
Abstract
Eriksen and Eriksen (Perception & Psychophysics, 16, 143–149, 1974) explained the flanker compatibility effect in terms of response competition. A simplified version of the original flanker task, featuring a 1-to-1 mapping of stimuli onto responses, has become prominent in the literature. Compatible flanker trials present identical items (HHHHH), whereas incompatible trials present different items (HHSHH). The 1-to-1 mapping is potentially problematic because it invites a strategy that people could use to perform the task. Subjects could first determine whether all the items are the same and focus attention on the central target only if they are not. Response times (RTs) would be longer for incompatible trials partly because they require the extra step of focusing attention. We tested this conditional focusing hypothesis by combining a 1-to-1 flanker task with a digit probe detection procedure. In half of the trials, the digit ‘7’ appeared immediately after the response to the flanker display, at the target or a flanker location. Three experiments showed a V-shaped function of RTs to digits across locations that was not modulated by flanker compatibility. These results demonstrate that subjects focused attention on the central target regardless of the same/different configuration of the display, refuting the conditional focusing hypothesis. Our findings support Eriksen and Eriksen’s original interpretation of the flanker task.
Similar content being viewed by others


Introduction
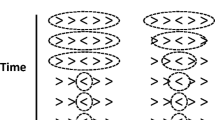
Eriksen and Eriksen (1974) introduced the flanker task to measure the size of the attentional spotlight in target identification by manipulating the nature and proximity of surrounding noise elements (see also Eriksen & Hoffman, 1973). Subjects were instructed to identify a target letter, which always appeared at the center of the display to eliminate visual search, and ignore surrounding letters. Subjects responded with a lever movement in one direction if the target letter was an H or a K, and in the other direction if it was an S or a C. Several experimental conditions were used, but we will focus on three of them for present purposes. In the same flanker condition, the target letter was flanked on each side by three identical letters (e.g., HHHHHHH). In the compatible flanker condition, the target letter was flanked on each side by three different letters from the same response set (e.g., KKKHKKK). In the incompatible flanker condition, the target letter was flanked on each side by three different letters from the opposite response set (e.g., SSSHSSS). Behavioral results from six subjects showed a flanker compatibility effect: responses were slower and less accurate in the incompatible flanker compared to compatible and same flanker conditions. By contrast, response times (RTs) and accuracy data were not significantly different between compatible and same flanker conditions, suggesting that the flanker compatibility effect is the result of response competition. The flanker compatibility effect has been replicated using a wide variety of visual stimuli such as colors (Servant, Montagnini, & Burle, 2014) or arrows (Ridderinkhof, van der Molen, & Bashore, 1995), and has contributed to investigations of a wide variety of problems in both cognitive, developmental, and clinical psychology (e.g., Cragg, 2016; Eriksen, Eriksen, & Hoffman, 1986; Eriksen, O'Hara, & Eriksen, 1982; Eriksen, Pan, & Botella, 1993; Eriksen & St James, 1986; Evans, Craig, & Rinker, 1992; LaBerge, Brown, Carter, Bash, & Hartley, 1991; Richardson, Anderson, Reid, & Fox, 2011; Ridderinkhof, Scheres, Oosterlaan, & Sergeant, 2005; Ridderinkhof, van der Molen, Band, & Bashore, 1997; Rueda, Fan, et al., 2004; Rueda, Posner, Rothbart, & Davis-Stober, 2004b; Servant, van Wouwe, Wylie, & Logan, 2018; Skelton & Eriksen, 1976; Ste-Marie & Jacoby, 1993; Wylie et al., 2009).
Eriksen and colleagues (Coles, Gratton, Bashore, Eriksen, & Donchin, 1985; C. W. Eriksen, Coles, Morris, & O'Hara, 1985; Gratton, Coles, Sirevaag, Eriksen, & Donchin, 1988) later simplified the original flanker design to increase the number of observations per subject in experiments using noisy electrophysiological measures. Participants had to make a squeeze response with one hand if the central letter was an H, and with the other hand if the central letter was a S. There were only two conditions: compatible flanker (HHHHH or SSSSS) versus incompatible flanker (HHSHH or SSHSS). Note that this task variant implies a 1-to-1 mapping of stimuli onto responses instead of the original 2-to-1 mapping. Electrophysiological data provided strong evidence for response competition. In particular, analyses of the electromyographic activity of the response agonists revealed an incorrect muscle activation in some trials where the correct response was overtly executed. The proportion of these so-called “partial errors” was greater in the incompatible flanker condition. The 1-to-1 flanker task has become prominent in the literature (e.g., Ridderinkhof et al., 2005; Ridderinkhof et al., 1997; Rueda, Fan, et al., 2004; Servant, White, Montagnini, & Burle, 2015; Wylie et al., 2009), and has routinely been used to test computational models of the flanker compatibility effect (Hübner & Töbel, 2012; Servant et al., 2014; Ulrich, Schroter, Leuthold, & Birngruber, 2015; White, Brown, & Ratcliff, 2011a; White, Ratcliff, & Starns, 2011b).
The use of a 1-to-1 mapping is potentially problematic because it invites a strategy that people could use to perform the task. It is not necessary to focus attention on the central target in the compatible flanker condition, because all items are identical, but it is necessary to focus on the central target in the incompatible flanker condition to produce a correct response. Subjects could perform the task by first determining whether all the items are the same and focusing attention on the central target only if they are not, a strategy hereafter referred to as conditional focusing. Because focusing takes time, this strategy would generate longer RTs in the incompatible than in the compatible flanker condition. The evidence for response competition in the 1-to-1 situation suggests that conditional focusing cannot account for the entire flanker effect, but the question remains whether conditional focusing contributes something to the flanker effect. If this were the case, then researchers interested in studying response competition and compatibility effects should avoid the 1-to-1 version. If not, then researchers might prefer the 1-to-1 version because it is more efficient (faster RTs, so less noisy RTs, thereby allowing smaller samples). The goal of our research was to evaluate the plausibility of the conditional focusing strategy.Footnote 1
To assess this strategy, we combined a 1-to-1 flanker task with a probe detection procedure inspired by studies of LaBerge and colleagues (LaBerge, 1983; LaBerge & Brown, 1986, 1989). Probe RTs allow us to infer the shape of the attentional spotlight in the flanker task. In half of the trials, the digit probe ‘7’ appeared immediately after the response to the flanker display, at the target or a flanker location (five possible locations). RTs to the digit probe at location x should decrease monotonically with the quantity of attention allocated to location x (LaBerge, 1983). The standard interpretation of the flanker effect predicts faster RTs to probes in the central position in both compatible and incompatible conditions, as attention would be focused on the central target. Probe RTs should increase progressively as the distance from the center increases, producing a V-shaped function in both compatible and incompatible conditions. The conditional focusing strategy predicts different patterns of probe RTs for compatible and incompatible conditions. If subjects do not focus attention on the central target in the compatible condition, probe RTs should be invariant across the five locations, producing a flat function. Subjects have to focus attention on the central target in the incompatible condition, so a V-shaped function should be observed. Experiment 1 tested these alternative hypotheses. Experiment 2 was designed to rule out an alternative explanation of V-shaped functions in terms of visual acuity. Experiment 3 evaluated whether the demands to coordinate the flanker task with a detection task modulated the magnitude of the compatibility effect.
Experiment 1
Method
Participants
The number of subjects in 1-to-1 flanker tasks generally ranges from six to 28 in the literature (e.g., Coles et al., 1985; Eriksen et al., 1985; Gratton et al., 1988; Ridderinkhof et al., 1997; Servant et al., 2014; Servant et al., 2015; Ulrich et al., 2015; White, Ratcliff, et al., 2011; Wylie et al., 2009). However, the measure of interest in our experiments was the RT to digit probes. We originally sought to determine our sample size by computing a power analysis based on effect sizes reported in prior work that used a similar probe detection procedure (e.g., LaBerge & Brown, 1986, 1989). However, LaBerge and Brown did not report effect sizes in their studies, the sample size of which ranged from eight to 20 subjects. We opted for a sample size of 24 subjects in each experiment reported in this paper, and 40–50 trials per probe detection condition. The combination of a relatively large sample size and number of trials per condition should offer considerable power, because we assumed stochastic dominance in both flanker and probe detection tasks (Rouder & Haaf, 2018).
Twenty-four volunteers (20–30 years of age, eight males, two left-handed subjects) participated in the experiment in exchange for monetary compensation. They had normal or corrected-to-normal vision. Informed consent was obtained prior to the beginning of the experiment. All procedures were approved by the Vanderbilt Institutional Review Board.
Stimuli and apparatus
The experiment was written in Python, using components of the PsychoPy toolbox (Peirce, 2007). The experiment was run on a PC computer (CPU: AMD A6-6400K; GPU: AMD RADEON R9 200 Series) operating with a Windows 7 system. Stimuli were displayed on a BENQ XL2411 LCD monitor with a refresh rate of 144 Hz. Each stimulus array in the flanker task consisted of five black letters (H or S; font: Lucida Console) presented on the horizontal midline of a 49.91° × 28.07° gray field, based on a distance of 60 cm from eye to screen. Each letter subtended visual angles of 0.19° horizontally and 0.29° vertically, with a separation of 0.18° between letters. Altogether, flanker displays subtended 1.67° horizontally. Stimuli in the compatible flanker condition were HHHHH or SSSSS. Stimuli in the incompatible flanker condition were HHSHH or SSHSS. Participants responded to stimuli by pressing a left or right key (‘f’ and ‘j’, respectively, on an American QWERTY keyboard) with the left or right index. A warning signal (red square; 0.18° × 0.18°) was presented at the center of the screen at the beginning of each trial. The stimulus in the probe detection task was the digit ‘7’ (0.19° × 0.29°; font: Lucida Console), presented at the target or a flanker location (5 possible locations). Participants responded to the digit by pressing the space bar with their dominant thumb.
Procedure
Participants were tested in a normally lighted room. They were instructed to respond as quickly and accurately as possible to the central letter (H vs. S), and ignore surrounding letters. Half of the participants gave a left response to the letter H, and a right response to the letter S. This mapping was reversed for the other half. Participants were further instructed to press the space bar with their dominant thumb if the digit ‘7’ appeared immediately after their response. Each trial was defined by a factorial combination of target letter (H vs. S), flanker compatibility (compatible vs. incompatible), digit presence (present vs. absent), and digit location (five possible slots). All types of trials occurred equally often, and were presented in a random order. Each trial started with a red square warning signal, followed by a 250-ms blank screen. The flanker stimulus array was then presented, with a maximum duration of 1,500 ms. If participants failed to respond by then, “TOO LATE! PLEASE RESPOND FASTER” was displayed on the screen for 5,000 ms. If a response was given within the time limit, the stimulus array was removed and was immediately followed by the presentation of the digit ‘7’ on half of the trials. The digit remained on the screen until the spacebar was pressed. The interval between the response to the flanker array and the beginning of the next trial was always 1,500 ms, regardless of the presence of the digit. A space-bar press within this interval in digit-present trials was registered as a hit. A space-bar press within this interval in digit-absent trials was registered as a false alarm. Participants first completed ten practice trials to ensure they understood the task, and then worked through ten blocks of 100 trials in a single session lasting approximately 60 min. Practice trials were discarded from analyses.
Data analyses
Statistical tests were performed by means of repeated-measures ANOVAs. For each test, we report a partial eta-squared ηp2 statistic as a measure of effect size. The assumption of sphericity was tested by Mauchly’s test (1940). When sphericity was violated, degrees of freedom were adjusted according to the procedure developed by Greenhouse and Geisser (1959). To evaluate whether RTs to digits as a function of location exhibit a V-shape, we used a V-shaped contrast with the following weights: 4 (left outer flanker location), -1 (left inner flanker), -6 (central target), -1 (right inner flanker), 4 (right outer flanker).
Results
Flanker task
Anticipations (responses faster than 100 ms: 0%) and trials in which participants failed to respond (.18%) were discarded from analyses. Figure 1a shows the mean RT of correct responses and accuracy rate for each compatibility condition. There was a reliable flanker compatibility effect on mean RT (M = 62 ms), F(1, 23) = 335.27, MSE = 137.37, p < .001, ηp2 = .94. Accuracy rate was also significantly higher for the compatible than the incompatible condition (M = 2.1%), F(1, 23) = 46.74, MSE = .0001, p < .001, ηp2 = .67.

Behavioral data from Experiment 1 (a, b) and Experiment 2 (c-f). Left panels show mean response times (RTs) of correct responses and accuracy data in the choice tasks. Right panels display the mean RT to digits in the probe detection task as a function of condition in the choice task and digit location. Digit location is expressed as the relative distance from the center of the screen (-2: left outer flanker; -1: right inner flanker; 1: right inner flanker; 2: right outer flanker). The dashed line shows RTs to digits averaged across choice task conditions. Error bars indicate ±1 within-subjects standard error of the mean (Morey, 2008)
Digit detection
The percentage of hits and false alarms was 99.82% and 3.15%, respectively. The percentage of anticipations was .03%. Figure 1b shows the mean RT for hits as a function of position and flanker compatibility (compatible vs. incompatible). Trials in which an incorrect response was made to the flanker display were discarded. An ANOVA on mean RT revealed a main effect of compatibility F(1, 23) = 17.21, MSE = 617.26, p < .001, ηp2 = .43, a main effect of position F(4, 92) = 3.76, MSE = 241.90, p = .007, ηp2 = .14, but no significant interaction between the two factors F(2.90, 66.78) = 1.54, MSE = 264.95, p = .21, ηp2 = .06. These results show that RTs to digits were generally faster in the incompatible than the compatible condition, and increased as the distance from the center increased in a similar fashion between compatibility conditions. The latter was further evaluated by computing a V-shaped contrast for the main effect of position (contrast 1), and another V-shaped contrast for the interaction between position and compatibility (contrast 2). Contrast 1 reached significance (t(23) = 2.66, p = .01) while contrast 2 did not (t(23) = 0.84, p = .41), suggesting that RTs to digits follow a V-shaped function, and this function is not modulated by compatibility. These analyses confirm that subjects focused attention on the central target in both compatible and incompatible conditions.
Discussion
The aim of Experiment 1 was to determine whether subjects perform 1-to-1 flanker tasks by first evaluating whether all the items are the same and focusing attention on the central target only if they are not. Our results speak against this hypothesis. Digit probe trials generated a V-shaped function of RT across probe positions that was not modulated by flanker compatibility, showing that subjects focused attention on the target regardless of the same/different configuration of the display. These results are fully consistent with the standard response competition account (Eriksen & Eriksen, 1974).
Empirical investigations of cone distribution across the retina and psychophysical studies have revealed a progressive decrease of visual acuity as the distance between the visual stimulation and foveal vision increases (e.g., Curcio, Sloan, Packer, Hendrickson, & Kalina, 1987; Green, 1970; Osterberg, 1935). Thus, the observed V-shaped functions may not be caused by attentional focusing, but may instead reflect visual acuity. To rule out this alternative hypothesis, it is necessary to demonstrate a flat RT function in a condition that requires a homogenous allocation of attention across our five locations. Experiment 2 was designed to test this premise.
Experiment 2
LaBerge (1983) used a digit probe detection technique to investigate the spatial extent of attention when subjects categorized five-letter words versus the middle letter of five-letter words. The attentional field should be focused on the central letter in the letter categorization task, and broadly distributed across the five positions in the word categorization task. Accordingly, digit probe trials generated a V-shaped function in the letter categorization task, and a relatively flat function in the word categorization task. These results speak against an interpretation of V-shaped functions in terms of visual acuity, and show that the digit probe detection procedure is a valid measure of the attentional field. However, the separation between letters in LaBerge’s study (.08°) was smaller compared to the separation used in Experiment 1 (.18°). Consequently, the impact of visual acuity on our results remains unclear.
In Experiment 2 we had two goals. The first goal was two replicate empirical results from Experiment 1. The second goal was to rule out an alternative interpretation of V-shaped functions in terms of visual acuity. Participants completed two tasks on two different days (task order counterbalanced). One of the tasks was a flanker task similar to Experiment 1, with a few minor methodological differences (see Methods). The other task was a five-letter word categorization task (living versus nonliving), which required attention to all five letters. Each task was administered with and without digit probes. If the digit probe procedure is a valid measure of the attentional field, we should observe a V-shaped function in probe RTs in the flanker task and a flat function in the word categorization task.
Method
Participants
Twenty-four native English speakers (18–28 years of age, seven males, three left-handed subjects) volunteered in the experiment in exchange for monetary compensation. None of them participated in Experiment 1. All participants had normal or corrected-to-normal vision. Informed consent was obtained prior to the beginning of the experiment. All procedures were approved by the Vanderbilt Institutional Review Board.
Stimuli and apparatus
Stimuli for the flanker task were identical to Experiment 1, except for the warning signal that featured five red symbols **#**, with symbol # marking the center of the screen where the target subsequently appeared and symbols * marking each flanker location. Stimuli for the word categorization task were 20 five-letter words belonging to the living category (e.g., BISON, MOUSE) and 20 five-letter words belonging to the nonliving category (e.g., KNIFE, STAMP). The words in each list were associated with at least 90% agreement on living/nonliving semantic judgments, based on a study performed by Polyn, Kragel, Morton, McCluey, and Cohen (2012) on a pool of 42 native English speakers from the USA. The word frequency averaged 11.58 per million for the living category and 11.47 per million for the nonliving category (based on the SUBTLEX-US index, Brysbaert & New, 2009), t(38) = .04, p = .97. Words are provided in the Appendix 1. The warning signal for the word categorization task featured five identical red symbols #####, each symbol # marking a letter location. The digit probe was identical to Experiment 1, and identical between flanker and word categorization tasks.
Procedure
Participants completed the flanker task and the word categorization task in two separate sessions occurring on different days, with a maximum of 3 days between sessions. Task order was counterbalanced across subjects. Experimental procedures for the flanker task and the digit detection task were similar to Experiment 1, except that the RT deadline and the latency between the response and the next trial were set to 1,700 ms (instead of 1,500 ms). The structure of a trial in the word categorization task was similar to the structure of a trial in the flanker task, except that the stimulus was a five-letter word belonging to the living or the nonliving category. Each word was repeated 20 times across the experiment. All types of trials were equally frequent and presented in a random order. Participants were instructed to decide as quickly and accurately as possible whether the word referred to a living or a nonliving thing. Half of the participants gave a left response for a living thing, and a right response for a nonliving thing. This mapping was reversed for the other half. For each session, participants first completed ten practice trials to ensure they understood the task, and then worked through eight blocks of 100 trials. Practice trials were discarded from analyses. Each session lasted approximately 50–60 min depending on the task completed.
Results
Flanker task
Anticipations (.005%) and trials in which participants failed to respond (.05%) were discarded from analyses. Figure 1c shows the mean RT of correct responses and accuracy rate for each compatibility condition. There was a reliable flanker compatibility effect on mean RT (M = 52 ms), F(1, 23) = 194.45, MSE = 168.20, p < .001, ηp2 = .89. Accuracy rate was also significantly higher in the compatible than the incompatible condition (M = 2.6%), F(1, 23) = 26.15, MSE = .0003, p < .001, ηp2 = .53.
Word categorization task
Anticipations (0%) and trials in which participants failed to respond (.13%) were discarded from analyses. Figure 1e shows the mean RT of correct responses and accuracy rate for living and nonliving categories. RTs to living items were faster than RTs for nonliving items, F(1, 23) = 13.81, MSE = 456.47, p < .001, ηp2 = .38. Accuracy was relatively high and did not significantly differ between the two categories, F(1, 23) = 1.46, MSE = .0004, p = .24, ηp2 = .06.
Digit detection
The percentage of hits and false alarms was 99.93% and 3.67% for the flanker task, and 99.91% and 3.98% for the word categorization task. The percentage of anticipations was .55% for the flanker task, and .12% for the categorization task. Figure 1d and f show mean RT to digits across the five locations for the flanker task and the word categorization task, respectively. An ANOVA on mean RT to digits in the flanker task with digit position and flanker compatibility as factors revealed a main effect of compatibility F(1, 23) = 9.06, MSE = 450.67, p = .006, ηp2 = .28, a main effect of position F(2.94, 67.64) = 6.02, p = .001, ηp2 = .21, but no significant interaction between the two factors F(4, 92) = .79, p = .54 MSE = 255.08, ηp2 = .03. We then computed a V-shaped contrast for the main effect of position (contrast 1), and another V-shaped contrast for the interaction between position and compatibility (contrast 2). Contrast 1 reached significance (t(23) = 3.55, p = .002) while Contrast 2 did not (t(23) = 1.09, p = .29). These results replicate findings from Experiment 1: RTs to digits were generally faster in the incompatible than the compatible condition, and increased as the distance from the center increased in a similar fashion between compatibility conditions.
An ANOVA on mean RT to digits in the word categorization task with digit position and category as factors revealed a small trend for main effect of category F(1, 23) = 3.19, MSE = 1565.52, p = .09, ηp2 = .12, reflecting slightly slower RTs in the nonliving compared to the living condition. Neither the main effect of position nor the interaction between category and position reached significance, F(2.98, 68.57) = .36, MSE = 456.30, p = .78, ηp2 = .02 and F(4, 92) = 1.50, MSE = 241.57, p = .21, ηp2 = .06, respectively. These results suggest that attention was broadly distributed across the five letter locations. This was confirmed by non-significant V-shaped contrasts for the main effect of position (t(23) = .12, p = .91) and for the interaction between position and category (t(23) = 1.35, p = .19).
We finally computed a mixed-design ANOVA comparing probe RTs in the flanker task with probe RTs in the word task. We collapsed data across compatibility conditions in the flanker task (since there was no interaction), and collapsed data across living/nonliving conditions in the word categorization task (since there was no interaction). This analysis revealed a significant task × position interaction, F(4, 92) = 2.81, p = .03, ηp2 = .11. The V-shaped contrast for the task × position interaction was also significant (t(23) = 2.86, p = .008), providing further evidence for different probe RT functions in the two tasks.
Discussion
The pattern of results from Experiment 2 replicates findings from Experiment 1, and rules out an alternative explanation of V-shaped functions in terms of visual acuity. Consistent with LaBerge (1983), we found a flat RT function in the word categorization task, showing that the digit detection procedure is a valid measure of the attentional field. These findings demonstrate that subjects do not perform the 1-to-1 flanker task by first determining whether all the items are the same and focusing attention on the central target only if they are not.
Consistent with Experiment 1, we found that RTs to digit probes were significantly faster after incompatible than compatible flanker trials. The additive effect of position and flanker compatibility on digit detection performance suggests that this modulation is caused by a stage of processing not related to attentional focusing (Sternberg, 1969, 2011). We shall come back to this peculiarity of the data in the general discussion.
Results from Experiments 1 and 2 speak against a conditional focusing strategy in the 1-to-1 version of the flanker task. However, it is possible that the demands to coordinate the flanker task with a probe detection task altered processing in the flanker task. To rule out this possibility, it is necessary to compare the magnitude of the flanker effect in this dual-task coordination context against the magnitude of the flanker effect in a pure 1-to-1 flanker task.
Experiment 3
Lavie, Hirst, de Fockert, and Viding (2004) evaluated the effect of dual-task coordination on the magnitude of the flanker compatibility effect. In dual-task blocks, the flanker task was preceded by a short-term memory task in which participants had to decide whether a memory set matched a memory probe. Single-task blocks were visually similar to dual-task blocks, but subjects were instructed to respond to the flanker task and ignore the short-term memory task. Results showed a larger flanker compatibility effect on mean RT in the dual-task compared to the single-task condition. Lavie and colleagues argued that dual-task coordination exhausts cognitive control resources, thereby hampering the efficiency of selective attention. The demands to coordinate a flanker task with a digit probe detection task in Experiments 1 and 2 might thus have altered processing in the flanker, preventing generalization of our results to standard 1-to-1 flanker tasks. Experiment 3 was designed to test this hypothesis by comparing performance in alternating dual- and single-task blocks. Dual-task blocks were similar to Experiments 1 and 2: the flanker task was followed by a digit probe detection task. Single-task blocks were visually similar to dual-task blocks, but participants were instructed not to respond to the digit ‘7’ if it appeared after the response to the flanker array. If the demands to coordinate a flanker task with a digit probe detection task hamper the efficiency of selective attention, the magnitude of the flanker compatibility effect should be larger in dual-task compared to single-task blocks.
Method
Participants
Twenty-four volunteers (19–34 years of age, seven males, three left-handed subjects) participated in the experiment in exchange for monetary compensation. None of them participated in Experiments 1 and 2. All subjects had normal or corrected-to-normal vision. Informed consent was obtained prior to the beginning of the experiment. All procedures were approved by the Vanderbilt Institutional Review Board.
Stimuli and apparatus
Stimuli for the flanker task and the probe detection task were identical to Experiment 1.
Procedure
The procedure for the dual-task condition was identical to Experiment 1. The single-task condition was similar to the dual-task condition, expect that participants were required to ignore the digit ‘7’ whenever it appeared after the response to the flanker array. The digit seven was presented during 369 ms, which corresponds to detection times averaged across Experiments 1 and 2. Single-task and dual-task conditions were thus visually similar to one another, and differed only with respect to task switching. Participants completed eight single- and eight dual-task blocks of 100 trials each, in a single session lasting approximately 110 min. Single-task and dual-task blocks alternated. Half of the subjects began with a single-task block, and the other half began with a dual-task block. At the beginning of the experiment, participants were told that they would be presented with single-task and dual-task blocks in alternation. Task instructions were specified at the beginning of each block. The experimental session was preceded by 24 practice trials, organized in two short blocks of 12 trials each. Participants were trained in the single-task condition in the first block, and were then trained in the dual-task condition in the second block. Practice blocks were discarded from analyses.
Results
To avoid contamination of results by failures to comply with task instructions, any dual-task block was excluded from analyses if the percentage of misses was greater than 10%. Similarly, any single-task block was excluded from analyses if the percentage of hits was greater than 10%. Participants complied with task instructions, as revealed by low percentages of rejected blocks in both single-task (M = 1.56%; range 0-12.50%) and dual-task (M = 3.13%; range 0-25%) blocks, t(23) = .82, p = .42. None of the participants had more than two blocks rejected across conditions. Statistical inferences remained identical when no blocks were excluded from analyses.
Flanker task
Anticipations (responses faster than 100 ms; dual-task: .02%, single-task: .01%) and trials in which participants failed to respond (dual-task: .12%, single-task: .12%) were discarded from analyses. Figure 2a shows mean RT of correct responses and accuracy rate for each condition. An ANOVA on mean RT with task (single versus dual) and compatibility as within-subject factors revealed a main effect of flanker compatibility (F(1, 23) = 273.27, MSE = 219.74, p < .001, ηp2 = .92), and a main effect of task (F(1, 23) = 12.58, MSE = 502.77, p = .002, ηp2 = .35), showing that participants were generally slower in the dual-task than the single-task condition. Critically, the interaction between task and compatibility was not significant, F(1, 23) < 1, MSE = 36.26, ηp2 =.001, reflecting a similar magnitude of the compatibility effect in the dual-task (M = 50.16 ms) and the single-task (M = 49.88 ms) conditions. An ANOVA on accuracy rates revealed a main effect of compatibility, F(1, 23) = 57.11, MSE = .0007, p < .001, ηp2 = .71, reflecting a lower accuracy in the incompatible than the compatible flanker condition. Neither the main effect of task nor the interaction between task and compatibility reached significance, F(1, 23) = 1.61, MSE = .0001, p = .22, ηp2 = .07 and F(1, 23) = 2.64, MSE = .0001, p = .12, ηp2 = .1, respectively.

Behavioral data from Experiment 3 (a, b). The upper panel shows mean response time (RT) of correct responses and accuracy data in the flanker task for single-task and dual-task conditions. The lower panel displays the mean RT to digits in the probe detection task as a function of compatibility in the flanker task (dual-task condition only) and digit location. Digit location is expressed as the relative distance from the center of the screen (-2: left outer flanker; -1: right inner flanker; 1: right inner flanker; 2: right outer flanker). The dashed line shows mean RT to digits averaged across flanker compatibility conditions. Error bars indicate ±1 within-subjects standard error of the mean (Morey, 2008)
Digit detection (dual-task condition)
The percentage of hits and false alarms was 99.42% and 3.23%, respectively. The percentage of anticipations was .16%. Figure 2b shows mean RT for hits as a function of position and flanker compatibility (compatible versus incompatible). Trials in which an incorrect response was made to the flanker display were discarded. An ANOVA on mean RT revealed a main effect of compatibility F(1, 23) = 8.79, MSE = 336.21, p = .007, ηp2 = .28, a main effect of position F(4, 92) = 3.55, MSE = 388.74, p = .01, ηp2 = .13, but no significant interaction between the two factors F(4, 92) = .13, MSE = 433.61, p = .97, ηp2 = .005. The V-shaped contrast for the main effect of position was significant (t(23) = 3.94, p < .001) while the V-shaped contrast for the interaction between position and compatibility was not (t(23) = .65, p = .52). These analyses replicate findings from Experiments 1 and 2.
Discussion
The results from Experiment 3 show that the magnitude of the flanker compatibility effect on mean RT and accuracy data was virtually identical in single-task and dual-task conditions. Dual-task coordination demands only increased overall RTs relative to the single-task condition, as hypothesized by all models of dual-task coordination (Kiesel et al., 2010). Consequently, there is no reason to doubt that the dual-task nature of our design altered selective attention dynamics, and our inferences can be generalized to the standard 1-to-1 flanker task. Consistent with Experiments 1 and 2, we found that digit probe trials generated a V-shaped function of RTs across probe positions that was not modulated by flanker compatibility, demonstrating that subjects focused attention on the target regardless of the same/different configuration of the display. Altogether, these findings refute the conditional focusing hypothesis.
The lack of a specific effect of dual-task coordination on the magnitude of the flanker compatibility effect appears in contrast with results obtained by Lavie et al. (2004). One possible explanation for this discrepancy concerns the difficulty of the task that had to be coordinated with the flanker task. Arguably, the two-choice working memory task used by Lavie and colleagues is more difficult than our digit detection task, and might have required more cognitive control, impairing selective attention mechanisms. It should also be noted that the modulation of the flanker compatibility effect by dual-task coordination reported by Lavie and colleague was only observed on mean RT. If dual-task coordination demands had exhausted cognitive control resources, one would expect a modulation of the flanker compatibility effect on accuracy as well. The effect of dual-task coordination on the flanker compatibility effect should be investigated more in depth in future studies, by combining the flanker task with a variety of tasks.
General discussion
Charles Eriksen was fond of saying “every theory should come with a shovel to bury it.” In our experiments, the shovel is the digit probe detection procedure, which is capable of burying the conditional focusing hypothesis. This hypothesis states that subjects perform 1-to-1 flanker tasks by first determining whether all the items are the same and focusing attention on the central target only if they are not. The extra time required for focusing on the target in incompatible displays would thus explain some variance of the flanker effect, in addition to the standard response competition account (Eriksen & Eriksen, 1974; Eriksen & Hoffman, 1973).
The conditional focusing hypothesis predicts a flat function of RTs across probe positions in the compatible condition and a V-shaped function in the incompatible condition. However, the data from Experiment 1 showed similar V-shaped functions between compatibility conditions, suggesting that participants focused attention on the central target regardless of trial type. We replicated these findings in Experiment 2, and ruled out an alternative explanation of V-shaped functions in terms of visual acuity (Curcio et al., 1987; Green, 1970; Osterberg, 1935). Participants completed an additional word categorization task (living/nonliving) that required attention to all five letters. Accordingly, RTs to digit probes after word categorization trials followed a flat function across positions, demonstrating that the probe detection procedure is a valid measure of the attentional field (LaBerge, 1983; LaBerge & Brown, 1986, 1989). Experiment 3 was designed to evaluate whether the demands to coordinate the flanker task with a probe detection task exhausted cognitive control resources, altering selective attention mechanisms in the flanker task. Dual-task blocks similar to Experiments 1 and 2 alternated with single-task blocks in which participants had to respond to the flanker task only. Responses were generally slower in the dual-task condition, as predicted by models of dual-task coordination (Kiesel et al., 2010). However, the magnitude of the flanker compatibility effect on RT and accuracy data was virtually identical in dual-task and single-condition, suggesting similar selective attention dynamics. Consistent with Experiments 1 and 2, RTs to digit probes in the dual-task condition followed a V-shaped function that was similar in compatible and incompatible trials. These findings bury the conditional focusing hypothesis, and guarantee the generalization of our inferences to the standard 1-to-1 flanker task. Additional support for this conclusion comes from a Bayesian analysis of the data (Appendix 2).
The data from our experiments consistently showed a main effect of flanker compatibility on V-shaped probe RT functions. Probe RTs were significantly faster after incompatible than compatible flanker trials. Could this effect be generated by more attentional focusing in incompatible compared to compatible trials? If one assumes a fixed attentional capacity, this hypothesis necessarily predicts an interaction between digit position and compatibility conditions. More attentional focusing on the central target would generate faster RTs to digits presented at the central target location, but slower RTs at the flanker locations. Alternatively, the main effect of flanker compatibility on V-shaped probe RT functions might be due to the progressive decay of the flanker task set, reducing interference when retrieving the task set for the probe task (Altmann, 2005; Meiran, 1996) and facilitating probe detection performance. Facilitated detection performance could also be the consequence of active task preparation (Rogers & Monsell, 1995). Both hypotheses predict a negative correlation between RTs in the flanker task and RTs in the probe task for each participant. However, we found a positive correlation for almost every participant in each experiment (Experiment 1: 24/24 subjects; Experiment 2: 24/24; Experiment 3: 22/24). This correlation was small (Experiment 1: M = .11; Experiment 2: M = .20; Experiment 3: M = .13) and often significant due to the large number of trials (Experiment 1: correlation significant in 17/24 subjects; Experiment 2: 10/24; Experiment 3: 17/24). These findings refute an explanation of the main effect of flanker compatibility on V-shaped probe RT functions in terms of passive decay of the flanker task set or active preparation for the probe task. The observed additive effects between compatibility and position on digit detection performance should be investigated more in depth in future work.
To summarize, this work rules out an additional explanation of compatibility effects observed in 1-to-1 flanker tasks in terms of conditional attentional focusing. Our findings show that participants focused attention on the central target in a similar way in compatible and incompatible trials. Thus, the best interpretation of flanker compatibility effects is the original Eriksen and Eriksen (1974) account, in which subjects focus attention on the target in all conditions and endure the costs and benefits of response competition. The Eriksen and Eriksen account is the basis of current computational models of the flanker task (Hübner, Steinhauser, & Lehle, 2010; Servant et al., 2015; Ulrich et al., 2015; White, Brown, et al., 2011; White, Ratcliff, et al., 2011; White, Servant, & Logan, 2018). Our research suggests that account provides a firm ground on which to build more detailed theories.
Notes
At first glance, the lack of a significant difference between same flanker and compatible flanker conditions reported by Eriksen and Eriksen (1974) speaks against the conditional focusing confound. However, their Fig. 1 shows a numerical trend toward faster RTs in the same flanker compared to the compatible flanker condition when between-letter spacing is relatively small (.06° and .5° conditions). Given the very small sample size in this study (six subjects), the non-significant difference might be due to a lack of power. In addition, the study featured a 2-to-1 mapping, plus two additional conditions in which the flankers were not informative of the response (the “noise heterogeneous similar” condition, in which flanking letters shared features similar to the target set, and the “noise heterogeneous dissimilar” condition, in which flanking letters had features dissimilar to the target set). The percentage of same flanker trials (20%) is thus considerably lower compared to a 1-to-1 mapping design (50%), making a conditional focusing strategy less useful, and instead promoting a narrow attentional spotlight. Consequently, the non-significant difference between same flanker and compatible flanker conditions reported by Eriksen and Eriksen (1974) cannot be considered as evidence against a conditional focusing strategy in the 1-to-1 version of the task.
References
Altmann, E. M. (2005). Repetition priming in task switching: Do the benefits dissipate? Psychonomic Bulletin & Review, 12(3), 535-540.
Brysbaert, M., & New, B. (2009). Moving beyond Kucera and Francis: A critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English. Behavior Research Methods, 41(4), 977-990. https://doi.org/10.3758/brm.41.4.977
Coles, M. G., Gratton, G., Bashore, T. R., Eriksen, C. W., & Donchin, E. (1985). A psychophysiological investigation of the continuous flow model of human information processing. Journal of Experimental Psychology: Human Perception and Performance, 11(5), 529-553.
Cragg, L. (2016). The development of stimulus and response interference control in midchildhood. Developmental Psychology, 52(2), 242-252. https://doi.org/10.1037/dev0000074
Curcio, C. A., Sloan, K. R., Jr., Packer, O., Hendrickson, A. E., & Kalina, R. E. (1987). Distribution of cones in human and monkey retina: Individual variability and radial asymmetry. Science, 236(4801), 579-582.
Eriksen, B. A., & Eriksen, C. W. (1974). Effects of noise letters upon the identification of a target letter in a nonsearch task. Perception & Psychophysics, 16, 143-149. https://doi.org/10.3758/BF03203267
Eriksen, B. A., Eriksen, C. W., & Hoffman, J. E. (1986). Recognition memory and attentional selection: Serial scanning is not enough. Journal of Experimental Psychology. Human Perception and Performance, 12(4), 476-483.
Eriksen, C. W., Coles, M. G. H., Morris, L. R., & O'Hara, W. P. (1985). An electromyographic examination of response competition. Bulletin of the Psychonomic Society, 23, 165-168.
Eriksen, C. W., & Hoffman, J. E. (1973). The extent of processing of noise elements during selective encoding from visual displays. Perception & Psychophysics, 14, 155-160.
Eriksen, C. W., O'Hara, W. P., & Eriksen, B. (1982). Response competition effects in same-different judgments. Perception & Psychophysics, 32(3), 261-270.
Eriksen, C. W., Pan, K., & Botella, J. (1993). Attentional distribution in visual space. Psychological Research, 56(1), 5-13.
Eriksen, C. W., & St James, J. D. (1986). Visual attention within and around the field of focal attention: A zoom lens model. Perception & Psychophysics, 40(4), 225-240.
Evans, P. M., Craig, J. C., & Rinker, M. A. (1992). Perceptual processing of adjacent and nonadjacent tactile nontargets. Perception & Psychophysics, 52(5), 571-581.
Gratton, G., Coles, M. G., Sirevaag, E. J., Eriksen, C. W., & Donchin, E. (1988). Pre- and poststimulus activation of response channels: A psychophysiological analysis. Journal of Experimental Psychology: Human Perception and Performance, 14(3), 331-344.
Green, D. G. (1970). Regional variations in the visual acuity for interference fringes on the retina. The Journal of Physiology, 207(2), 351-356.
Greenhouse, S., & Geisser, S. (1959). On methods in the analysis of profile data. Psychometrika, 24, 95-112.
Hübner, R., & Töbel, L. (2012). Does attentional selectivity in the flanker task improve discretely or gradually? Frontiers in Psychology, 3, 1-11. https://doi.org/10.3389/fpsyg.2012.00434
Hübner, R., Steinhauser, M., & Lehle, C. (2010). A dual-stage two-phase model of selective attention. Psychological Review, 117(3), 759–784.
JASP Team (2018). JASP (Version 0.9.2)[Computer software].
Jeffreys, H. (1961). Theory of probability, (3rd ed.) Oxford, UK: Oxford University Press.
Kiesel, A., Steinhauser, M., Wendt, M., Falkenstein, M., Jost, K., Philipp, A. M., & Koch, I. (2010). Control and interference in task switching--A review. Psychological Bulletin, 136(5), 849-874. https://doi.org/10.1037/a0019842
LaBerge, D. (1983). Spatial extent of attention to letters and words. Journal of Experimental Psychology. Human Perception and Performance, 9(3), 371-379.
LaBerge, D., & Brown, V. (1986). Variations in size of the visual field in which targets are presented: An attentional range effect. Perception & Psychophysics, 40(3), 188-200.
LaBerge, D., & Brown, V. (1989). Theory of attentional operations in shape identification. Psychological Review, 96, 101-124.
LaBerge, D., Brown, V., Carter, M., Bash, D., & Hartley, A. (1991). Reducing the effects of adjacent distractors by narrowing attention. Journal of Experimental Psychology. Human Perception and Performance, 17(1), 65-76.
Lavie, N., Hirst, A., de Fockert, J. W., & Viding, E. (2004). Load theory of selective attention and cognitive control. Journal of Experimental Psychology. General, 133(3), 339-354. https://doi.org/10.1037/0096-3445.133.3.339
Mauchly, J. W. (1940). Significance test for sphericity of a normal N-variate distribution. The Annals of Mathematical Statistics, 11(2), 204-209.
Meiran, N. (1996). Reconfiguration of processing mode prior to task performance. Journal of Experimental Psychology: Learning, Memory, and Cognition, 22, 1423-1442.
Morey, R. D. (2008). Confidence intervals from normalized data: A correction to Cousineau (2005). Tutorial in Quantitative Methods for Psychology, 4(2), 61-64.
Osterberg, G. (1935). Topography of the layer of rods and cones in the human retina. Acta Ophtalmology Supplement, 6, 11-97. https://doi.org/10.1001/jama.1937.02780030070033
Peirce, J. W. (2007). PsychoPy--Psychophysics software in Python. Journal of Neuroscience Methods, 162(1-2), 8-13. https://doi.org/10.1016/j.jneumeth.2006.11.017
Polyn, S. M., Kragel, J. E., Morton, N. W., McCluey, J. D., & Cohen, Z. D. (2012). The neural dynamics of task context in free recall. Neuropsychologia, 50(4), 447-457. https://doi.org/10.1016/j.neuropsychologia.2011.08.025
Richardson, C., Anderson, M., Reid, C. L., & Fox, A. M. (2011). Neural indicators of error processing and intraindividual variability in reaction time in 7 and 9 year-olds. Developmental Psychobiology, 53(3), 256-265. https://doi.org/10.1002/dev.20518
Ridderinkhof, K. R., Scheres, A., Oosterlaan, J., & Sergeant, J. A. (2005). Delta plots in the study of individual differences: new tools reveal response inhibition deficits in AD/Hd that are eliminated by methylphenidate treatment. In Journal of Abnormal Psychology (Vol. 114, pp. 197-215). United States: 2005 APA, all rights reserved.
Ridderinkhof, K. R., van der Molen, M. W., Band, G. P., & Bashore, T. R. (1997). Sources of interference from irrelevant information: A developmental study. Journal of Experimental Child Psychology, 65(3), 315-341. https://doi.org/10.1006/jecp.1997.2367
Ridderinkhof, K. R., van der Molen, M. W., & Bashore, T. R. (1995). Limits on the application of additive factors logic: Violations of stage robustness suggest a dual-process architecture to explain flanker effects on target processing. Acta Psychologica, 90(Issues 1–3), 29–48. https://doi.org/10.1016/0001-6918(95)00031-O
Rogers, R. D., & Monsell, S. (1995). Costs of a predictable switch between simple cognitive tasks. Journal of Experimental Psychology: General, 124, 207-231.
Rouder, J. N., & Haaf, J. M. (2018). Power, dominance, and constraint: A note on the appeal of different design traditions. https://doi.org/10.1177/2515245917745058
Rueda, M. R., Fan, J., McCandliss, B. D., Halparin, J. D., Gruber, D. B., Lercari, L. P., & Posner, M. I. (2004a). Development of attentional networks in childhood. Neuropsychologia, 42(8), 1029-1040. https://doi.org/10.1016/j.neuropsychologia.2003.12.012
Rueda, M. R., Posner, M. I., Rothbart, M. K., & Davis-Stober, C. P. (2004b). Development of the time course for processing conflict: An event-related potentials study with 4 year olds and adults. BMC Neuroscience, 5, 39. https://doi.org/10.1186/1471-2202-5-39
Servant, M., Montagnini, A., & Burle, B. (2014). Conflict tasks and the diffusion framework: Insight in model constraints based on psychological laws. Cognitive Psychology, 72, 162-195. https://doi.org/10.1016/j.cogpsych.2014.03.002
Servant, M., van Wouwe, N., Wylie, S. A., & Logan, G. D. (2018). A model-based quantification of action control deficits in Parkinson's disease. Neuropsychologia, 111, 26-35. https://doi.org/10.1016/j.neuropsychologia.2018.01.014
Servant, M., White, C., Montagnini, A., & Burle, B. (2015). Using covert response activation to test latent assumptions of formal decision-making models in humans. The Journal of Neuroscience, 35(28), 10371-10385. https://doi.org/10.1523/jneurosci.0078-15.2015
Skelton, J. M., & Eriksen, C. W. (1976). Spatial characteristics of selective attention in letter matching. Bulletin of the Psychonomic Society, 7(2), 136-138. https://doi.org/10.3758/BF03337143
Ste-Marie, D. M., & Jacoby, L. L. (1993). Spontaneous versus directed recognition: The relativity of automaticity. Journal of Experimental Psychology: Learning, Memory, and Cognition, 19(4), 777-788. https://doi.org/10.1037/0278-7393.19.4.777
Sternberg, S. (1969). The discovery of processing stages: Extensions of Donders’ method. Acta Psychologica, 30, 276-315. https://doi.org/10.1016/0001-6918(69)90055-9
Sternberg, S. (2011). Modular processes in mind and brain. Cognitive Neuropsychology, 28(3-4), 156-208. https://doi.org/10.1080/02643294.2011.557231
Ulrich, R., Schroter, H., Leuthold, H., & Birngruber, T. (2015). Automatic and controlled stimulus processing in conflict tasks: Superimposed diffusion processes and delta functions. Cognitive Psychology, 78, 148-174. https://doi.org/10.1016/j.cogpsych.2015.02.005
White, C. N., Brown, S., & Ratcliff, R. (2011). A test of Bayesian observer models of processing in the Eriksen flanker task. Journal of Experimental Psychology: Human Perception and Performance, 38(2), 489-497. https://doi.org/10.1037/a0026065
White, C. N., Ratcliff, R., & Starns, J. J. (2011). Diffusion models of the flanker task: Discrete versus gradual attentional selection. Cognitive Psychology, 63(4), 210-238. https://doi.org/10.1016/j.cogpsych.2011.08.001
White, C. N., Servant, M., & Logan, G. D. (2018). Testing the validity of conflict drift-diffusion models for use in estimating cognitive processes: A parameter-recovery study. Psychonomic Bulletin & Review, 25(1), 286–301.
Wylie, S. A., van den Wildenberg, W. P., Ridderinkhof, K. R., Bashore, T. R., Powell, V. D., Manning, C. A., & Wooten, G. F. (2009). The effect of speed-accuracy strategy on response interference control in Parkinson's disease. Neuropsychologia, 47(8-9), 1844-1853. https://doi.org/10.1016/j.neuropsychologia.2009.02.025
Author notes
Our friend and colleague, Charles Eriksen, died as we were designing these experiments. We offer this paper as testament to his legacy, which will live on for many years. He would have liked that we challenged his theory, and he would have liked that we found he was right all along.
Grant support statement This research was supported by National Eye Institute grant no R01 EY025275.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing financial interests.
Open Practices Statement
The data and materials for all experiments are available on the Open Science Framework (https://osf.io/v6kn2/).
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1
Five-letter words used in Experiment 2
Living | Nonliving |
BISON | BADGE |
BUNNY | BANJO |
CAMEL | BLADE |
CHICK | CABIN |
DAISY | CANOE |
EAGLE | DRYER |
GOOSE | FENCE |
HOUND | GLOVE |
MOOSE | KNIFE |
MOUSE | MEDAL |
OTTER | LODGE |
ROACH | PEDAL |
ROBIN | RIFLE |
SHARK | RAZOR |
SHEEP | SCARF |
SNAIL | STAMP |
SNAKE | STRAW |
TIGER | TOWEL |
WHALE | WAGON |
ZEBRA | YACHT |
Appendix 2
Bayesian analysis of the digit probe RT data
We conducted Bayesian ANOVAs on digit probe RTs with flanker compatibility and position as within-subject factors using JASP (2018; Version 0.9.2). For each experiment, the model that received the most support compared to the null model (containing only the grand mean) is the two main effects model (compatibility + position). The Bayes factor (BF) in favor of this two main effects model relative to the model containing the interaction term was BF = 6.9 for Experiment 1, BF = 14.7 for Experiment 2, and BF = 27 for Experiment 3. According to Jeffrey’s (1961) scale, these BFs represent moderate, strong, and strong evidence for the two main effects model for Experiments 1, 2, and 3, respectively.
We next computed a BF for the V-shaped contrast for the main effect of position (contrast 1), and a BF for V-shaped contrast for the interaction between position and compatibility (contrast 2) for each experiment. For contrast 1, the BF in favor of the V-shaped model relative to the null model was 3.7 (moderate evidence) for Experiment 1, 21.9 (strong evidence for Experiment 2, and 51.3 (very strong evidence) for Experiment 3. For contrast 2, the BF in favor of the null model relative to the interaction model was 3.4 (moderate evidence) for Experiment 1, 2.7 (anecdotal evidence) for Experiment 2, and 3.9 (moderate evidence) for Experiment 3.
For completeness, we performed a Bayesian analysis of the digit probe RT data associated with the word categorization task of Experiment 2. The Bayesian ANOVA showed that the model with the most support (compared to the null model) was the model incorporating a main effect of category. The BF in favor of this model compared to the two main effects model (category + position) was 58.6 (very strong evidence). Contrast 1 showed moderate evidence for the null model compared to the V-shaped model, BF = 4.6, and contrast 2 showed anecdotal evidence for the null model compared to the model with the interaction model, BF = 2.1. Altogether, these Bayesian analyses provide moderate to strong support for conclusions drawn in the main text.
Rights and permissions
About this article

Cite this article
Servant, M., Logan, G.D. Dynamics of attentional focusing in the Eriksen flanker task. Atten Percept Psychophys 81, 2710–2721 (2019). https://doi.org/10.3758/s13414-019-01796-3
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-019-01796-3