
Abstract
Template matching is an important technique used for object tracking. It aims at finding a given pattern within a frame sequence. Pearson’s Correlation Coefficient (PCC) is widely used to quantify the degree of similarity of two images. This coefficient is computed for each image pixel. This entails a computationally very expensive process. In this work, aiming at accelerating this process, we propose to implement the template matching as an embedded co-design system . In order to reduce the processing time, a dedicated co-processor, which is responsible for performing the PCC computation is designed and implemented. In this chapter, two techniques of computational intelligence are evaluated to improve the search for the maximum correlation point of the image and the used template: Particle Swarm Optimization (PSO) was better than Genetic Algorithms (GA). Thus, in the proposed design, the former is implemented in software and is run by an embedded general purpose processor, while the dedicated co-processor executes all the computation regarding required PCCs. The performance results show that the designed system achieves real-time requirements as needed in real-word applications.
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
12.1 Introduction
With the development and enhancement of sensors and the advent of intelligent equipment capable of capturing, storing, editing and transmitting images, the acquisition of information, which is extracted from images and videos, became possible and led to a blossoming of an important research area. In defense and security fields of expertise, this kind of research is very relevant as it allows target recognition and tracking in image sequences. It can provide solutions for the development of surveillance and monitoring systems [13], firing control [2], guidance [5], navigation [8], remote biometrics authentication [4], control of guided weapons [16], among many other applications.
In general, a pattern is an arrangement, or a collection of objects that are similar, and thus it is identified by its arrangement of disposition. One of the most used techniques for finding and tracking patterns in images is generally identified as template matching [1, 12]. It consists basically in finding a small image, considered as a template, inside a larger image. Among the methods used to evaluate the matching process, the normalized cross correlation is very known and widely used. The underlying task is computationally very expensive, especially when using large templates with an extensive image set [18].
Aiming at improving the performance, we propose an implementation of the template matching as a software/hardware co-design system, using global best PSO , implemented in software, while the required computation of PCC, implemented in hardware via a dedicated co-processor. In order to evaluate the proposed design, the processing time as required by the software-only and the co-design systems are evaluated and compared.
The rest of this paper is organized in six sections. First, in Sect. 12.2, we define the template matching and correlation concepts as they are used in this work. After that, in Sect. 12.3, we briefly present the methods and evaluate the performance of GAs , global best PSO and local best PSO as computational intelligence techniques to be used as software sub-system. Subsequently, in Sect. 12.4, we describe in detail the proposed hardware used as co-processor. Then, in Sect. 12.5, we present and analyze the obtained performance results. Finally, in Sect. 12.6, we draw some useful conclusions and point out one direction for future works.
12.2 Template Matching
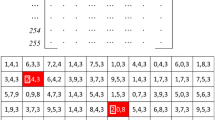
Template matching is used in image processing, basically, to find an object given via its image inside a bigger image. The object to be recognized is compared to a pre-defined template. Figure 12.1 illustrates the dynamics of the used process for a gray scale image, wherein the pixels are represented by bytes of value between 0 and 255 (higher values are represented by squares with color closer to white). The template, identified by a red square in the figure, slides over all the pixels. In each position, the images are compared using a similarity measure. Once the similarity evaluation is completed, regarding all pixels, the pixel that provides the highest correlation degree is identified as the location of the template within the image [15].

Template matching process
Among existing similarity measures for template matching, the normalized cross correlation is well known and often used. The Pearson’s Correlation Coefficient (PCC) is used as a measure of similarity between two variables and can be interpreted as a dimensionless measure. When applied to images, the PCC can be computed as defined in Eq. (12.1):
wherein p i is the intensity of pixel i in template P; \(\overline {p}\) is the average intensity of all pixels of the template; a i is the intensity of pixel i in patch A from the analyzed image; \(\overline {a}\) is the average intensity of all pixels in the patch of image A. Note that template P and patch A of the image must have the same dimensions. The PCC always assumes real values within [−1, +1]. Coefficient + 1 implies a perfect positive correlation of the compared variables while coefficient − 1 represents a perfect negative correlation of the compared variables.
The advantage of template matching is that the template stores particular characteristics of the object (color, texture, shape, edges, centroid), differentiating it from the others, allowing more accuracy. Besides, the object detection does not depend on how the objects are classified or represented. The disadvantage is the underlying high computational cost necessary to perform the computation regarding all possible positions.
12.3 Software Development
Figure 12.2b shows an example where the PCC is calculated for all pixels of the Fig. 12.2a. The template is highlighted by a green square. We can note that the correlation graphic has a visible maximum peak, which corresponds to the center of the object. So, the tracking problem is related to an optimization problem, where the global maximum must be discovered and the objective function is PCC.

Aircraft image—361 × 481 pixels. (a) Template highlighted—137 × 85. (b) Correlation aspect
Optimization algorithms are search methods in which the objective is to find out an optimal solution, by associating values to variables, for a given optimization problem. For this, the algorithm examines the space of solutions to discover possible solutions that meet the problem constraints [7]. Many computational intelligence techniques comply with this purpose. In the work presented in this chapter, Genetic Algorithms and two topologies of Particle Swarm Optimization were evaluated, as described in the next sections.
12.3.1 Genetic Algorithms
Genetic Algorithms is one of the most established methods of computational intelligence [9]. It is inspired by the evolution theory, which states that the best solution to a problem is found from the combination of possible solutions that are improved iteratively.
At each iteration (generation), a new population of candidate solutions (individuals) is created from the genetic information of the best individuals of the previous generation. The algorithm represents a possible solution using a simple structure, called chromosome. Genetic inspired operators are applied (selection, crossover, and mutation) to chromosomes in order to simulate the process of solution evolution. Each chromosome is comprised of genes that are usually represented by bits, depending on codification. Figure 12.3 shows the flowchart of GA execution.

Typical steps of GA
In the basic genetic algorithms, an initial population of possible solutions is generated randomly. Each individual is composed by a chromosome, which is represented internally by a binary array. The population is evaluated by a fitness function, which assigns a value proportional to the quality of the solution to the problem.
In order to create the population of the next generation, a selection process is used. During this process, individuals are selected to generate the offspring based on their fitness. An individual has a chance to reproduce and thus pass its genetic information to the individuals of the next generation proportional to its fitness.
In GA, the selection process is based on an addicted roulette, where each individual is represented by a space proportional to its fitness [9]. The selection process is repeated, with replacement, until it reaches the desired number of individuals required to form the new population. Some genetic algorithms implementations use the principle of elitism to prevent losing the best solution. It consists in an unconditional repetition of the best-fitted individual in the next generation.
After the selection process, the crossover is carried out. The parents are separated, two by two, to participate on the crossover. If the crossover does not occur, the two descendants are exact copies of their parents. The canonical genetic algorithms generally use one-point crossover that consists in swapping the chromosomes of each parent, at a random point.
After some generations, the population will have similar individuals, located in the same region of the search space, which may not be the region where the global optimum is located, indicating a premature convergence. In order to overcome this problem, the mutation operator is used. It provides an exploratory behavior, inducing the algorithm to sample new points of the search space. In the proposed operator in Ref. [9], the mutation is characterized by flipping, with a certain probability, some bits of the chromosome.
All the process is repeated, with the creation and evaluation of new populations, until a stopping criterion is achieved. This criterion can be a target fitness value, considered acceptable, or a maximum number of generations.
12.3.2 Particle Swarm Optimization
The PSO algorithm resulted from the observation of social behavior of flock birds and fish schools [10]. The particles, considered as possible solutions, behave like birds looking for food using their own learning (cognitive component) and the flock learning (social component). The problem is expressed via an objective function. The quality of the solution represented by a particle is the value of the objective function in the position of that particle. The term particle is used, in analogy to the physical concept, because it has a well-defined position and velocity, but it has no mass or volume. The term swarm represents a set of possible solutions. At each iterative cycle, the position of each particle of the swarm is updated according to Eq. (12.2):

where \( x_i^{(t)} \) is the position of the particle i at time t, and \( x_i^{(t+1)} \) and \( v_i^{(t+1)} \) are the position and the velocity of the particle i at time t + 1, respectively.
The velocity is the sum of three components: inertia, memory, and cooperation. Inertia keeps the particle in the same direction. The memory conducts the particle towards the best position discovered by itself during the process so far. The cooperation conducts the particle towards the best position discovered by the swarm or neighborhood, depending on the topology used. The neighborhood of a particle is directly linked to the topology considered.
The social structure of the PSO is determined by the way particles exchange information and exert influence on each other [7]. In the star topology, the neighborhood of the particle consists of all other particles of the swarm. In this case, the velocity vector is updated according to Eq. (12.3):
where w is a constant that represents the inertia of the particle; c 1 and c 2 are constants that give weights to the components cognitive and social, respectively; r 1 and r 2 are random numbers between 0 and 1; pbest i is the best position found by the particle i and gbest is the best position found by the swarm. The positions of the particles are confined into the search space, and the maximum speed can be set for each dimension of the search space.
In the ring topology, the neighborhood of each particle consists of a subset of two neighboring particles. In this case, the velocity vector is updated according to Eq. (12.4):
where lbest is the best position found by the neighborhood of the particle. So, the social component of the velocity is influenced only by a limited neighborhood, and the information flows more slowly through the swarm.
The aforementioned steps are repeated until the stopping criterion is reached. This criterion can be a target fitness value, considered acceptable, or a maximum number of iterations. The steps used in PSO are summarized in Fig. 12.4.

Typical steps of PSO
12.3.3 Comparison Between GA and PSO
In order to perform the comparisons between the computational intelligence algorithms, we used, initially, MATLAB software 7.10.0 (R2010a) installed on a computer ASUS, Intel Core i7-2630 QM 2 GHz, 6 GB memory and Windows 7 Home Premium 64-bit. For the implementation of the genetic algorithms, an external toolbox for MATLAB was used.
For the Genetic Algorithm, a script was written using the classical algorithm, as described in the previous section. PCC is considered as the fitness function and chromosomes correspond to random positions in the main image. The following steps were taken into account:
-
1.
First, transform the main image and the template into gray scale.
-
2.
Then, generate the initial population, with chromosomes corresponding to random positions in the main image;
-
3.
For each individual, extract a patch of the same size as the template, and compute the corresponding PCC at its center that corresponds to its fitness. It is noteworthy to point out that the limits of the main image are completed with zeros.
-
4.
After that, generate the new population, using selection by roulette and elitism, one-point crossover and mutation. Considering that correlation has negative values, the fitness has been normalized before applying the roulette selection.
-
5.
Repeat steps 3 and 4 until an acceptable PCC value is reached or a maximum limit for the generation number is exceeded.
For Particle Swarm Optimization, another script was written. We evaluated two topologies, based on previous section: star and ring. For the star topology, hereinafter called global best PSO (PSO-G), the neighborhood of the particles are all particles of the swarm. For the ring topology, hereinafter called local best PSO (PSO-L), the neighborhood of the particle are only two neighboring particles, considering the index of the particles. The PCC was used as fitness function, and the particles corresponded to random positions in the main image. So, the following steps were taken into account:
-
1.
First, transform the main image and the template into gray scale.
-
2.
Then, generate the initial particle swarm, with random positions and velocities.
-
3.
For each particle, extract a patch of the same size as the template, and compute the corresponding PCC at its center. It is noteworthy to point out that the limits of the main image are completed with zeros.
-
4.
After that, store the best value of PCC found for each particle and also that related to the whole swarm of particles in the case of PSO-G or in its neighborhood in the case of PSO-L.
-
5.
Update the particle positions with Eq. (12.2), and the particle velocities with Eqs. (12.3) and (12.4) for the PSO-G and PSO-L, respectively.
-
6.
Repeat steps 3, 4, and 5 until an acceptable PCC value is reached or a maximum limit for the iteration number is exceeded.
An aircraft video was downloaded from YouTube [22], and a frame, identified hereinafter as aircraft was extracted. Figure 12.2 shows the aircraft frame and its corresponding correlation behavior. Also, the frame number 715 of the benchmark video EgTest05 downloaded from a website [6] was used. Hereinafter, this frame is identified as pickup715, and is shown in Fig. 12.5, together with its corresponding PCC behavior. Furthermore, the first frame of the benchmark video EgTest02, downloaded from the same website [6], was also used for performance evaluation. The resolution of this frame was reduced to 320 × 240 pixels and, hereinafter, is identified as cars320. It is shown in Fig. 12.6, together with the corresponding PCC behavior.

Pickup715 image—640 × 480 pixels. (a) Template highlighted—249 × 193. (b) Correlation aspect

Cars320 image—320 × 240 pixels. (a) Template highlighted—21 × 19. (b) Correlation aspect
For comparison purposes, the brute force search considering all pixels of the image was also performed, hereinafter called Exhaustive Search (ES). All algorithms are used to find the pixel localization of the template center within the main image. In Table 12.1 are shown the center position of the template, the PCC and computational time for the different images and optimization methods. In this case, the parameters for the GA, PSO-G, and PSO-L were set empirically as follows (config 1):
-
GA config1: population of 30 individuals; selection by roulette and elitism; crossover rate 80%; mutation rate 12%.
-
PSO config1: swarm of 100 particles; maximum velocity V max = 10, w = 1, c 1 = 1.5, and c 2 = 2.
The stopping criteria were also set empirically. We considered a threshold of 0.95 for the PCC or a maximum number of iterations. For the genetic algorithms, this number was set to 300 generations while for PSO-G and PSO-L as 50 iterations.
It is possible to observe in the correlation graphic of the image cars320 (Fig. 12.6) that it includes many local maxima and thus it entails a complex optimization process in order to identify the target. During this case study, the algorithms were reconfigured to avoid local maxima. The results of this configuration, called config 2, are shown in the last column of Table 12.1. This configuration is set as follows:
-
GA config2: population of 35 individuals; selection by roulette and elitism; crossover rate 80%; mutation rate 15%; maximum 400 generations.
-
PSO config2: swarm of 200 particles; w = 1.4; c 1 = c 2 = 1.5; maximum velocity V max = 10; the maximum number of iteration for PSO-G was set to 50, while for PSO-L, this number was set to 150 iterations.
Because of the stochastic characteristic of GA and PSO, it is important to evaluate convergence. To do this, Monte Carlo simulations were used, and the process was repeated 100 times (we performed 100 tracking simulations). The results are shown and compared in the bar diagrams of the Figs. 12.7, 12.8, and 12.9. Note that the PSO-G is the fastest, and is more accurate than both PSO-L and GA. PSO-L is faster than GA. For the image cars320, using config 2, the speedup obtained with GA is only 2, with 71% success rate.

Average processing time for the images over 100 searches (ms)

Average iterations/generations number for the images over 100 searches

Success rate for the images over 100 searches (%)
We can conclude that the global best PSO is the most appropriate tool to perform the optimization. Thus, this technique was implemented as software of the proposed co-design system in order to track targets using template matching and correlation. More detailed results can be verified in Ref. [20], where the authors also performed a comparison between GA and PSO.
12.4 Hardware Architecture
The most expensive part of template matching is the PCC related computations, as verified in Ref. [19]. In order to improve the processing time, and thus allow real-time execution, this computation is implemented via a dedicated co-processor, taking advantage of the inherent parallelism of the hardware. Furthermore, the search for the location with the maximum correlation is assisted by global best PSO, executed as a software, by a general purpose processor. Unlike brute force methods, this intelligent technique optimizes the search process.
This hardware/software approach, usually called co-design, is a methodology to develop an integrated system using hardware and software components, to satisfy performance requirements and cost constraints [14]. The final target architecture usually has software components executed by a soft processor that is aided by some dedicated hardware components developed especially for the application.
The macro-architecture of the proposed integrated system is presented in Fig. 12.10. The system includes: a processor (PS), in order to execute the PSO iteration; a co-processor to compute the required PCC; two dedicated memory blocks (BRAM IMG and BRAM TMP) that store the original image and the template, respectively; and the drivers to access these memories (GET IMG and GET TMP).

Macro-architecture of the proposed system
12.4.1 Dedicated Co-processor
Figure 12.11 presents the proposed architecture for the co-processor that is responsible for performing the correlation computation for two given images, as defined in Eq. (12.1). The architecture is designed so as it can operate in a pipeline way. Each of the three blocks corresponds to one of the three pipeline stages. In each rising edge of the clock signal, the co-processor requires three data:
-
data_p: one pixel from the template, consisting of 8 bits;
-
data_ac: one pixel from the image to be compared, consisting of 8 bits;
-
data_am: one pixel from the next image, consisting of 8 bits.

Macro-architecture of the co-processor
All the images considered during the comparison are composed by 64 × 64 pixels, consisting of a total of 4096 pixels that are represented by 4 KBytes. The computations are performed on a block, and the obtained results are transferred to the next one, at every synchronism pulse. This pulse is generated by component sincro at every 4103 clock cycles. As output, the co-processor provides the value of the PCC (result), as 32 bits two’s complement together with a flag, indicating the operation end (flag_end) as well as an error signal (error), indicating that the result is not valid, which usually occurs when there is a division by zero.
12.4.1.1 First Stage
Figure 12.12 shows the architecture of block 1, which represents the first stage of the pipeline and is responsible for the computation of the average of the pixels of the images to be compared. It has output registers that are loaded only when the stage task is completed. At a syncronism pulse, only component media, which is responsible for computing the main image average, is restarted.

Micro-architecture of block 1
12.4.1.2 Second Stage
Figure 12.13 shows the architecture of the block 2, which represents the pipeline second stage, and is responsible for computing the 3 sums of Eq. (12.1). It consists of two components subt_A2, three components mult_CLK and three components sum_A2. Component subt_A2 performs, in two’s complement, the subtraction of image pixels of the averages obtained by the block 1. Component mult_CLK performs, in one clock pulse, the multiplication of the results provided by components subt_A2. Component sum_A2 performs the sum, in two’s complement, of the multiplications provided by components mult_CLK. Like block 1, block 2 has output registers that are loaded only when the stage task is completed. At the syncronism pulse, components subt_A2, mult_CLK, and subt_A2 are reset.

Micro-architecture of block 2
12.4.1.3 Third Stage
Figure 12.14 shows the architecture of the block 3, which represents the pipeline third stage, and is responsible for computing the main multiplication, the square-root and the division of Eq. (12.1). It consists of component mult_CLK that performs, in one clock pulse, the multiplication of the denominator sum of Eq. (12.1), component SQRT that calculates the square-root and component div_frac_A2 that performs the division, providing a result with 2−24 precision. This last component provides the output signals of the co-processor. The operation of this block is controlled by a state machine (FSM), which is responsible for coordinating the block’s components. At a syncronism pulse, the FSM returns to its initial state. Similarly to block 1 and block 2, block 3 has output registers that are loaded only when the stage task is completed.

Micro-architecture of block 3
12.4.1.4 Square-Root Computation
Historically, one of the first methods to calculate the square root was developed by ancient Babylonians [11]. Based on this numerical method, so-called Babylonian, the component SQRT in block 3 has been implemented, in hardware, using an iterative process of N steps, based on Eq. (12.5):
wherein x is the square root, S is the radicand (\(x = \sqrt {S}\)), x i is the value of x in the current iteration, and x i+1 is the value of the next iteration. The number of iterations N is set according to the required result precision.
12.4.1.5 Division Computation
Algorithm 12.1 is used to compute the required division result. This algorithm is implemented, in hardware, as component div_frac_A2 in block 3.
Algorithm 12.1 Division Q = A∕B

12.4.2 Memory Controllers
The dedicated memory blocks BRAM_TMP and BRAM_IMG store the template and the main image, respectively. They are implemented in the programmable logic of the Zynq chip (PL). Component BRAM_TMP can store up to 4096 8-bit pixels, totalizing 4KBytes corresponding to the template size. On the other hand, component BRAM_IMG can store up to 573 × 463 8-bit pixels, totalizing 260 KBytes. The maximum size of main image is 510 × 400 pixels. Note that the image is padded with zeros.
Drivers GET_TMP and GET_IMG are responsible for providing access to dedicated memories BRAM_TMP and BRAM_IMG, respectively. They deliver the data to the co-processor, on the right time. The read and write cycles are synchronized by the clock signal (CLK) and the syncronism signal (CLK_sync). Moreover, these memory controllers also allow the processor to access the dedicated memory.
12.5 Performance and Results
The proposed design is implemented using the Smart Vision Development Kit rev 1.2 (SVDK) of Sensor to Image [17]. This board has a Xilinx module called PicoZed 7Z015 System-On Module Rev.C that provides a hardware environment for developing and evaluating designs targeting machine vision applications. Among the various features, common to many embedded processing systems, this board has a UART interface, a USB3 interface, 1GB DDR3 memory (× 32), 33.333 MHz oscillator, a HDMI video encoder, and a chip XC7Z015 Xilinx [3, 17]. This chip is part of Zynq-7000 family, with architecture All Programmable System on Chip. It integrates a dual-core ARM Cortex-A9 based processing system (PS) and a Xilinx programmable logic (PL), in a single device [21]. This component provides the flexibility and scalability of an FPGA, while providing a performance, power, and ease of use typically of an ASIC. So, it is perfect for co-design implementations.
The implementation in SVDK board used 11% of flip-flops, 39% of LUTs, 25% of buffers, and 69% of BRAMs (Block RAMs). Because of synthesis time constraints associated with the project, the co-processor runs at 25 MHz.
Figure 12.15 shows the images used in this section, and the corresponding templates, highlighted by the inner squares. These images are considered benchmarks for computational vision and are available in [6].

Reference images used in the performance tests. (a) Pickup—I 1. (b) Truck—I 2. (c) Rcar—I 3. (d) Cars—I 4. (e) Sedan—I 5. (f) IR1—I 6. (g) IR2—I 7. (h) IR3—I 8
The performance of the proposed system was evaluated using three scenarios:
-
1.
ES: which is the exhaustive search of all main image pixels, executed by the main processor;
-
2.
PSO SO: which is the intelligent search using global best PSO implemented only in software and executed by the main processor; and
-
3.
PSO HP: which is the intelligent search using global best PSO implemented in software whereby PCCs are calculated by the co-processor, working in pipeline mode.
The correlation for each pixel is calculated extracting a patch, of the same size as the template, and computing the corresponding PCC at its center. It is noteworthy to point out that the limits of the main image are completed with zeros.
The canonical PSO algorithm is used, and the PCC is the cost function. The parameters were set, empirically, as follows: 18 particles, inertial coefficient w = 0.6, cognitive coefficient c 1 = 0.6, social coefficient c 2 = 2 with a maximum velocity of 10. As stopping criteria, we combined either an acceptable PCC threshold of 0.95 or maximum of 10 iterations. In terms of search space, we limited the search in a window of 101 × 101 pixels. Note that in real situations, the object does not change position abruptly, and it remains nearby its position in the previous frame. All templates considered have 64 × 64 pixels.
The results, in terms of average processing time, as obtained for the compared scenarios are given in Fig. 12.16. These average results are for 1000 template searches performed in each image. We can observe for the image IR1, with the best result, the time processing has been improved 131 ×, comparing the PSO SO with the ES, and has been improved 1614 ×, comparing the PSO HP with the ES. In order to track an object in a usual video of 30 frames/s, it is necessary to process each frame in a time of at most 33 ms. All results for PSO HP are lower than 19 ms, confirming that the proposed design is a viable way to achieve real-time execution.

Average processing time for the images over 1000 searches (ms)
Because of the stochastic behavior of the PSO, the success rates on finding the object for the PSO scenarios are also evaluated. The results are depicted in Fig. 12.17 for 1000 template searches in each image. It is possible to observe that the success rate is above 89.4% for all the images, which is acceptable in real-world object tracking.

Average success rate for the benchmark images over 1000 searches
12.6 Conclusions
The proposed co-design system , wherein the PCC computation is implemented in hardware keeping the global best PSO iterative process in software, showed to be a viable way to achieve real-time execution in template matching. The average processing time for the images was improved up to 1614 ×, comparing with the exhaustive search, and is lower than 19 ms. As a future work, and in order to further improve the performance of the process, the co-processor design could be examined as to increase the operation frequency.
References
Ahuja, K., Tuli, P.: Object recognition by template matching using correlations and phase angle method. Int. J. Adv. Res. Comput. Commun. Eng. 2(3), 1368–1373 (2013)
Ali, A., Kausar, H., Khan, M.I.: Automatic visual tracking and firing system for anti aircraft machine gun. In: 6th International Bhurban Conference on Applied Sciences and Technology (IBCAST), pp. 253–257. IEEE, Piscataway (2009)
Avnet: PicoZed 7Z015 / 7Z030 System-On Module Hardware User Guide, version 1.3 (2015)
Benfold, B., Reid, I.: Stable multi-target tracking in real-time surveillance video. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3457–3464. IEEE, Piscataway (2011)
Choi, H., Kim, Y.: UAV guidance using a monocular-vision sensor for aerial target tracking. Control Eng. Pract. 22, 10–19 (2014)
Collins, R., Zhou, X., Teh, S.K.: An open source tracking testbed and evaluation web site. In: IEEE International Workshop on Performance Evaluation of Tracking and Surveillance, vol. 2, p. 35 (2005)
Engelbrecht, A.P.: Fundamentals of Computational Swarm Intelligence. Wiley, West Sussex (2006)
Forlenza, L., Fasano, G., Accardo, D., Moccia, A.: Flight performance analysis of an image processing algorithm for integrated sense-and-avoid systems. Int. J. Aerosp. Eng. 2012, 1–8 (2012)
Holland, J.H.: Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control and Artificial Intelligence. MIT Press, Cambridge (1992)
Kennedy, J., Eberhart, R.: Particle swarm optimization. In: IEEE International Conference on Neural Network, vol. 4, pp. 1942–1948. EUA (1995)
Kosheleva, O.: Babylonian method of computing the square root: justifications based on fuzzy techniques and on computational complexity. In: Fuzzy Information Processing Society, NAFIPS, pp. 1–6. IEEE, Piscataway (2009)
Mahalakshmi, T., Muthaiah, R., Swaminathan, P., Nadu, T.: Review article: an overview of template matching technique in image processing. Res. J. Appl. Sci. Eng. Technol. 4(24), 5469–5473 (2012)
Narayana, M.: Automatic tracking of moving objects in video for surveillance applications. Ph.D. Thesis, University of Kansas (2007)
Nedjah, N., Mourelle, L.M.: Co-design for System Acceleration: A Quantitative Approach. Springer Science & Business Media, Berlin (2007)
Nixon, M.S., Aguado, A.S.: Feature Extraction and Image Processing, 1st edn. Academic, Great Britain (2002)
Olson, T.L., Sanford, C.W.: Real-time multistage IR image-based tracker. In: AeroSense’99, pp. 226–233. International Society for Optics and Photonics, Bellingham (1999)
SensorToImage: SVDK Hardware User Guide, revision 1.1 (2015)
Sharma, P., Kaur, M.: Classification in pattern recognition: a review. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 3(4), 1–3 (2013)
Tavares, Y.M., Nedjah, N., Mourelle, L.M.: Embedded Implementation of template matching using correlation and particle swarm optimization. In: International Conference on Computational Science and Its Applications, pp. 530–539. Springer, Beijing (2016)
Tavares, Y.M., Nedjah, N., Mourelle, L.M.: Tracking patterns with particle swarm optimization and genetic algorithms. Int. J. Swarm Intell. Res. 8(2), 34–49 (2017)
Xilinx: UG585 Zynq-7000 AP SoC Technical Reference Manual, version 1.10 (2015)
YouTube: Rafale - High Technology Hunting Plane (Brazil) (in Portuguese) (2015)
Acknowledgements
Y. M. Tavares acknowledges the Brazilian Navy for the support given during the development of his research work. We are also grateful to FAPERJ (Fundação Carlos Chagas Filho de Amparo à Pesquisa do Estado do Rio de Janeiro, http://www.faperj.br) and CNPq (Conselho Nacional de Desenvolvimento Científico e Tecnológico, http://www.cnpq.br) for their continuous financial support.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this chapter

Cite this chapter
Tavares, Y.M., Nedjah, N., de Macedo Mourelle, L. (2019). Co-design System for Tracking Targets Using Template Matching. In: Platt, G., Yang, XS., Silva Neto, A. (eds) Computational Intelligence, Optimization and Inverse Problems with Applications in Engineering. Springer, Cham. https://doi.org/10.1007/978-3-319-96433-1_12
Download citation
DOI: https://doi.org/10.1007/978-3-319-96433-1_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-96432-4
Online ISBN: 978-3-319-96433-1
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)