
Abstract
The actor–partner interdependence (APIM) and common-fate (CFM) models for dyadic data are well understood and widely applied. The actor and partner coefficients estimated in the APIM reflect the associations between individual-level variance components, whereas the CFM coefficient describes the association between dyad-level variance components. Additionally, both models assume that the theoretically relevant and/or empirically dominant component of variability resides at the same level (individual or dyad) across the predictor and outcome variables. The present work recasts the APIM and CFM in terms of dyadic nonindependence, or the extent to which a given variable reflects dyad- versus individual-level processes, and describes a pair of hybrid actor–partner and common-fate models that connect variance components residing at different levels. A series of didactic examples illustrate how the traditional APIM and CFM can be combined with the hybrid models to describe mediational processes that span the individual and dyad levels.
Similar content being viewed by others


A number of procedures for analyzing dyadic data have been developed over the past decades (see Kenny, Kashy, & Cook, 2006, for a review). The most widely applied method, known as the actor–partner interdependence model (APIM; Campbell & Kashy, 2002; Kenny, 1996), focuses on the individual-level relationships between one dyad member’s predictor(s) and the partner’s outcome (i.e., partner effects), as well as the member’s own outcome (i.e., actor effects). In contrast, the common-fate model (CFM; Kenny, 1996; Kenny & La Voie, 1985) focuses on dyad-level associations between the predictor and outcome variables by treating individual-level responses as indicators of dyad-level latent variables. Both models are essentially mono-level, to the extent that they assume that the theoretically relevant and/or empirically dominant component of variability resides at the same level of analysis (i.e., individual, dyad) across the predictor and outcome variables. These assumptions may be problematic, because the array of theories describing dyadic interaction and interdependence often postulate both top-down and bottom-up processes (e.g., models of dyadic stress and coping; Karney, Story, & Bradbury, 2005; Neff & Karney, 2004) that cannot be effectively captured by the inherently mono-level perspective of either the APIM or the CFM. The present work seeks to recast these models in terms of dyadic nonindependence, or the extent to which a given variable reflects dyad- versus individual-level processes, in order to set the stage for a pair of hybrid actor–partner (AP) and common-fate (CF) models, which connect variance components residing at different levels.
The idea that variables measured at different levels of analysis may influence one another is obvious to researchers familiar with the traditional nested designs commonly found in educational and organizational research (Snijders & Bosker, 2011), as well as in longitudinal studies examining individual change (Singer & Willett, 2003; West, Ryu, Kwok, & Cham, 2011). However, a cursory review of published research suggests that, with a few notable exceptions (Conger, Rueter, & Elder, 1999; Galovan, Holmes, & Proulx, 2017; Ledermann & Kenny, 2012), these basic ideas may be underdeveloped among researchers examining dyadic processes. Indeed, the idea of cross-level processes in dyadic analyses has largely been limited to circumstances in which observed dyad-level variables (i.e., number of children, length of relationship) are included as predictors of individual-level outcomes (e.g., relationship satisfaction). Providing dyadic researchers with a framework for understanding how the dyad-level components of individual variables may serve as indicators of a dyad-level latent variable, which in turn may predict either individual- or dyad-level variance components, has the potential to expand the range of phenomena under investigation by relationship scientists.
The present work begins by deconstructing the APIM and CFM into their constituent submodels, to illustrate how these analytic approaches treat the nonindependent or “shared” component of variance differently. This modular approach to dyadic analysis leads to a number of interesting insights and applications. For instance, understanding the empirical conditions favoring the traditional APIM or CFM allows for a more judicious application of each. Moreover, a pair of hybrid models follow logically from this perspective, which allow one to examine the relationship between predictors and outcomes in terms of the shared dyadic-level variance of one variable and the unique individual-level variance of the other.
Deconstructing dyadic data
Understanding the inner workings of the APIM and CFM and their relation to the forthcoming AP–CF and CF–AP hybrid models requires a basic familiarity with the underlying sample moments from which the model parameters are estimated. Without loss of generality, we adopt a generic design in which a single predictor and outcome variable are measured for each dyad member at a single time point, and we assume that dyad members are distinguishable on the basis of some attribute (e.g., birth order, sex), though the basic principles discussed here generalize to situations in which multiple predictors are postulated, as well as to dyads that comprise indistinguishable members (i.e., same-sex couples). In the present example, each dyad member (a, b) provides a score for the predictor (X) and outcome (Y), resulting in sample matrices containing four observed variables, Xa, Xb, Ya, Yb, which give rise to six linear relationships among these person-level variables. These associations can be represented either in unstandardized form, as variances and covariances, or as correlation coefficients. The present work draws on both representations.
Intradyadic correlations
Intradyadic (ID) correlations describe the association between scores on the same variable for individuals belonging to the same dyad (e.g., rXa,Xb). ID correlations also serve as a direct measure of non-independence, or the extent to which individuals belonging to the same dyad report similar (or dissimilar) levels for a given variable, accounting for mean differences across dyadic roles. Values of rid = + 1 and rid = – 1 suggest perfect rank order concordance or discordance (respectively) between members of the same dyad, and ID correlations of 0 reflect a complete absence of association. Shifting the level of analysis from the individual to the dyad, the squared ID correlation represents the proportion of variability that is between dyads. Moreover, as the absolute value of the squared ID correlation increases, the proportion of variance shared by individuals belonging the same dyad also grows larger. For example, an ID correlation of + .80 indicates that individuals belonging to the same dyad report very similar values for the variable, after accounting for role-specific differences in mean levels (e.g., male partners may report lower levels of commitment to the relationship), and that 64% of the variability is common among dyad members. Perhaps less intuitive is the case in which an ID correlation is – .80. In this case, 64% of the variability is still shared, although it implies that persons belonging to the same dyad are less similar to one another than two randomly selected pairs of individuals. As a result, a negative ID correlation suggests when one dyad member reports a higher score on the attribute of interest, the other dyad member is likely to have a lower score (again, accounting for mean differences across roles).
The poles of the continuum illustrated in Fig. 1 describe situations of complete nonindependence (rid = – 1, rid = + 1), characterized by perfect correlation (positive or negative) among the dyad member responses, which are represented by Venn diagram circles that completely overlap. Kenny and colleagues (2006) designated variables with an ID correlation of rid = – 1 as within variables, which may reflect a zero-sum attribute of the relationship (e.g., the proportion of housework performed) or identify a respondent’s role (e.g., gender, illness status), in the case of distinguishable dyads. Variables with ID correlations of rid = + 1 are between variables, which reflect dyad-level attributes that are common to both members (e.g., relationship length, marital status). The center of the continuum corresponds to independent variables, which exhibit no agreement between members of the same dyad (i.e., rid = 0). Most variables fall somewhere between the poles and midpoint of the continuum, and are known as mixed variables; however, unlike within and between dyad variables, mixed variables also contain some component of unique (person-specific) variability within the dyad.

Dyadic nonindependence continuum
Actor–partner correlations
Actor–partner (AP) correlations describe either the relationship between the predictor and outcome variables within the same person (Actor correlations), or the association between the predictor for one person and the outcome for their dyadic partner (Partner correlations). For example, rActor a is the correlation between the predictor for person a (Xa) and the outcome for person a (Ya), whereas the relationship between the predictor for person b (Xb) and the outcome for person a (Ya) is reflected in the rPartner a correlation. At first glance the interpretation of the AP correlations appears unambiguous, however, when considered in conjunction with the ID correlations, it becomes apparent that in most cases (i.e., samples and variables for which rid ≠ 0) these actor and partner correlations are confounded by shared dyadic variance. As a result, from a traditional multilevel modeling perspective, the observed AP correlations reflect a weighted average of their constituent individual- and dyad-level relationships (Kreft, De Leeuw, & Aiken, 1995; Lüdtke et al., 2008; Preacher, Zyphur, & Zhang, 2010). The commonly used actor-partner and common-fate models may be distinguished by which component of the AP correlation their parameters capture and model. Following sections will discuss these differences in detail, along with the role of shared dyadic variance in shaping our interpretation of the structural coefficients estimated in dyadic regression models.
Modeling dyadic nonindependence
Observed person-level variables in dyadic studies often capture variability that is unique to the individual along with some part that is nonindependent, or shared between the dyadic partners (i.e., “mixed” variables). Researchers have long known that nonindependence in outcome variables must be taken into account in order for the inferential tests applied to other parameters to be valid (Kashy & Grotevant, 1999; Kenny, 1995; Kenny & Judd, 1986), and prior work has described two procedures that model nonindependence between dyad members: the random-intercept method (Raudenbush, Brennan, & Barnett, 1995) and the covariance method (Griffin & Gonzalez, 1995), each of which is illustrated in Fig. 2. For the sake of generality, these diagrams employ the traditional LISREL notation utilized by Bollen (1989), and the observed variables are treated as endogenous.

The latent-variable and covariance approaches to modeling dyadic nonindependence
Under the random-intercept specification (top panel), the observed response for each dyad member serves as a factor indicator of a dyad-level latent variable (ηYdyad). As an essential identifying constraint (Bollen, 1989), the loadings for this random intercept are fixed to 1, and as such, each person’s observed score contributes equal weight to the dyad-level latent variable. The disturbance term for this variable (ζYdyad) reflects dyad-specific deviations, whereas the error terms for the observed variables (εYa, εYb) represent person-specific deviations from the dyad-level factor score. The variances of these terms can be described using measurement model parameters, ψY, θYaa, θYbb (respectively). Moreover, because the number of estimated parameters equals the number of elements in the data covariance matrix, these model parameters can be expressed in terms of their sample moments. Most notably, the variance of the dyad-level latent variable (ψY) equals the covariance between dyad member responses, cov(YaYb), whereas the model parameters for the individual-level residual variances equal the observed (unconditional) variance [i.e., var(Ya), var(Yb)], minus the covariance among dyad member responses [cov(Ya, Yb)]. This demonstration illustrates that the random intercept model neatly decomposes variables representing observed person-level variables (i.e., mixed variables) into between-dyad (ψY) and within-dyad (θYaa, θYbb) variance components. As a result, these parameters can also be used to express the intra-class correlation (ICC) coefficient, or the proportion of (total) variance in person-level responses attributable to (shared) dyad-level influence (Snijders & Bosker, 2011).
The covariance approach (bottom panel) is comprised of a nondirectional path linking the disturbances of person-level responses provided by members of the same dyad (Ya, Yb). Because this relationship is treated as an “unanalyzed association” or unconditional relationship (Bollen, 1989, p. 33), the model parameters describing the variances of these disturbances represent total (rather than person-specific) variability, which is a mixture of person- and dyad-level factors (as well as measurement error). As before, the ICC or intradyadic correlation can be expressed in terms of model parameters and observed sample statistics. It is also clear that both specifications will perfectly replicate the sample covariance matrix, and that the parameters of one are recoverable from the other.
Although these methods constitute mathematically equivalent ways of modeling dyadic nonindependence, the practical consequences of their application may differ dramatically depending on the context in which they are applied. The most salient difference between these approaches stems from the manner in which nonindependence between dyad members is parameterized. Specifically, the random intercept method explicitly models dyad-level variability as a parameter (ζY), whereas the covariance approach treats dyadic nonindependence as merely an unanalyzed association. As a result, the random intercept method allows the researcher to directly access the dyad-level variance component present in mixed variables, in the form of factor scores (i.e., dyad-specific deviations), which can in turn be used as predictor or outcome variables in a larger structural model.
Finally, it is worth noting that the random intercept approach may become difficult to implement as the intradyadic covariance approaches zero [i.e., cov(Ya, Yb) ➔ 0]. Under these conditions, the dyad-level latent variable may become empirically underidentified because all of the variability in responses resides at the individual level. This aspect of the random intercept specification underscores our argument that the degree of dyadic nonindependence present in a given data set has strong implications for the feasibility of certain dyadic regression models, specifically models featuring a random intercept. Difficulties can also arise when rid is negative because they suggest that a given dyad member is less similar to his or her dyadic partner than to another person in the sample. This causes problems for the latent variable approach because the dyad-level variance (ψY) cannot be negative. However, this limitation may be overcome by fixing one of the factor loadings to − 1, which maintains the correct model-implied covariance while allowing the estimated factor variance to be positive (Ledermann & Kenny, 2012).
A modular perspective on existing dyadic regression analysis
The present section introduces a modular approach to dyadic regression analysis by recasting the traditional APIM and CFM in terms of dyadic nonindependence. This synthesis sets the stage for a pair of hybrid models that will allow researchers to approach dyadic analysis from a new perspective.
The actor–partner interdependence model
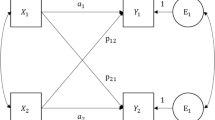
The actor–partner interdependence approach is a multiple regression model in which the outcome variable for each member of the dyad is regressed on each dyad member’s predictor variable. The traditional specification (Kenny, 1996; Kenny et al., 2006) is illustrated as a path diagram in the upper-left panel of Fig. 3 and is described by the following equations:
where Y is the outcome variable and ν represents the regression intercept. The Greek letter kappa (κ) is used to represent these observed-on-observed variable regressions, with subscripts describing the type of APIM coefficient and the dyad member (i.e., a, b), and the εYa and εYb terms represent the person-specific errors or residuals. For illustrative purposes, the present example assumes that the individuals in question are members of heterosexual relationships, so that they are distinguishable on the basis of gender. The path leading from one dyad member’s own predictor to his or her own outcome is known as the actor effect (i.e., κactor a, κactor b; Kenny et al., 2006), and the path leading from a dyad member’s own predictor to his or her partner’s outcome is known as the partner effect (i.e., κpartner a, κpartner b).

Diagrams for the APIM (left) and CFM (right)
These actor and partner coefficients describe the associations among individual-level variables, addressing research questions that are inherently intradyadic in nature. Notably, because the actor and partner regression coefficients represent partialed or unique relationships, the association between the shared or confounded component of the individual-level predictors is not reflected in the APIM regression coefficients. The degree of confounding is directly related to the proportion of shared dyadic variance on the predictor variable, as indicated by the rid X correlation. For example, the κactor a coefficient represents the unique association between the predictor for men and the outcome for men, after removing the component of the raw rActor a correlation that is shared with the rPartner a correlation. The standardized actor and partner coefficients can be expressed in terms of raw correlations by applying the rules of covariance algebra (Bollen, 1989; Kenny, 1979) to the model equations:
Notice that in the numerator of Eq. 3, the correlation between person a’s predictor and person b’s outcome (rPartner a) and the intradyadic correlation (rid X) are first multiplied and then subtracted from the raw actor correlation (rActor a). This means that as the magnitude of rid X increases, the value subtracted from rActor a grows larger, and the κactor a coefficient diverges further from the raw actor correlation. Conceptually, these formulae are consistent with a general understanding of multicollinearity in regression analysis: As the magnitude of the correlation between predictors (i.e., rid X ) increases, more of the total variability and potential covariability is shared between predictors (dyad members). As such, the interpretability of the κactor and κpartner coefficients becomes less clear as the ratio of the predictor ID correlation to the AP correlations grows larger (i.e., ID:AP > |1|), because the concept of individual-level association begins to disintegrate when a significant portion of (co)variability occurs between dyads (not individuals). In contrast, the models described in the following sections feature dyad-level latent variables as predictor, outcome, or both.
The common-fate model
The CFM, first described by Kenny and La Voie (1985) and later refined by others (Galovan et al., 2017; Griffin & Gonzalez, 1995, Gonzalez & Griffin, 2002; Kenny, 1996; Ledermann & Kenny, 2012), is a latent-on-latent regression that comprises dyad-level latent variables measured by individual-level predictor and outcome variables. The measurement components of the model are expressed by the following equations linking the observed individual-level variables to dyad-level latent variables:
The upper-right panel of Fig. 3 provides the path diagram for the generic CFM. Because each of the latent variables is measured by only two observed variables, both factor loadings are fixed to a constant (i.e., 1.0) in order to identify the latent variables. These latent variables capture dyad-level information regarding the relative standing of each dyad relative to others in the sample. The structural relationship between the dyad-level latent variables is described by the following equation:
The βshared coefficient in Eq. 9 describes the relationship among the factor scores for the predictor (ηX) and outcome (ηY) latent variables, which reflects the association between the dyad-level variability in the predictor and outcome constructs. As such, the CFM addresses research questions that are predominately interdyadic in nature (i.e., Do couples who report higher levels of responsiveness experience greater commitment?). Finally, dyad-specific disturbances are carried by the zeta (ζ) term.
CFM overidentifying restrictions
In contrast to the unconstrained APIM, the standard CFM is overidentified, because the number of unique data elements in the sample covariance matrix (ten) exceeds the number of parameters estimated (seven), resulting in three degrees of freedom, which correspond to a set of overidentifying restrictions (Bollen, 1989; Kenny, 1979). Practically, these restrictions express the CFM assumption that the components of shared variance captured by the latent variables are consistently related to one another (i.e., equal AP covariances), with the number of equalities corresponding to the number of degrees of freedom. As with the APIM, covariance algebra can be used to derive a hand calculation formula for the standardized model coefficients:
The resulting standardized βshared coefficient describes the relationship between the dyad-level predictor and outcome variables. The tenability of these overidentifying restrictions is evaluated by the χ2 test of model fit. Though the offending restriction is often evident from the sample covariance matrix, the violation can also be identified by inspecting the model residual covariance matrix, provided by all structural equation modeling software platforms. The value of this coefficient will range from − 1 to + 1, as long as the generalized mean of the ID correlations (i.e., the denominator) is greater than the generalized mean of the AP correlations (i.e., the numerator). Alternatively, when the AP correlation exceeds the mean ID correlation, βshared will be greater than 1 (i.e., |βshared| > 1). This introduces difficulties in both interpretation and statistical inference, because ηX will appear to “overpredict” ηY (i.e., ΨY < 0) and the standard errors for the estimated coefficients cannot be computed. Finally, the formula described in Eq. 10 is undefined when either rid X or rid Y is 0, so the βshared coefficient cannot be computed unless both the predictor and outcome variables contain shared dyadic variance. These basic ratios (i.e., ID correlations > AP correlations; ID correlations > 0) establish boundaries for the raw sample correlations, confirming that the CFM is most appropriate when dyadic nonindependence is high; however, the relationship between the sample correlations and CFM parameters is further complicated by a series of restrictions on the pattern of AP associations.
In practice, the overidentifying restrictions imposed by the CFM are often violated (Ledermann & Kenny, 2012), and modifications to the model are required in order to obtain an unbiased estimate for βshared. Consider a scenario in which three of the AP correlations are of equal magnitude (e.g., rActor a = rPartner a = rPartner b = .3), but one of the correlations is notably different (e.g., rActor b = .6). Under these conditions the standard CFM overidentifying restrictions are only partially satisfied, because rActor a = rPartner a = rPartner b ≠ rActor b. The violated restrictions can be relaxed by allowing the residuals of the offending variables (e.g., Xb and Yb) to correlate. These residual paths are important to the CFM, because the average AP correlation will overestimate the strength of the dyad-level association when the AP correlations are heterogeneous.
Sometimes only two or three of the AP correlations are approximately equal in magnitude. In these situations, one or two of the overidentifying restrictions will be violated, and an additional residual covariance parameter must be included for each. The choice of which residual covariance to include is far from arbitrary, because the AP correlation corresponding to the modeled covariance is no longer influencing the estimate of βShared. As a result, the residual paths that correspond to the larger of the errant AP correlations should be estimated in order to ensure that the βshared coefficient reflects the more conservative estimate of the shared dyad-level association. Consider a scenario in which two of the AP correlations are approximately equal to one another (e.g., rActor a ≈ rPartner a ≈ .3), but differ from the other two AP associations (e.g., rActor b = .5, rPartner b = .7). An unbiased estimate of βshared would be obtained by specifying the residual covariances that correspond to the larger AP correlations (i.e., ΘActor b, ΘPartner b). In contrast, specifying residual covariances that correspond to the smaller AP correlations leads to an inflated βShared coefficient, because the more conservative AP correlations (i.e., rActor a, rPartner a) do not contribute to the estimate of the shared dyad-level coefficient. As a general rule of thumb, when the model is correctly specified, the estimated residual covariances in the correct specification will have the same sign as the βshared coefficient. However, it is also important to consider the impact that these residual covariances have on the interpretation of the shard dyadic coefficient, because the resulting shared coefficient no longer represents the combination of all AP correlations. Thus, in cases in which the assumption of equal AP correlations is violated, it may be argued that the CFM does not provide an optimal characterization of the dyadic relationships, and other models, such as those presented below, may provide a better alternative.
Analysis and critique of traditional actor–partner and common-fate models
Prior work has advised researchers to rely on theory (Kenny, 1996) or the contextual features of each measured construct (Galovan et al., 2017; Ledermann & Kenny, 2012) when approaching dyadic analysis, whereas the present work points out that empirical aspects of the predictor and outcome variables (i.e., the magnitude and direction of the ID and AP correlations) also influence the feasibility of each model. Although the APIM and CFM feature the same four observed variables (Xa, Xb, Ya, Yb), meaning that either could be applied in a given scenario, examining the APIM and CFM through the lens of dyadic nonindependence reveals that the models address fundamentally different aspects of the dyadic process. The bottom panel of Fig. 3 provides a conceptual representation of the coefficients estimated in each model, using the Venn diagram scheme introduced earlier. More specifically, the APIM is a multivariate regression model, in which the person-specific components of the predictor variable are captured by the regression coefficients. In contrast, the CFM is a latent-on-latent regression model, in which the component of shared dyadic variances is both empirically present and theoretically prominent for both the predictor and outcome variables.
The mono-level regressions featured in the APIM and CFM implicitly assume that nontrivial levels of variance reside at the between- and within-dyad levels, respectively, for both the predictor and outcome variables. However, in practice, research questions may naturally arise that involve one construct that is inherently person-specific (e.g., trait anger), for which the corresponding observed variables exhibit relatively little nonindependence (e.g., |rid pred| < .05), and another variable (e.g., constructive communication) that is more dyadic in nature (e.g., |rid out| > .40). The remainder of this article demonstrates that loosening the traditional restrictions on these models leads to a pair of hybrid models that are both conceptually intuitive and theoretically compelling.
Hybrid actor–partner and common-fate models
The APIM and CFM implicitly assume that predictors and outcomes contain comparable levels of dyadic nonindependence and that the shared dyadic variance either serves as the focal point of the analysis for both the predictor and outcome (CFM) or is removed (partialed out) from the structural coefficients (APIM). In practice, a researcher’s questions may involve the dyad-level component of one construct and the individual-level component of another. Moreover, the empirical reality observed in a given dataset—specifically, the magnitude of the ID correlations—may lead the researcher to focus on the dyad- or individual-level variance components of the predictor or outcome. The first hybrid model relaxes these constraints by examining a situation in which individual-level variables predict shared dyadic outcomes (i.e., the AP–CFM), and the second illustrates a scenario in which the shared dyadic component of the predictor variance is associated with individual-level outcomes (i.e., the CF–APM). Because the coefficients linking predictor and outcome variables cross levels of analysis, the concept of a standardized coefficient is ambiguous for these hybrid models. This is not surprising, given the convention within multilevel modeling (Hox, 2010) of discussing the relationships among predictors and outcomes solely in terms of unstandardized coefficients. As such, the formulae provided for the hybrid models will more closely approximate the unstandardized solutions provided by statistical software. Mplus code for these hybrid models can be found in the Appendix.
It is also important to note that minor discrepancies between hand-calculated and software-estimated solutions can be attributed to the use of standardized coefficients (correlations) rather than raw sample moments (covariances) in the hand calculation formulas. We chose to present approximate formulae based on correlations because they are more comprehensible and intuitive than the more exact solutions based on covariances and variances. As a result, the hand calculation formulas presented here do not account for differences in the variances across dyad members. These formulas will also differ from those provided by software, because of minor violations of overidentifying restrictions. Although algebraically correct, the formulas for both hybrid models will provide results identical to those from software only under very specific conditions, and they should be regarded primarily as didactic tools.
The AP–CFM hybrid model
The AP–CFM is a structural equation model featuring a dyad-level latent outcome regressed on each person-level predictor variable. The path diagram describing the AP–CFM is illustrated in the upper left panel of Fig. 4. The measurement model for the dyad-level latent variable was provided in Eqs. 7 and 8, and the structural portion is expressed by Eq. 11.

Diagrams for the AP–CFM (left) and CF–APM (right) hybrid models
As before, ηY represents the dyad-level latent variable measured by each member’s observed outcome, whereas Xa and Xb represent observed predictors for each dyad member. The gamma (γ) parameters represent these latent-on-observed variable regressions, with subscripts describing the type of APIM coefficient and the dyad member. These coefficients describe the unique association between each person-level predictor and the shared dyadic component of the outcome variable. For example, if Y variables are scores on a measure of relationship satisfaction, and Xa is interpersonal trust for male members of heterosexual couples, the γa coefficient describes the degree to which men with higher levels of trust tend to belong to dyads reporting higher levels of relationship satisfaction. As in any model with multiple predictors, the association with the shared or “confounded” component of the predictor is not reflected in these coefficients, and the degree of confounding is directly related to the proportion of shared dyadic variance on the predictor variable (i.e., rid X). As such, the AP–CFM is most applicable in situations in which rid X is weak and rid Y is moderate or strong.
Expressing AP–CFM coefficients using sample correlations
The AP–CFM has a pair of overidentifying restrictions stipulating that the AP covariances originating from the same dyad member must have the same magnitude. Specifically, the actor correlation for partner a is assumed to have the same magnitude as the partner correlation for partner b (i.e., rActor a = rPartner b), because both correlations involve the predictor variable for partner a (Xa). Similarly, the partner correlation for partner a must equal the actor correlation for partner b (i.e., rPartner a = rActor b), because both correlations involve the predictor for partner b (Xb). These restrictions are conceptually logical, in that they stipulate that person-specific predictor variance is consistently related to the shared dyadic variance component for the outcome variable. The overidentifying restrictions result in a baseline model with two degrees of freedom, and accepting these restrictions allows for an approximate solution for the coefficients:
where, in an approximate sense, roriginate a ≈ Mean(rActor a, rPartner b) and roriginate b = Mean(rActor b, rPartner a). The resulting γ coefficients describe the relationship between individual-level predictors and a dyad-level outcome variable in terms of the AP correlations that originate from dyad members a (i.e., rActor a, rPartner b) and b (rActor b, rPartner a). Interestingly, these formulae are identical to those for computing the APIM actor and partner coefficients described earlier. Indeed, imposing the AP–CFM constrains on the traditional APIM leads to equivalent models; however, later sections will illustrate that the AP–CFM allows for greater flexibility in modeling complex dyadic processes when the outcome variable exhibits a high degree of dyadic nonindependence. These formulae suggest that the structural coefficients linking the predictor and outcome variables become attenuated (relative to the zero-order correlations) as shared predictor variance increases, making the AP–CFM best suited for variables with weak intradyadic correlations among the dyad member predictors.
AP–CFM example for trait anger and constructive communication
The following example illustrates the AP–CFM by drawing on previously validated measures selected from the Parent Survey of 500 Family Project (Schneider & Waite, 2000), and focuses on 242 heterosexual couples with teenage children. The participants responded to two items from Taylor’s Anger scale (Taylor & Tomasic, 1996; “My anger is unpredictable,” “I get more angry than I should”; r = .67) using a scale ranging from 0 (Never) to 4 (Very Often), and a predictor variable representing person-level anger scores was created by computing the mean of these items. Additionally, a person-level observed variable representing constructive communication style was created using a pair of items introduced by the following prompt: “There are various ways that couples deal with serious disagreements. When you have a serious disagreement with your spouse/partner, how often do you. . . .” A composite was created by averaging participants’ responses to two items (“Discuss disagreements calmly,” “Argue heatedly or shout out at each other” [R]; α = .65), measured on a scale ranging from 1 (Never) to 5 (Very Often).
The right panel of Table 1 provides the raw correlations (lower triangle), covariances (upper triangle), and variances (lower tier) for the variables of interest. As we noted in the previous analysis, the ID correlation for constructive communication was strong and positive (r = .454), though the ID correlation for the other predictor was essentially zero (r = − .002), suggesting that dyad members exhibit no similarity in trait anger. All of the observed AP correlations were negative in direction, and ranged from − .195 to − .500, suggesting that the dyad-level variance components were consistently related to one another.
The model χ2 for the fully constrained baseline AP–CFM with person-level anger predicting dyad-level constructive communication was statistically significant [χ2(2) = 26.75, p < .01], suggesting that one or both of the overidentifying restrictions were likely violated. A closer inspection of the sample correlation matrix revealed that the rActor M correlation (r = − .500) was notably larger than the corresponding rPartner W correlation (r = − .202), suggesting that the overidentifying restriction associated with roriginate a was likely violated. As a result, the AP–CFM was respecified with a covariance linking the residuals of men’s anger and women’s constructive communication (i.e., ΘAnger.m,Const.Comm.w), since this covariance corresponded to the stronger correlation in violation of the overidentifying restriction, and this single degree-of-freedom model exhibited a marginally significant chi-square value [χ2(1) = 2.94, p = .09] indicating that the remaining overidentifying restriction was likely satisfied.
Parameter estimates for the final model are provided in the left panel of Table 1. The path linking men’s individual-level anger to dyad-level constructive communication was negative and significant (γmen = − .18, 95%CI: [− .28, − .07]), suggesting that male partners with greater anger tend to cultivate relationships characterized by less constructive communication. Similarly, the coefficient describing the association between women’s anger and dyad-level communication was also negative and significant (γwomen = − .26, 95%CI: [− .35, − .17]), and collectively, person-level anger scores were able to account for approximately 37% of the variance in dyad-level communication [1 − (.154/.244) = .368]. As expected, the residual path ΘAnger.m,Const.Comm.w was negative and significant, suggesting that the γmen coefficient underestimates the relationship between men’s anger and men’s communication, but not women’s communication.
The hand-calculated coefficients were comparable to the estimates provided by Mplus for both men {γmen = − .202 − (− .002 × − .254)/[1 − (− .0022)] = − .318/.999 = − .202} and women {γwomen = − .254 − (− .002 × − .202)/[1 − (− .0022)] = − .254/.999 = − .254}.Footnote 1 Because anger scores are independent across dyad members (i.e., rid X = 0), the estimated coefficients are very similar to the AP correlations. The discrepancy between the hand-calculated and software-estimated solutions arises from the heterogeneity of variances across dyad members and from trivial violations of the remaining overidentifying restriction.
Summary of AP–CFM
The AP–CFM is most useful when the predictor exhibits low levels of dyadic nonindependence but the outcome variable displays a moderate (or greater) level of nonindependence. Moreover, the AP–CFM is only applicable when the AP relationships originating from the same dyad member type have the same sign. As in the traditional CFM, violating this overidentifying restriction requires the estimation of residual covariance paths, so that unbiased estimates are obtained for the structural coefficients. It could be argued that the AP–CFM represents either a restricted form of the simple APIM, in which κactor a = κpartner b and κactor b = κpartner a, or a relaxed form of the CFM, with nondirectional paths connecting the residuals of Xa to Ya or Yb, and Xb to Ya or Yb. Though partially correct, these interpretations are incomplete, because they neglect both the conceptual and empirical importance of shared dyadic variance. For example, if the outcome variable reflects an inherently dyad-level construct such as interpersonal trust, and if the predictor construct is more person-centric (e.g., level of abuse experienced as a child), the AP–CFM provides a more theoretically sensible approach for evaluating the structural relationship between these variables than does the traditional APIM or CFM. The following section describes a complementary model, featuring a dyad-level predictor and individual-level outcomes, that is most applicable when nonindependence is high for the predictor but low for the outcome variable.
The CF–APM hybrid model
The CF–APM is a structural equation model in which individual-level outcome variables are regressed on a dyad-level latent variable. The path diagram describing the CF–APM is illustrated in the upper-right panel of Fig. 4. The measurement model for the dyad-level latent variable was provided in Eqs. 7 and 8, and the structural portion is expressed by the following equations:
Ya and Yb represent the observed person-level outcome variables, and the νs are their respective intercepts, whereas ηX is the dyad-level latent predictor variable. The lambda (λ) parameters represent the association between the dyad-level predictor attribute and each individual-level outcome variable in these observed-on-latent variable regressions. For example, if the Y variables are scores on a measure of anxiety symptoms and X is a measure of perceived financial security, the λ coefficients describe the extent to which individuals belonging to dyads with greater financial security report fewer anxiety symptoms. The CF–APM describes the relationship between the shared or “confounded” component of the predictor and the individual-level component of the outcome variable. As a result, the CF–APM is most applicable in situations in which rid X is moderate or strong, and it can be a better alternative to the CFM when rid Y is weak.
Expressing CF–APM coefficients using sample correlations
The CF–APM has two overidentifying restrictions, stipulating that AP correlations terminating at a dyad member’s outcome must have the same magnitude. Specifically, the actor and partner correlations for partner a must equal one another (i.e., rActor a = rPartner a), because both correlations involve the outcome variable for partner a (Ya), and the actor and partner correlations for partner b must also be equal (i.e., rActor b = rPartner b), because both correlations involve the outcome for partner b (Yb). These restrictions make conceptual sense, in that they suggest that shared dyadic variance in the predictor variable is consistently related to person-specific variance in each dyad member’s outcome. The overidentifying restrictions result in a baseline model with two degrees of freedom. Accepting these restrictions allows for an approximate solution for the coefficients:
where rterminate a ≈ Mean(rActor a, rPartner a) and rterminate b ≈ Mean(rActor b, rPartner b). The resulting λ coefficients describe the relationship between the dyad-level predictor and individual-level outcome variables in terms of AP correlations that terminate at the dyad members a (i.e., rActor a, rPartner a) and b (rActor b, rPartner b). Violation of the overidentifying restrictions will bias these coefficients unless residual covariance paths are estimated in order to relax the constraint. As before, the residual covariance path should be estimated for the largest correlation in the offending pair, so that the λ coefficient will be based on the more conservative estimate of the relationship between the dyad-level predictor and person-level outcome.
CF–APM example for marital satisfaction and depression
Drawing again on the 500 Families dataset, descriptive statistics for measures of marital satisfaction (i.e., the ENRICH martial inventory; Fowers & Olson, 1993; Nielsen, 2005) and depression symptoms (CES-D; Radloff, 1977) are provided in the right panel of Table 2. The ID correlation for marital satisfaction was strong and positive (r = .583), whereas the ID correlation for depression was essentially zero (r = .04). As expected, the AP correlations were negative and ranged from − .224 to − .430, and the χ2 test of model fit for the baseline AP–CFM was statistically significant [χ2(2) = 12.15, p < .01], suggesting that at least one of the overidentifying restrictions was not satisfied. In the present example, the rActor W correlation (r = − .379) is notably larger than the corresponding rPartner W correlation (r = − .224). As a result, the AP–CFM was respecified with a residual covariance linking the residuals of women’s martial satisfaction and women’s depression (i.e., ΘMarSat.w,Depress.w). The revised model had a single degree of freedom, χ2(1) = 0.51, p = .48, and a nonsignificant chi-square, suggesting that the remaining overidentifying restriction was likely satisfied.
Parameter estimates for the final model are provided in the left panel of Table 2. The path linking dyad-level satisfaction to men’s depression was negative and significant (λmen = − .68, 95%CI: [− .88, − .48]), suggesting that male partners belonging to dyads with greater satisfaction report significantly lower levels of depression. Similarly, the coefficient describing the association between dyadic satisfaction and women’s depressive symptoms was also negative and significant (λwomen = − .36, 95%CI: [− .55, − .17]). The residual path relaxing the overidentification restriction on the correlations terminating at women’s depression was negative and significant (ΘMarSat.w,Depress.w = − 10.27, 95%CI: [− 16.39, − 4.15]), which is consistent with the idea that the total relationship between women’s satisfaction and depression also comprises an individual-level component. As before, the hand-calculated coefficients were similar to the estimates provided by Mplus for both men (λmen = − .376/.583 = − .64) and women (λwomen = − .224/.583 = − .38).Footnote 2
Summary of CF–APM
The CF–APM describes the extent to which shared dyadic variance in the predictor is related to individual-level outcome variance. Because of this, the CF–APM requires a nontrivial component of dyad-level variance in the predictor, as well as AP relationships terminating at the same dyad member’s outcome with a common sign and nonzero magnitude. Under these conditions, the λ coefficients provide a powerful test of the association between dyad- and individual-level variance components. Although a simplified version of the CF–APM could be estimated by regressing individual-level outcomes on an observed dyad-level composite formed from the individual-level predictors, this approach is problematic for a number of reasons. First, an observed dyad-level composite would contain both reliable (true-score) variance and random measurement error, which would attenuate the structural coefficients relative to the latent-variable approach. Second, the observed dyad-level predictor method confounds individual- and dyad-level correlations, because the true-score variance in the observed predictor contains both individual- and dyad-level components. In contrast, using a latent-variable approach to partition predictor variance into distinct sources allows for a more powerful and precise evaluation of these processes.
Analysis of the hybrid AP–CF and CF–AP models
The latent-variable approach to modeling dyadic nonindependence allows the researcher to partition the variance in individual-level variables into person- and dyad-specific variance components, and thus constitutes a useful tool for examining the relationships between dyad-level variance in the predictors and individual-level variability in the outcomes, and vice versa, through the CF–AP and AP–CF models. The lower panel of Fig. 4 provides a conceptual representation of the effects estimated in each model, using the Venn diagram scheme. The gamma coefficients (γ) located at the top of the diagram connect unique (person-specific) variance in each predictor to the shared dyadic variance component in the outcome. More conceptually, these coefficients describe how individual-level variables relate to a dyad-level outcome variable. In contrast, the lambda coefficients (λ) located at the bottom of the figure connect the shared variance in the predictor to individual-level variance in the outcome variable, corresponding to a top-down process in which the dyad-level variance of individual-level predictors relates to individual-level outcomes. The modular approach to dyadic analysis described here casts the observed individual-level and latent dyad-level variables as “model building blocks” for simple bivariate (single-predictor, single-outcome) regression models. However, this perspective readily generalizes to more complex designs involving multiple predictors, outcomes, or even intervening variables, as is illustrated in the following section.
Application: Combining traditional and hybrid approaches to examine cross-level mediation
The hybrid models presented here have the potential to broaden the way researchers investigate dyadic processes. One example is the potential for these models to allow one to examine the indirect effect of an individual- or dyad-level predictor on individual- or dyad-level outcomes, via mediating variable(s) residing at either level of analysis. The idea that constructs operationalized at different levels may influence one another is familiar to researchers working with traditional nested designs, such as experience-sampling studies (West et al., 2011; Wickham & Knee, 2013), and a compelling body of methodological work has emerged describing the theoretical and conceptual aspects of the associated statistical models (Bauer, Preacher, & Gil, 2006; Lüdtke et al., 2008; Preacher et al., 2010). In the context of dyadic research, one possibility is that dyad-level processes may be the mechanism though which individual-level predictors influence individual-level outcomes, as is illustrated in Fig. 5. This path diagram describes a mediation model composed of the bivariate APIM, AP–CFM, CFM, and CF–APM used the previous examples. In the first stage, an AP–CFM describes the relationship between individual-level trait anger and dyad-level constructive communication. Dyad-level communication goes on to predict dyad-level relationship satisfaction in a CFM, and in the third stage, dyad-level relationship satisfaction is linked to individual-level depressive symptomology in a CF–APM. Finally, direct paths linking individual-level anger and depression scores correspond to the APIM.

Cross-level dyadic regression model
Cross-level mediation example
The model illustrated in Fig. 5 was specified using the final configuration for each bivariate analysis (i.e., including the previously specified residual covariances), and it proved an excellent fit for the data: χ2(11) = 9.83, p = .54, RMSEA = .034, 90% CI: [.000, .062]. The AP–CFM coefficients linking anger to constructive communication were negative and significant for both men (γmen = − .20, 95%CI: [− .30, − .11]) and women (γwomen = − .26, 95%CI: [− .36, − .16]), suggesting that individuals reporting higher levels of depression tend to cultivate relationships with less constructive communication patterns. Moreover, the CFM coefficient linking dyad-level communication and marital satisfaction was positive and significant (βshared = 7.83, 95%CI: [5.74, 9.93]), suggesting that couples reporting more constructive communication were more satisfied. In the final stage, the CF–AP coefficients were negative and significant for both men (λmen = − .54, 95%CI: [− 0.77, − 0.32]) and women (λwomen = − .70, 95%CI: [− 1.00, − .40]), indicating that individuals in relationships characterized by higher satisfaction tended to report lower levels of depression. Finally, the direct actor path linking anger and depression was significant for men (κactor m = 2.76, 95%CI: [1.65, 3.87]), but not for women (κactor w = 0.90, 95%CI: [− 0.35, 2.14), whereas the partner path was nonsignificant for men (κpartner m = −0.26, 95%CI: [− 1.30, 0.79]), but a significant negative coefficient was observed for women (κpartner w = − 1.69, 95%CI: [− 2.84, − 0.54]).
The model in Fig. 5 contains four indirect pathways through which anger may influence depression via constructive communication and martial satisfaction. The indirect actor paths (i.e., Indiractor m = γmen × βshared × λmen; Indiractor w = γwomen × βshared × λwomen) link an individual’s own anger score to his or her own depression, whereas the indirect partner paths (i.e., Indirpartner m = γwomen × βshared × λmen; Indirpartner w = γmen × βshared × λwomen) link an individual’s partner’s predictor to his or her own outcome. Because the sampling distribution for these indirect effects is likely to be nonnormal (Shrout & Bolger, 2002), 95% confidence intervals were estimated using the nonparametric bootstrapping (k = 5,000) procedure provided by Mplus (Muthén & Muthén, 2014). The indirect actor effect for women (Est. = 1.42, 95%CI: [0.54, 2.31]) was nearly two times larger than the corresponding effect for men (Est. = 0.86, 95%CI: [0.24, 1.48]), but the indirect partner effects were identical for men (Est. = 1.11, 95%CI: [0.44, 1.77]) and women (Est. = 1.11, 95%CI: [0.35, 1.87]). None of the confidence intervals for these indirect effects contained zero, which suggests that the magnitudes of these pathways are likely different from zero.
The results of these analyses are consistent with the argument that individual trait-level anger is associated with individual-level depressive symptoms, and that this relationship may be explained (in part) by dyad-level communication style and martial satisfaction. That is, individuals who report higher levels of trait anger cultivate close relationships characterized by less constructive communication style. In turn, dyads exhibiting lower levels of constructive communication also tended to report lower levels of relationship satisfaction. Diminished satisfaction at the dyad level undermines individual-level well-being, as manifested in higher levels of depressive symptomology.
General discussion
Researchers have long been aware that individual-level responses collected from members of the same two-person group (i.e., dyad) are often correlated, which violates the assumption of the independence of observations imposed by general linear modeling approaches (Kenny, 1996). Moreover, a critical evaluation of the dyadic literature suggests that applied researchers tend to regard nonindependence among responses as “nuisance” variance that must simply be accounted for so that they may get on to the business of addressing their substantive research questions. In contrast, the present work argues that nonindependence among the responses provided by members of the same dyad is intrinsically meaningful, because it reflects the degree to which the construct of interest represents an individual- versus a dyad-level process. This perspective encourages researchers to consider the magnitude of intradyadic correlations and the relative strength of actor–partner correlations when selecting a dyadic regression model, because failing to do so may lead to a suboptimal analytic approach that may obscure potentially interesting relationships. We also argue that the traditional APIM and CFM possess an implicit assumption of uniformity regarding any nonindependence in predictor and outcome variables that is both unnecessary and unrealistic. In response, a pair of hybrid models, AP–CFM and CF–APM, were described, which connect predictor and outcome variables across the individual and dyad levels, allowing researchers to pose research questions involving top-down and bottom-up processes. Traditional and hybrid models can also be combined in order to examine cross-level mediation models, which can describe processes that otherwise might be obscured by unilevel APIM-only (Ledermann, Macho, & Kenny, 2011) or CFM-only (Ledermann & Macho, 2009) mediation models.
Comparison to prior work
A number of prior methodological and empirical publications have described variations on the standard APIM and CFM, and the commonalities among previous work and the present discussion warrants analysis. For example, the didactic example used in Teachman, Carver, and Day (1995) primer on dyadic analysis features paths linking person-level variables to dyad-level latent variables as part of a larger process model, as have Conger and colleagues (Conger et al., 1999; Matthews, Conger, & Wickrama, 1996), as well as Burk and Laursen (2010). Although many of these expositions were well ahead of their time (particularly Teachman and colleagues), they differ from the present work in a number of important ways. Most critically, the present article is the first to fully articulate the relationship between lower-order sample moments (i.e., correlations or covariances) and the corresponding hybrid model parameters. Moreover, the present article is distinct in its modular perspective on dyadic analysis, which allowed us to make more concrete recommendations regarding model selection and specification based on the degree of dyadic non-independence present in a given construct.
Ledermann and Kenny (2012) and, more recently, Galovan et al. (2017) also described a number of interesting variations on the traditional CFM, some of which are directly relevant to the models discussed here. For example, the default CFM described by Ledermann and Kenny is less restrictive (df = 1) than the version presented here (df = 3) and is characterized by two additional covariances linking each dyad member’s X-variable residual to their own Y-variable residual. The authors went on to describe a number of variations on this general design, including a “pure CFM,” which is identical to the generic CFM presented here, as well as an equivalent respecification of their default model in which person-specific random intercepts are substituted for the within-person residual covariances (“two-factor CFM”). Ledermann and Kenny also proposed a “multilevel CFM” in which directional paths between person-level observed X and Y variables are estimated, in addition to the dyad-level direct path between latent X and Y, which is noteworthy for a number of reasons. Finally, as part of a final worked examples, the authors presented a cross-level mediation model in which individual-level actor and partner paths lead to a dyad-level mediator, and ultimately dyad-level outcome.
Ledermann and Kenny (2012) argued that the choice of whether to focus on the individual or dyad level operationalization of a construct depends on the measurement (e.g., item wording) and research objective. For example, they argued that self-report items that address individual-level behavior or attitudes (e.g., “I tell my partner how I feel,” p. 141) may be more appropriately addressed by the APIM, whereas questions that address the relationship as the object (e.g., “We tell each other how we feel,” p. 141) may be best modeled by the CFM. Although the authors also acknowledged that empirical aspects of the construct (i.e., level of nonindependence) may limit the feasibility of CFMs in some circumstances, they stopped short of advocating that researchers look to nonindependence as a guiding feature when selecting models for dyadic analysis. Galovan et al. (2017) expressed a similar viewpoint, and also provided an interesting discussion of the theoretical issues regarding the distinction between level of measurement and level of analysis. The present work does not advocate that researchers rely solely on sample correlations to guide model specification, but rather consider sample correlations as setting practical boundaries for the feasibility of estimating person, dyad, or cross-level processes. We also argue that when large, representative sample data are available, researchers should be less wary of using ID correlations to inform their model specification.
It is also important to consider the present work in terms of the broader literature on multilevel structural equation modeling (MSEM; Preacher et al., 2010). In fact, the cross-level dyadic models presented here and in prior research (Burk & Laursen, 2010; Conger et al., 1999; Kenny & La Voie, 1985; Ledermann & Kenny, 2012; Matthews et al., 1996; Teachman et al., 1995) appear to contradict Preacher and colleagues’ demonstration that under the standard MSEM formulation, lower-level observed variables may not directly influence higher-level variables. More specifically, contemporary MSEM thinking (Lüdtke et al., 2008; Preacher et al., 2010) holds that mediational processes for hierarchically nested data are essentially mono-level, because the random intercepts partition the variance of lower-level observed variables into lower- and upper-level components that are orthogonal. However, the decomposition of the structural coefficients in the AP–CF and CF–AP models provided here (Eqs. 12–13, 15–16) suggests that the data structure generated by dyads may constitute an exception to this general rule in which lower-level observed variables may exert a direct influence on variables at a higher level (and vice versa).
Our discussion was restricted to situations in which dyad members are distinguishable (e.g., heterosexual couples, nontwin siblings, or therapist–client dyads), because the overidentifying restrictions on the hybrid models are much more stringent (and less likely to be satisfied) when dyad members are indistinguishable (e.g., same-sex dyads or monozygotic twins). For indistinguishable dyads there are no longer explicit roles, so the rActor a and rActor b correlations for each dyad member are the same (i.e., rActor), as are the rPartner a and rPartner b correlations (i.e., rPartner). Additionally, because the overidentifying restrictions of hybrid models require actor and partner correlations to be equal (rActor = rPartner), by extension, all AP correlations are assumed to be equal in these models. A formal evaluation of hybrid models for indistinguishable dyads is left for future work.
Extensions and limitations
The multiplicative product (Xa × Xb) of the individual-level predictors for each dyad member is another form of between-dyad predictor. These Actor × Partner interactions allow the researcher to address hypotheses related to dyadic coordination or matching effects (Wickham & Knee, 2012). Indeed, the Actor × Partner interaction represents a fundamentally different process from the shared dyad-level coefficient described by the CFM or the individual-on-dyad regressions native to the CF–APM. In the context of the APIM, coordination refers to changes in outcome that occur when dyad members have similar (or dissimilar) values on the predictor variable and are based on differences in the levels of matching (or mismatching) across the dyads in the sample of interest. Specifically, a positive coefficient for the Xa × Xb predictor suggests that dyads in which both members have high or low scores will have higher values on an individual dyad member’s outcome.
The logic supporting Actor × Partner effects in the APIM generalizes to the AP–CFM hybrid model, and the interpretation of the interaction term is nearly identical. The only qualification is that in the context of the AP–CFM, a positive coefficient for the Xa × Xb predictor indicates that dyads in which both members have high or low scores will have higher values on the dyad-level variance component of the outcome variable. Wickham and Knee (2012) showed that allowing the magnitude of the Actor × Partner interaction to vary across dyad member role identities (e.g., male–female) results in an APIM analysis that directly corresponds to the source and outcome matrices that form the basis of interdependence theory (IT; Kelley et al., 2003). Future work should seek to integrate the previously established connections between the APIM and IT with the hybrid models introduced here.Footnote 3
The present work has focused on situations in which predictor and outcome constructs are operationalized by a single observed measure, though the basic principles discussed here generalize to more complex situations in which multiple indicators of a predictor or outcome variable are available for each dyad member. Finally, future work should also further explore issues concerning statistical power for the hybrid models described here (in addition to the traditional APIM and CFM), as well as model specification and estimation considerations when the observed variables are not continuous (i.e., nominal, count, or censored).
Concluding remarks
The present work has recast the components of well-understood and widely applied dyadic regression models in terms of nonindependence. We showed that the APIM removes the influence of dyadic nonindependence (between-dyad variance) from the primary parameters, whereas the CFM treats nonindependence as a central feature of the model (relegating within-dyad variance to the error terms), which suggests that in conditions under which the APIM is less applicable (i.e., higher levels of nonindependence), the CFM is ideally suited, and vice versa. The present work also introduced two hybrid models, which relax the uniformity-of-nonindependence assumption implicitly imposed by the APIM and CFM. As such, all of the approaches to dyadic analysis presented here should be viewed as complementary frameworks, with distinct theoretical and empirical implications. Understanding the conditions that favor each of the models should encourage a more informed and effective use of these valuable analytic tools.
Notes
Because a residual covariance parameter was estimated, the correlation not represented by the residual path (rPartner Women = − .202) was used for rorigin in the hand-calculated estimate.
Because a residual covariance parameter was estimated, the correlation not represented in the residual path (rPartner Women = − .224) was used for rterm in the hand-calculated estimate.
Under conditions of multivariate normality, the first-order variables (e.g., Xa and Xb) are uncorrelated with their product term (Aiken & West, 1991, pp. 191–192). As a result, the product term of dyad member responses to the predictor or outcome should not be included as indicators in the CFM or CF–APM latent variables. Including the product term in these models would lead to model identification and convergence problems.
References
Aiken, L. S., & West, S. G. (1991). Multiple regression: Testing and interpreting interactions. Newbury Park: Sage.
Bauer, D. J., Preacher, K. J., & Gil, K. M. (2006). Conceptualizing and testing random indirect effects and moderated mediation in multilevel models: New procedures and recommendations. Psychological Methods, 11, 142–163. https://doi.org/10.1037/1082-989X.11.2.142
Bollen, K. A. (1989). Structural equations with latent variables (Wiley Series in Probability and Mathematical Statistics). New York: Wiley.
Burk, W. J., & Laursen, B. (2010). Mother and adolescent reports of associations between child behavior problems and mother–child relationship qualities: Separating shared variance from individual variance. Journal of Abnormal Child Psychology, 38, 657–667.
Campbell, L., & Kashy, D. A. (2002). Estimating actor, partner, and interaction effects for dyadic data using PROC MIXED and HLM: A user-friendly guide. Personal Relationships, 9, 327–342.
Conger, R. D., Rueter, M. A., & Elder, G. H. (1999). Couple resilience to economic pressure. Journal of Personality and Social Psychology, 76, 54–71.
Fowers, B. J., & Olson, D. H. (1993). ENRICH marital satisfaction scale: A brief research and clinical tool. Journal of Family Psychology, 7, 176–185.
Galovan, A., Holmes, E. K., & Proulx, C. (2017). Theoretical and methodological issues in relationship research: Considering the common fate model. Journal of Social and Personal Relationships, 34, 44–68.
Gonzalez, R., & Griffin, D. (2002). Modeling the personality of dyads and groups. Journal of Personality, 70, 901–924.
Griffin, D., & Gonzalez, R. (1995). Correlational analysis of dyad-level data in the exchangeable case. Psychological Bulletin, 118, 430–439. https://doi.org/10.1037/0033-2909.118.3.430
Hox, J. (2010). Multilevel analysis: Techniques and applications (2nd). New York: Routledge.
Karney, B. R., Story, L. B., & Bradbury, T. N. (2005). Marriages in context: Interactions between chronic and acute stress among newlyweds. In T. A. Revenson, K. Kayser, & G. Bodenmann (Eds.), Couples coping with stress: Emerging perspectives on dyadic coping (pp. 13–32). Washington, DC: American Psychological Association.
Kashy, D. A., & Grotevant, H. D. (1999). Methodological and data analytic advances [Special Issue]. Personal Relationships, 6(9).
Kelley, H. H., Holmes, J. G., Kerr, N. L., Reis, H. T., Rusbult, C. E., & Van Lange, P. A. M. (2003). An atlas of interpersonal situations. New York: Cambridge University Press.
Kenny, D. A. (1979). Correlation and causality. New York: Wiley-Interscience.
Kenny, D. A. (1995). The effect of nonindependence on significance testing in dyadic research. Personal Relationships, 2, 67–75.
Kenny, D. A. (1996). Models of non-independence in dyadic research. Journal of Social and Personal Relationships, 13, 279–294.
Kenny, D. A., & Judd, C. M. (1986). Consequences of violating the independence assumption in analysis of variance. Psychological Bulletin, 99, 422–431. https://doi.org/10.1037/0033-2909.99.3.422
Kenny, D. A., Kashy, D. A., & Bolger, N. (1998). Data analysis in social psychology. In D. Gilbert, S. T. Fiske, & G. Lindzey (Eds.), Handbook of social psychology (4th ed., Vol. 1, pp. 233–265). New York: McGraw-Hill.
Kenny, D. A., Kashy, D. A., & Cook, W. L. (2006). Dyadic data analysis (1st). New York: Guilford Press.
Kenny, D. A., & La Voie, L. (1985). Separating individual and group effects. Journal of Personality and Social Psychology, 48, 339–348.
Kreft, I. G., De Leeuw, J., & Aiken, L. S. (1995). The effect of different forms of centering in hierarchical linear models. Multivariate Behavioral Research, 60, 1–21.
Ledermann, T., & Kenny, D. A. (2012). The common fate model for dyadic data: Variations of a theoretically important but underutilized model. Journal of Family Psychology, 26, 140–148.
Ledermann, T., & Macho, S. (2009). Mediation in dyadic data at the level of the duads: A structural equation modeling approach. Journal of Family Psychology, 23, 661–670.
Ledermann, T., Macho, S., & Kenny, D. A. (2011). Assessing mediation in dyadic data using the actor–partner interpendence model. Structural Equation Modeling, 18, 595–612.
Lüdtke, O., Marsh, H. W., Robitzsch, A., Trautwein, U., Asparouhov, T., & Muthén, B. (2008). The multilevel latent covariate model: A new, more reliable approach to group-level effects in contextual studies. Psychological Methods, 13, 203–229. https://doi.org/10.1037/a0012869
Matthews, L. S., Conger, R. D., & Wickrama, K. A. S. (1996). Work–family conflict and marital quality: Mediating processes. Social Psychology Quarterly, 59, 62–79.
Muthén, L. K., & Muthén, B. O. (2014). Mplus user’s guide (7th). Los Angeles: Muthén & Muthén.
Neff, L. A., & Karney, B. R. (2004). How does context affect intimate relationships? Linking external stress and cognitive processes within marriage. Personality and Social Psychology Bulletin, 30, 134–148. https://doi.org/10.1177/0146167203255984
Nielsen, M. R. (2005). Couples making it happen: Marital satisfaction and what works for highly satisfied couples. In B. Schneider & L. J. Waite (Eds.), Being together, working apart: Dual-career families and the work–life balance (pp. 196–216). Cambridge: Cambridge University Press.
Preacher, K. J., Zyphur, M. J., & Zhang, Z. (2010). A general multilevel SEM framework for assessing multilevel mediation. Psychological Methods, 15, 209–233. https://doi.org/10.1037/a0020141
Radloff, L. (1977). Center for Epidemiologic Studies Depression Scale. Applied Psychological Measurement, 1, 385–401.
Raudenbush, S. W., Brennan, R. T., & Barnett, R. C. (1995). A multivariate hierarchical model for studying psychological change within married couples. Journal of Family Psychology, 9, 167–174.
Schneider, B., & Waite, L. (2000). The 500 Family Study. ICPSR04549–v1. Ann Arbor, MI: Inter-University Consortium for Political and Social Research [Distributor], 2008-05-30. doi:10.3886/ICSPR04549.v1.
Shrout, P. E., & Bolger, N. (2002). Mediation in experimental and nonexperimental studies: New procedures and recommendations. Psychological Methods, 7, 422–445. https://doi.org/10.1037/1082-989X.7.4.422
Singer, J. D., & Willett, J. B. (2003). Applied longitudinal data analysis: Modeling change and event occurrence. Oxford: Oxford University Press.
Snijders, T. A. B., & Bosker, R. J. (2011). Multilevel analysis: An introduction to basic and advanced multilevel modeling (2nd). Thousand Oaks: Sage.
Taylor, J., & Tomasic, M. (1996). Taylor’s measures of dysphoria, anxiety, anger, and self-esteem. Handbook of Tests and Measurements for Black Populations, 2, 295–305.
Teachman, J. D., Carver, K., & Day, R. (1995). A model for the analysis of paired data. Journal of Marriage and the Family, 557, 1011–1024.
West, S. G., Ryu, E., Kwok, O. M., & Cham, H. (2011). Multilevel modeling: Current and future applications in personality research. Journal of Personality, 79, 2–50.
Wickham, R. E., & Knee, C. R. (2012). Interdependence theory and the actor–partner interdependence model: Where theory and method converge. Personality and Social Psychology Review, 16, 375–393.
Wickham, R. E., & Knee, C. R. (2013). Examining temporal processes in diary studies. Personality and Social Psychology Bulletin, 39, 1184–1198.
Author note
The work of the first author was supported in part by Tobacco Related Disease Research Prevention (TRDRP) Grant #24RT-0027, funded by the State of California. The TRDRP had no role in the study design, collection, analysis, or interpretation of the data; writing of the manuscript; or the decision to submit the article for publication.
Author information
Authors and Affiliations
Corresponding author
Appendix: Mplus input scripts for hybrid models
Appendix: Mplus input scripts for hybrid models

Rights and permissions
About this article

Cite this article
Wickham, R.E., Macia, K.S. Examining cross-level effects in dyadic analysis: A structural equation modeling perspective. Behav Res 51, 2629–2645 (2019). https://doi.org/10.3758/s13428-018-1117-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-018-1117-5