
Abstract
An efficient robust fusion estimation (RFE) for distributed fusion system without knowledge of the cross-covariances of sensor estimation errors is suggested. With the hypothesis that the object lying in the intersection of some ellipsoids related to sensor estimations, the robust fusion estimation is designed to be a minimax problem, which is solved by proposing a novel relaxation strategy. Some properties of the RFE are discussed, and numerical simulations are also present to compare the tracking performance of RFE with that of the centralized fusion and CI method. The numerical examples show that the average tracking performance of RFE is slightly better than that of the CI method, and the performance degradation of RFE is acceptable compared with the centralized fusion.
Similar content being viewed by others


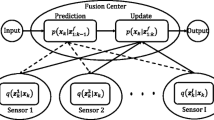
1 Introduce
In recent years, multisensor information fusion has received significant attention for both military and civilian applications. The fusion center integrates information from multiple sensors to achieve improved accuracies and system survivability than could be achieved by the use of a single sensor alone. If the communication channel and processor bandwidth are not constrained, then all observations from local sensors can be transmitted to a central processor for fusing. In this case, there is no preprocessing in each sensor, and the local sensors only act as simple observers. Therefore, the multisensor fusion system can be viewed as a single sensor system in nature, and conventional optimal methods can be implemented (see [20]). Such a multisensor fusion is called the centralized fusion. Clearly, the centralized fusion has the best performance since all observations are used. However, in many practical applications, processing all sensor measurements at a single location is sometimes infeasible due to communication or reliability constraints. So one may require that a preprocessing is performed at the individual sensors and a compressed sensor data is transmitted to the fusion center. Accordingly, we call this multisensor fusion the distributed fusion or decentralized fusion. In a distributed fusion system, the sensors will form sensor tracks from the measurements and communicate the tracks with other sensors or processors. The tracks are then associated and the estimates of associated tracks are fused in the fusion center. Many distributed fusion architectures have been proposed over the years.
With the assumption that the cross-covariance of the errors of local estimators is known, Bar-Shalom and Campo proposed a track-to-track fusion for two-sensor distributed estimation systems. The analysis of the optimality of the fusion formulae is given in [2]. For the system with l local sensors, the fusion equations presented in [8] and [10] use the fusion center’s one-step prediction as well as the l sensors’ state estimates and their one-step predictions to obtain a final fusion. Moreover, they proved rigorously that the presented fusion formulae can be converted equivalently from the corresponding centralized Kalman filtering. Recently, the best linear unbiased estimation (BLUE) (see, e.g., [12, 18]) was proposed, and a general version of the linear minimum variance of estimation fusion rule is derived. The above two estimation fusion methods turn into the special cases of BLUE fusion method with some appropriate assumptions. The BLUE fusion method relies on two assumptions: (1) the local estimators are unbiased; (2) the error covariance matrix of the sensor estimates at each time is known. The cross-covariance of estimation errors is the key to optimally fuse the sensor estimates in the distributed estimation systems, but it is very difficult to realize in many practical applications.
Over the last three decades, many works have been performed to design different appropriate distributed fusion estimations with unknown cross-covariance of estimation errors. Considering a distributed fusion system, when there exist some uncertainties in state equation or sensor observation equations, some researchers seek to design robust distributed fusion estimation by modeling the uncertainties appropriately (including deterministic and stochastic uncertainties, see [5, 6], and references therein). When the state equation and sensor observation equations are unavailable, and only the sensors estimators are given, the well-known covariance intersection (CI) filter (see [7, 11, 13]) is designed to fuse sensor estimates without cross-covariance of sensor estimators. The objective of CI filter is to obtain a consistent estimation of the covariance matrix when two estimates are linearly combined, where “consistent” means the estimated covariance is always an “upper-bound” (in the positive-definite sense) of the true covariance. The CI filter is more robust than the linear combination algorithm and provides a bound on the estimation accuracy. Therefore, the CI algorithm has been widely applied in the area of distributed estimation. However, the CI method has some obviously disadvantages: (1) it designs the estimator to be linear form of local sensor estimates; (2) the parameter to be optimized is a scalar although the estimated state may be a multiple dimensional vector.
Recently, different strategies are proposed to fuse sensor estimators without complete knowledge of the cross-covariance matrix. A formulation is proposed in [9] to restrict the set of possible cross-covariance matrices, then an optimal robust fusion method is presented in the minimax sense via semi-definite programming. The work in [1] provides a deeper insight into the suboptimality of the covariance intersection fusion of multiple estimates under unknown correlations. In reference [17], the authors generalize the covariance intersection algorithm for distributed estimation and information fusion of random vectors.
In this paper, inspired by the idea of set-membership filtering, which seeks to compute a compact feasible set in which the true state or parameter lies (see [4, 14]), we consider the problem to fuse local estimates by directly maximizing the estimation error on some set given by the prior knowledge, then select the optimal estimation to minimize it. Compared with the works in references [1, 9, 17], all the methods are presented to fuse sensor estimators with unknown cross-correlation. However, the strategies employed to design robust fusion estimation are different. In [1, 9, 17], the authors seek to design the upper bound of the cross-covariance, then robust fusion estimations are proposed based on different optimization methods. In this paper, we suppose that the true state lies in a compact feasible set, then we model it as a non-convex optimization problem with the minimax strategy, and propose a novel relaxation strategy to approximatively solve the non-convex problem. The prominent merits of the presented robust optimal fusion estimation (RFE) includes (1) instead of optimizing the trace of the estimation error covariance, we directly minimize the estimation error; (2) the fused estimator is a non-linear combination of local estimators; (3) the presented methods can be used to fusion multiple sensors directly; (4) the average tracking performance of the RFE is slightly better than that of the CI filter in our simulations.
This paper is organized as follows. A brief introduction of the CI filter are given in Section 2. Then the RFE is proposed in Section 3, and some properties the RFE are also discussed. Section 4 provided a number of simulations to show the performances of the presented method. Finally, Section 5 gives a conclusion.
2 The CI filter
The CI filter provides a mechanism for fusing two estimates of the mean value of a random variable when the correlation between the estimation errors is unknown. The following notations are followed from [7]. Let c∗∈Rn×1 be the mean of some random variable to be estimated. Two sources of information are available: estimate a∈Rn×1 and estimate b∈Rn×1. Define their estimation errors as
and suppose
The true values of \(\tilde {P}_{aa}\) and \(\tilde {P}_{bb}\) may be unknown, but some consistent estimates Paa∈Rn×n and Pbb∈Rn×n of \(\tilde {P}_{aa}\) and \(\tilde {P}_{bb}\) are obtainable respectively with properties
where the notation “ A≽B” means that the matrix A−B is positive semi-definite. The cross-covariance between the two estimation \(E\left (\tilde {a}\tilde {b}^{T}\right)=\tilde {P}_{ab}\) is also unknown.
Firstly, the CI method proposes a linear unbiased estimator
where K1,K2∈Rn×n,K1+K2=I. Let \(\tilde {c}=c-c^{*}\), then the covariance of \(\tilde {c}\) is
Secondly, it tries to find a consistent estimator Pcc of \(\tilde {P}_{cc}\), such that \(P_{cc}\succeq \tilde {P}_{cc}\). It is easy to find a kind of consistent estimators in following form
Finally, the CI estimator is derived by minimizing the trace of Pcc which is given as follows.
Theorem 1
(Theorem 2 in [7]) There exists ω∈[0,1] such that
is minimized by
Therefore, the CI estimator is \(a\omega P_{cc}P_{aa}^{-1}+b\omega P_{cc}P_{bb}^{-1}\).
3 The robust fusion estimation
In a distributed system with l sensors, let xk∈Rn is a deterministic parameter vector to be estimated. Suppose \(\hat {x}_{k}^{(i)},i=1,\ldots, l\) are sensor estimators of xk at time k, and we have the prior information that the state xk lies in the non-empty intersection of l ellipsoids \(S_{k}^{(i)}\)defined by
where \(P_{k}^{(i)}\) are some known positive semi-definite matrices, and ai is a positive scalar. It is easy to standardize the ellipsoids as
When the fusion central receives l sensor estimators and the ellipsoids \(S_{k}^{(i)},i=1,\ldots, l\), they should be fused to obtain optimal fusion estimation. Therefore, we first maximize the estimation error over the intersection of \(S_{k}^{(i)}\), then choose the fusion estimate \(\hat {x}_{k}\) to minimize the estimation error. Finally, the fusion estimation is designed to solve the following minimax problem:
Generally speaking, problem (1) is an NP-hard problem when l≥2. In the sequel, we seek for approximation solution of problem (1) by designing a convex relaxation strategy.
The following lemmas are necessary for further derivation.
Lemma 1
(see [15]) Let X be an symmetric matrix partitioned as
Then X>0 if and only if \(X_{3}-X_{2}'X_{1}^{-1}X_{2}>0\). Furthermore, if X1>0, then X≥0 if and only if \(X_{3}-X_{2}'X_{1}^{-1}X_{2}\geq 0\).
Lemma 2
Let ε,γi be non-negative scalars, z and Bi be any compatible vector and Hermitian matrices, i=1,…,l. Then the following inequality holds for any vector y and scalar t
if and only if
Furthermore, if (2) or (3) holds, then
Proof
Note that (3) is equivalent to
holds for any vector y and scalar t, which implies the equivalence between (2) and (3). At the same time, from (2),
Obviously,
Therefore, (4) follows from (2).
A positive semi-definite relaxation of problem (1) is presented in the following theorem, which can be solved by some efficient semidefinite programming solvers such as SeDuMi (see [16]). □
Theorem 2
The positive semi-definite relaxation of the optimal problem (1) is
where \(A_{k}^{(i)}=(0,\ldots,I\ldots,0)_{n\times nl}, Q_{k}^{(i)}=\left (A_{k}^{(i)}\right)^{T} P_{k}^{(i)}A_{k}^{(i)}, i=1,\ldots,l\). The optimal fusion estimation \(\hat {x}_{k}\) is given by the solution of the SDP problem (5).
Proof
Note that problem (1) is the same as
Denoted by
then \(\eta _{k}^{(i)}=A_{k}^{(i)}\eta _{k},i=1,\ldots,l\). For any real scalars \(\alpha _{k}^{(i)},i=1,\ldots, l\) satisfy \(\sum \limits _{i=1}^{l}\alpha _{k}^{(i)}=1\), let
Note that the ζk is not the linear combination of local estimator \(\hat {x}_{k}^{(i)}\), unless the \(\alpha _{k}^{(i)}\) is independent of local estimators \(\hat {x}_{k}^{(i)}\). In fact, the \(\alpha _{k}^{(i)}\) is given by the optimal problem (1), thus it is not independent of \(\hat {x}_{k}^{(i)}\). Therefore, problem (6) is the same as
Let \(\beta _{k}=\zeta _{k}-\hat {x}_{k}, Q_{k}^{(i)}=(A_{k}^{(i)})^{T} P_{k}^{(i)}A_{k}^{(i)}\), so \(x_{k}-\zeta _{k}=\sum _{i=1}^{l}\alpha _{k}^{(i)}A_{k}^{(i)}\eta _{k}\). Denote \(A_{k}=\sum _{i=1}^{l}\alpha _{k}^{(i)}A_{k}^{(i)}\), then problem (7) is equivalent to
Considering the constrains of problem (8), it is the same as
Equivalently,
which can be reformulated to
From Lemma 2, for non-negative scalars γ,γi,i=1,…,l, the constrains
and
are sufficient for (9) holding. Let \(\epsilon =\gamma +\beta _{k}^{T}\beta _{k}\), then (10) can be rewritten as
From Lemma 1, which is equivalent to
Therefore, we can relax the problem (8) to be the following SDP problem:
which is equivalent to
Then, we finish the proof from the equivalence between the problem (8) and problem (1). □
Remark 1
Theorem 2 gives a approximate solution of problem (1), and the approximation is exactly when l=1 (see [3]). Furthermore, the proof of the Theorem 2 does not require the positive semi-definite of Pk, so we can only require the Pk to be Hermitian if problem (5) is of sense.
Just like the idea of weighted least squares estimation, we can generalize the result by introducing a positive semi-definite weight-valued matrix Wk, and replace problem (1) by
where \(\|x_{k}-\hat {x}_{k}\|_{W_{k}}=(x_{k}-\hat {x}_{k})^{T}W_{k}(x_{k}-\hat {x}_{k})\).
Obviously, it is of sense to introduce weight matrix Wk if one wants to give different punishments to the estimation error in different dimension. Then, problem (1) is a special of problem (11) by taking Wk=I. Similar to the proof of Theorem 2, we can derived the positive semi-definite relaxation of problem (11).
Colloary 1
The positive semi-definite relaxation of optimal problem (11) is
where \(A_{k}^{(i)}, Q_{k}^{(i)}\) is defined as in Theorem 2. The optimal fusion estimation \(\hat {x}_{k}\) is given by the solution of the SDP (12).
Theorem 2 provides a way to fusion sensor estimates when the prior knowledge \(x_{k}\in \bigcap _{i=1}^{l}S_{k}^{(i)}\) is available. With appropriate assumption, the feasible and unique of the solution to problem (1) can be derived.
Proposition 1
Suppose the set \(\bigcap _{i=1}^{l}S_{k}^{(i)}\) has non-empty inner point, then the optimal fusion estimation given by problem (1) is feasible and unique.
Proof
Note that problem (1) can be rewritten as
thus \(\max _{x_{k}\in \bigcap _{i=1}^{l} S_{k}^{(i)}}\left (-2x_{k}^{T}\hat {x}_{k}+\|x_{k}\|_{2}^{2}\right)\) is convex in \(\hat {x}_{k}\). Therefore, \( \|\hat {x}_{k}\|_{2}^{2}+\max _{x_{k}\in \bigcap _{i=1}^{l}S_{k}^{(i)}}\left (-2x_{k}^{T}\hat {x}_{k}+\|x_{k}\|_{2}^{2}\right)\) is strictly convex in \(\hat {x}_{k}\), which implies the solution of problem (1) is feasible and unique.
In the sequel, some properties of RFE are considered. □
Theorem 3
Suppose that there is one \(P_{k}^{(i)}>0\), then the feasible solution set of problem (5) is always non-empty, thus the solution of problem (5) always exists.
Proof
Without loss of generality, suppose \(P_{k}^{(l)}>0\), note that problem (5) is the same as
Let \(\alpha _{k}^{(i)}=0, i=1,\ldots,l-1\), and \(\hat {x}_{k}=\hat {x}_{k}^{(l)}\), then the matrix constrain is
equivalently,
Note that \(P_{k}^{(i)}\!\geq 0,i=1,\ldots,l-1\), and \(P_{k}^{(l)}>0\), then (13) always holds by taking large enough γl. In other words, the feasible solution set of problem (5) is always non-empty, thus the positive semi-definite relaxation solution exists. □
Proposition 2
Suppose \(P_{k}^{(i)}>0, i=1,\cdots,l\), then each local estimate \(\hat {x}_{k}^{(i)}\) is a feasible fusion estimations of problem (5). In other words, the fusion estimation \(\hat {x}_{k}\) always has better tracking performance than that of local estimates \(\hat {x}_{k}^{(i)}\).
Proof
Suppose \(P_{k}^{(l)}>0\), from the proof of Theorem 3, there exist appropriate ε, \(\alpha _{k}^{(i)}, \gamma _{i},i=1,\cdots,l\) and τ, such that \((\epsilon,\gamma _{i},\tau,\hat {x}_{k}^{(l)}, \alpha _{k}^{(i)})\) is a feasible solution of problem (5). Therefore, the local estimate \(\hat {x}_{k}^{(l)}\) is a feasible fusion estimation. The proofs of local estimates \(\hat {x}_{k}^{(i)}, i=1, \cdots, l-1\) are similar. □
4 Simulations
Considering that both RFE and CI method seek for fusing local estimates with unknown cross-covariance, and the knowledge of state and sensor observation equations is not unavailable in the design of the fusion estimation. Therefore, some comparisons between the RFE and CI method are provided to analyze the tracking performance of the proposed method. Furthermore, the centralized fusion is also employed to show the performance degradation of the proposed method.
Simulation 1: The simulations were done for a dynamic system modeled as an object moving in a helical trajectory at constant speed with process and measurement noises. Let the system equation be
where vk is the Gaussian noise with zero mean and covariance matrix
and xk is a deterministic parameter vector with initial state x0=(1,0), and
At time k, two sensors estimate xk in the plane from observations \(y_{k}^{(i)}\) respectively, which are related through the linear model
where \(w_{k}^{(i)}\) is Gaussian noise with zero mean and covariance matric \(R_{w_{k}^{(i)}}\) is
and the measurement matrices Hi (i=1,2) are also constant and given by
To obtain the local estimation \(\hat {x}_{k}^{(i)}\) and their covariance matrices \(C_{k}^{(i)}~(i=1,2) \) of xk at every step, Kalman filter is employed to each sensor.
Then, the CI and RFE methods are applied to fuse the local estimations by taking ai=8 and \(\bar {P}_{k}^{(i)}=(C_{k}^{(i)})^{-1}\) for i=1,2. Using Monte Carlo method of 50 runs, the absolute track errors in x-axis and y-axis are given in Figs. 1, 2, 3, and 4.

The absolute tracking errors of CI method in x-axis with ai=8

The absolute tracking errors of RFE in x-axis with ai=8

The absolute tracking errors of CI method in y-axis with ai=8

The absolute tracking errors of RFE in y-axis with ai=8
From Figs. 1 and 2, the average tracking performance of FRE is comparable to that of CI method. The average absolute tracking errors of RFE and CI method in x-axis are 0.080 and 0.094, respectively. For the average tracking performance in y-axis, the case is similar. As shown in Figs. 3 and 4, the average absolute tracking errors are 0.083 and 0.072 respectively.
In order to derive a clearer comparison of average tracking performance, we evaluate the tracking performance of an algorithm by estimating the second moments of the tracking errors \(E_{k}^{2}\), which is presented in [19], and given by
using Monte Carlo method of 50 runs, the second moments of the tracking errors of CI and RFE are given in Fig. 5.

The comparison of the second moments of the tracking errors with ai=8
It can be observed from Fig. 5, the RFE has smaller second moments of the tracking errors.
Therefore, compared with the CI method, the average tracking performance of RFE is slightly better than that of CI method.
More comparisons are present in the following with different ai.
From Figs. 6, 7, 8, and 9, for ai=10,i=1,2, the average absolute tracking errors of CI method and RFE in x-axis are 0.092 and 0.078, and the average absolute tracking errors in y-axis are 0.077 and 0.067, respectively.

The absolute tracking errors of CI method in x-axis with ai=10

The absolute tracking errors of RFE in x-axis with ai=10

The absolute tracking errors in of CI method in y-axis with ai=10

The absolute tracking errors of RFE in y-axis with ai=10
Let ai=12,i=1,2, as shown in Figs. 10, 11, 12, and 13, the average absolute tracking errors of CI method and RFE in x-axis are 0.089 and 0.072, and the average absolute tracking errors in y-axis are 0.079 and 0.067, respectively.

The absolute tracking errors of CI method in x-axis with ai=12

The absolute tracking errors of RFE in x-axis with ai=12

The absolute tracking errors in of CI method in y-axis with ai=12

The absolute tracking errors of RFE in y-axis with ai=12
It can be observed from Figs. 14, 15, 16, and 17, as ai=14,i=1,2, the average absolute tracking errors of CI method and RFE in x-axis are 0.097 and 0.083, and the average absolute tracking errors in y-axis are 0.078 and 0.068, respectively.

The absolute tracking errors of CI method in x-axis with ai=14

The absolute tracking errors of RFE in x-axis with ai=14

The absolute tracking errors in of CI method in y-axis with ai=14

The absolute tracking errors of RFE in y-axis with ai=14
As shown in Figs. 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, and 17, when ai varied from 8 to 14, both the tracking performance of RFE and CI method are degraded. However, the average absolute tracking errors of RFE are always slightly better than that of CI method.
In the sequel, the performance of the proposed method is verified under different cross-correlation levels. To assure that the levels of cross-correlation varies in steady state for the above tracking problem, let
where \(u_{k}^{(i)},i=1,2\) are sampled from the sets {0.5,1,1.5} and {1.5,2,2.5} in equal probability respectively. The parameters ai,i=1,2 are taken as a1=8 and a2=10. After 50 Monte Carlo runs, the comparisons of the absolute track errors in x-axis and y-axis are given in Figs. 18, 19, 20, and 21.

The absolute tracking errors of CI method in x-axis with varied cross-correlation

The absolute tracking errors of RFE in x-axis with varied cross-correlation

The absolute tracking errors of CI method in y-axis with varied cross-correlation

The absolute tracking errors of RFE in y-axis with varied cross-correlation
As shown in Figs. 18, 19, 20, and 21, the average absolute tracking errors of CI method and RFE in x-axis are 0.4337 and 0.4175, and the average absolute tracking errors in y-axis are 0.6360 and 0.5362, respectively.
Simulation 2: In the following, the RFE is employed to fuse three sensor estimators, and the centralized fusion is used to show the performance degradation of RFE.
The object dynamics equation and the first two sensor measurement equations are the same as given in simulation 1. The third sensor measurement equation is \(y_{k}^{(3)}=H_{3}x_{k}+w_{k}^{(3)}\), where \(w_{k}^{(3)}\) is Gaussian noise with zero mean and covariance matric \(R_{w_{k}^{(3)}}\) is
and the measurement matrices
With 50 Monte Carlo simulations, the average absolute tracking errors of the RFE and centralized fusion are presented in Figs. 22, 23, 24, and 25.

The absolute tracking errors of the centralized fusion in x-axis with ai=10

The absolute tracking errors of RFE in x-axis with ai=10

The absolute tracking errors of the centralized fusion in y-axis with ai=10

The absolute tracking errors of RFE in y-axis with ai=10
It can be observed from Figs. 22, 23, 24, and 25, the absolute tracking errors of RFE are larger than that of the centralized fusion. The average absolute tracking errors of the RFE and centralized fusion in x-axis are 0.071 and 0.054, and the average absolute tracking errors in y-axis are 0.056 and 0.049. Considering that the centralized fusion utilizes complete information of system and observation equations, the performance degradation of RFE is acceptable.
The second moments of the tracking errors of RFE and the centralized fusion are given in Fig. 26.

The comparison of the second moments of the tracking errors
As shown in Fig. 26, after 30 steps, the tracking performance of both method become stable, and the second moments of the tracking errors of RFE is about 0.005 larger than that of the centralized fusion.
5 Conclusion
A robust fusion estimation in distributed systems are derived in this paper which minimizes the worst-case estimation errors on some given parameter set. Compared with the BLUE fusion, the RFE tracks well without the information of the cross-covariance between sensor estimates. At the same time, simulation example shows that the tracking performance of RFE is comparable to that of the CI filter.
References
J. Ajgl, O. Straka, Fusion of multiple estimates by covariance intersection: why and how it is suboptimal. Int. J. Appl. Math. Comput. Sci. 28(3), 521–530 (2018).
Y. Bar-Shalom, L. Campo, The effect of the common process noise on the two-sensor fused track covariance. IEEE Trans. on Aero. Elect. Syst. AES-22:, 803–805 (1986).
A. Ben-Tal, L. E. Ghaoui, A. Nemirovski, Robust Optimization (Princeton University Press, Princeton, 2009).
D. P. Bersekas, I. B. Rhodes, Recursive state estimation for a Set-Membership description of uncertainty. IEEE Trans. on Auto. Contr. 16(2), 117–128 (1971).
B. Chen, G. Q. Hu, W. C. Ho Daniel, W. A. Zhang, L. Yu, Distributed robust fusion estimation with application to state monitoring systems. IEEE Trans. Syst. Man Cybern. Syst.47(11), 2994–3005 (2017).
B. Chen, W. C. Ho Daniel, W. A. Zhang, L. Yu, Networked fusion estimation with bounded noises. IEEE Tran. on Auto. Contr.62(10), 5415–5421 (2017).
L. Chen, P. O. Arambel, R. K. Mehra, Estimation under unknown correlation: covariance intersection revisited. IEEE Trans. on Auto. Contr.47(11), 1879–1882 (2002).
C. Y. Chong, K. C. Chang, S. Mori, in Proc. 1986 Amer. Contr. Conf.Distributed tracking in distributed sensor networks (IEEESeattle, 1986).
Y. Gao, X. R. Li, E. Song, Robust linear estimation fusion with allowable unknown cross-covariance. IEEE Trans. Syst. Man Cybern. Syst.46(9), 1324–1325 (2016).
H. R. Hashmipour, S. Roy, A. J. Laub, Decentralized structure for parallel Kalman filtering. IEEE Trans. Auto. Contr. AC-33:, 88–93 (1988).
S. Julier, J. Uhlmann, in Handbook of Multisensor Data Fusion, Ch. 12, ed. by D. Hall, J. Llians. General decentralized data fusion with co-variance intersection (CI) (CRC PressBoca Raton, 2001), pp. 12–1–12-25.
X. R. Li, Y. M. Zhu, J. Wang, C. Z. Han, Optimal linear estimation fusion - Part I: unified fusion rules. IEEE Trans. Inform. Theory. 49(9), 2192–2208 (2003).
D. Nicholson, R. Deaves, in Proc. SPIE, Signal and Data Processing of Small Targets, Vol. 4048. Decentralized Track Fusion in Dynamic Networks (SPIE, 2000). https://doi.org/10.1117/12.357168.
F. C. Schweppe, Recursive state estimation: unknown but bounded errors and system inputs. IEEE Trans. Auto. Contr. 13(1), 22–38 (1968).
J. F. Sturm, Using SeDuMi 1.02, a Matlab toolbox for optimization over symmetric cones. Optim. Methods Softw.11–12:, 625–653 (1999).
L. Vandenberghe, S. Boyd, Semidefinite Programming. SIAM Rev.38(1), 40–95 (1996).
Z. Wu, Q. Cai, M. Fu, Covariance Intersection for Partially Correlated Random Vectors. IEEE Trans. Auto. Contr.63(3), 619–629 (2018).
J. Zhou, Y. M. Zhu, Z. S. You, E. B. Song, An efficient algorithm for optimal linear estimation fusion in distributed multisensor systems. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum.36(5), 1000–1009 (2006).
Y. M. Zhu, Efficient recursive state estimator for dynamic systems without knowledge of noise covariances. IEEE Trans. Aero. Elect. Syst.35(1), 102–114 (1999).
Y. M. Zhu (Kluwer Academic Publishers, Boston, 2003).
Acknowledgements
The authors thank for the valuable and constructive comments from the editor and reviewers.
Funding
This work was supported in part by the project of Yangtze Upriver Economic Research Center under grant CJSYI-201806, the project of social science program of Chongqing Education Commission of China under grant 19SKGH230, the youth project of science and technology research program of Chongqing Education Commission of China under grant KJQN201802102, the NSF of China under grants 11871124 and 11471060, and Basic Research Program of Chongqing under grant cstc2018jcyjAX0241.
Author information
Authors and Affiliations
Contributions
DW conceived of the algorithm and designed the experiments. AH performed the experiments, analyzed the results, and drafted the manuscript. DW and AH revised the manuscript. Both authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Wu, D., Hu, A. A robust fusion estimation with unknown cross-covariance in distributed systems. EURASIP J. Adv. Signal Process. 2019, 45 (2019). https://doi.org/10.1186/s13634-019-0640-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13634-019-0640-6