
Abstract
Trade-off between resolution and signal to noise ratio(SNR) of magnetic resonance (MR) images can be improved by post processing algorithms to provide high quality MR images required for several medical diagnosis. This paper proposed a constraint to sharpen the gradient profile (GP), typically symbolizes the quality of image, of super-resolved MR images in the framework of sparse representation based super resolution without any external LR (low-resolution)-HR (high resolution) pair images. It has been performed by establishing a piecewise linear relation between GP of LR image up-scaled by Bi-cubic interpolation (UR), and corresponding LR image. The resultant relationship is used to approximate the ground truth HR image such that GP of upsampled LR image is improved. Further, to preserve the details along with its consistency among coronal, sagittal and axial planes, we have learned multiple dictionaries by extracting patches from the same and adjacent slices. The experimental results demonstrate that the proposed approach outperforms qualitatively and quantitatively the existing algorithms of increasing the resolution of MR images.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
- Gradient profile sharpness
- MRI super resolution
- Sparse representation
- Edge preservation
- Multiple dictionaries
1 Introduction
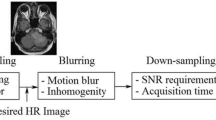
The requirement of precise medical diagnosis using MR scanner demands high spatial resolution and signal to noise ratio (SNR) of MR images, which can be achieved either by (i) choosing appropriate parameters of the pulse sequences or (ii) by having expensive materials in the MR scanner [1, 2]. However, the spatial resolution which is inversely determined by the voxel size is ultimately lower bounded by the threshold for SNR, and the time requisites in clinical practices also encourages the larger voxel size to speed up the MR scanning [1]. Decreasing the voxel size using pulse sequence parameters results in noisy MR images, which may not be able to serve the clinical purpose. Thus, post-processing algorithms of scanned MR images serve a convenient alternative for improving the trade off between resolution and SNR in order to provide better quality MR images. Moreover, it has been demonstrated experimentally that the application of signal processing techniques can improve the spatial resolution along with significant increment in the SNR [3] of MR images.
The objective to increase the resolution of MR images can be framed as super resolution problem and various approaches have attempted in literature for the same [4,5,6,7,8]. These approaches can be classified into two broad categories namely - super resolution of MR images (i) using available exemplar HR-LR images [7,8,9] (ii) without using any external HR or LR images. In the first category of these approaches, the lost fine details of the image to be super resolved are estimated from the external HR MR images. Here, the mapping between LR and HR MR images are learned and the given test LR image is mapped to HR image using learned mapping. These approaches give good reconstruction results but require HR-LR image pairs, which may not be possible to get in real world scenario. This issue is addressed by approaches from the second category, in which the fine image details are estimated using the patches extracted from the same image or same MR image volume itself. This comes from the observation that the same detail structure can be observed in the up and down-sampled versions of the image [10].
Following this, Manajon et.al. [11] exploited the self similarity of MR images with a strategy to construct 3D cube by weighted averaging of the several 3D cubes extracted from the same MR image volume. The averaging operator may smear the fine details of the resultant super resolved image, which otherwise reflect important information of tissue being captured like tissue boundaries in MR images. Moreover, it should be noted that, MR images essentially have many minor details which relate to subparts of the organ and each details’ sharpness play its role in clinical practices for e.g., diffused boundary/detail might be interpreted as hemorrhage/deformity. Thus, the preservation of the image details and their profile in super resolved MR images is an important aspect. In single image super resolution, it has been experimented in [5] to preserve the local variations by using total variation (TV) as a regularizer with low rank representation of MR images. The total variation considers the averaged variations in all directions irrespective of the detail’s structure, thus it preserves the details but tend to blur and reduce the sharpness of image details.
In this paper, we have proposed a constraint to preserve image details and the corresponding gradient profiles in the super resolved MR images using framework of sparse representation based super resolution without any external LR-HR images. In order to preserve the gradient profile of the details while upsampling, we explore the relation between gradient profile of details in LR image upscaled by bicubic interpolation (UR), and LR image details’ profile. It has been observed that the GPS profile of UR and LR images are related by a piecewise linear function, which is used to approximate the gradient profile for HR image estimate. Further, to preserve the details along with its consistency among coronal, sagittal and axial planes, we learn multiple dictionaries by extracting patches from the up-downsampled versions of same and adjacent slices. The experimental results demonstrate that the proposed approach outperforms the existing state-of-the-art single image super resolution algorithms explored to improve resolution of MR images.
The work done in the proposed approach has similarity with the approach in [12], where the super resolution of intensity images is addressed by estimation of gradient map while maintaining the consistency in GPS. Later, estimated gradient map of HR image is fused in intensity image to derive super-resolved HR image. On the contrary, in the proposed work, consistency in GPS is put as a constraint to estimate the MR images. Also it should be noted that, the proposed approach employs the framework of sparse representation based SR, which is completely different from the work in [12].
The rest of the paper is organized as follows: Sect. 2 briefly explains the sparse representation framework for super resolution. The proposed approach for preserving the gradient profile is explained in Sect. 3. Experimental results in Sect. 4 demonstrate that the proposed approach performs better than the existing approaches qualitatively and quantitatively, and the paper is concluded in Sect. 5.
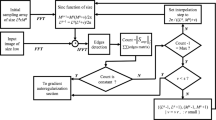
2 Sparse Representation Framework for Super Resolution
Considering the low rank structure and sparse manifold of the MR signal, we use the sparse representation framework for super resolution of MR image (\(\mathbf {y}\)) with sparsity regularizer [13]. The optimization problem is thus defined as:
where \(\mathbf {y}\in \mathbb {R}^m\) is the LR image obtained by degradation with downsampling \(\mathbf {D}\in \mathbb {R}^{m\times n}\) and blurring \(\mathbf {H}\in \mathbb {R}^{n\times n}\) operators, applied on the HR image \(\mathbf {x}\in \mathbb {R}^{n}, (n>>m)\) which is assumed to be represented as linear combination of columns of the overcomplete dictionary \(\mathbf {A}\), which means \(\mathbf {x}=\mathbf {A}\varvec{\beta }\). The choice of dictionary \(\mathbf {A}\) in Eq. (1) is important and several approaches have been explored to learn \(\mathbf {A}\) from the data itself. In this work, PCA based dictionary, as explained in [14] is used to demonstrate the effectiveness of the proposed approach.
3 Proposed Approach
The medical significance of image details in MR images requires the preservation of details along with their gradient profiles. In order to do so, the proposed approach develops a piece-wise linear relation between gradient profile of UR image and LR image, to approximate gradient profile for HR estimate. The estimated gradient profile for HR image is used as constraint to give super resolved images with sharper gradient profiles.
The parameters to model the image details, which mainly describe the edges, can be contrast(h) and width(d) of the edge as shown in Fig. 1(a). These two parameters are computed as explained in [15]. The values of h and d are combined to define the gradient profile sharpness(GPS, \(\eta = h/d\)), which can be used as a metric for indicating sharpness of image. The higher values of GPS indicate sharper image. To explore the nature of GPS values, HR image is taken randomly from an MR image volume obtained from 7T MR scanner with spatial resolution of \(173\times 173\). It is downsampled by factor 2 to obtain LR image, and the histogram of non-zero GPS values for each of UR, LR and HR images is plotted in Fig. 2. It can be seen in Fig. 2(a) that most of the values lie in lower range in case of UR image as compared to LR and HR image. This is due to the upsampling process on LR image, which blurs minor details of image. Blur will account for lower GPS values and zero GPS values are due to various missing details. It is important to note that the HR image is used to observe the behavior of GPS values, but it is not used while estimating the HR image. On the other hand, the percentage of edge pixels in LR and HR image remains almost same, and thus it is reasonable to represent \(hist(\varvec{\eta }_{H}\)) by \(hist(\varvec{\eta }_{L})\).

(a) Parameters to characterize the edge; (b) Illustration of 2D histogram for \(\varvec{\eta }_U\) (x-axis) and \(\varvec{\eta }_H\) (y-axis) for upscale factor 2 in left image and for upscale factor 3 in right image.

Histogram of non-zero GPS values obtained for randomly selected (a) UR image, (b) LR with downsample factor 2, (c) Super resolved HR image, and (d) the corresponding ground truth HR image, from MR image volumes in the dataset. Here x-axis shows the GPS values and y-axis indicates the corresponding count of GPS values scaled in 0 to 1 range.
To find the relation between \(\varvec{\eta }_U\) and \(\varvec{\eta }_H\), we extract the (\(\varvec{\eta }_{U}\), \(\varvec{\eta }_{H}\)) pairs following the spatial distance and gradient distance criteria as described in [12]. The 2D(\(\varvec{\eta }_{U}\), \(\varvec{\eta }_{H}\)) GPS distribution histogram is shown in Fig. 1(b) and Pearson product correlation coefficient(PPCC) is computed to validate the linearity in relation between \(\varvec{\eta }_H\) and \(\varvec{\eta }_U\). It has been observed that PPCC values is relatively lower for MR images. This can be due to the small details present in MR images which are approximately zero in \((\varvec{\eta }_{U})\) but are non-zero in \((\varvec{\eta }_{H})\). Moreover, as the upscale factor increases, the linearity is distorted. Hence, we divide the GPS values into multiple ranges, and approximate the linear relationship for each range. This results in a piece-wise linear relations of \(\varvec{\eta }_U\) with \(\varvec{\eta }_H\) values. In this work, we have divided the GPS values into four ranges. This linear relation can be modeled by \(\varvec{\eta }_H=\varvec{\alpha }\varvec{\eta }_U\), and \(\varvec{\alpha }\) can be estimated by minimizing the chi-square distance between histogram of \(\varvec{\eta }_L\) and \(\varvec{\eta }_U\). For each region, the following optimization cost is used to estimate \(\varvec{\alpha }\).
where f(z) represents the histogram of non-zero values of z and N is the number of elements selected in f(z).
3.1 Estimation of HR Image
We transform the gradient profile of UR image in order to define an estimate for gradient profile of high resolution image (\({\varvec{\eta }_{Ref}}=\varvec{\alpha }^*\varvec{\eta }_U\)). This can be used to constrain the solution space further, in order to choose only the solutions with sharper gradient profiles. This in effect reduces the blurring and other artifacts across tissue boundaries which is crucial for medical diagnosis. Thus the cost function with \(\mathbf {x}=\mathbf {A}\varvec{\beta }\) can now be:
It can be observed in Fig. 3(c) that the histogram of reconstructed HR image obtained by the proposed approach is similar to that of the ground truth HR image, which demonstrates the preservation of gradient profile of some details.
4 Experimental Results
To compare the performance of proposed algorithm, evaluated metrics(peak signal to noise ratio(PSNR), signal to noise ratio(SNR), structure similarity index measurement(SSIM)) are compared with two existing approaches. - sparse representation based LRTV algorithm [5], weighted averaging based NLM3D [11]. The performance of the proposed algorithm is evaluated using 8 randomly selected MR image volumes scanned by 7 T with \(1.05\times 1.05\times 1.05\,\text {mm}^3\) from dataset publicly available online [16]. Each volume contains 207 slices out of which we select central 120 slices due to insignificant information in first and last few slices. LR images are formed by first blurring the image with Gaussian kernel with sigma of 1 voxel and downsample the HR image volume in x and y directions with factors 2, and 3.

Examples of reconstruction quality of two highlighted windows shown in first row, zoomed in second and third row constructed by various approaches including proposed approach- (a) interpolated image with bicubic spline, (b) upsampled image with NLM3D [11], (c) reconstructed image with LRTV [5], and d) shows the result for proposed algorithm.
Super resolved images for using bicubic spline and NLM3D [11] are displayed in Fig. 3(a,b) which shows the blurry estimates and are not able to distinguish the structures. However, in LRTV [5] shown in Fig. 3(c) the ability to distinguish two distinct tissues is improved, but with blurred gradient profiles and zig-zag artifacts, which are visibly improved in the proposed approach Fig. 3(d) with sharper profiles. Please zoom in the computer screen to appreciate the improvements in the results.
The quality of images for each of the volume constructed using the proposed as well as existing approaches are evaluated quantitatively, and the computed values for metrics are tabulated in Tables 1 and 2 with the corresponding mean and variance values for upscale factor 2 and 3 respectively. It can be observed that the proposed algorithm outperforms the existing algorithms.
5 Conclusion
In the proposed approach, we approximate the piece-wise linear relation of gradient profiles in UR and LR image, in sparse representation framework with multiple dictionaries for restoration as well as for consistency of details in all directions. The proposed approach outperforms the existing approaches qualitatively as well as quantitatively.
References
Poldrack, R.A., Mumford, J.A., Nichols, T.E.: Handbook of Functional MRI Data Analysis. Cambridge University Press, Cambridge (2011)
Cosmus, T.C., Parizh, M.: Advances in whole-body MRI magnets. IEEE Trans. Appl. Supercond. 21(3), 2104–2109 (2011)
Plenge, E.: Super-resolution methods in MRI: can they improve the trade-off between resolution, signal-to-noise ratio, and acquisition time? Magn. Reson. Med. 68(6), 1983–1993 (2012). https://doi.org/10.1002/mrm.24187
Van Reeth, E., Tham, I.W.K., Tan, C.H., Poh, C.L.: Super-resolution in magnetic resonance imaging: a review. Concepts Magn. Reson. Part A 40A(6), 306–325 (2012). https://doi.org/10.1002/cmr.a.21249
Shi, F., Cheng, J., Wang, L., Yap, P.T., Shen, D.: LRTV: MR image super-resolution with low-rank and total variation regularizations. IEEE Trans. Med. Imaging 34(12), 2459–2466 (2015)
Roy, S., Carass, A., Prince, J.L.: Magnetic resonance image example based contrast synthesis. IEEE Trans. Med. Imaging 32(12), 2348–2363 (2013). http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3955746/
Rousseau, F., Alzheimer’s Disease Neuroimaging Initiative: A non-local approach for image super-resolution using intermodality priors. Med. Image Anal. 14(4), 594–605 (2010). http://www.ncbi.nlm.nih.gov/pmc/articles/PMC2947386/
Pham, C.H., Ducournau, A., Fablet, R., Rousseau, F.: Brain MRI super-resolution using deep 3D convolutional networks. In: 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), pp. 197–200, April 2017
Rueda, A., Malpica, N., Romero, E.: Single-image super-resolution of brain MR images using overcomplete dictionaries. Med. Image Anal. 17(1), 113–132 (2013). http://dblp.uni-trier.de/db/journals/mia/mia17.html#RuedaMR13
Glasner, D., Bagon, S., Irani, M.: Super-resolution from a single image. In: 2009 IEEE 12th International Conference on Computer Vision, pp. 349–356, September 2009
Manjón, J.V., Coupé, P., Buades, A., Fonov, V., Louis Collins, D., Robles, M.: Non-local MRI upsampling. Med. Image Anal. 14(6), 784–792 (2010). https://doi.org/10.1016/j.media.2010.05.010
Yan, Q., Xu, Y., Yang, X., Nguyen, T.Q.: Single image superresolution based on gradient profile sharpness. IEEE Trans. Image Process. 24(10), 3187–3202 (2015)
Yang, J., Wright, J., Huang, T.S., Ma, Y.: Image super-resolution via sparse representation. IEEE Trans. Image Process. 19(11), 2861–2873 (2010)
Mandal, S., Bhavsar, A., Sao, A.K.: Noise adaptive super-resolution from single image via non-local mean and sparse representation. Signal Process. 132, 134–149 (2017). http://www.sciencedirect.com/science/article/pii/S016516841630247X
Guan, J., Zhang, W., Gu, J., Ren, H.: No-reference blur assessment based on edge modeling. J. Vis. Commun. Image Represent. 29, 1–7 (2015). http://www.sciencedirect.com/science/article/pii/S1047320315000085
https://www.humanconnectome.org/study/hcp-young-adult/document/1200-subjects-data-release
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Kaur, P., Sao, A.K. (2018). Gradient Profile Based Super Resolution of MR Images with Induced Sparsity. In: Frangi, A., Schnabel, J., Davatzikos, C., Alberola-López, C., Fichtinger, G. (eds) Medical Image Computing and Computer Assisted Intervention – MICCAI 2018. MICCAI 2018. Lecture Notes in Computer Science(), vol 11070. Springer, Cham. https://doi.org/10.1007/978-3-030-00928-1_13
Download citation
DOI: https://doi.org/10.1007/978-3-030-00928-1_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-00927-4
Online ISBN: 978-3-030-00928-1
eBook Packages: Computer ScienceComputer Science (R0)