
Abstract
Parkinson’s disease (PD) is associated with procedural learning deficits. Nonetheless, studies have demonstrated that reward-related learning is comparable between patients with PD and controls (Bódi et al., Brain, 132(9), 2385–2395, 2009; Frank, Seeberger, & O’Reilly, Science, 306(5703), 1940–1943, 2004; Palminteri et al., Proceedings of the National Academy of Sciences of the United States of America, 106(45), 19179–19184, 2009). However, because these studies do not separate the effect of reward from the effect of practice, it is difficult to determine whether the effect of reward on learning is distinct from the effect of corrective feedback on learning. Thus, it is unknown whether these group differences in learning are due to reward processing or learning in general. Here, we compared the performance of medicated PD patients to demographically matched healthy controls (HCs) on a task where the effect of reward can be examined separately from the effect of practice. We found that patients with PD showed significantly less reward-related learning improvements compared to HCs. In addition, stronger learning of rewarded associations over unrewarded associations was significantly correlated with smaller skin-conductance responses for HCs but not PD patients. These results demonstrate that when separating the effect of reward from the effect of corrective feedback, PD patients do not benefit from reward.
Similar content being viewed by others
Reward impacts a wide variety of functions, including attention (Anderson, Laurent, & Yantis, 2011; Roper, Vecera, & Vaidya, 2014), cognitive control (van Steenbergen, Band, & Hommel, 2009, 2012), and visual working memory (Gong & Li, 2014). To improve the chances of obtaining a reward in the future, an organism must use reward to guide learning. Indeed, reward can modulate several forms of learning, including declarative (Adcock, Thangavel, Whitfield-Gabrieli, Knutson, & Gabrieli, 2006; Wittmann, Dolan, & Düzel, 2011; Wittmann et al., 2005), probabilistic (Delgado, Miller, Inati, & Phelps, 2005; Galvan et al., 2005), and procedural learning (Abe et al., 2011; Freedberg, Schacherer, & Hazeltine, 2016; Wachter, Lungu, Liu, Willingham, & Ashe, 2009).
A wealth of evidence has demonstrated the basal ganglia’s essential role in feedback-related learning (Aron et al., 2004; Ashby, Noble, Filoteo, Waldron, & Ell, 2003; Bellebaum, Koch, Schwarz, & Daum, 2008; Knowlton, Mangels, & Squire, 1996; Palminteri et al., 2011; Poldrack et al., 2001; Shohamy, Myers, Onlaor, & Gluck, 2004; Shohamy, Myers, Grossman, et al., 2004), and reward processing (Apicella, Ljungberg, Scarnati, & Schultz, 1991; Delgado et al., 2005; Galvan et al., 2005; McClure, York, & Montague, 2004; Samanez-Larkin et al., 2007; Wachter et al., 2009). Evidence from neuroimaging studies demonstrate activation of the striatum during feedback-dependent learning (Aron et al., 2004; R. A. Poldrack et al., 2001; R. Poldrack, Prabhakaran, Seger, & Gabrieli, 1999), so it is not surprising that patients with Parkinson’s disease (PD) who experience basal ganglia dysfunction as a result of dopamine neuron loss (Agid, 1991; Agid, Javoy-Agid, & Ruberg, 1987; Hornykiewicz, 1966) experience feedback learning deficits (Ashby et al., 2003; Cools, Barker, Sahakian, & Robbins, 2001; Foerde, Race, Verfaellie, & Shohamy, 2013; Knowlton et al., 1996; D. Shohamy, Myers, Onlaor, et al., 2004; Swainson et al., 2000). Interestingly, despite the feedback-learning deficits exhibited by patients with PD, three recent studies have demonstrated that PD patients are able to learn from reward just as well or better than healthy controls (HCs) when taking their usual antiparkinsonian medication (Bódi et al., 2009; Frank et al., 2004; Palminteri et al., 2009).
Although these studies demonstrate that patients can learn to select responses that lead to reward just as well or better than healthy controls (HCs), it is unclear whether reward can improve learning in patients with PD beyond simply providing feedback as to whether the response was correct. This issue has not been resolved because, thus far, the reward aspect of feedback has not been dissociated from the information necessary to learn the task. In other words, in studies showing comparable learning between medicated patients with PD and HCs (Bódi et al., 2009; Frank et al., 2004; Palminteri et al., 2009) the reward also served as the task-relevant information needed to perform the task accurately; there was no distinction between informing the participants that responses were correct and rewarding them. For example, Bódi and colleagues (2009) consistently presented “+25” as feedback when participants correctly categorized a stimulus and presented no feedback when an incorrect response was selected. Thus, because the reward also signaled that the task had been performed correctly, and because a reward condition was not contrasted with one in which feedback was given without reward, it is difficult to tell whether learning from reward was different from learning only from corrective feedback.
A second complication with studying the effect of reward on learning in any population is that it can be difficult to tease apart from incentive learning. In other words, in many cases, it is difficult to determine whether reward directly improves learning processes by “stamping in” stimulus-response (S-R) associations (such as the dopamine hypothesis of reinforcement; Wise, 2004), or reward enhances motivational processes, which consequently improves S-R binding. Several imaging studies have shown that the striatum responds to rewards (Delgado et al., 2005; Galvan et al., 2005; Wachter et al., 2009); however, only a few studies have attempted to dissociate the motivational and reinforcing effects of reward (e.g., Miller, Shankar, Knutson, & McClure, 2014; Robinson & Flagel, 2009). Untangling this dissociation in Parkinson’s patients has not been attempted to our knowledge, so it is possible that the results of previous studies of medicated PD patients can also be explained indirectly by the motivational influence of reward on learning rather than by reward’s direct influence on learning.
The objective of the current study is to determine whether reward can improve incidental learning in medicated patients with PD. Incidental learning is akin to procedural learning in that it occurs through task repetition but emerges without intention. Here, we used a task (Freedberg et al., 2016) that allows us to compare the performance of rewarded and unrewarded S-R associations across training and a transfer phase where rewards are no longer present. In the task, participants learn to produce responses to pairs of stimuli. While participants receive feedback on their performance of every pair, only half of the pairs provide reward when the responses are correct. Thus, because the reward is task irrelevant and only available for half of the S-R associations, we can examine the effect of reward separate from the effect of corrective feedback. Additionally, because participants generally do not gain awareness of which pairs were rewarded, and thus are rarely certain whether each trial is rewarded or not, we are able to minimize (but not abolish) the motivational influence of reward to better understand the reinforcing role of reward on learning. Because PD is associated with procedural and feedback learning deficits (Ashby et al., 2003; Cools et al., 2001; Foerde et al., 2013; Knowlton et al., 1996; Muslimović, Post, Speelman, & Schmand, 2007; D. Shohamy, Myers, Onlaor, et al., 2004; Swainson et al., 2000), we hypothesized that HCs would demonstrate significantly stronger learning of rewarded S-R pairs compared to unrewarded S-R pairs, but that PD patients would benefit less from reward. Because we were interested in studying PD patients under circumstances related to their daily functioning and because medicated patients have been shown to demonstrate comparable reward-related learning to HCs (Bódi et al., 2009; Frank et al., 2004; Palminteri et al., 2009), we studied patients while on their usual antiparkinsonian medications.
Additionally, we measured skin-conductance responses (SCRs) to (1) determine whether our patients and controls display a physiological biomarker related to the effect of reward on learning and (2) determine whether SCRs correlate with the effect of reward on learning. Previous work has shown that participants experience autonomic arousal, in elevated SCRs and increased pupil dilation, during response uncertainty, or when errors are committed (Critchley, Tang, Glaser, Butterworth, & Dolan, 2005; Harding & Punzo, 1971). Furthermore, SCR magnitudes are positively correlated with activation of areas of the brain associated with conflict monitoring, such as the anterior cingulate cortex (Botvinick, Braver, Barch, Carter, & Cohen, 2001; Critchley, Mathias, & Dolan, 2001) and SCRs are elevated for risky (over nonrisky) decisions in healthy individuals (Bechara, Damasio, Tranel, & Damasio, 1997). Because we expected stronger associations for rewarded pairs than pairs not linked to rewards, thus reducing response uncertainty, we predicted that healthy controls (HCs) would exhibit significantly larger SCRs to unrewarded pairs relative to rewarded pairs and that patients with PD would show no significant difference in SCRs between pairs.
Method
Participants
Thirty-six participants provided written consent in accordance with the University of Iowa’s Intuitional Review Board (IRB). Of the 36 participants, 17 were diagnosed with PD, and 19 were healthy older adults with no known neurological or orthopedic disease (HCs). All patients were tested while on their usual course of antiparkinsonian medication. Three HCs and one PD patient were excluded for achieving perfect accuracy during transfer, indicating that they had achieved explicit knowledge of the rules.Footnote 1 We assume this knowledge taps a separate system from the incidental learning mechanisms we intend to study. Therefore, we compared the performance of 16 HCs (mean age = 65.44 ± 0.56 years) and 16 PD patients (mean age = 67.38 ± 1.56 years; see Table 1). Three patients and one HC were left-handed.
Patients with Parkinson’s disease
Patients with PD were recruited from the eastern Iowa area. All patients lived independently and were being treated with dopaminergic medications. All patients were on dopaminergic treatment at the time of testing. Of the 16 patients, 15 of them were on levodopa treatment, 10 of them were taking dopamine agonists (five were prescribed Ropinirole and five were prescribed Pramipexole), and nine were taking both dopamine and levodopa agonists. Patients with PD were matched with older adults in terms of age and education. Two patients were also prescribed either Citalopram or Clonazepam to treat depression or anxiety. A neurologist with expertise in Parkinson’s disease (NN) administered Part 3 (motor examination) of the Unified Parkinson’s Disease Rating Scale (UPDRS) to each patient. All procedures occurred between 9 and 11 a.m., and all patients took medication as usual and were in the ON phase.
Neuropsychological and motor testing (Table 1)
All participants were tested on a battery of neuropsychological measures including tests of executive function (Trail-Making Test; Reitan, 1958) working memory (Digit Span, Forwards and Backwards), a broad cognitive assessment (the Montreal Cognitive Assessment [MOCA]; Nasreddine et al., 2005), and long-term memory (Rey-Auditory Verbal Learning Task; Rey, 1964). All participants were screened with the Beck’s Anxiety and Depression Inventories (BDI/BAI; Beck, Ward, & Mendelson, 1961; Beck, Steer, & Carbin, 1988), and the Near Visual Acuity (NVA) test. No participants met the threshold for moderate or severe depression or anxiety (one participant’s anxiety index data was unusable because it was filled out incorrectly). All participants had better than 20/50 near visual acuity. Patient and HC scores did not differ on the MOCA, t(30) = 0, p = 1. Patients and HCs differed statistically on three measures: (1) long-term memory, t(30) = 2.50, p < .05; items recalled, HCs: 11.13 ± 0.67, PD: 8.50 ± 0.86, (2) depression, t(30) = 2.02, p = .05; higher scores indicate higher depressive symptoms, HCs: 3.50 ± 0.79, PD: 6.06 ± 1.05, and (3) motor function, t(30) = 2.91, p < .01; higher scores indicate better motor function, HC: 103.63 ± 4.49, PD: 88.00 ± 3.36. No other tests revealed cognitive differences between groups. In addition, we also contrasted the personality traits of reward responsiveness, drive, and sensation seeking between groups using the Behavioral Inhibition System/Behavioral Avoidance System scale (BIS/BAS; Carver & White, 1994; see Table 1). No trait differences were detected between groups.
Apparatus and stimuli
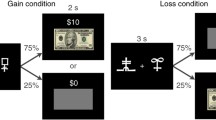
The experiment was implemented using E-Prime 2.0 software (Psychology Software Tools Inc., Sharpsburg, PA). Participants responded with their right index and middle fingers to stimuli presented on a 19-inch computer monitor using the two leftmost buttons on a serial response box. The visual stimuli consisted of eight faces of Caucasian males on a gray background. We used faces from one race of people to discourage chunking strategies. Caucasian faces were used because the majority of research participants at the University of Iowa are also Caucasian, and we did not want some faces to have more salient visual differences than others. Each stimulus was 2 degrees wide and appeared 1.87 degrees to the left and right of the fixation cross (1 deg. × 1 deg.). Four of the face pairs were mapped to the left button (Key 1, index finger) and four pairs were mapped to the right button (Key 2, middle finger; see Fig. 1, left panel). The remaining eight pairs were not presented. Each individual stimulus belonged to a pair mapped to Key 1 and a pair mapped to Key 2, so the individual stimuli were uncorrelated with the correct response. In addition, two of the pairs that were mapped to the left and right keys were linked to monetary rewards, while the other two pairs were never rewarded. The pairs were chosen so that each individual face stimulus belonged to a rewarded pair and an unrewarded pair, so individual stimuli were uncorrelated with reward. Moreover, half of the pairs linked to the left button and half of the pairs linked to the right button were rewarded. Rewarded pairs were counterbalanced across participants (see Fig. 1, left panel). The side of the screen that each stimulus appeared was also counterbalanced across participants. In this way, across participants we counterbalanced which stimulus pairs were rewarded (two groups), which stimulus pairs were withheld from training (two groups), the mapping of stimulus pairs to keys (two groups), and the laterality of stimuli on the screen (two groups). Thus, a complete set of participants equals 16 participants (24 = 16).

Left panel: Example training set. Each box indicates the correct keypress for each pair of faces and whether the pair was linked to a reward. Blank boxes represent pairs not used in the experiment. Right panel: Trial sequence for rewarded and unrewarded pairs during training
Procedure
Participants were instructed to respond as accurately as possible. They first performed a practice block of 50 trials in order to become accustomed to the task. Two stimuli were presented, and participants made one response (with either the right index or middle finger). Participants had 5 seconds to make their responses or the trial was counted as incorrect. Immediately after a response was made, the stimuli were extinguished and feedback was provided. If the participant responded correctly, the word “Correct” appeared below the stimuli for 1,000 ms in green text. If the participant responded incorrectly or did not respond within the 5,000 ms time limit, the words “Incorrect Response” appeared below the stimuli for 2000 ms in red text. The intertrial interval was 1,000 ms.
The rationale for providing 1,000 ms of feedback for correct trials and 2,000 ms of feedback for incorrect trials was to create a contrast between incorrect trials and unrewarded trials so participants had adequate time to process the feedback and could distinguish between being incorrect and being correct but unrewarded. Note that no behavioral measures (RT, accuracy, response switching) differed between groups when contrasting trials after errors and after no errors and that the amount of errors did not differ significantly between groups across training.Footnote 2
Following the practice block, participants were again presented with the same pairs of stimuli and were instructed to continue to learn the corresponding key presses. Participants were also instructed that accurate trials would either be rewarded with money or not, and that inaccurate trials would not be rewarded. A critical goal of the experiment was to prevent participants from gaining awareness of which pairs were rewarded and which were not. The rationale for this approach is that we are interested in the role of reward as a direct reinforcer of learning and not reward’s usefulness as a motivational tool (see Freedberg et al., 2016). Thus, we intermixed rewarded and unrewarded pairs randomly throughout training. In this way, participants were not certain that the current trial was rewarded.Footnote 3 Additionally, participants were not instructed to focus on learning either rewarded or unrewarded pairs. For correct responses, half of the pairs were consistently rewarded when the response was correct and half were never rewarded, but participants were not given this information. Even when no reward was given, participants were consistently given feedback as to whether their response was correct.
Rewards ranged from 10¢ and 40¢ on rewarded trials, with the actual value of the reward determined randomly on a trial-by-trial basis. The rewards (when presented) were presented immediately below the stimuli in the center of the screen in green text on a black background for 1,000 ms. Unrewarded pairs were followed by the presentation of “+$0.00” in gray text on a black background for 1,000 ms (see Fig. 1, right panel) if performed accurately. All incorrect responses were followed by the presentation of the words “Incorrect Response,” without rewards, in red text for 2,000 ms.
Each of the eight training blocks contained 30 trials. With four left-side stimuli and four right-side stimuli, there were 16 possible pairs, although only eight pairs were used for each participant. The assignments of rewards to pairs were done in such a way so that each individual stimulus belonged to one rewarded pair and one unrewarded pair. Thus, individual stimuli were completely uninformative as to whether a reward would be given for a correct response (see Fig. 1, left panel).
Completion of the training blocks was followed by one 50-trial transfer block after a short delay of 5 minutes. The transfer block was similar to the training blocks, except that feedback was not provided but was replaced with 1000 ms of a black screen, and the stimuli were not extinguished after the response was made. Electrodermal activity (EDA) was monitored at 1000 Hz during the transfer phase of the experiment using Ag-AgCl electrodes that were attached to the thenar and hypothenar eminences of the left palm of each participant (all participants responded manually with their right hand). The EDA recording was acquired via an MP150 system (BIOPAC Systems) and by AcqKnowledge 3.91 software for Windows. The recording of EDA was continuous. EDA data were time locked to the onset of the stimuli for both previously rewarded and unrewarded pairs and lasted 6,000 ms. These data were used to compute SCRs (see Statistical analysis section).
Explicit knowledge questionnaire
Following completion of the task, a questionnaire assessing explicit knowledge of the pair–reward relationships was administered. Participants first reported their ability to predict when rewards were given by responding to the question “How confident were you in your ability to predict when would receive rewards?” on a Likert scale from 0 (not confident at all) to 9 (completely confident). These scores were transformed by dividing by 9 so they ranged from 0 to 1. Next, each of the rewarded and unrewarded pairs from training was presented, and participants were asked to determine if the pair was followed by a reward. Participants’ recall accuracy was scored. We then calculated a composite awareness score by summing these two scales (self-reported confidence and recall), which ranged from 0 to 2 (higher scores indicate higher awareness). The rationale for combining the two scales was to validate whether participants had gained explicit awareness of which pairs were rewarded. If a participant had gained awareness of which pairs were rewarded, they would presumably have high self-reported confidence (Part 1) and recall scores (Part 2). High scores on only one of these scales would indicate either that awareness was mostly implicit (a high recall score but a low self-reported confidence score) or that they were expressing pseudoawareness (high confidence but low recall accuracy). However, as part of our analysis we analyzed both parts of the questionnaire individually, and as a combined score (the composite measure).
Statistical analysis
Participants’ accuracies served as the main dependent variables. For the analysis of accuracy, trials were eliminated if (1) the stimulus pair was repeated from the previous trial (13.42%), (2) the RT was less than 300 ms or greater than 3,000 ms (10.83%). Overall, 23.2% of the data was eliminated for the analysis of accuracy. The number of trials excluded did not differ between groups, t(30) = 0.94, p = 0.35. Omitted responses occurred infrequently (a total of 34 times across all participants). The number of omitted responses did not differ between groups,t(30) = 0.01, p = .99. Because our accuracy data are proportional, they were submitted to an empirical logit transformation. Note that after logit transformation, chance performance would be indicated by a score of zero. For the analysis of RT, trials were eliminated if any of the above occurred and/or the trial was incorrect (40.22% of all trials), leaving 56.0% of the remaining data.Footnote 4
Training
Average RTs and accuracies were modeled across blocks using a linear model in which the slope parameter indexed the rate of learning across blocks. This model was fit to block-specific performance using R’s (R Development, 2010) linear mixed-effects (lme4) package (Pinheiro & Bates, 2000). Prior to modeling, block was centered so the intercept corresponded to the halfway point during training. The fixed effects of reward and group were effect coded (“1” for reward and “-1” for no reward; “1” for HCs, and “-1” for PD patients). Maximum likelihood was used to estimate all fixed and random effects simultaneously. The most complex model for each analysis included (1) fixed effects for block, reward, group, and all interactions and (2) random intercepts and slopes of the linear term and reward on participant. Chi-square model comparisons were performed to trim the most complex model but did not indicate the need to eliminate any random effects for accuracy; the most complex model was used to model accuracy, but the random reward slope on participant was removed from the RT model because it did not significantly improve the fit of the model. Fixed effects for the best fitting model were then interpreted as described in the results. Confidence intervals around parameter estimates are reported for all significant effects for modeling results using R’s “confint” function.
Transfer
To determine if reward affected learning differently between groups, we contrasted logit-transformed accuracies and RTs between group (HC vs. PD) and pair type (rewarded vs. unrewarded) using a pair of two-factor repeated-measures ANOVAs (rm-ANOVA). Where applicable, bootstrapped confidence intervals around effect sizes based on 10,000 simulations are reported using R’s bootES package (Kirby & Gerlanc, 2013). Confidence intervals are represented as either a Cohen’s d or Pearson’s R statistic.
Skin-conductance responses
To compute SCRs, EDA were processed using MATLAB (MathWorks, Natick, MA). Individual SCRs for each participant were first time locked to each stimulus presentation and separated by pair type (rewarded vs. unrewarded). Next, to reduce the influence of noise, a moving average of every 10 trials was applied to each trial. For each participant, rewarded and unrewarded trials were averaged separately to form two mean signals, one for each pair type. Next, the maximum change in amplitude of the averaged signal for each pair type was divided by that participant’s largest single trial SCR. This normalization procedure controlled for differences in SCR response between our two populations (HCs vs. patients). Finally, we log-transformed the data so that the final values were distributed normally (Levey, 1980).
At the group level, we conducted two ANOVAs. First, we analyzed the SCRs for correct and incorrect trials, and between groups. This analysis was conducted to confirm that response uncertainty elevates SCRs (Harding & Punzo, 1971). Second, we analyzed SCRs for correctly performed rewarded and unrewarded pairs, and between groups. Finally, we performed correlational analyses between the behavioral (accuracy) and physiological (SCRs) effects of reward.
Results
Training—RT
Figure 2 shows RTs across training for both groups (top panels). No effects of group, reward, or any significant interactions were detected.

Training results for Experiment 1. Solid bold lines represent model-fitted linear curves for rewarded and unrewarded pairs for RT (a, HC; b, PD) and accuracy (c, HC; d, PD) data. Dashed lines represent average observed data, and the shaded regions represent the SEMs for the observed data. Since the accuracy data are logit-transformed, zero on the y-axis represents chance performance
Training—Accuracy
By the last block of training, average accuracies for HCs were 63% for rewarded trials, and 64% for unrewarded trials, while accuracies for PD patients were 52% for rewarded trials and 61% for unrewarded trials. There was a significant linear slope, t(30) = 3.77, p < .001, d = 0.85, estimate = 0.06, 95% CI [0.03, 0.09], indicating that accuracy increased across training for both groups. No other effects or interactions were significant (see Fig. 2, bottom panels).
Transfer—RTs
Next, we analyzed RTs and accuracies from the transfer block to determine whether reward influenced learning differently between groups (see Fig. 3a–b). During transfer, participants performed the same eight pairs in the absence of any feedback. RT data were submitted to a two factor rm-ANOVA using group (HC vs. PD) and pair type (rewarded vs. unrewarded) as factors. The results of the rm-ANOVA revealed no significant main effects (Fs < 1) or interaction, F(1, 30) = 1.15, ns.

Transfer RTs (left panel) and logit transformed accuracies (right panel) for both groups for rewarded (black bars) and unrewarded pairs (gray bars). SEMs are denoted by the error bars. *p < .05. Since the accuracy data are logit-transformed, zero on the y-axis represents chance performance
Transfer—Accuracy
HCs were 76.6% accurate responding to rewarded pairs and 58.1% accurate responding to unrewarded pairs. PD patients were 53.6% accurate responding to rewarded pairs and 54.4% accurate responding to unrewarded pairs. The right panel of Fig. 3 plots the logit-transformed accuracies for both groups. The analysis of transfer accuracies revealed significant main effects of group, F(1, 30) = 6.91, p < .05, η 2 p = 0.19, d = 0.71, 95% CI [0.23, 1.18], and pair type, F(1, 30) = 5.07, p < .05, η 2 p = 0.15, d = 0.44, 95% CI [-0.06, 0.93]. These effects indicate higher accuracy for rewarded pairs over unrewarded pairs, and for HCs over PD patients. In addition, we detected a significant interaction between group and pair type, F(1, 30) = 7.97, p < .01, η 2 p = 0.21, d = 0.87, 95% CI [0.19, 1.47], indicating that HCs benefitted significantly more from reward than PD patients. This effect is also significant when excluding the patients taking Citalopram and Clonazepam, F(1, 28) = 4.37, p < .05, η 2 p = 0.14, d = 0.76, 95% CI [0.06, 1.37]. To determine if our results were driven by any group differences identified in our cognitive battery (e.g., long-term memory, motor function, depressive symptoms), we conducted three separate ANCOVAs using group and pair type as factors. Our rationale for centering around each group mean is that centering around a grand mean is problematic when sample sizes are small and there are significant group differences with respect to the covariate. Specifically, the assumption of linearity of the covariate between groups may be violated (G. Chen, 2014; G. Chen, Adleman, Saad, Leibenluft, & Cox, 2014). Therefore, for each ANCOVA, covariates were centered around group means prior to analysis. In all cases, the covariate did not interact with the effect of reward.
When long-term memory scores (amount of items recalled after a 30-minute delay) were used as a covariate, the ANCOVA revealed a significant effect of group, F(1, 29) = 6.68, p < .05, η 2 p = 0.19], reward, F(1, 29) = 5.02, p < .05, η 2 p = 0.15, and a significant interaction, F(1, 29) = 5.93, p < .05, η 2 p = 0.17. Post hoc results revealed a significant difference between logit-transformed accuracy results for HCs on rewarded trials and all other comparisons (ps < .05). No other comparisons were significant. Long-term memory scores did not correlate with the effect of reward on transfer accuracies for HCs, r(14) = -.29, ns, or PD patients, r(14) = -.04, ns, and correlations between groups did not differ (Z = -0.66, p = .51).
When finger-tapping scores (the number of finger taps produced in 20 seconds) were used as a covariate, the ANCOVA revealed a significant effect of group, F(1, 29) = 8.18, p < 0.01, η 2 p = 0.22, reward, F(1, 29) = 4.93, p < .05, η 2 p = 0.15, and a significant interaction, F(1, 29) = 5.82, p < .05, η 2 p = 0.17. Post hoc results were similar to the previous analysis. Finger-tapping scores did not correlate with the effect of reward on transfer accuracies for HCs, r(14) = .18, ns, or PD patients, r(14) = -.09, ns, and correlations between groups did not differ (Z = -0.23, p = .82).
When Beck’s depression scores were used as a covariate, the ANCOVA revealed a significant effect of group, F(1, 29) = 7.44, p < .05, η 2 p = 0.20, reward, F(1, 29) = 5.05, p < .05, η 2 p = 0.15, and a significant interaction, F(1, 29) = 5.97, p < .05, η 2 p = 0.17. Post hoc analyses yielded similar results to the previous analyses. Depression scores did not correlate with the effect of reward on transfer accuracies for HCs, r(14) = -.16, ns, or PD patients, r(14) = -.19, ns, and correlations between groups did not differ (Z = -0.08, p = 0.94).
In sum, including these factors as covariates in separate ANCOVAs did not reduce the significant interaction between group and the effect of reward. Thus, we found no evidence that long-term memory, depression symptoms, and motor function differences between groups were responsible for the reduced effect of reward on learning in medicated patients with PD.Footnote 5
Median-split analysis
Although HCs achieved accuracies well above 50%, t(15) = 3.96, p < .005, the same was not true for PD patients, t(15) = 1.01, p = .33. An interesting note is that several PD patients experienced transfer accuracies well below 50% (e.g., 46%, 33%, 34%, 33%, and 40%) while only two HCs performed below 50% (40%, 35%). Note that to achieve these scores, it is possible that patients consistently performed some pairs wrong by committing errors of perseverance. In fact, the absolute value of the difference from chance is significantly different from chance for PD patients, t(15) = 6.06, p < .001.
To examine this further, we performed a median-split analysis on both groups, dividing the participants into high and low accuracy subgroups based on the overall median transfer accuracy. Figure 4 indicates the reward effect (logit-transformed accuracy on rewarded trials minus logit transformed accuracy on unrewarded trials) of each group (HC vs. PD) and subgroup (high vs. low within-group accuracy). Note that since these data are logit-transformed, a score of zero in this figure represents no reward effect. Overall accuracy scores for each subgroup are indicated above each bar. While HCs experienced large reward effects regardless of subgroup, patients in both subgroups experienced noticeably smaller reward effects. To confirm this impression, we submitted reward effect scores to an ANOVA using group and subgroup (high vs. low accuracy) as factors. This analysis revealed a significant effect of group, F (1, 28) = 5.12, p < .05, η 2 p = 0.15, d = 0.87, 95% CI [0.21, 1.47], no effect of subgroup, F(1, 28) = 0.002, p = .96, and no interaction, F(1, 28) = 0.98, p = .33, indicating that the reward effect for HCs was significantly larger than for PD patients independent of overall accuracy. Thus, even the PD patients who achieved accuracies well above chance, t(7) = 4.10, p < .001, experienced a significantly smaller reward effect compared to HCs.Footnote 6

Reward effect (logit-transformed accuracy on rewarded pairs minus logit-transformed accuracy on unrewarded pairs) is plotted as a function of group (PD vs. HC) and subgroup (high vs. low accuracy). Subgroups were divided based on a median-split of overall transfer accuracy within each group (HC vs. PD). Figures above each bar represent the overall accuracy scores (not logit-transformed) for that subgroup. SEMs are denoted by the error bars. Since the reward effect data are logit-transformed, zero on the y-axis represents no reward effect
Transfer—SCRs
During transfer, SCRs were measured for both groups and both pair types. We hypothesized that higher accuracies for rewarded pairs would be associated with lower SCRs compared to unrewarded pairs. Data from three healthy participants were either corrupt or were unable to be collected. Overall, we compared the physiological response of 16 patients and 14 HCs.
First, to confirm that response uncertainty elevates SCRs, we contrasted SCRs for accurate and inaccurately performed trials and between groups using a mixed-effects ANOVA. These data are shown in Fig. 5. The results of the ANOVA revealed a significant main effect of accuracy, F(1, 28) = 10.89, p < .005, η 2 p = 0.28, d = 0.59, 95% CI [0.03, 1.10], and a marginally significant interaction between group and accuracy, F(1, 28) = 3.1, p = .09, η 2 p = 0.10, but no main effect of group (F < 1). Post hoc t tests revealed significant differences between accurate and inaccurate trials for both HCs, t(13) = 2.6, p < .05, d = 0.95, 95% CI [0.10, 1.73] and PD patients, t(15) = 2.6, p < .05, d = 0.28, 95% CI [-0.47, 1.00]. These results indicate that both groups experienced significantly smaller SCRs for correct trials compared to incorrect trials (see Fig. 5).

Peak SCR responses for HCs and PD patients. Correct trials (black bars) were associated with lower SCR responses compared to incorrect trials (gray bars) for both groups. *p < .05
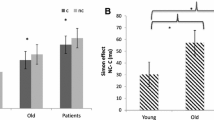
Next, these data were analyzed similar to the behavioral data measured during transfer using a rm-ANOVA. The results revealed no main effect of pair type, F(1, 28) = 2.2, p = .15, group, F(1, 28) = 1.7, p = .20, and no interaction (F < 1; see Fig. 6, Panel A). Although the interaction was not significant, we were interested in whether SCR magnitudes were lower for rewarded pairs within each group. Thus, we conducted an exploratory within-group analysis on SCRs between pair types. HCs experienced larger peak SCRs for unrewarded pairs, t(13) = 2.62, p < .05, d = 0.77, 95% CI [0.01, 1.53], while PD patients did not, t(15) = 0.16, ns. Although we did not identify a significant interaction, which would have indicated a comparatively smaller effect of reward on SCRs for PD patients, these data suggest that HCs experienced a stronger physiological response while performing unrewarded pairs compared to rewarded pairs but that PD patients did not.

a Average peak SCRs for HCs and PD patients, separated for rewarded (black) and unrewarded (gray) pairs. b Correlations between the effect of reward on learning and the effect of reward on SCR magnitudes for HCs (black) and PD patients (gray). *p < .05
Finally, we investigated whether the effect of reward on transfer accuracies (rewarded accuracy – unrewarded accuracy) was associated with the effect of reward on peak SCRs (unrewarded SCRs – rewarded SCRs). Thus, we wanted to determine if lower accuracy on unrewarded trials was associated with greater SCRs for unrewarded trials. The analysis revealed a significant correlation across groups, r(28) = .43, p < .05, 95% CI [0.05, 0.71]. However, a within-groups analysis revealed that this correlation was significant for HCs, r(12) = .59, p < .05, 95% CI [0.11, 0.85], and not patients with PD, r(14) = .27, ns (see Fig. 6, Panel B). The correlation between the behavioral and physiological effect of reward was not statistically different between groups (Z = 1.02, p = .30). In sum, patients with PD were not able to distinguish rewarded pairs from unrewarded pairs both behaviorally and physiologically, in contrast to the HCs.Footnote 7
Questionnaire
To test whether participants gained explicit awareness of which pairs were rewarded, we analyzed participants’ responses on the postexperiment questionnaire. The average self-reported awareness of the pair–reward relationship was 0.22 ± 0.06, where zero indicates no awareness and one indicates full awareness of which pairs were rewarded. Self-reported confidence scores differed between groups, t(31) = 2.31, p < .05, d = 0.82, d = 0.82, 95% CI [0.15, 1.52], indicating that HCs (0.31) reported higher subjective confidence than PD patients (0.13), although both groups demonstrated very low confidence (<50%; see Fig. 7). The mean recall score was 0.47 (SD = 0.17), which did not differ significantly from chance for all participants (Z = -0.15, ns), or each group separately (HCs: Z = -0.32, ns; PD: Z = 0.02, ns). Self-reported awareness and recall did not correlate significantly with each other, r(26) = .08, ns.Footnote 8 We summed these two scores to form a composite index of each participant’s awareness and averaged each group’s scores. No significant difference was detected between groups in terms of composite score, t(31) = 1.12, ns. No significant correlation was revealed between all participants’ composite awareness scores and the effect of reward on transfer accuracies, r(26) = .03, ns, suggesting that awareness had very little influence on the reward effect we observed at transfer. However, a significant negative correlation was detected between composite awareness scores and the effect of reward on accuracies at transfer for PD patients, r(14) = -.55, 95% CI [-0.80, -0.18], p < .05, but not HCs, r(14) = .24, p = .38 (see Fig. 8). The correlation between composite awareness scores and the effect of reward on transfer accuracies were significantly different between groups (Z = 2.16, p < .05), indicating that the negative correlation between awareness and the effect of reward was significantly stronger for PD patients.

Results of the postexperiment questionnaire for HCs (black bars) and PD patients (gray bars). Dashed lines represent the maximum score for self-reported confidence and recall (1.0), and the composite measure (2.0). SEMs are denoted by the error bars. A significant difference was detected between groups for self-reported confidence, t(31) = 231, p < .005, d = 082. *p < .05

Correlations between composite awareness and the effect of reward on learning scores for HCs (black) and PD patients (gray). PDs, but not HCs, demonstrated a significant negative relationship between awareness and the effect of reward on learning
We also performed the same analysis for each awareness score separately (self-report and recall). Self-reported confidence did not correlate significantly with the behavioral effect of reward at transfer, r(30) = .26, ns. No significant correlation was detected between recall scores and the behavioral effect of reward at transfer, r(26) = -.29, p = .10. However, within-groups correlational analyses revealed a significant negative correlation between recall and the effect of reward on transfer accuracies for PD patients, r(12) = -.68, p < .005, 95% CI [-0.82, -0.37], but not HCs, r(12) = 0.13, p = .62. The correlation between recall scores and the effect of reward on transfer accuracies were significantly different between groups (Z = 2.45, p < .05). To assess whether group interacted with the correlation between recall and the effect of reward transfer accuracies, we performed a hierarchical linear regression. The first step of the model included group and recall as predictors, and the second step added the interaction. The interaction significantly improved the fit of the model, F(1, 28) = 5.62, p < .05, and the interaction coefficient was significant (p < .05). Because PD patients had low awareness scores in general, it appears that attempting to learn explicitly which pairs were rewarded may have hindered the benefit of reward on incidental learning (see Fig. 8).
Finally, we asked whether our awareness scores were related to the effect of reward on SCRs. Across both groups, no significant correlations were detected between any of our awareness measures and the effect of reward on SCRs (ps > .29). No significant correlations between awareness and SCRs were identified for HCs (ps > .50) or PD patients (ps > .15). The correlation between composite awareness and the effect of reward on SCRs was not statistically different between groups (Z = -0.78).
In sum, we determined that (1) awareness for both groups was low, (2) awareness scores did not differ significantly between groups (with the exception that HCs had significantly higher self-reported confidence in their ability to discriminate between rewarded and unrewarded pairs), and (3) for PD patients, the effect of reward on learning was negatively correlated with recall scores.
Item-level analysis
It is possible that the reason PD patients did not benefit from reward is because they unable to learn the S-R associations. Indeed, Parkinson’s patients as a group did not achieve performance above chance at transfer, t(15) = 1.01, p = .33, contrary to HCs, t(15) = 3.96, p < .005. Although accuracy analyses are able to indicate whether participants’ performance differed from chance overall, these analyses are unable to indicate whether participants learned specific pairs. To determine if participants learned specific pairs, we performed an item-level analysis. First, we calculated a Z score for every item performed using a binomial test against chance (50%). The Z score was calculated using the following equation (as in Wasserman, Brooks, & McMurray, 2015):
where P equals the average accuracy for each pair performed during transfer and N equals the number of times that pair was performed during transfer. Thus, a pair performed accurately 4 out of 5 times would yield a Z score of 1.68. The Z score was then transformed into a p value, and if the p value was below 0.00625 (corrected for multiple comparisons; α = 0.05/8), then we concluded that the item was performed significantly above chance and was labeled as learned. Finally, we contrasted the number of items learned between groups (PD vs. HC) and within groups (rewarded vs. unrewarded) using nonparametric tests. Our results reveal that HCs learned 3.6 items on average, and PD patients learned 1.8 items, which was statistically different (U = 57.00, p < .01, r = .48). The number of rewarded and unrewarded items learned did not differ between rewarded and unrewarded pairs for both groups, HCs: Z = -1.67, p = .09; PD: Z = -0.54, p = .59 (see Fig. 9). Thus, although both groups learned individual items, reward did not improve the number of items learned for either group.

Number of items learned for HCs and PD patients. Maximum number of pairs that participants can learn for each pair type is four
Discussion
We examined rewarded learning in HCs and medicated patients with PD on an incidental learning task where the informative (e.g., corrective) aspect of feedback was separated from the effect of reward. We found that during training accuracies increased for both groups, but no effect of reward or group was found. Nevertheless, we assessed learning between groups and between pair types immediately after training during a single transfer block. Here, participants responded without feedback, and SCRs were measured. We hypothesized that while HCs would learn rewarded pairs significantly stronger than unrewarded pairs, this effect would be smaller in PD patients. Additionally, because we expected HCs to encode rewarded pairs significantly stronger than unrewarded pairs, we predicted that SCRs would be significantly smaller for rewarded pairs compared to unrewarded pairs, reflecting higher response uncertainty for unrewarded trials. HCs demonstrated significantly higher accuracies for rewarded pairs over unrewarded pairs compared to patients with PD. Our physiological data confirmed that both groups showed elevated SCRs for incorrect trials over correct trials, which supports prior research demonstrating elevated autonomic activity during response uncertainty (Critchley et al., 2005; Harding & Punzo, 1971). Although we did not observe a significant interaction between group and pair type, our exploratory within-group analyses suggest that for HCs, but not in PD patients, SCRs were significantly higher for unrewarded pairs compared to rewarded pairs. For HCs, there was a significant correlation between the behavioral reward effect (greater accuracy for rewarded pairs compared to unrewarded pairs) and the reward effect on SCRs (greater SCRs for unrewarded pairs compared to rewarded pairs); stronger learning of rewarded pairs was associated with smaller SCRs. Thus, for HCs the behavioral reward effect was related to the physiological SCR reward effect. In sum, we conclude that medicated patients with PD experience a significantly reduced benefit of reward during incidental learning relative to HCs.
Both groups demonstrated little awareness of which pairs were rewarded. PD patients, however, demonstrated a strong negative association between recall scores (the ability to identify rewarded and unrewarded pairs) and the behavioral reward effect. This suggests that PD patients may have engaged an explicit learning strategy in order to learn the relationship between a given pair and whether that pair is rewarded, and that this resulted in a reduced benefit of reward on accuracies. This is consistent with findings from other groups demonstrating the engagement of suboptimal learning strategies by patients with PD (D. Shohamy, Myers, Onlaor, et al., 2004). Although this finding was unexpected, a potential explanation is that PD patients either paid more attention to which pairs were rewarded and which ones were not, or compensated by engaging an explicit learning strategy (D. Shohamy, Myers, Onlaor, et al., 2004). Indeed, several of the PD patients that guessed above chance on the recall portion of the questionnaire showed a lower reward effect than those who performed at or below chance on the recall portion of the questionnaire (see Fig. 8).
Comparison to previous studies of reward and Parkinson’s disease
In contrast to previous studies (Bódi et al., 2009; Frank et al., 2004; Palminteri et al., 2009), our results demonstrate a reduced effect of reward in medicated patients with Parkinson’s disease. We note two key differences between our study designs. First, in our study, reward was distinct from corrective feedback; because reward was only available on 50% of trials and only if a correct response was made, we were able to distinguish learning from reward and learning from corrective feedback. Second, we were able to confirm that participants remained agnostic to our reward contingencies in a postexperiment questionnaire. Thus, it is unlikely that motivational differences prior to the performance of rewarded and unrewarded pairs caused our pattern of results. However, because we did not include a condition in which no reward was given, we cannot exclude motivational differences between groups as a potential contributor. In fact, based on recent findings (Muhammed et al., 2016), it is possible that depression and/or apathy modulates reward-related learning in patients with PD.
Several studies have attempted to dissociate the motivational influence of reward from the expected value of reward and reveal their distinct neural substrates in healthy adults and in rats (Miller et al., 2014; Robinson & Flagel, 2009). For example, Miller and colleagues (2014) scanned participants while they performed a task where trial difficulty and the magnitude of potential rewards varied on each trial. Dorsal striatum activity scaled with increasing motivation (induced by higher task difficulty), and ventral striatum activity scaled with expected value (induced by higher reward magnitude). Note that in the early stages of Parkinson’s disease, the head of the caudate receives less dopamine due to midbrain dopamine neuron loss, while the ventral striatum is relatively spared from this damage (Frank, 2005; Kish, Shannak, & Hornykiewicz, 1988). This suggests that early damage in PD may underlie a reduced motivation to receive rewards. Because many of the patients in our study were in the early phase of the disease process, it is possible that their pattern of striatal damage also followed this progression. Thus, an interesting question is whether dorsal striatum damage impaired motivation to receive a reward in the current study.
One potential interpretation of our results is that patients with PD need a larger reward or more training on rewarded pairs in order to match the effect seen in controls. Indeed, PD patients match controls on feedback-based learning tasks with extended practice (Myers et al., 2003; D. Ã. Shohamy, Myers, Kalanithi, & Gluck, 2008) supporting the hypothesis that dopamine depletion slows gradual learning processes but does not abolish them. It may be the case, then, that extending training for patients with PD, or increasing the size of the reward, may reduce differences in the reward effect between PD patients and healthy older adults. Alternatively, the use of monetary rewards in our study may have induced an increased motivational effect that hurt reward learning in our patient group. For example, it may be the case that the prospect of reward elevated motivational processes and increased the pressure to receive a reward. In other words, the availability of reward may have caused PD patients to collapse under pressure. Support for this hypothesis comes from studies demonstrating impaired Iowa gambling task (IGT) performance and elevated impulsivity in medicated PD patients (Cools, Barker, Sahakian, & Robbins, 2003; Evens, Hoe, Biber, & Lueken, 2016). In our study, patients with PD experienced numerically faster response times during training compared to HCs. Although this effect was not significant, it is possible that impulsivity on each trial (in order to receive a reward faster) may have caused patients to “choke” under pressure.
In the current study, we used a feedback-based task where feedback was delivered immediately after a response was selected. Recent discoveries in the study of Parkinson’s disease point to potential ways to remediate the reward learning deficits we observed. First, it is well-established that the basal ganglia plays a critical role in feedback-based learning, but is not critical for observational learning, such as paired-associates learning (Cincotta & Seger, 2007; de Vries, Ulte, Zwitserlood, Szymanski, & Knecht, 2010; Delgado et al., 2005; Foerde & Shohamy, 2011b; Galvan et al., 2005; Knowlton et al., 1996; D. Shohamy, Myers, Grossman, et al., 2004; D. Shohamy, Myers, Onlaor, et al., 2004). For instance, PD patients are impaired on feedback-based learning tasks, but not on observational versions of the same task (Knowlton et al., 1996; Schmitt-Eliassen, Ferstl, Wiesner, Deuschl, & Witt, 2007; D. Shohamy, Myers, Grossman, et al., 2004). For PD patients, it may be possible to induce a reward effect by tailoring task demands to accommodate intact (declarative) learning processes. If this is the case, one would predict that, for PD patients, observational learning of rewarded associations would be greater than learning unrewarded associations. Second, feedback timing is critical for PD patients during feedback-based learning (Foerde et al., 2013; Foerde & Shohamy, 2011a, b); PD patients perform as well as controls on feedback-based tasks (e.g., the WPT) when feedback is delayed, but perform worse than controls when feedback is immediate (Foerde et al., 2013). Thus, a second potential way to induce a reward effect in patients with PD is to delay the timing of rewards. Under both circumstances (observational learning, learning with delayed feedback) it may be possible to induce a reward effect by engaging declarative memory systems that are spared in PD. For example, because the hippocampus is intact in PD and is innervated by dopaminergic afferents, this might be a viable neuronal path for selectively encoding rewarding information for PD patients.
Dopamine and learning
The role of dopamine in reward-related learning is well-established (Adcock et al., 2006; Apicella et al., 1991; J. Beeler, Daw, Frazier, & Zhuang, 2010; J. A. Beeler et al., 2010; Bódi et al., 2009; Fiorillo, 2013; Frank, 2005; Frank et al., 2004; Palminteri et al., 2009, 2011; Schultz, Dayan, & Montague, 1997; Wise, 2004). Although dopamine’s specific role in learning is not without controversy (Berridge, 2007; Flagel et al., 2011), several studies have provided support that reward can modulate learning through dopamine dynamics; levodopa causes elevated levels of dopamine in the striatum (Maruyama, Naoi, & Narabayashi, 1996; Robertson & Robertson, 1988), causing enhanced reward-related learning in patients with PD; in contrast, lower tonic dopamine levels in the striatum in nonmedicated patients results in poor reward learning and a greater ability to learn from punishments (Bódi et al., 2009; Frank et al., 2004; Palminteri et al., 2009). The explanation for the comparable learning between controls and medicated patients with PD is that levodopa medication raises dopamine to levels high enough so that phasic bursts of dopamine in response to reward can potentiate D1 receptor medium spiny neurons (MSNs) in the striatum (Frank, 2005; Frank et al., 2004). Why then, did we observe no benefit of reward for patients with PD?
In studies reporting that medicated PD patients showed greater or comparable learning with reward compared to controls (e.g. Bódi et al., 2009; Frank et al., 2004; Palminteri et al., 2009), particular stimuli were strongly associated with a particular response. For example, in Palminteri and colleagues’ (2009) study, consistently responding with one key press to a given stimulus resulted in optimal accumulation of rewards, and medicated patients with PD responded more often with the key that yielded rewards compared to adults without PD. However, in our experiment, participants had to learn the relationships between pairs of stimuli and responses, to which any individual stimulus was uninformative about the correct answer or the outcome (rewarded vs. unrewarded); information from both cues needed to be integrated to obtain optimal rewards. Thus, it may be that elevated dopamine levels are associated with a gain in action selection bias, and that selective dopamine neurotransmission in response to reward promotes selectively stronger encoding of rewarded associations. That is, elevated dopamine levels bias response selection processes to choose responses that lead to reward, whereas selective firing of dopamine neurons in response to rewarded associations causes stronger binding of those associations. In the present study, both responses were equally likely to be correct and rewarded at the same rate, so a response bias would result in chance performance. This could explain the differences in results between our study and previous studies (Bódi et al., 2009; Frank et al., 2004; Palminteri et al., 2009).
This possibility is supported by previous work examining learning in patients with PD using the weather prediction task (WPT), which like the task in the current study, requires the integration of information from multiple cues (Knowlton, Squire, & Gluck, 1994). During learning on the WPT, patients with PD demonstrate an impairment learning from multiple cues, and instead, rely on single cues (D. Shohamy, Myers, Onlaor, et al., 2004). It is possible that the patients in our study engaged a similar strategy by paying attention to only one stimulus, leading to suboptimal reward learning. Furthermore, the impairment of medicated PD patients on the WPT is not seen when patients withdraw from levodopa (Jahanshahi, Wilkinson, Gahir, Dharminda, & Lagnado, 2010), suggesting that elevated tonic dopamine levels may contribute to an increased reliance on single cue learning, or perhaps a failure to express reward-related learning in general (J. Beeler et al., 2010). Thus, it is possible that levodopa may increase the overreliance on single cue learning by increasing tonic dopamine levels, allowing patients to benefit from reward when a response bias to one cue is advantageous, but not when information from multiple cues are necessary to achieve the reward, as in the current study. However, it will be necessary to study patients withdrawn from levodopa medication to test this hypothesis.
Parkinson’s disease and learning
It has previously been reported that patients with PD have procedural learning (Muslimović et al., 2007; Siegert, Weatherall, & Bell, 2008) and feedback learning deficits (Ashby et al., 2003; Knowlton et al., 1996; D. Shohamy, Myers, Grossman, et al., 2004). Our work demonstrates no noticeable benefit of reward for patients with PD when separating the effect of reward and corrective feedback. If this is the case, then differences in the strength of the rewards may explain the variability in the results regarding procedural learning in patients with PD. For example, a study using a strong and salient reward (money) may result in stronger differences between patient and control groups than simple corrective feedback (e.g. “correct” or “incorrect”). Alternatively, it may be the case that medicated patients with PD require a stronger reward than controls in order to match their performance. Indeed, studies of learning in medicated patients with PD that use monetary rewards as feedback (Bódi et al., 2009; Frank et al., 2004; Palminteri et al., 2009) have observed more comparable results between groups than studies using only corrective feedback as rewards (Ashby et al., 2003; Jahanshahi et al., 2010; Knowlton et al., 1996; D. Shohamy, Myers, Onlaor, et al., 2004; Wilkinson, Lagnado, Quallo, & Jahanshahi, 2008).
PD is also associated with abnormal autonomic (Bowers et al., 2006; Dietz, Bradley, Okun, & Bowers, 2011) and emotional responses (Ariatti, Benuzzi, & Nichelli, 2008) that may have affected our pattern of SCRs. Interestingly, we found that PD patients responded differently to correctly performed pairs compared to incorrectly performed pairs, but responded similarly to correctly performed rewarded and unrewarded pairs. The former finding could reflect a functional sympathetic response in PD, whereas the inability to distinguish between rewarded and unrewarded pairs could reflect an emotional deficit (see Dietz et al., 2011).
Results related to differences between healthy adults and patients with PD must be interpreted with caution. First, while PD is typically considered to be a basal ganglia disorder, it is important to note that patients also experience deficits related to frontal lobe function (K.-H. Chen et al., 2016; Gotham, Brown, & Marsden, 1988; Parker, Chen, Kingyon, Cavanagh, & Narayanan, 2015). Although we did not identify working memory or executive function differences between groups in our experiment, it is possible that our results may be explained by the increased presence of dopamine in the prefrontal cortex due to levodopa treatment, which can sometimes impair cognitive processes in PD patients (Cools et al., 2001; Cools & D’Esposito, 2011; Gotham et al., 1988; Swainson et al., 2000). Second, PD patients as a group are not homogenous (Narayanan, Rodnitzy, & Uc, 2013), as they exhibit variability in the severity of cognitive, motor, and perceptual deficits. Thus, the patients we tested may have varied in terms of how reward benefitted learning, even though no effect of reward was detected. Finally, the dopamine signaling system is only one of several systems that are disrupted in PD, including the norepinephrine (Del Tredici & Braak, 2013; Vazey & Aston-Jones, 2012), cholinergic (Narayanan et al., 2013; Perry et al., 1985), and serotonergic systems (Kish, 2003). Thus, our results can potentially be explained by differences in the functioning and availability of these neurotransmitters. Further research will be needed to disambiguate whether one or more of these factors play a critical role in producing the deficits we observed in our study.
In the current experiment, we were limited by several factors. The first is that our sample size was small (as is the case with many patient studies). The second is that we were unable to verify that dopamine neurotransmission was indeed driving our effect. As mentioned above, several differences between patients and HCs can be driving our effect. Therefore, the results of this study must be interpreted carefully. Finally, our results are only generalizable to medicated patients with Parkinson’s disease. Future research will need to determine whether unmedicated patients experience the same reward dysfunction with respect to learning.
Conclusions
We tested healthy controls and patients with PD on an incidental learning paradigm in which the effect of reward was separated from the effect of corrective feedback on learning; half of the pairs were linked to rewards and half were not. Healthy controls experienced a stronger learning benefit of reward at transfer compared to patients with PD. In addition, HCs also experienced a larger SCR for unrewarded pairs at transfer compared to rewarded pairs, while PD patients experienced similar SCRs for the two pair types. For HCs, the behavioral benefit of reward at transfer (higher accuracies for rewarded pairs) was significantly associated with the SCR, demonstrating a link between the learning of rewarded pairs and the degree of their physiological response. These results demonstrate that patients with PD experience difficulty discriminating between rewarded and unrewarded information both behaviorally and physiologically, possibly associated with a critical role of the basal ganglia in the acquisition of rewarded information and additional abnormalities in emotional processing in PD.
Notes
Including these participants in our analysis did not change the pattern of our results.
A concern is that differences in the number of errors committed would lead to more spaced out trials between groups and lead to differences in the temporal dynamics of learning. To test this hypothesis, the count of incorrect trials across training were submitted to a two factor ANOVA using block, pair type (rewarded vs. unrewarded) and group as factors. We identified a significant effect of block, F(7, 210) = 2.47, p < .05, pair type, F(1, 30) = 4.32, p < .05, and a significant interaction between pair type and block, F(7, 210) = 2.13, p < .05. These results indicate that (1) Less errors were committed for rewarded pairs compared to unrewarded pairs, (2) less errors were committed later in training, and (3) less errors were committed for rewarded pairs over unrewarded pairs later in training. Because we identified no effect of group, and because group did not interact with the number of errors committed during training, this means that the amount of spacing between trials could not have been different between groups.
Introducing reward close in time to unrewarded pairs may have induced contextual effects that could potentially change the way that both groups approach unrewarded pairs. We therefore conducted additional analyses to determine whether receiving a reward on the previous trial resulted in difference in how each group performed on the current trial. If the context of reward impacts how participants learn from each pair, then participants should respond differently based on whether the previous trial was rewarded. To this end, we performed three separate ANOVAs to determine if the previous trial outcome affected next trial RTs, accuracy, and each group’s propensity to switch their response. In these analyses, previous trial outcome (rewarded or not rewarded), current trial type (rewarded or unrewarded) and group were used as factors. All three analyses yielded no significant group by previous trial outcomes. In addition, reward magnitude did not interact with our results. Thus, although we are unable to offer a comparison between rewarded and unrewarded contexts and their effect on learning, our sequential analyses do not offer support that our groups differed in their approach to learning when rewards were most salient (after receiving a reward on the previous trial).
To determine whether trials after errors significantly modulated our training results, we submitted our training data to a four-way ANOVA using previous trial accuracy (correct or incorrect), current trial pair type (rewarded vs. unrewarded), group, and training phase (first four blocks vs. last four blocks) as factors. Trials after rewards were eliminated from this analysis. This analysis revealed no significant group by previous trial accuracy interactions for RT or accuracy. Thus, because errors did not affect the groups differently during training, we included trials after errors in our analysis.
It is possible that PD patients might have learned less from rewards because of their impulsive responding to rewarded pairs during training. However, controlling for differences in RT between rewarded and unrewarded pairs during the last four blocks of training did not eliminate the interaction between group and reward on transfer accuracies, F(1, 29) = 5.1, p < .05, η 2 p = 0.150. No significant correlation between RT differences between rewarded and unrewarded pairs during the last four blocks of training and the effect of reward on learning during transfer was identified (p = 0.11).
In addition, we performed an additional ANCOVA to determine whether overall accuracy differences were contributing to our interaction. This ANCOVA revealed no effect of group, F(1, 29) = 105.78, p < .001, η 2 p = 0.78, an effect of reward, F(1, 29) = 4.92, p < .05, η 2 p = 0.15, and a significant interaction, F(1, 29) = 5.82, p < .05, η 2 p = 0.17. Post hoc results were similar to the previous ANCOVA analyses. Overall accuracy scores did not correlate with the effect of reward on transfer accuracies for HCs, r(14) = .01, ns, or PD patients, r(14) = .19, ns, and correlations between groups did not differ (Z = -0.46, p = .65). Thus, overall accuracy did not significantly contribute to the reward by group interaction.
This pattern of results is similar when excluding patients taking Citalopram and Clonazepam.
This correlation was not significantly different between groups (p = .76).
References
Abe, M., Schambra, H., Wassermann, E. M., Luckenbaugh, D., Schweighofer, N., & Cohen, L. G. (2011). Reward improves long-term retention of a motor memory through induction of offline memory gains. Current Biology, 21(7), 557–562. doi:10.1016/j.cub.2011.02.030
Adcock, R. A., Thangavel, A., Whitfield-Gabrieli, S., Knutson, B., & Gabrieli, J. D. E. (2006). Reward-motivated learning: Mesolimbic activation precedes memory formation. Neuron, 50(3), 507–517. doi:10.1016/j.neuron.2006.03.036
Agid, Y. (1991). Parkinson’s disease: Pathophysiology. The Lancet, 337(8753), 1321–1324. doi:10.1016/0140-6736(91)92989-F
Agid, Y., Javoy-Agid, F., & Ruberg, M. (1987). Biochemistry of neurotransmitters in Parkinson’s disease. Movement Disorders, 2(7), 166–230.
Anderson, B. A., Laurent, P. A., & Yantis, S. (2011). Value-driven attentional capture. Proceedings of the National Academy of Sciences of the United States of America, 108(25), 10367–10371. doi:10.1073/pnas.1104047108
Apicella, P., Ljungberg, T., Scarnati, E., & Schultz, W. (1991). Responses to reward in monkey dorsal and ventral striatum. Experimental Brain Research, 85(3), 491–500. doi:10.1007/BF00231732
Ariatti, A., Benuzzi, F., & Nichelli, P. (2008). Recognition of emotions from visual and prosodic cues in Parkinson’s disease. Neurological Sciences, 29(4), 219–227. doi:10.1007/s10072-008-0971-9
Aron, A. R., Shohamy, D., Clark, J., Myers, C., Gluck, M. A., & Poldrack, R. A. (2004). Human midbrain sensitivity to cognitive feedback and uncertainty during classification learning. Journal of Neurophysiology, 92, 1144–1152. doi:10.1152/jn.01209.2003
Ashby, G., Noble, S., Filoteo, V., Waldron, E. M., & Ell, S. W. (2003). Category learning deficits in Parkinson’s disease. Neuropsychology, 17(1), 115–124. doi:10.1037/0894-4105.17.1.115
Bechara, A., Damasio, H., Tranel, D., & Damasio, A. R. (1997). Deciding advantageously before knowing the advantageous strategy. Science, 275(5304), 1293–1295.
Beck, A. T., Steer, R. A., & Carbin, M. G. (1988). Psychometric properties of the Beck Depression Inventory: Twenty-five years of evaluation. Clinical Psychology Review, 8(1), 77–100. doi:10.1016/0272-7358(88)90050-5
Beck, A. T., Ward, C. H., & Mendelson, M. (1961). Beck depression inventory (BDI). Archives of General Psychiatry, 4, 561–571.
Beeler, J. A., Cao, Z. F. H., Kheirbek, M. A., Ding, Y., Koranda, J., Murakami, M., … Zhuang, X. (2010). Dopamine-dependent motor learning insight into levodopa’s long-duration response. Annals of Neurology, 67(5), 639–647. doi:10.1002/ana.21947
Beeler, J., Daw, N., Frazier, C. R. M., & Zhuang, X. (2010). Tonic dopamine modulates exploitation of reward learning. Frontiers in Behavioral Neuroscience, 4, 170. doi:10.3389/fnbeh.2010.00170
Bellebaum, C., Koch, B., Schwarz, M., & Daum, I. (2008). Focal basal ganglia lesions are associated with impairments in reward-based reversal learning. Brain, 131(3), 829–841. doi:10.1093/brain/awn011
Berridge, K. C. (2007). The debate over dopamine’s role in reward: The case for incentive salience. Psychopharmacology, 191(3), 391–431. doi:10.1007/s00213-006-0578-x
Bódi, N., Kéri, S., Nagy, H., Moustafa, A., Myers, C. E., Daw, N., … Gluck, M. A. (2009). Reward-learning and the novelty-seeking personality: A between-and within-subjects study of the effects of dopamine agonists on young Parkinsons patients. Brain, 132(9), 2385–2395. doi:10.1093/brain/awp094
Botvinick, M. M., Braver, T. S., Barch, D. M., Carter, C. S., & Cohen, J. D. (2001). Conflict monitoring and cognitive control. Psychological Review, 108(3), 624–652. doi:10.1037//0033-295X.I08.3.624
Bowers, D., Miller, K., Mikos, A., Kirsch-Darrow, L., Springer, U., Fernandez, H., … Okun, M. (2006). Startling facts about emotion in Parkinson’s disease: Blunted reactivity to aversive stimuli. Brain, 129(12), 3356–3365. doi:10.1093/brain/awl301
Carver, C. S., & White, T. L. (1994). Behavioral inhibition, behavioral activation, and affective responses to impending reward and punishment: The BIS/BAS Scales. Journal of Personality and Social Psychology, 67(2), 319–333. doi:10.1037/0022-3514.67.2.319
Chen, G. (2014). When and how to center a variable? Retrieved from https://afni.nimh.nih.gov/sscc/gangc/centering.html
Chen, G., Adleman, N. E., Saad, Z. S., Leibenluft, E., & Cox, R. W. (2014). Applications of multivariate modeling to neuroimaging group analysis: A comprehensive alternative to univariate general linear model. NeuroImage, 99, 571–588. doi:10.1016/j.neuroimage.2014.06.027
Chen, K.-H., Okerstrom, K. L., Kingyon, J. R., Anderson, S. W., Cavanagh, J. F., & Narayanan, N. S. (2016). Startle habituation and midfrontal theta activity in Parkinson’s disease. Journal of Cognitive Neuroscience, 28(12), 1923–1932.
Cincotta, C. M., & Seger, C. A. (2007). Dissociation between striatal regions while learning to categorize via feedback and via observation. Journal of Cognitive Neuroscience, 19(2), 249–265.
Cools, R., Barker, R. A., Sahakian, B. J., & Robbins, T. W. (2001). Enhanced or impaired cognitive function in Parkinson’s disease as a function of dopaminergic medication and task demands. Cerebral Cortex, 11(12), 1136–1143. doi:10.1093/cercor/11.12.1136
Cools, R., Barker, R. A., Sahakian, B. J., & Robbins, T. W. (2003). l-Dopa medication remediates cognitive inflexibility, but increases impulsivity in patients with Parkinson’s disease. Neuropsychologia, 41, 1431–1441. doi:10.1016/S0028-3932(03)00117-9
Cools, R., & D’Esposito, M. (2011). Inverted-U-shaped dopamine actions on human working memory and cognitive control. Biological Psychiatry, 69(12), e113–e125. doi:10.1016/j.biopsych.2011.03.028
Critchley, H. D., Mathias, C. J., & Dolan, R. J. (2001). Neural activity in the human brain relating to uncertainty and arousal during anticipation. Neuron, 29, 537–545.
Critchley, H. D., Tang, J., Glaser, D., Butterworth, B., & Dolan, R. J. (2005). Anterior cingulate activity during error and autonomic response. NeuroImage, 27(4), 885–895. doi:10.1016/j.neuroimage.2005.05.047
de Vries, M. H., Ulte, C., Zwitserlood, P., Szymanski, B., & Knecht, S. (2010). Increasing dopamine levels in the brain improves feedback-based procedural learning in healthy participants: An artificial-grammar-learning experiment. Neuropsychologia, 48(11), 3193–3197. doi:10.1016/j.neuropsychologia.2010.06.024
Del Tredici, K., & Braak, H. (2013). Dysfunction of the locus coeruleus-norepinephrine system and related circuitry in Parkinson’s disease-related dementia. Neurology, Neurosurgery & Psychiatry, 84(7), 774–783. doi:10.1136/jnnp-2011-301817
Delgado, M. R., Miller, M. M., Inati, S., & Phelps, E. A. (2005). An fMRI study of reward-related probability learning. NeuroImage, 24(3), 862–873. doi:10.1016/j.neuroimage.2004.10.002
Dietz, J., Bradley, M. M., Okun, M. S., & Bowers, D. (2011). Emotion and ocular responses in Parkinson’s disease. Neuropsychologia, 49(12), 3247–3253. doi:10.1016/j.neuropsychologia.2011.07.029
Evens, R., Hoe, M., Biber, K., & Lueken, U. (2016). The Iowa gambling task in Parkinson’s disease: A meta-analysis on effects of disease and medication. Neuropsychologia, 91, 163–172. doi:10.1016/j.neuropsychologia.2016.07.032
Fiorillo, C. D. (2013). Two dimensions of value: Dopamine but not aversiveness. Science, 341(6145), 546–549. doi:10.1126/science.1238699
Flagel, S. B., Clark, J. J., Robinson, T. E., Mayo, L., Czuj, A., Willuhn, I., … Akil, H. (2011). A selective role for dopamine in stimulus-reward learning. Nature, 469(7328), 53–57. doi:10.1038/nature09588
Foerde, K., Race, E., Verfaellie, M., & Shohamy, D. (2013). A role for the medial temporal lobe in feedback-driven learning: Evidence from amnesia. The Journal of Neuroscience, 33(13), 5698–5704. doi:10.1523/JNEUROSCI.5217-12.2013
Foerde, K., & Shohamy, D. (2011a). Feedback timing modulates brain systems for learning in humans. Journal of Neuroscience, 31(37), 13157–13167. doi:10.1523/JNEUROSCI.2701-11.2011
Foerde, K., & Shohamy, D. (2011b). Neurobiology of learning and memory the role of the basal ganglia in learning and memory : Insight from Parkinson’s disease. Neurobiology of Learning and Memory, 96(4), 624–636. doi:10.1016/j.nlm.2011.08.006
Frank, M. J. (2005). Dynamic dopamine modulation in the basal ganglia: A neurocomputational account of cognitive deficits in medicated and non-medicated parkinsonism. Journal of Cognitive Neuroscience, 17(1), 51–72.
Frank, M. J., Seeberger, L. C., & O’Reilly, R. C. (2004). By carrot or by stick: Cognitive reinforcement learning in parkinsonism. Science, 306(5703), 1940–1943. doi:10.1126/science.1102941
Freedberg, M., Schacherer, J., & Hazeltine, E. (2016). Incidental learning of rewarded associations bolsters learning on an associative task. Journal of Experimental Psychology: Learning Memory and Cognition, 42(5). doi:10.1037/xlm0000201
Galvan, A., Hare, T. A., Davidson, M., Spicer, J., Glover, G., & Casey, B. J. (2005). The role of ventral frontostriatal circuitry in reward-based learning in humans. Journal of Neuroscience, 25(38), 8650–8656. doi:10.1523/JNEUROSCI.2431-05.2005
Gong, M., & Li, S. (2014). Learned reward association improves visual working memory. Journal of Experimental Psychology: Human Perception and Performance, 40(2), 841–856. doi:10.1037/a0035131
Gotham, A. M., Brown, R. G., & Marsden, C. D. (1988). “Frontal” cognitive function in patients with Parkinson’s disease “on” and “off” levodopa. Brain, 111, 299–321.
Harding, G., & Punzo, F. (1971). Response uncertainty and skin conductance. Journal of Experimental Psychology, 88(2), 265–272. doi:10.1037/h0030929
Hornykiewicz, O. (1966). Dopamine (3-hydroxytyramine) and brain functions. Pharmacological Reviews, 18, 925–964.
Jahanshahi, M., Wilkinson, L., Gahir, H., Dharminda, A., & Lagnado, D. A. (2010). Medication impairs probabilistic classification learning in Parkinson’s disease. Neuropsychologia, 48(4), 1096–1103. doi:10.1016/j.neuropsychologia.2009.12.010
Kirby, K. N., & Gerlanc, D. (2013). BootES: An R package for bootstrap confidence intervals on effect sizes. Behavior Research Methods, 45(4), 905–927. doi:10.3758/s13428-013-0330-5
Kish, S. J. (2003). Biochemistry of Parkinson’s disease: Is a brain serotonergic deficiency a characteristic of idiopathic Parkinson’s disease. Advances in Neurology, 91, 39–49.
Kish, S. J., Shannak, K., & Hornykiewicz, O. (1988). Uneven pattern of dopamine loss in the striatum of patients with idiopathic Parkinson’s disease. New England Journal of Medicine, 318(14), 876–880.
Knowlton, B. J., Mangels, J. A., & Squire, L. R. (1996). A neostriatal habit learning system in humans. Science, 273(5280), 1399–1402. doi:10.1126/science.273.5280.1399
Knowlton, B. J., Squire, L. R., & Gluck, M. A. (1994). Probabilistic classification learning in amnesia. Learning & Memory, 1(2), 106–120. doi:10.1101/lm.1.2.106
Levey, A. (1980). Electrodermal activity. Techniques in Psychophysiology, 597–628.
Maruyama, W., Naoi, M., & Narabayashi, H. (1996). The metabolism of L-DOPA and L-threo-3,4-dihydroxyphenylserine and their effects on monoamines in the human brain: Analysis of the intraventricular fluid from parkinsonian patients. Journal of the Neurological Sciences, 139(1), 141–148. doi:10.1016/S0022-510X(96)00049-4
McClure, S. M., York, M. K., & Montague, P. R. (2004). The neural substrates of reward processing in humans: The modern role of fMRI. The Neuroscientist, 10(3), 260–268. doi:10.1177/1073858404263526
Miller, E. M., Shankar, M. U., Knutson, B., & McClure, S. (2014). Dissociating motivation from reward in human striatal activity. Journal of Cognitive Neuroscience, 26(5), 1075–1084. doi:10.1162/jocn_a_0053
Muhammed, K., Manohar, S., Yehuda, M. B., Trevor, T., Tofaris, G., Lennox, G., … Husain, M. (2016). Reward sensitivity deficits modulated by dopamine are associated with apathy in Parkinson’s disease. Brain, 139(10). doi:10.1093/brain/aww188
Muslimović, D., Post, B., Speelman, J. D., & Schmand, B. (2007). Motor procedural learning in Parkinson’s disease. Brain, 130(11), 2887–2897. doi:10.1093/brain/awm211
Myers, C. E., Shohamy, D., Gluck, M. A., Grossman, S., Kluger, A., Ferris, S., … Schwartz, R. (2003). Dissociating hippocampal versus basal ganglia contributions to learning and transfer. Journal of Cognitive Neuroscience, 15(2), 185–193. doi:10.1162/089892903321208123
Narayanan, N. S., Rodnitzy, R. L., & Uc, E. (2013). Prefrontal dopamine signaling and cognitive symptoms of Parkinson’s disease. Reviews in the Neurosciences, 24(3), 267–278.
Nasreddine, Z., Phillips, N., Bédirian, V., Charbonneau, S., Whitehead, V., Colllin, I., … Chertkow, H. (2005). The Montreal Cognitive Assessment, MoCA: A brief screening tool for mild cognitive impairment. Journal of the American Geriatrics Society, 53(4), 695–699. doi:10.1111/j.1532-5415.2005.53221.x
Palminteri, S., Lebreton, M., Worbe, Y., Grabli, D., Hartmann, A., & Pessiglione, M. (2009). Pharmacological modulation of subliminal learning in Parkinson’s and Tourette’s syndromes. Proceedings of the National Academy of Sciences of the United States of America, 106(45), 19179–19184. doi:10.1073/pnas.0904035106
Palminteri, S., Lebreton, M., Worbe, Y., Hartmann, A., Lehéricy, S., Vidailhet, M., … Pessiglione, M. (2011). Dopamine-dependent reinforcement of motor skill learning: Evidence from Gilles de la Tourette syndrome. Brain, 134(8), 2287–2301. doi:10.1093/brain/awr147
Parker, K. L., Chen, K.-H., Kingyon, J. R., Cavanagh, J. F., & Narayanan, N. S. (2015). Medial frontal ~4-Hz activity in humans and rodents is attenutated in PD patients and in rodents with cortical dopamine depletion. Journal of Neurophysiology, 114(2), 1310–1320.
Perry, E. K., Curtis, M., Dick, D. J., Candy, J. M., Atack, J. R., Bloxham, C. A., … Perry, R. H. (1985). Cholinergic correlates of cognitive impairment in Parkinson’s disease: Comparisons with Alzheimer’s disease. Journal of Neurology, Neurosurgery, and Psychology, 48(5), 413–421.
Pinheiro, J. C., & Bates, D. M. (2000). Mixed-effects models in S and S+. Retrieved from https://books.google.com/books?hl=de&lr=&id=ZRnoBwAAQBAJ&pgis=1
Poldrack, R. A., Clark, J., Pare-Blagoev, E. J., Shohamy, D., Moyano, J. C., Myers, C., & Gluck, M. A. (2001). Interactive memory systems in the human brain. Nature, 414(6863), 546–550. doi:10.1038/35107080
Poldrack, R., Prabhakaran, V., Seger, C. A., & Gabrieli, J. D. (1999). Striatal activation during acquisition of a cognitive skill. Neuropsychology, 13(4), 564–574. doi:10.1037/0894-4105.13.4.564
R Development. (2010). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing.
Reitan, R. M. (1958). Trail making manual for administration, scoring, and interpretation. Indianapolis: Department of Neurology, Section of Neuropsychology, Indiana University Medical Center.
Rey, A. (1964). Auditory-verbal learning test (AVLT). Paris: Press Universitaire de France.
Robertson, G. S., & Robertson, H. A. (1988). Evidence that the substantia nigra is a site of action for l-DOPA. Neuroscience Letters, 89(2), 204–208. doi:10.1016/0304-3940(88)90382-5
Robinson, T. E., & Flagel, S. B. (2009). Dissociating the predictive and incentive motivational properties of reward-related cues through the study of individual differences. BPS, 65(10), 869–873. doi:10.1016/j.biopsych.2008.09.006
Roper, Z. J. J., Vecera, S. P., & Vaidya, J. G. (2014). Value-driven attentional capture in adolescence. Psychological Science. doi:10.1177/0956797614545654
Samanez-Larkin, G. R., Gibbs, S. E. B., Khanna, K., Nielsen, L., Carstensen, L. L., & Knutson, B. (2007). Anticipation of monetary gain but not loss in healthy older adults. Nature Neuroscience, 10(6), 787–791. doi:10.1038/nn1894
Schmitt-Eliassen, J., Ferstl, R., Wiesner, C., Deuschl, G., & Witt, K. (2007). Feedback-based versus observational classification learning in healthy aging and Parkinson’s disease. Brain Research, 2. doi:10.1016/j.brainres.2007.01.042
Schultz, W., Dayan, P., & Montague, P. R. (1997). A neural substrate of prediction and reward. Science, 275, 1593–1599. doi:10.1126/science.275.5306.1593
Shohamy, D., Myers, C. E., Grossman, S., Sage, J., Gluck, M. A., & Poldrack, R. A. (2004). Cortico-striatal contributions to feedback-based learning: Converging data from neuroimaging and neuropsychology. Brain, 127(4), 851–859. doi:10.1093/brain/awh100
Shohamy, D., Myers, C. E., Kalanithi, J., & Gluck, M. A. (2008). Basal ganglia and dopamine contributions to probabilistic category learning. Neuroscience and Biobehavioral Reviews, 32, 219–236. doi:10.1016/j.neubiorev.2007.07.008
Shohamy, D., Myers, C. E., Onlaor, S., & Gluck, M. A. (2004). Role of the basal ganglia in category learning: How do patients with Parkinson’s disease learn? Behavioral Neuroscience, 118(4), 676–686. doi:10.1037/0735-7044.118.4.676
Siegert, R. J., Weatherall, M., & Bell, E. M. (2008). Is implicit sequence learning impaired in schizophrenia? A meta-analysis. Brain and Cognition, 67(3), 351–359. doi:10.1016/j.bandc.2008.02.005
Swainson, R., Rogers, R. D., Sahakian, B. J., Summers, B. A., Polkey, C. E., & Robbins, T. W. (2000). Probabilistic learning and reversal deficits in patients with Parkinson’s disease or frontal or temporal lobe lesions: Possible adverse effects of dopaminergic medication. Neuropsychologia, 38(5), 596–612. doi:10.1016/S0028-3932(99)00103-7
Tomlinson, C. L., Stowe, R., Patel, S., Rick, C., Gray, R., & Clarke, C. E. (2010). Systematic review of levodopa dose equivalency reporting in Parkinson's disease. Movement disorders, 25(15), 2649–2653.
van Steenbergen, H., Band, G. P. H., & Hommel, B. (2009). Reward counteracts conflict adaptation: Evidence for a role of affect in executive control. Psychological Science, 20(12), 1473–1477. doi:10.1111/j.1467-9280.2009.02470.x
van Steenbergen, H., Band, G. P. H., & Hommel, B. (2012). Reward valence modulates conflict-driven attentional adaptation: Electrophysiological evidence. Biological Psychology, 90(3), 234–241. doi:10.1016/j.biopsycho.2012.03.018
Vazey, E. M., & Aston-Jones, G. (2012). The emerging role of norepinephrine in cognitive dysfunctions of Parkinson’s disease. Frontiers in Behavioral Neuroscience, 6, 48. doi:10.3389/fnbeh.2012.00048
Wachter, T., Lungu, O. V., Liu, T., Willingham, D. T., & Ashe, J. (2009). Differential effect of reward and punishment on procedural learning. Journal of Neuroscience, 29(2), 436–443. doi:10.1523/JNEUROSCI.4132-08.2009
Wasserman, E. A., Brooks, D. I., & McMurray, B. (2015). Pigeons acquire multiple categories in parallel via associative learning: A parallel to human word learning? Cognition, 136, 99–122. doi:10.1016/j.cognition.2014.11.020
Wilkinson, L., Lagnado, D. A., Quallo, M., & Jahanshahi, M. (2008). The effect of feedback on non-motor probabilistic classification learning in Parkinson’s disease. Neuropsychologia, 46(11), 2683–2695. doi:10.1016/j.neuropsychologia.2008.05.008
Wise, R. A. (2004). Dopamine, learning and motivation. Nature Reviews Neuroscience, 5(6), 483–494. doi:10.1038/nrn1406
Wittmann, B. C., Dolan, R. J., & Düzel, E. (2011). Behavioral specifications of reward-associated long-term memory enhancement in humans. Learning & Memory, 18(5), 296–300. doi:10.1101/lm.1996811
Wittmann, B. C., Schott, B. H., Guderian, S., Frey, J. U., Heinze, H. J., & Düzel, E. (2005). Reward-related fMRI activation of dopaminergic midbrain is associated with enhanced hippocampus-dependent long-term memory formation. Neuron, 45(3), 459–467. doi:10.1016/j.neuron.2005.01.010
Acknowledgements
The authors would like to thank the Neurology department at the University of Iowa’s Hospitals and Clinics (UIHC), including Ruth Henson, Kenneth Manzel, Natalie Denburg, and Daniel Tranel. The authors would like to thank Bob McMurray and Teresa Treat for their assistance with our statistical analyses, and Sara Hussain for her help with our physiological analyses. This study was funded from the National Institute on Drug Abuse under Award Number 5R03DA031583-02 and by the Graduate and Professional Student Government (GPSG) at the University of Iowa.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing financial interests.
Rights and permissions
About this article

Cite this article
Freedberg, M., Schacherer, J., Chen, KH. et al. Separating the effect of reward from corrective feedback during learning in patients with Parkinson’s disease. Cogn Affect Behav Neurosci 17, 678–695 (2017). https://doi.org/10.3758/s13415-017-0505-0
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13415-017-0505-0