
Abstract
Level shifters to convert signal swings from low-voltage (VDDL) to high-voltage (VDDH) are required at the boundary of voltage domains in SoC employing multiple supply voltages. However, they cost delay, power and area in addition to increasing the complexity of physical design. This paper proposes a level-shifter-less (LSL) approach to use a reverse body bias (RBB) at pMOS transistors in the VDDH domain and superior threshold-voltage modulation capability of FD-SOI devices. Simulation results and measurements of a fabricated chip showed that the chip applying the LSL approach correctly operates at VDDL = 0.6 V and VDDH = 1.2 V under 2 V pMOS RBB while suppressing the static dc current in the VDDH domain. We also demonstrate that adaptive RBB control for pMOS can maintain effectiveness of this approach under process and temperature variations.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Multi-VDD design to include multiple voltage domains within a chip is one of the key techniques in low-power oriented SoCs [1]. Lowering the supply voltage (VDD) contributes to power reduction but it is likely that some circuits within a SoC cannot be made to operate at lower voltage. One reason is that lowering the supply voltage degrades the performance of MOS transistors, leading to degradation of circuit speed. If the circuit is required to operate at high clock frequency or is on the critical path, the voltage cannot be lowered. Another reason is that memory circuits provided as SRAM or ROM macros usually do not work at low voltage. To enjoy power reduction by lowering the supply voltage, multi-VDD design is essential which allows the reduced VDD domain and the nominal VDD domain to coexist in a SoC.
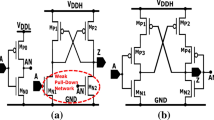
Realizing multi-VDD design comes with several overheads. In particular, when an output signal of a lower-VDD (VDDL) circuit is connected to the input of a higher-VDD (VDDH) circuit, a level shifter (LS) circuit needs to be inserted at the interface. The conventional cross-coupled LS [2] and the conventional current-mirror LS [3] are depicted in Fig. 1(a) and (b), respectively. LS converts the voltage swing VDDL to the voltage swing VDDH but its delay and power dissipation become a critical overhead. In addition, LS requires both VDDH and VDDL as the power supply. This makes the physical design using the standard P&R flow significantly complicated [4], and thereby increases design effort. Authors of [5] proposed another LS circuit which requires only one supply (VDDH). This eliminates the layout constraint that both VDDH and VDDL supplies must be connected to LS and hence mitigates the complexity in physical design. However, the overheads in delay, power and area remain as problems.

In this paper, we propose a novel technique to make LS insertion unnecessary in the multi-VDD design by the combination of body-bias control and threshold-voltage modulation capability of FD-SOI devices. We augmented the original conference paper [6] with the following contents:
-
Impact by process variation
Process variation is one of the serious concerns in modern scaled devices. We investigated how much the process variation affects effectiveness of the proposed LSL approach through simulations. We also studied how much the approach can adaptively deal with the impact of the variation.
-
Impact by temperature variation
The temperature of a chip varies during the operation by its own heat dissipation. Since effective threshold voltage of MOS transistors changes with the temperature [1], we investigated how much the temperature variation impacts on the proposed approach. This evaluation was conducted through real chip measurements.
-
Influence of gate types in receivers
In the proposed LSL approach, a VDDH receiver gate with reverse-body-biasing receives the VDDL signal at the VDDL/VDDH interface. The paper [6] demonstrated that the gate types (e.g. NAND/NOR/inverter) of the receiver affect the delay. We newly added detailed simulation results in this paper showing that the receiver gate types also affect the lowest VDDL voltage to ensure the receiver’s operation. We added description about underlying common mechanisms on how the receiver gate types relate to the delay and the lowest VDDL voltage.
-
More detailed analysis on delay in cascaded gates influenced by RBB
RBB is applied to the whole pMOS transistors in the VDDH domain in the proposed LSL approach. We added more detailed analysis on how pMOS RBB influences the gate delay and demonstrated that only half of the gates in cascaded gates were made slower whereas others were made slightly faster.
We presented a part of the results for the process variation at another conference [18] but we have included new results to this paper. The rest of this paper is organized as follows: Sect. 2 describes the background and Sect. 3 presents the LSL approach that we propose. Section 4 presents simulation results and Sect. 5 presents measured results for a fabricated microprocessor test chip. Section 6 describes conclusions and the future work.
2 Background
First, we briefly describe the reason why LS is required when an output signal of a VDDL circuit is connected to the input of a VDDH circuit. As shown in Fig. 2, when the output of the VDDL circuit (INV1) is logical “1”, the voltage of the node N1 is raised to VDDL. However, if VDDL < VDDH-|Vt,p|, the pMOS transistor M1 is not turned off, where Vt,p is the threshold voltage of M1. Since the nMOS transistor M2 is ON at this time, the static dc current flows from VDDH to the ground in INV2, dissipating static power. This is caused by the fact that the voltage at the node N1 is not raised higher than VDDL. Conventionally, this problem has been solved by inserting LS to N1 to convert the voltage swing from VDDL to VDDH. Notice that LS is not needed when a VDDH circuit drives a VDDL circuit. This is because the gate voltage of a pMOS transistor in VDDL circuit is raised to VDDH and thereby it is completely turned off.

VDDH gate driven by VDDL gate.
As described in Sect. 1, LS insertion has critical overheads in delay, power, design complexity and area. To reduce the number of required LSs, a clustered voltage scaling (CVS) approach was proposed [2]. In CVS, low voltage clusters are built in the circuit in such a way that there is no VDDL gate driving a VDDH gate. This is done by assigning VDDL to the gates starting from the circuit outputs depending on their slack in the path delay, eliminating the use of LS in the combinational logic. LS insertion is required only at the primary outputs of the circuits. Various algorithms were studied for cluster construction to maximize the power reduction [7, 8]. When the primary outputs of the combinational logic are connected to flip-flops (FFs), use of level-shifting FF circuits [9, 10] can eliminate the LS insertion. The level-shifting FF receives the data input with VDDL swing and produces the Q output with VDDH swing. These CVS based approaches basically try to minimize the number of required LSs by restricting the level-shifting points to the primary outputs of the combinational logic or FFs. Hence, they cannot be applied to a general SoC design in which the output signal of a pre-designed logic module operating at VDDL needs to be connected to the input of another pre-designed module operating at VDDH. In this case, LSs need to be inserted at the module boundary. Thus, the CVS based approaches cannot completely eliminate the required LSs at the entire chip level.
Diril et al. [11, 12] proposed a level-shifter free approach to use an additional threshold voltage. The concept is that they achieve VDDL > VDDH-|Vt,p| by employing larger |Vt,p|. As shown in Fig. 3, the second threshold voltage Vt,p2 whose magnitude is larger than the original Vt,p is used in the pMOS transistors of VDDH gates driven by VDDL gates. This approach reduces the static dc current flowing through the transistor when the gate voltage is VDDL. An approach similar to this idea was addressed in [13]. There is a performance penalty due to the increase of the rise time. The biggest advantage is the fact that it has no energy or area penalties. However, this approach has two critical problems: one is the requirement for the manufacturing. Although the multi-Vt process is available in a modern technology, the magnitude of Vt,p2 for this approach may not be the same as the High-Vt (HVT) which is regularly provided by the semiconductor vendors. Even if it is possible to add a special Vt for this purpose, there will be an extra cost. The other problem of this approach is the robustness for the process variation. Even though we determine the optimum value for Vt,p2 at the design stage, the threshold voltage varies in real chips [1]. When Vt,p2 is varied to smaller magnitude, the static dc current would not be reduced sufficiently. To deal with this, much larger Vt,p2 value has to be chosen considering the process variation but it further increases the delay. This problem becomes more serious as the device is scaled.

Level shifting NAND [11].
The problems described above motivated us to study an approach for variation-tolerant multi-VDD design that requires no level-shifter insertion and no addition of extra threshold voltage.
3 Proposed Approach
First, we describe an approach we propose which employs body-bias control. Next we present the feature of an SOTB (Silicon on Thin BOX) device that maximizes effectiveness of the proposed approach.
3.1 Body-Bias Control to PMOS Transistors in VDDH Domain
We propose an approach to reduce the static dc current by raising the threshold voltage of pMOS transistors through the body bias control to the VDDH domain. This approach does not require any addition of extra Vt at the manufacturing. Moreover, the magnitude of Vt to minimize the static dc current can be adjusted adaptively in accordance with the process and temperature variations by varying the body bias. However, it is necessary to separate the body bias to pMOS transistors in the VDDH domain from that in the VDDL domain, and to apply a reverse body bias (RBB) to pMOS in the VDDH domain. To implement this, there are two possible approaches: one is a fine-grained approach to apply RBB only to the gates receiving the VDDL signal (i.e. the receiver gates), and the other is a coarse-grained approach to apply RBB to pMOS transistors in the entire VDDH domain. The fine-grained approach may be ideal to minimize the delay penalty due to the raised Vt in pMOS. However, it suffers from significant increase in area and the complexity of physical layout. This is because a triple-well process technology is required to separate the n-well (and hence the deep n-well) for the receiver gates from that for non-receiver gates. Different deep n-wells must be placed apart from each other with larger space in between as compared to the inter p-well separation. This incurs significant area penalty. Another difficulty in the fine-grained approach is that only the receiver gates need to be extracted from the VDDH domain and placed in a different domain to apply RBB. This is because zero body bias (ZBB) is applied to the non-receiver gates in the original VDDH domain. This requirement clearly increases the complexity of physical design. Considering these problems, we think that the fine-grained approach will not be realistic in real SoCs.
Our proposal is the coarse-grained approach. Since it applies RBB to pMOS transistors in the entire VDDH domain, there is no penalty in area and in the design complexity. However, the rise delay increases at all gates in the VDDH domain because RBB is applied to all pMOS transistors. The good news is that in a gate chain the rise operation typically occurs every other gate and hence delay penalty is incurred only at half of the gates at a time. In addition, the fall delay slightly reduces when applying RBB to pMOS transistors. This is because the pMOS transistor with raised Vt is turned off earlier than that of the non-RBB case at the fall transition. We will quantitatively discuss the delay penalty of our approach in Sect. 4. The n-well for the VDDH domain needs to be separated from the n-well for the VDDL domain so independent body bias control can be performed at both voltage domains.
3.2 SOTB Device
SOTB is a FD-SOI (Fully Depleted Silicon on Insulator) device with ultra-thin (10 nm) BOX layer [14]. Figure 4 depicts a schematic of SOTB MOS transistors. Vt can be controlled by changing the voltage of underlying n-well or p-well, which has the same effect as changing the body bias in a bulk-MOS device. Thanks to the ultra-thin BOX, SOTB has a large body-bias coefficient. It is reported that Vt shift is more than 0.15 V by the RBB voltage of 1 V [15]. Moreover, since the body bias is applied from below the insulating BOX layer, we do not have to concern about the junction leakage between the source/drain and the body. Inter-well leakage between the deep n-well and p-well is negligible within the voltage range considering the BOX reliability for RBB. Authors of [15] reported that they applied RBB of 2.0 V, observing that Vt of a pMOS transistor is shifted from 0.2 V to approximately 0.5 V. The features of SOTB described above enhance the capability of body-bias control for threshold-voltage modulation as compared to the bulk counterpart. By combining this capability with the coarse-grained body-bias control for pMOS transistors, we suppress static dc current in a LSL multi-VDD design.

Schematic cross section of SOTB MOS transistors.
4 Results from Simulation
4.1 Simulation Setup
We conducted simulation analyses for delay, static current and active energy by using a HSPICE simulator and the 65 nm SOTB MOS transistor models. The nominal supply voltage (i.e. VDDH) is 1.2 V. In comparative evaluations with the conventional approach using LS, we used a LS circuit shown in Fig. 5 [16], instead of LSs depicted in Fig. 1. This is because evaluations for the wide range of VDDL require a LS circuit that converts the corresponding input voltage (i.e. VDDL).

LS circuit [16].
In [16], it is reported that the delay of the cross-coupled LS shown in Fig. 1(a) increases significantly as the input voltage is reduced, and the delay is more than 10 ns even for the 0.6 V input in the 65 nm SOTB technology. Considering that the inverter delay is approximately 30 ps in the same technology, the cross-coupled LS is too slow. The current-mirror LS depicted in Fig. 1(b) gives the delay of ~200 ps for the same input voltage but consumes 100X energy. In contrast, LS shown in Fig. 5 gives the delay of 200 ps for the 0.6 V input at almost the same energy dissipation as the cross-coupled LS. Circuits of inverter, NAND and NOR gates used in the simulation are those of the standard cells provided in the 65 nm SOTB library.
In the LSL approach, logic gates in the VDDH domain receiving the VDDL input (i.e. receiver gates) are most affected in delay and static current. Logic gates receiving the outputs of the receiver gates are affected next, because output signals of the receiver gates may not necessarily produce the full swing between 0 V and VDDH. Since LS shown in Fig. 5 produces a non-inverted output, we define an equivalent receiver as two cascaded logic gates consisting of “a front-end (FE) NAND/NOR/inverter gate receiving the VDDL input” plus “a back-end (BE) inverter gate operating at VDDH”, as depicted in Fig. 6. Notice that RBB to pMOS transistors (referred to as pRBB) is applied to both the FE receiver and the BE inverter in the LSL approach, unlike the approach with LS. We discuss electrical characteristics of LS-based and LSL approaches by focusing on LS and the equivalent receivers.

Equivalent receivers: (a) NAND-type, (b) inverter-type and (c) NOR-type.
4.2 Voltage Limit for VDDL
Before discussing the delay or energy, we discuss how much we can reduce the VDDL voltage for the stable operation and understand the mechanism that determines the lowest VDDL voltage. We investigated VDDLLIMIT which is the lowest operable input voltage of the equivalent receivers while changing the pRBB voltage. Figure 7 shows the output voltage of the FE NAND receiver and the output voltage of the BE inverter at ZBB as a function of the VDDL voltage. We assumed the input voltage transition from 0 V to VDDL. For the VDDL voltage range from 1.2 V to 0.75 V, the correct output voltage of the BE inverter (i.e. 1.2 V) can be obtained. However, for the VDDL voltage below 0.75 V, the BE inverter produces incorrect output voltage 0 V because the FE NAND receiver does not produce sufficient low output voltage. In contrast, as shown in Fig. 8, by applying pRBB of 2 V the BE inverter produces the correct output voltage even at 0.6 V. This is because the output voltage of the FE NAND receiver is suppressed to low voltage even below 0.75 V. Thus, VDDLLIMIT reduces from 0.75 V to 0.6 V by applying pRBB of 2 V. The mechanism of this can be explained as follows.

Output voltages of the FE NAND receiver and the BE inverter at ZBB.

Output voltages of the FE NAND receiver and the BE inverter at pRBB = 2 V.
As depicted in Fig. 6(a), when the input voltage is VDDL, the contention occurs between the current flowing incompletely turned-off pMOS transistors and the current flowing turned-on nMOS transistors in the FE NAND receiver. As reducing the VDDL voltage, the current flowing incompletely turned-off pMOS increases. This raises the output voltage of the FE NAND receiver, resulting in producing the incorrect output voltage at the BE inverter. By applying pRBB, the current flowing incompletely turned-off pMOS at the FE receiver is reduced and thereby the contention is reduced. As a result, the FE receiver produces the sufficiently low output voltage even for lower VDDL input, leading to the correct operation at the BE inverter.
Next, we investigated VDDLLIMIT of other types of equivalent receivers such as inverter-type or NOR-type while changing the pRBB voltage. Figure 9 shows the results. It is demonstrated that VDDLLIMIT reduces as we increase pRBB at any type of equivalent receivers. Another important observation is that for any pRBB voltage, VDDLLIMIT of the NAND-type is the highest among three, followed by the inverter-type and that of the NOR-type is the lowest. This reason can be explained by the contention occurring in the FE receiver as well. As depicted in Fig. 6(a) and (c), pMOS pull-up transistors are in parallel in the NAND-type receiver and are in series in the NOR-type. Hence, the combined conductance of incompletely turned-off pMOS pull-up transistors in the NAND-type is larger than that of the NOR-type, leading to larger contention in the NAND-type than the NOR-type. Since the inverter-type receiver has no parallel or series pMOS pull-up transistors, the degree of the contention is in the middle.

VDDLLIMIT of equivalent receivers as a function of pRBB voltage.
Since we aim to investigate the potential of RBB in the proposed LSL approach, we choose the pRBB voltage as 2 V which is close to the allowable maximum RBB voltage in this study. As seen in Fig. 9, VDDLLIMIT is lowered to or below 0.6 V at any type of the receivers among NAND/NOR/inverter for pRBB of 2 V. This indicates that the circuit in the VDDH domain could work for the VDDL voltage of as low as 1/2 of the VDDH voltage in the proposed LSL approach.
4.3 Delay
We compared the delay of LS and the equivalent receiver circuits in the LSL approach, assuming that they drive 4 inverter cells as the load capacitance. We analyzed rise and fall delays and found that the fall delays are shorter than the rise delays when applying pRBB of 2 V. The reason is described later.
Figure 10 shows the rise delay of LS and the equivalent receivers as a function of the VDDL voltage. For the VDDL voltage of 0.65 V and higher, any equivalent receivers give smaller delay than LS. In contrast, at VDDL of 0.6 V, the delay of a NAND-type equivalent receiver excesses that of LS but both NOR-type and inverter-type receivers still 2X faster than LS. While the inverter-type receiver becomes slower than LS at VDDL of 0.5 V, the NOR-type receiver remains faster than LS even at VDDL of 0.45 V.

Rise delay of LS and equivalent receivers.
We investigated the reason why the degree of delay increase is different among receivers. It turned out that the delay of equivalent receivers is determined by the combination of the following two factors: (1) the conductance degradation of pMOS due to RBB and (2) the contention between an incompletely turned-off pMOS and a turned-on nMOS described earlier. In the NOR-type equivalent receiver depicted in Fig. 6(c), pMOS transistors are in series and nMOS transistors are in parallel in the FE receiver. Due to this, the conductance degradation at the pMOS transistors affects more than the contention when VDDL is not such a low voltage. However, as VDDL is lowered, the static dc current flowing through pMOS increases, and thereby the contention becomes dominant. Figure 11(c) shows the results for the rise and fall delays of a NOR-type equivalent receiver for VDDL of 0.9 V and 0.6 V. At VDDL of 0.9 V, the fall time is larger than the rise time. This is because the rise time of the front-end NOR receiver is large due to pRBB and the output of the back-end inverter is made slow. In contrast, at VDDL of 0.6 V, the rise time becomes larger than the fall time. Since the increased dc current flowing through pMOS hinders the discharging of nMOS transistors (i.e. contention), the fall operation at the front-end receiver becomes slower. Furthermore, the rise operation at the back-end inverter gets slower due to pRBB. As a result, the magnitude relation between the rise and fall times gets inverted.

Rise and fall delays of equivalent receivers: (a) NAND-type, (b) inverter-type and (c) NOR-type.
In the NAND-type and inverter-type equivalent receivers, the rise times are larger than the fall times both at 0.9 V and 0.6 V for VDDL, as shown in Fig. 11(a) and (b). Since there are no series pMOS transistors in those circuits, the influence of the contention is dominant over that of the conductance degradation.
In the LSL approach, we also need to consider the delay degradation due to pRBB at the gates that follow the equivalent receiver. We analyzed the path delay for gate chains with 30 stages, in which LS or an inverter-type equivalent receiver is followed by cascaded inverters. We assumed that the cascaded inverters are minimum sized cells provided in the library and each gate in a path drives 4 inverter cells as the load capacitance. Figure 12 shows the results for the total delay of the gate chain as a function of the number of stages N at VDDL = 0.6 V and VDDH = 1.2 V. We assumed the pRBB voltage as 2 V for the LSL approach. For comparison, we also analyzed the path delay for the LSL approach with ZBB.

Path delay for gate chains as a function of the number of stages.
The delay values for N = 1 correspond to the rise delays of LS or the equivalent receivers. In “LSL with ZBB”, since no pRBB is applied to the equivalent receiver, the fall operation at the FE inverter in the equivalent receiver gets slower due to the contention and thereby the rise operation at the BE inverter becomes slower. As a result, the rise delay for the equivalent receiver with ZBB becomes larger than the rise delays of LS and the equivalent receiver with 2 V pRBB. In the conventional LS based technique and the LSL approach with ZBB, their cascaded inverters in the second and subsequent stages are both the inverters with ZBB and hence their path delays almost match. In contrast, in the LSL approach with 2 V pRBB, the delay at N = 1 is approximately 100 ps smaller than that of the LS based approach. As the number of stages increases, the path-delay difference between “LS based” and “LSL with 2 V pRBB” gradually reduces due to the performance degradation by pRBB. Interestingly, the path-delay difference is not reduced constantly at each stage. To investigate the reason, we analyzed the delay of the inverter at each stage. Figure 13 shows the results.

Delay of the inverter at each stage.
In the cascaded inverters in this analysis, the fall operation occurs at the even number stages, while the rise does at the odd number stages. At the second stage (i.e. stage_number = 2), since the inverter in the LS based approach receives the LS output signal whose waveform is not so steep, the delay becomes larger than that of any other inverters at the even number stages. In contrast, in the LSL approach with 2 V pRBB, the delay at stage_number = 2 is the “fall” delay and hence it is not degraded by pRBB. Rather, the delay becomes smaller than the delay without applying pRBB. This is because the pMOS transistor is weakened by pRBB and thereby the contention at the switching is reduced. This phenomenon can be seen at other even number stages, in which the fall delay of the inverter with 2 V pRBB is 18% smaller than that of the inverter with ZBB in the LS based approach. Meanwhile, at the odd number stages, the delay is the “rise” delay and hence is degraded by pRBB. As a result, the delay at the odd number stage becomes 55% larger than that in the conventional LS based approach.
Thus, in the LSL approach with 2 V pRBB, performance degradation caused by applying RBB does not occur at all gates but instead occurs only at half of the gates. In the remaining half gates, the delay rather reduces. As demonstrated in Fig. 12, the path delay for the LSL approach with 2 V pRBB is smaller than that for the conventional LS-based technique if the number of stages is less than 23.
Another strong point of the proposed LSL approach is the fact that pRBB is always applied to the circuits in the VDDH domain. Although applying RBB at lower voltage degrades the circuit performance significantly, we do not need to be concerned about it in the proposed LSL approach.
4.4 Static Current
Figure 14 shows the results for static current in LS and equivalent receivers. When VDDL is 1.2 V, the static current of the equivalent receivers is smaller than that of LS, because there is no contention and applying pRBB reduces leakage of the equivalent receivers. As we reduce VDDL, the static current of the equivalent receivers drastically increases even with pRBB. It should be noted that for VDDL of 0.9 V, the static current for pRBB = 0.5 V is more than 50X as compared to that for pRBB = 2 V. For VDDL of 0.6 V, this difference reduces, but even only a receiver draws static current of as much as 50 μA when pRBB is 0.5 V. The largest pRBB voltage allowed in the technology should be applied as long as the maximum delay constraint is met. Difference in the static current among equivalent receivers is due to the difference in the dc current flowing through the pMOS transistors. Compared with the NAND-type and the inverter-type equivalent receivers, the NOR-type counterpart draws less dc current for the same pRBB voltage because pMOS transistors are in series.

Static current in LS and equivalent receivers.
4.5 Active Energy
Figure 15 shows the results for active energy of LS and equivalent receivers with pRBB of 2 V. This energy includes both the dynamic energy for charging and discharging the output capacitance and the static energy. For the VDDL voltage higher than 0.8 V, energy dissipation of the equivalent receivers is only 60% of that of LS. As we reduce VDDL, the energy of the equivalent receivers goes up due to the increased static dc current. When the VDDL voltage is 0.6 V, the NAND-type and the inverter-type equivalent receivers consume 1.5X energy as compared to LS. In contrast, the NOR-type equivalent receiver dissipates less energy than LS until VDDL is lowered to ~0.5 V. The difference in active energy dissipation among equivalent receivers results from the difference in the static energy component.

Active energy of LS and equivalent receivers.
4.6 Influence by Process Variation
We studied an impact of global and local process variations on effectiveness of the proposed LSL approach. First, we investigated how much VDDLLIMIT of the equivalent receiver is affected by the global variation. Figure 16 shows the results from SPICE simulations for VDDLLIMIT of an inverter-type receiver at the five process corners. VDDLLIMIT for the SF (slow nMOS, fast pMOS) corner is 0.02 V higher than that of TT due to higher conductance of pMOS transistors. By adaptively increasing pRBB to 2.5 V, VDDLLIMIT becomes equal to the value at TT.

VDDLLIMIT of an inverter-type receiver at the five process corners.
We also investigated an impact of local variations. Generally, designers should pay attention to the stability of a memory cell under local variations, because the conductance of individual nMOS and pMOS transistors within a memory cell varies. In particular, since RBB is applied only to pMOS transistors in the proposed LSL approach, the balance between nMOS and pMOS in the conductance becomes worse as compared to ZBB. We evaluated the static noise margin (SNM) of a flip-flop cell under the local process variation. SNM is determined by the butterfly curves for cross-coupled inverters [1] in a master or slave latch of a flip-flop cell. Unlike an SRAM cell, we do not need to be concerned about the “read SNM” in a flip-flop because there is no structure to share the bit line in the flip-flop. We do not need to care about the “write SNM” in a flip-flop because the inverter-loop in a latch is electrically cut off at the write operation. Hence, we only investigated the “hold SNM” of master and slave latches in a flip-flop cell.
Assuming a design in which a flip-flop does not become a receiver but pRBB of 2 V is applied to all internal pMOS transistors, we conducted Monte Carlo simulations for Vt variation for 1,000 times under the condition of ±0.1 V at 5σ at the five process corners. Since RBB is applied only to pMOS in the proposed approach, the balance between nMOS and pMOS becomes worst at the FS corner. As shown in Fig. 16, applying 2 V pRBB is required to achieve VDDLLIMIT = 0.5 V at TT, whereas only 1.4 V pRBB is just enough for achieving the same VDDLLIMIT at the FS corner. Hence, we investigated influence of local variations at the FS corner for a flip-flop with 1.4 V pRBB and without it (i.e. ZBB). Figure 17 shows the butterfly curves and the histogram of SNM for the hold operation in a master latch for the FS corner with pRBB = 1.4 V.

(a) Butterfly curves of master latch of a flip-flop in the hold operation for the FS corner with pRBB = 1.4 V; (b) Distribution of SNM.
The mean value of SNM was 403 mV for pRBB = 1.4 V. We compared these results with those for ZBB (Fig. 18). The mean value of SNM for ZBB was 402 mV. Thus, the hold SNM of a master latch did not change so much even if we apply RBB to pMOS for the FS corner. This means that the proposed LSL approach does not impair robustness of the latch operation under the local variation. We also evaluated SNM of the slave latch as well, but it was almost the same as that of the master latch.

(a) Butterfly curves of master latch of a flip-flop in the hold operation for the FS corner with ZBB; (b) Distribution of SNM.
5 Results from Chip Measurements
5.1 Test Chip Design and Measurement Environment
We designed and fabricated a test chip consisting of a 32-bit MIPS based microprocessor core and 8 KB caches for instruction and data in a 65 nm SOTB technology. The caches were implemented only with standard cell flip-flops and logic gates. Figure 19 shows the layout of the test chip. We separated the power supply of the cache module from that of the microprocessor core so the microprocessor core and the cache module are made to operate at VDDL and VDDH, respectively. The cache module is the target of applying pRBB in the proposed LSL approach. Figure 20 shows an evaluation board and measurement environment. The test chip and FPGA are equipped on the evaluation board where the FPGA feeds a program code and data to the test chip and monitors the output. We ran the test chip by feeding a code containing a loop of instructions to write data to the cache. We conducted measurement at 45 °C and 65 °C by setting the evaluation board into a temperature chamber.

Layout of the test chip.

(a) Evaluation board; (b) Measurement environment.
5.2 Measured VDDLLIMIT
First we measured VDDLLIMIT of the cache module under the VDDH of 1.2 V. As shown in Fig. 21, VDDLLIMIT reduces from 0.58 V to 0.48 V by increasing pRBB from 0 V to 2 V at 20 °C. This is because the contention is mitigated by applying pRBB as described in Sect. 4.2. When the temperature goes up to 65 °C, VDDLLIMIT increases by 0.02 V at pRBB = 2 V. By increasing pRBB to 2.5 V, VDDLLIMIT returns to the value at 20 °C (i.e. 0.48 V). These phenomena can be interpreted as follows. First, as the temperature goes up, |Vt,p| reduces [1] and thereby the current flowing through the incompletely turned-off pMOS increases at the receiver gate. This leads to the increase of the contention and hence raising VDDLLIMIT. Increasing pRBB from 2 V to 2.5 V further increases |Vt,p| and reduces the contention, resulting in lowering VDDLLIMIT.

Measured VDDLLIMIT.
5.3 Measured Static Current and Power Dissipation
Figure 22(a) shows the measured results for the static current flowing through the cache module at 20 °C. We measured the static current by stopping the clock after executing above described program for the sufficient time. In ZBB, as we lower the VDDL voltage, the static current starts to increase at 0.9 V and reaches 1.6 mA at 0.6 V. When we apply pRBB of 2 V, the static current keeps constant until 0.8 V and slightly increases for the lower VDDL voltage. It should be noted that for the VDDL voltage of 0.6 V the static current is only 1/5 of that of the ZBB case.

Measured static current at (a) 20 °C, (b) 45 °C and (c) 65 °C.
According to the simulation results, that static current of the equivalent receiver increases to 1000X–5000X even with 2 V pRBB when lowering the VDDL voltage from 1.2 V to 0.6 V. However, as summarized in Table 1, the number of receivers in this design is only 0.2% of the total cells. As a result, the total static current of the cache module does not increase so much when we apply pRBB of 2 V. Even though the number of receivers is very small, the increase of the static current is visible with ZBB. This is because the static current of the equivalent receiver increases to more than 20,000X with ZBB when the VDDL voltage is lowered from 1.2 V to 0.6 V. The static current for VDDL = 1.2 V is purely the leakage because VDDL and VDDH voltages are the same. Applying pRBB reduces the leakage component as well.
Figure 22(b) and (c) show the measured results for the static current at 45 °C and 65 °C, respectively. By applying pRBB = 2 V for VDDL = 0.6 V, the static current was reduced to 1/3 at 45 °C and to 2/5 at 65 °C. Thus, the proposed LSL approach effectively reduced the static current increasing with lowering VDDL for a wide range of the temperature.
We also evaluated the impact of the proposed approach on the entire power dissipation. We measured power dissipation of the cache module at 20 °C. As described in Sect. 5.1, the VDDL supply was connected to the microprocessor core and the VDDH supply was to the cache module. Since we reduced the VDDL voltage to 0.6 V, the microprocessor core was made to operate at 0.6 V. Due to this, we chose 8 MHz as the clock frequency to ensure the correct operation of the microprocessor core. Figure 23(a) and (b) show the results for the measured power dissipation. It is demonstrated that the share of the static power component increases as we lower the VDDL voltage.

Share of static power component (meas.) for (a) ZBB and (b) pRBB = 2 V at 20 °C.
Although the share of the static power component is 11% at VDDL of 0.6 V for ZBB, it is reduced to 3% by applying pRBB of 2 V. Thus, the measured results at real silicon demonstrated that the proposed LSL approach enabled us to suppress the static current and thereby effectively reduce the static power component in the entire power dissipation.
6 Conclusions and Future Work
We proposed an LSL approach to employ body-bias control to pMOS transistors in a SOTB device for suppressing the static dc current in the multi-VDD design. Results from simulations and measurements at a microprocessor test chip demonstrated effectiveness of the proposed approach under process and temperature variations.
As the future work, delay evaluation at real silicon is required. This time the objective of the chip measurement was to demonstrate the feasibility of the proposed LSL approach. Hence, we applied it to an existing design of a microprocessor [17] and showed that it works at VDDL = 0.6 V and VDDH = 1.2 V. Meanwhile, this application imposed a constraint for the Fmax-based delay measurement. Since the PLL we used only produces a clock signal with 0.5 MHz increment, the delay difference less than 8 ns could not be detected at the measurement around 8 MHz. This is because the clock periods are 125 ns at 8 MHz and 133 ns at 7.5 MHz, respectively, leading to the difference of 8 ns. To measure the delay difference less than 1 ns, we need to design a special circuit to which the proposed LSL approach is applied. Furthermore, to enhance the capability of this LSL approach, combination with other approaches such as an increased-L (increased transistor length) technique should be explored. Since it also increases |Vt,p| and can be used locally, an optimized combination may produce better results and hence is the future work.
References
Weste, N., Harris, D.: CMOS VLSI Design, 4th edn. Addison-Wesley, Boston (2011)
Usami, K., Horowitz, M.: Clustered voltage scaling technique for low-power design. In: Proceedings of the International Symposium on Low Power Design (ISLPED), pp. 3–8, April 1995
Itoh, K.: VLSI Memory Chip Design, pp. 84–87. Springer, Heidelberg (2001). https://doi.org/10.1007/978-3-662-04478-0. The Current-Mirror Amplifier
Keating, M., Flynn, D., Aitken, R., Gibbons, A., Shi, K.: Low Power Methodology Manual. Springer, Boston (2007). https://doi.org/10.1007/978-0-387-71819-4
Puri, R., et al.: Pushing ASIC performance in a power envelope. In: Proceedings of the 40th Design Automation Conference (DAC), pp. 788–793, June 2003
Usami, K., Kogure, S., Yoshida, Y., Magasaki, R., Amano, H.: Level-shifter-less approach for multi-VDD design to use body bias control in FD-SOI. In: Proceedings of the 25th IFIP/IEEE International Conference on Very Large Scale Integration (VLSI-SoC), October 2017
Chen, C., Srivastava, A., Sarrafzadeh, M.: On gate level power optimization using dual-supply voltages. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 9(5), 616–629 (2001)
Donno, M., Macchiarulo, L., Macii, A., Macii, E., Poncino, M.: Enhanced clustered voltage scaling for low power. In: Proceedings of the 12th ACM Great Lakes Symposium on VLSI (GLSVLSI), pp. 18–23, April 2002
Hamada, M., et al.: A top-down low power design technique using clustered voltage scaling with variable supply-voltage scheme. In: Proceedings of the IEEE Custom Integrated Circuits Conference (CICC), pp. 495–498, May 1998
Ishihara, F., Sheikh, F., Nikolic, B.: Level conversion for dual-supply systems. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 12(2), 185–195 (2004)
Diril, A., Dhillon, Y., Chatterjee, A., Singh, A.: Level-shifter free design of low power dual supply voltage CMOS circuits using dual threshold voltages. In: Proceedings of the 18th International Conference on VLSI Design (VLSID), January 2005
Diril, A., Dhillon, Y., Chatterjee, A., Singh, A.: Level-shifter free design of low power dual supply voltage CMOS circuits using dual threshold voltages. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 13(9), 1103–1107 (2005)
Tawfik, S., Kursun, V.: Low power and high speed multi threshold voltage interface circuits. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 17(5), 638–645 (2009)
Tsuchiya, R., et al.: Silicon on thin BOX: a new paradigm of the CMOSFET for low-power and high-performance application featuring wide-range back-bias control. In: IEEE International Electron Devices Meeting (IEDM) Technical Digest, December 2004
Yamamoto, Y., et al.: Ultralow-voltage operation of Silicon-on-Thin-BOX (SOTB) 2Mbit SRAM down to 0.37V utilizing adaptive back bias. In: Symposium on VLSI Technology, June 2013
Nakamura, S., Usami, K.: Level converter design for ultra-low voltage operation in FDSOI devices. In: Proceedings of the 28th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), July 2014
Usami, K., et al.: Design and control methodology for fine grain power gating based on energy characterization and code profiling of microprocessors. In: Proceedings of the 19th Asia and South Pacific Design Automation Conference (ASP-DAC), pp. 843–848, January 2014
Usami, K., Kogure, S., Yoshida, Y., Magasaki, R., Amano, H.: Level-shifter free approach for multi-VDD SOTB employing adaptive Vt modulation for pMOSFET. In: Proceedings of the IEEE SOI-3D-Subthreshold Microelectronics Technology Unified Conference (S3S), October 2017
Acknowledgment
This work was partially supported by JSPS KAKENHI S Grant Number 25220002. This work was supported by VLSI Design and Education Center (VDEC), the University of Tokyo in collaboration with Synopsys, Inc. and Cadence Design Systems, Inc. This presentation was supported by SIT Research Center for Green Innovation.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 IFIP International Federation for Information Processing
About this paper

Cite this paper
Usami, K., Kogure, S., Yoshida, Y., Magasaki, R., Amano, H. (2019). Level-Shifter-Less Approach for Multi-VDD SoC Design to Employ Body Bias Control in FD-SOI. In: Maniatakos, M., Elfadel, I., Sonza Reorda, M., Ugurdag, H., Monteiro, J., Reis, R. (eds) VLSI-SoC: Opportunities and Challenges Beyond the Internet of Things. VLSI-SoC 2017. IFIP Advances in Information and Communication Technology, vol 500. Springer, Cham. https://doi.org/10.1007/978-3-030-15663-3_1
Download citation
DOI: https://doi.org/10.1007/978-3-030-15663-3_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-15662-6
Online ISBN: 978-3-030-15663-3
eBook Packages: Computer ScienceComputer Science (R0)