
Abstract
Spatial information can incidentally guide attention to the likely location of a target. This contextual cueing was even observed if only the relative configuration, but not the individual locations of distractor items were repeated or vice versa (Jiang & Wagner in Perception & Psychophysics, 66(3), 454-463, 2004). The present study investigated the contribution of global configuration and individual spatial location to contextual cueing. Participants repeatedly searched 12 visual search displays in a learning session. In a subsequent transfer session, there were four conditions: fully repeated configurations (same as the displays in the learning session), recombined configurations from two learned configurations with the same target location (preserving distractor locations but not configuration), rotated configurations (preserving configuration but not distractor locations), and new configurations. We could show that contextual cueing occurred if only distractor locations or relative configuration, randomly intermixed, was preserved in a single experiment. Beyond replicating the results of Jiang and Wagner, we made an adjustment to a particular type of transformation – that may have occurred in separate experiments – unlikely. Moreover, contextual cueing in rotated configurations showed that repeated configurations can serve as context cues even without preserved azimuth.
Similar content being viewed by others
Introduction
What regularities can be used as contextual cues to guide visual search in repeated displays? Chun and Jiang (1998) developed a well-defined paradigm to investigate this question. Participants were asked to search for the target T among some L-shaped distractors. There were two types of search displays: old and new displays. For the old displays, the layout of distractors presented in the first block was preserved across repetitions. For the new displays, the positions of distractors varied randomly across blocks. However, contextual cueing was observed even if only some aspects of the displays were repeated. Either repetition of global configuration or individual distractor locations alone sufficed to facilitate search speed (Jiang & Wagner, 2004). In their Experiment 1, Jiang and Wagner (2004) constructed search displays that consisted of half the distractor locations of one previously searched repeated display and half of the distractor locations of another searched repeated display that both shared the same target location. In this way, all distractor locations were repeated, but the display configuration was new. In contrast, in their Experiment 2, they rescaled and displaced previously searched displays, in this way changing the distractor locations but keeping the relative configuration intact (Fig. 1). Contextual cueing was observed in both experiments, indicating that both location and configuration cues contribute to contextual cueing.

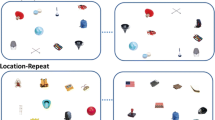
A schematic sample of the displays tested in Jiang and Wagner (2004, Experiment 2, redrawn after their original figure) and the present study (rotated configuration). All dotted parts and the letters A and B (see text for explanation) were not visible in the actual experiments
In the present study, similar to that of Jiang and Wagner (2004), we also investigated the contribution of global configuration and individual spatial location to contextual cueing. However, the present study differed from Jiang and Wagner’s work in two important aspects. First, Jiang and Wagner (2004) separately investigated the role of overall configuration and individual locations in two separate experiments. In contrast, we adopted a within-subjects design to investigate the contribution of the two kinds of cues to the contextual cueing effect. Second, we used a rotated configuration instead of the rescaling and displacing of configurations used in Jiang and Wagner (2004, Experiment 2). Jiang and Wagner had rescaled the search displays by a factor of 1.25 and additionally shifted the displays in one of the cardinal directions by 4.5°. These operations changed the item locations with reference to the computer screen but preserved the relative spatial relations within the configuration. For example, the upper half of Fig. 1 is a sketch from Jiang and Wagner (2004). The distractor ‘A’ appeared at the lower right of the target in the learning phase (figure on the upper left) and also in the transfer phase (figure on the upper right). However, participants might be flexible in choosing their spatial reference. For instance, if item locations are defined relative to the stimulus-filled area rather than the computer screen, item locations may essentially be unchanged by rescaling and displacement. For the related effect of target location probability cueing, a persistent bias towards the target-rich quadrant of the display has been shown (Jiang, Swallow, Rosenbaum, & Herzig, 2013), supporting the view that participants may flexibly adapt their reference frame to the actual stimulus-filled display borders rather than the screen borders. Therefore, we wanted to dissociate configuration and item locations in a more fundamental way by rotating the display by 45°. In the example in Fig. 1, the relative position between distractor ‘B’ and the target changed from the learning phase to the transfer phase from the lower left to the lower right of the target. In this way, a contextual cueing effect observed for the rotated displays would support the concept of contextual cueing by global configuration independent of item position more strongly than the original experiment by Jiang and Wagner (2004). Moreover, the random succession of four conditions – fully repeated, recombined, rotated, and new configurations – should make it much more difficult to adjust, perhaps implicitly, to one type of manipulation than in the experiments of Jiang and Wagner (2004).
To obtain contextual cueing from a rotated configuration is not trivial. In fact, Chua and Chun (2003) did not observe significant contextual cueing after rotation of a pseudo-3-D configuration for 30° or 45° in depth. Similarly, Tsuchiai, Matsumiya, Kuriki, and Shioiri (2012) observed contextual cueing for 3D configurations rotated in depth only when this rotation was caused by the motion of the observer to a new viewpoint. Similar restrictions were observed for target probability cueing (Jiang & Swallow, 2013).
In contrast, intact contextual cueing was observed after 90° rotation of a 2D configuration – actually smartphone icons – in the image plane, although successful contextual cueing was influenced by the exact way of transformation. Contextual cueing was preserved when local arrangements of neighboring icon clusters in the display center or at its edges were preserved after rotation (Shi, Zang, Jia, Geyer, & Müller, 2013). However, smartphone icons had different shapes and colors and the grid of the smartphone display was fully occupied, different from a classic contextual cueing display. Thus, participants rather learned the spatial arrangement of specific features than a spatial configuration of similar distractors.
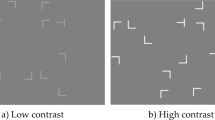
Since we were not interested in the question of viewpoint dependence that led to the 3D-rotation studies and because cueing appeared to survive 2D rotation better than 3D rotation, we chose 2D rotation to keep the configuration of search items intact while maximally altering the individual items' locations. Specifically, we manipulated global configuration and individual spatial location by using three repeated configurations: fully repeated, recombined, and rotated configurations. Fully repeated configurations were the same as the configurations shown in the learning session. Distractor locations in recombined configurations were randomly drawn from two fully repeated displays from the learning phase that shared the same target location (see Fig. 2). In this way, all distractor locations were repeated, but the configuration was destroyed. The displays of the rotated condition were formed by rotating fully repeated displays of the learning phase clockwise or counterclockwise by 45°. In this way, the configuration was preserved but the individual distractor locations were changed. In order to avoid a confound with the target probability effect, all four types of configurations (three repeated and one new) in the transfer session shared the same set of target locations.

A schematic illustration of the displays in four configurations during the transfer phase. In the actual experiment, the circle marking the target, the four concentric circles, and the straight line were all invisible. Configurations in the dotted line or in the solid line have the same target location
Following the report by Jiang and Wagner (2004), we hypothesized that all three repeated conditions would lead to contextual cueing, even though the presence of several types of repeated displays and the new display in one experiment might increase the difficulty of the memory-guided search.
Methods
Participants
In order to determine the appropriate sample size, we first calculated the effect size for the contextual cueing effect of the recombined condition in the study by Jiang and Wagner (2004). Their t-test resulted in t (14) = 2.32 from which we calculated the effect size \( dz=t/\sqrt{n} \) = 0.599. In turn, this effect size led to a required sample size of n = 26 for dependent means with α = 0.05 and 1-β = 0.90 (calculated with G-power, Faul et al., 2009).
Twenty-seven healthy young adults (11 females, 15 males) with a mean age of 25.3 years participated in this study. One participant’s data were excluded because of an unexpected program crash. Participants were all right-handed and had normal or corrected-to-normal visual acuity. All subjects were naïve to the purpose of the present research. After the experiment, the participants received a fixed payment of €8 or a 1-h study credit.
Equipment and stimuli
Participants were tested individually in a sound-attenuated chamber. They viewed a computer screen from a fixed distance of 57 cm by using a chin rest, at which 1 cm of distance corresponds to 1° of visual angle. The program was run by PsychoPy software and the experiment was conducted on a screen (resolution: 1,920 × 1,080 pixels; refresh rate: 60 Hz).
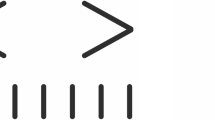
The displays consisted of an array of eleven white items (one T-shaped target and ten L-shaped distractors) that were presented on a black background (Fig. 2). The target T was rotated by 90o to the left or right and the distractors were rotated by 0o, 90o, 180o, or 270o, each individual letter’s orientation was randomly chosen for each trial. In order to increase the search difficulty, there was an offset of the line junction of the distractor Ls, making the distractors more similar to the target T (Jiang & Chun, 2001). To control item eccentricity, their positions were chosen on four imaginary concentric circles. Every circle comprised eight equidistant possible item locations. In order to ensure that the target was not immediately detected at display onset, target locations were chosen only on the three outer circles to obtain a minimum distance from central fixation.
Procedure
Participants were instructed to search the target T as fast as possible. They were asked to place the left index finger and the right index finger on the J and F keys of the keyboard, respectively, and indicate the target’s rotation (left or right) by pressing one of two buttons. Each trial started with a white fixation cross for 1s. Then a search display came on and remained visible until either a button was pressed to signal a judgment, or 10 s had elapsed. The search display was followed by 0.5 s of feedback with the word “correct” or “incorrect” shown on the screen.
The experiment consisted of a learning phase and a transfer phase. The learning phase consisted of 20 blocks of 12 trials and the transfer phase consisted of three blocks of 48 trials. Every 48 trials (four blocks in the learning phase, one block in the transfer phase) were followed by 10 s of rest. The transfer phase was followed by an explicit recognition test. The whole experiment lasted about 50 min.
Learning phase: Six target locations were drawn from the three outer imaginary concentric circles so that the polar angle between the two target positions on each circle was 45°. In this way, the two target positions could be exchanged with each other in the rotated condition of the transfer phase, keeping target location probability constant.
For each target location, 20 distractor locations were randomly selected from the 32 possible locations and randomly divided into two sets of ten locations. In this way, each target location was paired with two different sets of ten distractor locations. Twelve displays (six target locations × two sets of distractor locations) in total were presented in random order in each block.
Transfer phase: The transfer phase consisted of three blocks, each block contained 12 displays of four configuration types (fully repeated, recombined, rotated, and new; Fig. 2). The displays of the four configurations were randomly interleaved in the transfer session. The 12 fully repeated displays were the same as those presented during the learning phase. The 12 recombined displays also contained the same six target locations as the fully repeated displays. However, half of the distractors were selected randomly from each of the two distractor sets that were initially paired with the same target location in the learning phase. Because of the random selection, the configurations of the learning phase were completely destroyed. New displays also contained the same six target locations from the learning phase, but each target location was paired with two sets of randomly selected distractor locations. To keep learning of repeated and new displays comparable during the transfer phase, new displays were also repeated across transfer blocks. The rotated displays were generated by 45° clockwise or counterclockwise respectively rotation of one half each of the displays from the learning phase so that the target location probabilities of the six target locations were kept constant by this manipulation.
Recognition test: The recognition test consisted of a question section and an assessment section. In the question section, participants answered the question: “Do you think that some items’ configurations were repeated?”. If the answer was “yes,” the participant was asked the second question: “Did you deliberately try to memorize these configurations?”.
Subsequently, the 12 fully repeated, 12 recombined, and 12 rotated displays of the transfer session and 12 new configurations were presented. The newly created configurations shared the same set of target locations with the three types of repeated configurations. Participants’ task was to indicate whether they had seen the display before or not by pressing one of two buttons.
Results
Learning phase
Error trials and search times longer than 3 standard deviations from the mean reaction times (outliers) were excluded from the analysis. Overall error rates and outliers were quite low, namely 1.3% for target localization errors and 0.27% for outliers. Error rates and outliers did not differ between blocks, as assessed by one-way analyses of variance (F (19, 500) = 1.40, p > .1, ηp2 = 0.05 for target localization errors and F (19, 500) = 0.80, p > .1, ηp2 = 0.03 for outliers).
For the mean reaction times (RTs) without error trials, data were aggregated into epochs consisting of four blocks each, forming five epochs in total. We observed a significant main effect of epoch, analyzed by one-way analysis of variance (F (4, 125) = 6.23, p < .001, ηp2 = 0.13) due to the decreasing reaction times over epochs.
Transfer phase
Error rates (%) and outlier rates (%) based on means and SDs from each configuration and participant as a function of configuration are shown in Table 1. We calculated a Bayesian repeated-measures ANOVA of the error rates of the four configurations (fully repeated, recombined, rotated, and new configuration) that yielded a BF01 = 9.197 for the main effect of configuration. The same calculation method for the outlier rates yielded a BF01 = 7.523. The results thus provided substantial evidence for the equality of the four configurations in both error and outlier rates.
Trials with errors or outliers were excluded from the analysis of RTs. A one-way analysis of variance showed that the main effect of configuration was significant (F (3, 100) = 3.46, p < .05, ηp2 = 0.07).
We hypothesized that all three kinds of repeated displays (fully repeated, recombined, and rotated displays) would lead to a search time advantage compared with new displays. To test this hypothesis, we tested the linear contrast 3 * RT new – RT fully repeated – RT recombined – RT rotated versus zero that yielded t (25) = 7.367, p < 0.001, d = 2.04, confirming the hypothesis.
To further analyze if each repeated condition led to shorter reaction times compared with new displays, we used one-tailed paired-samples t-tests. After Bonferroni correction (Armstrong, 2014) for three comparisons (α = 0.05 / 3 = 0.017), as shown in Table 2, RTs in the new configuration were significantly longer than all of the three repeated configurations (fully repeated, recombined, rotated). Another family of three tests was calculated between the repetition conditions, to investigate potential differences in the amount of contextual cueing due to full or partial display repetition. These two-tailed paired-samples t-tests were not significant.
In order to test for equality of reaction times between the repeated conditions, we calculated Bayes factors for the fully repeated, recombined and rotated configuration. BF01 = 3.908 between recombined and rotated yielded substantial evidence for equality. BF01 = 1.830 between fully repeated and recombined and BF01 = 2.384 between fully repeated and rotated yielded anecdotal evidence for equality (Wetzels, Matzke, Lee, Rouder, Iverson, & Wagenmakers, 2011).
The mean RTs, separately for the last three blocks of the learning phase and the three blocks and four configurations (fully repeated, recombined, rotated and new) of the transfer phase, are presented in Fig. 3.

Mean response time in the last three blocks of the learning phase and four configurations (fully repeated, recombined, rotated, and new) of the transfer phase. Error bars represent standard errors of the mean. The statistical results can be seen in Table 2
Recognition test
Overall accuracy was 48.5%. Mean accuracy for fully repeated configurations was 51.6%, for recombined configurations 48.4%, for rotated configurations 49.4%, and for new configurations 55.6%. Two-tailed paired-samples t-tests indicated no significant deviations from chance level (50%), either for fully repeated (t (25) = 0.467, p = 0.644, d = 0.13), or for recombined (t (25) = -0.385, p = 0.703, d = 0.11) or rotated (t (25) = -0.167, p = 0.869, d = 0.05) or new configurations (t (25) = 1.668, p = 0.108, d = 0.47).
For fully repeated configurations, the hit rates were 26% for fully repeated configurations, 25% for recombined configurations, and 25% for rotated configurations. The false-alarm rate for new configurations was 22%. To rule out that the lack of significant differences was due to a lack of power, we also conducted Bayesian t-tests assessing whether the alarm rate was comparable to the hit rate in the three repeated configurations. BF01 = 2.376 in the recombined configuration and BF01 = 2.759 in the rotated configuration yielded anecdotal evidence for equality. In the fully repeated configuration, BF01 = 3.752 yielded substantial evidence for equality.
Discussion
The present study confirmed that the presence of global configuration or individual distractor locations alone can produce contextual cueing. Participants learned and flexibly used both global configuration or individual distractor location cues within the same experiment. Disrupting either the global configuration (recombined condition) or the individual distractor locations (rotated condition) did not remove contextual cueing, as long as the other cue was presented.
Beyond previous work (Jiang & Wagner, 2004), we observed configuration and location cueing in the same experiment instead of two separate experiments, reducing the chance that participants could adjust to one particular type of display change (recombined or rotated) in the transfer phase. Moreover, the present study investigated configurational cueing in rotated configurations instead of the rescaled and displaced displays of Jiang and Wagner (2004). Rotation prevented the use of a strategy to adapt the personal spatial reference frame to the stimulus-filled part of the monitor that could have been used in Experiment 2 of Jiang and Wagner (2004). Taken together, the results of both studies showed the high flexibility of configurational cueing.
While recombined and rotated displays led to significantly shorter reaction times than new displays, recombined and rotated reaction times were still numerically higher than for fully repeated displays. Bayes factors yielded only anecdotal evidence for equality of reaction times between fully repeated and either recombined or rotated displays. Thus, we cannot say that contextual cueing by recombined or rotated displays is as efficient as contextual cueing by fully repeated displays. It should be noted that the efficiency of contextual cueing may depend on parameters like the rotation angle for rotated displays or the number of items in recombined displays; therefore, we cannot make a generalizable statement of the relative impact of location and configuration information in the present study. In future studies, it might be worth investigating the impact of rotation or recombination by varying the rotation angle and the proportion of item number.
Could it be that the use of two manipulations in a single experiment led to carry-over effects in learning between conditions? We find it difficult to imagine that this created systematic dependencies between conditions. The similarity of our results with the results from separate experimental tests of contextual cueing by individual locations and global configuration reported by Jiang and Wagner (2004) rather suggested that contextual cueing by individual locations or global configuration occurred rather independently from each other.
Beesley, Vadillo, Pearson, and Shanks (2015) have noted that the recombination condition of Jiang and Wagner (2004), used again in our study, may still have contained partial configurational information in addition to the repeated distractor locations. However, we are confident that in the present study the random recombination of distractor locations destroyed the original configurations of the two original displays quite severely, as illustrated in Fig. 2.
The preserved contextual cueing effect for rotated configurations is in agreement with a previous study by Shi et al. (2013) that also found preserved contextual cueing after rotation - although in quite dissimilar displays (smartphone display icons) and with a more complex rearrangement of rotated display parts. Rotations in the depth plane of three-dimensional displays, however, appeared to be more detrimental to contextual cueing.
A post-experimental recognition test yielded no evidence for the explicit recognition of the fully repeated displays. There has been a debate about the validity of recognition tests for the contextual cueing paradigm (Colagiuri & Livesey, 2016; Vadillo, Konstantinidis, & Shanks, 2016). The main point of critique is the necessarily limited number of repeated displays and the associated limited power of recognition tests. In the present experiment, we tried to evaluate the likelihood of a "true" similarity of hit and false-alarm rates, supporting implicit learning, by calculating Bayes factor analyses between hits and false alarms for the repeated conditions. These analyses yielded moderate support for equality of hits and false alarms for the fully repeated displays and somewhat weaker support for the recombined and rotated displays. In any case, the analysis yielded more support for implicit than for explicit learning.
Conclusion
Our findings showed that both global configuration and individual locations can be used as contextual cues. This is true even when displays contain only configuration or location cues in random succession, making the adjustment to one category of cues difficult. Moreover, configurational cues were effective after 45° rotation, demonstrating a high flexibility of cueing by configurations.
References
Armstrong, R. A. (2014). When to use the Bonferroni correction. Ophthalmic and Physiological Optics, 34(5), 502-508. https://doi.org/10.1111/opo.12131
Beesley, T., Vadillo, M. A., Pearson, D., & Shanks, D. R. (2015). Pre-exposure of repeated search configurations facilitates subsequent contextual cuing of visual search. Journal of Experimental Psychology: Learning, Memory, and Cognition, 41(2), 348-362. https://doi.org/10.1037/xlm0000033
Chua, K. P., & Chun, M. M. (2003). Implicit scene learning is viewpoint dependent. Perception & Psychophysics, 65(1), 72-80.
Chun, M. M., & Jiang, Y. (1998). Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology, 36, 28-71. https://doi.org/10.1006/cogp.1998.0681
Colagiuri, B., & Livesey, E. J. (2016). Contextual cuing as a form of nonconscious learning: Theoretical and empirical analysis in large and very large samples. Psychonomic Bulletin & Review, 23(6), 1996-2009. https://doi.org/10.3758/s13423-016-1063-0
Faul, F., Erdfelder, E., Buchner, A., & Lang, A.-G. (2009). Statistical power analyses using G*Power 3.1: Tests for correlation and regression analyses. Behavior Research Methods, 41, 1149-1160.
Jiang, Y., & Chun, M. M. (2001). Selective attention modulates implicit learning. The Quarterly Journal of Experimental Psychology Section A, 54(4), 1105-1124.
Jiang, Y., & Wagner, L. C. (2004). What is learned in spatial contextual cueing—Configuration or individual locations? Perception & Psychophysics, 66(3), 454-463.
Jiang, Y. V., & Swallow, K. M. (2013). Spatial reference frame of incidentally learned attention. Cognition, 126(3), 378-390. https://doi.org/10.1016/j.cognition.2012.10.011
Jiang, Y. V., Swallow, K. M., Rosenbaum, G. M., & Herzig, C. (2013). Rapid acquisition but slow extinction of an attentional bias in space. Journal of Experimental Psychology: Human Perception and Performance, 39(1), 87-99.
Shi, Z., Zang, X., Jia, L., Geyer, T., & Müller, H. J. (2013). Transfer of contextual cueing in full-icon display remapping. Journal of Vision, 13(3): 2, 1-10. https://doi.org/10.1167/13.3.2
Tsuchiai, T., Matsumiya, K., Kuriki, I., & Shioiri, S. (2012). Implicit learning of viewpoint-independent spatial layouts. Frontiers in Psychology, 3, 207. https://doi.org/10.3389/fpsyg.2012.00207
Vadillo, M. A., Konstantinidis, E., & Shanks, D. R. (2016). Underpowered samples, false negatives, and unconscious learning. Psychonomic Bulletin & Review, 23(1), 87-102.
Wetzels, R., Matzke, D., Lee, M. D., Rouder, J. N., Iverson, G. J., & Wagenmakers, E. J. (2011). Statistical evidence in experimental psychology: An empirical comparison using 855 t tests. Perspectives on Psychological Science, 6(3), 291-298.
Acknowledgements
This work was supported in part by the China Scholarship Council (NO.201808120093).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zheng, L., Pollmann, S. The contribution of spatial position and rotated global configuration to contextual cueing. Atten Percept Psychophys 81, 2590–2596 (2019). https://doi.org/10.3758/s13414-019-01871-9
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-019-01871-9