
Abstract
Depth prediction from monocular images is an important task in many computer vision fields as monocular cameras are currently the majorities of the image acquisition equipment, which is used in many fields such as stereo scenes understanding and Simultaneous Location and Mapping (SLAM). In this paper, we regard depth prediction as an image generation task and propose a new method for monocular depth prediction using Conditional Generative Adversarial Nets (CGAN). We transform the corresponding depth images of RGB images as the Relative depth images by dividing the maximum value, then we use an encoder-decoder as the generator of CGAN, which is used to generate depth images corresponding to input RGB images, the discriminator is constituted by an encoder, which is used to discriminate whether the input images are true or fake by evaluating the difference between input images. By learning the potential correspondence between pixels of RGB images and depth image, we could finally obtain the corresponding depth images of test RGB images with our CGAN model. We test our model with different objective functions in TUM RGB-D dataset and NYU V2 dataset, and the result shows excellent performance.
Similar content being viewed by others


Keywords
1 Introduction
Depth prediction is one of the fundamental tasks in computer vision, which could be widely used in many fields such as SLAM, autonomous driving, augmented reality (AR) and stereo scenes understanding. Also, many other computer vision tasks such as object detection, semantic segmentation can benefit from depth prediction. Depth prediction is mainly used for monocular or stereo images which depth can’t be obtained directly. At present, depth sensors such LiDARs, Kinect and stereo cameras are the main image depth acquisition equipment, however, these depth sensors have limitations in application such as cost-prohibitive, sparse measurement, sunlight-sensitive and power-consuming. Meanwhile, monocular cameras are still the majorities of the image acquisition equipment and are widely used in our lives. Thus, monocular depth prediction now becomes an important task to be solved.
Traditional depth prediction methods are mostly based on mathematical or physical theories, such as Triangulation, that is, for two or more monocular images, through the feature matching between adjacent images, we could obtain the real distances according to the corresponding feature points by Trangulation. Methods based on physical theories, such as Structure-from-Motion (SFM) [1], Shape-from-Shading (SFS) [2], are mostly relied on the Lambertian Surface reflection Model. These methods discard most information of images, which lead to the lack of effective constraints and large errors.
There is another kind of methods of depth prediction, the probabilistic graphical models. In [3], images are divided into sub-pixel blocks of the same category, and the depth information between sub-pixel blocks of the image is inferred by global MRF, which could finally estimate the 3D structure of objects in images. Saxena et al. [4] obtains the depth map of the image using MRF and Laplacian Model.
Recent years, some excellent depth prediction methods based on deep convolutional neural network (deep CNN) have been proposed. Eigen et al. [5] uses two deep network stacks: Global Coarse-Scale Network and Local Fine-Scale Network to predict the predicts the depth of the scene at a global level and local level respectively. Laina et al. [6] uses the fully convolutional residual network to obtain the depth images by its up-sampling blocks.
In this paper, we propose a depth prediction method based on CGAN [7]. Compared with other methods based on deep convolutional neural network, we regard depth prediction as an image generation task, by calculating the relative depth of image pixels and forming then into the target images, the constraint from the discriminator is added into the depth prediction process, which will increase the accuracy of the prediction. At the training step, we train CGANs with different objective functions to evaluate the performance of our models. We test our model on TUM RGBD dataset [8] and NYU V2 dataset [9]. We introduce the related work about our research in Sect. 2 and the architecture of our method will be described in Sect. 3.
2 Related Work
Before Traditional depth prediction from monocular images mostly relied on the motion of cameras or objects, such as Structure-from-Motion (SFM) [1], Shape-from-Shading (SFS) [2] or Shape-from-Defocus (SFD) [10]. These traditional methods are based on the ideal physical model, i.e., Lambertian Surface reflection Model, by making ideal assumptions about imaging conditions and optical features, we could obtain the 3D information by converse-solving the reflection equation based on Lambertian Surface reflection Model. These methods are convenient and fast, however, they require high quality light and other constraints, these weaknesses result in the inability to reconstruct curved objects which have concave or convex surfaces.
There are other depth prediction methods which are mainly relied on hand-crafted features and probabilistic graphical models. For instance, Saxena et al. [4], uses a linear regression and MRF to infer depth from local and global features extracted from images, [11] proposes a non-parametric method, that is, given an input image, a candidate similar to it is found in the candidate database, the depth of the input image is estimated using the existing depth information of the candidate based on a kNN transfer mechanism, [12] trains a factored autoencoder which is based on learning about the interrelations between images from multiple cameras on image patches to predict depth from stereo sequences, [13] uses supervised learning to train the MRF in order to model the depth information of the image and the relationships between different parts of the image, [14] formulates the depth prediction as a discrete-continuous optimization problem with CRF models. [15] trains a Markov random field (MRF) as a separate depth estimator for semantic classes labeled by semantic segmentation. These probabilistic graphical models are based on the premise that similarities between regions in the RGB images imply also similar depth cues, which normally need to compare the similarity between image patches with unknown depth information and the patches whose depth values are known.
Recent years, some excellent methods of depth prediction based on deep convolutional neural networks are proposed. [5] directly regress on the depth using a neural network which is constituted by two CNN stacks: the Global Coarse-Scale Network predicts the overall depth map structure in a global view, while the fine-scale network receives the coarse prediction and align with local details such as object and wall edges. [16] uses a cascaded network which is constructed with a sequence of three scales to generate features and refine depth predictions. [17] combines CNN and CRF and proposed a deep convolutional neural field model for depth prediction, which could learn the unary and pairwise potentials of continuous CRF in a unified deep network. [18, 19] formulates depth estimation in a two-layer hierarchical CRF to refine their patch-wise CNN predictions from superpixel levels down to pixel levels. [20] proposes a neural regression forest (NRF) model, combines random forests and CNNs and predicts depth values in the continuous domain via regression. [6] trains a convolutional residual network and replaces the fully-connected layer with up-sampling blocks, which could generate the corresponding depth images of input images directly. [21] predicts depth values with the semantic information of pixels by training a semantic depth classifier.
3 Model Architecture
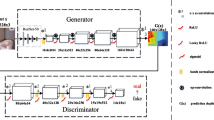
In this paper, we use CGAN [7] as the producer of depth images which is proposed in 2014 by Mirza and Osindero. Original GAN [22] doesn’t need a hypothetical data distribution when generate images, this method is too simple, which leads to the uncontrollable of generating process. In the contrary, CGAN is an improvement of turning unsupervised GAN into a supervised model. CGAN adds the tag information in the process of image generation, which adds the constraints and pertinence in generating process. In this section, we will introduce our model based on CGAN. The pipeline of our method is shown as Fig. 1.

The pipeline of our method.
3.1 Principle of CGAN
A CGAN is the abbreviation of conditional Generative Adversarial Nets, which is a variant of GAN. The objective function of CGAN is written as follow:
where pdata(x) means the distribution of input images, pz(z) means the distribution of generated images.
We define our model architecture similar as used in [23], which is described in the following sections.
3.2 Architecture of Generator
In this paper, we use the U-net as the generator of our CGAN model. The U-net can be regarded as an encoder-decoder model which concatenates corresponding feature maps in different layers together between encoder and decoder. The architecture of generator is shown as Fig. 2.

The architecture of generator.
3.3 Architecture of Discriminator
The discriminator is constituted as a encoder, which learns to classify between real and fake images pairs. The discriminator will supervise the generation of depth images. When training the discriminator, real depth images and fake images are sent into the network and the differences between real and fake images will be learnt by minimize the objective function. The prediction will be obtained by a sigmoid function at last. The architecture of discriminator is shown as Fig. 3.

The architecture of discriminator.
3.4 Loss Function
The common objective function of a CGAN is expressed as formula (1) shows. For the training of the generator, the purpose is to minimize the value of the objective function, which means the prediction of generated data by the discriminator approaches to 1. On the contrary, the purpose of discriminator training is to maximize the value of the objective function, which means the prediction of generated data approaches to 0.
In reality, the objective function of discriminator is usually remains in its original form as formula (1), however, the objective function of generator is expressed as:
where function F means a kind of traditional loss, such as L1 or L2 distance of input data y and generated data G(z), \( \lambda \) is the weight of F.
In this paper, we choose the reverse Huber (BerHu) function as F, which is written as:
c means the threshold value, which is defined as:
where i means all pixels of images in every training batch, \( \tilde{d}_{i} \) means the depth prediction value of one pixel, di means the real depth value of this pixel.
Thus, the final objective function of generator is written as:
\( \lambda \) means the weight of BerHu function.
When training our model, we test several different objective functions, such as the BerHu function and L1, Huber function.
4 Data Augmentation
4.1 Foreground Clipping for Image Pre-processing
As described in [6], the depth values of image follow heavy-tailed distribution, that is, in the whole depth range of an image, most depth values are in a few depth ranges, while the other depth ranges contains only a small part of the total depth values, which means that the regularities of image depth distribution are mostly included in these areas. Thus, we clip the foreground images and train our model firstly, then the model is trained with the original images. The results of foreground clipping are shown in Fig. 4.

The distribution of depth values in different dataset. (a) means the distribution in TUM RGBD dataset; (b) means the distribution in NYU V2 dataset.
Based on this phenomenon, in this paper, we propose the method of foreground clipping to increase the amount of images. Specifically, we count all depth values of pixels in images and divide the whole depth range into ten subranges, compute the foreground of images in which the depth values of pixels is responsible for 85% of all pixels. The results of foreground area cut are shown in Fig. 5.

The results of foreground cut tested on TUN RGBD dataset. Images on the lefts side are the original images in dataset, images on the right side are the result images.
4.2 Training Data Augmentation
Before training our model, we downscale the input RGB images to 286 × 286, and clip patches of 256 × 256 randomly as inputs of the generator, we also set a 50% chance to flip the clipping images left and right to augment the input images.
During training process, we first train the model in foreground images for 200 epochs, then we apply the checkpoint on raw dataset for further training.
5 Experiments
We estimate our method on two datasets, the TUM-RGBD dataset and the NYU indoor dataset. In our experiments, we evaluate the performance of three functions: L1, Huber and the reverse Huber (BerHu), prior works [5, 6, 14, 18, 19, 24] are also compared with our experimental results.
When comparing with other works, we choose several measures commonly used in works such as [6, 16, 20], which is shown as:
-
root mean squared error (rms): \( \sqrt {\frac{1}{T}\sum\nolimits_{i \in T} {\left\| {\tilde{d}_{i} - d_{i} } \right\|^{2} } } \)
-
average relative error (rel): \( \frac{1}{T}\sum\nolimits_{i \in T} {{{\left| {d_{i} - \tilde{d}_{i} } \right|} \mathord{\left/ {\vphantom {{\left| {d_{i} - \tilde{d}_{i} } \right|} {d_{i} }}} \right. \kern-0pt} {d_{i} }}} \)
-
average log 10 error (log10): \( \frac{1}{T}\sum\nolimits_{i \in T} {\left| {\log_{10} d_{i} - \log_{10} \tilde{d}_{i} } \right|} \)
-
root mean squared log error (rmslog): \( \sqrt {\frac{1}{T}\sum\nolimits_{i \in T} {\left\| {\log \tilde{d}_{i} - \log d_{i} } \right\|^{2} } } \)
-
accuracy with threshold \( thr \): \( \left( \% \right){\text{ of }}\tilde{d}_{i} {\text{ s}} . {\text{t}} . { }\hbox{max} \left( {\frac{{d_{i} }}{{\tilde{d}_{i} }},\frac{{\tilde{d}_{i} }}{{d_{i} }}} \right) = \delta < thr \)
5.1 TUM-RGBD Dataset
The TUM RGBD dataset contains a series of continuous RGB image and depth images, the ground truth file are given to associate the RGB images and their corresponding depth images.
We test our models with different objective functions, and the results are shown as Table 1 and Fig. 6.

The results with different object functions tested on TUM RGBD dataset.
In Table 1, we test our model with 3 different objective functions of the generator in CGAN, and the results shows that, the BerHu function works best in the depth prediction task. The result images of different objective functions are shown in Fig. 6.
5.2 NYU V2 Dataset
We train our model in NYU V2 dataset, and test our model in test image set compared with other works and the results are shown in Table 2 and Fig. 7.

Test results on NYU V2 dataset with different objective functions.
We compare our model with other depth prediction works, and the results of these measures are shown in Table 2. The results show that the performance of our model are better than other works. And the generating images of our method with different objective functions of generator are shown in Fig. 7.
6 Conclusion
In this paper, we propose a new method of depth prediction based on CGAN. We regard depth prediction as an image generation task and use an encoder-decoder as the generator of CGAN, which is used to generate depth images corresponding to input RGB images. The discriminator supervises the generation of depth images in training steps. We train our model on TUM RGBD dataset and NYU V2 dataset with the image argumentation such as foreground clipping. Finally, we test our model compared with other works. The results of experiments show the excellent performance of our method.
References
Szeliski, R.: Structure from motion. In: Computer Vision, Texts in Computer Science, pp. 303–334. Springer, London (2011). https://doi.org/10.1007/978-1-84882-935-0_7
Zhang, R., Tsai, P.S., Cryer, J.E., Shah, M.: Shape-from-shading: a survey. IEEE Trans. Pattern Anal. Mach. Intell. 21(8), 690–706 (1999)
Saxena, A., Sun, M., Ng, A.Y.: Make3D: learning 3D scene structure from a single still image. IEEE Trans. Pattern Anal. Mach. Intell. (PAMI) 12(5), 824–840 (2009)
Saxena, A., Chung, S.H., Ng, A.Y.: Learning depth from single monocular images. In: NIPS (2005)
Eigen, D., Puhrsch, C., Fergus, R.: Depth map prediction from a single image using a multi-scale deep network. In: Proceedings of Advances in Neural Information Processing systems (2014)
Laina, I., Rupprecht, C., Belagiannis, V., Tombari, F., Navab, N.: Deeper depth prediction with fully convolutional residual networks. In: 3DV (2016)
Mirza, M., Osindero, S.: Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784 (2014)
TUM RGB-D dataset. http://vision.in.tum.de/data/datasets/rgbd-dataset
Silberman, N., Hoiem, D., Kohli, P., Fergus, R.: Indoor segmentation and support inference from RGBD images. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012. LNCS, vol. 7576, pp. 746–760. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33715-4_54
Suwajanakorn, S., Hernandez, C.: Depth from focus with your mobile phone. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2015)
Karsch, K., Liu, C., Kang, S.B.: Depthtransfer: depth extraction from video using non-parametric sampling. IEEE Trans. Pattern Anal. Mach. Intell. 36, 2144–2158 (2014)
Konda, K., Memisevic, R.: Unsupervised learning of depth and motion. arXiv:1312.3429v2 (2013)
Saxena, A., Chung, S.H., Ng, A.Y.: 3-D depth reconstruction from a single still image. Int. J. Comp. Vis. 76, 53–69 (2007)
Liu, M., Salzmann, M., He, X.: Discrete-continuous depth estimation from a single image. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2014)
Liu, B., Gould, S., Koller, D.: Single image depth estimation from predicted semantic labels. In: 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1253–1260. IEEE (2010)
Eigen, D., Fergus, R.: Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In: Proceedings of the IEEE International Conference on Computer Vision (2015)
Liu, F., Shen, C., Lin, G., Reid, I.D.: Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans. Pattern Anal. Mach. Intell. 38, 2024–2039 (2016)
Li, B., Shen, C., Dai, Y., van den Hengel, A., He, M.: Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2015)
Wang, P., Shen, X., Lin, Z., Cohen, S., Price, B., Yuille, A.L.: Towards unified depth and semantic prediction from a single image. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, June 2015
Roy, A., Todorovic, S.: Monocular depth estimation using neural regression forest. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016)
Ladicky, L., Shi, J., Pollefeys, M.: Pulling things out of perspective. In: CVPR (2014)
Goodfellow, I., et al.: Generative adversarial nets. In: NIPS (2014)
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with conditional adversarial networks. In: CVPR (2017)
Liu, F., Shen, C., Lin, G.: Deep convolutional neural fields for depth estimation from a single image. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5162–5170 (2015)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhang, W., Zhang, G., Zou, Q. (2018). Depth Prediction from Monocular Images with CGAN. In: Qiu, M. (eds) Smart Computing and Communication. SmartCom 2018. Lecture Notes in Computer Science(), vol 11344. Springer, Cham. https://doi.org/10.1007/978-3-030-05755-8_42
Download citation
DOI: https://doi.org/10.1007/978-3-030-05755-8_42
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-05754-1
Online ISBN: 978-3-030-05755-8
eBook Packages: Computer ScienceComputer Science (R0)