
Abstract
Language has a rhythmic structure, but little is known about the mechanisms that underlie how it is planned. Traditional models of language production assume that metrical and segmental planning occur independently and in parallel (Roelofs & Meyer Learning Memory and Cognition, 24(4), 922–939, 1998). We test this claim in two experiments. In Experiment 1, participants completed an event-description task in which a disyllabic target word shared segmental overlap with a prime that either had matching or nonmatching lexical stress. Participants lengthened words in trials with both segmental and metrical overlap, which could either be the result of metrical interference or having uttered a prime with similar segmental realizations. To adjudicate between these possibilities, Experiment 2 included segmentally distinct word pairs with either matching or nonmatching stress. Participants again showed lengthening in trials with both segmental and metrical overlap, but no lengthening from metrical overlap alone. These data suggest that the acoustic-phonetic similarity of the initial syllables of the prime and target creates competition that leads to word lengthening. These are consistent with production models in which segmental and metrical structures are tightly bound at the point of phonological encoding.
Similar content being viewed by others


Spoken English is composed of continuous chains of stressed and unstressed syllables that create a rhythmic pattern in phrases such as SterlingCooperDraperPryce or DunderMifflinPaperCompany. This rhythmic framework across syllables is called metrical structure or meter. In English, syllables may be stressed by accentuating pitch, intensity, and durational variations, and meter is thought to play a role in segmenting words in the speech signal (Pitt & Samuel, 1990). Meter also plays a role in distinguishing between words that are otherwise identical phonologically, such as DES-ert (a barren landscape) versus dess-ERT (a tasty treat). Despite these observations about meter, it is not clear how word stress is planned and encoded during speech production.
Current theories of lexical production assume that metrical structure is planned independently of segmental structure (Levelt, Roelofs, & Meyer, 1999; Schiller, Jansma, Peters, & Levelt, 2006). According to Levelt et al. (1999), word-form generation involves separately retrieving phonemes and stress patterns, and then associating the phonological segments with the metrical frame. Roelofs and Meyer (1998) conducted a series of implicit priming experiments to test the independence of phonological and metrical encoding within the framework of the Word-form Encoding by Activation and Verification (WEAVER) model (Roelofs, 1997). They tested this by teaching participants prime–target word pairs. During testing, the experimenters presented the subject with a prime and measured the onset latency to articulate the associated target word. Roelofs and Meyer (1998) found that pairs with both segmental and metrical overlap were produced with shorter reaction times, suggesting that overlap can facilitate lexical access by priming the target word. However, they did not find an effect when prime–target pairs shared only one feature—either segmental or metrical structure. Therefore, they concluded that processes associated with planning segmental and metrical structure are independent and run in parallel. They argue that priming one system is not facilitative because the other unprimed system acts as a bottleneck, preventing language production from proceeding until processing in all systems is complete.
Other models have also proposed that segmental and metrical structures are independent (e.g., Keating & Shattuck-Hufnagel, 2002). Evidence for this comes from analyses of speech errors in which speakers misplace sound segments, as in “well-boiled icicle” (well-oiled bicycle) or “Is the bean dizzy?” (Is the dean busy?). Misplaced segments generally maintain their position within a syllable; that is, an onset exchanges for an onset, nucleus for nucleus, and coda for coda (MacKay, 1970; Shattuck-Hufnagel, 1987), suggesting that there is a predetermined metrical outline that is independent of segments. In addition, when speakers produce segmental errors, the overall stress pattern of the utterance is typically preserved (Berg, 1990; Shattuck-Hufnagel, 1986).
In this paper, we investigate whether metrical and segmental representations are actually planned independently or whether they rely on the same representations. To answer this question, we use a paradigm that has been used to understand the processes that underlie phonological encoding. It has been argued that phonological encoding—the process of selecting and ordering the phonemes in a word—occurs serially in time such that phonemes are selected sequentially (e.g., O’Seaghdha & Marin, 2000; Sevald & Dell, 1994). Sevald and Dell (1994) found that word pairs with initial segmental overlap (e.g., pick–pin) are produced at a slower rate than word pairs with final segmental overlap (e.g., pick–tick). They argue that the production of initially overlapping phonemes [pɪ] activate lexical representations for both words, which then compete with one another. This interference leads to overall longer word durations because the system slows down over the course of articulating the entire word in order to accommodate phonological activation time. Lexical competition for overlapping offsets [ɪk] is lower because interference does not occur until the end of the word, which leads to less overall miscuing of the correct sound sequence. These findings suggest that phonological overlap between words may create competition in production planning, for which the system requires additional time for generating the appropriate word form (Watson, Buxó-Lugo, & Simmons, 2015).
This phonological-related lengthening effect has been found in numerous event description experiments (e.g., Buxó-Lugo, Jacobs, & Watson, 2018; Yiu & Watson, 2015). Yiu and Watson (2015) found that when a prime word overlaps phonologically with a target word, the target’s duration increases. In “The beetle shrinks. The beaker flashes,” the target—beaker—has a longer duration than usual due to overlap with the prime—beetle. Using a similar paradigm, Buxó-Lugo et al. (2018) found that these lengthening effects occur even when the prime is produced by another speaker, suggesting that auditory feedback mechanisms may play a role in ordering the sounds of a word (also see Guenther, 2014; Hickok, 2014; Jacobs, Yiu, Watson, & Dell, 2015).
Thus, phonological overlap interference offers a useful tool for investigating speech-planning mechanisms. In the context of the overlap interference paradigm, we can assume that if a target lengthens, the dimension of overlap with the prime is (a) encoded serially and (b) can lead to competition between lexical representations. In the current set of studies, we use this paradigm to examine the organization of metrical and segmental spell-out in two experiments. Our strategy was to first test whether metrical structure has the same effect on duration as segmental structure (Experiment 1). If so, we can then use this paradigm to explore whether segmental and metrical structures are planned independently during phonological encoding or whether they interact (Experiment 2).
In Experiment 1, we manipulated whether primes and targets overlapped metrically while keeping segmental overlap constant. Prime and target words either shared the same metrical structure or had differing metrical structures. If metrical planning engages the same types of encoding mechanisms as segmental planning, we should see similar overlap-driven lengthening effects, with longer productions of a target word when the prime shares the same metrical structure. In Experiment 2, we manipulated both segmental overlap and metrical overlap independently to directly test whether segmental and metrical planning have independent roles in phonological encoding or whether metrical and segmental information interact.
Experiment 1
Method
Participants
Sixty-nine healthy adults (age range: 18–27, M = 20.3 years, SD = 2.4, 51 female) participated in this study, a sample size that was similar to that of previous studies that have used this paradigm (Jacobs et al., 2015; Yiu & Watson, 2015). Participants were native speakers of English recruited from the Vanderbilt University Psychology Department subject pool, and they either received course credit or $10 for participating in the study. All participants provided written informed consent in accordance with the Vanderbilt University Institutional Review Board.
Materials
A set of 144 color images was selected from the Snodgrass and Vanderwart (1980) data set (Rossion & Pourtois, 2001) and clip art. A subset of 72 images served as the critical items, and the remaining 72 images were filler items. Critical items consisted of 18 targets and 54 primes. There were three conditions:
- 1.
Same meter: The candy shrinks. The candle flashes.
- 2.
Different meter: The canteen shrinks. The candle flashes.
- 3.
Control: The giraffe shrinks. The candle flashes.
In the same and different meter conditions, the prime–target pairs had segmental overlap for their initial segments, and the meter of the words either matched (1) or did not match (2). In the control condition (3), the prime–target pairs had no segmental overlap and had nonmatching meter.
A Latin square design yielded three counterbalanced lists of items, such that each participant was presented with 18 critical prime–target pairs. An equal number of trochees and iambs were used as critical targets. Each list had six critical pairs for each of the three conditions. In addition, participants were exposed to 38 noncritical pairs, drawn from the filler items, for a total of 56 trials in the experiment. Trials were randomized for each participant.
Audio recording
Participant responses were recorded via a head-mounted microphone at a sampling rate of 44100 Hz. Participants were instructed to speak directly into the microphone as they described the events on the computer screen.
Procedure
Participants completed the experiment on a Mac computer in MATLAB using the CogToolbox (Fraundorf et al., 2014) and Psychophysics Toolbox 3 (Kleiner, Brainard, & Pelli, 2007). Participants first completed a training task to learn the names of potentially difficult to name items (e.g., Buxó-Lugo et al., 2018). Items were displayed in the center of the screen with the intended label at the top of the screen, and participants recited the label aloud. They were encouraged to use these names during testing.
Following item training, participants received instructions for the experiment. For each trial, four images were displayed equidistant around the center of the screen (see Fig. 1). One image—the prime—would shrink, and participants described the action. Then another image—the target—would flash, and participants described the action. Events occurred in the same order for all trials (i.e., shrinking then flashing). The first three trials were conducted with the experimenter present, and the subject was allowed to ask questions if needed. Trials were randomized and separated into three blocks, allowing participants to take a break between blocks as needed.

Example display of event description task. The images for candy and candle form a critical prime–target pair, and flower and button are filler items
Acoustic analysis
Speech recordings were analyzed in Praat (Boersma & Weenink, 2017), using manual segmentation to code the start and end times of target words. Three coders (including the first author) analyzed a subset of all trials in isolation using spectrographic and waveform information, and coders were blind to experimental condition of the trials. Target words were segmented such that they were not identifiable as anything other than the targets. Praat scripting was used to calculate the duration of each target word. Interrater reliability was assessed by comparing manual coding from a random subset of trials (~10%) between all coders and the first author, who was blinded to the original measurements and experimental condition. The intraclass correlation coefficient (ICC) was calculated using a one-way single-measures approach, and the average of these was ICC = 0.931, indicating excellent agreement between coders.
Results
Target-word durations across conditions were analyzed, and only target utterances that matched the intended label were considered in the analyses. Trials were excluded if participants mispronounced the prime or target, or if they used alternate names (e.g., boat for canoe, orchestra for quartet, cologne for perfume). A total of 97 out of 1,242 trials met these criteria and were removed. Scripts and the complete data set are available at https://osf.io/zk4qv/.
To examine the effects of condition on word duration, results were analyzed using a linear mixed-effects model, with condition as a fixed effect and random slopes and intercepts by item and by participant. Models were built using R package lme4 Version 1.1-10 (Bates, Maechler, Bolker, & Walker, 2015). Data were log transformed and centered. Helmert contrasts were used in model development such that the condition with segmental and metrical overlap was compared with the average of the segmental overlap and control conditions, and the segmental overlap condition was compared with the control condition. Significance was assumed for t values with an absolute value above 1.96 in a two-tailed test (Baayen, 2008).
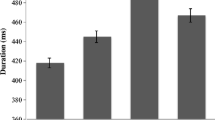
We found that target items with segmental and metrical overlap were significantly longer than target items in the other conditions (β = 0.047, t = 3.729), and target items in the segmental overlap condition were significantly longer than target items with no overlap (β = −0.033, t = −2.446). Table 1 displays parameter estimates for the model. Additionally, iambs were significantly longer than trochees (β = −0.138; t = −2.707), regardless of condition; there was no interaction between meter type and overlap condition. Figure 2 displays average target durations by condition for this experiment.

Average duration (in seconds) of target words by condition in Experiment
Discussion
In this experiment, we replicate previous findings that have shown that segmental overlap leads to significant word lengthening compared with prime–target pairs that do not overlap. We also found that the addition of metrical overlap leads to even more lengthening. This experiment demonstrates that metrical structure plays a role in the dynamics of phonological encoding, and representational similarity at the metrical level between prime and target has the same planning consequences for encoding as segmental similarity. It is also potentially consistent with the notion that segmental and metrical spell-out occur through separate but similar processes (e.g., Roelofs & Meyer, 1998).
However, an alternative explanation for the additive effect of metrical and segmental overlap is that the two representations are not independent, and a representation that has access to both segmental and metrical information guides phonological encoding. Although there are multiple ways to think about what such a representational system might look like (see the General Discussion), one possibility is that encoding depends on a representation that tracks acoustic-phonetic detail that includes metrical and segmental information. That is to say, the overlapping syllable in words with the same stress pattern (candy/candle) are more similar than overlapping syllables in words with a conflicting stress pattern (canteen/candle). Thus, it is possible that an acoustically detailed representation that includes both metrical and segmental information is used in phonological encoding and is driving the lengthening/competition effects we see in Experiment 1.
Thus, our goal in Experiment 2 was to understand whether segmental and metrical planning occur independently or whether they share representations at the level of phonological encoding. To adjudicate between these possible explanations, we introduced a condition with metrical overlap alone in Experiment 2. If the lengthening effect from Experiment 1 is driven by metrical similarity, rather than acoustic-phonetic similarity, we should see lengthening in a condition in which there is metrical overlap between prime and target but no segmental overlap.
Experiment 2
Method
Participants
Sixty native English speakers (age range: 18–32, M = 19.9 years, SD = 2.8, 47 female) participated in this study. Recruitment procedures were the same as Experiment 1, with the caveat that participants were not permitted to participate in both experiments.
Materials
A set of 160 color images was selected from the Snodgrass and Vanderwart (1980) data set (Rossion & Pourtois, 2001) and clip art, which included 80 critical items and 80 filler items. Critical items consisted of 16 targets and 64 primes. Prime–target pairs were arranged into four conditions:
- 1.
Metrical & segmental overlap: The ballet shrinks. The balloon flashes.
- 2.
Segmental overlap alone: The ballot shrinks. The balloon flashes.
- 3.
Metrical overlap alone: The guitar shrinks. The balloon flashes.
- 4.
No overlap: The trumpet shrinks. The balloon flashes.
We used a Latin square design, which yielded four counterbalanced lists of items, such that each participant was exposed to 16 critical prime–target pairs—four pairs for each of the four conditions. An equal number of trochees and iambs were used in each list. In addition, participants were exposed to 32 noncritical pairs, drawn from the filler items, for a total of 48 trials in the experiment.
Procedure
The design and instructions were the same as in Experiment 1. The primary difference between experiments was in the materials used. The predictions and data analysis strategy for Experiment 2 were preregistered through the Open Science Framework (Myers & Watson, 2018). There were two coders in this experiment, and interrater reliability was assessed as in Experiment 1, with an average ICC = 0.953, indicating excellent agreement between coders.
Results
As in Experiment 1, target word durations were manually coded in Praat, and trials were excluded if the prime or target were mispronounced or incorrectly named. A total of 59 out of 944 trials were removed. Scripts and the complete data set are available at https://osf.io/zk4qv/.
Maximal mixed-effects models were built in the same manner as in Experiment 1 to examine the fixed effects of segmental overlap, metrical overlap, and their interaction. An ANOVA was carried out to determine the best fitting model, which included random slopes and intercepts for the Segmental × Metrical interaction by item, as well as the segmental and metrical manipulations by participant.Footnote 1 Data were log transformed and centered. Significance was assumed by t values with absolute value above 1.96 in a two-tailed test (Baayen, 2008). There was a significant main effect of segmental overlap (β = 0.054, t = 5.038) and a significant interaction between segmental and metrical overlap (β = −0.038, t = −2.030). No main effect of metrical overlap was observed. Table 2 displays parameter estimates for the model. Additionally, iambs had longer durations than trochees on average (β = −0.162, t = −3.216), regardless of condition; there was no interaction between metrical type and overlap condition. Figure 3 displays average target durations by condition for this experiment.

Average duration (in seconds) of target words by condition in Experiment 2. Error bars represent standard error for each condition
Discussion
We replicated the findings from Experiment 1 by showing that segmental overlap alone leads to significant word lengthening, and metrical and segmental overlap lead to even longer word durations. However, speakers did not lengthen words with metrical overlap alone; this condition was no different than the control condition without overlap. Although we hesitate to draw conclusions from a null result, the data seem to contradict previous claims that meter and segments are planned as parallel independent processes (Roelofs & Meyer, 1998), at least during the stage of phonological encoding. Because meter by itself did not affect word duration in Experiment 2, it seems that stress is closely bound to segmental representations in phonological encoding.
General discussion
In two experiments, we tested the hypothesis that metrical and segmental spell-out occur as distinct but parallel processes (Roelofs & Meyer, 1998). We used word lengthening driven by segmental and metrical overlap as an index of whether these two types of linguistic structures are planned independently or together. Both Experiments 1 and 2 revealed lengthening when primes and targets had metrical and segmental overlap, but in Experiment 2 we found no evidence of lengthening from metrical overlap alone. This suggests that representations for metrical stress and segmental structure are linked, at least at the point of phonological encoding. Experiment 2 also revealed that segmental overlap in the absence of metrical overlap leads to lengthening, suggesting that segmental representations may play a more central role in planning than metrical representations.
Although the current data suggest that metrical and segmental structure are linked at phonological encoding, it is unclear what the precise mechanism for this might be. One possible explanation that we discussed above is that the fine-grained acoustic properties of sounds—rather than more abstract metrical and segmental representations—play a role in speech planning. It is possible that the production system maintains individuated representations for stressed and unstressed syllables (e.g. /ca-/ in candle and canteen) and uses these bound representations when ordering the sounds of the word. There is ample evidence suggesting that contextual information, including variability in productions, is maintained in long-term linguistic representations alongside segmental information (see Pierrehumbert, 2016, for review). This suggests that at the very least, speakers are capable of maintaining detailed acoustic forms of words and syllables, and this could potentially include whether a syllable is stressed or not.
There is also evidence that this type of detailed acoustic representation may play a role in the encoding process by serving as the basis of feedback to the production system during articulation. We know that auditory feedback plays a key role in tracking the state of the production system during articulation, and it has been argued that one function of auditory feedback is to provide information about deviations from the intended output (see Guenther, 2014; Hickok, 2014, for review). Data from Jacobs et al. (2015) suggest that phonological overlap interference effects may be driven in part by auditory feedback. They found that producing a prime aloud affects a subsequent target word’s duration, but producing the prime as inner speech or silent mouthing does not. Similarly, Buxó-Lugo et al. (2018) found that subjects lengthened a target word when they produced a phonologically overlapping prime, but lengthening also occurred when a different speaker produced the prime. No target lengthening occurred when the subject silently mouthed the prime. These findings suggest that the acoustic realization may be related to the interference effect, possibly by influencing representations that are used in feedback mechanisms for speech encoding. Taken together, these studies suggest that acoustic representations of words and syllables may play a role in sequencing the sounds of words, possibly through feedback.
Another possibility is that metrical and segmental representations are independent and abstract, but interact strongly in the course of phonological encoding. This is consistent with previous data from the literature suggesting that meter and segmental representation are separate at least at some points in speech planning. In speech errors, misplaced syllables tend to maintain their word position, and sentence level stress tends to maintain its sentence position, even when the word to which it was meant to be attached mistakenly appears elsewhere in the sentence (MacKay, 1970; Shattuck-Hufnagel, 1987). In addition, as we discussed above, Roelofs and Meyer (1998) present evidence from production tasks that suggests that meter and segments are planned independently. However, one puzzle for accounts that posit separate (but interactive) representations of metrical and segmental structure in phonological encoding is that segmental overlap between primes and targets alone seemed to lead to word lengthening, but the same is not true for metrical overlap. This would entail that metrical information may be available to segmental representations, but not vice versa. Future studies will need to explore how metrical and segmental information interact throughout the speech planning process, but the data here suggest that at the point of phonological encoding, these two types of information are not completely separate, or at least interact strongly.
In sum, these data suggest that segmental and metrical information are intimately connected in sequencing the sounds of words. We did not see evidence of independent metrical and segmental planning at the point of phonological encoding, suggesting that this level of speech planning may rely on representations for which segmental and metrical information are joined.
Data availability
The data and materials for all experiments are available at osf.io/zk4qv, and Experiment 2 was preregistered.
Notes
Two models converged that were one step down from the maximal model. These models did not differ significantly from one another. Both models yielded a significant segmental by metrical overlap interaction using the 1.96 criteria. However, the lmerTest function yielded an interaction that was marginal for one model but significant for the other. We report findings from the best fitting model based on AIC, BIC, and log-likelihood scores although the interaction in this model (t = −2.030) was marginally significant according to lmerTEST but significant using the 1.96 threshold.
References
Bates, D., Maechler, M., Bolker, B., & Walker, S. (2015). lme4: Linear mixed-effects models using Eigen and S4 (R Package Version 1.1-10) [Computer software]. Retrieved from https://cran.r-project.org
Baayen, R. H. (2008). Analyzing linguistic data: A practical introduction to statistics using R. Cambridge, UK: Cambridge University Press.
Berg, T. (1990). The differential sensitivity of consonant and vowels to stress. Language Sciences, 12, 65–84.
Boersma, P., & Weenink, D. (2017). Praat: Doing phonetics by computer (Version 6.0.37) [Computer software]. Retrieved from http://www.fon.hum.uva.nl/praat/
Buxó-Lugo, A., Jacobs, C. L., & Watson, D. G. (2018). The world is not enough to explain lengthening of phonological competitors. https://doi.org/10.31234/osf.io/6fnwa
Fraundorf, S. H., Diaz, M. I., Finley, J. R., Lewis, M. L., Tooley, K. M., Isaacs, A. M., … Brehm, L. (2014). CogToolbox for MATLAB [Computer software]. Retrieved from http://www.lrdc.pitt.edu/maplelab/cogtoolbox.html
Guenther, F. H. (2014). Auditory feedback control is involved at even sub-phonemic levels of speech production. Language, Cognition and Neuroscience, 29, 44–45.
Hickok, G. (2014). The architecture of speech production and the role of the phoneme in speech processing. Language, Cognition and Neuroscience, 29, 2–20.
Jacobs, C. L., Yiu, L. K., Watson, D. G., & Dell, G. S. (2015). Why are repeated words produced with reduced durations? Evidence from inner speech and homophone production. Journal of Memory and Language, 84, 37–48.
Keating, P., & Shattuck-Hufnagel, S. (2002). A prosodic view of word form encoding for speech production. UCLA Working Papers in Phonetics, 101, 112–156.
Kleiner, M., Brainard, D., & Pelli, D., (2007). What’s new in Psychtoolbox-3? Perception, 36(14), 1–16. (ECVP Abstract Supplement)
Levelt, W. J. M., Roelofs, A., & Meyer, A. S. (1999). A theory of lexical access in speech production. Behavioral and Brain Sciences, 22, 1–75.
MacKay, D. G. (1970). Spoonerisms: The structure of errors in the serial order of speech. Neuropsychologia, 8, 323–350.
Myers, B., & Watson, D. (2018). The role of meter in word lengthening. Retrieved from https://osf.io/zk4qv
O’Seaghdha, P. G., & Marin, J. W. (2000). Phonological competition and cooperation in form related priming: Sequential and nonsequential processes in word production. Journal of Experimental Psychology: Human Perception and Performance, 26, 57.
Pierrehumbert, J. B. (2016). Phonological representation: Beyond abstract versus episodic. Annual Review of Linguistics, 2(1), 33–52.
Pitt, M. A., & Samuel, A. G. (1990). The use of rhythm in attending to speech. Journal of Experimental Psychology: Human Perception and Performance, 16(3), 564–573.
Roelofs, A. (1997). The WEAVER model of word-form encoding in speech production. Cognition, 64, 249–284.
Roelofs, A., & Meyer, A. S. (1998). Metrical structure in planning the production of spoken words. Journal of Experimental Psychology: Learning Memory and Cognition, 24(4), 922–939.
Rossion, B., & Pourtois, G. (2001). Revisiting Snodgrass and Vanderwart’s object database: Color and texture improve object recognition. Journal of Vision, 1, 413a.
Schiller, N.O., Jansma, B., Peters, J., & Levelt, W. (2006). Monitoring metrical stress in polysyllabic words. Language and Cognitive Processes, 21(1–3), 112–140.
Sevald, C. A., & Dell, G. S. (1994). The sequential cuing effect in speech production. Cognition, 53, 91–127.
Shattuck-Hufnagel, S. (1986). The representation of phonological information during speech production planning: Evidence from vowel errors in spontaneous speech. Phonology Yearbook, 3, 117–149.
Shattuck-Hufnagel, S. (1987). The role of word-onset consonants in speech production planning: New evidence from speech error patterns. Hillsdale, NJ: Erlbaum.
Snodgrass, J. G., & Vanderwart, M. (1980). A standardized set of 260 pictures: Norms for name agreement, familiarity and visual complexity. Journal of Experimental Psychology: Human Learning & Memory, 6, 174–215.
Watson, D. G., Buxó-Lugo, A. S., & Simmons, D. C. (2015). The effect of phonological encoding on word duration: Selection takes time. In L. Frazier & E. Gibson (Eds.), Explicit and implicit prosody in sentence processing (Vol. 46, pp. 85–98). Cham, Switzerland: Springer International Publishing.
Yiu, L. K., & Watson, D. G. (2015). When overlap leads to competition: Effects of phonological encoding on word duration. Psychonomic Bulletin & Review, 22, 1701–1708.
Acknowledgements
The authors would like to thank Sarah Bibyk, Andrés Buxó-Lugo, Cassandra Jacobs, and Reyna Gordon for theoretical and methodological contributions to this work, and Michael West, Joseph Barnette, Jordan Spencer, and Yiran Chen for assistance with data collection and analysis. This material is based upon work supported by the National Science Foundation under Grant No. 1557097. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. This work was additionally supported by the Vanderbilt Trans-Institutional Programs, the Program for Music, Mind, and Society at Vanderbilt, and the Vanderbilt University Department of Psychology and Human Development.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Myers, B.R., Watson, D.G. Paying the meter: Effect of metrical similarity on word lengthening. Psychon Bull Rev 26, 1941–1947 (2019). https://doi.org/10.3758/s13423-019-01635-4
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-019-01635-4