
Abstract
We improve the performance of sparse matrix-vector multiplication(SpMV) on modern cache-based superscalar machines when the matrix structure consists of multiple, irregularly aligned rectangular blocks. Matrices from finite element modeling applications often have this structure. We split the matrix, A, into a sum, A 1 + A 2 + ... + A s , where each term is stored in a new data structure we refer to as unaligned block compressed sparse row (UBCSR) format. A classical approach which stores A in a BCSR can also reduce execution time, but the improvements may be limited because BCSR imposes an alignment of the matrix non-zeros that leads to extra work from filled-in zeros. Combining splitting with UBCSR reduces this extra work while retaining the generally lower memory bandwidth requirements and register-level tiling opportunities of BCSR. We show speedups can be as high as 2.1× over no blocking, and as high as 1.8× over BCSR as used in prior work on a set of application matrices. Even when performance does not improve significantly, split UBCSR usually reduces matrix storage.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

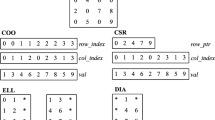
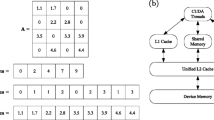
References
Baker, A.H., Jessup, E.R., Manteuffel, T.: A technique for accelerating the convergence of restarted GMRES. Technical Report CU-CS-045-03, University of Colorado, Dept. of Computer Science (January 2003)
Buttari, A., Eijkhout, V., Langou, J., Filippone, S.: Performance optimization and modeling of blocked sparse kernels. Technical Report ICL-UT-04-05, Innovative Computing Laboratory, University of Tennessee, Knoxville (2005)
D’Azevedo, E., Fahey, M.R., Mills, R.T.: Vectorized sparse matrix multiply for compressed sparse row storage. In: Sunderam, V.S., van Albada, G.D., Sloot, P.M.A., Dongarra, J. (eds.) ICCS 2005. LNCS, vol. 3514, pp. 99–106. Springer, Heidelberg (2005)
Geus, R., Röllin, S.: Towards a fast parallel sparse matrix-vector multiplication. In: D’Hollander, E.H., Joubert, J.R., Peters, F.J., Sips, H. (eds.) Proceedings of the International Conference on Parallel Computing (ParCo), pp. 308–315. Imperial College Press, London (1999)
Im, E.-J.: Optimizing the performance of sparse matrix-vector multiplication. PhD thesis, University of California, Berkeley (May 2000)
Im, E.-J., Yelick, K., Vuduc, R.: Sparsity: Optimization framework for sparse matrix kernels. International Journal of High Performance Computing Applications 18(1), 135–158 (2004)
Lee, B.C., Vuduc, R., Demmel, J., Yelick, K.: Performance models for evaluation and automatic tuning of symmetric sparse matrix-vector multiply. In: Proceedings of the International Conference on Parallel Processing, Montreal, Canada (August 2004)
Mellor-Crummey, J., Garvin, J.: Optimizing sparse matrix vector multiply using unroll-and-jam. In: Proceedings of the Los Alamos Computer Science Institute Third Annual Symposium, Santa Fe, NM, USA (October 2002)
Nishtala, R., Vuduc, R., Demmel, J., Yelick, K.: When cache blocking sparse matrix vector multiply works and why. In: Proceedings of the PARA 2004 Workshop on the State-of-the-art in Scientific Computing, Copenhagen, Denmark (June 2004)
Pinar, A., Heath, M.: Improving performance of sparse matrix-vector multiplication. In: Proceedings of Supercomputing (1999)
Remington, K., Pozo, R.: NIST Sparse BLAS: User’s Guide. Technical report, NIST (1996) http://www.gams.nist.gov/spblas
Saad, Y.: SPARSKIT: A basic toolkit for sparse matrix computations (1994), http://www.cs.umn.edu/Research/arpa/SPARSKIT/sparskit.html
Temam, O., Jalby, W.: Characterizing the behavior of sparse algorithms on caches. In: Proceedings of Supercomputing (1992)
Toledo, S.: Improving memory-system performance of sparse matrix-vector multiplication. In: Proceedings of the 8th SIAM Conference on Parallel Processing for Scientific Computing (March 1997)
Vassilevska, V., Pinar, A.: Finding nonoverlapping dense blocks of a sparse matrix. Technical Report LBNL-54498, Lawrence Berkeley National Laboratory, Berkeley, CA, USA (2004)
Vuduc, R.: Automatic performance tuning of sparse matrix kernels. PhD thesis, University of California, Berkeley, Berkeley, CA, USA (December 2003)
Vuduc, R., Demmel, J., Yelick, K.: OSKI: An interface for a self-optimizing library of sparse matrix kernels (2005) http://www.bebop.cs.berkeley.edu/oski
Vuduc, R., Demmel, J.W., Yelick, K.A., Kamil, S., Nishtala, R., Lee, B.: Performance optimizations and bounds for sparse matrix-vector multiply. In: Proceedings of Supercomputing, Baltimore, MD, USA (November 2002)
Vuduc, R., Moon, H.-J.: Fast sparse matrix-vector multiplication by exploiting variable blocks structure. Technical Report UCRL-TR-213454, Center for Applied Scientific Computing, Lawrence Livermore National Laboratory, Livermore, CA, USA (July 2005)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2005 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Vuduc, R.W., Moon, HJ. (2005). Fast Sparse Matrix-Vector Multiplication by Exploiting Variable Block Structure. In: Yang, L.T., Rana, O.F., Di Martino, B., Dongarra, J. (eds) High Performance Computing and Communications. HPCC 2005. Lecture Notes in Computer Science, vol 3726. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11557654_91
Download citation
DOI: https://doi.org/10.1007/11557654_91
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-29031-5
Online ISBN: 978-3-540-32079-1
eBook Packages: Computer ScienceComputer Science (R0)