
Abstract
In a previous series of studies, we have shown that search for human targets in the context of natural scenes is more efficient than search for mechanical targets. Here we asked whether this search advantage extends to other categories of biological objects. We used videos of natural scenes to directly contrast search efficiency for animal and human targets among biological or nonbiological distractors. In visual search arrays consisting of two, four, six, or eight videos, observers searched for animal targets among machine distractors, and vice versa (Exp. 1). Another group searched for animal targets among human distractors, and vice versa (Exp. 2). We measured search slope as a proxy for search efficiency, and complemented the slope with eye movement measurements (fixation duration on the target, as well as the proportion of first fixations landing on the target). In both experiments, we observed no differences in search slopes or proportions of first fixations between any of the target–distractor category pairs. With respect to fixation durations, we found shorter on-target fixations only for animal targets as compared to machine targets (Exp. 1). In summary, we did not find that the search advantage for human targets over mechanical targets extends to other biological objects. We also found no search advantage for detecting humans as compared to other biological objects. Overall, our pattern of findings suggests that search efficiency in natural scenes, as elsewhere, depends crucially on the specific target–distractor categories.
Similar content being viewed by others

Efficient processing of animate, biological objects is beneficial from an ecological point of view. It allows observers to find partners for social interactions or to avoid dangerous animals, for example. Recently we provided evidence that visual scenes containing one specific class of biological object—human beings—are processed more efficiently than those containing nonbiological, mechanical objects (Mayer, Vuong, & Thornton, 2015, 2017). Using a standard visual search paradigm (Treisman & Gelade, 1980; Treisman & Souther, 1985; Wolfe, 1998; Wolfe & Horowitz, 2004, 2017), we showed that human targets embedded in natural scenes were located more efficiently than a range of complex, mechanical targets. This human search advantage, observed in terms of shallower search slopes, occurred in a standard search asymmetry design (in which humans and machines served as the targets and distractors for each other; Mayer et al., 2015), and also when such targets had to be found in the context of a third, common distractor class of moving natural objects, such as clouds and fire (Mayer et al., 2017). The shallower slopes in both our previous studies were complemented by higher proportions of first fixations landing on a human target and shorter on-target fixation durations.
The goal of the present work was to examine whether this search advantage is specific to human targets, or whether, instead, it extends to other animate, biological categories. This question can be addressed by using the same task to directly investigate similarities and differences in the processing of different categories of biological objects, which few studies to date have done. Therefore, in two experiments we used the visual search paradigm from our previous studies (Mayer et al., 2015, 2017) to directly compare search efficiencies for animal targets relative to both mechanical objects (Exp. 1) and humans (Exp. 2).
A large body of literature supports perceptual and neural mechanisms being visually tuned to process human body pose and movement in an automatic and bottom-up fashion (see Blake & Shiffrar, 2007, for a review; Giese & Poggio, 2003; Lange & Lappe, 2006; Thornton & Vuong, 2004; Troje & Westhoff, 2006). There is also evidence that top-down mechanisms can play an important role (Bertenthal, Proffitt, & Cutting, 1984; Bülthoff, Bülthoff, & Sinha, 1998; Cavanagh, Labianca, & Thornton, 2001; Thompson & Parasuraman, 2012; Thornton, Rensink, & Shiffrar, 2002). In particular, it has been suggested that through extensive experiences with others, observers form attentional sprites that can efficiently guide search for human motion in a top-down fashion (Cavanagh et al., 2001).
Much of the evidence for visual tuning to human body pose and movement is based on degrading either form or motion information in the visual input (Beintema & Lappe, 2002; Johansson, 1973). For example, Johannson showed that observers can infer a human figure from only the movement pattern generated by point-lights attached to an upright human walker’s joints. Moreover, even with such highly impoverished point-light stimuli, observers can infer the walker’s actions (e.g., Johansson, 1973) or whether the walker is female or male (Kozlowski & Cutting, 1977; Pollick, Kay, Heim, & Stringer, 2005). The underlying perceptual and neural mechanisms may be present from birth or at least may develop in early infancy. Simion, Regolin, and Bulf (2008) showed that 2-day-old babies preferentially look at upright as compared to inverted point-light walkers. Infants younger than half a year preferentially look at biological motion patterns (Fox & McDaniel, 1982), are better at memorizing actions of adults than the faces of the adults (Bahrick, Gogate, & Ruiz, 2002), and show sensitivity to figural coherence of biological motion (Bertenthal et al., 1984). At the neural level, some brain regions in the temporal lobe, for example, respond selectively to human body pose (e.g., the extrastriate body area; Downing, Bray, Rogers, & Childs, 2004) and movement (e.g., the superior temporal sulcus, STS; Grossman et al., 2000; Saygin, 2007).
Apart from human form and motion, observers can also quickly and accurately detect and interpret visually impoverished stimuli of other animal species. For example, they can recognize a wide variety of animals, including chicks, pigeons, horses, and dogs, from point-light stimuli (Bellefeuille & Faubert, 1998; Kaiser, Shiffrar, & Pelphrey, 2012; Mather & West, 1993; Troje & Westhoff, 2006). Human babies as young as 2 days old preferentially look at point-light stimuli of hens as compared to point-light stimuli of moving nonbiological objects (Bardi, Regolin, & Simion, 2011). However, there is some evidence for a human advantage when human point-light stimuli are directly contrasted with animal point-light stimuli. For example, Pinto and Shiffrar (2009) found higher sensitivity to human than to horse motion using point-light stimuli. Similarly, Kaiser et al. (2012) found stronger responses in the STS when observers viewed point-light humans in contrast to point-light dogs.
For static images displaying natural scenes, New, Cosmides, and Tooby (2007) showed that observers detected changes to both humans and other animals more quickly and reliably than changes to other types of objects, such as vehicles or tools. These findings argue for preferential processing of biological as compared to nonbiological objects. Furthermore, New et al. found higher accuracy for change detection in scenes displaying humans than in scenes displaying animals. With respect to reaction times, however, they found that changes were detected equally quickly for humans and animals.
Thus, it is not clear to what extent the perceptual and neural mechanisms visually tuned to humans can also efficiently process other animals, particularly under more naturalistic conditions. Previous studies have used impoverished point-light stimuli, a small number of actions or animals (e.g., walking human vs. walking horse; Pinto & Shiffrar, 2009), static images (e.g., New et al., 2007), and simple discrimination paradigms, which limited their generality to real-world situations. In the present experiments, we used a visual search paradigm to compare search efficiencies for animals and humans in the context of natural scenes.
As already mentioned, we have previously used this paradigm to investigate search efficiency for human targets relative to mechanical targets in dynamic natural videos (Mayer et al., 2015, 2017). Using the same paradigm and measures, here we asked whether search efficiency differs between animals and machines (Exp. 1) and whether search efficiency differs between animals and humans (Exp. 2). We hypothesized that visual tuning to biological motion (e.g., Cavanagh et al., 2001; Thornton & Vuong, 2004; Troje & Westhoff, 2006) enables more efficient search for animals than for machines. Furthermore, we hypothesized that the familiarity and social relevance of human form and movement (Boucart et al., 2016; Pinto & Shiffrar, 2009) would enable more efficient search for humans than for animals, via top-down mechanisms (e.g., Cavanagh et al., 2001). Finally, we checked whether any combination of target and distractor categories allows for efficient search in the form of pop-out search (Mayer et al., 2015; Treisman & Souther, 1985; Wolfe, 1998).
Experiment 1: Animals and machines
Methods
Participants
Nine participants were recruited from the wider Newcastle University community (mean age = 19.9 years, SD = 2 years; eight females, one male). The sample size was determined prior to data collection, on the basis of our previous studies (Mayer et al., 2015, 2017); this allowed us to compare results across studies (see below). To assess the adequacy of this sample size to detect a slope difference between the two categories of interest (animals vs. machines in Exp. 1, or animals vs. humans in Exp. 2), we used the effect size obtained in the closest matching condition of our previous work (Exp. 1 of Mayer et al., 2015) to conduct a power analysis. The effect size from the comparison of slopes in this previous experiment was 1.36 (Cohen’s d; mean difference divided by the pooled standard deviation), which suggests a sample size of seven participants for a power of .8 and an alpha level of .05. This sample size was established using the G*Power 3.1 software package (Faul, Erdfelder, Buchner, & Lang, 2009). Participants received course credit or were reimbursed with £5. They had normal vision or wore contact lenses. Participants were informed that the experiment involved category search with eyetracking prior to the experiment, but they were naïve to the specific hypothesis. They gave informed consent. The ethics for this study were approved by the local ethics committee of Newcastle University.
Stimuli and apparatus
The stimuli were 128 × 96 pixel grayscale videos displaying animals and machines. The videos displaying machines were used in our previous studies (Mayer et al., 2015, 2017). We used eight videos for each category. The machine videos displayed, for example, a spinning wheel or a sawing machine (Fig. 1, bottom row). The animal videos displayed a kangaroo sitting in a field and scratching its belly, a running bear cub, a lemur walking along a branch, a chimpanzee climbing up a rope, a walking lion, walking zebras, a running antelope, and a running desert fox (Fig. 1, top and middle rows). We only included mammals in the videos so as to exclude detection biases for highly salient animals like snakes and spiders (Öhman, Flykt, & Esteves, 2001). Each video predominantly showed an object from one scene, and there were never any objects from the other category in the video. Videos were acquired from films, documentaries or recorded with a camcorder. Each video lasted 1.8 s and had a frame rate of 25 frames per second.

Frames from the animal (top and middle rows) and machine (bottom row) videos used in the present study.
Participants were seated at a distance of 50 cm from a Sony Trinitron CRT monitor (refresh rate 100 Hz; resolution 1,024 × 768 pixels). Thus, the videos subtended 5.4° × 4.1° of visual angle. Head movements were constrained with a chin rest, and responses were collected with a standard keyboard. Eye movements were sampled using a Cambridge Research Systems eyetracker at a rate of 50 Hz, with a spatial resolution of 0.1°. The experiments were controlled using a Windows PC running Matlab (Mathworks). We used the Psychtoolbox (Brainard, 1997; Kleiner, Brainard, & Pelli, 2007; Pelli, 1997) extension for Matlab to present the stimuli.
Design
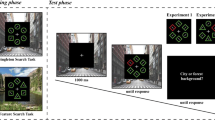
Participants searched for a target (i.e., a video displaying an animal or a video displaying a machine) amidst distractor videos from the other category. The target could be present or absent in the search array. The search array consisted of two, four, six, or eight videos. The experiment was set up as a 2 × 2 × 4 design, with the within-subjects factors target type (animal target, machine target), trial type (present trial, absent trial), and set size (search array consisting of two, four, six, or eight videos).
Procedure
To ensure that participants were familiar with the specific videos in the experiment, all eight videos of each category were presented prior to the experiment. The videos were arranged on the screen in two rows and four columns and were played as loops. Participants wrote a short description of the content of each video. There was no time limit. Once a participant had written the descriptions of one category, the other category was presented.
After the familiarization phase, the actual experiment began. Participants were now asked to search for videos containing the target category and to respond whether the target was present or absent as quickly and accurately as possible. A few practice trials were presented in order to ensure that participants understood the task.
Search arrays were rendered against a gray background. In the search arrays, the videos were distributed evenly on an invisible circle. The circle had a radius of 12.5° (300 pixels), and its center was placed at the center of the screen. The actual locations of the videos were randomly assigned on every trial.
Each trial started with a white fixation cross, rendered against a gray background, that was shown for 1 s before the search array was displayed. Participants were required to look at the fixation cross and they could then move their eyes freely when the search array was presented. The fixation cross remained visible throughout the trial. The videos shown on a given trial started at a randomly selected frame and looped continuously until the participant responded. Present and absent responses were collected using the “c” and the “m” key. The response mapping was counterbalanced across participants. When participants responded incorrectly a 1500 Hz tone was played for 80 ms as feedback. After the response the search array disappeared and a gray screen was shown for 500 ms before the fixation cross for the next trial appeared. Eyetracking of the right eye started when participants looked at the fixation cross at the beginning of a trial.
Each of the 16 conditions was presented 32 times, leading to 512 trials (256 for each target type). For each target type, we presented four blocks of 64 trials each. The two target types were run in alternating blocks, with the starting category counterbalanced across participants. At the beginning of each block, a written text indicated what the target category was for that block. On target-present trials, each of the eight videos was shown equally often at each set size (i.e., four times). As distractor videos on both the absent and present trials, the eight videos from the other category (i.e., machine videos on animal-target blocks or animal videos on machine-target blocks) were randomly selected, with the constraints that no videos were repeated within a given trial and that the videos were used approximately equally often across trials. Within each block, the order of the trials was randomized. There were self-timed breaks after each block. We calibrated the eyetracker before each block. In total, the experiment lasted approximately 40 min.
Data analysis
Accuracies were high across all conditions (> 90%) and thus will not be discussed further (Mayer et al., 2017). Search times were measured from the onset of the search array until a response was made. We analyzed search slopes, which were computed by linear regressions of median search times onto set size. Only search times from trials in which participants responded correctly were included.
With respect to the eye movement data, we computed fixation duration and the proportion of first fixations that landed on the target, by analyzing the first fixation following onset of the search array, and only included trials in which participants responded correctly (Eckstein, 2011; Mayer et al., 2015, 2017). For fixation durations, we analyzed only the first fixation that landed on a target video, on present trials, and the first fixation that landed on any video, on absent trials. To be considered as being on a video, a fixation had to be within 100 pixels (4.1°) of the center of a video. Fixations within 0.6° spatially and 120 ms temporally of each other were considered a single fixation. For present trials, we also calculated the proportion of first fixations that landed on the target video by dividing the number of first fixations on the target by the number of fixations that landed on any video in the search array for each condition. Custom software was used to extract the fixations on every trial. The raw eyetracking data were smoothed using a median filter within a moving 60-ms temporal window. Blinks were removed. Only trials in which 70% or more of the trial duration was tracked successfully were included in the analyses. This criterion removed between 0.8% and 22.1% of the fixation data across participants.
The search slopes and fixation duration data were submitted to separate 2 trial type (present, absent) × 2 target type (Exp. 1: animal, machine; Exp. 2: animal, human) repeated measures analyses of variance (ANOVAs). The proportions of first fixations that landed on a target were submitted to a 2 target type (Exp. 1: animal, machine; Exp. 2: animal, human) × 4 set size (two, four, six, and eight videos) repeated measures ANOVA. One-sample t tests were used to test for “pop-out” (i.e., slope = 0; Treisman & Souther, 1985; Wolfe, 1998). Additional post-hoc paired and independent-samples t tests were used for pairwise comparisons (as appropriate). An alpha of .05 was used as the significance level for all statistical tests.
Additionally, we included Bayes factor analyses, to adjudicate between the hypothesis that slopes were consistent across target types and the hypothesis that slopes differed across target types for our two main experiments. We used the repeated measures Bayes analyses (2 trial type × 2 target type) implemented in the JASP software package (JASP Team, 2018). Because a prior is required for Bayes analyses and we did not know the exact prior for our data, we tested a range of priors between .1 and .9 (in steps of .1) for each analysis. We followed the interpretation of Bayes factors of Jeffreys (1961), as adopted by Wagenmakers, Wetzels, Borsboom, and van der Maas (2011), and accepted Bayes factors of > 3 as an indication for differences in performance, and Bayes factors of < 1/3 as an indication of consistent performance.
Results
Animals versus machines: Search slope
Search times and search slopes are plotted in Fig. 2a and b, respectively. All search slopes were > 0, indicating that search times increased with set size (ps < .001). We found only a main effect of trial type, indicating steeper slopes on target-absent trials [F(1, 8) = 61.30, p < .001, partial η2p = .89; absent: M = 132 ms/video, SE = 16 ms/video; present: M = 38 ms/video, SE = 5 ms/video]. No other main effect or interaction was significant (ps > .63, n.s.).

Animals versus machines: Bayes factor
The Bayes factor analysis showed evidence for differences in performance between present and absent trials (the Bayes factors ranged from 1.02 × 108 and 8.04 × 108, depending on the prior setting). The Bayes factor analysis was in favor of consistent performance across animal and machine targets (the Bayes factors ranged from 0.20 to 0.73, depending on the prior setting). There was no evidence for an interaction (the Bayes factors ranged from 0.24 to 0.85, depending on the prior setting).
Animals versus machines: Fixation duration
The fixation durations are plotted in Fig. 2c and displayed in Table 1. We found a significant interaction between target type and trial type [F(1, 8) = 13.72, p = .006, partial η2p = .63]. On present trials, the fixation duration on animal targets (M = 225 ms, SE = 8 ms) was shorter than the one on machine targets (M = 260 ms, SE = 17 ms) [t(8) = 3.07, p = .015]. By comparison, on absent trials, the fixation durations did not differ between animal (M = 159 ms, SE = 5 ms) and machine (M = 162 ms, SE = 5 ms) distractor videos (p = .45, n.s.). There were also main effects of trial type, indicating quicker fixation durations on distractor videos than on targets [F(1, 8) = 92.35, p < .001, partial η2p = .92; target absent: M = 106 ms, SE = 5 ms; target present: M = 242 ms, SE = 12 ms], and target type, indicating quicker fixation durations on animal than on machine targets [F(1, 8) = 5.74, p = .043, partial η2p = .42; animal target: M = 193 ms, SE = 6 ms; machine target: M = 209 ms, SE = 11 ms].
Animals versus machines: Proportion of first fixations on the target
We observed a main effect of set size [F(3, 24) = 19.50, p < .001, partial η2p = .71], showing that the proportion of first fixations on the target decreased linearly with set size [linear contrast: F(1, 8) = 27.81, p = .001, partial η2p = .78; Table 1]. There was no main effect of target type, and no interaction between target type and set size (ps > .80, n.s.).
Saliency model observers
To investigate the extent to which participants used low-level salient features to find targets (Mayer et al., 2015), we tested model observers who searched for targets based on orientation, brightness, and motion-energy saliency maps (Koch & Ullman, 1985; Parkhurst, Law, & Niebur, 2002). Briefly, eight model observers searched arrays for animal targets among machine distractors, and eight searched for machine targets among animal distractors. There were only target-present trials. On a given trial, each model observer progressively “fixated” on locations of decreasing saliency based on the computed saliency maps. Search was terminated when a target was fixated. This procedure allowed us to count the number of cycles to “detect” a target for each set size and compute the slope for each target category (i.e., the cycles can be used as a proxy for search times). We used the Saliency Toolbox for Matlab (version 2.1; Walther & Koch, 2006) and Piotr Dollar’s image-processing toolbox (https://pdollar.github.io/toolbox/; see Mayer et al., 2015, for full details). We found that searching for animal targets among machine distractors yielded steeper slopes (M = 20 cycles/video, SE = 2 cycles/video) than searching for machines among animal distractors (M = 11 cycles/video, SE = 1 cycle/video) [t(7) = 4.66, p = .002].
Discussion
As with human targets in our previous studies (Mayer et al., 2015, 2017), searching for animal targets was effortful—that is, there was no “pop-out” (Treisman & Souther, 1985; Wolfe, 1998), as indicated by search slopes > 0. In contrast to our previous studies, we found no significant search slope difference between searching for animal and searching for machine targets. Participants also made equal proportions of first on-target fixations to both categories, and they fixated on animal targets more briefly than on machine targets.
Although humans and animals have different forms, with respect to movements, they share more similar kinematics with each other (e.g., pendular motion of joints) than do animals and machines. This motion similarity may confer some processing advantage for animals relative to machines, as captured by the shorter fixation duration found for animal targets in this experiment. This advantage is in line with the biological advantage found using impoverished point-light stimuli of humans and animals, in which predominantly motion information is available (e.g., Pavlova, Krageloh-Mann, Sokolov, & Birbaumer, 2001; Ruffieux et al., 2016; Shi, Weng, He, & Jiang, 2010; Troje & Westhoff, 2006). As we previously suggested (Mayer et al., 2015, 2017), the shorter fixation duration may reflect faster processing of animal than of machine targets. However, unlike the human targets in our previous studies, this advantage did not lead to more efficient search, as measured by search slopes.
To ensure that the results across the two experiments were not driven solely by low-level visual features of the videos we used, we simulated model observers that used salient luminance, orientation, and motion-energy information to find targets (Mayer et al., 2015). In contrast to the human search performance, the model observers’ search slopes were steeper for animal than for machine targets. The difference found between model and human observers suggests that the participants in our studies did not exclusively base their search on low-level visual features of the videos.
Experiment 2: Humans and animals
In Experiment 1, search slopes were the same for animals and machines. Previously we found that searching for humans was more efficient (shallower slope) than searching for machines (Mayer et al., 2015). Given these findings, searching for humans might be more efficient than search for animals if these two biological categories were directly contrasted. There is further evidence that observers may search for other humans efficiently: People have extensive exposure to other people, and often in socially relevant situations (e.g., Pinto & Shiffrar, 2009). For example, the rich interaction between humans may lead to the formation of attentional sprites that may efficiently guide search for human targets (Cavanagh et al., 2001) but not for animal targets. In Experiment 2, we directly compared search efficiency for animals and humans, using each biological category as both target and distractor. We also presented model observers with the search displays, to test whether and how low-level visual features affect search behaviors (Mayer et al., 2015).
Method
Participants
Nine participants were recruited from the wider Newcastle University community for Experiment 2 (mean age = 19.4 years, SD = 0.9 years; all females). They participated for course credit or were reimbursed with £5. One female participant took part in both experiments. All participants had normal vision or wore contact lenses. The participants were informed prior to participating that the experiment involved category search with eyetracking, but they were naïve to the specific hypotheses. They gave informed consent. The study ethics were approved by the local ethics committee of Newcastle University.
Design, procedure, and analyses
The same design and procedure were used as we reported for Experiment 1, except that the videos displaying humans used in our previous studies were included instead of the videos displaying machines. The same analyses were conducted as we reported for Experiment 1.
Results
Animals versus humans: Search slope
The search times and search slopes are plotted in Fig. 2d and e, respectively. All search slopes were > 0, indicating that search times increased with set size (ps < .001). In contrast to Experiment 1, we observed a significant interaction between trial type and target type [F(1, 8) = 6.41, p = .04, partial η2p = .45]. For present trials, there were no differences between the two target types [animal present: M = 67 ms/video, SE = 6 ms/video; human present: M = 78 ms/video, SE = 10 ms/video; t(8) = 1.16, p = .28, n.s.]. By comparison, for absent trials, the slope was steeper on animal-target than on human-target blocks [animal absent: M = 198 ms/video, SE = 21 ms/video; human absent: M = 166 ms/video, SE = 19 ms/video; t(8) = 3.05, p = .016]. That is, participants were less efficient at correctly terminating the search when the search array consisted of only human distractor videos (animal-target block) than when the array consisted of only animal distractor videos (human-target blocks). There was also a main effect of trial type, indicating steeper search slopes on target-absent than on target-present trials [F(1, 8) = 63.33, p < .001, partial η2p = 72 ms/video, SE = 7 ms/video; absent: M = 182 ms/video, SE = 19 ms/video], but only a marginal effect of target type [F(1, 8) = 4.11, p = .08, partial η2p = .34; human target: M = 122 ms/video, SE = 13 ms/video; animal target: M = 132 ms/video, SE = 12 ms/video].
Animals versus humans: Bayes factor
The Bayes factor analysis showed evidence for differences in performance between present and absent trials (the Bayes factors ranged from 4.82 × 107 and 3.77 × 108, depending on the prior setting). The Bayes factor was in favor of consistent performance across target types (the Bayes factors ranged from 0.22 to 0.75, depending on the prior setting). There was only anecdotal evidence for an interaction (the Bayes factors ranged from 1.44 to 1.91, depending on the prior setting).
Animals versus humans: Fixation duration
The fixation durations are plotted in Fig. 2f and displayed in Table 2. We observed a marginal interaction between target type and trial type [F(1, 8) = 5.18, p = .052, partial η2p = .39]. A main effect of trial type indicated shorter fixation durations on target-absent than on target-present trials [F(1, 8) = 126.39, p < .001, partial η2p = .94; absent: M = 167 ms, SE = 5 ms; present: M = 255 ms, SE = 11 ms], but we found no main effect of target type (p = .35, n.s.).
Animals versus humans: Proportion first fixations on the target
The results for this eye movement measurement were consistent with those in Experiment 1: There was only a main effect of set size [F(3, 24) = 38.81, p < .001, partial η2 = .83; all other ps > .37, n.s.]. The proportion of first fixations that landed on a target linearly decreased with set size [linear contrast: F(1, 8) = 70.49, p < .001, partial η2p = .90; Table 2].
Saliency model observers
Search slopes for animal targets among human distractors (M = 18 cycles/video, SE = 2 cycles/video) were steeper than search slopes for human targets among animal distractors [M = 12 cycles/video, SE = 2 cycles/video; t(7) = 4.19, p = .004].
Discussion
Participants were equally efficient at searching for animal and human targets when both types of stimuli were present in the search array: There were no significant differences between the two categories for search slopes. Furthermore, we did not find any differences for the two eye movement measurements when the target was present. These findings are somewhat surprising. Previous research with point-light stimuli suggested an advantage for human as compared to animal targets (Boucart et al., 2016; Pinto & Shiffrar, 2009). The discrepancy between the present and the previous findings might originate from the nature of the visual search paradigm. In the previous studies, observers were presented with human and animal stimuli on separate trials. In our Experiment 2, however, observers processed animals and humans in the same search display. To detect the target, the observers in Experiment 2 potentially had to also rely on form information, as the kinematics of human and animal motion are similar. This motion similarity may have been detrimental to search efficiency for human targets when animals were the distractors (e.g., Duncan & Humphreys, 1989). By comparison, the observers in Mayer et al. (2015) could rely on both form and motion information, leading to more efficient search for humans than for machines in dynamic natural scenes.
With respect to search slopes on target-absent trials, we found that searching arrays in which an animal target was absent (i.e., an array of human distractors only) was less efficient than searching arrays in which a human target was absent (i.e., an array of animal distractors only). Similarly, in Mayer et al. (2015) we found that search was less efficient when a machine target was absent and the search array consisted of human distractors than vice versa. Less efficient processing of arrays displaying human distractor videos may reflect attentional capture by a human body and motion (Mayer et al., 2017).
Consistent with Experiment 1, saliency model observers’ search patterns differed from the patterns of human observers. This indicates that human observers did not solely rely on low-level visual features when performing the search tasks, but most likely used other features, such as experience with human form and motion (Cavanagh et al., 2001).
Comparing search performance for animal and human targets across different distractors
Our previous results (Mayer et al., 2015) combined with our present ones suggest that the nature of the distractor may affect search efficiency (e.g., Duncan & Humphreys, 1989) in the current studies. To investigate this possibility further, we directly compared search performance on target-present trials for the different target–distractor category pairs in all experiments across this study and our previous one. First, we compared performance for animal targets among either machine or human distractors in Experiments 1 and 2 of this study. We found that search slopes were steeper with human than with machine distractors [human distractors: M = 67 ms/video, SE = 6 ms/video; machine distractors: M = 38 ms/video, SE = 6 ms/video; t(16) = 3.24, p = .005], indicating less efficient search for animal targets in the context of human distractors. Consistent with this, a higher proportion of first fixations landed on an animal target when the distractors were machines than when the distractors were humans [human distractors: M = .44; SE = .03; machine distractors: M = .62; SE = .04; t(16) = 3.83, p = .001]. Fixation durations on animal targets did not differ depending on whether the search array consisted of human or machine distractors [human distractors: M = 246 ms, SE = 10 ms; machine distractors: M = 225 ms, SE = 8 ms; t(16) = 1.63, p = .12, n.s.].
Second, we compared search performance for human targets among machine or animal distractors from Mayer et al. (2015) and from Experiment 2 of the present study. We found that search slopes were significantly steeper with animal than with machine distractors [animal distractors: M = 78 ms/video, SE = 10 ms/video; machine distractors: M = 35 ms/video, SE = 5 ms/video; t(11.13) = 3.84, p = .003, degrees of freedom corrected for unequal variances], indicating less efficient search for humans in the context of animal distractors. Consistent with this finding, the proportion of first fixations that landed on a human targets was higher when the distractors were machines than when the distractors were animals [machine distractors: M = .67, SE = .04; animal distractors: M = .44, SE = .03; t(15) = 4.74, p < .001]. Fixation durations on human targets did not differ depending on whether the search array consisted of animal or machine distractors [animal distractors: M = 263 ms, SE = 13 ms; machine distractors: M = 270 ms, SE = 9 ms; t(15) = 0.46, p = .65, n.s.].
Finally, we tested whether there were any search behavior differences between animal and human targets when they were searched for among the same machine distractors in, respectively, Experiment 1 of this study and Experiment 1 from Mayer et al. (2015). We found that search slopes did not differ for animal and human targets [animal targets: M = 38 ms/video, SE = 6 ms/video; human targets: M = 35 ms/video, SE = 5 ms/video; t(15) = 0.44, p = .67, n.s.]. Consistent with this finding, the proportions of first fixations on a target were the same for both animal and human targets [animal targets: M = .62, SE = .04; human targets: M = .67, SE = .04; p = .43, n.s.]. By comparison, fixation durations were shorter for animal than for human targets [animal targets: M = 225 ms, SE = 8 ms; human targets: M = 270 ms, SE = 9 ms; t(15) = 3.73, p = .002].
The results from the comparisons between different target–distractor category pairs suggest that search efficiency is affected by the similarity of the distractors to the targets. For both animal and human targets, search efficiency was reduced by distractors that had similar biological motion, relative to distractors that had more dissimilar mechanical motion and form (Duncan & Humphreys, 1989). Interestingly, we found that participants fixated on animal targets more briefly than on human targets when the same machines were the distractors, which suggests faster processing of animal than of human targets. However, this processing advantage for animals did not lead to more efficient search than for humans (or for machines, in Exp. 1) at the behavioral level (i.e., search slopes).
General discussion
In the present study, we asked whether search advantages for humans extend to other animate, biological categories, such as animals. Using a visual search paradigm, we measured search slopes as a proxy for search efficiency, and complemented the search slope with eye fixation measurements (fixation durations on targets and proportions of first fixations on targets; Bindemann, Scheepers, Ferguson, & Burton, 2010; Mayer et al., 2015, 2017). Searching for animals was effortful (i.e., no “pop-out”; Treisman & Souther, 1985; Wolfe, 1998). In contrast to our hypotheses, search efficiency was the same for animals and machines (Exp. 1), as well as for animals and humans (Exp. 2). The only advantage we found for animals in this study was a shorter processing time—as indexed by fixation duration—both relative to machines (Exp. 1) and relative to humans contrasted against the same machine-distractor category (Exp. 1 in this study and Exp. 1 from Mayer et al., 2015). Finally, model observers showed search patterns different from those of human observers, suggesting that human observers do not exclusively rely on low-level visual features of the videos during visual search.
There is evidence that human observers can quickly and accurately perceive other humans and animals, even from visually impoverished point-light stimuli (Beintema & Lappe, 2002; Bellefeuille & Faubert, 1998; Johansson, 1973; Kaiser et al., 2012; Mather & West, 1993; Troje & Westhoff, 2006). This implies that under more naturalistic conditions searching for biological targets would be more efficient than searching for mechanical targets, as we demonstrated previously for humans (Mayer et al., 2015, 2017). However, the results of Experiment 1 do not support this hypothesis, in that search efficiency was the same for both categories (i.e., animals and machines). There were shorter fixations on animals. Although this may reflect faster processing of individual items, it may not necessarily contribute to more efficient search. One possible explanation is that search efficiency may depend on both low-level visual features that allow for quick processing and top-down mechanisms. This is consistent with what we found for human targets in our previous studies (Mayer et al., 2015, 2017). In summary, the findings from Experiment 1 suggest that perceptual and neural mechanisms tuned for human form and motion (e.g., Cavanagh et al., 2001; Troje & Westhoff, 2006) may not generalize to other biological categories.
The next question was whether top-down and bottom-up mechanisms would lead to more efficient search for humans relative to animals. Observers generally have more experience and richer interactions with humans than with animals (Pinto & Shiffrar, 2009), which could potentially lead to additional top-down mechanisms tuned to humans (e.g., attentional sprites; Cavanagh et al., 2001). In line with this proposal, studies using point-light stimuli provide evidence that observers process human stimuli quicker and more accurately than nonhuman animal stimuli (Boucart et al., 2016; Han et al., 2013; Pinto & Shiffrar, 2009). For example, Pinto and Shiffrar found that observers processed human gait more accurately over horse gait. These previous findings comparing point-light humans and animals imply that under more naturalistic conditions searching for human targets would be more efficient than searching for animal targets. New et al. (2007) found higher accuracy in a change detection task for changes in humans than for changes in animals (but not in reaction times). The results from Experiment 2 did not support this hypothesis either, as search efficiency was the same for both biological categories. This was the case even when we compared search efficiency for the same machine distractors.
Different factors may contribute to why we did not find search efficiency differences between human and animal targets in the present study. First and foremost, this pattern of results may relate to the similarity of both the form and motion between humans and animals, which may increase the difficulty to discriminate between videos from these categories (e.g., Duncan & Humphreys, 1989). This assumption is in line with evidence from neuroimaging. Papeo, Wurm, Oosterhof, and Caramazza (2017) recently showed that regions in the right posterior STS discriminated between bipedal and quadrupedal motion in point-light stimuli across biological categories (e.g., upright walking human and walking chick vs. crawling human baby and walking cat), and that regions in the left posterior STS reliably decoded humans (adult walker and crawling baby) and animals (walking chick and walking cat). Animals and humans may be represented in similar brain regions, which may account for the similar search efficiencies for animals and humans in our study. Second, the familiarity of the actions may be important. Previous studies had used a limited number of common actions, such as running versus walking (Cavanagh et al., 2001; Papeo et al., 2017; Pinto & Shiffrar, 2009; Ruffieux et al., 2016; Troje & Westhoff, 2006). We used videos of humans and animals that performed a wider variety of both familiar and less familiar actions—for example, a person rolling on the ground, a person doing jumping jacks, a kangaroo moving its arms, and a chimpanzee climbing a tree. It might be that searching for human targets can be more efficient than searching for animals if familiar or typical actions are used, as these are the ones that are most likely encountered in everyday life and therefore may, for example, match attentional sprites developed during experience with human movements (Cavanagh et al., 2001).
Our previous studies (Mayer et al., 2015, 2017) revealed a search advantage for humans over machines. The present study showed similar search behavior when searching for animal targets among human distractors and vice versa. If search performance across categories were transitive, we would expect a search advantage for animals over machines. Our data did not confirm this transitivity as search behavior was not significantly different when searching for animal targets among machine distractors and vice versa (Exp. 1). This intransitivity supports the notion that search performance depends on the similarity between targets and distractors in a given search array (e.g., Duncan & Humphreys, 1989).
We note that the availability of motion information may contribute to the pattern of results in the present study. In our previous study (Mayer et al., 2015), we found a behavioral search advantage for human targets among machine distractors, as measured by search slope, irrespective of whether we presented videos or static images. However, we found that fixations on human targets were shorter than on machine targets for search arrays consisting of videos but not for arrays consisting of images. Based on these findings, we suggested that biological motion may facilitate target processing, as measured by fixation duration. In the present study, we did not find a behavioral search advantage for animal targets over machine targets even though biological motion was present in the videos. Other studies have shown that the detection of animals is more efficient than the detection of inanimate objects when static images are shown (e.g., New et al., 2007; Öhman et al., 2001). Thus, it may be possible that nonhuman biological motion can interfere with search efficiency. Future research will be needed to clarify whether and how different types of biological motion facilitates or interferes with search behaviors and how that relates to eye fixation patterns.
It is also worth noting that low-level features might have affected the pattern of results in the present Experiments 1 and 2 (see also Mayer et al., 2015). We showed that model observers needed more search cycles to detect an animal target for both human and machine distractors than vice versa. This finding suggests that the animal videos used in the present study were less salient than the ones containing humans or machines. This could lead to a potential disadvantage in detecting the animal videos, regardless of the distractor category. In our studies, the model observers searched for targets on the basis of the saliency of contrast, orientation, and motion features (Koch & Ullman, 1985; Parkhurst et al., 2002). Using these relatively simple low-level features, we found that the search behavior of the model observers differed from that of our human observers. Zhang et al. (2018) recently developed advanced computational models that searched for targets on the basis of more complex features that can better tolerate changes in object appearance; therefore, such models are more likely to capture the features used by human observers. Future research will be necessary to investigate whether these models can approximate human search behavior in dynamic natural scenes to increase our understanding of the underlying perceptual and neural processes during visual search. For instance, we could use the Zhang et al. computational models with our search paradigm and naturalistic videos.
Much of the evidence for specialized perceptual and neural mechanisms for human form and motion is based on studies that have used visually impoverished point-light stimuli (e.g., Cavanagh et al., 2001; Pinto & Shiffrar, 2009; Troje & Westhoff, 2006). Overall, the results of the present study, together with those of our previous studies (Mayer et al., 2015, 2017), highlight important limitations in generalizing from visually impoverished stimuli to more naturalistic ones. Perhaps more importantly, our results point to additional factors that may be important for processing ecologically relevant stimuli like humans and animals. Learning may be one factor that affects search efficiency. Human observers may learn the specific features of human body pose and movement, and this may contribute to the advantage in processing humans over other moving objects (e.g., Mayer et al., 2015, 2017). There is evidence that observers can learn to efficiently process the form and motion of specific animal species, which leads to measurable behavioral and neural changes (e.g., Kujala, Kujala, Carlson, & Hari, 2012; Wan, Bolger, & Champagne, 2012). Learning is not restricted to real animals; indeed, observers can also quickly learn novel “biological” stimuli within a single experimental session (Jastorff, Kourtzi, & Giese, 2006; Pyles, Garcia, Hoffman, & Grossman, 2007). Searching for animals may become more efficient than searching for machines after substantial learning. We included a familiarization phase, but this may not have been sufficient. On the other hand, any learning during the familiarization phase might also improve the detection of nonbiological motions, such as the ones performed by the machines in the videos used in our study. For example, Hiris (2007) found that detecting structured nonbiological motion was as good as detecting biological motion after a brief familiarization phase. The ecological saliency of humans and animals is a second factor that might affect search efficiency. For example, some studies have used static images of animals that have evolutionary relevance (e.g., snakes and spiders) and found increased search efficiency for these animals, relative to distractors such as plants, for both adults and children (Lobue & DeLoache, 2008; Öhman et al., 2001). It may be possible that searching for animal targets in natural dynamic scenes is more efficient than searching for machine targets if the animal targets are dangerous or threatening. Similarly, searching for humans performing threatening actions in natural scenes may be more efficient than searching for animals, as has been indicated by studies investigating detection efficiency using point-light stimuli (e.g., van Boxtel & Lu, 2012).
Conclusion
Previously we demonstrated that humans are detected more efficiently than machines in natural videos (Mayer et al., 2015, 2017), but here we found that this advantage did not extend to nonhuman animals. In combination with our previous findings, the present study thus highlights the importance of the similarity of form and motion between targets and distractors (e.g., Duncan & Humphreys, 1989) for search efficiency in natural scenes. Our findings also highlight other important factors to be systematically investigated in future research, including the variety and familiarity of actions performed by the targets, learning, and the potential (evolutionary) threat value of biological stimuli. The visual search paradigm provides a simple yet powerful way to investigate these factors.
References
Bahrick, L. E., Gogate, L. J., & Ruiz, I. (2002). Attention and memory for faces and actions in infancy: The salience of actions over faces in dynamic events. Child Development, 73, 1629–1643. doi:https://doi.org/10.1111/1467-8624.00495
Bardi, L., Regolin, L., & Simion, F. (2011). Biological motion preference in humans at birth: Role of dynamic and configural properties. Developmental Science, 14, 353–359. doi:https://doi.org/10.1111/j.1467-7687.2010.00985.x
Beintema, J. A., & Lappe, M. (2002). Perception of biological motion without local image motion. Proceedings of the National Academy of Sciences, 99, 5661–5663. doi:https://doi.org/10.1073/pnas.082483699
Bellefeuille, A., & Faubert, J. (1998). Independence of contour and biological-motion cues for motion-defined animal shapes. Perception, 27, 225–235. doi:https://doi.org/10.1068/p270225
Bertenthal, B. I., Proffitt, D. R., & Cutting, J. E. (1984). Infant sensitivity to figural coherence in biomechanical motions. Journal of Experimental Child Psychology, 37, 213–230. doi:https://doi.org/10.1016/0022-0965(84)90001-8
Bindemann, M., Scheepers, C., Ferguson, H. J., & Burton, A. M. (2010). Face, body, and center of gravity mediate person detection in natural scenes. Journal of Experimental Psychology: Human Perception and Performance, 36, 1477–1485. doi:https://doi.org/10.1037/a0019057
Blake, R., & Shiffrar, M. (2007). Perception of human motion. Annual Review of Psychology, 58, 47–73. doi:https://doi.org/10.1146/annurev.psych.57.102904.190152
Boucart, M., Lenoble, Q., Quettelart, J., Szaffarczyk, S., Despretz, P., & Thorpe, S. J. (2016). Finding faces, animals, and vehicles in far peripheral vision. Journal of Vision, 16(2), 10. doi:https://doi.org/10.1167/16.2.10
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial Vision, 10, 433–436. doi:https://doi.org/10.1163/156856897X00357
Bülthoff, I., Bülthoff, H., & Sinha, P. (1998). Top-down influences on stereoscopic depth-perception. Nature Neuroscience, 1, 254–257. doi:https://doi.org/10.1038/699
Cavanagh, P., Labianca, A. T., & Thornton, I. M. (2001). Attention-based visual routines: Sprites. Cognition, 80, 47–60. doi:https://doi.org/10.1016/s0010-0277(00)00153-0
Downing, P. E., Bray, D., Rogers, J., & Childs, C. (2004). Bodies capture attention when nothing is expected. Cognition, 93, B27–B38. doi:https://doi.org/10.1016/j.cognition.2003.10.010
Duncan, J., & Humphreys, G. W. (1989). Visual search and stimulus similarity. Psychological Review, 96, 433–458. doi:https://doi.org/10.1037/0033-295X.96.3.433
Eckstein, M. P. (2011). Visual search: A retrospective. Journal of Vision, 11(5), 14. doi:https://doi.org/10.1167/11.5.14
Faul, F., Erdfelder, E., Buchner, A., & Lang, A.-G. (2009). Statistical power analyses using G*Power 3.1: Tests for correlation and regression analyses. Behavior Research Methods, 41, 1149–1160. doi:https://doi.org/10.3758/BRM.41.4.1149
Fox, R., & McDaniel, C. (1982).The perception of biological motion by human infants. Science, 218, 486–487. doi:https://doi.org/10.1126/science.7123249
Giese, M. A., & Poggio, T. (2003). Neural mechanisms for the recognition of biological movements. Nature Reviews Neuroscience, 4, 179–192. doi:https://doi.org/10.1038/nrn1057
Grossman, E., Donnelly, M., Price, R., Pickens, D., Morgan, V., Neighbor, G., & Blake, R. (2000). Brain areas involved in perception of biological motion. Journal of Cognitive Neuroscience, 12, 711–720. doi:https://doi.org/10.1162/089892900562417
Han, Z. Z., Bi, Y. C., Chen, J., Chen, Q. J., He, Y., & Caramazza, A. (2013). Distinct regions of right temporal cortex are associated with biological and human-agent motion: Functional magnetic resonance imaging and neuropsychological evidence. Journal of Neuroscience, 33, 15442–15453. doi:https://doi.org/10.1523/jneurosci.5868-12.2013
Hiris, E. (2007). Detection of biological and nonbiological motion. Journal of Vision, 7(12), 4. doi:https://doi.org/10.1167/7.12.4
JASP Team. (2018). JASP (Version 0.10.0) [Computer software]. Retrieved from https://jasp-stats.org/download/
Jastorff, J., Kourtzi, Z., & Giese, M. A. (2006). Learning to discriminate complex movements: Biological versus artificial trajectories. Journal of Vision, 6(8), 791–804. doi:https://doi.org/10.1167/6.8.3
Johansson, G. (1973). Visual-perception of biological motion and a model for its analysis. Perception & Psychophysics, 14, 201–211. doi:https://doi.org/10.3758/bf03212378
Jeffreys, H. (1961). Theory of probability. Oxford, UK: Oxford University Press.
Kaiser, M. D., Shiffrar, M., & Pelphrey, K. A. (2012). Socially tuned: Brain responses differentiating human and animal motion. Social Neuroscience, 7, 301–310. doi:https://doi.org/10.1080/17470919.2011.614003
Kleiner, M., Brainard, D., & Pelli, D. (2007). What’s new in Psychtoolbox-3? Perception, 36(ECVP Abstract Suppl.), 14.
Koch, C., & Ullman, S. (1985). Shifts in selective visual attention: Toward the underlying neural circuitry. Human Neurobiology, 4, 219–227.
Kozlowski, L. T., & Cutting, J. E. (1977). Recognizing sex of a walker from a dynamic point-light display. Perception & Psychophysics, 21, 575–580. doi:https://doi.org/10.3758/bf03198740
Kujala, M. V., Kujala, J., Carlson, S., & Hari, R. (2012). Dog experts’ brains distinguish socially relevant body postures similarly in dogs and humans. PLoS ONE, 7, e39145. doi:https://doi.org/10.1371/journal.pone.0039145
Lange, J., & Lappe, M. (2006). A model of biological motion perception from configural form cues. Journal of Neuroscience, 26, 2894–2906.
Lobue, V., & DeLoache, J. S. (2008). Detecting the snake in the grass—Attention to fear-relevant stimuli by adults and young children. Psychological Science, 19, 284–289. doi:https://doi.org/10.1111/j.1467-9280.2008.02081.x
Mather, G., & West, S. (1993). Recognition of animal locomotion from dynamic point-light displays. Perception, 22, 759–766. doi:https://doi.org/10.1068/p220759
Mayer, K. M., Vuong, Q. C., & Thornton, I. M. (2015). Do people “pop out”? PLoS ONE, 10, e139618. doi:https://doi.org/10.1371/journal.pone.0139618
Mayer, K. M., Vuong, Q. C., & Thornton, I. M. (2017). Humans are detected more efficiently than machines in the context of natural scenes. Japanese Psychological Research, 59, 178–187. doi:https://doi.org/10.1111/jpr.12145
New, J., Cosmides, L., & Tooby, J. (2007). Category-specific attention for animals reflects ancestral priorities, not expertise. Proceedings of the National Academy of Sciences, 104, 16598–16603. doi:https://doi.org/10.1073/pnas.0703913104
Öhman, A., Flykt, A., & Esteves, F. (2001). Emotion drives attention: Detecting the snake in the grass. Journal of Experimental Psychology: General, 130, 466–478. doi:https://doi.org/10.1037/0096-3445.130.3.466
Papeo, L., Wurm, M. F., Oosterhof, N. N., & Caramazza, A. (2017). The neural representation of human versus nonhuman bipeds and quadrupeds. Scientific Reports, 7, 14040. doi:https://doi.org/10.1038/s41598-017-14424-7
Parkhurst, D., Law, K., & Niebur, E. (2002). Modeling the role of salience in the allocation of overt visual attention. Vision Research, 42, 107–123. doi:https://doi.org/10.1016/S0042-6989(01)00250-4
Pavlova, M., Krageloh-Mann, I., Sokolov, A., & Birbaumer, N. (2001). Recognition of point-light biological motion displays by young children. Perception, 30, 925–933. doi:https://doi.org/10.1068/p3157
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10, 437–442. doi:https://doi.org/10.1163/156856897X00366
Pinto, J., & Shiffrar, M. (2009). The visual perception of human and animal motion in point-light displays. Social Neuroscience, 4, 332–346. doi:https://doi.org/10.1080/17470910902826820
Pollick, F. E., Kay, J. W., Heim, K., & Stringer, R. (2005). Gender recognition from point-light walkers. Journal of Experimental Psychology: Human Perception and Performance, 31, 1247–1265. doi:https://doi.org/10.1037/0096-1523.31.6.1247
Pyles, J. A., Garcia, J. O., Hoffman, D. D., & Grossman, E. D. (2007). Visual perception and neural correlates of novel “biological motion.” Vision Research, 47, 2786–2797. doi:https://doi.org/10.1016/j.visres.2007.07.017
Ruffieux, N., Ramon, M., Lao, J. P., Colombo, F., Stacchi, L., Borruat, F. X., … Caldara, R. (2016). Residual perception of biological motion in cortical blindness. Neuropsychologia, 93, 301–311. doi:https://doi.org/10.1016/j.neuropsychologia.2016.11.009
Saygin, A. P. (2007). Superior temporal and premotor brain areas necessary for biological motion perception. Brain, 130, 2452–2461. doi:https://doi.org/10.1093/brain/awm162
Shi, J. F., Weng, X. C., He, S., & Jiang, Y. (2010). Biological motion cues trigger reflexive attentional orienting. Cognition, 117, 348–354. doi:https://doi.org/10.1016/j.cognition.2010.09.001
Simion, F., Regolin, L., & Bulf, H. (2008). A predisposition for biological motion in the newborn baby. Proceedings of the National Academy of Sciences, 105, 809–813. doi:https://doi.org/10.1073/pnas.0707021105
Thompson, J., & Parasuraman, R. (2012). Attention, biological motion, and action recognition. NeuroImage, 59, 4–13.
Thornton, I. M., Rensink, R. A., & Shiffrar, M. (2002). Active versus passive processing of biological motion. Perception, 31, 837–853.
Thornton, I. M., & Vuong, Q. C. (2004). Incidental processing of biological motion. Current Biology, 14, 1084–1089. doi:https://doi.org/10.1016/j.cub.2004.06.025
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12, 97–136. doi:https://doi.org/10.1016/0010-0285(80)90005-5
Treisman, A., & Souther, J. (1985). Search asymmetry—A diagnostic for preattentive processing of separable features. Journal of Experimental Psychology: General, 114, 285–310. doi:https://doi.org/10.1037/0096-3445.114.3.285
Troje, N. F., & Westhoff, C. (2006). The inversion effect in biological motion perception: Evidence for a “life detector”? Current Biology, 16, 821–824. doi:https://doi.org/10.1016/j.cub.2006.03.022
van Boxtel, J. J., & Lu, H. (2012). Signature movements lead to efficient search for threatening actions. PLoS ONE, 7, e37085. doi:https://doi.org/10.1371/journal.pone.0037085
Wagenmakers, E.-J., Wetzels, R., Borsboom, D., & van der Maas, H. L. J. (2011). Why psychologists must change the way they analyze their data: The case of psi. Comment on Bem (2011). Journal of Personality and Social Psychology, 100, 426–432. doi:https://doi.org/10.1037/a0022790
Walther, D., & Koch, C. (2006). Modeling attention to salient proto-objects. Neural Networks, 19, 1395–1407.
Wan, M., Bolger, N., & Champagne, F. A. (2012). Human perception of fear in dogs varies according to experience with dogs. PLoS ONE, 7, e51775. doi:https://doi.org/10.1371/journal.pone.0051775
Wolfe, J. M. (1998). What can 1 million trials tell us about visual search? Psychological Science, 9, 33–39. doi:https://doi.org/10.1111/1467-9280.00006
Wolfe, J. M., & Horowitz, T. S. (2004). What attributes guide the deployment of visual attention and how do they do it? Nature Reviews Neuroscience, 5, 495–501. doi:https://doi.org/10.1038/nrn1411
Wolfe, J. M., & Horowitz, T. S. (2017). Five factors that guide attention in visual search. Nature Human Behaviour, 1, 0058. doi:https://doi.org/10.1038/s41562-017-0058
Zhang, X., Dash, R. K., Jacobs, E. R., Camara, A. K. S., Clough, A. V., & Audi, S. H. (2018). Integrated computational model of the bioenergetics of isolated lung mitochondria. PLoS ONE, 13, e0197921. doi:https://doi.org/10.1371/journal.pone.0197921
Acknowledgements
Special thanks to Y. Tadmor for the provision of lab space and help with analyzing the eyetracking data.
Statement of Availability
The behavioral and eyetracking raw data will be made available upon request.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Mayer, K.M., Thornton, I.M. & Vuong, Q.C. Comparable search efficiency for human and animal targets in the context of natural scenes. Atten Percept Psychophys 82, 954–965 (2020). https://doi.org/10.3758/s13414-019-01901-6
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-019-01901-6