
Abstract
The idea of a “predictive brain”—that is, the interpretation of internal and external information based on prior expectations—has been elaborated intensely over the past decade. Several domains in cognitive neuroscience have embraced this idea, including studies in perception, motor control, language, and affective, social, and clinical neuroscience. Despite the various studies that have used face stimuli to address questions related to predictive processing, there has been surprisingly little connection between this work and established cognitive models of face recognition. Here we suggest that the predictive framework can serve as an important complement of established cognitive face models. Conversely, the link to cognitive face models has the potential to shed light on issues that remain open in predictive frameworks.
Similar content being viewed by others


In very early neuroscience textbooks, vision seemed to be a hierarchical process that started at the lowest processing levels in the brain and propagated into higher areas that progressively computed more details and complexity. But we have also known for a long time that there are massive descending feedback connections in the brain, modulating processing at lower levels (Felleman & Van Essen, 1991). In general, a range of so-called contextual effects indicate that neurons’ responses are influenced by information outside their receptive fields that is difficult to explain by mere bottom-up processing. Srinivasan, Laughlin, and Dubs (1982) were the first to suggest a computational model based on a predictive-coding mechanism, to explain the center–surround antagonisms that interneurons of the retina exhibit. Predictive coding originally referred to an algorithm used in the context of image compression that enabled the removal of redundancy. This process exploits the fact that neighboring pixel intensities tend to be correlated; thus, the actual information can be sufficiently represented by deviations in these intensities. In this way, an image can be stored most efficiently. There are considerable statistical regularities in the visual images and scenes that biological organisms encounter, too (Torralba & Oliva, 2003). Rao and Ballard (1999) suggested a computational model that explains extracellular field effects in the visual cortex on the basis of similar mechanisms. They proposed that cortico-cortical feedback connections provide predictions about sensory input, and only the deviations, or prediction errors, are fed forward in the visual hierarchy to be processed further.
The scope of predictive coding quickly grew beyond the cellular level and promoted large-scale proposals that suggested that the minimization of surprise might be the brain’s major computational goal (Friston, 2005, 2010). Nowadays, the idea of a predictive brain is influential in many domains in cognitive science—for example, perception (Bar, 2007; Kok, Jehee, & de Lange, 2012; Summerfield & de Lange, 2014), action control (Makris & Urgesi, 2015), interoception (Seth & Critchley, 2013; Seth, Suzuki, & Critchley, 2011), language (DeLong, Urbach, & Kutas, 2005; Kuperberg & Jaeger, 2015; Weber, Lau, Stillerman, & Kuperberg, 2016), and affective and social neuroscience (Barrett & Bar, 2009; Koster-Hale & Saxe, 2013). Lastly, clinical disorders, such as anxiety, autism, and schizophrenia, have also been connected to deficits in anticipatory processes (Fletcher & Frith, 2009; Grupe & Nitschke, 2013; Pellicano & Burr, 2012; Van de Cruys et al., 2014).
Just like objects or any other sensory information, faces are perceived within fractions of a second (e.g., Liu, Harris, & Kanwisher, 2002), and this despite sharing the key problems prevalent in visual recognition—that is, variations in illumination, viewpoint, and other objects that may partly cover a face. Studies have suggested that robust representations are involved in the recognition of familiar faces, whereas the recognition of once-seen unfamiliar faces is relatively more dependent on single-image information (Burton, 2013; Burton, Jenkins, & Schweinberger, 2011; Eger, Schweinberger, Dolan, & Henson, 2005; Hancock, Bruce, & Burton, 2000). This efficiency and robustness raises the question of whether and how predictive processes shape face recognition to mitigate the computational burden.
Several studies have used faces as stimuli to address questions regarding the predictive-coding framework in the past. A major reason for this is that faces are known to be processed in certain well-defined and widely studied dedicated areas of the brain. Although functional imaging studies first established the fusiform face area (FFA; Kanwisher, McDermott, & Chun, 1997) as a face-sensitive brain region, the “core” system for face processing includes at least two further regions in the inferior occipital gyri (IOG) and the superior temporal sulcus (STS) areas (Gobbini & Haxby, 2007; Haxby, Hoffman, & Gobbini, 2000). These face-sensitive regions have been related to early visual analysis (IOG), the processing of changeable aspects of a face (STS), and the processing of more time-invariant aspects of face information. In parallel, electroencephalography (EEG) and magnetoencephalography (MEG) studies have identified a number of face-sensitive brain responses, including the N/M170, P/M200, N/M250r, and N/M400, which are thought to reflect different stages of face perception (e.g., Schweinberger & Burton, 2003).
Overall, this well-described network enables one to test the predictions of the complex predictive-coding models directly—using faces allows for probing the effects of prediction manipulations in exactly those regions or in well-known EEG/MEG components. Probably the most important evidence of connections between the face-processing network and predictive coding comes from neuroimaging studies of repetition suppression (RS). RS refers to a reduced neural response for repeated as compared to alternating stimuli and has been explained by neuronal fatigue or adaptation effects (Grill-Spector, Henson, & Martin, 2006). Summerfield et al. (2008) presented pairs of faces, which could show either two different individuals (alternation trial, AltT) or the same image twice (repetition trial, RepT). RepT and AltT were not presented randomly; rather, they were grouped into short blocks with either high (repetition block, RepB) or low (alternation block, AltB) probabilities of stimulus repetition. The authors found that RS in the FFA was enhanced in blocks in which repetitions were frequent. They interpreted this probabilistic modulation as a result of top-down influence on RS. In other words, it was suggested that participants predicted the frequently occurring repetitions and that this enhanced RS in those blocks. Later, such modulations of RS by expecting the repetition have been found in almost every member of the core network—namely in the occipital face area (OFA) and lateral occipital complex (LO) (for a summary, see Grotheer & Kovács, 2016). Interestingly, this effect seems to be specific for faces and familiar characters, and it does not occur for other stimuli (Grotheer & Kovács, 2014; but see Utzerath, John-Saaltink, Buitelaar, & Lange, 2017, for a different conclusion).
This functional magnetic resonance imaging (fMRI) RS modulation seems not to be attenuated for inverted faces, suggesting that the prediction effect operates at an early level—that is, before configural or holistic processing of facial features (Grotheer, Hermann, Vidnyánszky, & Kovács, 2014). In an EEG study, however, Schweinberger, Huddy, and Burton (2004) found that the N250r repetition effect was strongly attenuated for inverted faces, possibly supporting the idea that prediction effects (1) should be considered at multiple levels of processing and (2) should be considered not just with fMRI, but also with EEG. De Gardelle, Waczuzk, Egner, and Summerfield (2013) used a repetition suppression paradigm and examined the neural correlates of repetition enhancement (RE) and suppression (RS) in face-sensitive regions with multivoxel pattern analysis, and they found that both coexist in the same region but show different latencies and connectivities with lower- and higher-level surrounding areas. Egner, Monti, and Summerfield (2010) reported that the FFA is activated when faces are highly expected, due to the presentation of a prior cue, regardless of whether the actual stimulus was a face or a house. They fitted the fMRI data with either a (traditional) feature detection model or the predictive-coding model, and found that the latter had a better fit. Bell, Summerfield, Morin, Malecek, and Ungerleider (2016) exposed a macaque monkey to either fruits or face stimuli and recorded activity from single neurons in the inferior temporal cortex. They found reduced signals for expected face stimuli, a greater accuracy in decoding the stimulus from multivariate population signals, and the encoding of probabilistic information about the face occurrence in the inferior temporal cortex. Brodski, Paasch, Helbling, and Wibral (2015) manipulated expectations of faces and provided further evidence that bottom-up propagation of prediction error signals is reflected in gamma-band activity. Apps and Tsakiris (2013) directly addressed whether face recognition can be reconciled with predictive coding. They aimed to understand why familiarity for faces is increased regardless of changes in viewpoint. They provided evidence for the argument that familiarity is constantly updated and takes into account contextual information that renders familiarity more or less likely (with context being defined here as a specific situation in which familiar faces tend to occur). In their study, the behavioral responses of participants were in line with a computational model that is built upon predictive-coding principles.
Despite these enormous efforts that were designed to put the predictive-coding model under empirical scrutiny, the above-mentioned studies (with the exception of Apps & Tsakiris, 2013) made little reference to established cognitive models of face perception. Instead, they used face stimuli as a means to address questions in the context of predictive processing. In other words, theoretical questions with regard to cognitive face models have remained untouched. Conversely, with respect to face recognition, early studies investigating the cognitive and neuronal mechanisms of priming (both repetition and semantic priming) have provided crucial information on the ways that faces could be represented and processed (e.g., Bruce & Valentine, 1985, 1986; Schweinberger, Pfütze, & Sommer, 1995). However, reference to the role of expectations during face processing in studies of priming remained indirect only.
We argue here that wrapping up cognitive face models in a predictive framework will not only address open issues in these models, but also shed light on questions related to the predictive-processing framework. In the next section, we will briefly review dominant cognitive models of face perception.
Cognitive models of face perception
Cognitive models of face perception distinguish several levels of sensory face processing. During low-level visual analysis (image encoding), a detailed analysis is conducted of the visual stimulus and its elements, before this basic information (e.g., about edges, coloration, and shape) is integrated into a uniform holistic representation of a face. So-called first-order configural information (i.e., the fact that a face contains two eyes above a nose, above a mouth) may be crucial for the categorization of a stimulus as a face. So-called second-order configural information (in terms of the relative metric distances between features) can then be encoded (Maurer, Le Grand, & Mondloch, 2002). Although spatial configural information likely is important for learning new faces, recent evidence suggests that the representations that mediate the recognition of familiar faces depend to a great extent on the texture/reflectance information in the image, rather than on spatial configuration per se (e.g., Burton, Schweinberger, Jenkins, & Kaufmann, 2015; Itz, Schweinberger, Schulz, & Kaufmann, 2014). Once an encoded representation has been matched with a more permanently stored representation of a familiar face, the face may be recognized, and semantic or episodic information (e.g., occupation, most recent encounter) about the depicted person may subsequently become available. The existence of temporal or permanent difficulties in retrieving personal names (e.g., Diaz, Lindin, Galdo-Alvarez, Facal, & Juncos-Rabadan, 2007) is one of several arguments for separating name retrieval from general semantic processes in cognitive models of familiar face identification.
Even though face recognition and identification are the results of successful processing at multiple levels (see also Fig. 1), the level of representation of faces has received particularly strong scientific attention. One important framework for modeling the representational level of face perception is in terms of a face space (Valentine, 1991, 2001; Valentine, Lewis, & Hills, 2016), so that a face is conceived as being a point within a multidimensional face space (MDFS) made up of the entire set of faces with which one has familiarity. Each dimension of the space represents a visible characteristic upon which faces can be differentiated. Two versions of face space have been widely debated. The first version suggests that faces are processed in terms of their deviation from the average face, or “norm” (Leopold, Bondar, & Giese, 2006; Rhodes, Brennan, & Carey, 1987; Rhodes & Jeffery, 2006). The competing proposal—the exemplar-based model—suggests that each face is encoded as a specific point within the space and is differentiated from the others as a whole, without specific reference to the center of the space (Nosofsky, 1988, 1991; Valentine, 1991). Although the MDFS model has its merits, the metaphor of a face being represented as a point in MDFS has its limitations and could potentially be misleading with respect to the representation of familiar faces. This becomes evident when considering the evidence for qualitative differences in the mental representations of familiar and unfamiliar faces (Megreya & Burton, 2006). Whereas the visual characteristics of the image are crucial for processing unfamiliar faces (Hancock et al., 2000), familiar faces are characterized by robust representations that are much less image-dependent. In that sense, familiar face representations may be better considered as covering an area, rather than a point, in MDFS—where the area covers all “possible” images of a specific familiar face (e.g., Burton et al., 2011; Burton et al., 2015).

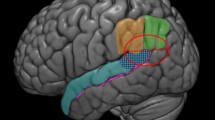
Simplified cognitive model of face perception, which depicts an approximate time course of the subprocesses involved in face perception and recognition and indicates some of the event-related potential components that are sensitive to different types of face repetition effects. The subprocesses are sensitive to predictive-coding mechanisms, as indicated by the bidirectional arrows with subsequent levels. From “Repetition Effects in Human ERPs to Faces,” by S. R. Schweinberger and M. F. Neumann, 2016, Cortex, 80, pp. 141–153. Copyright 2016 by Elsevier. Adapted with permission, license number 4262480623312
Face space and robust-representation models are appealing because they provide frameworks to consider the many different ways in which faces differ from each other. Originally proposed by Valentine (1991) to account for findings such as facial distinctiveness and the other-race effect (Hayward, Crookes, & Rhodes, 2013), most recent investigations have used perceptual adaptation to examine the ways that face perception is distorted following prolonged exposure to a face. In face adaptation (e.g., Leopold, O’Toole, Vetter, & Blanz, 2001; Rhodes & Leopold, 2011), exposure to a face with certain characteristics—for example, femininity—makes a subsequent face appear to take on the opposite characteristics (in this case, to look more masculine). Adaptation effects seem naturally to derive from a face space model, because changes in perceived appearance can be conceptualized as temporary changes in position within the space. Face aftereffects are generally interpreted as being more favorable to norm-based than to exemplar accounts, since adaptation effects typically show sensitivity to the center of the space. For example, Rhodes and Jeffery (2006) created adaptor–test pairs that in some cases formed dimensions running through a central face norm and in other cases formed dimensions that did not run through the centroid of face space. The authors argued that a norm-based coding account would predict greater adaptation when the norm was involved, since any changes in perceived appearance should be maximally driven toward or away from the norm. They further argued that an exemplar-based account would propose relatively similar levels of adaptation in the two conditions, since a function can be placed between any two points in face space, and there is no a priori reason to assume that one pair would produce stronger aftereffects than another. Rhodes and Jeffery found support for the norm-based account, in that stronger adaptation effects were observed when adaptation went through the center of the space than when it went on a different trajectory. Recently, however, Ross, Deroche, and Palmeri (2014) have demonstrated that such arguments may be less compelling than was previously claimed. They modeled the results of face adaptation experiments using three different architectures: (1) exemplar-based (e.g., Valentine, 1991, 2001), (2) norm-based (using a centroid norm; e.g., Leopold et al., 2001), and (3) opponent-coding-based (a variant of the norm-based approach; e.g., Rhodes & Jeffery, 2006). According to previous conceptions, the norm-based and opponent-coding approaches, but not exemplar-based models, could account for face adaptation effects such as those demonstrated by Rhodes and Jeffery. However, Ross et al. demonstrated that an exemplar-based model could also account for such results, whereas the norm-based model using a centroid of the space as the norm was unable to do so. Overall, the controversy between exemplar- and norm-based views is likely to continue. Although norm-based opponent coding may not be a good model to explain adaptation for selected facial signals such as eye gaze (Calder, Jenkins, Cassel, & Clifford, 2008), the norm-based account appears to remain dominant as an explanation of facial adaptation effects for a variety of important social signals, including identity, gender, and expression (Rhodes et al., 2017).
The (missing) link between predictive frameworks and cognitive face models
We have outlined that cognitive models of face perception emphasize that the successful processing of a face (i.e., the recognition of a given person or the correct perception of an emotion on a given face) is mediated by multiple subprocesses within a network of occipito-temporal and frontal cortical areas. In brief, these models typically include the following processing steps, each allocated to certain cortical areas of the network: low-level, image-based pictorial processing of visual features; detection of a face in a scene; perceptual encoding of a facial representation; comparison with the representations of familiar faces stored in memory; and retrieval of semantic information and naming (in the case of familiar faces) (Bruce & Young, 1986; Gobbini & Haxby, 2007; Haxby et al., 2000; Schweinberger & Burton, 2003). In principle, predictive coding may occur at all these levels of processing (e.g., Schweinberger & Neumann, 2016; see Fig. 1).
In current conceptualizations of face perception, processing starts with the incoming sensory information. This information is carried up to the cortex via thalamo-cortical sensory pathways and enters the cortex via V1. After early, local, feature-based processing in early cortical areas such as V1 and V2, the face stimulus—like every type of shape-related information—enters the ventral visual pathways. Current models of face perception (e.g., Haxby et al., 2000) split the processing into two basic steps. The first step performs a relatively low-level visual feature analysis of the faces and is connected to the so-called “core network” of face perception. The core network is composed of occipital (OFA, LO), posterior (FFA), and superior temporal sulcal (STS) areas. A second, final step complements this early processing and is connected to an extended network of areas. Areas in the parietal and auditory cortices, the amygdala, the insula, over the anterior tip of the temporal lobe, and over the frontal cortex connect the currently observed faces to attention, emotion, identity-specific, and speech-related information, and to various social factors. At this stage of processing, the stimulus is compared to an existing template (and mnemonic information). In other words, the processing of faces proceeds from easy and “sketchy” toward complicated, in a hierarchical system.
Although the idea of a cortical network behind face perception is very attractive, and many studies support its existence (Fairhall & Ishai, 2007), several researchers doubt that such a model is able to explain every aspect of face perception. These considerations are based on two different caveats. First, many areas that were originally thought to be involved only in low-level processing have in fact been shown to be necessary for higher-level tasks such as person recognition (Ambrus, Dotzer, Schweinberger, & Kovács, 2017; Davies-Thompson & Andrews, 2012; Gschwind, Pourtois, Schwartz, Van De Ville, & Vuilleumier, 2012; Rossion, 2008, 2014). Second, many areas of the extended part of the “face-network” are not face-specific but are involved in general cognitive mechanisms such as attention, emotion processing, or executive control. How can these aspects be reconciled with current cognitive face models? Taking into account the role of expectations in face perception, cortical feedback originating from higher-level cortical areas descending to lower levels may solve this issue. Indeed, this perspective is currently attracting more attention in face recognition. For example, it is argued that these feedback connections may be important in integrating the processes that precede the incoming face stimulus—that is, expectations that prepare the system for the interpretation of specific information. This is an operation step that has been examined thoroughly in the context of predictive processing.
What happens in the system when the face is not yet presented, but expected? Several studies have already addressed this question by manipulating prediction with a cue—for example, an arrow or a preceding symbol that participants learn to associate with an upcoming stimulus. Several studies have shown that this results in a baseline shift in areas that process the face stimulus (Esterman & Yantis, 2010; Puri, Wojciulik, & Ranganath, 2009). This anticipatory activity in the FFA was even sensitive to the likelihood of the upcoming face (Trapp, Lepsien, Kotz & Bar, 2016).
However, to the best of our knowledge, studies demonstrating evidence for predictive effects in face perception have not applied functionally predictive coding steps into currently available face-processing theories. The only exception has been the study of Apps and Tsakiris (2013)—these authors directly looked at the neural bases of face perception, familiarity, and prediction. They showed that FFA activity signals how much information can be extracted about a face (and thus how much more familiar it can become) and that the posterior STS signals the current level of familiarity of faces in the environment (i.e., a key prior), which would influence how face space might be processed. This was one of the first studies to suggest how face processing and predictive models might interact. It should also be noted that self-perception has been linked with predictive-processing accounts (Apps & Tsakiris, 2014).
Not only can the prediction perspective address current discussions in face perception with regard to the brain areas involved, it may also help us understand difficulties with face perception in specific clinical disorders—for example, in autism spectrum disorder (for a review, see Weigelt, Koldewyn, & Kanwisher, 2012). From the predictive perspective, it may be that although comparison with existing face templates works well, deficits occur during the prediction process, thereby slowing the comparison process or adding more noise to it. This aligns with a recent suggestion that autistic individuals might generally perceive the world with fewer expectations (Pellicano & Burr, 2012; Van de Cruys et al., 2014). A recent study revealed that children with autism spectrum disorder showed higher activation of (dorsolateral) frontal regions during successful face recognition, which was accompanied by increased response times (Herrington, Riley, Grupe, & Schultz, 2015). The authors suggested that this activation might act as a compensatory mechanism. From the predictive perspective, it could be interpreted as more effort being required in order to activate predictive information elsewhere in the cortex.
How cognitive face models can inform predictive frameworks
The rise of predictive coding in cognitive neuroscience has stimulated a plethora of studies, and much work has been dedicated to identifying the correlates of prediction and prediction errors, as well as the neural networks that support the process (e.g., Alink, Schwiedrzik, Kohler, Singer, & Muckli, 2010; Bendixen, Schwartze, & Kotz, 2015; de Gardelle et al., 2013; Kimura, Kondo, Ohira, & Schröger, 2012; Kok, Failing, & de Lange, 2014; Todorovic, van Ede, Maris, & de Lange, 2011). However, as of yet, predictive frameworks have been relatively mute on the representational format of the “prediction.” For example, do we expect a specific chair, or rather an abstract category? What would such an abstract category look like? It is here that we see a role of (neuro)cognitive face models to inform predictive frameworks: As we have outlined in this article, face models are detailed about the representational format of the template (which may be a norm or an exemplar), and may thereby generate ideas about the format of the prior in other domains of perception. In addition, it remains to be specified how exactly the comparison between prior and incoming sensory information is accomplished. The lack of psychological process models within abstract mathematical frameworks such as Bayesian models has been discussed extensively elsewhere (Jones & Love, 2011). Notably, through decades of research, the comparison process between face templates and incoming sensory information has been specified, and this knowledge may guide the way we conceptualize and investigate questions in the context of the “predictive brain.”
References
Alink, A., Schwiedrzik, C. M., Kohler, A., Singer, W., & Muckli, L. (2010). Stimulus predictability reduces responses in primary visual cortex. Journal of Neuroscience, 30, 2960–2966. https://doi.org/10.1523/JNEUROSCI.3730-10.2010
Ambrus, G. G., Dotzer, M., Schweinberger, S. R., & Kovács, G. (2017). The occipital face area is causally involved in the formation of identity-specific face representations. Brain Structure and Function, 222, 4271–4282. https://doi.org/10.1007/s00429-017-1467-2.
Apps, M. A. J., & Tsakiris, M. (2013). Predictive codes of familiarity and context during the perceptual learning of facial identities. Nature Communications, 4, 2698.
Apps, M. A. J., & Tsakiris, M. (2014). The free-energy self: A predictive coding account of self-recognition. Neuroscience & Biobehavioral Reviews, 41, 85–97.
Bar, M. (2007). The proactive brain: Using analogies and associations to generate predictions. Trends in Cognitive Sciences, 11, 280–289.
Barrett, L. F., & Bar, M. (2009). See it with feeling: Affective predictions during object perception. Philosophical Transactions of the Royal Society B, 364, 1325–1334.
Bell, A. H., Summerfield, C., Morin, E. L., Malecek, N. J., & Ungerleider, L. G. (2016). Encoding of stimulus probability in macaque inferior temporal cortex. Current Biology, 26, 2280–2290.
Bendixen, A., Schwartze, M., & Kotz, S. A. (2015). Temporal dynamics of contingency extraction from tonal and verbal auditory sequences. Brain and Language, 148, 64–73.
Brodski, A., Paasch, G. F., Helbling, S., & Wibral, M. (2015). The faces of predictive coding. Journal of Neuroscience, 35, 8997–9006. https://doi.org/10.1523/JNEUROSCI.1529-14.2015
Bruce, V., & Valentine, T. (1985). Identity priming in the recognition of familiar faces. British Journal of Psychology, 76, 373–383.
Bruce, V., & Valentine, T. (1986). Semantic priming of familiar faces. Quarterly Journal of Experimental Psychology, 38A, 125–150.
Bruce, V., & Young, A. (1986). Understanding face recognition. British Journal of Psychology, 77, 305–327.
Burton, A. M. (2013). Why has research in face recognition progressed so slowly? The importance of variability. Quarterly Journal of Experimental Psychology, 66, 1467–1485.
Burton, A. M., Bruce, V., & Johnston, R. A. (1990). Understanding face recognition with an interactive activation model. British Journal of Psychology, 81, 361–380.
Burton, A. M., Jenkins, R., & Schweinberger, S. R. (2011). Mental representations of familiar faces. British Journal of Psychology, 102, 943–958.
Burton, A. M., Schweinberger, S. R., Jenkins, R., & Kaufmann, J. M. (2015). Arguments against a configural processing account of familiar face recognition. Perspectives on Psychological Science, 10, 482–496.
Calder, A. J., Jenkins, R., Cassel, A., & Clifford, C. W. G. (2008). Visual representation of eye gaze is coded by a nonopponent multichannel system. Journal of Experimental Psychology: General, 137, 244–261.
Davies-Thompson, J., & Andrews, T. J. (2012). Intra- and inter-hemispheric connectivity between face-selective regions in the human brain. Journal of Neurophysiology, 108, 3087–3097.
de Gardelle, V., Waczuzk, M., Egner, T., & Summerfield, C. (2013). Concurrent representations of prediction and prediction error signals in visual cortex. Cerebral Cortex, 23, 2235–2244.
DeLong, K. A., Urbach, T. P., & Kutas, M. (2005). Probabilistic word pre-activation during language comprehension inferred from electrical brain activity. Nature Neuroscience, 8, 1117–1121.
Diaz, F., Lindin, M., Galdo-Alvarez, S., Facal, D., & Juncos-Rabadan, O. (2007). An event-related potentials study of face identification and naming: The tip-of-the-tongue state. Psychophysiology, 44, 50–68.
Eger, E., Schweinberger, S. R., Dolan, R. J., & Henson, R. N. (2005). Familiarity enhances invariance of face representations in human ventral visual cortex: fMRI evidence. NeuroImage, 26, 1128–1139.
Egner, T., Monti, J. M., & Summerfield, C. (2010). Expectation and surprise determine neural population responses in the ventral visual stream. Journal of Neuroscience, 8, 16601–16608.
Esterman, M., & Yantis, S. (2010). Perceptual expectation evokes category-selective cortical activity. Cerebral Cortex, 20, 1245–1253. https://doi.org/10.1093/cercor/bhp188
Fairhall, S. L., & Ishai, A. (2007). Effective connectivity within the distributed cortical network for face perception. Cerebral Cortex, 17, 2400–2406.
Felleman, D. J., & Van Essen, D. C. (1991). Distributed hierarchical processing in the primate cerebral cortex. Cerebral Cortex, 1, 1–47.
Fletcher, P. C., & Frith, C.-D. (2009). Perceiving is believing: A Bayesian approach to explaining the positive symptoms of schiophrenia. Nature Reviews Neuroscience, 10, 48–58.
Friston, K. (2005). A theory of cortical responses. Philosophical Transactions of the Royal Society B, 360, 815–836.
Friston, K. (2010). The free-energy principle: A unified brain theory? Nature Reviews Neuroscience, 11, 127–138.
Gobbini, M. I., & Haxby, J. V. (2007). Neural systems for recognition of familiar faces. Neuropsychologia, 45, 32–41.
Grill-Spector, K., Henson, R., & Martin, A. (2006). Repetition and the brain: Neural models of stimulus-specific effects. Trends in Cognitive Sciences, 10, 14–23. https://doi.org/10.1016/j.tics.2005.11.006
Grotheer, M., Hermann, P., Vidnyánszky, Z., & Kovács, G. (2014). Repetition probability effects for inverted faces. NeuroImage, 102, 416–423.
Grotheer M., & Kovács G. (2014). Repetition probability effects depend on prior experiences. Journal of Neuroscience, 34, 6640–6646.
Grotheer, M., & Kovács, G. (2016). Can predictive coding explain repetition suppression? Cortex, 80, 113–124.
Grupe, D. W., & Nitschke, J. B. (2013). Uncertainty and anticipation in anxiety: An integrated neurobiological and psychological perspective. Nature Reviews Neuroscience, 14, 488–501.
Gschwind, M., Pourtois, G., Schwartz, S., Van De Ville, D., & Vuilleumier, P. (2012). White-matter connectivity between face-responsive regions in the human brain. Cerebral Cortex, 22, 1564–1576. https://doi.org/10.1093/cercor/bhr226
Hancock, P. J. B., Bruce, V., & Burton, A. M. (2000). Recognition of unfamiliar faces. Trends in Cognitive Sciences, 4, 330–337.
Haxby, J. V., Hoffman, E. A., & Gobbini, M. I. (2000). The distributed human neural system for face perception. Trends in Cognitive Sciences, 4, 223–233.
Hayward, W. G., Crookes, K., & Rhodes, G. (2013). The other-race effect: Holistic coding differences and beyond. Visual Cognition, 21, 1224–1247.
Herrington, J. D., Riley, M. E., Grupe, D. W., & Schultz, R. T. (2015). Successful face recognition is associated with increased prefrontal cortex activation in autism spectrum disorder. Journal of Autism and Developmental Disorders, 45, 902–910.
Itz, M. L., Schweinberger, S. R., Schulz, C., & Kaufmann, J. M. (2014). Neural correlates of facilitations in face learning by selective caricaturing of facial shape or reflectance. NeuroImage, 102, 736–747. https://doi.org/10.1016/j.neuroimage.2014.08.042
Jones, M., & Love, B. C. (2011). Bayesian fundamentalism or enlightenment? On the explanatory status and theoretical contributions of Bayesian models of cognition. Behavioral and Brain Sciences, 34, 169–188.
Kanwisher, N., McDermott, J., & Chun, M. M. (1997). The fusiform face area: A module in human extrastriate cortex specialized for the perception of faces. Journal of Neuroscience, 17, 4302–4311.
Kimura, M., Kondo, H., Ohira, H., & Schröger, E. (2012). Unintentional temporal context-based prediction of emotional faces: An electrophysiological study. Cerebral Cortex, 22, 1774–1785.
Kok, P., Failing, M., & de Lange, F. P. (2014). Prior expectations evoke stimulus templates in the primary visual cortex. Journal of Cognitive Neuroscience, 26, 1546–1554.
Kok, P., Jehee, J. F., & de Lange, F. P. (2012). Less is more: Expectation sharpens representations in the primary visual cortex. Neuron, 75, 265–270. https://doi.org/10.1016/j.neuron.2012.04.034
Koster-Hale, J., & Saxe, R. (2013). Theory of mind: A neural prediction problem. Neuron, 79, 836–848.
Kuperberg, G. R., & Jaeger, T. F. (2015). What do we mean by prediction in language comprehension? Language, Cognition, and Neuroscience, 31, 32–59.
Leopold, D. A., Bondar, I. V., & Giese, M. A. (2006). Norm-based face encoding by single neurons in the monkey inferotemporal cortex. Nature, 442, 572–575.
Leopold, D. A., O’Toole, A. J., Vetter, T., & Blanz, V. (2001). Prototype-referenced shape encoding revealed by high-level aftereffects. Nature Neuroscience, 4, 89–94.
Liu, J., Harris, A., & Kanwisher, N. (2002). Stages of processing in face perception: An MEG study. Nature Neuroscience, 5, 910–916.
Makris, S., & Urgesi, C. (2015). Neural underpinnings of superior action prediction abilities in soccer players. Social Cognitive and Affective Neuroscience, 10, 342–351.
Maurer, D., Le Grand, R., & Mondloch, C. J. (2002). The many faces of configural processing. Trends in Cognitive Sciences, 6, 255–260.
Megreya, A. M., & Burton, A. M. (2006). Unfamiliar faces are not faces: Evidence from a matching task. Memory & Cognition, 34, 865–876.
Nosofsky, R. M. (1988). Exemplar-based accounts of relations between classification, recognition, and typicality. Journal of Experimental Psychology: Learning, Memory, and Cognition, 14, 700–708.
Nosofsky, R. M. (1991). Tests of an exemplar model for relating perceptual classification and recognition memory. Journal of Experimental Psychology: Human Perception and Performance, 17, 3–27.
Pellicano, E., & Burr, D. (2012). When the world becomes ‘too real’: A Bayesian explanation of autistic perception. Trends in Cognitive Sciences, 16, 504–510.
Puri, A. M., Wojciulik, E., & Ranganath, C. (2009). Category expectation modulates baseline and stimulus-evoked activity in human inferotemporal cortex. Brain Research, 1301, 89–99.
Rao, R. P., & Ballard, D. H. (1999). Predictive coding in the visual cortex: A functional interpretation of some extra-classical receptive-field effects. Nature Neuroscience, 2, 79–87.
Rhodes, G., Brennan, S., & Carey, S. (1987). Identification and ratings of caricatures: Implications for mental representations of faces. Cognitive Psychology, 19, 473–497.
Rhodes, G., & Jeffery, L. (2006). Adaptive norm-based coding of facial identity. Vision Research, 46, 2977–2987. https://doi.org/10.1016/j.visres.2006.03.002
Rhodes, G., & Leopold, D. A. (2011). Adaptive norm-based coding of face identity. In A. W. Calder, G. Rhodes, M. H. Johnston, & J. V. Haxby (Eds.), Oxford handbook of face perception (pp. 263–286). Oxford, UK: Oxford University Press. https://doi.org/10.1093/oxfordhb/9780199559053.013.0014
Rhodes, G., Pond, S., Jeffery, L., Benton, C. P., Skinner, A. L., & Burton, N. (2017). Aftereffects support opponent coding of expression. Journal of Experimental Psychology: Human Perception and Performance, 43, 619–628.
Ross, D. A., Deroche, M., & Palmeri, T. J. (2014). Not just the norm: Exemplar-based models also predict face aftereffects. Psychonomic Bulletin & Review, 21, 47–70.
Rossion, B. (2008). Constraining the cortical face network by neuroimaging studies of acquired prosopagnosia. NeuroImage 40, 423–426.
Rossion, B. (2014). Understanding face perception by means of prosopagnosia and neuroimaging. Frontiers in Bioscience (Elite ed.), 6, 258–307.
Schweinberger, S. R., & Burton, A. M. (2003). Covert recognition and the neural system for face processing. Cortex, 39, 9–30.
Schweinberger, S. R., & Neumann, M. F. (2016). Repetition effects in human ERPs to faces. Cortex, 80, 141–153.
Schweinberger, S. R., Pfütze, E. M., & Sommer, W. (1995). Repetition priming and associative priming of face recognition: Evidence from event-related potentials. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 722–736.
Schweinberger, S. R., Huddy V, & Burton, A. M. (2004). N250r – A face-selective brain response to stimulus repetitions. NeuroReport, 15, 1501–1505.
Seth, A. K., & Critchley, H. D. (2013). Extending predictive processing to the body: Emotion as interoceptive inference. Behavioural Brain Science, 36, 227–228.
Seth, A. K., Suzuki, K., & Critchley, H. D. (2011). An interoceptive predictive coding model of conscious presence. Frontiers in Psychology, 2, 395.
Srinivasan, M. V., Laughlin, S. B., & Dubs, A. (1982). Predictive coding: A fresh view of inhibition in the retina. Proceedings of the Royal Society B, 216, 427–459.
Summerfield, C., & de Lange, F. P. (2014). Expectation in perceptual decision-making: Neural and computational mechanisms. Nature Reviews Neuroscience, 15, 745–756.
Summerfield, C., Trittschuh, E. H., Monti, J. M., Mesulam, M. M., Egner, T. (2008). Neural repetition suppression reflects fulfilled perceptual expectations. Nature Neuroscience, 11, 1004–1006.
Todorovic, A., van Ede, F., Maris, E., & de Lange, F. P. (2011). Prior expectation mediates neural adaptation to repeated sounds in the auditory cortex: An MEG study. Journal of Neuroscience, 31, 9118–9123.
Torralba, A., & Oliva, A. (2003). Statistics of natural image categories. Network, 14, 391–412.
Trapp, S., Lepsien, J., Kotz, S., & Bar, M. (2016). Prior probability modulates baseline activity in category-specific areas. Cognitive, Affective, & Behavioral Neuroscience, 16, 135–144.
Utzerath, C., St. John-Saaltink, E., Buitelaar, J., & de Lange, F. P. (2017). Repetition suppression to objects is modulated by stimulus-specific expectations. Science Reports, 7, 8781:1–8. https://doi.org/10.1038/s41598-017-09374-z
Valentine, T. (1991). A unified account of the effects of distinctiveness, inversion, and race in face recognition. Quarterly Journal of Experimental Psychology, 43A, 161–204.
Valentine, T. (2001). Face-space models of face recognition. In M. J. Wenger & J. T. Townsend (Eds.), Computational, geometric, and process perspectives on facial cognition: Contexts and challenges (pp. 83–113). Mahwah, NJ: Erlbaum.
Valentine, T., Lewis, M. B., & Hills, P. J. (2016). Face-space: A unifying concept in face recognition research. Quarterly Journal of Experimental Psychology, 69, 1996–2019.
Van de Cruys, S., Evers, K., Van der Hallen, R., Van Eylen, L., Boets, B., de-Wit, L., & Wagemans, J. (2014). Precise minds in uncertain worlds: Predictive coding in autism. Psychological Review, 121, 649–675.
Weber, K., Lau, E. F., Stillerman, B., & Kuperberg, G. R. (2016). The yin and the yang of prediction: An fMRI study of semantic predictive processing. PLoS ONE, 11.
Weigelt, S., Koldewyn, K., & Kanwisher, N. (2012). Face identity recognition in autism spectrum disorders: A review of behavioral studies. Neuroscience & Biobehavioral Reviews, 36, 1060–1084.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Trapp, S., Schweinberger, S.R., Hayward, W.G. et al. Integrating predictive frameworks and cognitive models of face perception. Psychon Bull Rev 25, 2016–2023 (2018). https://doi.org/10.3758/s13423-018-1433-x
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-018-1433-x