
Abstract
We address the severe interference condition with unity frequency re-use factor in each cell and propose a novel distributed receiver for reliable detection of the uncoded data transmitted in multi-user multi-cell multiple input, multiple output (MIMO) systems. The new algorithm employs distributed probabilistic data association (PDA) with turbo base-station (BS) cooperations (PDA-TB). From a Bayesian point of view, we modify the original complex PDA detector to incorporate the a priori probability, which makes the complex PDA detector applicable to turbo processing: the soft information is extracted using PDA algorithm at local BS and then used as the a priori probability for further detection at neighboring BSs. Final soft decision is made after the algorithm converges. In this way, the benefit of macro-diversity is achieved and the inter-cell interferences are mitigated. In heavy interference condition, the proposed algorithm outperforms the distributed PDA aided soft combining (PDA-SC) and achieves the near optimal performance. Meanwhile, low complexity is maintained due to the rapid convergence.
Similar content being viewed by others


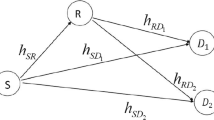
1 Introduction
To design the mobile communication systems, one has to face two key challenges: fading and interference. Both of them restrict the system coverage and capacity. Especially in a multi-user multi-cell multiple input, multiple output (MIMO) system, the gain of MIMO technique is determined by the inter-cell co-channel interference (CCI). Consider a server interference condition with unit frequency re-use factor where, at the cell boundary areas, mobile stations (MSs) transmit the signals which can be detected by the surrounding base stations (BSs). The conventional non-cooperative BS detects the desired MS signals independently using local received data. Moreover, the co-channel users’ signals are considered as interference and then degrade the system throughput. However, in the cooperative system, those interference signals are dealt with specific tools such as virtual MIMO and then are treated more like the useful information to jointly detect the MS signals. In this way, the number of co-channel links can be maximized so as to optimize the system capacity.
In the centralized BS cooperations, the complexity of the general multi-user multi-cell MIMO detection grows exponentially with the number of antennas. It raises a question of scalability and motivates the search for simplified suboptimal algorithms. To solve this problem, it is straightforward to distribute, across a network of interacting BSs, the global uplink task of demodulating all users’ data symbols [1]. Each BS individually performs local computations and then passes the processed soft information to immediate neighbors for further processing. Distributed BS cooperations were discussed in recent literatures [2, 5–7]. Among them, Yang [2] proposed a simple soft combining method through which the soft information, calculated in parallel at different BSs, is statistically aggregated to make the final decision.
Besides the conventional distributed schemes, it is very natural to try and apply well-known turbo principle [1], which has been employed in turbo equalization [3, 4], Bayesian data integration [7, 8], and turbo BS cooperations [5–7, 9]. Turbo principle was originated from turbo decoding, and in the context of cooperative communication systems, it explores the synergy from distributed detections on symbols and combines the soft (probabilistic) detection in a turbo fashion to achieve greater performance improvement. The implementation of turbo cooperations separates the joint detections into commonly two or possibly more connected units (BSs), and the a posteriori probability (APP) of symbols are calculated at each unit with the extrinsic information obtained at other units as the a priori probability. The processes then iterate among the units until the convergence of the APPs. The output of the turbo BS cooperation is a near optimal approximation of true APPs, and Mayer [10] illustrated the explicit connection to Turbo-decoding and message-passing algorithm.
To obtain the soft information through local detection, many low-complexity algorithms have been investigated as alternative designs for optimal maximum a posteriori probability (MAP) solution. Among them, probabilistic data association (PDA) has attracted many attentions and shown to provide a near-optimal multi-user detection (MUD) [11, 12] performance in the context of Code Division Multiple Access (CDMA) [16]. The basic idea of the PDA is to approximate the Gaussian mixture with a single Gaussian distribution, a concept seemingly simple yet very effective in practice. Another appealing advantage of the PDA is that it is soft in nature and thus applicable to turbo BS cooperations. Moreover, [17] indicated that the larger the number of users, the better performance achievable due to the Gaussian approximation. This makes PDA attractive for a MUD scenario with large number of interferers.
The soft combining in [2] is based on complex PDA (CPDA) algorithm [13–15], which matches the full parameters of the complex Gaussian distribution and outperforms the approximated CPDA used in our previous work [4]. However, the original form of CPDA assumes uniform (or non-informative) prior and then does not incorporate practical prior knowledge. As a result, empirical information obtained in other BSs is lost and then the overall performance is somehow degraded. It implies that further performance improvement over the PDA-SC algorithm is possible if the prior information can be carefully manipulated.
In this paper, we investigate the distributed PDA detector with turbo BS cooperations. We modify the structure for original CPDA, where the a priori probability is appropriately incorporated. This modification considers the soft information obtained from neighboring BSs and then makes PDA readily applicable to turbo BS cooperations. We also provide the performance of the proposed algorithm by simulations.
The remaining of the paper is organized as follows. The problem is formulated in Section 2. The distributed PDA with turbo BS cooperations is described in Section 3. Simulation results are presented in Section 4, and finally, the conclusions are drawn in Section 5.
2 Problem formulation
Consider the uplink in a multi-user multi-cell system, where the uncoded data is transmitted from N m mobile stations (MS) to N b BSs. Each MS has N t transmit antennas, and each BS is equipped with N r receive antennas. In the cell edges, assume the signals transmitted by MSs are in the detectable range (DR) of N b BSs and then can be detected by all the BSs. We are interested in this extremely challenging scenario and discuss the signal model as follows.
The signal received at BS i is
where y i is the N r ×1 vector of symbols received at BS i , \(\mathbf {H}^{i}_{l}\) is the N r ×N t complex channel matrix between MS l and BS i , x l is the N t ×1 vector of symbols transmitted from MS l , and n i is the complex Gaussian noise with zero mean and covariance matrix \(\sigma ^{2}_{n} \mathbf {I}_{N_{r}}\). This signal model can be further formulated as a virtual MIMO system as the following
where \(\mathbf {H}^{i}=\,\left [\!\mathbf {H}^{i}_{1}, \cdots, \mathbf {H}^{i}_{N_{m}}\right ]\), \(\mathbf {x}=\,\left [\!(\mathbf {x}_{1})^{\top }, \cdots, (\mathbf {x}_{N_{m}})^{\top }\right ]^{\top }\). Assume H i and \(\sigma ^{2}_{n}\) are known.
To mitigate the inter-cell interferences, a natural way is to perform the joint detection with BS cooperations. Our objective is to determine x k ,k=1,…,N m ×N t given received signals y i,i=1,…,N b . From a Bayesian point of view, the marginal APP is calculated to make the decision,
where \(\mathbf {y}^{1:N_{b}} = \mathbf {y}^{1}, \cdots, \mathbf {y}^{N_{b}}\) and α m is the m-th element of the M-ary constellation A.
3 PDA-based turbo BS cooperations
The goal of our soft detector is to obtain \(p\left (x_{k}|\mathbf {y}^{1:N_{b}}\right)\) and then detect the transmitted symbol x k . One way to reduce the complexity is to perform distributed detection, using local y i to calculate p(x k |y i) and approximating \(p\left (x_{k}|\mathbf {y}^{1:N_{b}}\right)\) through BS cooperations. This motivates us to exploit distributed detector with BS cooperations, and it is very natural to apply well-known turbo principle to achieve near optimal performance.
p(x k |y i) can be obtained easily if p(y i|x k ) is known since
However, to obtain p(y i|x k ), marginalization must be performed as
where x −k represents a (N t N m −1)×1 vector that contains all data symbols except x k . Apparently, the optimal MAP solution of (3) is of complexity exponential increasing of N t N m and thus computationally infeasible for large systems. Notice that \(\sum _{\mathbf {x}_{-k}} p(\mathbf {y}^{i}|\mathbf {x})p(\mathbf {x}_{-k})\) is the mixture of Gaussian distribution; we can further simplify the receiver by approximating the mixture Gaussian by a single Gaussian. This motivates us to employ PDA detector at every BS. In addition, modification is made to allow PDA detector to accept prior information and then workable in turbo BS cooperations.
The proposed algorithm is then named by PDA-TB. It follows the Bayesian rule and turbo principle that BSi individually perform local PDA computation with y i, and then outputs the soft information as the a priori probability for neighboring BSs to continue their PDA detections until the APPs calculated at different BSs get convergence.
3.1 The complex PDA detector
3.1.1 N m N t ≤N r
Given that (H i)H H i is invertible, (2) can be rewritten as the decorrelated signal model:
and it is equivalent to have
where \(\tilde {\mathbf {n}}^{i}\) is a Gaussian noise with zero mean and covariance \(\mathbf {\Lambda }=\sigma ^{2}_{n} \left [(\mathbf {H}^{i})^{H} \mathbf {H}^{i}\right ]^{-1}\), e k is a column vector with a 1 in the kth element and zeros elsewhere, and vector \(\mathbf {v}^{i}_{k}=\sum \limits _{j\neq k}x_{j}e_{j} + \tilde {\mathbf {n}}^{i}\) has a multimodal Gaussian mixture distribution.
Since the signal model is complex-valued, the complex formulation of PDA is preferred. The basic idea behind complex PDA is to approximate \(\mathbf {v}^{i}_{k}\) as a single Gaussian distribution with the matched mean \(E(\mathbf {v}^{i}_{k})\), covariance \(V(\mathbf {v}^{i}_{k})\), and pseudo-convariance \(U(\mathbf {v}^{i}_{k})\) [15],
where
This approximation is called data association.
Let
and
where R(∗) and I(∗) represent the real and imaginary part of a complex variable. The original complex PDA assumes the uniform or non-informative prior [15], and then, the APP of x k is approximated by the likelihood function. To develop a general complex PDA detector, we incorporate the prior information \(p(x^{i}_{k})\) and calculate the APP of x k by
and the symbol log-likelihood ratio (LLR) \(\mathbf {\Lambda }^{i}_{k}\) by
with
where m=0,⋯,M−1 is the index of the elements in symbol constellation A.
Since (19) is only an approximation to the true APP, the PDA detector will, after one sweep of update from k=1:N t N m , start another sweep until the APPs converge. In the end, the detection is performed as
The complexity of PDA at each BS per iteration is on the order of O[ (N m N t )3]. The above procedure is summarized in Table 1.
3.1.2 N m N t >N r
Given that the total number of transmit antennas is smaller than the number of receive antennas, (H i)H H i is not invertible any more. In the case of non-decorrelated model, (2) is rewritten as
where \(\mathbf {h}^{i}_{k}\) is the k-th column of H i and \(\mathbf {u}^{i}_{k}\) is the equivalent interference plus noise. Then, PDA algorithm can be obtained using a similar derivation as in decorrelated model discussed in Section 3.1.1.
3.2 Turbo BS cooperations
For simple illustration, assume that there are two BSs in the system: BS1 and BS2. The following method can be easily extended to the case with N m ≥3. In turbo BS cooperations, LLR \(\mathbf {\Lambda }^{i}_{k}\) is the soft information and exchanged among BSs iteratively until the APPs p(x k |y 1:2) converge. The detailed procedure is demonstrated in the following.
APP p(x k |y 1:2) can be further factorized as
assuming y 1 and y 2are independent given x k . Initially, assume p(x k )=1/M. At BS1, use \(p(x_{k}^{1})=p(x_{k})\) with data y 1 to approximate APP p(x k |y 1) and LLR \(\mathbf {\Lambda }^{1}_{k}\). Then at BS2, p(x k )p(y 1|x k ) is equivalent to the a priori probability \(p(x_{k}^{2})\). Given p(x k )=1/M is a non-informative prior, we set \(p(x_{k}^{2})\propto p(\mathbf {y}^{1}|x_{k})\). Specifically, \(p(x_{k}^{2}=\alpha _{m})=\frac {\exp (\lambda _{m}^{1})}{1+\sum _{p=1}^{M-1}\exp (\lambda _{p}^{1})}\). In another word, the LLR \(\mathbf {\Lambda }^{1}_{k}\) computed at BS1 is treated as soft information and set as the a priori probability \(p(x_{k}^{2})\) at BS2. With the local received data y 2 and the prior information \(p(x_{k}^{2})\), BS2 performs the PDA detection and produces the approximated APP p(x k |y 1:2). Again, the LLR \(\mathbf {\Lambda }^{2}_{k}\) needs to be updated according to
where
Before moving to the next step, check first the gap between p(x k |y 1:2) and p(x k |y 1). If the difference is small enough, the algorithm can be stopped and p(x k |y 1:2) is used to make the final decision on x k . Otherwise, this LLR \(\mathbf {\Lambda }^{2}_{k}\) is passed to BS1 as \(p(x_{k}^{1})\), and then, turbo processing is continued until the APPs converge. LLR is updated at each BS by
The summary of proposed turbo BS cooperations using distributed PDA is in Table 2.
3.3 Soft information exchange
Assume there is an idealized backbone connecting all the BSs and the soft information \(\mathbf {\Lambda }^{i}_{k}\)s are exchanged among BSs in a turbo fashion. After the APP converges, the soft decision is sent to each user’s home BS.
4 Simulation results
For ease of illustration, we assume first N b =2, N t =1 in the system and a BPSK modulation for the transmitted data. And it is straightforward to extend those assumptions to the case with N b >2,N t >1 and high-order modulations. Moreover, we also offer the the results for those general cases with N b >2,N t >1.
In the simulation, H i is flat rayleigh fading channels. The maximum iteration in PDA computation is 5 since PDA typically converges within 3 ∼5 iterations [16]. However, the inner PDA iterations degrade the performance of turbo processing [12] despite of the increasing complexity. Therefore, we investigate and conclude that in PDA-TB, the optimal number of inner PDA iteration is 0. In contrast, the inner PDA iterations are adaptive according to the convergence condition of CPDA, in both PDA-SC and PDA-JP. The maximum outer iteration in turbo processing is 3 based on the empirical data.
4.1 BER comparison
4.1.1 Illustration on the simple cases with N b =2, N t =1 and BPSK modulation
Figures 1 and 2 show the BER performance of the proposed PDA-TB algorithm and PDA aided soft combining (PDA-SC) [2]. “PDA-SC” is the distributed algorithm where the term “soft combining” means

BER performance with N m =4 and N r =4

BER performance with N m =16 and N r =16
where the a priori probability \(p(x_{k}^{i})\) is non-informative. In those two figures, “PDA” denotes the PDA detection with local received data y 1; “PDA-JP” indicates the joint processing in a centralized system by employing PDA algorithm directly on the received data \(\phantom {\dot {i}\!}\mathbf {y}^{1:N_{b}}\); “SD-JP” indicates the sphere decoding with the joint processing. Among them, PDA-JP and SD-JP are centralized BS cooperations where a central processing unit collects the received data \(\mathbf {y}^{1:N_{b}}\phantom {\dot {i}\!}\) and employs PDA or SD respectively to calculate directly the APP \(\phantom {\dot {i}\!}p(x_{k}|\mathbf {y}^{1:2})\).
Without BS cooperations, “PDA” shows significant degradation compared with centralized or distributed BS cooperations. PDA-JP obtains almost the same performance as SD-JP. “PDA-TB” achieves similar BER performance as PDA-SC if small number of users (N m =4) are in DR. However, if interference is severe and more users are in DR, say N b =16, PDA-TB is close to the optimal SD-JP and outperforms PDA-SC by 0.5dB at BER of 10−4. Even in rand-deficient case showed in Figs. 3 and 4 where N m N t =2N r , PDA-TB outperforms PDA-SC by around 1dB at BER of 10−2.

BER performance with N m =16 and N r =8

BER performance with N m =4 and N r =2
4.1.2 Illustration on general cases
The proposed algorithm can be extended to the scenarios with higher-order modulation schemes, arbitrary N t or even N b >2.
Figure 5 shows the impact of modulation order when N m =4, N t =1, N b =2, and N r =4. As the modulation scheme changes from BPSK to 4QAM and 8QAM, the gain between PDA-TB and PDA-SC increases from almost 0, 0.3, and 1 dB at BER of 10−3, respectively.

The impact of modulation order
Figure 6 demonstrates the impact of the total number of streams which is equal to N m ×N t , when N b =2 and N r =N m ×N t . As the total number of streams increases from 4 to 8 and 16, the gain of PDA-TB over PDA-SC is accordingly from 0, 0.4, and 0.55 dB at BER of 10−4. The simulation results demonstrate that the PDA-TB can achieve a slight gain over the PDA-SC when the system has a fixed stream number.

The impact of total number of streams
Figure 7 indicates that PDA-TB achieves about 2.2 dB gain while incorporating 3 base stations over 2. However, there is no obvious improvement if PDA-SC is used to involve 3 base stations rather than 2. Hence, we can conclude that the diversity gain of the base station dominates the total gain.

The impact of BS number
4.2 Complexity evaluation
The computational complexity of the proposed PDA-TB can be evaluated by simply comparing its complexity to PDA-SC and PDA-JP in a single (one inner and outer) iteration. The major computational cost of PDA-based algorithms is the calculation of Σ k −1 and the matrix multiplication of
Using the Sherman-Morrison-Woodbury formulation-based “speed-up” techniques of [16], the computational cost of calculating Σ k −1 can be reduced to \(\mathcal {O}(4N_{m}N_{t}N_{r}^{2})\) real-valued operations (N RO ). Moreover, the calculation of (32) requires \(\mathcal {O}(4MN_{m}N_{t}N_{r}^{2}+2MN_{m}N_{t}N_{r}) N_{RO}\). In summary, the computational cost of the proposed PDA-TB is \(\mathcal {O}(4N_{m}N_{t}N_{b}N_{r}^{2})+\mathcal {O}(4MN_{m}N_{t}N_{b}N_{r}^{2}+2MN_{m}N_{t}N_{b}N_{r}) N_{RO}\) per iteration.
The computational cost of PDA-SC is the same per iteration as PDA-TB, but PDA-JP has the complexity of \(\mathcal {O}(4N_{m}N_{t}N_{b}^{2}N_{r}^{2})+\mathcal {O}(4MN_{m}N_{t}N_{b}^{2}N_{r}^{2}+2MN_{m}N_{t}N_{b}N_{r}) N_{RO}\) per iteration.
In addition, Fig. 8 shows that the average iteration number in turbo processing is rapidly reduced to 1 as E b /N 0 increases and BER is below 10−4. This implies that PDA-TB converges even at the first iteration t=0 and then indicates that PDA-TB does not require more PDA computation than PDA-SC once BER reaches 10−4 or below. Meanwhile, the inner PDA iteration in PDA-TB is 0 while that in PDA-SC is set to be adaptive according to the convergence condition.

Average turbo iteration number in PDA-TB
Moreover, PDA-TB does not have the step of soft combining employed by PDA-SC to make final decision. Instead, PDA-TB uses the output of PDA detector as the final decision once the algorithm converges. The possible disadvantage in PDA-TB is that it might introduce the delay since it is sequential processing; however, PDA-SC is a parallel algorithm.
5 Conclusions
We propose a novel distributed PDA detector with turbo BS cooperations and show that PDA-TB outperforms existing PDA-SC in severe interference conditions. This improvement is due to the appropriate manipulation of the a priori probability. The future direction will be complexity reduction for the distributed PDA detector.
References
D Gesbert, S Hanly, H Huang, S Shamai Shitz, O Simeone, Y Wei, Multi-cell MIMO cooperative networks: a new look at interference. Selected Areas in Communications, IEEE J.28(9), 1380–1408 (2010).
S Yang, T Lv, R Maunder, L Hanzo, Distributed probabilistic data association based soft reception employing base station cooperation in MIMO-aided multi-user multi-cell systems. IEEE Trans. Veh. Technol.60(7), 3532–3538 (2011).
R Koetter, AC Singer, M Tuchler, Turbo equalization. Signal Proc. Mag. IEEE.21(1), 67–80 (2004).
Y Yin, Y Huang, J Zhang, Turbo equalization using probabilistic data association. Glob. Telecommun. Conf. IEEE.4:, 2535–2539 (2004).
S Khattak, W Rave, G Fettweis, Distributed iterative multiuser detection through base station cooperation. EURASIP J. Wirel. Commun. Netw.15(17) (2008).
P Marsch, G Fettweis, Uplink CoMP under a constrained backhaul and imperfect channel knowledge. IEEE Trans. Wirel. Commun.10(6), 17301742 (2011).
P Li, RCde Lamare, Distributed iterative detection with reduced message passing for networked MIMO cellular systems. IEEE Trans. Veh. Technol.63(6), 29472954 (2014).
Y Huang, Y Yin, Turbo Data Integration for Uncovering Gene Networks. Life Science Systems and Applications Workshop. IEEE/NLM, 2006:, 1–2.
BD Woerner, MC Valenti, Iterative multiuser detection, macrodiversity combining, and decoding for the TDMA cellular uplink. Selected Areas in Communications. IEEE J.19: (2001).
T Mayer, H Jenkac, J Hagenauer, Turbo Base-Station Cooperation for Intercell Interference Cancellation. Commun. IEEE Int. Conf.11:, 4977–4982 (2006).
B Habtemariam, R Tharmarasa, T Thayaparan, M Mallick, T Kirubarajan, A multiple-detection joint probabilistic data association filter. IEEE J. Sel. Top. Sig. Process.7(3), 461–471 (2013).
S Yang, T Lv, RG Maunder, L Hanzo, From nominal to true a posteriori probabilities: an exact Bayesian theorem based probabilistic data association approach for iterative MIMO detection and decoding. IEEE Trans. Commun.61(7), 2782–2793 (2013).
TL Song, HW Kim, D Musicki, Iterative joint integrated probabilistic data association for multitarget tracking. IEEE Trans. Aerosp. Electron. Syst.51(1), 642–653 (2015).
S Yang, L Wang, T Lv, L Hanzo, Approximate Bayesian probabilistic-data-association-aided iterative detection for MIMO systems using arbitrary M -ary modulation. IEEE Trans. Veh. Technol.62(3), 1228–1240 (2013).
Y Jia, CM Vithanage, C Andrieu, RJ Piechocki, Probabilistic data association for symbol detection in MIMO systems. Electron. Lett.42(1), 38–40 (2006).
J Luo, KR Pattipati, PK Willett, F Hasegawa, Near optimal multiuser detection in synchronous CDMA using probabilistic data association. IEEE Commun. Lett.5(9), 361–363 (2001).
J Fricke, M Sandell, J Mietzner, PA Hoeher, Impact of the Gaussian approximation on the performance of the probabilistic data association MIMO decoder. Wirel. Commun. Netw. EURASIP J.2005(5) (2005).
Acknowledgements
This work is supported by the Scientific Research Foundation of CUIT (No.KYTZ201415, KYTZ201501, KYTZ201502), Sichuan Provincial Department of Science and Technology Innovation and R&D projects in Science and Technology Support Program (No. 2015RZ0060, 2015GZ0340, 2015GZ0286, 2015GZ0290), and the Scientific Research Foundation for the Returned Overseas Chinese Scholars, State Education Ministry. We give thanks for the insightful discussion and help of Li Li. Finally, we give great thanks to the anonymous reviewers for the their suggestions to improve the quality of this paper.
Funding
The work is sponsored by Sichuan Provincial Department of Science and Technology Innovation, P.R.China, Chengdu Technological University, and Chengdu University of Information and Technology (Grant No. KYTZ201415, KYTZ201501, KYTZ201502, 2015GZ0340, 2015GZ0286, 2015GZ0290).
Authors’ contributions
YY and HW contributed to the conception and design of the study. YY and GL contributed to the acquisition of data and simulation. YY, GL, and HW contributed to the analysis and interpretation of simulation data. All authors read and approved the final manuscript.
About the authors
Dr. Yufang Yin obtained her Ph.D. degree in 2007 from EE department, the University of Texas at San Antonio. From Jan. 2009 to June. 2012, she worked as the specialist and research scientist in Nokia Networks. From July 2012 to Oct. 2014, she worked as the staff engineer in Spread Spectrum Communication. Since Nov. 2016, she joined in Chengdu Technological University. Her research area includes statistical signal processing and applied machine learning.
Gangjun Li received the B.S. degree in Mechatronic Engineering from the University of Electronic Science and Technology of China in 1987 and the M.S. degree in Mechanics from the Harbin Institute of Technology in 1990. He received the Ph.D. degree in Robotics Engineering from the Southwest Jiaotong University in 2002. Since 2010, he is a professor of Chengdu Technological University(CDTU). His research interests are in areas of robotics, simulation, modeling of complex systems and nonlinear control.
Hua Wei obtained his Ph.D. degree from ECS department, University of Southampton in September, 2005. From Jan. 2006 to Sep. 2014, he worked as the principle engineer in Spread spectrum Communication for wireless modem design. Since September 2014, he joined in Chengdu University of information Technology. His research area includes adaptive equalization, signal processing and VLSI design for wireless baseband processor.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Yin, Y., Li, G. & Wei, H. Distributed probabilistic data association detector with turbo base-station cooperations in multi-user multi-cell MIMO systems. J Wireless Com Network 2017, 81 (2017). https://doi.org/10.1186/s13638-017-0865-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13638-017-0865-8