
Abstract
In this study, we propose a neural network approach to capture the functional connectivities among anatomic brain regions. The suggested approach estimates a set of brain networks, each of which represents the connectivity patterns of a cognitive process. We employ two different architectures of neural networks to extract directed and undirected brain networks from functional Magnetic Resonance Imaging (fMRI) data. Then, we use the edge weights of the estimated brain networks to train a classifier, namely, Support Vector Machines (SVM) to label the underlying cognitive process. We compare our brain network models with popular models, which generate similar functional brain networks. We observe that both undirected and directed brain networks surpass the performances of the network models used in the fMRI literature. We also observe that directed brain networks offer more discriminative features compared to the undirected ones for recognizing the cognitive processes. The representation power of the suggested brain networks are tested in a task-fMRI dataset of Human Connectome Project and a Complex Problem Solving dataset.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Brain imaging techniques, such as, functional Magnetic Resonance Imaging (fMRI) have facilitated the researches to understand the functions of human brain using machine learning algorithms [14, 15, 20, 25]. In traditional approaches, such as Multi-Voxel Pattern Analysis (MVPA), the aim was to discriminate cognitive tasks from the fMRI data itself without forming brain graphs and considering relationship between nodes of graphs. Moreover, Independent Component Analysis (ICA) and Principal Component Analysis (PCA) have been applied to obtain better representations. In addition to feature extraction methods, General Linear Model (GLM) and Analysis of Variance (ANOVA) have been used to select important voxels [20]. None of these approaches take into account the massively connected network structure of the brain [3, 4, 12, 22, 26]. Recently, use of deep learning algorithms have also emerged in several studies [7,8,9] to classify cognitive states. Most of these studies mainly focus on using deep learning methods to extract better representations from fMRI data for brain decoding.
Several studies form brain graphs using voxels or anatomical regions as nodes and estimate the edge weights of brain graphs with different approaches. Among them, Richiardi et al. [21] have created undirected functional connectivity graphs in different frequency subbands. They have employed Pearson correlation coefficient between responses obtained from all region pairs as edge weights and use these edge weights to perform classification in an audio-visual experiment. Brain graphs, constructed using pairwise correlations and mutual information as edge weights, have been used to investigate the differences in networks of healthy controls and patients with Schizophrenia [11] or Alzheimer’s disease [10, 13]. Yet, these studies consider only pairwise relationships while estimating the edge weights and ignore the locality property of the brain.
Contrary to pairwise relationships, a number of studies have estimated the relationships among nodes within a local neighborhood. Ozay et. al. [19] and Firat et al. [6] have formed local meshes around nodes and constructed directed graphs as ensembles of local meshes. They have applied Levinson-Durbin recursion [24] to estimate the edge weights representing the linear relationship among voxels and have used these weights to classify the category of words in a working memory experiment. Similarly, Alchihabi et al. [2] have applied Levinson-Durbin recursion to estimate the edge weights of local meshes of dynamic brain network for every brain volume in Complex Problem Solving task and have explored activation differences between sub-phases of problem solving. While these studies conserve the locality in the brain, construction of a graph for every time instant discards temporal relationship among nodes of the graph. Onal et al. [17, 18] have formed directed brain graphs as ensemble of local meshes. They have estimated the relationships among nodes within a time period considering the temporal information using ridge regression. Since the spatially neighboring voxels are usually correlated, linear independence assumption of features required for closed form solution to the estimation of linear relationship among voxels is violated. This may result in large errors and inadequate representation. Since the aforementioned studies form local meshes around each node separately, associativity is ignored in the resulting brain graphs.
In this study, we propose two brain network models, namely, directed and undirected Artificial Brain Networks to model the relationships among anatomical regions within a time interval using fMRI signals. In both network models, we train an artificial neural network to estimate the time series recorded at node which represent an anatomic region by using the rest of the time series recorded in the remaining nodes. In our first neural network architecture, called directed Artificial Brain Networks (dABN), global relationships among nodes are estimated without any constraint whereas in our second architecture of undirected Artificial Brain Networks (uABN), we apply a weight sharing mechanism to ensure undirected functional connections.
We test the validity of our dABN and uABN in two fMRI datasets and compare the classification performances to the other network models available in the literature. First, we employ the Human Connectome Project (HCP), task-fMRI (tfMRI) dataset, in which the participants were required to complete 7 different mental tasks. The second fMRI dataset contains fMRI scans of subjects solving Tower of London puzzle and has been used to study regional activations of Complex Problem Solving [2, 16]. The task recognition performances of the suggested Artificial Brain Networks are significantly greater than the ones obtained with state of the art functional connectivity methods.
2 Extraction of Artificial Brain Networks
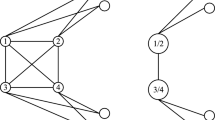
In this section, we explain how we estimate the edge weights of directed and undirected brain networks using artificial neural networks. Throughout this study, we represent a brain network by \(G=(V,E)\), where \(V = \{ v_{1}, v_{2}, v_{3}, \ldots , v_{M} \}\), denotes the vertices of the network, which represent \(M = 90\) anatomical brain regions, \(R = \{r_{1}, r_{2}, r_{3}, \ldots , r_{M}\}\). The attribute of each node is the average time series of BOLD activations. The average BOLD activation of an anatomical region \(r_i\) at time t is denoted with \(b_{i,t}\). We use all anatomical regions defined by Anatomical Atlas Labeling (AAL) [23], except for the ones residing in Cerebellum and Vermis. We represent the edges of the brain network by \( E = \{ e_{i,j} | \forall v_i,v_j \in V, i \ne j \} \). The weights of edges depend on the estimation method. We denote the adjacency matrix which consists of the edge weights, as \( \varvec{A}\), where \(a_{i,j}\) represents the weight of edge from \(v_i\) to \(v_j\), when the network is directed. When the network is undirected the weight of the edge formed between \(v_i\) and \(v_j\) is \(a_{i,j}= a_{j,i}\). Sample representations of directed and undirected brain networks are shown in Figs. 1 and 2, respectively.

A directed brain network.

An undirected brain network.
We temporally partition the fMRI signal into chunks with length L recorded during each cognitive process. The fMRI time series at each chunk is used to estimate a network to represent the spatio-temporal relationship among anatomic regions. Then, the cognitive process k of subject s is described as a consecutive list (\(T_{k}^{s}\)) of brain networks, formed for each chunk within time interval \([t, t+L]\), where \(T_{k}^{s} = \{ G_{1}, G_{2}, \ldots , G_{C_k}\}\). Note that, \(C_k\) is the number of chunks obtained for cognitive process k and equals to \(\lfloor N_k/L \rfloor \), where \(N_k\) denotes the number of measurements recorded for cognitive process k. Since we obtain a different network for each duration of length L for a cognitive process of length \(N_k\), this approach estimates a dynamic network for the cognitive process, assuming that \(N_k\) is sufficiently large.
For a given time interval \([t, t+L]\), weights of incoming edges to vertex \(v_i\) is defined by an M dimensional vector, \(\mathbf {\overline{a}_{i}} = [ a_{i,1}, a_{i,2}\ldots a_{i,M} ]\). Note that the ith entry \(a_{i,i} = 0\), which implies that a node does not have an edge value into itself. These edge weights define the linear dependency of activation, \(b_{i,t}\), of region \(r_i\) at time t to the activations of the remaining regions, \(b_{j,t}\) for a time interval \(t' \in \{t,t+L\}\)
where \(\hat{b}_{i,t'}\) is the estimated value of \(b_{i,t'}\) at time \(t'\) with error rate \(\epsilon _{t'}\), which is the difference between the real and estimated activation. Note that each node is connected to the rest of \(M-1\) nodes each of which corresponding to anatomic regions.
2.1 Directed Artificial Brain Networks (dABN)
In fully connected directed networks, we define two distinct edges between all pairs of vertices, \(E = \{ e_{i,j}, e_{j,i}| v_i,v_j \in V, i \ne j \}\) where \(e_{i,j}\) denotes an edge from \(v_i\) to \(v_j\). The weights of the edge pairs are not to be symmetrical, \(a_{i,j} \ne a_{j,i}\).
The neural network we design to estimate edge weights consists of an input layer and an output layer. For every edge in the brain network, we have an equivalent weight in the neural network, such that weight between \(input_{i}\) and \(output_{j}\), \(w_{i,j}\) is assumed to be an estimate for the weight, \(a_{i,j}\) of the edge from \(v_{i}\) to \(v_{j}\), in the artificial brain network.

Directed Artificial Brain Network architecture.
We employ a regularization term \(\lambda \) to increase generalization capability of the model and minimize the expected value of sum of squared error through time. Loss of an output node \(output_i\) is defined as,
where \(w_{i,j}\) denotes the neural network weight between \(input_i\) and \(output_j\) and E(.) is the expectation operator taken over time interval [t, t + L]. For each training step of the neural network, e, gradient descent is applied for the optimization of the weights as in Eq. (3) with empirically chosen learning rate, \(\alpha \). The whole system is trained for an empirically selected number of epochs (Fig. 3).
After training, the weights of neural network are assigned to edge weights of the corresponding brain graph, \( a_{i,j} \leftarrow w_{i,j}, \forall _{i,j}\).
2.2 Undirected Artificial Brain Network (uABN)
In undirected brain networks, similar to directed brain network, we define double connections between every pair of vertices \(E = \{ e_{i,j}, e_{j,i}| v_i,v_j \in V, i \ne j \}\). However, in order to make the network undirected, we must satisfy the constraint that twin (opposite) edges have the equal weights, \(a_{i,j} = a_{j,i}\). In order to assure th’s property in the neural network explained in the previous section, we use a weight sharing mechanism and keep the weights of the twin (opposite) edges in the neural network equal through the learning process, such that \(w_{i,j} = w_{j,i}\). The proposed architecture is shown at Fig. 4.

Neural network structure to create undirected Artificial Brain Networks (connections with the same colors are shared).
We use Eq. (2) for undirected Artificial Brain Networks. The weight matrix of uABN is initialized symmetrically, \(w_{i,j}=w_{j,i}\) and in order to satisfy the symmetry constraint through training epochs, we define the following update rule for the weights, \(w_{i,j}\) and \(w_{j,i}\) at epoch e.
Again, after an empirically determined number of epochs, the weights of edges in the undirected graph is assigned to the neural network weights, \(a_{i,j} \leftarrow w_{i,j}\).
2.3 Baseline Methods
In this subsection, we briefly describe the popular methods that have been used to build functional connectivity graphs, in order to provide some comparison for the suggested Artificial Brain Network.
Pearson Correlation. In their work, Richiardi et al. [21] defined the functional connectivity between two anatomic regions as pair-wise Pearson correlation coefficients computed between the average activations of these regions in a time interval. The edge weights are calculated by,
where \(\mathbf {b_{i,t,L}} = [b_{i,t}, b_{i,(t+1)},\ldots , b_{i,(t+L)}]\) represents the average time series of BOLD activations of region i between time t and \(t+L\), cov() defines the covariance, and \(\sigma _{s}\) represents the standard deviation of time series s. This approach assumes that the pair of similar time series represent the same cognitive process measured by fMRI signals.
Closed Form Ridge Regression. In order to generate brain networks with the method proposed in [18], we estimate the activation of a region from the activations of its neighboring regions in a time interval \([t, t+L]\). We minimize the loss function in Eq. 2 using closed form solution for ridge regression. The loss function is minimized with respect to the edge weights outgoing from a vertex \(v_i\), \( \overline{a}_{i} = [ a_{i,1}, a_{i,2}\ldots a_{i,M} ]\) and the following closed form solution of ridge regression is obtained:
where \(\mathbf {B}\) is an \(L \times (M-1)\) matrix, whose columns consist of the average BOLD activations of anatomic regions except for the region \(r_i\) in the time interval \([t, t+L]\) such that column j of matrix \(\mathbf {B}\) is \(\mathbf {b_{j,t,L}}\). \(\lambda \in R\) represents the regularization parameter.
3 Experiments and Results
In order to examine the representation power of the suggested Artificial Brain Networks, we compare them with the baseline methods, presented in the previous subsection, on two different fMRI dataset. The comparison is done by measuring the cognitive task classification performances of all the models.
3.1 Human Connectome Project (HCP) Experiment
In Human Connectome Project dataset, 808 subjects attended 7 sessions of fMRI scanning in each of which the subjects were required to complete a different cognitive task with various durations, namely, Emotion Processing, Gambling, Language, Motor, Relational Processing, Social Cognition, and Working Memory. We aim to discriminate these 7 tasks using the edge weights of the formed brain graphs.
In the experiments, the learning rate \(\alpha \) was empirically chosen as \(\alpha = 10^{-5}\) for both dABN and uABN and window size is chosen as \(L = 40\). We tested the directed and undirected Artificial Brain Networks and Ridge Regression method using various \(\lambda \) values. Since computation of Pearson correlation does not require any hyper parameter estimation, a single result is obtained for the Pearson correlation method.
After estimating the Artificial Brain Networks and forming the feature vectors from edge weights of the brain networks, we performed within-subject and across-subject experiments using Support Vector Machines with linear kernel. During the within-subjects experiments, we performed 3-fold cross validation using only the samples of a single subject. Table 1 shows the average of within-subject experiment results over 807 subjects, when the classification is performed using a single subject brain network of 7 tasks. During the across-subject experiments, we performed 3-fold cross validation using the samples obtained from 807 subjects. For each fold we employed the samples from 538 subjects to train and 269 subject to test the classifier. Table 2 shows the across-subject experiment results.
Table 1 shows that in within subject experiments our methods, dABN and uABN, have the best performances in classifying the cognitive task under different \(\lambda \) values, furthermore performances of directed networks are slightly better than undirected ones. It can be observed that as \(\lambda \) increases, generalization of our models also increase up to \(\lambda =128\).
Table 2 shows that our methods outperforms the others within a range of lambdas, \(\lambda = \{32, 64, 128\}\). Pearson Correlation results in the best accuracy when no regularization is applied to Artificial Brain Networks. Closed Form Ridge Regression solution offers more discriminative power in higher \(\lambda \) values.
3.2 Tower of London (TOL) Experiment
We also test the validity of the suggested Artificial Brain Network on a relatively more difficult fMRI dataset, recorded when the subjects solve Tower of London (TOL) problem. TOL is a puzzle game which has been used to study complex problem solving tasks in human brain. TOL dataset used in our experiments contains fMRI measurements of 18 subjects attending 4 session of problem solving experiment. In the fMRI experiments, subjects were asked to solve 18 different puzzles on computerized version of TOL problem [16]. There are two labeled subtask of problem solving with varying time periods namely, planning and execution phases.
As the nature of the data is not compatible with a sliding window approach and the dimensionality is too high for a computational model, in the study of Alchihabi et al. [1], a series of preprocessing steps were suggested for the TOL dataset. In this study, we employ the first two steps of their pipeline. In the first step called voxel selection and regrouping, a feature selection method is applied on time series of voxels to select the “important” ones. Then, the activations of the selected voxels in the same region are averaged to obtain the activity of corresponding region. As a result, a more informative and lower dimensional representation is achieved. In the second step, bi-cubic spline interpolation is applied to every consecutive brain volumes and a number of new brain volumes are inserted between two brain volumes to increase temporal resolution. For the details of interpolation, refer to [1]. In this study, the optimal number of volumes inserted between two consecutive brain volumes are found empirically and it is set to 4. Therefore, the time resolution of the data is increased four times.
We applied the above-mentioned preprocessing steps to all of the 72 sessions in the dataset. After the voxel selection phase, number of regions containing selected voxels is much less than 116 regions. Note that, we discard regions located in Cerebellum and Vermis. Window size for this dataset was set to \(L = 5\), since there are at least 5 measurements for every sub-phase after the interpolation. The neural network parameters used in our experiments are \(\alpha =10^{-6}\) and \(\# epochs = 10\). Table 3 shows the mean and standard deviation of classification accuracies obtained with our method and the base-line methods. Similar to HCP experiments, we slided non-overlapping windows on the measurements and we performed 3-fold cross validation during TOL experiments.
Table 3 shows that using Artificial Brain Networks gives better performances than using Pearson Correlation and Closed Form Ridge Regression methods in classifying sub-phases of complex problem solving under various regularization parameters. We observe that decoding performances of directed brain networks outperforms those of undirected brain networks.
4 Discussion and Future Work
In this study, we introduce a network representation of fMRI signals, recorded when the subjects perform a cognitive task. We show that the suggested Artificial Brain Network estimated from the average activations of anatomic regions using an artificial neural network leads to a powerful representation to discriminate cognitive processes. Compared to the brain networks obtained by ridge regression, the suggested Artificial Brain Network achieves more discriminative features. The success of the suggested brain network can be attributed to the iterative nature of the neural network algorithms to optimize the loss function, which avoids the singularity problems of Ridge Regression.
In most of the studies, it is customary to represent functional brain connectivities as an undirected graphs. However, in this study, we observe that the directed network representations capture more discriminative features compared to the undirected ones in brain decoding problems.
In this study, we consider complete brain graphs where all regions are assumed to have connections to each other. A sparser brain representation can be computationally more efficient and neuro-scientifically more accurate. As a future work, we aim to estimate more efficient brain network representations by employing some sparsity parameters in the artificial neural networks.
It is well-known that brain processes the information in various frequency bands. [5, 21] applied discrete wavelet transform before creating connectivity graphs. A similar approach can be taken for a more complete temporal information in brain decoding problems.
References
Alchihabi, A., Kivilicim, B.B., Ekmekci, O., Newman, S.D., Vural, F.T.Y.: Decoding cognitive subtasks of complex problem solving using fMRI signals. In: 2018 26th Signal Processing and Communications Applications Conference (SIU). IEEE (2018)
Alchihabi, A., Kivilicim, B.B., Newman, S.D., Vural, F.T.Y.: A dynamic network representation of fMRI for modeling and analyzing the problem solving task. In: 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), pp. 114–117. IEEE (2018)
Calhoun, V.D., Adali, T., Hansen, L.K., Larsen, J., Pekar, J.J.: ICA of functional MRI data: an overview. In: Proceedings of the International Workshop on Independent Component Analysis and Blind Signal Separation. Citeseer (2003)
Calhoun, V.D., Liu, J., Adalı, T.: A review of group ICA for fMRI data and ICA for joint inference of imaging, genetic, and ERP data. Neuroimage 45(1), S163–S172 (2009)
Ertugrul, I.O., Ozay, M., Vural, F.T.Y.: Hierarchical multi-resolution mesh networks for brain decoding. Brain Imaging Behav. 1–17 (2016)
Fırat, O., Özay, M., Önal, I., Öztekiny, İ., Vural, F.T.Y.: Functional mesh learning for pattern analysis of cognitive processes. In: 2013 12th IEEE International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC), pp. 161–167. IEEE (2013)
Firat, O., Oztekin, L., Vural, F.T.Y.: Deep learning for brain decoding. In: 2014 IEEE International Conference on Image Processing (ICIP), pp. 2784–2788. IEEE (2014)
Kawahara, J., et al.: BrainNetCNN: convolutional neural networks for brain networks; towards predicting neurodevelopment. NeuroImage 146, 1038–1049 (2017)
Koyamada, S., Shikauchi, Y., Nakae, K., Koyama, M., Ishii, S.: Deep learning of fMRI big data: a novel approach to subject-transfer decoding. arXiv preprint arXiv:1502.00093 (2015)
Kurmukov, A., et al.: Classifying phenotypes based on the community structure of human brain networks. In: Cardoso, M.J., et al. (eds.) GRAIL/MFCA/MICGen -2017. LNCS, vol. 10551, pp. 3–11. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-67675-3_1
Lynall, M.E., et al.: Functional connectivity and brain networks in schizophrenia. J. Neurosci. 30(28), 9477–9487 (2010)
McKeown, M.J., Sejnowski, T.J.: Independent component analysis of fMRI data: examining the assumptions. Hum. Brain Mapp. 6(5–6), 368–372 (1998)
Menon, V.: Large-scale brain networks and psychopathology: a unifying triple network model. Trends Cogn. Sci. 15(10), 483–506 (2011)
Michel, V., Gramfort, A., Varoquaux, G., Eger, E., Keribin, C., Thirion, B.: A supervised clustering approach for fMRI-based inference of brain states. Pattern Recogn. 45(6), 2041–2049 (2012)
Mitchell, T.M., et al.: Learning to decode cognitive states from brain images. Mach. Learn. 57(1–2), 145–175 (2004)
Newman, S.D., Greco, J.A., Lee, D.: An fMRI study of the tower of London: a look at problem structure differences. Brain Res. 1286, 123–132 (2009)
Onal, I., Ozay, M., Mizrak, E., Oztekin, I., Vural, F.T.Y.: A new representation of fMRI signal by a set of local meshes for brain decoding. IEEE Trans. Sig. Inf. Process. Netw. 3(4), 683–694 (2017)
Onal, I., Ozay, M., Vural, F.T.Y.: Modeling voxel connectivity for brain decoding. In: 2015 International Workshop on Pattern Recognition in NeuroImaging (PRNI), pp. 5–8. IEEE (2015)
Ozay, M., Öztekin, I., Öztekin, U., Vural, F.T.Y.: Mesh learning for classifying cognitive processes. arXiv preprint arXiv:1205.2382 (2012)
Pereira, F., Mitchell, T., Botvinick, M.: Machine learning classifiers and fMRI: a tutorial overview. Neuroimage 45(1), S199–S209 (2009)
Richiardi, J., Eryilmaz, H., Schwartz, S., Vuilleumier, P., Van De Ville, D.: Decoding brain states from fMRI connectivity graphs. Neuroimage 56(2), 616–626 (2011)
Smith, S.M., Hyvärinen, A., Varoquaux, G., Miller, K.L., Beckmann, C.F.: Group-PCA for very large fMRI datasets. Neuroimage 101, 738–749 (2014)
Tzourio-Mazoyer, N., et al.: Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. Neuroimage 15(1), 273–289 (2002)
Vaidyanathan, P.: The theory of linear prediction. Synth. Lect. Sig. Process. 2(1), 181–184 (2007)
Wang, X., Hutchinson, R., Mitchell, T.M.: Training fMRI classifiers to detect cognitive states across multiple human subjects. In: Advances in Neural Information Processing Systems, pp. 709–716 (2004)
Zhou, Z., Ding, M., Chen, Y., Wright, P., Lu, Z., Liu, Y.: Detecting directional influence in fMRI connectivity analysis using PCA based granger causality. Brain Res. 1289, 22–29 (2009)
Acknowledgment
The work is supported by TUBITAK (Scientific and Technological Research Council of Turkey) under the grant No: 116E091. We also thank Sharlene Newman, from Indiana University, for providing us the TOL dataset.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Kivilcim, B.B., Ertugrul, I.O., Yarman Vural, F.T. (2018). Modeling Brain Networks with Artificial Neural Networks. In: Stoyanov, D., et al. Graphs in Biomedical Image Analysis and Integrating Medical Imaging and Non-Imaging Modalities. GRAIL Beyond MIC 2018 2018. Lecture Notes in Computer Science(), vol 11044. Springer, Cham. https://doi.org/10.1007/978-3-030-00689-1_5
Download citation
DOI: https://doi.org/10.1007/978-3-030-00689-1_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-00688-4
Online ISBN: 978-3-030-00689-1
eBook Packages: Computer ScienceComputer Science (R0)