Transactions on Symmetric Cryptology, 2016(2):52–79, 2017.
Frédérique Oggier and Miodrag J Mihaljević. An information-theoretic security evaluation of a class of randomized encryption schemes. IEEE Transactions on Information Forensics and Security, 9(2):158–168, 2014.
Ronald L Rivest and Alan T Sherman. Randomized encryption techniques. In Advances in Cryptology, pages 145–163. Springer, 1983.
Jian Wang, Jiaqi Mu, Shuangqing Wei, Chunxiao Jiang, and Norman C Beaulieu. Statistical characterization of decryption errors in block-ciphered systems. IEEE Transactions on Communications, 63(11):4363–4376, 2015.
Shuangqing Wei, Jian Wang, Ruming Yin, and Jian Yuan. Trade-off between security and performance in block ciphered systems with erroneous ciphertexts. IEEE Transactions on Information Forensics and Security, 8(4):636–645, 2013.
Bin Zhang and Xinxin Gong. Another tradeoff attack on Sprout-like stream ciphers. In ASIACRYPT 2015, volume 9453 of LNCS, pages 561–585. Springer, 2015.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2021 The Author(s)
About this chapter

Cite this chapter
Mikhalev, V., Mihaljević, M.J., Kara, O., Armknecht, F. (2021). Selected Design and Analysis Techniques for Contemporary Symmetric Encryption. In: Avoine, G., Hernandez-Castro, J. (eds) Security of Ubiquitous Computing Systems. Springer, Cham. https://doi.org/10.1007/978-3-030-10591-4_3
Download citation
DOI: https://doi.org/10.1007/978-3-030-10591-4_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-10590-7
Online ISBN: 978-3-030-10591-4
eBook Packages: Computer ScienceComputer Science (R0)