
Abstract
When the scale of your system grows, two things will likely happen.
Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
As a software project approaches release, its mass increases.
—Laws of Software Relativity
When the scale of your system grows, two things will likely happen:
-
1.
In order to deploy your firmware promptly and consistently, you need a formal build process.
-
2.
Multitasking becomes crucial, which may very likely call for an embedded OS.
This chapter offers some useful clues to answer those challenges.
The Build Process
Source code has to be built into binaries before all the magic happens. And it is imperative to have a formal build process in place for every firmware project. Such a process is supposed to track dependency among source files and produce various flavors of images when configurations are given. Most likely, it will boil down to a makefile, which is the centerpiece of this section. However, due to the plethora of build tools, the makefile is not the only option on the table. Other options will also be explored, and the pros and cons of them will be discussed in detail.
Makefile Basics
The makefile is interpreted by the Make utility, which has a history going back to as early as the 1970s. Given its longevity, the Make utility has produced a handful of derivative versions over the years. For all practical purposes, the rest of the book will discuss makefiles for GNU Make only and present a few useful templates for projects of small and medium scale.
The Make utility has a long list of syntax rules, many of which can be convoluted and tedious. It will be too pandemic to discuss all of them here. For those of you who are ambitious enough to become the master of the Make utility, Ref [3] is a good place to start. At a minimum, you should be familiar with the issues in the following sections.
Targets and Prerequisites
The backbone of the makefile is the dependency rule, which is illustrated in Listing 8-1. Both the targets and the prerequisites are files on the disk, and wildcard can also be used to match filenames. (Phony target is an exception, which will be discussed later.) Basically, it means the targets are dependent on those prerequisites. If any of the prerequisites is updatedFootnote 1, Make utility will try to update the target as well by executing the corresponding shell commands.
The shell commands that are listed under the dependency should follow a certain format:
-
There should be a leading Tab character in front of each shell command. Replacing the tab with blank space will produce errors, although tab and spaces look the same in most text editors.
-
Each shell command that is invoked by the Make utility will be echoed onscreen. You can put an @ sign in front of that command to disable the auto-echo.
-
The Make utility will quit if the shell command returns a non-zero value. You can put a - sign in front of that command to let the Make utility ignore the error and move onFootnote 2.
-
You can use $@ and $< to refer to targets and prerequisites, respectively.
Listing 8-1. Targets and Prerequisites
targets : prerequisites shell commands ... Example %.o : %.c -@echo "===> Building $@" @$(CC) $(CFLAGS) -c -o $@ $<
Variable Expansion
You can use variables in your makefiles. Depending on the way variables are assigned, there are two kinds of them: simply-expanded and recursively-expanded. Simply-expanded variables get to determine their values immediately when they are being assigned, while recursively-expanded ones have to wait until the moment when they are being referenced. In order to distinguish one from the other, the two kinds of variables use := (for simply-expanded) and = (for recursively-expanded) for assignment operation. As demonstrated in Listing 8-2, $(TOPDIR) is a simply-expanded variable while $(dependency) is a recursively-expanded one. As you can see, $(obj) might change its value before $(dependency) is being used. So it makes more sense to defer to $(dependency)’s expansion.
Listing 8-2. Variable Expansion
TOPDIR := $(shell pwd) export TOPDIR dependency = $(patsubst %.o,%.d,$(obj)) ... ifneq "$(MAKECMDGOALS)" "clean" -include $(dependency) endif
Phony Target
As mentioned early, a target is supposed to match the corresponding file on the disk. However, this is not always the case. With the . PHONY directive , you can stop such a filename matching by declaring the target as a phony target. The Make utility will always treat a phony target as out-of-date. As demonstrated in Listing 8-3, both all and clean are phony targets. make all will trigger the processing of all object files before link is conducted, while make clean will prepare for a fresh new build by removing files generated in the previous iteration.
Listing 8-3. Phony Target
obj = test/test_main.o \ common/CRC32.o \ common/about.o \ align/align.o target = demo.exe ... all: $(obj) @echo "====> Linking $(target)" @$(LD) $(LDFLAGS) $(obj) -o $(target) @chmod 755 $(target) clean : -@rm -vf $(target) -@find . -type f \( -name "*.d" -o -name "*.o" \) -exec rm -vf {} \; .PHONY: clean all
Simple Makefile
From this section forward, I will try to provide a few makefile templates for practical use. I will start small by organizing some files mentioned in early chapters into the source tree structure shown in Figure 8-1. Within the top folder, there are four directories. All the common header files, such as debug.h, are stored in the common/include folder, and they will be included in the whole project.

Source tree structure
Given the source tree structure , you can have a simple makefile as illustrated in Listing 8-4:
-
Specify cross-compiler, cross-assembler, and cross-linker in $(CC), $(AS), and $(LD) variables, respectively.
-
Specify all the compiler options in $(CFLAGS). These options should include header file search paths and optimization flags. All the global macro definitions, such as VMAJOR, VMINOR, and DEBUG, are supposed to be placed here as well.
-
By the same token, you specify all necessary link options in $(LDFLAGS).
-
Specify all the modules (object names) in $(obj) variable.
-
Specify the target image name in $(target) variable.
-
The phony target all will kick-start the compiling for all objects, which will in turn trigger the %.o : %.c rule.
-
With the help of a wildcard, the %.o : %.c rule will trigger the compiling for those modules listed in $(obj) variable.
-
The phony target clean will kick-start shell scripts to remove files generated in the previous building cycle.
Listing 8-4. Simple Makefile
CC = gcc AS = LD = gcc CFLAGS += -I. -Icommon/include -Istate_machine -Ialign -g -W -DVMAJOR=1 -DVMINOR=3g -DDEBUG -DCONSOLE_PRINT=printf -DABOUT_CRC32=0x68DAC604 LDFLAGS += #== Put all the object files here obj = main/main.o \ common/CRC32.o \ common/about.o \ align/align.o \ state_machine/state_machine.o target = demo.exe all: $(obj) @echo "====> Linking $(target)" @$(LD) $(LDFLAGS) $(obj) -o $(target) @chmod 755 $(target) %.o : %.c @echo "===> Building $@" @$(CC) $(CFLAGS) -c -o $@ $< clean : -@rm -vf $(target) -@find . -type f \( -name "*.d" -o -name "*.o" \) -exec rm -vf {} \; .PHONY: clean all
The simple makefile in Listing 8-4 serves as a good starting point for small projects, except for one thing: It does not handle dependency among source files. For example, debug.h is included by many sub-modules, such as align.c, about.c, and main.c. However, modifying debug.h does not automatically trigger the rebuilding of these .c files, because such a dependency is not reflected in Listing 8-4. Since source files are in a constant state of changing, and header files could include other headers files in a nested fashion, it can be quite labor-intensive to extract dependencies manually. Fortunately, this dilemma can be solved with the help of compiler option -M.
Makefiles that Handle Dependency
For each source file, C compilers like gcc can produce a list of include filesFootnote 3 by using the -M option, as demonstrated in Listing 8-5. This list is dumped into a corresponding .d file where the d stands for dependency. The sed command in Listing 8-5 is there to correct the output list with directory information, whose purpose will be explained soon. Given all that, each .c file can generate a corresponding .d file that contains the full dependency information.
Listing 8-5. main.c and List of Include Files
// main.c ... #include "stdio.h" #include "about.h" #include "align.h" int main (void) { about(); alignment_test(); return 0; } // End of main() $ gcc -I. -Icommon/include -Istate_machine -Ialign -g -W -DVMAJOR=1 -DVMINOR=3g -DDEBUG -DCONSOLE_PRINT=printf -DABOUT_CRC32=0x68DAC604 -M main/main.c | sed "s,main.o\s*:,main/main.o :," > main/main.d $ cat main/main.d main/main.o : main/main.c /usr/include/stdio.h /usr/include/_ansi.h \ /usr/include/newlib.h /usr/include/sys/config.h \ /usr/include/machine/ieeefp.h /usr/include/sys/features.h \ /usr/include/cygwin/config.h \ /usr/lib/gcc/i686-pc-cygwin/4.5.3/include/stddef.h \ /usr/lib/gcc/i686-pc-cygwin/4.5.3/include/stdarg.h \ /usr/include/sys/reent.h /usr/include/_ansi.h /usr/include/sys/_types.h \ /usr/include/machine/_types.h /usr/include/machine/_default_types.h \ /usr/include/sys/lock.h /usr/include/sys/types.h \ /usr/include/machine/types.h /usr/include/cygwin/types.h \ /usr/include/sys/sysmacros.h \ /usr/lib/gcc/i686-pc-cygwin/4.5.3/include/stdint.h /usr/include/stdint.h \ /usr/include/endian.h /usr/include/bits/endian.h /usr/include/byteswap.h \ /usr/include/sys/stdio.h /usr/include/sys/cdefs.h common/include/about.h \ common/include/common_type.h common/include/debug.h align/align.h \ common/include/common_type.h common/include/debug.h \ state_machine/state_machine.h
By including these .d files, makefile will be able to determine the exact scope of source files to rebuild after a header file is modified. Thus, the simple makefile in Listing 8-4 can be transformed into the one in Listing 8-6 to support dependency.
Listing 8-6. Makefile that Handles Dependency
CC = gcc AS = LD = gcc CFLAGS += -I. -Icommon/include -Istate_machine -Ialign -g -W -DVMAJOR=1 -DVMINOR=3g -DDEBUG -DCONSOLE_PRINT=printf -DABOUT_CRC32=0x68DAC604 LDFLAGS += #== Put all the object files here obj = main/main.o \ common/CRC32.o \ common/about.o \ align/align.o \ state_machine/state_machine.o target = demo.exe all: $(obj) @echo "====> Linking $(target)" @$(LD) $(LDFLAGS) $(obj) -o $(target) @chmod 755 $(target) %.o : %.c @echo "===> Building $@" @echo "============> Building Dependency" @$(CC) $(CFLAGS) -M $< | sed "s,$(@F)\s*:,$@ :," > $*.d @echo "============> Generating OBJ" @$(CC) $(CFLAGS) -c -o $@ $<; \ if [ $$? -ge 1 ] ; then \ exit 1; \ fi @echo "----------------------------------------------------------------------------" dependency = $(patsubst %.o,%.d,$(obj)) ifneq "$(MAKECMDGOALS)" "clean" -include $(dependency) endif clean : -@rm -vf $(target) -@find . -type f \( -name "*.OBJ" -o -name "*.d" -o -name "*.o" -o -name "*.LST" -o -name "*.M51" \ -o -name "*.hex" -o -name "*.rsp" \) -exec rm -vf {} \; .PHONY: clean all
As you can see, the enhancements made in Listing 8-6 are as follows:
-
Dependency information will be extracted from the .c file and dumped into a .d file before the object is generated.
-
For each .c file, its corresponding .d file will be included by the makefile. The default dependency information produced by the compiler does not include a directory path. That’s what sed "s,$(@F)\s*:,$@ :," is there for—to correct this behavior, since a directory path is required when .d files are being included.
-
When the object is generated, the makefile will determine the next step of action based on the compiler’s return value. By default, a compiler should return a non-zero value only when there is compiling error. However, some compilers, like Keil C51 (Ref [5]), will return 1 on warning and 2 on error. To let the makefile only stop on compiling errors rather than on warnings, use the automatic variable $$? to convert the compiler’s return values.
For all practical purposes, Listing 8-6 can be a good makefile template for small projects. Here my definition of "small" is a project whose total number of source files is less than 200 and total number of sub-folders is less than 20. If your project grows far beyond that point, you might consider deploying recursive makefiles.
Recursive Makefiles
Rome wasn’t built in a day, and neither is any meaningful embedded system. The only viable approach to building anything relatively big is divide-and-conquer. You start off with those basic building blocks and then test them and make sure they are solid. On top of those basic blocks, you can create bigger modules. You test them so they can be used as solid building blocks as well. And you repeat those aforementioned steps recursively until you reach the top. As far as development is concerned, it implies the following:
-
The project is composed of multiple sub-modules.
-
There could be dependency among those sub-modules, and such a dependency should be reflected in build process as well. Basically it means that some sub-modules have to be built before others in order not to violate the dependency rule. Note that mere symbol reference from one module to another does not necessarily constitute build dependency. The two modules can be built in any chosen order and linked at the last stage. However, build dependency does exist if module A is referencing files from module B and these files are dynamically generated by module B in its build process. Consequently, you can assert that A is dependent on B and should be built after B.
-
Since the whole project is developed from bottom up, the building and testing should be carried out at both the sub-module level and the top level.
To accommodate these issues, I suggest the project source tree and makefiles being organized in the following manner:
-
Each sub-module should have a corresponding sub-folder in source tree, and it is better to have a flat structure for the source tree. The dependency among sub-modules should be reflected in the makefile instead of the source tree structure.
-
Since each sub-module should be built and tested independently, you can put two makefiles in each sub-folder. One is named literally as Makefile, and it is responsible for building the sub-module. The other can be called Makefile_Test, and it is for building the test fixture.
-
As you can imagine, most makefiles look the same, which are the close cousins of Listing 8-6. To avoid code duplication, the greatest common factor of them, namely the bulk of Listing 8-6, can be extracted into a file called Rules.mak. Rules.mak resides in the top level. All the makefiles in the project are supposed to include Rules.mak. Generally, makefiles differ from each other only by specifying the distinctive objects and targets involved.
-
As stated earlier, dependency among sub-modules has to be accommodated. However, dependency can grow into something that involves multiple layers of assorted modules. Assuming there is no mutual or cyclic dependencyFootnote 4, you can describe module dependency by using DAG (Directed Acyclic Graph ), as illustrated in Figure 8-2. The longest path in Figure 8-2 is the length of four (Top -> A1 -> B0 -> C0 -> D0 and Top -> A1 -> B0 -> C1-> D0). Based on each module’s longest distance from top, the DAG in Figure 8-2 can be divided into four layers. For a medium-scale project, the longest path in its dependency DAG is usually no more than four. So I will design my template of recursive makefiles based on this assumption and name the four layers of sub-modules submodules, submodules_sofa, submodules_carpet, and submodules_floor. (As you can see, submodules sit on the sofa, and the sofa is on top of the carpet with the floor underneath. Hopefully I don’t have to add one more layer for the basement.) These names will correspond to respective variables in the makefile to implement sub-module dependency.
Figure 8-2. 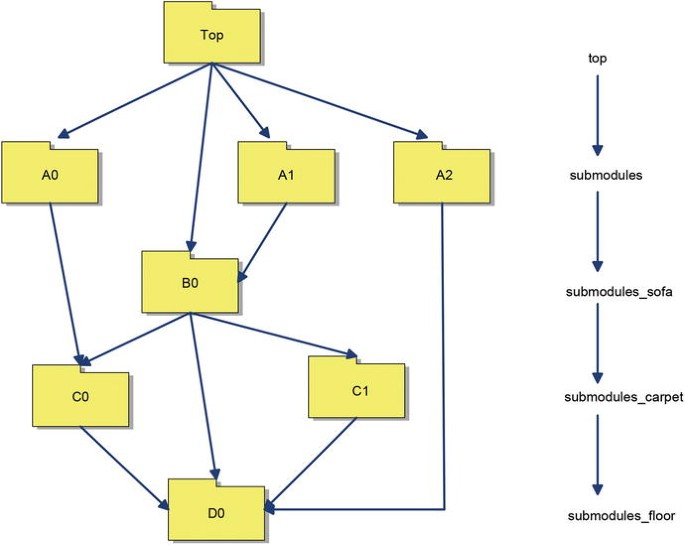
Describe dependency with DAG

Now let me use the source tree structure in Figure 8-1 to show you how recursive makefiles can be employed to tackle the same problem. To use recursive Make, there should be makefiles in each sub-folder. As stated previously, a test fixture can also reside in the sub-folder to carry out a unit test. So the source tree in Figure 8-1 will evolve into the one in Figure 8-3 with more files in it.

Source tree for recursive make
Compare Figure 8-3 to Figure 8-1 and you will find that the source tree folder structure is the same. The only difference is that each sub-folder now has three more files: Makefile, Makefile_Test, and test_main.c. Makefile is for building the sub-module, while Makefile_Test and test_main.c are part of the test fixture. Rules.mak resides in the top folder, and it is supposed to be included by all the makefiles.
Listing 8-7. Rules.mak
CFLAGS += -I. -I$(TOPDIR)/common/include CFLAGS += -g -W -DVMAJOR=1 -DVMINOR=3g -DDEBUG -DCONSOLE_PRINT=printf all: $(submodules) $(obj) @if [ -n "$(target)" ] ; then \ echo "====> Linking $(target)";\ $(CROSS_LD) $(LDFLAGS) $(obj) $(link_obj) -o $(target); \ fi @if [ -n "$(post_link_action)" ] ; then \ echo "====> $(post_link_action)"; \ fi @$(post_link_action) $(submodules) : $(submodules_sofa) @$(MAKE) -C $@ @echo "============================================================================" @echo $(submodules_sofa) : $(submodules_carpet) @$(MAKE) -C $@ @echo "============================================================================" @echo $(submodules_carpet) : $(submodules_floor) @$(MAKE) -C $@ @echo "============================================================================" @echo %.o : %.c @echo "===> Building $@" @echo "============> Building Dependency" @$(CROSS_CC) $(CFLAGS) -M $< | sed "s,$(@F)\s*:,$@ :," > $*.d @echo "============> Generating OBJ" @$(CROSS_CC) $(CFLAGS) -c -o $@ $<; \ if [ $$? -ge 1 ] ; then \ exit 1; \ fi @echo "----------------------------------------------------------------------" dependency = $(patsubst %.o,%.d,$(obj)) ifeq (,$(filter "clean" "clean_recursive", "$(MAKECMDGOALS)")) -include $(dependency) endif clean_recursive : -@for dir in $(submodules_floor) $(submodules_carpet) $(submodules_sofa) $(submodules); do \ $(MAKE) -s -C $$dir clean; \ done -@rm -vf $(target) -@rm -vf $(obj) -@rm -vf $(patsubst %.o,%.d,$(obj)) clean : -@rm -vf $(target) -@find . -type f \( -name "*.OBJ" -o -name "*.d" -o -name "*.o" -o -name "*.LST" -o -name "*.M51" \ -o -name "*.hex" -o -name "*.rsp" \) -exec rm -vf {} \; .PHONY: clean all clean_recursive $(submodules) $(submodules_sofa) $(submodules_carpet) $(submodules_floor)
Listing 8-7 has the bulk of Rules.mak, and comparing Listing 8-7 to Listing 8-6 will reveal the following:
-
$(submodules), $(submodules_sofa), $(submodules_carpet), and $(submodules_floor) are added to Rules.mak to enforce the building order. These variables are also listed as phony targets. For each dependency rule of these variables, $(MAKE) -C is used to iterate all the sub-folders involved.
-
To make Rules.mak more generic, $(post_link_action) is added to accommodate script processing after the link is done.
-
$(obj) and $(target) are not specified in Rules.mak. Instead, they are supposed to be set up by the makefile.
The top/common/include/about_CRC32.h file in Figure 8-3 contains the CRC32 checksum of the about signature, and it is produced dynamically by a Perl script (the script about_sig_CRC32.pl will derive the about signature from the binary files and calculate the CRC32). Other modules, such as state_machine and main, will include this header file. Thus there is dependency and the common module should be built before the others. The whole DAG for Figure 8-3 is shown in Figure 8-4.

Example DAG
As you can deduce from Figure 8-4, $(submodules) and $(submodules_sofa) will be employed in the makefile to force the build order among modules. Thanks to Rules.mak, the top-level makefile can be more succinct, as shown in Listing 8-8.
Listing 8-8. Top-Level Makefile
TOPDIR := $(shell pwd) export TOPDIR obj = main/main.o target = demo link_obj = state_machine/state_machine.o common/common.o align/align.o submodules = align state_machine submodules_sofa = common CROSS_LD = gcc CFLAGS += -I$(TOPDIR)/align -I$(TOPDIR)/state_machine include $(TOPDIR)/Rules.mak
As stated earlier, building and testing should also be carried out at sub-module level. Accordingly, there are two makefiles in each sub-folder: Makefile and Makefile_Test. The former is for building only while the latter is for unit testing. Take sub-module state_machine for example; its Makefile and Makefile_Test files are demonstrated in Listings 8-9 and 8-10, respectively. As you can see, state_machine’s dependency on the common module is reflected in Makefile_Test, but not in Makefile. This is because the unit test needs to link all the relevant sub-modules to produce a complete binary. For the recursive make, the top-level makefile will handle the module dependency as a whole.
Listing 8-9. Makefile of state_machine Module
obj += state_machine.o target = ifndef TOPDIR TOPDIR := .. endif include $(TOPDIR)/Rules.mak
Listing 8-10. Makefile_Test of state_machine Module
ifndef TOPDIR TOPDIR := .. endif obj = test_main.o target = test_main link_obj = state_machine.o $(TOPDIR)/common/common.o submodules += $(TOPDIR)/common $(TOPDIR)/state_machine CROSS_LD = gcc include $(TOPDIR)/Rules.mak
The recursive makefile architecture demonstrated in this section can serve as a template for medium-scale firmware projects with a reasonable build time. However, for the sake of completeness, be aware that there is also an alternative approach that employs a non-recursive, centralized makefile, as suggested in Ref [4]. The non-recursive makefile will include module-specific information (a file called module.mk) from each sub-folder, and it will have multiple targets to build sub-modules. Personally I am not very enthusiastic about this non-recursive approach, for the following three reasons:
-
The problems described in Ref [4] do not apply to the makefile template presented in this section.
-
The architecture of a firmware project is NOT always in a static shape throughout its lifecycle. It might be premature to have a centralized makefile when all the possible avenues are still being explored at the planning stage. It runs counter to the ideas of divide-conquer and bottom-up approach that I mentioned earlier.
-
Oftentimes, your project will utilize modules provided by a third party. These modules are usually self-contained, with their own makefiles out of the box. It would be reinventing the wheel to impose non-recursive makefiles on those modules.
Thus from the perspective of practicality, I don’t recommend such a non-recursive solution to readers. Instead, consider the makefile template presented in this section for your new project.
Makefile with Kernel Configuration Language
One thing not included in the previous template is the GUI-based configuration. The kernel configuration language that accompanies the Linux kernel offers a nice solution in this regard.
Configuration Process
To survive and beat your competitors, your project team has to answer calls from a wide variety of customers, in a prompt fashion. More often than not, those demands from customers are only slightly different from each other. For example, most OEM customers want to customize the display of product names and versions. Some customers, in order to differentiate themselves from the pack, may choose to include certain modules (with cool features supposedly) offered by a third-party. Consequently, the build process has to be flexible enough to accommodate those demands. And under such fast-spinning circumstances, the surviving guide usually suggests building the firmware from the same baseline, but with macro definitions to conduct conditional compiling. The build process is basically divided into two stages: configuration and compile/link. The configuration stage will produce a makefile, which is fed into the second stage.
One way to do this configuration is, of course, to manually modify the makefile every time when a new customer demand comes in. However, when your business is booming and the list of customers grows, the manual configuration job quickly becomes tedious and error-prone. Thus most companies will develop some scripts to automate the configuration process. The drawback of in-house scripts is obvious: These scripts are custom-made and offer no generic value to other projects.
Fortunately, since configuration is such a pandemic issue, there are generic solutions. One of them is to use the kernel configuration language, which is discussed in detail in this section.
The Linux Kernel Configuration Language
The Linux kernel finds itself with hundreds of sub-modules, and it is targeted to be run on more than 20 different CPU architectures. Such a huge variety makes configuration an acute issue. A special kernel configuration language was thus developed, and it has undergone some major revamps after kernel 2.5 (Ref [6]). The new kernel configuration language provides a generic solution that is not confined only to the Linux kernel. And for the rest of the book, the new kernel configuration system will be referred to as Kconfig. Kconfig is an independent part by itself, and any project that needs a configuration process can borrow a page from Linux kernel by using Kconfig.
As shown in Figure 8-5, the configuration process needs to provide config options (manifested in the kernel configuration language) to Kconfig, and these config options are usually saved in a text file named Config.in or Kconfig. Based on this text file, Kconfig will present four different configuration interfaces: command line, text-mode menu, GTK+ based GUI, and Qt based GUI. These four configuration interfaces correspond to the four makefile targets respectively: config, menuconfig, gconfig, and xconfig.

Kconfig workflow
No matter what interface you choose, all of them will save your configuration in a file named .config. This .config file can be included in your makefile or Rules.mak, which will then produce conditional compiling macros for code building (see Figure 8-5).
The support of GUI makes Kconfig stand out and shine. I think it should be the first thing to consider if your firmware project merits some sort of configuration process.
Integrate Kconfig into Firmware Project
To demonstrate Kconfig integration, I will recycle the example shown earlier by adding a configuration process to it. Assume there is a customer from Mars who put forward the following demands:
-
The product name and product version (VMajor and VMinor) should be configurable.
-
Since the firmware code might be ported to various CPU architectures, the cross-compiler should also be configurable.
-
As shown earlier, alignment and state_machine are the two major modules in the project. Each module should be individually included or excluded by configuration options.
-
There should be a separate option to enable/disable about-signature verification.
-
Due to the common module’s popularity, there should be a dedicated checkbox option to rebuild it.
These demands can thus be manifested by the kernel configuration language (saved as Config.in) shown in Listing 8-11. As you can see, it is composed of three menus: About, Tools Setup, and Modules Configuration:
-
There are three string entries under the About menu. These entries are used to specify product name, major version, and minor version (for demand #1).
-
There are two string entries under the Tool Setup menu to satisfy demand #2. One entry is used to set up the cross-compiler for firmware. The other one is in case a different compiler is used. (Some applications may prefer μClibc over the standard C library. This option is mainly reserved for this purpose.)
-
Under the Modules Configuration menu, the ENABLE_ALIGNMENT_MODULE and ENABLE_STATE_MACHINE_MODULE entries are both dependent on BUILD_WHOLE_IMAGE. These are Boolean options and they are designed to meet demand #3.
-
Demand # 4 and #5 are answered by Boolean entries CHECK_ABOUT_SIGNATURE and REBUILD_COMMON, respectively.
-
What demonstrated in this example is only a subset of the kernel configuration language, and more detailed information on Kconfig can be found in Ref [7].
Listing 8-11. Config.in
mainmenu "Firmware Configuration" config HAVE_DOT_CONFIG bool default y #======================================================================== # Firmware Version #======================================================================== menu "About" config PRODUCT_NAME string "Product Name" default "A Super Product" help Name of the Product config VMAJOR_STR string "Major Version" default "xx" help Major Version for the firmware config VMINOR_STR string "Minor Version" default "xx" help Minor Version for the firmware endmenu #======================================================================== # Tools Setup #======================================================================== menu "Tools Setup" config CROSS_COMPILER_PREFIX string "Cross Compiler prefix" default "arm-elf-" help Cross compiler pre-fix, such as arm-elf-, xscale_le- config APP_COMPILER_PREFIX string "Cross Compiler prefix for App Build" default "arm-uclibc-" help Cross compiler pre-fix, such as arm-uclibc-, for application build. This is often used in the case where uclibc is preferred over standard C library. endmenu #======================================================================== # Config all the modules in the firmware #======================================================================== menu "Modules Configuration" config BUILD_WHOLE_IMAGE bool "Build Whole Image" default y help Build Whole Image config ENABLE_EVERYTHING bool "Enable All Modules" default n depends on BUILD_WHOLE_IMAGE select ENABLE_ALIGNMENT_MODULE select ENABLE_STATE_MACHINE_MODULE help To enable all modules config ENABLE_ALIGNMENT_MODULE bool "Enable Alignment Module" default n depends on BUILD_WHOLE_IMAGE help To Enable Alignment Module config ENABLE_STATE_MACHINE_MODULE bool "Enable State Machine Module" default y depends on BUILD_WHOLE_IMAGE help To Enable State Machine Module comment "---------------------------------" depends on BUILD_WHOLE_IMAGE config CHECK_ABOUT_SIGNATURE bool "Check About Signature" default y depends on BUILD_WHOLE_IMAGE help To check the integrity of about signature at startup comment "====================================" config REBUILD_COMMON bool "Rebuild Common Module" default n help Rebuild Common Module endmenu
In order to process Config.in, the source tree in Figure 8-3 has to be expanded to include the Kconfig module. As demonstrated in Figure 8-6, the new source tree will have a config folder, which homes the Kconfig module extracted from the Linux kernel. The Config.in file from Listing 8-11 resides at the top level.

Source tree with Kconfig integrated
As mentioned earlier, Kconfig supports four different kinds of interfaces that are mapped to respective make targets. Listing 8-11 can thus be tendered in four different ways, as shown in Figures 8-7 through 8-10. The exciting news is that this petty example project now can be configured by a variety of GUIs, which lends it a professional touch.

The make config (command line version)

The make menuconfig (text-mode menu version)

The make gconfig (GTK+ version)

The make xconfig (Qt version)
No matter what interface you prefer, a file called .config will be saved in the config folder afterward. For this project, the .config may look like something in Listing 8-12.
Listing 8-12. .config
# # Automatically generated file; DO NOT EDIT. # Firmware Configuration # CONFIG_HAVE_DOT_CONFIG=y # # About # CONFIG_PRODUCT_NAME="A Super Product" CONFIG_VMAJOR_STR="1" CONFIG_VMINOR_STR="3g" # # Tools Setup # CONFIG_CROSS_COMPILER_PREFIX="arm-elf-" CONFIG_APP_COMPILER_PREFIX="arm-uclibc-" # # Modules Configuration # CONFIG_BUILD_WHOLE_IMAGE=y # CONFIG_ENABLE_EVERYTHING is not set CONFIG_ENABLE_ALIGNMENT_MODULE=y CONFIG_ENABLE_STATE_MACHINE_MODULE=y # # --------------------------------- # CONFIG_CHECK_ABOUT_SIGNATURE=y # # ==================================== # # CONFIG_REBUILD_COMMON is not set
As you can see from Listing 8-12, .config is nothing but a bunch of variable definitions, and they are supposed to be included by Rules.mak or by the top-level makefile. The Rules.mak file in Listing 8-7 is now transformed into Listing 8-13. (Due to the constraint of real estate space, only the part relevant to Kconfig is shown in Listing 8-13.) The new Rules.mak file will include .config at the beginning, and object files should also be dependent on .config, so that they will be rebuilt when new configuration is saved.
Listing 8-13. Rules.mak that Supports Kconfig
... config_targets ?= menuconfig config xconfig gconfig config_folder_name ?= config #check to see if we need to include ".config" ifneq ($(strip $(CONFIG_HAVE_DOT_CONFIG)),y) ifeq (,$(filter $(config_targets), "$(MAKECMDGOALS)")) -include $(TOPDIR)/$(config_folder_name)/.config endif endif ifeq ($(strip $(CONFIG_HAVE_DOT_CONFIG)),y) config_file := $(TOPDIR)/$(config_folder_name)/.config else config_file := endif ... %.o : %.c $(config_file) @echo "===> Building $@" @echo "============> Building Dependency" @$(CROSS_CC) $(CFLAGS) -M $< | sed "s,$(@F)\s*:,$@ :," > $*.d @echo "============> Generating OBJ" @$(CROSS_CC) $(CFLAGS) -c -o $@ $<; \ if [ $$? -ge 1 ] ; then \ exit 1; \ fi @echo "----------------------------------------------------------------------" ...
A top-level makefile should also be revised to invoke Kconfig when .config is missing, as illustrated in Listing 8-14. Compare Listing 8-14 to Listing 8-8; the new makefile is now conspicuously bigger for the following reasons:
-
A big ifeq-else forms the skeleton of new makefile, and the else branch is responsible for invoking the Kconfig when .config is not detected.
-
The ifeq branch is the mainstay of the makefile. Most variables from .config will be processed in this branch, translated into macro definitions, and passed along to source files as compiler options. However, variables like product name and version will be processed in Rules.mak instead of makefile, because they are applicable across the board.
Listing 8-14. Top-Level Makefile with Kconfig Support
TOPDIR := $(shell pwd) export TOPDIR config_targets := menuconfig config xconfig gconfig config_folder_name := config # Pull in the user's configuration ifeq (,$(filter $(config_targets),$(MAKECMDGOALS))) -include $(TOPDIR)/$(config_folder_name)/.config endif ############################################################################ ifeq ($(strip $(CONFIG_HAVE_DOT_CONFIG)),y) link_obj += main/main.o submodules += main ifeq ($(strip $(CONFIG_BUILD_WHOLE_IMAGE)),y) target := demo endif #+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ifeq ($(strip $(CONFIG_ENABLE_ALIGNMENT_MODULE)),y) submodules_sofa += align link_obj += align/align.o CFLAGS += -DCONFIG_ENABLE_ALIGNMENT_MODULE endif #+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ifeq ($(strip $(CONFIG_ENABLE_STATE_MACHINE_MODULE)),y) submodules_sofa += state_machine link_obj += state_machine/state_machine.o CFLAGS += -DCONFIG_ENABLE_STATE_MACHINE_MODULE endif #+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ifeq ($(strip $(CONFIG_CHECK_ABOUT_SIGNATURE)),y) CFLAGS += -DCONFIG_CHECK_ABOUT_SIGNATURE endif #+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ submodules_carpet = common link_obj += common/common.o CROSS := CROSS_LD := gcc export CROSS #+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ifeq ($(strip $(CONFIG_REBUILD_COMMON)),y) submodules_floor = clean_common submodules_floor_build_command = \ @echo "===> clean common module";\ make -C common clean;\ echo "---------------------------------------------------" endif #+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ export CFLAGS include $(TOPDIR)/Rules.mak ############################################################################ else # need to be configured $(config_targets): @make -C $(config_folder_name) $(MAKECMDGOALS) .PHONY: $(config_targets) endif
To summarize, if you want to integrate Kconfig into your build process, the Rules.mak and makefile demonstrated in this section can serve as a template for your reference. The kernel configuration language is very intuitive, and the support of GUI is its most valuable asset. That’s why I strongly recommend it.
Other Ways to Implement a Build Process
Jumping on the bandwagon is not a virtue, nor is basking in the comfort zone. The main reason I’ve included this section is an attempt to not be single-minded, as the old saying goes: one man’s limerick is another man’s clue trail. The build process that has been illustrated so far centers on makefile, with Kconfig as its configuration sub-process. Personally, I think this is a handy approach for small- and medium-scale firmware projects. However, as you can imagine, there are many other options that you can explore when it comes to a build process. And those alternative approaches will be introduced in this section.
Among those alternative approaches, my personal favorite is SCons, which I will elaborate with practical details. For other options that are introduced in this section, although they may not be the best match for building firmware, they still have their merits.
Automake and Autoconf
Automake (Ref [8]) and Autoconf (Ref [9]) are part of the GNU build system (Autotool) that comprises Automake, Autoconf, Libtool, and Gnulib. Their main purpose is to make it easy to build and distribute packages across a wide variety of platforms. They can fathom out the differences among various platforms and dynamically produce a makefile to resolve those differences. In addition, chores like dependency checks can also be handled by these dynamically generated makefiles.
As illustrated in Figure 8-11, to use Automake and Autoconf, users have to prepare two files: Makefile.am and configure.ac. (Optionally, Makefile.am can include another file called aclocal.m4, which is generated by the aclocal command.) Automake will produce an output file called Makefile.in based on Makefile.am, while Autoconf will generate a script called configure. Afterward, the configure script will be executed to produce a makefile based on Makefile.in. Differences among various platforms will be reflected in this produced makefile.

Automake and Autoconf
Automake and Autoconf can be used to distribute source code packages to a wide variety of hosting systems. The produced makefile will have targets like all and install to facilitate code building and installation. However, being able to build across multiple hosting systems is less of a concern for firmware development, since the chance of moving to a different cross-building environment is quite low over the entire project lifecycle.
With a long list of predefined macros, preparing Makefile.am and configure.ac can be a daunting task. (Part of this complexity comes from the GNU M4 (Ref [10]), which is the macro language processor employed by Autoconf.) That’s why I don’t think Automake and Autoconf are suitable for firmware projects, unless you want to distribute your source packages to a variety of hosting environments.
CMake
CMake (Ref [11]) is a cross-platform build system that supports configuration and dependency detection. To achieve cross-platform use, CMake works with its own flavor of makefile, called CMakeList.txt. The output of CMake is makefiles or project files that your development tool can recognize, such as a Unix makefile, Visual Studio Project File, Borland makefile, etc. CMake relies on these makefiles or project files to do the final build. In that sense, CMake is similar to Automake/Autoconf.
The prerequisite of have CMakeList.txt means developers have to master a new script language in order to use CMake, which is a drawback to many including me. (I’m not ashamed to admit that I have “language inertia”.) And it takes a while to iron out all the quirks before you can write CMakeList.txt with sophistication. Since most firmware projects stick with a single platform (host machine) throughout the whole development cycle, the cross-platform is less attractive to embedded system development.
BJAM
JAM is a build tool first introduced by Perforce Software, Inc. (Ref [12]). And shortly after its inception, several refinements ensued. One of them made its way into the toolset of the Boost Library (Ref [13]), which is now called Boost Build (Ref [14]) or BJAM. Like Autoconf and CMake, BJAM also relies on its own script language (Boost Jam) to conduct the build flow, but it goes further by completely replacing the makefile with a Boost Jam file (Jamroot and Jamfile). In that sense, it is a self-contained build tool.
BJAM supports most mainstream compilers, like GNU C/C++ and Visual C++, and is popular among C++ programmers. Personally, I’ve found it works well if you work with Boost and C++. However, once you walk out of that setting, you will find yourself a lot of hoops to jump through before you can make a successfully customized build. And like CMake, mastering a new script language only for a build is not favorable to many, and it does not have GUI configuration either.
SCons
As you can see from previous sections, those who want to replace the traditional makefile have to pick up a second language. Autoconf relies on GNU M4, CMake uses CMakeList.txt, and BJAM adopts Boost Jam. SCons (Ref [15]) also has invented its own build script. However, unlike the other build tools, SCons’ build script is merely a Python script. In other words, SCons did not invent a new language. Instead, it has invented some new Python functions and classes and put them together to form a new build tool.
The dynamics of Python gives SCons great power. SCons supports dependency detection, external commands, multiple variants, the separation of source and build directories, etc. (Ref [16]). And because its build script is pure Python, those who are already familiar with Python can pick it up easily. Personally, I like the flexibility that SCons can offer. If your embedded project needs a build process other than a make/makefile, I suggest you consider SCons.
To elaborate on this, I have provided an example project in the companion material, which can be used as templates for future development. The corresponding source tree is shown in Figure 8-12.

Source tree for SCons
As you can see, the source tree here bears a striking resemblance to the one shown in Figure 8-3, except for the following:
-
At the top folder, the makefile is replaced by a file called SConstruct. At the sub-folder level, makefiles are replaced by files called SConscript. Both SConstruct and SConscript are in fact Python scripts.
-
I have added another folder called table_gen on top of Figure 8-3 to show how sub-projects can be customized. And table_gen is based on the example for “lookup table auto-generation” from previous chapters.
For SCons, it will always look for a file called SConstruct at the top level. The main purpose of SConstruct is to set up the environment and build all sub-projects with the respective SConscript. For the example in Figure 8-12, the corresponding SConstruct is shown in Listing 8-15.
Listing 8-15. SConstruct Template
... #=========================================================================== # Compiling Environment set up #=========================================================================== include = [".", "#common/include", "#align", "#state_machine"] c_flags = [] cpp_flags = ['-std=c++11'] cc_flags = ['-O3', '-Wall'] sub_projects = ['state_machine', 'main', 'align', 'common', 'table_gen'] output_dir = '#output_files' ... #=========================================================================== # Build Variables set up, use "VERBOSE=yes" for verbose output #=========================================================================== vars = Variables(None) vars.AddVariables( ('VMAJOR', 'major version', '1'), ('VMINOR', 'minor version', '3g'), ('PRODUCT_NAME', 'Product Name', 'A SUPER Product'), BoolVariable('VERBOSE', 'Verbose output', 0), BoolVariable('CONFIG_CHECK_ABOUT_SIGNATURE', 'About Signature enable/disable', 1), BoolVariable('CONFIG_ENABLE_ALIGNMENT_MODULE', 'align module enable/disable', 1), BoolVariable('CONFIG_ENABLE_STATE_MACHINE_MODULE', 'state machine module enable/disable', 1) ) ... #=========================================================================== # setup cross compiler here #=========================================================================== ## default_env.Replace (CC="sdcc") ## default_env.Replace (CXX="arm-g++") ## default_env.Append(ENV = {'PATH' : os.environ['PATH']}) ...
SConstruct is actually a big file. I’ve only shown the part that might need to be customized, such as the sub-project folder name, compiler flag, etc. And for this particular example, macro definitions like VMAJOR, VMINOR, and PRODUCT_NAME can be set in the SConstruct directly or provided through the command line.
At the sub-project level, most SConscript files will look like the one shown in Listing 8-16.
Listing 8-16. SConscript Template
src_files = ['xxxxxx.c'] obj = Object (src_files) Return('obj')
However, project table_gen is an exception. As mentioned in previous chapters, to accommodate large tables, -ftemplate-depth needs to be bumped up with a bigger number. The corresponding SConscript file looks like Listing 8-17.
Listing 8-17. SConscript with a Customized Build Option
src_files = ['Gen_Lookup_Table.cpp'] env = DefaultEnvironment() obj = Object (src_files, CXXFLAGS = env['CXXFLAGS'] + ['-ftemplate-depth=2048']) Return('obj')
SCons can be installed along with Cygwin, or it can be installed separately, as illustrated in more detail in Ref [16]. For the example at hand, the detailed command execution can be seen with the VERBOSE=yes option. And in SCons, the counterpart for make clean is scons --clean or scons -c. Figures 8-13 and 8-14 are the screen captures for them. (BTW, you can always use scons -Q to remove the messages generated by SCons itself.)

SCons Verbose Build

SCons clean
To use the cross-compilers, some of the environment variables, such as CC and CXX, have to be replaced, as shown in the last section in Listing 8-15. Another useful option I can think of for SCons is --debug=explain, which will go through every step with detailed reasoning. It comes in very handy when you have doubts about the dependency decisions that SCons makes for you.
Ant and Maven
For the sake of completeness, I also want to briefly mention some XML-based build tools here. As you can tell from previous sections, makefile is a good match for building in the C/C++ language, and it is heavily dependent on shell scripts. However, when Java was brought to the fore, Java programmers soon found that the combination of a makefile and shell script was not good enough to achieve platform independence. So they came up with new build tools, such as Ant and Maven. My personal interaction with Maven was through Eclipse CDT, where I tried to make a new plugin for it at one point. What makes Maven different from others is that Maven will pull a lot of plugins all over the Internet and use them to build up the whole thing. In my eyes, such an approach works well for cross-platform software like Java, but it may not be a good fit for low-level software (firmware) that are used in the embedded systems.
Building Java programs is beyond the scope of this book. Inquisitive readers can find more detail of Ant and Maven in Ref [17] and Ref [18], respectively.
Embedded OS
The term “embedded system ” runs a wide gamut. At low end, where the CPU has less horsepower and the storage space is compact, firmware runs on bare bones hardware. Hence the low-end systems can make do without any embedded OS. (One with an 8051 processor usually fits this profile.) For those systems, a super endless loop will suffice. Operations are carried out in serial fashion, plus some ISRs (Interrupt Service Routine) to handle asynchronous events.
However, as the system grows, so does the call for multi-threading and better support beyond a simple loop or HAL (hardware abstraction layer ). This naturally brings embedded OS to the fore, as warranted by a more powerful CPU and larger memory.
Among all the embedded OS commercially available, embedded Linux is leading the packFootnote 5. Over the past decade, embedded Linux has been winning market share at the expense of its rivals. And it enjoys a huge developer community that actively refines it on daily basis. Consequently, it was chosen by this book as the epitome of what a typical embedded OS ought to be. As you can imagine, embedded OS is a pandemic subject. This section can only serve as a starting point on this subject.
Choose an Embedded OS
The choice of embedded OS comes from many dimensions. The following factors should play into your decision making.
Royalty and License Costs
Your profit margin will be eroded if the OS vendor charges a royalty. Although many vendors dropped royalty terms after the rise of the open source movement, it is still the first thing to look out for, as it will directly affect your bottom line.
The development costs have to be taken into account as well. Many vendors charge licensing fees for their development tools based on the number of seats. In addition, tech support costs should also be nailed down beforehand.
Open Source and GPL
Embedded OS with open source code has been gaining ground in the past decade. Open source brings more flexibility and less cost, along with a large developer community. Among them, Linux stands out as the bellwether, partly due to its popularity on the desktop PC.
However, adopting an open source kernel may also impose some unappealing duty on your code as well. Take the Linux kernel for example—it’s licensed under the terms of the GPL, which stipulates that any derivative work is obligated to disclose its source code as well. So if you write a Linux device driver for your hardware, and you choose to link your driver into the kernel as a whole, that driver code is supposed to follow the open source terms. In practice though, many commercial products choose to implement their device drivers as a LKM (loadable kernel module) and ship them in binary form. The argument is that LKM is an attachment rather than a derivative work, and is thus not subject to GPL terms. Many companies, big and small, have been hiding their proprietary code under the LKM umbrella for years without any legal hiccups. Nevertheless, since it rides in a gray area, you might need to consult your legal department when it comes to the decision making.
Real Time, Interrupt Latency, and Throughput
Depending on the application scenario, your system may impose real-time requirements on the selection of OS. And there are two kinds of RTOSs (real-time OS) in the world: hard real-time and soft real-time.
An RTOS supporting hard real-time should have a predictable scheduling mechanism to guarantee that each task can be completed within a predetermined interval. No exception is taken. TDMA communication and pacemaker are two typical cases with hard real-time requirement. Besides the RTOS support, hard real-time should be considered at the system level. Each task should be carefully profiled. The CPU speed (normally measured in terms of MIPS) should be evaluated with meticulous number crunching to make sure there is enough computation power and a reasonable design margin.
On the other hand, under a soft RTOS, the majority of the tasks can be finished within the required interval, but a small amount of exceptions are also allowed in the interest of overall performance. A disk controller usually fits this profile, with most IOs being finished quickly, and extra latency on a small number of IOs poses no harm.
To achieve the optimal performance, designers normally have to strike a balance between interrupt latency and throughput. Those two benchmark indexes are closely tied to the RTOS beneath. Thus the maximum interrupt latency should be measured (or checked out through a datasheet) when evaluating the RTOS.
Preemptive and Non-Preemptive Kernels
OS kernels can also be categorized as preemptive and non-preemptive. Under preemptive kernels, a kernel task can be scheduled off CPU when a new one with higher priority becomes ready. However, for a non-preemptive kernel, the active task has to give up the CPU voluntarily before a new one can be scheduled, even when the new one might have higher priority. Tasks under non-preemptive kernels have to work in a very cooperative manner to achieve optimal performance.
Compared to preemptive kernel, non-preemptive ones may enjoy less overhead on rescheduling, but they also require better planning and collaboration among all tasks. Thus there are no carved-on-granite conclusions when choosing between a preemptive and non-preemptive kernel. The evaluation has to be conducted on a case-by-case basis.
Footprint Size
Most embedded OSs will be stored as a compressed image in Flash and expanded into RAM during bootstrapping. A small footprint will be a boon for cost-sensitive products. Thus the real estate expense, both in compressed and uncompressed form, should be taken into account during evaluation.
Hardware Requirements
Most embedded OSs will have a minimum hardware requirement in order in order to function properly. Your available choices are limited by such hard requirements. And those requirements are normally manifested as follows:
-
Specific CPU architecture, such as ARM, MIPS, x86, etc.
-
The existence of MMU.
-
Minimum RAM size requirement.
-
The existence of a particular peripherals, such as a graphic display device with certain dimensions and resolution, or a USB connection. As suggested in Ref [19], Android is a little picky in this regard.
Embedded Linux Development Flow
Despite the plethora of embedded OSs, the development flows of these systems are similar. This book will choose embedded Linux to demonstrate what a typical development flow ought to be.
Choose a Vendor
First off, you have to decide where to get your OS kernel. As for Linux, there are many ways to get an embedded Linux kernel for your target system:
-
One way is to download the vanilla kernel from the Linux Kernel Archives ( http://www.kernel.org ). However, porting kernels to a customized system is not a small undertaking. You run the risk of hitting road blocks that are unforeseen at the beginning.
-
In particular, the vanilla kernel may not fully support what you have in mind. For example, you might want to patch the kernel to reduce the interrupt latency for IO-intensive application scenarios. And there are vendors who provide their own flavors of kernel for various market segments. The good part of not doing it on your own is that you can focus your engineering resources on more important jobs and leave the kernel porting and patching to the hands of experts.
Development Machine Setup
In order to proceed efficiently, you need well-oiled development machines. By machine, what I really mean are servers, workstations, and storage boxes, as illustrated in Figure 8-15:

Servers, workstations, and storage boxes
-
A storage server where your Unix home directory resides : In a typical corporate IT environment, there are multiple Unix/Linux servers. You can have a SSO (Single Sign On ) among those servers through services like NIS or LDAP. No matter what server you log into, your home directory looks exactly the same, because every server mounts its home directory to a centralized storage box. The storage box is normally a NAS (Network Attached Storage ), with RAID (Redundant Array of Independent Disks) protection to survive single/multiple disk failure. Conceptually, you can view the storage box as a Linux server that exports NFS or Samba share. In other words, you should be able to map your Unix/Linux home directory to your Windows PC as a network drive.
-
Server for version control: Your source code, along with all the schematic drawing and documents, is the most valuable asset of your company. You are supposed to treat them seriously by setting up a version control server (e.g., a subversion server) and protecting the data with RAID storage, as shown in Figure 8-15. Strong security policy should also be enforced when accessing this server.
-
Build server: Obviously you have to turn your source code into binary images at some point. Although you can check out source code to your local drive and make intermittent builds on your workstation, it is hard to create a standard process from such a practice. Instead, an independent build server is recommended for the following reasons:
-
1.
It will be very hard to maintain exact the same toolchain across all the workstations. As time goes by, some team members may choose to upgrade the toolchain on their PCsFootnote 6 while others lag behind. A centralized build server can avoid such inconsistencies.
-
2.
There is no doubt that build servers can take the heavy load off workstations. On top of that, a build server is a first step toward CI (Continuous Integration, which will be discussed in later chapters). Basically, you can check out code from version control automatically and have nightly builds (or build on every commit). The build process can be streamlined to catch errors as early as possible.
-
1.
-
Development server: To develop with your embedded OS, embedded Linux in particular, you also need a dedicated server. The development server is responsible for the following jobs:
-
1.
Provide a BOOTP/DHCP service to your development board
Most likely, your target system (or at least the development board) will have an Ethernet connection if you are working with embedded Linux. Although you can manually set up IP addresses for each individual board, it will be more convenient to let your development server do this for you automatically. However, your corporate IT network may also have a DHCP server in place. I suggest you coordinate with your IT department before you enable the BOOTP/DHCP service on your development server. To be on the safe side, it is better to isolate your lab network with your corporate IT network.
-
2.
Provide a TFTP or FTP service to your development board
After your bootloader is successfully executed, it needs to locate your OS kernel image for second stage boot-up. During development, your kernel image can be loaded through RS-232, USB, or EthernetFootnote 7, assuming burning Flash frequently is not a viable option. Although RS-232 is handy, its low throughput does not work well with large images. USB is a good alternative, but not every microprocessor has built-in support for booting from USB. In that sense, Ethernet is a more generic solution. After your board acquires an IP address, it can grab images (which might include kernel, driver, and apps altogether) through the TFTP protocol. (In this regard, some use FTP instead of TFTP.) Every time you have a new image, you can put it on your development server to be deployed to your target boards.
-
3.
Provide an NFS service to your development board
The Linux kernel image is usually in a compressed form. After it is loaded into RAM, it will extract itself and start initialization. At some point, it will try to mount the root file system. During development, the root file system can be a NFS share exported by your development server, and accordingly your kernel image should be configured to mount the root file system through NFS. On the other hand, the root file system should reside on a Flash for your final product, and accordingly the production kernel image should be configured to use a Flash-based root file system.
Using NFS mount gives developers more latitude, and it is normally preferred when things are still in their early stages.
-
1.
-
Workstations: In this regard, I recommend using a Windows-based PC for your development, even if you are targeting embedded Linux. Here is why:
-
1.
Most likely, you will need software for ICE or FPGA programming as well during the course of your embedded development. This type of software is usually Windows PC-based.
-
2.
For embedded Linux , you will need a good terminal emulator as your debug console. My personal experience is that the Windows-based ones, such as Tera Term, are easier to use than their Linux counterparts.
-
3.
I like to map my home directory to my PC, edit the code with my favorite Windows-based editorsFootnote 8, and build the code on the server (telnet/ssh). Of course, this is more of a personal preference. But as mentioned earlier, you are supposed to do most of your builds on the server; that is what build server is set up for.
-
1.
Prepare the Toolchain
To make your code into binary, you need a cross-compiler. More precisely, you need a toolchain that includes a cross-compiler, linker, assembler, debugger, and other tools (such as objdump, objcopy, etc.). The toolchain is supposed to be installed on the build server and maintained by designated personnel.
There are three main ways to get the toolchain:
-
If you get your bootloader, OS kernel, or development tool from a vendor, the vendor will normally provide you with a pre-built toolchain . Having the blessing from your vendor can help you avoid many hidden roadblocks. So use your vendor’s toolchain if you can get ahold of one.
-
You can also download some pre-built toolchain for free from the Internet, such as the ELDK (Embedded Linux Development Kit , Ref [20]) from DENX Software Engineering, the pre-built GNU cross toolchain (Ref [21]) contributed by eCosCentric Limited, or the one from Linaro (Ref [29]).
-
If you are using GNU toolchain, you can build the toolchain by yourself. But I suggest you do it only when you don't have any vendor supplied toolchain, or can’t you find a free toolchain to match your host/target processor architecture.
Building a toolchain can be tedious, and it might also involve some special patches for your particular host/target processor architecture. If you choose uClibc as your C library, you can build your toolchain with BuildRoot (Ref [22]). Otherwise if you prefer glibc, you can get crosstool (Ref [23]) to help you build the toolchain.
Prepare the Bootloader
As mentioned in previous chapters, bootloader is the first program to be executed after the system powers on, and it is responsible for system initialization and for loading the OS kernel image. Because of this, embedded OS normally has its favored bootloaders. As for embedded Linux, bootloaders like RedBoot (Ref [24]) and U-Boot (Ref [25]) are popular among developers. After you get your toolchain ready, the next step is to port a bootloader to your target system.
Although it is always possible to port these bootloaders on your own, a more practical approach is to start with a BSP (Board Support Package). When CPU vendors roll out their latest models, they, or some third-party companies, normally provide a demo board or development kit that has the CPU plus some peripherals and connectors. Along with the development kit, there will be a BSP that has the bootloader readily available. (Sometimes it also includes an OS kernel and device drivers.) Usually you can get the bootloader source from the board vendor and use that as your baseline. As far as bootloader is concerned, the delta between your target board and the development kit is most likely in memory address map and the peripherals.
Prepare the OS Kernel Image
Just like the bootloader, you can port the Linux kernel based on an existing BSP. (Assuming you can find one that meets your requirements.) Or you can get an OS vendor to do the porting for you. The nitty-gritty of Linux kernel is beyond the scope of this book. Refer to Ref [26] for more information.
As mentioned earlier, you can make two flavors of kernel images. One is intended for NFS-mounting to your development server; the other is a standalone kernel that mounts the root file system onto Flash. The former is convenient for development, and the image can be grabbed by the bootloader through TFTP. The latter is mainly for the final product.
Prepare the Device Driver
Demo board and development kit are good references for hardware design. Chances are that your target system may be a close cousin of those demo boards, which uses the same microprocessor. And the main delta in hardware design will most likely be in memory mapping and new peripherals.
For those new peripherals, you will have to write device drivers for them. Writing device driver requires deep knowledge of Linux kernel, and is thus beyond the scope of this book. Refer to Ref [26][27][28] for more information.
Your device driver can be linked to the kernel source, and thus become part of the kernel image. Or it can be a LKM (Loadable Kernel Module ) that is loaded by shell script. As mentioned earlier, some companies use LKM to circumvent the GPL, and thus avoid disclosing their proprietary source code. However, since this is a legal gray area, consult your corporate lawyers for advice.
Prepare the Applications
As shown in previous chapters, anything above the OS and device driver can be called an application. And for applications, there are oodles of choices when it comes to their implementation. You can take the traditional approach by coding them in C/C++. Or you can use Java to create apps based on the virtual machine. You can even include a full-blown web server in your system if you have enough hardware resources. Due to the multitude of choices, the final decision has to be made on a case-by-case basis.
Prepare the Release Image
After you have all the previous tasks completed, you can start preparing the Flash image for your final product, which includes:
-
1.
Configuring the kernel image to mount the root file system on Flash partitions.
-
2.
Preparing the root file system. Instead of including the standard Unix/Linux command executables, you might consider using packages such as Busybox to significantly reduce the footprint size.
-
3.
Packaging your device drivers and applications into Flash partitions. The partition can use read-only Flash file systems, such as CramFS.
-
4.
Preparing the shell script to mount partitions, load device drivers, and start applications.
-
5.
If necessary, preparing other Flash partitions, such as a JFFS2 partition for read/write.
-
6.
Configuring the bootloader to load OS kernel images from Flash.
Finally, save the whole Flash image for release!
Summary
As the scale of your system grows, you need a formal build process to deploy your firmware consistently and promptly. The Make utility is a handy tool for this job. In fact, with the help of KConfig, you can even create for your build process a GUI-based configuration.
In addition to the Make utility, other build tools were also discussed and compared in this chapter. Among them, SCons stands out as a good alternative to Make.
Adopting embedded OS will be inevitable when multitasking becomes crucial to do your job. The second part of this chapter discussed the criteria for RTOS selection, as well as the general flow for embedded Linux development.
Notes
- 1.
The Make utility will check the timestamps to determine whether targets are older than any of the prerequisites.
- 2.
Another way to process the return value is to use the $? variable, which will be demonstrated in later sections.
- 3.
Nested includes are also covered in this list.
- 4.
Mutual or cyclic dependency could happen under complex circumstances. For example, both module A and module B could reference each other's configuration header files config_A.h and config_B.h, while these configuration header files are supposed to be generated dynamically during the build process. Due to their complexity, mutual dependency and cyclic dependency are usually solved on an ad hoc basis, and they will not be discussed in this book.
- 5.
The renowned Android OS is also based on the Linux kernel.
- 6.
Here I take the liberty of assuming that PC is the standard service rifle for embedded developers. Apple fans, feel free to replace it with iMAC. :-)
- 7.
Of course, you can always use JTAG ICE. But ICE is an expensive piece of equipment, and it might be overkill if all you need is to load something into memory and run it.
- 8.
As you can imagine, I am no expert on emacs.
References
Learning Perl on Win32 Systems. Randal L. Schwartz, Erik Olson, Tom Christiansen, O'Reilly Media, August, 1997
Learning Python, 3rd Edition. Mark Lutz, O’Reilly Media, 2008
Managing Projects with GNU Make, Third Edition. Robert Mecklenburg, O'Reilly Media, November, 2004
“Recursive Make Considered Harmful.” Peter Miller, AUUGN Journal of AUUG Inc., 1997
Cx51 Compiler User’s Guide, “Optimizing C Compiler and Library Reference for Classic and Extended 8051 Microcontrollers,” Keil Software Inc., September, 2011
“The Kernel Configuration and Build Process.” Greg Kroah-Hartman, Linux Journal, Issue #109, May, 2003
kconfig-language.txt, ( http://www.kernel.org/doc/Documentation/kbuild/kconfig-language.txt )
GNU Automake, version 1.11.1, David MacKenzie, Tom Tromey, Alexandre Duret-Lutz, Free Software Foundation, Inc., December 8, 2009
Autoconf, Creating Automatic Configuration Scripts, version 2.68, David MacKenzie, September, 2010
GNU M4, version 1.4.16, Rene Seindal, Francois Pinard, Gary V. Vaughan, and Eric Blake, Free Software Foundation, Inc., February, 28, 2011
CMake 2.8 Documentation ( http://www.cmake.org ), Kitware, Inc., Insight Software Consortium., 2009
JAM Product Information ( http://www.perforce.com/documentation/jam )
Boost C++ Library ( http://www.boost.org )
Boost.Build V2 User Manual, Vladimir Prus, 2009
SCons: A Software Construction Tool ( http://www.scons.org )
SCons User Guide 2.4.1, Steven Knight and the SCons Development Team, 2015
Ant: The Definitive Guide, 2nd Edition. Steve Holzner, O'Reilly Media, April, 2005
Maven by Example, Sonatype Inc., 2011
Embedded Android—Porting, Extending, and Customizing. Karim Yaghmour, O'Reilly Media, October, 2011
ELDK 5.1 Documentation ( http://www.denx.de/wiki/ELDK-5/WebHome )
Pre-built GNU cross toolchain ( ftp://ecos.sourceware.org/pub/ecos/gnutools/ ), contributed by eCosCentric Limited
Buildroot: Making Embedded Linux easy ( http://buildroot.uclibc.org )
Building and Testing gcc/glibc cross toolchains ( http://kegel.com/crosstool )
RedBoot ( http://ecos.sourceware.org/redboot )
Das U-Boot: The Universal Boot Loader ( http://www.denx.de/wiki/U-Boot/WebHome )
Linux Kernel Development, 3rd Edition. Pearson Education, Inc., 2010
Linux Device Drivers, 3rd Edition. Jonathan Corbet, Alessandro Rubini, Greg Kroah-Hartman, O'Reilly Media, February, 2005
Embedded Linux, Hardware, Software, and Interfacing. Craig Hollabaugh, Ph.D., Pearson Education, 2002
Linaro ( https://www.linaro.org/ )
Author information
Authors and Affiliations
Rights and permissions
Copyright information
© 2016 Changyi Gu
About this chapter
Cite this chapter
Gu, C. (2016). Building and Deployment. In: Building Embedded Systems. Apress, Berkeley, CA. https://doi.org/10.1007/978-1-4842-1919-5_8
Download citation
DOI: https://doi.org/10.1007/978-1-4842-1919-5_8
Published:
Publisher Name: Apress, Berkeley, CA
Print ISBN: 978-1-4842-1918-8
Online ISBN: 978-1-4842-1919-5
eBook Packages: Professional and Applied ComputingApress Access BooksProfessional and Applied Computing (R0)