
Abstract
Background
Both hyperkalemia and hypokalemia can lead to cardiac arrhythmias and are associated with increased mortality. Information on the predictors of potassium in individuals with diabetes in routine clinical practice is lacking.
Objective
To identify predictors of hyperkalemia and hypokalemia in adults with diabetes.
Design
Retrospective cohort study, with classification and regression tree (CART) analysis.
Participants
321,856 individuals with diabetes enrolled in four large integrated health care systems from 2012 to 2013.
Main Measures
We used a single serum potassium result collected in 2012 or 2013. Hyperkalemia was defined as a serum potassium ≥ 5.5 mEq/L and hypokalemia as < 3.5 mEq/L. Predictors included demographic factors, laboratory measurements, comorbidities, medication use, and health care utilization.
Key Results
There were 2556 hypokalemia events (0.8%) and 1517 hyperkalemia events (0.5%). In univariate analyses, we identified concordant predictors (associated with increased probability of both hyperkalemia and hypokalemia), discordant predictors, and predictors of only hyperkalemia or hypokalemia. In CART models, the hyperkalemia “tree” had 5 nodes and a c-statistic of 0.76. The nodes were defined by prior potassium results and eGFRs, and the 5 terminal “leaves” had hyperkalemia probabilities of 0.2 to 7.2%. The hypokalemia tree had 4 nodes and a c-statistic of 0.76. The hypokalemia tree included nodes defined by prior potassium results, and the 4 terminal leaves had hypokalemia probabilities of 0.3 to 17.6%. Individuals with a recent potassium between 4.0 and 5.0 mEq/L, eGFR ≥ 45 mL/min/1.73m2, and no hypokalemia in the previous year had a < 1% rate of either hypokalemia or hyperkalemia.
Conclusions
The yield of routine serum potassium testing may be low in individuals with a recent serum potassium between 4.0 and 5.0 mEq/L, eGFR ≥ 45 mL/min/1.73m2, and no recent history of hypokalemia. We did not examine the effect of recent changes in clinical condition or medications on acute potassium changes.
Similar content being viewed by others

INTRODUCTION
Medical laboratory testing is common in the USA, with over 4 billion tests ordered a year.1 Serum potassium is frequently monitored in individuals on specific medications and individuals with diabetes and other chronic diseases. Both hyperkalemia and hypokalemia can be dangerous, potentially leading to severe cardiac arrhythmias and increased mortality.2,3,4,5,6 Additionally, hyperkalemia can lead to muscle weakness, paralysis, cardiac arrhythmias, and sudden cardiac death,2 while hypokalemia increases risk of arrhythmias due to alterations in membrane excitability, cardiac automaticity, and ventricular repolarization.3 The association between mortality and abnormalities of potassium homeostasis has been shown to be higher at both extremes of serum potassium in the general population7 and in individuals with chronic kidney disease,4,5,6 heart failure, and diabetes.5
Diabetes is associated with a higher risk of hyperkalemia,8, 9 which can be due to insulin deficiency, acidosis, hyporeninemic hypoaldosteronism, renal tubular acidosis type IV, or comorbid chronic kidney disease.8, 10 In addition, blood pressure medications commonly used in diabetes, such as renin-angiotensin-aldosterone system (RAAS) inhibitors, beta blockers, and potassium-sparing diuretics, also increase the risk of hyperkalemia.10 Chronic kidney disease and heart failure, which are also associated with potassium abnormalities, are common in individuals with diabetes.3, 8
Information on the predictors of hyperkalemia and hypokalemia in individuals with diabetes in routine clinical practice is lacking, however. This information could guide decisions about the frequency of surveillance for both conditions, especially in light of attempts to minimize unnecessary testing in a patient population at risk for abnormalities in serum potassium.1 Using data from four large integrated health systems, we used classification and regression tree (CART) models to determine the prevalence and important predictors of hyperkalemia and hypokalemia among individuals with diabetes.
METHODS
Participants
This study was based in the SUPREME-DM (Surveillance, Prevention, and Effectiveness of ManagEment in Diabetes Mellitus) cohort of individuals with diabetes at 4 integrated health systems (HealthPartners [Minnesota], Kaiser Permanente Colorado, Kaiser Permanente Northern California, and Kaiser Permanente Northwest [Oregon/Washington]) from 2005 to 2013. Research institutes embedded in these health systems have developed a distributed virtual data warehouse that contains information on demographics, outpatient pharmacy dispensing, laboratory tests and results, and diagnostic and procedure codes from outpatient and inpatient health care encounters from their electronic health record and administrative data systems.11,12,13
In this study, diabetes was defined using diagnosis codes, medications, and lab results, as previously described (Appendix Table 2).11, 12 Individuals with diabetes were included in these analyses if they were (1) ages 21 or older, (2) enrolled in a participating health care system at any point in 2012–2013 with at least 1 year of prior enrollment, (3) not pregnant, (4) did not have end-stage renal disease, (5) had a serum potassium test in 2012–2013, and (6) had a serum creatinine test within the previous 18 months.
Measures
Outcomes
Hyperkalemia was defined as a serum potassium ≥ 5.5 mEq/L, and hypokalemia was defined as a serum potassium < 3.5 mEq/L. We collected outpatient serum potassium results between 2012 and 2013 and used the most recent one for the classification trees. The date of this serum potassium result was considered the index date.
Exposures
We identified potential predictors of hyperkalemia and hypokalemia using literature review and subject matter knowledge. Potential predictors included demographic factors (age, gender, race/ethnicity, body mass index (BMI) and diabetes type (type 1 vs type 2), the most recent laboratory measurements of eGFR, A1c, and albuminuria in the 18 months prior to but not including the date of the serum potassium lab (the index date)), the number of potassium results in the prior year, comorbidities defined as the presence of one or more diagnosis codes in the prior year (Quan-Elixhauser comorbidity score,16 congestive heart failure, hypertension, dementia, coronary artery disease, cerebrovascular disease, malignancy, and depression), the number of unique medications prescribed in the prior year, and acute care utilization (emergency department visit in the prior year, inpatient hospitalization in the prior year). We also created variables for current medications of interest (angiotensin-converting enzyme inhibitors and/or angiotensin receptor blockers (ACE/ARB), sulfamethoxazole/trimethoprim, beta blockers, digoxin, potassium-sparing diuretics, other diuretics, potassium chloride supplements, use of medications from 4 or more blood pressure medication classes) using prescriptions where the days’ supply plus 10% would have included the date of the index serum potassium result.
We also included a variable for either the presence of prior hyperkalemia or hypokalemia in the 30–365 days (depending on the model), as well as the most recent potassium results within the prior 30–365 days. We did not consider serum potassium results in the 29 days prior to the index date, as these may have represented sequential tests in the same “episode” of hyperkalemia or hypokalemia. Predictors based on diagnostic codes that were considered and excluded due to very low prevalence (< 1%) included the following: renal tubular acidosis, connective tissue disorders, HIV/AIDS, sickle cell disease, calcineurin inhibitors, amyloid disease, and adrenal insufficiency. Use of pentamidine or mineralocorticoids was also excluded due to low frequency. All covariates were assessed as the most recent value prior to but not including the day of the serum potassium result. Diagnostic codes for the different exposure variables are shown in Appendix Table 2.
Analysis
To conduct classification and regression tree (CART) analysis, we built classification trees using binary recursive partitioning for the hyperkalemia and hypokalemia categorical outcomes. Recursive partitioning uses a nonlinear and nonparametric approach to divide events into two subgroups based on continuous or categorical predictors. Unlike linear modeling methods, this approach is able to easily identify complex nested interactions and to identify nonlinear associations.18, 19 The goal was to find parsimonious tress that performed well using pruning to try to limit the number of terminal nodes.
When building the CART models, we built the models using 50% of the observations and used the other half to validate the models.20,21,22,23 Missing data were present for BMI (0.3%), A1c (4.0%), proteinuria (17.1%), race (2.5%), and most recent serum potassium result (20.3%) and were included as a separate category in the models. For the most recent serum potassium result and eGFR, we used conventional and standardized categories to define cutpoints (potassium results: missing, < 3.5 mEq/L, 3.5–3.9 mEq/L, 4.0–4.4 mEq/L, 4.5–4.9 mEq/L, 5.0–5.4 mEq/L, ≥ 5.5 mEq/L; eGFR values 15–29 mL/min/1.73m2, 30–44 mL/min/1.73m2, 45–59 mL/min/1.73m2, 60–89 mL/min/1.73m2, ≥ 90 mL/min/1.73m2).
During the tree training phase, if a numeric variable being considered for a candidate split has missing values (i.e., BMI, A1c), these are excluded from the assessment of that variable. If that variable is chosen for the split, observations with missing values on that variable are removed from the entire tree. During prediction, if there are missing values in a numeric variable used in the chosen tree, those records are dropped. Because most recent potassium value was specified using categories, missing values for most recent potassium value remained in the tree.
We used the c-statistic to assess performance on trees ranging from 2 to 20 terminal nodes. Tenfold cross-validation was used on each tree size to determine best performance, and the c-statistic was calculated from predicting the best-sized tree developed in the training sample on the holdout sample. In this setting, the c-statistic can be conceptualized as the area under the ROC curve, or the proportion of all possible outcome discordant pairs where the predicted probability ranks the pair correctly. For the final model, we estimated a tree of the chosen size on the combined training and validation sample. The binary recursive partitioning was all conducted in R version 3.4.3 using the tree package.24, 25
Using clinical judgment, we consider a risk of less than 1% to be low risk of hyperkalemia or hypokalemia, 1–5% to be intermediate risk, and 5% or greater to be high risk.26, 27
This study was approved by the KPCO Institutional Review Board (IRB), with the other institutions’ IRBs ceding oversight to the KPCO IRB. Informed consent was not required.
RESULTS
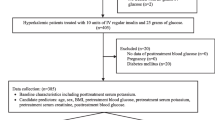
We identified 393,551 individuals with diabetes enrolled at any time during 2012–2013 (Fig. 1). Of those, 42,694 (10.8%) did not have any qualifying serum potassium results. After exclusions for pregnancy, ESRD, and lack of baseline eGFR, the final cohort included 321,856 individuals. The mean number of serum potassium results over the 2-year period was 3.8 (STD 3.8).

Cohort construction.
For the 2-year period (2012–2013), the prevalence of ever having hyperkalemia was 3.6% (11,450/321,856) and of every having hypokalemia was 3.4% (11,075/321,856). Using only the most recent serum potassium results between 2012 and 2013, we included 2556 hypokalemia events (0.8%) and 1517 hyperkalemia events (0.5%) in subsequent analyses.
Table 1 describes the characteristics of the population and their univariate associations with hyperkalemia and hypokalemia. Many factors were concordant and associated with increased probability of both hyperkalemia and hypokalemia. These include older age, decreased eGFR, proteinuria, total number of comorbidities (Elixhauser comorbidity scale), congestive heart failure, malignancy, hypertension, dementia, coronary artery disease and cerebrovascular disease, and depression, emergency department or inpatient utilization, beta blocker use, other diuretic use, sulfamethoxazole/trimethoprim use, potassium supplement use, use of 4 or more classes of blood pressure medications, number of medications in the prior year, and number of serum potassium results in the previous year. There were also several discordant characteristics. Men were more likely to have hyperkalemia, while women were more likely to have hypokalemia. Hyperkalemia was more common among white individuals, while hypokalemia was more common among African Americans. Digoxin use was associated with an increased probability of hyperkalemia. ACE/ARB use was associated with a decreased probability of hypokalemia. Interesting, ACE/ARB use was not associated with an increased probability of hyperkalemia. Use of potassium-sparing diuretics was associated with a decreased probability of hyperkalemia and increased probability of hypokalemia. Type 1 diabetes was associated with an increased probability of hyperkalemia.
Appendix Table 3 shows similar associations for ever having hyperkalemia or hypokalemia from 2012 to 2013, with the following exceptions: digoxin use was also associated with an increased probability of hypokalemia, ACE/ARB use was associated with an increased probability of hyperkalemia, and type 1 diabetes was associated with a decreased probability of hypokalemia.
Figure 2 a and Appendix Table 4 illustrate that the probability of both hyperkalemia and hypokalemia increased with decreasing eGFR. The association was stronger for hyperkalemia, with a prevalence of hyperkalemia 16.5 times higher in individuals with an eGFR of 15–29 mL/min/1.73m2 than in individuals with an eGFR ≥ 90 mL/min/1.73m2. For hypokalemia, the prevalence of hypokalemia was 2.9 times higher in individuals with an eGFR of 15–29 mL/min/1.73m2 than in individuals with an eGFR of ≥ 90 mL/min/1.73m2.

a Association between eGFR and hyperkalemia and hypokalemia. b Association between most recent prior potassium value and hyperkalemia and hypokalemia.
Figure 2 b and Appendix Table 4 illustrate the strong relationship between the most recent serum potassium result and the risk of hyperkalemia and hypokalemia. In individuals with a prior serum potassium < 5.0 mEq/L, the risk of hyperkalemia was < 1.0%, while the risk in individuals with a prior serum potassium of 5.0–5.4 was 2.6%, and in individuals with a prior serum potassium ≥ 5.5 was 8.4%. In individuals with a prior serum potassium > 4.0 mEq/L, the risk of hypokalemia was < 1.0%, while the risk in individuals with a prior serum potassium of 3.5–4.0 mEq/L was 3.2%, and in individuals with a prior serum potassium < 3.5 mEq/L was 17.0%.
The final hyperkalemia tree had 5 nodes (Fig. 3a), and the final hypokalemia tree had 4 nodes (Fig. 3b). The hyperkalemia tree had a c-statistic of 0.76 in the training set, and the hold out c-statistic was 0.76. The nodes were limited to prior serum potassium results and eGFRs, and the 5 terminal leaves had probabilities of hyperkalemia ranging from 0.2 to 7.2%. The vast majority (84.4%) of the sample was in the lowest probability terminal leaf. Using cutpoints as defined above for low (< 1%), intermediate (1–5%), and high (≥ 5%) risk, then the population can be divided into risk groups using a few simple rules: (1) most recent potassium value > 5.0 and any hyperkalemia in the past year = high risk; (2) most recent potassium value > 5.0, no hyperkalemia in the past year, and eGFR < 30 mL/min/1.73m2 = high risk; (3) most recent potassium result < 5.0, and eGFR ≥ 45 = low risk; (4) all others = intermediate risk.

a Hyperkalemia tree with 5 nodes, training sample. *Includes individuals with missing recent potassium values. *c-statistic in the training sample was 0.76, and in the hold out sample was 0.76. b Hypokalemia tree with 4 nodes, training sample. *Includes individuals with missing recent potassium values *c-statistic in the training sample was 0.76, and in the hold out sample was 0.77.
The hypokalemia tree had a c-statistic of 0.76 in the training set, and the hold out c-statistic was 0.77. The hypokalemia tree included nodes based on prior serum potassium results, and the 4 terminal leaves had probabilities of hypokalemia ranging from 0.3 to 17.6%. The vast majority (88.5%) of the sample was in the lowest probability terminal leaf. Using the same risk cut points as for hyperkalemia, the population can be divided into risk groups with the following rules: (1) any hypokalemia in the past year = high risk; (2) no hypokalemia in the past year and most recent K is between 3.5 and 4 = intermediate risk; (3) all others = low risk.
DISCUSSION
In this population of individuals with diabetes, the prevalence rates of hyperkalemia and hypokalemia were low (0.5% and 0.8%, respectively). Demographic factors, comorbid conditions, and medications were associated with an increased probability of both hyperkalemia and hypokalemia. There were also some discordant factors, including gender, race, certain medications, and prior serum potassium results. Low eGFR and prior serum potassium results, but not other demographic characteristics, clinical variables, or medications, defined the branch points in both the hyperkalemia trees, while the hypokalemia nodes were all based on prior serum potassium results. These risk factors are well established but emphasize the low overall rates of hyperkalemia and hypokalemia and the prognostic importance of prior serum potassium results.
Individuals with diabetes often undergo both routine serum potassium testing (often as part of a battery of annual or semi-annual labs) and serum potassium testing that are prompted by clinical factors (illness, medication changes, recent hospitalization). As a result, the true point prevalence of hyperkalemia and hypokalemia is likely lower than that observed in our study.
Strengths of our analysis include our evaluation of the frequency and likelihood of hyperkalemia and hypokalemia in real world setting, where the frequency likely differs from that observed in clinical trials. In addition, we had access to nearly complete outpatient laboratory values and a wide range of covariates. Our focus on prediction of hypokalemia and hyperkalemia using the information available to the clinician at the time the decision is made to test for serum potassium replicates the clinical decision-making process. Meanwhile, our use of CART regression divides the population into risk categories in a clear and transparent manner.
In the Stockholm CREAtinine Measurements (SCREAM) project of 364,955 individuals receiving health care in Stockholm, Sweden in 2009 and followed for 3 years, 13.6% had at least one episode of hypokalemia and 2.5% had hyperkalemia. The median number of measurements was 2 per year.9 In the Geisinger Health System, over a 3-year time period, the proportion of patients with hyperkalemia was 2.3%.2 Over a 2-year time period, we found a lower prevalence of hypokalemia (3.4%) and slightly higher prevalence of hyperkalemia (3.6%).
Most of the risk factors that we identified for hyperkalemia are similar to those reported by others,7, 9 with the exception that we did not find a higher risk of hypokalemia in younger individuals. In addition, the direction of associations for some blood pressure medications differed. For example, we did not find an association between ACE/ARBs and increased risk of hyperkalemia and did find associations between potassium-sparing diuretics and hypokalemia and between potassium supplements and hypokalemia. These likely reflect decisions that clinicians have made in the setting of prior hypokalemia, or due to co-prescription with other medications that may cause hypokalemia, and thus could reflect different patterns of confounding by indication.
Limitations of our study include the lack of standardized laboratory testing processes across the study sites and within study sites. While we attempted to identify erroneous values, spurious values (especially hyperkalemia due to hemolyzed samples) may have occurred. While we did not include potassium values in the 29 days preceding the index value, there is the possibility of recent clinical actions after the most recent potassium value affecting the index potassium value. Our study reflects patterns of care in 4 large integrated health systems and so may not be generalizable to other health care settings. Confounding by indication complicates the ability to interpret some of the medication-potassium associations. In addition, potassium values exist along a continuum, while we used cutpoints of < 3.5 mEq/L and ≥ 5.5 mEq/L to define hypokalemia and hyperkalemia, respectively. In doing so, we followed common clinical laboratory reference ranges, sought to identify values that would likely prompt clinical action, and followed examples in the literature.2, 9 However, different cutpoints could have been chosen (for example, < 4 mEq/L or ≥ 5.0 mEq/L) which might have resulted in different CART models and/or c-statistics.
No consensus exists about how often to monitor serum potassium. Our findings suggest that routine serum potassium testing may be low yield in individuals with a recent serum potassium between 4.0 and 5.0 mEq/L, eGFR ≥ 45 mL/min/1.73m2, and no hypokalemia in the previous year (< 1% rate of hypokalemia and hyperkalemia). We did not examine the effect of recent changes in clinical condition or medications on acute potassium changes.
References
Morgan DJ, Dhruva SS, Coon ER, Wright SM, Korenstein D. 2018 Update on medical overuse. JAMA Intern Med. 2019;179:240–46.
Chang AR, Sang Y, Leddy J, et al. Antihypertensive medications and the prevalence of hyperkalemia in a large health system. Hypertension. 2016;67:1181–8.
Bowling CB, Pitt B, Ahmed MI, et al. Hypokalemia and outcomes in patients with chronic heart failure and chronic kidney disease: findings from propensity-matched studies. Circ Heart Fail. 2010;3:253–60.
Hayes J, Kalantar-Zadeh K, Lu JL, Turban S, Anderson JE, Kovesdy CP. Association of hypo- and hyperkalemia with disease progression and mortality in males with chronic kidney disease: the role of race. Nephron Clin Pract. 2012;120:c8–16.
Collins AJ, Pitt B, Reaven N, et al. Association of serum potassium with all-cause mortality in patients with and without heart failure, chronic kidney disease, and/or diabetes. Am J Nephrol. 2017;46:213–21.
Nakhoul GN, Huang H, Arrigain S, et al. Serum potassium, end-stage renal disease and mortality in chronic kidney disease. Am J Nephrol. 2015;41:456–63.
Kovesdy CP, Matsushita K, Sang Y, et al. Serum potassium and adverse outcomes across the range of kidney function: a CKD Prognosis Consortium meta-analysis. Eur Heart J. 2018;39:1535–42.
Dunn JD, Benton WW, Orozco-Torrentera E, Adamson RT. The burden of hyperkalemia in patients with cardiovascular and renal disease. Am J Manag Care. 2015;21(15 Suppl):s307–15.
Nilsson E, Gasparini A, Arnlov J, et al. Incidence and determinants of hyperkalemia and hypokalemia in a large healthcare system. Int J Cardiol. 2017;245:277–84.
Liamis G, Liberopoulos E, Barkas F, Elisaf M. Diabetes mellitus and electrolyte disorders. World J Clin Cases. 2014;2:488–96.
Nichols GA, Desai J, Elston LJ, et al. Construction of a multisite DataLink using electronic health records for the identification, surveillance, prevention, and management of diabetes mellitus: the SUPREME-DM Project. Prev Chronic Dis. 2012;9:E110.
Nichols GA, Schroeder EB, Karter AJ, et al. Trends in diabetes incidence among 7 million insured adults, 2006-2011: The SUPREME-DM Project. Am J Epidemiol. 2015;181:32–9.
Ross TR, Ng D, Brown JS, et al. The HMO Research Network Virtual Data Warehouse: a public data model to support collaboration. EGEMS (Wash DC ). 2014;2:1049.
American Diabetes Association. Classification and diagnosis of diabetes. Standards of Medical Care in Diabetes – 2019. Diabetes Care 2019; 42 (Supplement 1); S13-S28.
Schroeder EB, Donahoo WT, Goodrich GK, Raebel MA. Validation of an algorithm for identifying type 1 diabetes in adults based on electronic health record data. Pharmacoepidemiol Drug Saf. 2018;27:1053–9.
Quan H, Sundararajan V, Halfon P, et al. Coding algorithms for defining comorbidities in ICD-9-CM and ICD-10 administrative data. Med Care. 2005;43:1130–9.
Chronic Conditions Data Warehouse. Chronic Conditions Data Warehouse condition categories. Availablet at: https://www.ccwdata.org/web/guest/condition-categories. Accessed 6/1/2017.
Karter AJ, Warton EM, Lipska KJ, et al. Development and validation of a tool to identify patients with type 2 diabetes at high risk of hypoglycemia-related emergency department or hospital use. JAMA Intern Med. 2017;177:1461–70.
Breiman L, Friedman JH, Olsehn RA, Stone CJ. Classification and Regression Trees. Monterey, CA: Wadsworth & Brooks/Cole Advanced Books & Software; 1984.
Moons KG, Altman DG, Reitsma JB, et al. Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD): explanation and elaboration. Ann Intern Med. 2015;162:W1–73.
Collins GS, Reitsma JB, Altman DG, Moons KG. Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD): the TRIPOD statement. Ann Intern Med. 2015;162:55–63.
Altman DG, Vergouwe Y, Royston P, Moons KG. Prognosis and prognostic research: validating a prognostic model. BMJ. 2009;338:b605.
Royston P, Moons KG, Altman DG, Vergouwe Y. Prognosis and prognostic research: Developing a prognostic model. BMJ. 2009;338:b604.
R Core Team. R: A language and environment for statistical computing. Available at: https://www.R-project.org. Accessed 9/19/2018.
Ripley B. tree: Classification and Regression Trees. R package version 1.0–39. Available at: https://CRAN.R-project.org/package=tree. Accessed 9/19/2018.
Kim K, Thomsen RW, Nicolaisen SK, Hasvold LP, Palaka E, Sorensen HT. Healthcare resources utilisation and cost associated with elevated potassium levels: a Danish population-based cohort study. BMJ Open. 2019;9:e026465.
Rodenburg EM, Visser LE, Hoorn EJ, Ruiter R, Lous JJ, Hofman A, Uitterlinden AG, Stricker BH. Thiazide and the risk of hypokalemia in the general population. Journal of Hypertenion. 2014;32:2092–2097.
Funding
This project was supported by grant 1K23DK099237 from the National Institute of Diabetes and Digestive and Kidney Disease (NIDDK) and grants 1R01HS022963 and R01HS019859 from the Agency for Healthcare Research and Quality. J.A.S. and P.J.O. received additional support from NIDDK-funded Health Delivery Systems Center for Diabetes Translational Research grant 1P30DK92924.
Author information
Authors and Affiliations
Contributions
The authors thank Ms. Andrea Paolino for her invaluable help with this manuscript and the SUPREME-DM study.
Corresponding author
Ethics declarations
This study was approved by the KPCO Institutional Review Board (IRB), with the other institutions’ IRBs ceding oversight to the KPCO IRB. Informed consent was not required.
Conflict of Interest
M.C. reports additional grant funding from the Department of Defense, Sanofi, Kadmon, AstraZeneca, and Corvidia. G.A.N. reports additional grant funding from Boehringer Ingelheim, Merck & Co, Bristol-Myers Squibb, and Amarin Pharma.
Disclaimer
The study sponsors had no role in the study design, collection, analysis, and interpretation of data; writing the report; and the decision to submit the report for publication. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health or the Agency for Healthcare Research and Quality.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Prior Presentations
None.
Electronic supplementary material
ESM 1
(DOCX 40.5 kb)
Rights and permissions
About this article

Cite this article
Schroeder, E.B., Adams, J.L., Chonchol, M. et al. Predictors of Hyperkalemia and Hypokalemia in Individuals with Diabetes: a Classification and Regression Tree Analysis. J GEN INTERN MED 35, 2321–2328 (2020). https://doi.org/10.1007/s11606-020-05799-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11606-020-05799-x