
Abstract
Seagrass is an important factor to balance marine ecological systems, and there is a great interest in monitoring its distribution in different parts of the world. This paper presents a deep capsule network for classification of seagrass in high-resolution multispectral satellite images. We tested our method on three satellite images of the coastal areas in Florida and obtained better performances than those achieved by the traditional deep convolutional neural network (CNN) model. We also propose a few-shot deep learning strategy to transfer knowledge learned by the capsule network from one location to another for seagrass detection, in which the capsule network’s reconstruction capability is utilized to generate new artificial data for fine-tuning the model at new locations. Our experimental results show that the proposed model achieves superb performances in cross-validation on three satellite images collected in Florida as compared to support vector machine (SVM) and CNN.
This work was realized by a student. This work is supported by NASA under Grant NNX17AH01G and the support of NVIDIA Corporation for the donation of the TESLA K40 GPU used in this research is gratefully acknowledged.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Seagrass detection
- Convolutional neural network
- Capsule network
- Deep learning
- Remote sensing
- Transfer learning
1 Introduction
Seagrass is an important component in coastal ecosystems. It provides food and shelter for fish and marine organisms, protects ecological systems, stabilizes sea bottom, keeps the desired level of water quality and helps local economy [1, 2, 18, 33]. Coastal areas have been significantly impacted over the last decades by activities of nearby inhabitants and coastal visitors. Due to the growing of human population and industrial evolution, the release of waste and polluted water has also increased significantly in the coastal area [1, 2, 18, 33]. These are causing the deterioration of water quality and a decrease in seagrass distribution. Seagrass distribution is also damaged by natural calamities such as typhoons, strong wind, rainfall, aquaculture and human with propeller current [1, 2, 18, 33]. Florida has lost 50% of seagrass between 1880s and 1950s [18]. Therefore, improving water quality to restore seagrass has been a priority during the last few decades.
In this paper, we develop a deep capsule network to detect seagrass in Florida coastal areas based on multispectral satellite images. To generalize a trained seagrass detection model to new locations, we utilize the capsule network as a data augmentation method to generate new artificial data for fine-tuning the model. The main contributions of this paper are:
-
1.
A capsule network was developed for seagrass detection in multispectral satellite images.
-
2.
A few-shot deep learning strategy was implemented for seagrass detection and it may be applicable to other applications.
The paper is structured as follows: Sect. 2 discusses the relevant literature. Section 3 describes the proposed method. Sections 4 and 5 present results and discussions, respectively, and Sect. 6 summarizes the paper.
2 Related Work
2.1 CNN and Transfer Learning
Deep CNN models use multiple processing layers to learn new representations for better recognition and achieved state-of-the-art in many applications including image classification [12, 13], medical imaging [10, 14, 15, 17], speech recognition [8], cybersecurity [5, 20], biomedical signal processing [16] and remote sensing [24]. Transfer learning tries to train a predictive model through adaptation by utilizing common knowledge between source and target data domains [31]. Oquab et al. have used transfer learning with CNN for small data set visual recognition task [22]. Transfer learning has been explored also in computer-aided detection [27], post-traumatic stress disorder diagnosis [4] and face representation [29].
2.2 Capsule Network
Sabour et al. recently proposed the capsule network for image classification [26]. It is more robust to affine transformation and it has been considered a better method than CNN for identifying overlapping digits in MNIST [26]. In 2018, the same group improved the capsule network with matrix capsules and the expectation maximization algorithm was used for dynamic routing [9]. The improved model achieved state-of-the-art performance on the smallNORB data set [9]. Capsule network has also been used in breast cancer detection [11], brain tumor type classification [3]. For highly complex data sets such as CIFAR10, capsule network has not achieved good performances [32].
2.3 Seagrass Detection
WorldView-2 multispectral images have been used for shallow-water Benthic identification [19]. Pasqualinia et al. have found the overall accuracies between 73% and 96% for identifying four classes: sand, photo-philous algae on rock, patchy seagrass beds and continuous seagrass beds, with two spatial resolutions of 2.5 m and 10 m [23]. Vela et al. used fused image of SPOT-5 and IKONOS in southern Tunisia near the Libyan border to detect four classes including low seagrass cover, high seagrass cover, superficial mobile sediments and deep mobile sediments [30]. For the lagoon environment mapping, they have obtained 83.25% accuracy over the entire area and 85.91% accuracy over the testing area with SPOT-5 images, and 73.41% accuracy over the testing area with IKONOS images [30]. Dahdough-Guebas et al. combined red, green, blue of visible bands with near infra-red band for seagrass and algae detection [6]. Oguslu et al. used sparse coding method for sea-grass’s propeller scar detection in WorldView-2 satellite images [21].
3 Methods
3.1 Datasets
We collected three multispectral satellite images captured by the WorldView-2 (WV-2) satellite. These images have a wavelength between 400–1100 nm and spatial resolution of 2 m in the 8 visible and near infrared (VNIR) bands. In this study, an experienced operator selected several regions in each of the three images with highest confidence of the labeling. These regions have been identified as blue, cyan, green and yellow boxes, corresponding to sea, sand, seagrass and land respectively (Fig. 1). At Saint Joseph Bay, intertidal class was added and it is represented as white in Fig. 1(a).

Satellite images taken from Saint Joseph Bay (a), Keeton Beach (b) and Saint George Sound (c). The blue, cyan, green, yellow and white boxes correspond to the selected regions belonging to sea, sand, seagrass, land and intertide respectively. (Color figure online)
3.2 Capsule Network
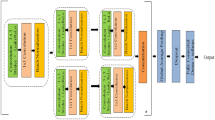
We develop a capsule network for seagrass detection by following the design in [26]. The model has two convolutional layers and 32 convolutional kernels with a size of \(2\,\times \,2\) for extracting high level features. The extracted features are then fed into the capsule layers, in which a weight matrix of \(8\,\times \,16\) is used to find the most similar capsule in the next layer. The last capsule layer, Feature-caps, stores a capsule per class, and each capsule has a total of 16 features. The length of each capsule represents posterior probability for a class. Additionally, the features in Feature-caps are used to reconstruct original images. The reconstruction architecture has 3 fully connected layers with a sigmoid activation function and sizes of the layers are 256, 512 and 200, respectively. Output size of the reconstruction structure is the same as that of input patch (\(5\,\times \,5\,\times \,8\)).
3.3 Transfer Learning
The ultimate goal of this study is to develop a deep learning model that is able to detect seagrass at any location in the world. However, there exists a significantly amount of variations in seagrass representation from different satellite images. To resolve this issue, we propose a transfer learning approach such that only a small number of samples are needed to adapt a trained deep model for predicting seagrass at a new location:
-
1.
Train a capsule network using all the selected data from Saint Joseph Bay.
-
2.
Feed the trained model with few labeled samples from Keeton Beach and extract features from the Feature-caps as new representations for the data.
-
3.
Utilize the new representations to classify the entire Keeton Beach image based on the 1-nearest neighbor (1-NN) rule.
-
4.
Repeat the procedures for the image from Saint George Sound bay.
3.4 Capsule Network as a Generative Model for Data Augmentation
The capsule network has the capability of reconstructing input data from features in Feature-caps. We generate artificial labeled data at new locations to improve model adaptation as follows,
-
1.
Train a capsule network with the selected patches at Saint Joseph Bay and fine-tune the model with a limited number of samples from Keeton Beach.
-
2.
For each of the patches used for fine-tuning the model, extract the 16 corresponding features in the Feature-caps and compute mean (\(\mu _C\)) and standard deviation (\(\sigma _C\)) for each of the 16 features.
-
3.
For each patch from Keeton Beach, generate a total of 176 new artificial patches by varying each of the features 11 times within the range of \([\mu _C-2\sigma _C, \mu _C+2\sigma _C]\).
-
4.
Fine-tune the trained capsule network with these artificial and original patches.
-
5.
Repeat this procedure for 20 iterations and repeat the same procedure for Saint George Sound.
For comparison purposes, we add random noise within the range of \([\mu _C-2\sigma _C, \mu _C+2\sigma _C]\) directly to the patches that are feed to the capsule network and then we extract their features to classify all the patches from Keeton Beach and Saint George Sound using the 1-NN rule.
3.5 Convolutional Neural Network
A similar method is implemented on CNN for comparison purposes. The CNN model has two convolutional layers with a ReLU activation function and 16 \(2\,\times \,2\) and 64 \(4\,\times \,4\) convolutional kernels, respectively. The convolutional layers are followed by one fully connected layer with 16 hidden units and a soft-max layer to perform classification. We utilize the dropout technique with a probability of 0.1 to reduce over-fitting [28].
4 Results
4.1 Model Structure Determination
We have selected Saint Joseph Bay as the primary location to train deep models with the selected regions. To have a fair comparison of the performances between capsule network and CNN, we keep the same number of parameters, 9k, in convolutional layers for both models. In the capsule network, there are 46k parameters for routing and 254k parameters for reconstruction. We train 10 epochs for CNN and 50 epochs for capsule network to roughly keep the same amount of training for both models.
4.2 Cross-Validation Results in Selected Regions
To validate our model, we perform 3-fold cross-validation (CV) in the selected regions for the three locations separately. Table 1 shows the classification accuracies for each satellite image using SVM, CNN and capsule network. Additionally, each model is trained with all the patches from the selected regions and then applied to the corresponding whole image as shown in Fig. 2.
4.3 Transfer Learning
Table 2 shows the classification accuracies in the selected regions by transfer learning with different number of labeled samples (shots) from new locations. Zero shot transfer learning means applying the deep learning model trained at Saint Joseph Bay directly to Keeton Beach and Saint George Sound. It is observed that CNN has better performances in transfer learning.
4.4 Capsule Network as a Generative Model for Data Augmentation
We use the capsule network as a generative model to obtain new training data for model adaptation as described in Sect. 3.4. For comparison purposes, we have identified the following cases:
-
Regular fine-tuning: We fine-tune the capsule network with a small number of labeled samples (shots) from the new locations. After fine-tuning, we use the transfer learning procedures to classify the rest of the patches.
-
Random noise: We add some random noises into the labeled patches to generate artificial patches for transfer learning.
-
Generative fine-tuning: We fine-tune the capsule network with a small number of labeled samples (shots) from the new locations. After fine-tuning, we generated artificial patches as described in Sect. 3.4 and use the transfer learning procedures to classify the rest of the patches.
Table 3 shows the classification accuracies for each of these cases with different number of fine-tuning shots. It can be observed that the best accuracies are obtained using generative fine-tuning for most of the cases.
The results displayed in Table 3 shows the accuracies for only one iteration in generative fine-tuning. To investigate the effect of the number of iteration on the performances, we run the generative fine-tuning method with different number of iterations in 100 shots deep learning and show the results in Table 4, where the accuracies obtained in Keeton Beach and Saint George Sound either with generated data only or combined with the original patches. Additionally, we show the classification maps of each method in Fig. 3. The Figure shows classification maps of one shot and 100 shots by each of the methods previously discussed. In the case of generative fine-tuning, we show the results after 20 iterations with the combination of generated and original data.

Three-fold CV results. From left to right, the classification map by the physics model [7], SVM, CNN and capsule network on Saint Joseph Bay (a), Keeton Beach (b) and Saint George Sound (c). The colors blue, cyan, green, yellow and magenta represent sea, sand, seagrass, land and intertide, respectively. (Color figure online)
4.5 Changes in Feature Orientation
We investigated the feature orientation changes in the Feature-caps layer of the capsule network while using each of the fine tuning methods. Figure 4 shows the average values of the features in Feature-caps after each fine-tuning method. The plots in Fig. 4 are generated through the following steps:
-
1.
For each class in the data set, collect all image patches and extract the feature matrix computed by the Feature-caps layer in the capsule network, which contains 5 capsules (where 5 is the number of classes), each of them with a size of 16 features.
-
2.
Reshape each feature matrix into an 1-dimensional vector in which the first 16 numbers are the features corresponding to the first class, the next 16 are the ones corresponding to the second class and so on. This feature vector has a total size of \(5*16\).
-
3.
Average all the feature vectors belonging to each class and plot them in a 2D graph. Since the probability of an entity belonging to a class is measured by the length of its instantiation parameters (or features), the absolute value of the features belonging to a class should be significantly larger than the rest of the features.

Classification maps by the generative fine-tuning method after 20 iterations at Keeton Beach (a, b, c) and Saint George Sound (d, e, f) with 0 shot (left) and 100 shots (right). The colors blue, cyan, green and yellow represent the patches classified as sea, sand, seagrass and land, respectively. (Color figure online)

Features orientation in feature-caps at Saint George Sound.
5 Discussion
For cross validation results in Table 1, SVM, CNN and capsule network perform better at Saint Joseph Bay location than at Keeton Beach and Saint George Sound. These results justify the reason behind the selection of Saint Joseph Bay as the primary location in the experiment of transfer learning. Capsule network outperforms SVM at all the three locations and CNN for two locations. In Fig. 2, the sea class is misclassified as sand in Keeton Beach and ST George Sound by SVM as compared to the physics based approach.
CNN and capsule network have lower accuracies at Keeton Beach and St George Sound in zero shot and one shot learning. Model trained at Saint Joseph Bay performed poorly at other two locations because of the variations of class orientation as shown in Fig. 4. One shot transfer learning is not enough to represent the entire orientation changes at different locations. However, with the increase of number of samples/shots, the classification accuracies were significantly improved (Table 2). In Table 3 and Fig. 3, we have compared the generative fine-tuning approach with regular fine-tuning and random noise approaches. Random noises may not be related to original data and its performances were worse than the generative fine-tuning approach.
In Fig. 4, we have evaluated how the capsule’s features are changing in different steps. In ideal situation if one of the classes is used as input, the capsule representing that class should have higher feature values. For example, in Fig. 4(a), the first 16 features should be large because sea patches were used as input. However, the second 16 features are large because of the location variations between Saint Joseph Bay and Saint George Sound as shown in Fig. 4(a). Because Saint George Sound’s sea sample (the first 16 features) is similar to sand sample (the second 16 features) at Saint Joseph Bay. Likewise, seagrass class and Land class of Saint George Sound are similar to sand and inter-tide class of Saint Joseph Bay respectively. Sand class samples are similar at both locations. The capsule feature’s orientations also explain the poor zero shot results using capsule-network. After fine-tuning the network with generative fine-tuning approach for 20 iterations, we can see that this capsule features are representing correct classes (Fig. 4(c)).
We have achieved the best accuracy of 99.16% and 99.67% in Keeton Beach and Saint George Sound location after 20 iterations in generative fine-tuning. Comparing Table 4 with Table 2, the accuracy is either comparable (99.16% vs. 99.75%) or better (99.67% vs. 98.76%) at both locations in transfer learning by CNN. Using generated data only for 1-NN rule, the best accuracy we have achieved are 93.00% and 93.34% in Keeton Beach and Saint George Sound. If we compare the end to end classification map in Figs. 2 and 3, generative fine-tuning approach has produced the best results for both locations. In our companion paper [25], we studied seagrass quantification after identification.
6 Conclusion
To the best of our knowledge, this study represents the first work of designing a capsule network for seagrass detection. We have achieved better classification accuracy than the baseline models (CNN and SVM) in 3-fold CV. Transfer learning proved to be a good technique to address the problem of model adaptation. In addition, our generative model is able to increase the classifier performance by iteratively generating new data from the capsule’s features. Using this method, we obtained accuracies of 99.16% and 99.67% at Keeton Beach and Saint George Sound, respectively. When we only used the generated data, we achieved accuracies of 93.00% and 93.34% at the two new locations, respectively, proving the similarity between the original samples and generated samples.
We also demonstrated the effectiveness of our method through a set of 2D plots that are able to display the capsule features. Since magnitudes of the capsule features determine probabilities of classes, the plots are able to visually assess performance of a trained capsule network in a significantly simple manner. To the best of our knowledge, we are the first to offer this visualization tool for the evaluation of capsule network’s performance.
References
Floridadep: Florida coastal office. https://floridadep.gov/fco. Accessed 20 Oct 2017
MyFWC: Florida fish and wildlife conservation commission. http://myfwc.com/research/habitat/seagrasses/information/importance/. Accessed 20 Oct 2017
Afshar, P., Mohammadi, A., Plataniotis, K.N.: Brain tumor type classification via capsule networks. arXiv preprint arXiv:1802.10200 (2018)
Banerjee, D., et al.: A deep transfer learning approach for improved post-traumatic stress disorder diagnosis. In: 2017 IEEE International Conference on Data Mining (ICDM), pp. 11–20. IEEE (2017)
Chowdhury, M.M.U., Hammond, F., Konowicz, G., Xin, C., Wu, H., Li, J.: A few-shot deep learning approach for improved intrusion detection. In: IEEE 8th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), 2017, pp. 456–462. IEEE (2017)
Dahdouh-Guebas, F., Coppejans, E., Van Speybroeck, D.: Remote sensing and zonation of seagrasses and algae along the Kenyan coast. Hydrobiologia 400, 63–73 (1999)
Hill, V.J., Zimmerman, R.C., Bissett, W.P., Dierssen, H., Kohler, D.D.: Evaluating light availability, seagrass biomass, and productivity using hyperspectral airborne remote sensing in Saint Josephs Bay, Florida. Estuaries Coasts 37(6), 1467–1489 (2014)
Hinton, G., et al.: Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups. IEEE Signal Process. Mag. 29(6), 82–97 (2012)
Hinton, G., Frosst, N., Sabour, S.: Matrix capsules with EM routing (2018)
Ibanez, D.P., Li, J., Shen, Y., Dayanghirang, J., Wang, S., Zheng, Z.: Deep learning for pulmonary nodule CT image retrievalâan online assistance system for novice radiologists. In: 2017 IEEE International Conference on Data Mining Workshops (ICDMW), pp. 1112–1121. IEEE (2017)
Iesmantas, T., Alzbutas, R.: Convolutional capsule network for classification of breast cancer histology images. arXiv preprint arXiv:1804.08376 (2018)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: Advances in Neural Information Processing Systems, pp. 1097–1105 (2012)
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature 521(7553), 436 (2015)
Li, F., Tran, L., Thung, K.-H., Ji, S., Shen, D., Li, J.: Robust deep learning for improved classification of AD/MCI patients. In: Wu, G., Zhang, D., Zhou, L. (eds.) MLMI 2014. LNCS, vol. 8679, pp. 240–247. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10581-9_30
Li, F., Tran, L., Thung, K.H., Ji, S., Shen, D., Li, J.: A robust deep model for improved classification of AD/MCI patients. IEEE J. Biomed. Health Inform. 19(5), 1610–1616 (2015)
Li, F., et al.: Deep models for engagement assessment with scarce label information. IEEE Trans. Hum.-Mach. Syst. 47(4), 598–605 (2017)
Li, R., et al.: Deep learning based imaging data completion for improved brain disease diagnosis. In: Golland, P., Hata, N., Barillot, C., Hornegger, J., Howe, R. (eds.) MICCAI 2014. LNCS, vol. 8675, pp. 305–312. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10443-0_39
Li, R., Liu, J.K., Sukcharoenpong, A., Yuan, J., Zhu, H., Zhang, S.: A systematic approach toward detection of seagrass patches from hyperspectral imagery. Mar. Geodesy 35(3), 271–286 (2012)
Manessa, M.D.M., Kanno, A., Sekine, M., Ampou, E.E., Widagti, N., As-syakur, A.R.: Shallow-water benthic identification using multispectral satellite imagery: investigation on the effects of improving noise correction method and spectral cover. Remote Sens. 6(5), 4454–4472 (2014)
Ning, R., Wang, C., Xin, C., Li, J., Wu, H.: DeepMag: sniffing mobile apps in magnetic field through deep convolutional neural networks. In: 2018 IEEE International Conference on Pervasive Computing and Communications (PerCom), pp. 1–10. IEEE (2018)
Oguslu, E., et al.: Detection of seagrass scars using sparse coding and morphological filter. Remote Sens. Environ. 213, 92–103 (2018)
Oquab, M., Bottou, L., Laptev, I., Sivic, J.: Learning and transferring mid-level image representations using convolutional neural networks. In: 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1717–1724. IEEE (2014)
Pasqualini, V., et al.: Use of spot 5 for mapping seagrasses: an application to posidonia oceanica. Remote Sens. Environ. 94(1), 39–45 (2005)
Perez, D., et al.: Deep learning for effective detection of excavated soil related to illegal tunnel activities. In: 2017 IEEE 8th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), pp. 626–632. IEEE (2017)
Perez, D., Islam, K.A., Schaeffer, B., Zimmerman, R., Hill, V., Li, J.: Deepcoast: Quantifying seagrass distribution in coastal water through deep capsule networks. In: Lai, J.-H., et al. (eds.) The First Chinese Conference on Pattern Recognition and Computer Vision, PRCV 2018. LNCS, vol. 11257, pp. 404–416. Springer, Heidelberg (2018)
Sabour, S., Frosst, N., Hinton, G.E.: Dynamic routing between capsules, pp. 3859–3869 (2017)
Shin, H.C., et al.: Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 35(5), 1285–1298 (2016)
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15(1), 1929–1958 (2014)
Sun, Y., Wang, X., Tang, X.: Deep learning face representation from predicting 10,000 classes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1891–1898 (2014)
Vela, A., et al.: Use of spot 5 and ikonos satellites for mapping biocenoses in a tunisian lagoon (2005)
Weiss, K.R., Khoshgoftaar, T.M.: An investigation of transfer learning and traditional machine learning algorithms. In: 2016 IEEE 28th International Conference on Tools with Artificial Intelligence (ICTAI), pp. 283–290. IEEE (2016)
Xi, E., Bing, S., Jin, Y.: Capsule network performance on complex data. arXiv preprint arXiv:1712.03480 (2017)
Yang, D., Yang, C.: Detection of seagrass distribution changes from 1991 to 2006 in xincun bay, hainan, with satellite remote sensing. Sensors 9(2), 830–844 (2009)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Islam, K.A., Pérez, D., Hill, V., Schaeffer, B., Zimmerman, R., Li, J. (2018). Seagrass Detection in Coastal Water Through Deep Capsule Networks. In: Lai, JH., et al. Pattern Recognition and Computer Vision. PRCV 2018. Lecture Notes in Computer Science(), vol 11257. Springer, Cham. https://doi.org/10.1007/978-3-030-03335-4_28
Download citation
DOI: https://doi.org/10.1007/978-3-030-03335-4_28
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-03334-7
Online ISBN: 978-3-030-03335-4
eBook Packages: Computer ScienceComputer Science (R0)