
Abstract
Robotic surgery has been proven to offer clear advantages during surgical procedures, however, one of the major limitations is obtaining haptic feedback. Since it is often challenging to devise a hardware solution with accurate force feedback, we propose the use of “visual cues” to infer forces from tissue deformation. Endoscopic video is a passive sensor that is freely available, in the sense that any minimally-invasive procedure already utilizes it. To this end, we employ deep learning to infer forces from video as an attractive low-cost and accurate alternative to typically complex and expensive hardware solutions. First, we demonstrate our approach in a phantom setting using the da Vinci Surgical System affixed with an OptoForce sensor. Second, we then validate our method on an ex vivo liver organ. Our method results in a mean absolute error of 0.814 N in the ex vivo study, suggesting that it may be a promising alternative to hardware based surgical force feedback in endoscopic procedures.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

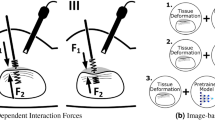

1 Introduction
Robot-assisted clinical systems have been increasingly adopted due to their advantages during surgical procedures. However, obtaining haptic feedback of a teleoperated surgical system still constitutes a hard problem due to practical challenges such as control loop stability. In the current version of the da Vinci Surgical System [1] (Intuitive Surgical, Inc., Sunnyvale, CA, USA), there is no haptic technology and no feedback on the grip forces. Surgeons depend on visual cues to infer the forces to avoid damage to tools and anatomy since excessive mechanical force can lead to the breakage of an end-effector string, serious artery or nerve injury, and even post-operation trauma [2]. As a result, there is a critical need to design force sensing systems in the field of surgical robotics.
Recently, many researchers have focused their efforts on solutions to this problem. For instance, numerous tactile sensing devices have been developed to estimate tactile information during static (point based) measurements, including indentation-based contact devices, aspiration devices, optical fiber devices, and non-contact devices [3]. Such devices are capable of providing accurate tactile information during static measurements of a single point, but they cannot scan soft tissue in a dynamic way, which is not a real-time solution [4]. Another area of investigation is directed towards using a torque sensor to model and compensate for grip force. This may provide a consistent internal force compensation based on the quantitative model, but it largely relies on the surgeon’s skills and experience [2]. In addition, most of these hardware-based solutions have delicate and expensive components, which often cannot withstand sterilization.
Vision based approaches are one way to overcome above limitations of hardware solutions. Starting from [5], computer vision has been used to measure the deformed object and recover the applied force from linear elasticity equations. Recent advances in deep learning bring opportunities to such vision based force prediction in real surgical scenarios [6,7,8,9]. For example, researchers in [6] extract the 3D deformable structure of the heart and use a neural network with the architecture of LSTM-RNN to predict the applied force.
In this paper, we propose a vision-based surgical force prediction model called RGB-Point Cloud Temporal Convolutional Network (RPC-TCN). The model is based on a spatial block that encodes information at individual time-steps from a video and a temporal block to reason over sequences of observations. The spatial block combines 2D features (e.g., from an RGB image) and 3D features (e.g., from a 3D point cloud) for a given time, while the temporal block makes use of multiple static features via the Temporal Convolutional Network [10] (TCN) to model force change over time. To better abstract the core feature, we apply a pre-trained VGG16 image model [11] along with a pre-trained 3D point cloud-based architecture called PointNet [12] to extract features from raw visual data and then concatenate these two features to train a TCN time-series model. We evaluate our approach on internally-collected da Vinci surgical video, and show that our model produces highly accurate results. Figure 1 shows representative test result on an ex vivo liver.

Results of the ex vivo liver study: (A) Test result w.r.t time sequence. The blue line represents the reference standard force and the red curve are the model predictions. (B) A set of screenshots of the RGB image and their reference standard force and error. (Color figure online)
Related Work. Much work has focused on modeling tissue deformation during force prediction, since for reasonably soft material the applied force is positively correlated to the deformation of the tissue surface [6, 8, 13]. Therefore, accurately measuring surface deformation in 3D is vitally important for vision-based force estimation. Furthermore, depth data can then be converted to 3D point cloud. The recently proposed PointNet [12] directly works on 3D unordered point cloud data, which essentially breaks the pixel order limit of the 2D depth image. The unordered point cloud is robust to camera view points and invariant to transformations, which brings the potential ability to generalize to different objects.
In prior work, Temporal Convolutional Networks (TCN) have been proposed to improve video-based analysis models [10]. The input feature vector is the latent encoding of a spatial CNN which corresponds to each frame of the video sequence. Here, we define an observation window which has n frames backward and forward, centered at the current time-step t. The label for each window is the force at time t, which corresponds to the middle vector in this window. The intuition behind utilizing a time-series model lies with the observation that anatomical surfaces are often deforming continuously. It is then reasonable to introduce time-varying features to determine these forces.
In this paper, our RPC-TCN coalesces the above mentioned features to fully grasp the vision-based properties and then make the force prediction.
2 Methodology
2.1 Dataset Collection
Since there is no open source dataset for this task, we conduct experiments both in a phantom study and ex vivo study to generate our internal dataset. Figure 2 presents the setup details.
To collect force data, we fix the OptoForce 3D Force Sensor underneath the phantom object to record force data. The sensor measures the force a robotic tool applies to the phantom rather than the force at the tool tip itself. The force sensor is accurate up to \({12.5\,\times \,10^{-3}}\,\mathrm{N}\) and collects 3D force observations (including x, y, and z in the force sensor coordinate). We only use the z-component, which is perpendicular to the planar surface the specimen is placed upon. It will automatically re-bias each time we place an object.
RGB images and depth images are collected using a Kinect2 RGB+D camera. This setup is convenient to demonstrate feasibility of the proposed fusion of RGB images and point clouds for force prediction. In a clinical scenario, a dedicated depth camera is not yet available. However, previous research has validated a learning-based method to estimate dense depth images and surface normal maps from endoscopic surgical video, which results in high-resolution spatial 3D reconstructions to an average error of 0.53 mm to 1.12 mm [14]. Based on this result, obtaining 3D point cloud and depth information from endoscopic video is realistically achievable.

(A) The experimental environment. (B) The depth image from the Kinect2 camera. (C) The phantom used in the experiment. The force sensor is placed under the phantom. (D) RGB image of the phantom. (E) A fresh piece of pig liver. (F) RGB image of the liver.
The object is fixed in the working area of a standard dual arm da Vinci system [1]. As the image stream flows at 30 fps, the RGB data, depth data, and force data are synchronized to be within 10 ms. The Kinect2 RGB+D camera is placed at four different positions to collect multiple points of view to test against model overfitting.
2.2 RPC-TCN
Spatial Block. Figure 3 shows the overall structure of our RPC-TCN. We use \(X_{RGB}\in \mathbb {R}^{224\times 224}\) and \(X_{D}\in \mathbb {R}^{151\times 151}\) to denote RGB image and depth image. The pre-trained VGG16 network has shown good performance at localization and classification tasks [11]. In our task, we assume that the movement of the da Vinci tool and the feature change of the phantom is relevant for the force prediction. Thus, we choose to fine tune the pre-trained VGG Network from the ImageNet dataset for later regression. The output feature comes from the 2nd classifier layer, which contains more representative variants than the last layer, such that \(X_{VGG}\in \mathbb {R}^{4096}\). Depth image \(X_{D}\) is converted to point cloud data in the depth camera’s coordinate system.
Depth Image to Point Cloud. In the following formula, \({x}_{D}\) and \({y}_{D}\) refer to the coordinate pixel index in the depth image, and \({z}_{D}\) is its depth value. \(\bar{x}_{D}\), \(\bar{y}_{D}\), and \(\bar{z}_{D}\) refer to the mean values. \({c}_{x}\), \({c}_{y}\) and \({f}_{x}\), \({f}_{y}\) are the intrinsic parameters of principal point and focal length of the depth camera. We use the maximum length in depth image to normalize the point cloud into a unit sphere. The normalized coordinates are
In order to fit the input vector size of the PointNet, the original point cloud is uniformly downsampled from 22801 to 2048 points. Next, we fine tune the pre-trained PointNet to select the feature from the second-to-last layer, \(X_{ptnet}\in \mathbb {R}^{512}\). Finally, we concatenate these two features to a larger one, \(X_{cat}=[X_{VGG},X_{ptnet}]\in \mathbb {R}^{4608}\).

The basic architecture of RPC-TCN. The spatial block extracts features from the pre-trained VGG net and PointNet and concatenates two features. The temporal block expands this feature to be 15 frames in a window and predict the force corresponding to the middle frame.
Temporal Block. Figure 4 presents the hierarchical structure of the temporal block. Here, we denote the concatenated feature \(X_{cat}\) with respect to time as \(X_{cat,t}\), then \(\bar{X}_{cat,t} = [X_{cat,t-n}, \ldots , X_{cat,t-1}, X_{cat,t}, X_{cat,t+1}, \ldots , X_{cat,t+n}]\). We define the collection of filters in each convolutional layer as \(W = \left\{ W^{(i)}\right\} _{i=1}^{F_{l}}\) for \(W^{(i)}\in \mathbb {R}^{d \times F_{l-1}}\) with a corresponding bias vector \(b\in \mathbb {R}^{F_{l}}\), where \(l\in \left\{ 1,\ldots ,L\right\} \) is the layer index. Given the signal from the previous layer, \(E^{(l-1)}\), we compute activations \(E^{(l)}\) with
where \(f(\cdot )\) is a non-linear activation function and \(*\) is the convolution operator. We also perform batch normalization after each convolutional layer. We compare different activation functions and find that the Rectified Linear Units (ReLU) perform best in our experiments. Finally, we use a linear regression at the last fully-connected layer to predict the force, \(\hat{Y}_{t}\in \mathbb {R}\). We define U as the filter for the last linear layer L and c as the bias. The process is

Hierarchical structure of the temporal block.
3 Experiment and Result
3.1 Experimental Setting and Dataset
In total, we obtain 61,473 samples in our phantom study and 44,413 samples in our ex vivo liver study. The training data is randomly split to 80% of the full dataset and 5% for validation, 15% for test in both experiments (e.g., the phantom and ex vivo were trained and tested separately). The loss function is Mean Squared Error (MSE) and the learning rate is initialized to be \({1\times 10^{-5}}\) and multiplied by 0.1 every 1000 epochs.
To test the power of the proposed algorithm, we compare to multiple algorithms in both the phantom and ex vivo study. We first conduct experiments on traditional single-frame based methods on the RGB images, called Single-frame RGB. In this setup, we use the same VGG16 network to abstract the feature and then construct a convolutional neural network to perform regression. Then we compare the temporal methods, RGB-TCN and Point Cloud-TCN. In these experiments, the features from the spatial block are the same as discussed before, but we test the performance by separately passing them to the same TCN structure. We finally test on the RPC-TCN.
3.2 Results and Analysis
Table 1 displays the prediction accuracy of various algorithms as a comparison on the same dataset. The percentage error is based on the maximum force magnitude in the dataset, which is −239 N for the phantom study and −190 N for the ex vivo liver study. The single-frame RGB is worse than the TCN type methods, which supports the hypothesis that the time-scaled feature is critical to force prediction. Compared to the other two TCN methods, our RPC-TCN presents the best mean absolute error result with 1.45 N, corresponding to 0.604% for the phantom study and 0.814 N, corresponding to 0.427% for the ex vivo liver study.

(A), (B) Illustration of the correlation matrix between reference standard force and the prediction force. (C), (D) Test Error trend with training epochs. The error is calculated as mean absolute error of all test data.
Figure 5(A) and (B) displays a correlation plot of our RPC-TCN result. The correlation coefficient is 0.995 and 0.996 for our predictions on the phantom and liver data, respectively, implying a strong relationship between the prediction and the reference standard data. From the test error trend in Fig. 5(C) and (D), we find that the single RGB image method presents much higher error, which indicates overfitting. All three TCN based methods can converge to a relatively low test error, while the PC-TCN and the RGB-TCN perform similarly well, but are outperformed by the proposed RPC-TCN suggesting that the use of information from multiple sources is indeed beneficial for vision-based force prediction.
To better understand the error distribution, we divide the force magnitude into 7 bins, each of which spans a 20 N force interval. Figure 6(A) and (B) show the phantom study result. We calculate the mean absolute error and the standard deviation error in each bin and plot them as comparison. Compared to the Point Cloud-TCN and the RPC-TCN, RGB-TCN shows smaller error in lower force, but it has large error and variation when the force becomes large. This comparison indicates that the RGB-TCN is good at predicting small forces, but it does not perform well for large force prediction.

(A) Illustration of mean absolute error distribution w.r.t 7 bins. (B) Illustration of standard deviation error distribution w.r.t 7 bins.
One of the reasons to this phenomenon is that the training data is biased in force distribution. There are more training samples for smaller forces. A more uniformly-distributed dataset will improve large force prediction. The Point Cloud-TCN shows higher error in low forces, but its prediction error is more uniformly distributed. The reason that Point Cloud-TCN is more steady than RGB-TCN is that features of 3D point cloud are more directly related to deformation than 2D features. This Point Cloud-TCN experiment also shows that only with 3D data, our model achieves good performance, validating the power of depth data. Our proposed RPC-TCN takes advantage of these two information and presents a more consistent error distribution trend regardless of absolute scale.
The ex vivo liver study is much closer to a human-organ application compared to the phantom study. Our model still reaches a low error when training and testing in this real organ scenario. We intentionally test large force magnitudes that could cause damage to tissues to be able to predict the onset of excessively large force and, thus, warn clinicians. Training and testing images include specularities, which improves the generalization ability to different surgical scenarios.
Our current model does not evaluate the transferability to different organs. Current results are reached by training and testing on one single phantom and ex vivo liver. We assume the liver properties are similar across different sources, but it still indicates a degree of overfitting to such object. Future study will include testing on multiple organs and considering tissue biomechanical properties. The Kinect camera and OptoForce are convenient tools to demonstrate feasibility of vision-based force estimation. The objects in our experiments are overall flat and thin, which enable the underneath force sensor to measure the applied force change, but the soft tissues are still absorbing part of the touch force. Going forward, however, we will consider setups that are more realistic regarding clinical practice. This includes monocular depth estimation from RGB endoscopic video as in [14] and slave-side force sensors to accurately measure tool tip contact force. These must be carefully designed as obtaining ground truth forces in vivo is non-trivial.
4 Conclusion
In this paper, we discuss a proof-of-principle system to infer forces during surgical activity from RGB+D video. We propose a convolutional neural network called RGB-Point Cloud TCN (RPC-TCN). This network combines the information from traditional RGB+D images obtained from dense depth imagery, and time series analysis for surgical force prediction in a robotic surgical system. Phantom and ex vivo liver experiments yield a mean prediction error to 0.814 N. Our results on this proof-of-principle prototype are promising and encourage further research on 3D sensing in endoscopy to realize the proposed force sensing approach in clinical practice.
References
DiMaio, S., Hanuschik, M., Kreaden, U.: The da Vinci surgical system. In: Rosen, J., Hannaford, R. (eds.) Surgical Robotics, pp. 199–217. Springer, Boston (2011). https://doi.org/10.1007/978-1-4419-1126-1_9
Lee, C., et al.: A grip force model for the da Vinci end-effector to predict a compensation force. Med. Biol. Eng. Comput. 53(3), 253–261 (2015)
Konstantinova, J., Jiang, A., Althoefer, K., Dasgupta, P., Nanayakkara, T.: Implementation of tactile sensing for palpation in robot-assisted minimally invasive surgery: a review. IEEE Sens. J. 14(8), 2490–2501 (2014)
McKinley, S., et al.: A single-use haptic palpation probe for locating subcutaneous blood vessels in robot-assisted minimally invasive surgery. In: 2015 IEEE International Conference on Automation Science and Engineering (CASE), pp. 1151–1158. IEEE (2015)
Greminger, M.A., Nelson, B.J.: Vision-based force measurement. IEEE Trans. Pattern Anal. Mach. Intell. 26(3), 290–298 (2004)
Aviles, A.I., Alsaleh, S.M., Hahn, J.K., Casals, A.: Towards retrieving force feedback in robotic-assisted surgery: a supervised neuro-recurrent-vision approach. IEEE Trans. Haptics 10(3), 431–443 (2017)
Karimirad, F., Chauhan, S., Shirinzadeh, B.: Vision-based force measurement using neural networks for biological cell microinjection. J. Biomech. 47(5), 1157–1163 (2014)
Aviles, A.I., Alsaleh, S.M., Sobrevilla, P., Casals, A.: Force-feedback sensory substitution using supervised recurrent learning for robotic-assisted surgery. In: 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pp. 1–4. IEEE (2015)
Gessert, N., Beringhoff, J., Otte, C., Schlaefer, A.: Force estimation from OCT volumes using 3D CNNs. Int. J. Comput. Assist. Radiol. Surg., 1–10 (2018)
Lea, C., Vidal, R., Reiter, A., Hager, G.D.: Temporal convolutional networks: a unified approach to action segmentation. In: Hua, G., Jégou, H. (eds.) ECCV 2016. LNCS, vol. 9915, pp. 47–54. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-49409-8_7
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of Computer Vision and Pattern Recognition (CVPR), vol. 1(2), p. 4. IEEE (2017)
Aviles, A.I., Alsaleh, S.M., Casals, A.: Sight to touch: 3D diffeomorphic deformation recovery with mixture components for perceiving forces in robotic-assisted surgery. In: 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 160–165. IEEE (2017)
Reiter, A., Léonard, S., Sinha, A., Ishii, M., Taylor, R.H., Hager, G.D.: Endoscopic-CT: learning-based photometric reconstruction for endoscopic sinus surgery. In: Medical Imaging 2016: Image Processing. vol. 9784, p. 978418. International Society for Optics and Photonics (2016)
Acknowledgement
This work was funded by an Intuitive Surgical Sponsored Research Agreement.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Gao, C., Liu, X., Peven, M., Unberath, M., Reiter, A. (2018). Learning to See Forces: Surgical Force Prediction with RGB-Point Cloud Temporal Convolutional Networks. In: Stoyanov, D., et al. OR 2.0 Context-Aware Operating Theaters, Computer Assisted Robotic Endoscopy, Clinical Image-Based Procedures, and Skin Image Analysis. CARE CLIP OR 2.0 ISIC 2018 2018 2018 2018. Lecture Notes in Computer Science(), vol 11041. Springer, Cham. https://doi.org/10.1007/978-3-030-01201-4_14
Download citation
DOI: https://doi.org/10.1007/978-3-030-01201-4_14
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-01200-7
Online ISBN: 978-3-030-01201-4
eBook Packages: Computer ScienceComputer Science (R0)