
Abstract
The presence of abstract letter identity representations in the Roman alphabet has been well documented. These representations are invariant to letter case (upper vs. lower) and visual appearance. For example, “a” and “A” are represented by the same abstract identity. Recent research has begun to consider whether the processing of non-Roman orthographies also involves abstract orthographic representations. In the present study, we sought evidence for abstract identities in Japanese kana, which consist of two scripts, hiragana and katakana. Abstract identities would be invariant to the script used as well as to the degree of visual similarity. We adapted the cross-case masked-priming letter match task used in previous research on Roman letters, by presenting cross-script kana pairs and testing adult beginning -to- intermediate Japanese second-language (L2) learners (first-language English readers). We found robust cross-script priming effects, which were equal in magnitude for visually similar (e.g., り/リ) and dissimilar (e.g., あ/ア) kana pairs. This pattern was found despite participants’ imperfect explicit knowledge of the kana names, particularly for katakana. We also replicated prior findings from Roman abstract letter identities in the same participants. Ours is the first study reporting abstract kana identity priming (in adult L2 learners). Furthermore, these representations were acquired relatively early in our adult L2 learners.
Similar content being viewed by others


Introduction
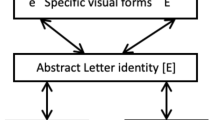
The Roman alphabet contains upper- and lowercase forms (allographs) of each letter identity many of which are nonidentical and visually dissimilar (e.g. g/G, a/A). Researchers have proposed that the mature letter identification system copes with this allographic variability by computing abstract letter identities that are invariant to the physical appearance and case form of a letter. This claim has been supported by data from many sources including individuals with reading difficulties (e.g., Coltheart, 1981; Rynard & Besner, 1987) skilled adult readers (Besner Coltheart & Davelaar, 1984; Bigsby, 1988; Bowers Vigliocco & Haan, 1998; Kinoshita & Kaplan, 2008) and neural measurements (e.g., Dehaene et al., 2004; Petit Midgley Holcomb & Grainger, 2006; Polk & Farah, 2002; Rothlein & Rapp, 2014).
A key source of evidence for abstract letter identities in skilled adult readers is the cross-case match task (also referred to as the nominal identity match task; e.g., Bigsby, 1988, 1990; Reuter-Lorenz & Brunn, 1990). This task involves (simultaneous or sequential) presentation of letter pairs (e.g., “a” and “A”). Participants’ task is to decide whether the letters have the same or different (nominal) identities, irrespective of letter case. It is important to point out that although early studies (e.g., Posner & Mitchell, 1967) suggested that responding Same to nominally identical letters such as “A” and “a” is based on a phonological “name code,” subsequent studies have conclusively argued against this claim. Specifically, multiple studies have shown that responding Different in a nominal identity match is unaffected by the phonological similarity of letter names (e.g., Bigsby, 1988; Boles & Eveland, 1983; Carrasco, Kinchla, & Figueroa, 1988), and there is now general consensus that cross-case identity matches are based a “non-phonological, case-independent, font-independent, abstract representation” (Bigsby, 1988, p. 455). (We return to this issue in the Discussion section.)
More recently, the cross-case letter match task has been combined with the masked-priming procedure (Forster & Davis, 1984) to produce the masked-priming cross-case letter match task (e.g., Kinoshita & Kaplan, 2008; Norris & Kinoshita, 2008). Here, as in the standard sequential letter match task, participants decide whether a target letter (e.g., “A”) has the same identity as the reference letter presented in advance (e.g., “a”), and a prime letter is presented briefly before the target. When the prime has the same identity as the target (e.g., “a”), it facilitates the Same response, relative to a control prime that has a different identity (e.g., “x”). In this task, the visual similarity between the prime–target pair can be manipulated, allowing for an examination of whether the priming is sensitive to the visual appearance of letters. Using this task, priming has been found to be equally robust for visually dissimilar cross-case prime–target pairs (e.g., g/G, a/A) and visually similar cross-case pairs (e.g., c/C, x/X), suggesting the use of abstract letter identities (Kinoshita & Kaplan, 2008; Norris & Kinoshita, 2008).
The manipulation of visual similarity to investigate letter-priming effects has been used previously with such tasks as the alphabet decision task and the letter-naming task (e.g., Arguin & Bub, 1995; Bowers et al., 1998), and these studies did not yield clear evidence for abstract letter identities (see Grainger, Rey, & Dufau, 2008, for a summary). Rather than taking these results as evidence against the presence of abstract letter identities, we, following Kinoshita and Kaplan (2008), note that the alphabet decision and letter-naming tasks are not well-suited for testing interactions with visual similarity. First, the priming effects in the alphabet decision task are small in size (<20 ms), leaving little room to observe modulation of the effect. Second, as Arguin & Bub, (1995) pointed out, the alphabet decision task does not require unique letter identification (i.e., activation of a specific abstract letter identity); instead, the decision can be based on “global letter activity,” the summed activation across all letter representations. (In the same way, a positive lexical decision can be made on the basis of comparison across the lexicon, rather than by the selection of a particular lexical entry—e.g., Grainger & Jacobs, 1996; Norris, 2006. Norris also explains how, if “summed probability” is used, the vowel–consonant decision task likewise does not require unique letter identification.) Finally, the letter-naming task, although it mitigates these issues, is “overly sensitive to phonological–articulatory factors, which . . . render the task relatively insensitive to visual factors,” due to the spoken response (Grainger et al., 2008, p. 384). The cross-case letter match task, in contrast, yields priming effects that are quite large (~50 ms) and requires the identification of a specific letter representation for accurate performance, but it does not involve speech output (for more detail, see Kinoshita & Kaplan, 2008).
An emerging line of research based on this task indicates that abstract identity representations are not unique to the letters of the Roman alphabet. The Arabic alphabet also has multiple allographs for each letter identity, and they differ in their cross-form visual similarity (e.g., ـعـ/ع vs. ـذ/ذ; see Carreiras, Perea, & Mallouh, 2012, for further examples). Carreiras and colleagues found robust cross-allograph priming for Arabic in the masked-priming letter match task, which did not depend on the visual similarity between the forms. They took their findings as evidence for abstract letter identities in the Arabic orthography, suggesting that abstract letter identities may be “universal” (the title of their article). A version of this experiment with concurrent event-related potential (ERP) recording revealed a late time window (280–500 ms) in which neural responses were invariant to the visual similarity of cross-form pairs, a possible neural correlate of abstract letter codes. Further evidence for abstract letter identities in Arabic, also demonstrated at the single-letter level, comes from Wiley, Wilson, and Rapp (2016).
Acquisition of abstract identities
Another source of evidence for abstract letter identity representations comes from children’s acquisition of letter knowledge. Work on the development of abstract letter identities in children learning to read has been conducted in both the Arabic and Roman orthographies. In a study utilizing primed lexical decision in Arabic, Perea, Abu Mallouh, and Carreiras (2013) compared the magnitudes of masked-priming effects for visually similar and visually dissimilar prime–target word pairs in third- and sixth-grade children as well as in adults. The adults showed abstract identity priming, with no difference in the magnitudes of priming effects when the pairs were visually similar or visually dissimilar. The same pattern was found in both age groups of children, suggesting the development of abstract identity processing in Arabic by third grade. Perea, Jiménez, and Gomez (2015) tested Spanish third graders, fifth graders, and adults in a lexical decision task with same- and cross-case word primes in the Roman alphabet (e.g., “arte” vs. “ARTE” priming “ARTE”). For the adults and fifth-grade participants, no effect of case was found, suggesting the use of abstract identities. In contrast, the third graders showed larger facilitation from a same- than from a cross-case prime for words composed of letters that were visually dissimilar across cases (i.e., “ARTE,” but not “arte” primed “ARTE”), suggesting that after 2 years of formal reading instruction, their abstract letter identity representations had not fully developed.
Thompson (2009) reviewed studies investigating the learning of Roman alphabet abstract letter identities (in English) and also concluded that acquisition is slow. Thompson pointed out that despite the predominance of the lowercase form of letters in the adult print environment, there is a lag in children’s knowledge of the names for lowercase letters. Before formal reading instruction commences, preschool children can identify some letters by name, but predominantly the uppercase forms (Worden & Boettcher, 1990). This is consistent with evidence that children’s home literacy instruction often involves uppercase letters, and that the word with which children are most familiar—their name—is written with a capital initial letter or in all uppercase (Treiman, Cohen, Mulqueeny, Kessler, & Schechtman, 2007). Thompson (2009) reviewed further evidence indicating that this lag for lowercase forms persists after formal reading instruction begins. Eleven-year-old children were significantly slower at naming lowercase than at naming uppercase letters from visually dissimilar pairs (e.g., a/A), while there was no significant difference in naming times for cross-case visually similar letter pairs. Thompson thus concluded that the use of abstract, form-invariant representations in the Roman alphabet appears to develop slowly. Both Perea et al.’s (2015) lexical decision experiment with Spanish-speaking children and Thompson’s review of English-speaking children suggest that the acquisition of abstract letter identities in the Roman alphabet is not fully in place after 2 years of formal reading instruction.
One point to note about these acquisition studies is that they generally used tasks that required more than the knowledge of which visual forms map onto the same letter identity. The masked-priming studies by Perea and colleagues (2013, 2015) used words rather than single letters, and therefore may have indexed abstract lexical representations rather than abstract representations at the letter level. Bowers, Vigliocco, and Haan noted in 1998 that researchers often investigate word (or pseudoword) identification on the (unwarranted) assumption that the results have implications for letters. According to this view, it is possible that the slow developmental trajectory of abstract letter identities observed by Perea et al. (2015) is specific to words. Although letter-naming tasks (as in Thompson, 2009) are conducted at the single-letter level, they also require explicit knowledge of (and automatic access to) the phonological form of the letter. Thus, it is possible that abstract letter identities may be present earlier in reading acquisition, but not evident in the tasks used to date. Many questions remain about the acquisition of abstract letter representations across orthographies in first-language (L1) learners, such as the children in these studies.
However, investigating L1 children’s acquisition of abstract letter identities is challenging, because other aspects of children’s cognitive abilities (e.g., visual attention) are rapidly developing. With adults this is of lesser concern, and researchers in visual word recognition have used adults to gain a handle on the acquisition of new (artificial) orthography (e.g., Taylor, Davis, & Rastle, 2017; Taylor, Plunkett, & Nation, 2011). Here we studied adults learning a new language (and orthography), Japanese. Studies on the acquisition of abstract letter representations in these individuals have the potential to inform the universality of letter processing across orthographies, as well as the extent to which second-language (L2) orthography acquisition resembles L1 acquisition.
Acquisition of abstract identities in Japanese kana
In the present study, we probed abstract identity representations in Japanese kana using the masked-priming letter match task. Kana comprise two different scripts: hiragana (used for writing all types of words, including function words) and katakana (used for loan words of foreign origin and other phonetic spellings). Hiragana is more commonly encountered than katakana in written text (36.6% vs. 6.4%, respectively, of the database of 56.6 million character tokens from the Asahi Shimbun newspaper, issued in 1993; Chikamatsu, Yokoyama, Nozaki, Long, & Fukuda, 2000). Both hiragana and katakana were derived in the eighth century from a set of characters introduced from China for their phonetic value. There are 46 basic kana, each mapping onto a mora, a syllable-like phonological unit comprising either a single vowel or a consonant–vowel combination.Footnote 1 For each kana there is a hiragana form and a katakana form. For example, の and ノ are the hiragana and katakana characters, respectively, for the syllable /no/. (Note that kana and morae have a completely consistent, one-to-one relationship, and unlike in the Roman alphabet, there is no distinction between “letter names” [e.g., “dee” for “d”] and “letter sounds” [/d/].) This cross-script allographic correspondence is analogous to the cross-case correspondences found in the Roman alphabet: two parallel forms that can vary in their visual similarity, yet correspond to the same identity and the same letter name, and are treated identically when sorting in alphabetical order (the equivalent of a–b–c in Japanese is a–i–u–e–o). We sought evidence for cross-script abstract identities in kana that would be involved in the recognition of both hiragana and katakana characters. Abstract identities, by definition, would be invariant to visual form, so that both の and ノ would be represented with a single identity, despite their difference in appearance.
Kinoshita, Schubert, and Verdonschot (2018) recently showed that native Japanese readers show evidence of priming based on orthographic overlap between the two forms of kana. However, these authors focused on distinguishing phonological priming from orthographic priming, and performed only a post-hoc analysis of the effect of visual similarity. (We return to this study and the role of phonology in the Discussion.) Here we tested adult Japanese L2 learners: adult English speakers who had received a minimum of two semesters of Japanese language instruction. Our study expands on that of Kinoshita et al. (2018) in two ways: by directly testing for abstract identities through the comparison of visually similar and visually dissimilar kana pairs, and by testing L2 rather than L1 Japanese readers.
Since our participants were fluent readers of English, we also sought to replicate Kinoshita and Kaplan’s (2008) findings of abstract letter identities in the Roman alphabet, for comparison. We used the masked-priming cross-case/cross-script match task, requiring participants to decide whether a target letter/kana (e.g., “a” or “あ”) is the same or different from a reference letter presented in advance (e.g., “A” or “ア”), with a prime stimulus that could be visually similar (e.g., c/C, へ/ヘ) or visually dissimilar (e.g., a/A, あ/ア) to the target. Following the kana match task, the participants were also asked to name the 44 basic kana presented in the hiragana and katakana forms.
Experiment
English speakers learning Japanese completed a Roman alphabet (Exp. 1a) and a Japanese kana (Exp. 1b) letter match task. The critical primes were cross-case (or cross-script) characters from the target. The visual similarity between the prime and target was also manipulated, with high-similarity cross-case (-script) and low-similarity cross-case (-script) pairs. Abstract identity priming would present as equivalent priming for cross-case (-script) similar and cross-case (-script) dissimilar primes. However, if abstract kana identities were not fully developed in these participants, due to their limited Japanese exposure, we might expect priming to be visually based—that is, greater for visually similar than for visually dissimilar kana pairs.
Method
Participants
Sixteen undergraduate psychology students from Macquarie University (ten females) with a mean age of 20 years (SD = 1.9) participated in the study as part of course requirements. They were required to have completed at least two semesters of Japanese language study, sufficient to have exposure to both kana scripts. (In the local system of teaching of Japanese, hiragana is taught first, and katakana is introduced in the second semester.) A brief survey on language exposure indicated that most of the participants had begun their Japanese studies in high school and spent fewer than 5 h reading Japanese-language materials (e.g., manga, novels, news articles) in a typical week. This study was approved by the Macquarie University Human Research Ethics Committee, and the participants provided informed consent.
Apparatus and procedure
The participants completed two analogous same–different matching tasks, one for Roman letters and one for kana characters. Each trial involved a reference, prime, and target, presented in that order (e.g., b–b–B or b–B–B). The reference and the target were always in the opposite case; in half of the trials the reference was in uppercase, and in the other half the reference was in lowercase. For half of the trials, the prime and target were opposite in case (as in Exp. 1 of Kinoshita & Kaplan, 2008); for the other half, the prime and target were in the same case (as in Exp. 2 of Kinoshita & Kaplan, 2008). (Kinoshita and Kaplan, 2008, found that the magnitudes and patterns of priming were similar in the two experiments.) Thus, for each letter (or kana), there were four reference–prime–target combinations (see Tables 1 and 2). For the “different” response–target pairs and control prime–target pairs, the letters were chosen from the same letter similarity class (similar or dissimilar).
The critical Roman stimuli were six cross-case dissimilar letter pairs (A/a, B/b, D/d, E/e, G/g, and R/r) and six similar letter pairs (C/c, K/k, O/o, P/p, S/s, and X/x) from Kinoshita and Kaplan (2008). The critical kana stimuli were eight cross-script dissimilar hiragana–katakana pairs (あ/ ア, い/イ, す/ス, の/ノ, み/ミ, よ/ヨ, ひ/ヒ, and と/ト) and eight cross-script similar pairs (う/ウ, か/カ, き/キ, せ/セ, へ/へ, も/モ, や/ヤ, and り/リ). Because there are no published visual similarity ratings for kana (to our knowledge), similarity classes were determined by the experimenters and confirmed by ratings from native Japanese readers. Five participants (who did not participate in the experimental tasks) rated all 44 hiragana–katakana cross-script pairs (see Appendix Table 6). On average, the similar hiragana–katakana pairs chosen for the experiment received a similarity rating of 4.75 (range 4.4–5.0, SD = 0.21), while the dissimilar stimuli were rated 1.45 (range 1.2–2.0, SD = 0.32)—that is, the similar and dissimilar kana pairs represented nonoverlapping extremes of the similarity ratings.
Each trial began with the presentation of a reference letter, shown directly above a forward mask (#). After 1,000 ms, the forward mask was replaced by the prime for 50 ms, followed by the target letter, which remained until the participant had responded or 2,000 ms had elapsed. A blank screen (800 ms) intervened between trials. Stimuli were presented in black in the center of a white screen, in 12-point Courier for the Roman letters and 12-point MSGothic for the kana characters. The target was magnified 1.2 times so that it did not completely overlap with the prime when they were identical. DMDX was used for the presentation of the stimuli and collection of responses (Forster & Forster, 2003).
Participants were instructed to decide, as quickly and accurately as possible, whether the two letters presented had the same or different identities, ignoring the difference in case (Roman) or script (kana). No mention was made of the presence of the primes. There were 192 trials per participant for the letter experiment (2 [Response Type: same/different] × 2 [Prime Type: identity/control] × 2 [Visual Similarity: similar/dissimilar] × 6 Letters per Condition × 4 Reference-Prime–Target Combinations) and 256 trials for the kana experiment (8 Kana per Condition). Participants first completed 12 practice trials involving characters that were not the critical stimuli. The order of trials within each experiment was randomized, and the letter experiment was always presented first.Footnote 2 Accuracy feedback was given following an incorrect trial.
Finally, as a check of participants’ explicit knowledge of kana, they named aloud the katakana and hiragana characters. These were presented singly for 2,000 ms each. Each katakana and hiragana character was presented once (44 syllables × 2 scripts = 88 trials), following six practice trials. Accuracy and response times (RTs) were recorded, and no feedback was given.
Analysis
The data were analyzed using mixed-effects modeling, treating participants and target stimuli as crossed random effects. The RTs were inverse-transformed to best meet the distributional assumption of the model and were multiplied by – 1,000 to maintain the direction of effects and reduce the number of decimal points (i.e., – 1,000/RT). A cutoff for outliers was determined by inspecting the Q–Q plots of the inverse-transformed RTs. The analysis of error rates used a logistic link function. We used the lme4 package (Version 1.1-5; Bates, Mächler, Bolker, & Walker, 2015), implemented in R Version 3.0.3 (R Core Team, 2016). Degrees of freedom (Satterthwaite’s approximation) and p values were estimated using the lmerTest package (Version 2.0-11; Kuznetsova, Brockhoff, & Christensen, 2016). In line with the recommendation to keep the random-effect structure maximal (Barr, Levy, Scheepers, & Tily, 2013), the initial model included random slopes on participants and targets; the final model we report was selected using a backward, stepwise model selection procedure. We also computed Bayes factors (BFs) using the BayesFactor package (Morey & Rouder, 2015). A BF indexes the proportion of evidence for one hypothesis over another and was used to supplement our null-hypothesis significance testing. The typical value for what is considered strong evidence for a hypothesis is BF > 3 (Dienes, 2014; Jeffreys, 1961).
We analyzed only the Same trials, for which masked-priming effects have been observed in the same–different task (Norris & Kinoshita, 2008). The fixed-effect factors were cross-case/-script similarity (similar/dissimilar), prime type (identity/control), and prime–target (PT) case (script) (same case/different case), all deviation-contrast-coded (– .5, .5) to reflect the factorial design.
Results
Roman alphabet
The RT and error data are presented in Table 3. In the analysis of correct RTs, there were no outliers, resulting in 1,465 data points. The best-fitting statistical model was invRT ~ similarity * prime type * PT case + (1 | target) + (1 + prime type | subject). The main effect of prime type was significant, t = – 5.958, p < .001. The main effect of similarity was also significant, t = – 3.564, p < .01. The main effect of prime–target case was nonsignificant, t = – 1.752, p = .08. Prime–target case interacted with prime type, t = – 2.79, p < .01, indicating that priming was greater when the prime case was the same as the target case, as compared to when they were different. However, the triple interaction between prime type, similarity, and prime–target case was nonsignificant, t = 1.068, p < .28, indicating that whether the prime case was the same as the target case did not modulate the pattern of interaction between prime type and similarity. Critically, there was also no interaction between prime type and similarity, t = 0.143, p = .887. The BFs were 1.74 × 1024 (over 1 septillion) in favor of the main effect of prime type, and 11 in favor of the null interaction between priming and visual similarity. These values indicate exceedingly strong evidence for a priming effect, and very strong evidence that the priming effect is independent of visual similarity.
In the analysis of errors, the statistical model was errors ~ PT case * similarity * prime type + (1 | target) + (1 | subject). Prime–target case interacted with similarity, Z = 1.998, p < .05. This reflected the fact that for the cross-case dissimilar letters, there were more errors when the case differed between the prime and target (same case, 3.12%; different cases, 5.98%), whereas for the cross-case similar letters, the error rate was greater when the prime and target cases were the same (same case, 5.47%; different cases, 3.91%). Note that this occurred independent of whether the prime was an identity or control prime (no interaction with the prime type factor). None of the main effects of prime type, similarity, or prime–target case, nor the interactions between them, were significant, all |Z|s < 1.21, ps > .22. Importantly, we observed no interaction between prime type and similarity, t = 0.312, p = .755.
Kana script
The RT and error data are presented in Table 4. In the analysis of correct RTs there were no outliers, resulting in 1,936 data points. The best-fitting statistical model included subject random slopes for the prime type factor and an item random intercept: invRT ~ similarity * prime type * PT script + (1 | target) + (1 + prime type | subject). The main effect of prime type was significant, t = – 7.953, p < .001. The main effect of similarity was nonsignificant, t = – 1.223, p = .242. The main effect of prime–target script was also nonsignificant, t = – 1.192, p = .23. Prime–target script interacted with prime type, t = – 2.019, p < .05, indicating that priming was greater when the prime script was the same as the target script, as compared to when they were different. However, the triple interaction between prime type, similarity, and prime–target script was nonsignificant, t = 1.287, p = .19, indicating that whether the prime script was the same as the target script did not modulate the pattern of interaction between prime type and similarity. Critically, we also found no interaction between prime type and similarity, t = – 1.506, p = .132. The BFs were 1.87 × 1024 in favor of the main effect of prime type, and 13 in favor of the null interaction with visual similarity. Analogous to the results from the Roman alphabet task, this indicates very strong evidence for priming that was independent of visual similarity.
In the analysis of errors, the statistical model we report is errors ~ similarity * prime type + (1 | target) + (1 | subject). (The same model including the interaction with prime–target script did not converge.) The main effect of prime type was significant, z = – 3.975, p < .001, but the main effect of similarity was nonsignificant, z = – 1.215, p = .225, as was the interaction between prime type and similarity, z = – 1.135, p = .256.
Kana naming
Table 5 shows the mean RTs for correct trials and the error rates for the kana-naming task. Means are given separately for the visually dissimilar and visually similar kana pairs used in the kana match task, as well as for the other (unused) kana pairs. The mean accuracy across participants was 81.32% (SD = 8.93), with a range of 72.73%–100% correct. It is apparent that the participants’ knowledge of kana names was not perfect (in fact, only one participant was able to name all of the kana characters correctly). Another noteworthy point is that the hiragana characters were named faster and more accurately than the katakana characters. This was supported by analysis of the critical items used in the kana match task and the unused items (analyzed separately), using a linear mixed-effects model with stimuli and subjects as crossed random factors.
For the critical items, log-naming RTs were analyzed using kana type (hiragana or katakana) and cross-script similarity (contrast-coded) as fixed-effect factors [in R syntax, logRT ~ kana type * similarity + (1 | stimuli) + (1 | subject)]. This revealed a significant main effect of kana type, t = 5.339, p < .001, and although the hiragana advantage was numerically greater for the dissimilar pairs (94 ms) than for the visually similar pairs (66 ms), the interaction with visual similarity did not reach significance, t = – 1.458, p = .146. Similarly, the analysis of error rates for the critical items revealed fewer errors on hiragana characters, Z = 2.249, p < .03, and the interaction between kana type and visual similarity did not reach significance, Z = – 1.114, p = .265.
For the items not used in the kana match task, the analysis involved kana type (hiragana vs. katakana) as the fixed factor and the subject and item intercepts as crossed random factors [in R syntax, logRT ~ kana type + (1 | stimuli) + (1 | subj)]. This analysis showed that katakana were named significantly more slowly than hiragana, t = 7.378, p < .001. The error rate was also significantly higher for katakana than for hiragana, Z = 6.34, p < .001.
To probe specifically whether the priming in the kana match task was based on phonology (kana names), we examined the correlations between the size of the priming effect and kana-naming performance for the cross-case dissimilar and similar pairs. If the cross-case match was based on phonology, the two dependent variables should be correlated (the more fluently the kana name is retrieved, the greater the priming). Indexing the kana-naming performance for the critical items required some consideration. Error rates could not be used, because there were very few naming errors for these items (see Table 5). Also, because the naming RT is highly dependent on the phonetic characteristics of the onset of an item (Balota, Cortese, Sergent-Marshall, Spieler, & Yap, 2004), the naming RT for individual items would not be an appropriate measure of fluency in retrieving the kana name. In view of these issues, we calculated for each participant the difference in mean naming RTs for the same identity when presented as hiragana and katakana (these have the same name, avoiding any confounding with initial phoneme)—that is, katakana naming RT – hiragana naming RT. A large positive value on this measure would indicate relatively less fluent naming of katakana, which was the more difficult of the kana forms for these participants (and hence a more sensitive index of their kana name retrieval). For the cross-kana dissimilar pairs, this ranged from – 35 to 307 ms (mean = 94 ms), and for similar pairs, – 90 to 268 ms (mean = 60 ms).Footnote 3 This measure correlated with the overall accuracy of katakana naming (for all 44 katakana)—for cross-kana dissimilar pairs, r = – .49, p = .05, and for cross-kana similar pairs, r = – .48, p = .05—indicating that the measure was sensitive to the individuals’ knowledge of the kana names. Critically, this measure did not correlate with the size of priming in the kana match task—for the cross-kana dissimilar pairs, r = .06, p = .83; for the cross-kana similar pairs, r = – .11, p = .69—consistent with the view that the cross-kana match is not based on phonology.
Discussion
We tested adult learners of Japanese (native English readers) in primed cross-case letter match and cross-script kana match tasks. In both tasks, the reference and target were in opposite cases (uppercase vs. lowercase) or kana scripts (hiragana vs. katakana), and the visual similarity of the cross-case/-script identity was manipulated (e.g., c/C, へ/ヘ, visually similar; a/A, あ/ア, visually dissimilar). Robust identity-priming effects, equal in size for the visually similar and dissimilar pairs, were found for both writing systems. For the Roman alphabet, this replicated previous findings of abstract identities at the single-letter level in L1 adult readers (Kinoshita & Kaplan, 2008, with English readers; Carreiras et al., 2012, with Arabic), suggesting that this finding is highly reliable. The same pattern of results was observed with kana: Robust priming effects were found that were independent of visual similarity. This is the first evidence for abstract identities in the Japanese kana writing system, and in adult L2 learners of any orthography.
Our data support the view that priming of abstract identities may be a “universal phenomenon” across writing systems with multiple visual forms for a given identity, as suggested by Carreiras et al. (2012). Moreover, we found abstract identities in learners of kana with only a few semesters of Japanese language instruction, suggesting that the learning of these representations occurs rapidly. This rapid acquisition of foreign letter forms is consistent with results reported by Pelli, Burns, Farrell, and Moore-Page (2006): These authors found that participants (ranging from 3 to 68 years old) attained the same proficiency in letter identification as fluent readers (as measured by the identification accuracy of a low-contrast letter) in just three thousand trials. (Three thousand trials is a tiny fraction of the letter encounters for a mature reader, estimated to be 1.1 × 109 letters for a reader reading 1 h every day for 40 years.)
Of interest, Pelli et al. (2006) noted that despite attaining the same efficiency as fluent readers in the identification of single letters, these participants had “the same meager memory span (measured using a partial report procedure) for the random strings of these characters as observers seeing them for the first time” (p. 4665)—only one or two letters, less than half the visual memory span of fluent L1 readers. Pelli et al.’s (2006) observation of a dissociation between proficiency in single letter identification and a limited memory span could help explain the discrepancy between our findings and previous work with children in L1 reading acquisition. For example, Perea et al. (2015) suggested that abstract identities for the Roman alphabet are acquired slowly, and are not fully present before third grade, supported by a larger facilitation from same-case identity word primes (e.g., ARTE–ARTE) than cross-case identity word primes (e.g., arte–ARTE). Extending Pelli’s findings that the processing of multiletter sequences lags behind that of single letters, it is possible that even established abstract letter identity representations at the single-letter level may not be sufficient to support the parallel processing of a string of letters (i.e., words).
There are other reasons to distinguish between representations that support the identification of single letters and letter strings (either pseudowords or words). Some types of allographic variation are relevant only at the level of a letter string and not at the level of a single letter. Examples are the position-dependent allography in Arabic, which is meaningful only when more than one letter is present to define multiple positions, and systematic case variation in the Roman alphabet, such as initial capitalization for nouns in German and for proper names (e.g., Mark/mark; China/china) in many European languages. These types of allographic variation at the word level do influence visual word recognition; for example, proper names (e.g., Anna, America) are recognized faster in initial-capitalized form (e.g., in Italian; Peressotti, Cubelli, & Job, 2003). However, these effects are not incompatible with abstract letter identity representations, they simply require an assumption that letter case/allograph information is also stored and passed on to subsequent processing levels (Schubert & McCloskey, 2013). The “orthographic cue hypothesis” proposed by Peressotti et al. is based on such an assumption.
Another recent finding concerning allographic variation at the word level has been used to argue against the presence of single-character abstract identities in Japanese kana. Perea, Nakayama, and Lupker (2017) conducted a masked-priming lexical decision task, with target words written in katakana (e.g., レストラン, meaning “restaurant”) and phonologically identical primes written in katakana (e.g., レストラン) or in alternating hiragana and katakana (e.g., レすトらン). Responses to targets preceded by pure katakana primes were faster than to those preceded by alternating-kana primes. Perea et al. (2017) concluded that “in Japanese, abstract units are shared at the lexical level, but not at the character level” (p. 1144). However, these results are not incompatible with abstract character identities. In Japanese, the use of katakana is a cue to the type of word presented: Loan words, mostly nouns of Western origin (like “restaurant” レストラン), are always written in katakana. That is, the katakana format conveys information about the class of words, just as initial capitalization in English indicates that a word is a proper name. This orthographic cue is clearly not available in words written in alternating script, which could reduce the benefit in lexical access conferred by an identity prime written in alternating hiragana and katakana. Although the lexical decision task clarifies the role of kana script at the word level, it does not provide direct evidence for or against abstract identity representations at the single-character level (just as results in Roman script indicating that proper names are recognized more easily with the first letter capitalized do not negate strong evidence from multiple sources for abstract letter identities at the single-letter level). Thus, though Perea et al.’s (2017) results are relevant to word-level processing in Japanese kana, their implications for single-character processing are unclear. For that, a paradigm would have to be used that involves the presentation only of single characters (cf. Bowers, et al., 1998), such as the letter match task used in our study.
Abstract orthographic codes or phonology?
We noted in the introduction that although early studies (e.g., Posner & Mitchell, 1967) assumed that nominal letter identity match is based on phonological (“name”) codes, subsequent studies have conclusively argued against this view and explained why the letter match task is well-suited to investigate the priming of abstract letter identities. Despite this body of existing evidence, some still question the orthographic basis of allograph priming effects in the same–different match task (e.g., Lupker, Nakayama, & Perea, 2015).Footnote 4 Specifically, the equal-sized priming effects found with visually similar (e.g., c–C) and visually dissimilar (e.g., g–G) prime–target letter pairs are also consistent with a phonological priming effect, based on allographs sharing the same letter name and/or sound (e.g., g–G are both linked to “gee” and to /g/).
Kinoshita, Schubert, and Verdonschot (2018) used masked priming in the same–different task to directly test for a phonological basis of allograph priming with native (L1) Japanese readers. This study took advantage of the fact that the Japanese writing system comprises logographic kanji characters (adapted from Mandarin characters) in addition to the syllabic kana used here. Where the two kana scripts are allographic, kanji is a distinct writing system and has no orthographic overlap with kana. However, some kanji characters are homophonic with kana (e.g., kanji–kana: 木–き, 木–キ, all pronounced /ki/), allowing an experiment that contrasted kanji–kana priming and kana–kana priming. If allographic priming is based on phonology, the priming of kana by a homographic kanji character should not differ in size from the priming of kana by a homographic (allographic) kana character. Instead, the experiment showed that the priming of a single kana target by a homophonic kanji character (e.g., kanji–kana: 木–き, 木–キ, all pronounced /ki/) was substantially smaller (29 ms) than the priming effect produced by an allographic kana prime (e.g., kana–kana: キ–き, き–キ, also all pronounced /ki/). This result indicates that allograph priming cannot be reduced to phonological priming. The allograph-priming effects were also found to be independent of similarity in visual form (e.g., visually similar: り–リ; visually dissimilar: す–ス), as we found in the present experiment with adult L2 learners.
In the present experiment, we examined the use of phonology by looking at participants’ explicit knowledge of kana names. Although the participants in our study demonstrated evidence of abstract kana representations in their L2 comparable to those found in their L1 alphabetic writing system in the matching task, their knowledge of that L2 was not fully native-like: They did not perform perfectly on the kana-naming task. Within this group of L2 learners, individuals differed in their kana-naming ability; however, there was no correlation between the fluency with which they named the kana and the magnitude of priming, either for the cross-script dissimilar (e.g., あ/ア) or the cross-script similar (e.g., り/リ) kana pairs. This pattern is similar to the neuropsychological data presented by Rynard and Besner (1987), in the Roman alphabet for an L1 learner. They presented a 16-year-old boy with minimal reading ability, who could not name all the letters of the alphabet, but who nevertheless was able to match all cross-case letter pairs perfectly. The absence of a correlation between the size of priming and the kana-naming ability in our L2 learners suggests that despite the fact that cross-script dissimilar kana pairs cannot be matched on the basis of visual similarity, they were also not matched on the basis of their phonology (name). These findings—the combination of imperfect knowledge of the kana names with robust cross-script priming, and the absence of correlation between the size of priming effect and kana-naming fluency—further strengthen the view that priming in the nominal identity match task is based on abstract orthographic codes, not phonological codes.
Comparing L1 and L2
The adult Japanese-learners we tested demonstrated lower knowledge of katakana than of hiragana, with the former named more slowly and less accurately, resembling Thompson’s (2009) observation of a lag in letter-naming performance for lowercase forms in English-speaking children. Given our results with L2 learners, including evidence that abstract identities are used prior to the acquisition of full kana-naming abilities, future studies should further investigate the development of abstract identities in L1 learners, separate from their knowledge of letter names. As we noted above, the acquisition of abstract letter identities in children has often been studied using tasks requiring explicit naming or using lexical decision tasks, which do not directly address abstract letter representations. It would be instructive to compare performance on different tasks in future studies of reading acquisition, in both L1 and L2 learners.
Since our participants were bilingual, one can ask how their performance in the kana task may have been related to their English and Roman-letter knowledge. Models of bilingual word recognition (e.g., the bilingual interactive activation model and BIA+; Dijkstra & van Heuven, 2002), although highly successful in accounting for task performance across European languages employing the same Roman alphabet, do not posit an architecture compatible with biscriptal individuals. Recent investigations of phonological priming across scripts (including kana and kanji priming English words; see the review in Ando, Jared, Nakayama, & Hino, 2014) have led to an extension of this model to biscriptal bilinguals (Ando et al., 2014; Miwa, Dijkstra, Bolger, & Baayen, 2014). In this version of BIA+, Ando and colleagues propose that the two scripts have separate orthographic systems, with the earliest point of overlap at sublexical phonological representations.
Our proposal that kana characters and Roman letters share a principle of orthographic abstraction, across kana scripts and across cases, respectively, is not to suggest that the two scripts share orthographic processing or orthographic representations. Rather, we contend that this organization develops naturally on the basis of the properties of the scripts: that is, the presence of two allographic forms in both kana (hiragana and katakana) and the Roman alphabet (uppercase and lowercase). Abstraction away from allographic variation in both scripts links disparate visual forms to a single orthographic identity that is invariant to visual form. Following this assumption, we predict that the development of abstract kana identities in L2 learners would not differ on the basis of the participants’ L1 script and would occur equally for L1 and L2 kana learners (though acquisition speed may differ for child vs. adult learners).
Letter abstraction in the brain
Neural evidence consistent with abstraction over allographic variation has been reported in ERP (e.g., Chauncey, Holcomb, & Grainger, 2008; Holcomb & Grainger, 2006; Petit et al., 2006) as well as in fMRI (e.g., Dehaene et al., 2004; Kronbichler et al., 2009; Polk & Farah, 2002; Rothlein & Rapp, 2014) studies. As with the behavioral work reviewed above, the majority of neuroimaging studies of orthographic abstraction have focused on word-level contrasts (e.g., a large body of work on the visual word form area). In the same way that behavioral studies with words provide primary evidence for word-level orthographic processing, these studies may be interpreted as neural evidence for word-level abstract orthographic processing (e.g., access to an orthographic lexicon). Letter-level processing has been targeted specifically by Petit et al. and Rothlein and Rapp, contributing to a growing consensus on abstract orthographic representations at the single-letter level. Furthermore, ERP results indicating a neural processing hierarchy, proceeding from levels sensitive to visual features to levels encoding case-specific letter forms and finally to case-invariant (abstract) letter forms (e.g., Petit et al., 2006), align with cognitive models of letter identification based on behavioral evidence (McCloskey & Schubert, 2014; Schubert & McCloskey, 2013).
Though these neural studies have typically involved Roman letters, neuroimaging work by Bolger and colleagues (Bolger, Perfetti, & Schneider, 2005) compared Japanese and Roman writing systems, finding similarities in the neural areas activated across scripts, consistent with the use of similar representational levels. Adapting the terminology from processing models of Roman script, we suggest that kana proceeds through visual feature processing, kana-specific (distinct hiragana and katakana) representations, and finally kana-invariant representations (shared by hiragana and katakana forms). It is this third and most abstract level that the priming in our experiment reflects.
Concluding remarks
We report a priming effect in L2 learners of Japanese that is consistent with abstract orthographic representations for single kana characters. Building on previous work that established that cross-kana priming is orthographic, rather than phonological, we demonstrated that this priming is not affected by visual similarity, a hallmark of orthographic abstraction. Furthermore, this priming is found not only in L1 Japanese readers but also in L2 learners, suggesting that it is a response to the properties of the kana scripts—specifically, the existence of two allographic forms (hiragana and katakana) for each syllable. Future work should explore the learning of abstract identities in L1 and L2 Japanese readers and the relationship between explicit and implicit knowledge of kana.
Author note
T.S. and S.K were supported by funding from the ARC Centre of Excellence in Cognition and Its Disorders (CE110001021). S.K. is further supported by an ARC Discovery Project grant (DP140101199).
Notes
In addition to these basic kana, voicing is denoted orthographically by a diacritic that looks like a double apostrophe above the basic kana—for instance, か (/ka/) → が (/ga/)—and morae beginning with palatalized consonants are written as digraphs—for instance, きゃ (“kya”). Here we focused only on the basic unvoiced kana, and we also excluded the kana denoting a nasal mora /n/ (hiragana ん, katakana ン), which cannot stand alone and only occur as a coda, and を/ヲ, which occur only as a grammatical particle, written usually in hiragana.
Due to the lack of orthographic overlap between Roman letters and kana, there could be no cross-language priming in this task, and the presentation order of the experiments should not affect performance. For further discussion, see the Discussion.
The mean differences here differ slightly from the differences of mean naming RTs shown in Table 5, because the former are the means of the individual differences in RTs, whereas the latter are the differences in mean RTs.
Lupker, Nakayama, and Perea (2015) recently argued that responses in same–different match tasks are based on phonological codes, on the basis of the finding that Japanese–English bilinguals asked to match English words (e.g., south/SOUTH) showed facilitation from masked primes that were transliterations in Japanese katakana (e.g., サウス, /sa.u.su/). However, their study’s finding of a phonological influence from cross-language primes in word matching bears little relevance for within-language cross-case (or -script) letter-matching tasks, in which no word-level phonological information is involved. Lupker et al. (2015; see also Lupker, Nakayama, & Yoshihara, 2018) did not directly test whether the priming produced by allograph primes within the same writing system was due to phonological priming. When this was tested directly, little support was found for the claim (for words in the Roman alphabet: Kinoshita, Gayed, & Norris, 2018).
References
Ando, E., Jared, D., Nakayama, M., & Hino, Y. (2014). Cross-script phonological priming with Japanese kanji primes and english targets. Journal of Cognitive Psychology, 26, 853–870.
Arguin, M., & Bub, D. (1995). Priming and response selection processes in letter classification and identification tasks. Journal of Experimental Psychology: Human Perception and Performance, 21, 1199–1219. https://doi.org/10.1037/0096-1523.21.6.1199
Balota, D. A., Cortese, M. J., Sergent-Marshall, S. D., Spieler, D. H., & Yap, M. J. (2004). Visual word recognition of single-syllable words. Journal of Experimental Psychology: General, 133, 283–316. https://doi.org/10.1037/0096-3445.133.2.283
Barr, D. J., Levy, R., Scheepers, C., & Tily, H. J. (2013). Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language, 68, 255–278. https://doi.org/10.1016/j.jml.2012.11.001
Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67, 1–48. arXiv:1406.5823
Besner, D., Coltheart, M., & Davelaar, E. (1984). Basic processes in reading: Computation of abstract letter identities. Canadian Journal of Psychology, 38, 126–34.
Bigsby, P. (1988). The visual processor module and normal adult readers. British Journal of Psychology, 79, 455–469.
Bigsby, P. (1990). Abstract letter identities and developmental dyslexia. British Journal of Psychology, 81, 227–263.
Boles, D. B., & Eveland, D. C. (1983). Visual and phonetic codes and the process of generation in letter matching. Journal of Experimental Psychology: Human Perception and Performance, 9, 657–674. https://doi.org/10.1037/0096-1523.9.5.657
Bolger, D. J., Perfetti, C. A., & Schneider, W. (2005). Cross-cultural effect on the brain revisited: Universal structures plus writing system variation. Human Brain Mapping, 25, 92–104.
Bowers, J. S., Vigliocco, G., & Haan, R. (1998). Orthographic, phonological, and articulatory contributions to masked letter and word priming. Journal of Experimental Psychology: Human Perception and Performance, 24, 1705–1719. https://doi.org/10.1037/0096-1523.24.6.1705
Carrasco, M., Kinchla, R. A., & Figueroa, J. G. (1988). Visual letter-matching and the time course of visual and acoustic codes. Acta Psychologica, 69, 1–17.
Carreiras, M., Perea, M., & Mallouh, R. A. (2012). Priming of abstract letter representations may be universal: The case of Arabic. Psychonomic Bulletin & Review, 19, 685–690.
Chauncey, K., Holcomb, P. J., & Grainger, J. (2008). Effects of stimulus font and size on masked repetition priming: An event-related potentials (ERP) investigation. Language and Cognitive Processes, 23, 183–200. https://doi.org/10.1080/01690960701579839
Chikamatsu, N., Yokoyama, S., Nozaki, H., Long, E., & Fukuda, S. (2000). A Japanese logographic character frequency list for cognitive science research. Behavior Research Methods, Instruments, & Computers, 32, 482–500.
Coltheart, M. (1981). Disorders of reading and their implications for models of normal reading. Visible Language, 15, 245–286.
Dehaene, S., Jobert, A., Naccache, L., Ciuciu, P., Poline, J. B., Le Bihan, D., & Cohen, L. (2004). Letter binding and invariant recognition of masked words: Behavioral and neuroimaging evidence. Psychological Science, 15, 307–313. https://doi.org/10.1111/j.0956-7976.2004.00674.x
Dienes, Z. (2014). Using Bayes to get the most out of non-significant results. Frontiers in Psychology, 5, 781:1–17. https://doi.org/10.3389/fpsyg.2014.00781
Dijkstra, T., & van Heuven, W. J. B. (2002). The architecture of the bilingual word recognition system: From identification to decision. Bilingualism: Language and Cognition, 5, 175–197. https://doi.org/10.1017/S1366728902003012
Forster, K. I., & Davis, C. (1984). Repetition priming and frequency attenuation in lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10, 680–698. https://doi.org/10.1037/0278-7393.10.4.680
Forster, K. I., & Forster, J. C. (2003). DMDX: A Windows display program with millisecond accuracy. Behavior Research Methods & Instrumentation, 35, 116–124. https://doi.org/10.3758/BF03195503
Grainger, J., & Jacobs, A. M. (1996). Orthographic processing in visual word recognition: A multiple read-out model. Psychological Review, 103, 518–565. https://doi.org/10.1037/0033-295X.103.3.518
Grainger, J., Rey, A., & Dufau, S. (2008). Letter perception: From pixels to pandemonium. Trends in Cognitive Sciences, 12, 381–387. https://doi.org/10.1016/j.tics.2008.06.006
Holcomb, P. J., & Grainger, J. (2006). On the time course of visual word recognition: An event-related potential investigation using masked repetition priming. Journal of Cognitive Neuroscience, 18, 1631–1643. https://doi.org/10.1162/jocn.2006.18.10.1631
Jeffreys, H. (1961). Theory of probability (3rd ed.). Oxford, UK: Oxford University Press.
Kinoshita, S., & Kaplan, L. (2008). Priming of abstract letter identities in the letter match task. Quarterly Journal of Experimental Psychology, 61, 1873–1885. https://doi.org/10.1080/17470210701781114
Kinoshita, S., Schubert, T., & Verdonschot, R. G. (2018). Allograph priming is on the basis of abstract letter identities: Evidence from Japanese kana. Journal of Experimental Psychology: Learning, Memory, and Cognition. Advance online publication. https://doi.org/10.1037/xlm0000563
Kronbichler, M., Klackl, J., Richlan, F., Schurz, M., Staffen, W., Ladurner, G., & Wimmer, H. (2009). On the functional neuroanatomy of visual word processing: Effects of case and letter deviance. Journal of Cognitive Neuroscience, 21, 222–229.
Kuznetsova, A., Brockhoff, P. B., & Christensen, R. H. B. (2016). lmerTest: Tests in linear mixed effects models (R package version 2.0-3.0). Retrieved from https://cran.r-project.org/package=lmerTest
Lupker, S. J., Nakayama, M., & Perea, M. (2015). Is there phonologically based priming in the same–different task? Evidence from Japanese–English bilinguals. Journal of Experimental Psychology: Human Perception and Performance, 41, 1281–1299.
Lupker, S. J., Nakayama, M., & Yoshihara, M. (2018). Phonologically-based priming in the same–different task with L1 readers. Journal of Experimental Psychology: Learning, Memory, and Cognition. Advance online publication. https://doi.org/10.1037/xlm0000515
McCloskey, M., & Schubert, T. M. (2014). Shared versus separate processes for letter and digit identification. Cognitive Neuropsychology, 31, 437–460. https://doi.org/10.1080/02643294.2013.869202
Miwa, K., Dijkstra, T., Bolger, P., & Baayen, R. H. (2014). Reading english with Japanese in mind: Effects of frequency, phonology, and meaning in different-script bilinguals. Bilingualism, 17, 445–463.
Morey, R. D., & Rouder, J. N. (2015). BayesFactor: Computation of Bayes factors for common designs. Retrieved from https://CRAN.R-project.org/package=BayesFactor
Norris, D. (2006). The Bayesian reader: Explaining word recognition as an optimal Bayesian decision process. Psychological Review, 113, 327–357. https://doi.org/10.1037/0033-295X.113.2.327
Norris, D., & Kinoshita, S. (2008). Perception as evidence accumulation and Bayesian inference: Insights from masked priming. Journal of Experimental Psychology: General, 137, 434–455. https://doi.org/10.1037/a0012799
Pelli, D. G., Burns, C. W., Farrell, B., & Moore-Page, D. C. (2006). Feature detection and letter identification. Vision Research, 46, 4646–4674.
Perea, M., Abu Mallouh, R. A., & Carreiras, M. (2013). Early access to abstract representations in developing readers: Evidence from masked priming. Developmental Science, 16, 564–573. https://doi.org/10.1111/desc.12052
Perea, M., Jiménez, M., & Gomez, P. (2015). Do young readers have fast access to abstract lexical representations? Evidence from masked priming. Journal of Experimental Child Psychology, 129, 140–147. https://doi.org/10.1016/j.jecp.2014.09.005
Perea, M., Nakayama, M., & Lupker, S. J. (2017). Alternating-script priming in japanese: Are katakana and hiragana characters interchangeable? Journal of Experimental Psychology: Learning, Memory, and Cognition, 43, 1140–1146.
Peressotti, F., Cubelli, R., & Job, R. (2003). On recognizing proper names: The orthographic cue hypothesis. Cognitive Psychology, 47, 87–116. https://doi.org/10.1016/S0010-0285(03)00004-5
Petit, J.-P., Midgley, K. J., Holcomb, P. J., & Grainger, J. (2006). On the time course of letter perception: A masked priming ERP investigation. Psychonomic Bulletin & Review, 13, 674–681. https://doi.org/10.3758/2FBF03193980
Polk, T. A., & Farah, M. J. (2002). Functional mri evidence for an abstract, not perceptual, word-form area. Journal of Experimental Psychology: General, 131, 65–72.
Posner, M. I., & Mitchell, R. F. (1967). Chronometric analysis of classification. Psychological Review, 74, 392–409. https://doi.org/10.1037/h0024913
R Core Team. (2016). R: A language and environment for statistical computing (Version 3.0.3). Vienna, Austria: R Foundation for Statistical Computing. Retrieved from https://www.r-project.org/
Reuter-Lorenz, P. A., & Brunn, J. L. (1990). A prelexical basis for letter-by-ietter reading: A case study. Cognitive Neuropsychology, 7, 1–20. https://doi.org/10.1080/02643299008253432
Rothlein, D., & Rapp, B. C. (2014). The similarity structure of distributed neural responses reveals the multiple representations of letters. NeuroImage, 89, 331–344.
Rynard, D., & Besner, D. (1987). Basic processes in reading: On the development of cross-case letter matching without reference to phonology. Bulletin of the Psychonomic Society, 25, 361–363.
Schubert, T. M., & McCloskey, M. (2013). Prelexical representations and processes in reading: Evidence from acquired dyslexia. Cognitive Neuropsychology, 30, 360–395.
Taylor, J. S. H., Davis, M. H., & Rastle, K. (2017). Comparing and validating methods of reading instruction using behavioural and neural findings in an artificial orthography. Journal of Experimental Psychology: General, 146, 826–858. https://doi.org/10.1037/xge0000301
Taylor, J. S. H., Plunkett, K., & Nation, K. (2011). The influence of consistency, frequency, and semantics on learning to read: An artificial orthography paradigm. Journal of Experimental Psychology: Learning, Memory, and Cognition, 37, 60–76. https://doi.org/10.1037/a0020126
Thompson, G. B. (2009). The long learning route to abstract letter units. Cognitive Neuropsychology, 26, 50–69. https://doi.org/10.1080/02643290802200838
Treiman, R., Cohen, J., Mulqueeny, K., Kessler, B., & Schechtman, S. (2007). Young children’s knowledge about printed names. Child Development, 78, 1458–1471.
Wiley, R. W., Wilson, C., & Rapp, B. (2016). The effects of alphabet and expertise on letter perception. Journal of Experimental Psychology: Human Perception and Performance, 42, 1186–1203.
Worden, P. E., & Boettcher, W. (1990). Young children’s acquisition of alphabet knowledge. Journal of Reading Behavior, 22, 277–295.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
Rights and permissions
About this article

Cite this article
Schubert, T., Gawthrop, R. & Kinoshita, S. Evidence for cross-script abstract identities in learners of Japanese kana. Mem Cogn 46, 1010–1021 (2018). https://doi.org/10.3758/s13421-018-0818-4
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-018-0818-4