
Abstract
For handling cross-domain distribution mismatch, a specially designed subspace and reconstruction transfer functions bridging multiple domains for heterogeneous knowledge sharing are wanted. In this paper, we propose a novel reconstruction-based transfer learning method called Latent Subspace Transfer Network (LSTN). We embed features/pixels of source and target into reproducing kernel Hilbert space (RKHS), in which the high dimensional features are mapped to nonlinear latent subspace by feeding them into MLP network. This approach is very simple but effective by combining both advantages of subspace learning and neural network. The adaptation behaviors can be achieved in the method of joint learning a set of hierarchical nonlinear subspace representation and optimal reconstruction matrix simultaneously. Notably, as the latent subspace model is a MLP Network, the layers in it can be optimized directly to avoid a pre-trained model which needs large-scale data. Experiments demonstrate that our approach outperforms existing non-deep adaptation methods and exhibits classification performance comparable with that of modern deep adaptation methods.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In computer vision, the dilemma of insufficient labeled data is common in visual big data, one of the prevailing problems in the practical application, is that when training data (source domain) exhibit a different distribution to test data (target domain), the task-specific classifier usually does not work well on related but distribution mismatched tasks.
Domain adaptation (DA) [5, 15, 31] techniques that are capable of easing such domain shift problem have received significant attention from engineering recently. It is thus of great practical importance to explore DA methods. These models allow machine learning methods to be self-adapted among multiple knowledge domains, that is, the trained model parameters from one data domain can be adapted to another domain. The assumption underlying DA is that, although the domains differ, there is sufficient commonality to support such adaptation.
A substantial number of approaches to domain adaptation have been proposed in the context of both shallow learning and deep learning, which bridge the source and target domains by learning domain-invariant feature representations without using target labels, such that the classifier learned from the source domain can also be applied to the target domain.
Visual representations learned by deep CNNs are fairly domain-invariant. Relatively high accuracy is always reported over a lot of visual tasks using off the-shelf CNN representations [4, 26]. However, on one hand, deep neural networks which learn abstract feature representations can only reduce, but not remove, the cross-domain discrepancy. On the other, training a deep model relies on massive amounts of labeled data. Compared with deep method, shallow domain adaptation methods which are more suitable for small-scale data usually fail to reach the high accuracy as deep learning.
Our work is primarily motivated by [21] which investigates a provocative question that domain adaptation is necessary even if CNN-based features are powerful. We thus proposed a non-deep method which combines both advantages of subspace learning and neural networks inspired by [12]. Although this LSTN method is simple, it can achieve competitive results compared with deep methods. The main contribution and novelty of this work are threefold:
-
In order to achieve the domain alignment, we propose a simple but effective net called Latent Subspace Transfer Network (LSTN). In order to get an optimal subspace representation, a joint learning mechanism is adopted for pursuing the latent subspace and reconstruction matrix simultaneously.
-
The optimal latent subspace to map the source and target samples in LSTN is achieved by MLP network, which has a simple network structure but is effective. The model is a non-linear neural network and can be optimized directly to avoid a pre-trained model which needs large-scale data.
-
In this simple network, we embed features/pixels of source and target into reproducing kernel Hilbert spaces (RKHS) as preprocessing before putting them into the optimization procedure. In this way, the dimension of input and the cost of running time are both reduced.
2 Related Works
2.1 Shallow Domain Adaptation
A number of shallow learning methods have been proposed to tackle DA problems. Generally, these shallow domain adaptation methods comprise of three categories: Classifier based approaches, feature augmentation/transformation based approaches and feature reconstruction based approaches. [5] proposed an adaptive multiple kernel learning (AMKL) for web-consumer video event recognition. [35] proposed a robust domain classifier adaptation method (EDA) with manifold regularization for visual recognition. [19] also proposed a Transfer Joint Matching (TJM) which tends to learn a non-linear transformation across domains by minimizing the MMD based distribution discrepancy. [36] proposed a Latent Sparse Domain Transfer (LSDT) method by jointly learning a subspace projection and sparse reconstruction across domains. Similarly, Shao et al. [25] proposed a LTSL method by pre-learning a subspace using PCA or LDA. Jhuo et al. [13] proposed a RDALR method, in which the source data is reconstructed by the target data using low-rank model. Recently, [21] proposed a LDADA method which can achieve the effect of DA without explicit adaptation by a LDA-inspired approach.
2.2 Deep Domain Adaptation
As deep CNNs become a mainstream technique, deep learning has witnessed a great achievements [22, 29, 32] in unsupervised DA. Very recently, [27] explored the performance improvements by combining the deep learning and DA methods.
Donahue et al. [4] proposed a deep transfer strategy for small-scale object recognition, by training a CNN network (AlexNet) on ImageNet. Tzeng et al. [29] proposed a CNN based DDC method which achieved successful knowledge transfer between domains and tasks. Long et al. [17] proposed a deep adaptation network (DAN) by imposing MMD loss on the high-level features across domains. Additionally, Long et al. [20] also proposed a residual transfer network (RTN) which tends to learn a residual classifier based on softmax loss. Hu et al. [12] proposed a non-CNN based deep transfer metric learning (DTML) method to learn a set of hierarchical nonlinear transformations for cross-domain visual recognition. Recently, GANs inspired adversarial domain adaptation methods have been preliminarily studied. Tzeng et al. proposed a novel ADDA method [30] for adversarial domain adaptation, in which CNN is used for adversarial discriminative feature learning. The work has shown the potential of adversarial learning in domain adaptation. In [11], Hoffman et al. proposed a CyCADA method which adapts representations at both the pixel-level and feature-level, enforcing cycle-consistency by leveraging a task loss.
However, most deep DA methods need large-scale data to train the model in advance, the insufficient data task involved is just used to fine tune the model. In contrast to these ideas, we show that one can achieve fairly good classification performance without pre-trained.

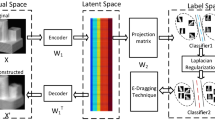
The basic idea of the LSTN method is shown in Fig. 1. For each sample in the training sets from the source domain and the target domain, we pass it to the MLP network. We enforce the reconstruction constraint on the outputs of all training samples at the top of the network, in this way, the adaptation behaviors can be achieved by joint learning a set of hierarchical nonlinear subspace representation and optimal reconstruction matrix simultaneously. The network architecture of the MLP used in our methods is also shown in Fig. 1. The \(\varvec{X}\) is the data points in the input space, \({f^{(1)}}({\mathbf{{X}}})\) is the output in the hidden layer and \({f^{(2)}}({\mathbf{{X}}})\) is the resulting representation of \(\varvec{X}\) in the common subspace. In our experiments, the number of layers is set as \(M=2\).
3 The Proposed Latent Subspace Transfer Network
3.1 Notation
In this paper, the source and target domain are defined by subscript “S” and “T”. The training set of source and target domain are defined as \(\varvec{{X}}_S\in \mathbb {R}^{d\times n_{S}}\) and \(\varvec{{X}_{T}}\in \mathbb {R}^{d\times n_{T}}\), where d denotes dimension of input, \(n_{S}\) and \(n_{T}\) denote the number of samples in source and target domain, respectively. Let \(\varvec{C}\) represents the number of classes, \(\varvec{\mathcal {{Z}}}\in \mathbb {R}^{n_{S}\times n_{T}}\) represents the reconstruction coefficient matrix. \(\parallel \cdot \parallel _{F}\) and \(\parallel \cdot \parallel _{*}\) denotes Frobenius norm and nuclear norm, respectively.
Notably, in order to reduce the feature dimension of input, we first embed the features in source and target domain into reproducing kernel Hilbert spaces (RKHSs) as preprocessing to get \(\varvec{{X}}_S\) and \(\varvec{{X}}_T\), then feed them to nonlinear neural network latent subspace. The kernel embedding represents a probability distribution \(\mathbf {P}\) by an element in RKHS endowed by a kernel \(k(\cdot )\) where the distribution is mapped to the expected feature map.
In our experiments, we consider a closer to reality case where no labeled training set is obtained from the target domain in unsupervised setting.
3.2 Model Formulation
As is shown is Fig. 1, unlike most previous transfer learning methods which usually seek a single linear subspace to map samples into a common latent subspace, we construct a multilayer perceptron network to compute the representations of each sample \(\varvec{x}\) by passing it to multiple layers of nonlinear transformations. By using such a network, besides the nonlinear mapping function can be explicitly obtained, the network structure is much simpler than deep methods which can avoid a pre-trained model.
Assume there are \(M + 1\) layers in the designed network. The output \(\varvec{X}\) at the \(m^{th}\) layer is computed as:
where \(m = 1, 2,\ldots , M\) and \(p^{(m)}\) units in the \(m^{th}\) layer. \(\varvec{W}^{(m)}\in \mathbb {R}^{p^{(m)}\times {p^{(m-1)}}}\) and \(\varvec{b}^{(m)}\in \mathbb {R}^{p^{(m)}}\) are the parameters of weight matrix and bias in this layer, the \({\mathbf{{Z}}^{(m)}} = {\mathbf{{W}}^{(m)}}{\mathbf{{h}}^{(m - 1)}} + {\mathbf{{b}}^{(m)}}\) and \(\varphi (\cdot )\) is a nonlinear activation function which operates component-wisely, such as widely used tanh or sigmoid functions. The nonlinear mapping \(f^{(m)}:\mathbb {R}^{p^{(m-1)}}\rightarrow \mathbb {R}^{p^{(m)}}\) is a function in the \(m^{th}\) layer parameterized by \(\{ {\mathbf{{W}}^{(i)}}\} _{i = 1}^m\) and \(\{ {\mathbf{{b}}^{(i)}}\} _{i = 1}^m\). For the first layer, we assume \({\mathbf{{h}}^{(0)}} = \mathbf{{X}}\) \((\varvec{{X}}_S\) or \(\varvec{{X}}_T)\) and \({{p}^{(0)}} = {d}\).
For both source data \(\varvec{{X}}_S\) and target data \(\varvec{{X}}_T\), their probability distributions are different in the original feature space. In order to reduce the distribution difference, it is desirable to map the probability distribution of the source domain and that of the target domain into the common transformed subspace. The two domains are finally represented as \({f^{(m)}}({{\varvec{X}_S}})\) and \({f^{(m)}}({{\varvec{X}_T}})\) at the \(m^{th}\) layer of our designed network respectively, and their reconstruction error can be expressed by computing the squared Euclidean distance between the representations \({f^{(M)}}({{\varvec{X}_S}})\) and \({f^{(M)}}({{\varvec{X}_T}})\) at the last layer as:
The low-rank representation is advantageous in getting the block diagonal solution for subspace segmentation, so that the global structure can be preserved. In constructing the reconstruction matrix \(\varvec{\mathcal {Z}}\) in this paper, the low-rank regularizer is used to better account for the global characteristics. By combining the reconstruction loss and the regularizer item together, the general objective function of the proposed LSTN model can be formulated as follows.
where \(\lambda (\lambda >0)\) and \(\gamma (\gamma >0)\) are the tunable positive regularization parameters.
3.3 Optimization
To solve the optimization problem in Eq. (3), a variable alternating optimization strategy is considered, i.e., one variable is solved while frozen the other one. In addition, the inexact augmented Lagrangian multiplier (IALM) and alternating direction method of multipliers (ADMM) are used in solving each variable, respectively. We just set reconstruction matrix (\(\varvec{\mathcal {Z}}\)) and subspace representation (\({f^{(m)}}({\mathbf{{X}}})\)) as two variables. For solving the \(\varvec{\mathcal {Z}}\), auxiliary variable \(\varvec{{J}}\) is added. To obtain the parameters \({\mathbf{{W}}^{(m)}}\) and \({\mathbf{{b}}^{(m)}}\), stochastic sub-gradient descent method is employed. With the two updating steps for \({f^{(m)}}({\mathbf{{X}}})\) and \(\varvec{\mathcal {Z}}\), the iterative optimization procedure of the proposed LSTN is summarized in Algorithm 1.

3.4 Classification
In this paper, the superiority of the proposed method is shown through the cross-domain or cross-place classification performance on the source data and target data in subspace, which can be represented as \({\varvec{\mathcal {X}}_S}={f^{(M)}}({\mathbf{{X}}_S})\) and \({\varvec{\mathcal {X}}_T}={f^{(M)}}({\mathbf{{X}}_T})\), respectively. Then, the general classifiers can be used for training on the source data \({\varvec{\mathcal {X}}_S}\) with label \({\varvec{\mathcal {Y}}_S}\) in unsupervised mode. Finally, the recognition performance is verified and compared based on the target data \({\varvec{\mathcal {X}}_T}\) and target label \({\varvec{\mathcal {Y}}_T}\).
4 Experiments
In this section, the experiments on several benchmark datasets [7, 9, 16] have been exploited for evaluating the proposed LSTN method, including: cross-domain 4DA office data and cross-place Satellite-Scene5 (SS5) dataset [21]. Several related transfer learning methods based on feature transformation and reconstruction, such as GFK [8], SA [6], DIP [2], TJM [19], LSSA [1], CORAL [28], JDA [18], JGSA [34], ILS [10], even the latest LDADA [21] have been compared and discussed. As the LSTN model we proposed can be regarded as a shallow domain adaptation approach, therefore, the shallow feature (4DA SURF features) and deep feature (4DA-VGG-M features) can be fed into the model. The deep transfer learning methods are also used to compare with our method (Fig. 2).

Some samples from 4DA datasets
Results on 4DA Office Dataset (Amazon, DSLR, Webcam and Caltech 256) [8]
This dataset is a standard cross-domain object recognition dataset. Four domains such as Amazon (A), DSLR (D), Webcam (W), and Caltech 256 (C) are included in 4DA dataset, which contains 10 object classes. With the domain adaptation setting, 12 cross-domain tasks are tested, e.g. \(A\rightarrow D\), \(C\rightarrow D\). In our experiment, the configuration is followed in [17] by full protocol. We compare the classification performance of LSTN using the conventional 800-bin SURF features [8]. The recognition accuracies are reported in Table 1, from which we observe that the performance of our method is higher than state-of-the-art method and 3.6% higher than the latest LDADA method in average cross-domain recognition performance.
CNN features (FC7 of VGG-M) of 4DA datasets are also used to verify the classification performance. This allows us to compare against several recently reported results. We have chosen the first nine tasks to exploit the performance in our method. Average multi-class accuracy is used as the performance measure. We have highlighted the best results in Table 2, from which we can observe that the proposed LSTN (92.2%) is better than LDADA (92.0%), and shows a superior performance over other related methods.
The compared methods above are shallow transfer learning. It is interesting to compare with deep transfer learning methods, such as AlexNet [14], DDC [29], DAN [17] and RTN [20]. The first nine tasks are used to verify the classification performance. The comparison is described in Table 3, from which we can observe that our proposed method ranks the second in average performance (92.2%), which is inferior to the residual transfer network (RTN), but still better than other deep transfer learning models. The comparison shows that the proposed LSTN, as a shallow transfer learning method, has a good competitiveness.
Notably, the 4DA and CNN features in 4DA tasks are challenging benchmarks, which attract many competitive approaches for evaluation and comparison. Therefore, excellent baselines have been achieved.
Results on SS5 (Satellite-Scene5) (Banja Luka (B), UC Merced Land Use (U), and Remote Sensing (R))
To validate that LSTN is general and can be applied to other images with different characteristics and particularly to the categories which are not included in the ImageNet dataset, we conduct evaluations on a cross-place satellite scene dataset. Three publicly available datasets as Banja Luka (B) [23], UC Merced Land Use (U) [33], and Remote Sensing (R) [3] datasets are selected specifically. In experiment, for cross-place classification, 5 common semantic classes: farmland/field, trees/forest, industry, residential, and river have been explored, respectively. There are 6 DA problem settings on this dataset. Several example images are shown in Fig. 3.
We follow the full protocol explained in LDADA [21], which allows us to compare against several recently reported results on the SS5 dataset. Results are shown in Table 4. We observe that LSTN (76.4%) which equals to the recent ILS [10] and LDADA [21], still outperforms other competitors and consistently improves the cross-place accuracy in DA tasks. The result suggests that LSTN should also be applicable to other general visual recognition problems.

Some samples from Satellite-Scene5 datasets
5 Discussion
5.1 Parameter Setting
In our method, two trade-off coefficients \(\gamma \) and \({\lambda }\) are involved. \(\gamma \) and \({\lambda }\) are fixed as 0.01 and 1 in experiments, respectively. The number of iterations \(T=10\) is enough in the experiments. The Gaussian kernel function \({k}(\mathbf {x}_i,\mathbf {x}_j)=exp(-{\parallel }\mathbf {x}_i-\mathbf {x}_j{\parallel }^2/2\sigma ^2)\) is used, where \(\sigma \) can be set as \(\sigma =1.4\) in the tasks. The least square classifier is used in DA experiments. In the MLP network, the number of layers is set as \(M=2\). The dimension of output in the latent space is the same as input. Tanh activation function \(\varphi (\cdot )\) is adopted in MLP network. The parameters of the weights and bias are auto updated by gradient descent based on back-propagation algorithm.
5.2 Computational Complexity
In this section, the computational complexity of the Algorithm 1 is presented. The algorithm includes three basic steps: update \(\varvec{\mathcal {Z}}\), update \(\varvec{{J}}\), and update \({f^{(m)}}\). The computation of \({f^{(m)}}\) involves \({\mathbf{{W}}^{(m)}}\) and \({\mathbf{{b}}^{(m)}}\), and the complexity is \(O(2M N^2)\). The computation of updating \(\varvec{{J}}\) and \(\varvec{\mathcal {Z}}\) is \(O(N^2)\). Suppose that the number of iterations is T, then the total computational complexity of LSTN can be expressed as \(O(T\times 2M N^2)+ O(T N^2)\).
In LSTN model, CPU is enough for model optimization, without using GPU. The time cost is much lower as shown in the last column of Tables 1 and 4. All experiments are implemented on the computer with Intel i7-4790K CPU, 4.00 GHz, and 16 GB RAM. The time cost is calculated under this setting. It is noteworthy that the time of data preprocessing and classification is excluded.

Convergence analysis on different tasks of LSTN model
5.3 Convergence
In this section, the convergence will be discussed. We have conducted the experiments on 4DA (\(A\rightarrow D\)) and SS5 (\(B\rightarrow R\)), respectively. The convergence of our LSTN method is explored by observing the variation of the objective function. In the experiments, the number of iterations is set to be 150 for verification the convergence better. The variation of the objective function (\(Obj_{min}\)) and reconstruction loss function (\(Dst_{min}\)) are described in Fig. 4. It is clear that the objective function and reconstruction loss function decrease to a constant value after several iterations. By running the algorithm, on 4DA and SS5 tasks, respectively, we can observe the good convergence of LSTN.
6 Conclusion
In this paper, we show that one can achieve the effect of DA by combining both advantages of subspace learning and neural network. Specifically, a reconstruction-based transfer learning approach called LSTN is proposed. It offers a simple but effective solution for DA with ample scope for improvement. In the method, we embed features/pixels of source and target into reproducing kernel Hilbert space (RKHS), in which the high dimensional features are mapped to nonlinear latent subspace by feeding them into MLP network. Leveraging the simple MLP, not only the layers can be optimized directly to avoid a pre-trained model which needs large-scale data, but also the adaptation behaviors can be achieved by joint learning a set of hierarchical nonlinear subspace representation and optimal reconstruction matrix simultaneously. Extensive experiments are conducted to justify our proposition in both effectiveness and efficiency. Results demonstrate that LSTN is applicable to small sample sizes, outperforms existing non-deep DA approaches, exhibits comparable accuracy against recent deep DA alternatives.
References
Aljundi, R., Emonet, R., Muselet, D., Sebban, M.: Landmarks-based kernelized subspace alignment for unsupervised domain adaptation. In: CVPR (2015)
Baktashmotlagh, M., Harandi, M.T., Lovell, B.C., Salzmann, M.: Unsupervised domain adaptation by domain invariant projection. In: ICCV, pp. 769–776 (2013)
Dai, D., Yang, W.: Satellite image classification via two-layer sparse coding with biased image representation. IEEE Geosci. Remote Sens. Lett. 8(1), 173–176 (2011)
Donahue, J., et al.: DeCAF: a deep convolutional activation feature for generic visual recognition. In: PMLR, pp. 647–655 (2014)
Duan, L., Xu, D., Tsang, I.W., Luo, J.: Visual event recognition in videos by learning from web data. In: CVPR, pp. 1959–1966 (2010)
Fernando, B., Habrard, A., Sebban, M., Tuytelaars, T.: Unsupervised visual domain adaptation using subspace alignment. In: ICCV, pp. 2960–2967 (2014)
Gaidon, A., Zen, G., Rodriguez-Serrano, J.A.: Self-learning camera: autonomous adaptation of object detectors to unlabeled video streams. arXiv (2014)
Gong, B., Shi, Y., Sha, F., Grauman, K.: Geodesic flow kernel for unsupervised domain adaptation. In: CVPR, pp. 2066–2073 (2012)
Gong, B., Grauman, K., Sha, F.: Learning kernels for unsupervised domain adaptation with applications to visual object recognition. IJCV 109(1–2), 3–27 (2014)
Herath, S., Harandi, M., Porikli, F.: Learning an invariant hilbert space for domain adaptation. In: CVPR, pp. 3956–3965 (2017)
Hoffman, J., et al.: CyCADA: cycle-consistent adversarial domain adaptation. arXiv preprint arXiv:1711.03213 (2017)
Hu, J., Lu, J., Tan, Y.P.: Deep transfer metric learning. In: CVPR, pp. 325–333 (2015)
Jhuo, I.H., Liu, D., Lee, D., Chang, S.F.: Robust visual domain adaptation with low-rank reconstruction. In: CVPR, pp. 2168–2175 (2012)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: NIPS, vol. 25, no. 2, pp. 1097–1105 (2012)
Kulis, B., Saenko, K., Darrell, T.: What you saw is not what you get: domain adaptation using asymmetric kernel transforms. In: CVPR, pp. 1785–1792 (2011)
Liu, D., Hua, G., Chen, T.: A hierarchical visual model for video object summarization. IEEE Trans. PAMI 32(12), 2178–2190 (2010)
Long, M., Cao, Y., Wang, J., Jordan, M.: Learning transferable features with deep adaptation networks. In: ICML, pp. 97–105 (2015)
Long, M., Wang, J., Ding, G., Sun, J., Yu, P.S.: Transfer feature learning with joint distribution adaptation. In: ICCV, pp. 2200–2207 (2014)
Long, M., Wang, J., Ding, G., Sun, J., Yu, P.S.: Transfer joint matching for unsupervised domain adaptation. In: CVPR, pp. 1410–1417 (2014)
Long, M., Zhu, H., Wang, J., Jordan, M.I.: Unsupervised domain adaptation with residual transfer networks. In: NIPS, pp. 136–144 (2016)
Lu, H., Shen, C., Cao, Z., Xiao, Y., van den Hengel, A.: An embarrassingly simple approach to visual domain adaptation. IEEE Trans. Image Process. PP(99), 1 (2018)
Oquab, M., Bottou, L., Laptev, I., Sivic, J.: Learning and transferring mid-level image representations using convolutional neural networks. In: CVPR, pp. 1717–1724 (2014)
Risojevic, V., Babic, Z.: Aerial image classification using structural texture similarity, vol. 19, no. 5, pp. 190–195 (2011)
Rosasco, L., Verri, A., Santoro, M., Mosci, S., Villa, S.: Iterative projection methods for structured sparsity regularization. Computation (2009)
Shao, M., Kit, D., Fu, Y.: Generalized transfer subspace learning through low-rank constraint. IJCV 109(1–2), 74–93 (2014)
Sharif Razavian, A., Azizpour, H., Sullivan, J., Carlsson, S.: CNN features off-the-shelf: an astounding baseline for recognition. In: CVPR, pp. 806–813 (2014)
Simon, K., Jonathon, S., Le, Q.V.: Do better imagenet models transfer better? arXiv preprint arXiv:1805.08974v1 (2018)
Sun, B., Feng, J., Saenko, K.: Return of frustratingly easy domain adaptation. In: AAAI, vol. 6, p. 8 (2016)
Tzeng, E., Hoffman, J., Darrell, T., Saenko, K.: Simultaneous deep transfer across domains and tasks. In: ICCV, pp. 4068–4076 (2015)
Tzeng, E., Hoffman, J., Saenko, K., Darrell, T.: Adversarial discriminative domain adaptation. In: CVPR (2017)
Wang, S., Zhang, L., Zuo, W.: Class-specific reconstruction transfer learning via sparse low-rank constraint. In: ICCVW, pp. 949–957 (2017)
Xie, M., Jean, N., Burke, M., Lobell, D., Ermon, S.: Transfer learning from deep features for remote sensing and poverty mapping. arXiv (2015)
Yang, Y., Newsam, S.: Bag-of-visual-words and spatial extensions for land-use classification. In: SIGSPATIAL International Conference on Advances in Geographic Information Systems, pp. 270–279 (2010)
Zhang, J., Li, W., Ogunbona, P.: Joint geometrical and statistical alignment for visual domain adaptation. In: CVPR, pp. 5150–5158 (2017)
Zhang, L., Zhang, D.: Robust visual knowledge transfer via extreme learning machine-based domain adpatation. IEEE Trans. Image Process. 25(3), 4959–4973 (2016)
Zhang, L., Zuo, W., Zhang, D.: LSDT: latent sparse domain transfer learning for visual adaptation. IEEE Trans. Image Process. 25(3), 1177–1191 (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Wang, S., Zhang, L. (2018). LSTN: Latent Subspace Transfer Network for Unsupervised Domain Adaptation. In: Lai, JH., et al. Pattern Recognition and Computer Vision. PRCV 2018. Lecture Notes in Computer Science(), vol 11257. Springer, Cham. https://doi.org/10.1007/978-3-030-03335-4_24
Download citation
DOI: https://doi.org/10.1007/978-3-030-03335-4_24
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-03334-7
Online ISBN: 978-3-030-03335-4
eBook Packages: Computer ScienceComputer Science (R0)