
Abstract
We extend and improve recent results given by Singh and Watson on using classical bounds on the union of sets in a chance-constrained optimization problem. Specifically, we revisit the so-called Dawson and Sankoff bound that provided one of the best approximations of a chance constraint in the previous analysis. Next, we show that our work is a generalization of the previous work, and in fact the inequality employed previously is a very relaxed approximation with assumptions that do not generally hold. Computational results demonstrate on average over a 43% improvement in the bounds. As a byproduct, we provide an exact reformulation of the floor function in optimization models.
Similar content being viewed by others
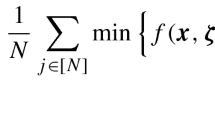

1 Introduction
1.1 Background
In a recent work, Singh and Watson [13] approximate a two-stage joint chance-constrained optimization model using approximations based on the union of sets. First, they rewrite a joint chance constraint (JCC) as a union of sets of “failed” scenarios. Then, using classical Bonferroni-styled approximations of the union, they bound the chance constraint, thereby bounding the optimization model itself. With a maximization objective, a lower (upper) bound for a union (or, the JCC) provides an upper (lower) bound for the optimization model. They consider two upper bounds and four lower bounds for the union; and, find that in a tradeoff between computational effort and the quality of solution, the so-called Bonferroni union bound and the linearized version of the Dawson and Sankoff [4] union bound nearly always provide the best optimization bounds.
Bounding the probability of the union of n events by the use of joint probabilities of \(k<n\) events has been studied since Boole and Bonferroni. For an extensive historical survey of such inequalities, see, e.g. [9]. The sharpness of linear bounds can be determined using linear programming [9]. Relatively recent methods to approximate this probability include cherry trees [3], chordal graphs [5], and aggregation and disaggregation [10]. The hardness of computing these bounds is also studied [12]. For a survey of bounds, including linear and non-closed form expressions, see [2].
We use the same notation as [13] and reiterate it here for conciseness. Let, \(x = (x_t)_{t \in T}\) be the first stage decision; \(w = (w_t)^\omega _{t \in T} \in \varOmega \) be a set of equally likely discrete scenario realizations with \(N=|\varOmega |\), \(\omega =\omega _1, \omega _2, \ldots , \omega _N\); \(y = (y_t)^\omega _{t \in T}\) be the second stage decision; \(A_t=\{ \omega : x_t > y_t^\omega + w_t^\omega \}\) be the set of scenarios we fail to satisfy at stage t; and, \(\varepsilon \) be a small positive number strictly less than 1. Let \(u_t^\omega =1\) and \(v_{tt'}^\omega =1, t'>t\) denote we fail in scenario \(\omega \) at time t, and in scenario \(\omega \) at both times t and \(t'\), respectively; i.e., \(v_{tt'}^\omega =1\) if and only if \(u_t^\omega =u_{t'}^\omega =1\). Finally, let \(S_1 = \sum _{t\in T}{{{\mathbb {P}}}(A_t }) = \sum _{t\in T}{\frac{1}{N} \sum _{\omega \in \varOmega } u_t^\omega }\) and \(S_2 = \sum _{t,t'\in T, t'> t}{{{\mathbb {P}}}(A_t \cap A_{t'})} = \sum _{t,t'\in T, t'>t}\frac{1}{N} {\sum _{\omega \in \varOmega } v_{tt'}^\omega }\).
Further, we use the following two mathematical conventions. First, \(\lfloor \cdot \rfloor \) rounds its argument down to the nearest integer; i.e., for any \(x \in {\mathcal {R}},\lfloor x \rfloor = \max _{n \in {\mathcal {Z}}} \{n \le x \}\). Second, \( \mathbf{frac} \{x \}\) denotes the fractional part of its argument; i.e., for any \(x \in {\mathcal {R}}, \mathbf{frac} \{x \} = x - \lfloor x \rfloor \).
The following is the generic chance-constrained optimization model of [13]:
The JCC in equation (1b) can be rewritten exactly as: \({{\mathbb {P}}}(\bigcup _{t \in T} A_t) \le \varepsilon \). The contribution of Singh and Watson is to utilize classical (upper and lower) approximations of this union within optimization model (1).
1.2 Our contributions
In this work, we investigate these classical bounds further. We seek to tighten the approximating optimization model by using tightened approximations of the probability of the union. We also present suitable reformulations of some bounds that were not investigated in the previous work due to their non-linear structure. In this sense, our work improves on the work initiated by Singh and Watson [13]. The following are the key contributions of this article:
-
1.
We observe that the Dawson and Sankoff bound, whose linearized version is claimed by Singh and Watson [13] as the tightest, is in fact a very relaxed bound with stringent necessary assumptions that are nearly always not satisfied.
-
2.
We utilize a tighter bound than the lower bound of Sathe et al. [11] used in Singh and Watson [13].
-
3.
We reformulate a resulting mixed-integer non-linear optimization exactly as a mixed-integer optimization model, including an exact reformulation of the floor function.
-
4.
We demonstrate a significant improvement in our computational experiments, with the new inequality dramatically improving the bounds by over 40%.
2 Tightening of union bounds
2.1 Bound by Sathe et al. [11]
The following two bounds on the union of sets, available from Result 1 and Result 3 by Sathe et al. [11] respectively, are used in [13].
Sathe et al. also provide a tightening of the bounds in equation (2); Result 2 and Result 4 of [11] say that the bounds in (2a) and (2b) can be tightened if \(2 S_2 < (|T|-1) S_1\) and \(S_2 < 0\) respectively hold. Clearly the latter condition cannot hold. Indeed, the upper bound in (2b) is the tightest bound by a linear combination of \(S_1\) and \(S_2\); this is proved in [10]. Result 2 of [11] provides the following tightened approximation of equation (2a):
where \(z= 2+ \lfloor \frac{2S_2}{S_1}\rfloor \). By the use of linear programming, Prékopa et al. [10] prove that the bounds in equation (3) and equation (2b) are the tightest lower and upper bounds using a linear combination of \(S_1\) and \(S_2\). Further, both Prékopa [10] and Dawson and Sankoff [4] prove the bound in (3) without requiring the condition mentioned by Sathe et al [11]; this condition is sufficient to guarantee an improvement but not necessary.
A subtle and important distinction stems from what the previously cited authors call as “linear” combinations of \(S_1\) and \(S_2\). Such linear bounds follow a structure of \(aS_1 + b S_2\) where a and b are coefficients that can be determined. In previous works [4, 10, 11], it is assumed that \(S_1\) and \(S_2\) can be calculated apriori; thus, z or \(\frac{2S_2}{S_1}\) is a known quantity. Then, equation (3) contains an exponent of one for both \(S_1\) and \(S_2\); hence, the bound is referred to as a linear bound. In this sense, the bounds can be said to be the tightest linear bounds given that z is known; for nonlinear bounds, see, e.g. [8]. We revisit this distinction in Sect. 2.3.
2.2 Bound by Dawson and Sankoff [4]
Theorem 1.1 of Dawson and Sankoff [4] provides the following lower bound, using the notation presented above.
where \(\theta = \mathbf{frac}\{\frac{2S_2}{S_1}\}\). Substituting \(\theta \) in terms of z, and using straightforward algebra, the right hand sides of equation (3) and equation (4) are exactly equivalent. The minimum of the right hand side of equation (4) occurs at \(\theta =0\); then, the following bound results:
This bound is available from Corollary 1 of [4]. In the computational results of [13], a piecewise linearization of the bound in equation (5) nearly always achieves the best upper bounds for the optimization model; this is given by equation (6) of [13] and is called as the linearized Dawson and Sankoff bound. However, equation (5) is a special case (i.e., a relaxation) of the general bound in equation (4). Thus, an approximation of model (1) with equation (5) instead of equation (4) always results in a worse (i.e., larger) bound. As we are interested in smaller upper bounds, this reasoning suggests we can do better with equation (4). Further, for this special case to hold we require the strong apriori assumption: \(\theta = 0\); in other words, \(\frac{2S_2}{S_1} \in {\mathcal {Z}}\). This clearly does not hold true in general.
An analogy for this observation is that of solving a mixed-integer program (MIP) using its linear programming relaxation (LP). The objective function value of the LP always provides a bound for that of the MIP, but for the LP solution to be valid to the MIP the restrictive assumption of all its optimal variables being integer is required.
2.3 Summary of observations
In the proceeding sections of this manuscript, we are interested in investigating the tighter version of the bound in equation (2a)— specifically that given by equation (3) or equation (4)—as an approximation of the JCC in model (1). We note that in an optimization model such as model (1), \(S_1\) and \(S_2\) are decision variables which are obviously unknown before solving the model. Hence, z is a decision variable as well, and equation (3) presents a challenging mixed-integer non-linear constraint. In Sect. 3.1 we provide results that assist us in modeling the quantity \(\lfloor \frac{2S_2}{S_1} \rfloor \), while in Sect. 3.2 we linearize the constraint (3).
We conclude this section with a summary of the above-mentioned observations, all of which follow directly from the three cited works [4, 10, 11].
Remark 1
Constraints (3) and (4) are always exactly equivalent.
Remark 2
Constraint (5) offers a special case of constraint (4) as a relaxation. Thus, upper bounds using the former are expected to be larger (worse) than the upper bounds using the latter. The upper bound using constraint (5) is derived by a stringent assumption on \(S_1\) and \(S_2\).
Remark 3
Constraint (2a) is weaker than constraint (3) or constraint (4). Thus, upper bounds using the former are expected to be larger (worse) than the upper bounds using the latter. However, unlike constraint (5), constraint (2a) does not require any assumptions on \(S_1\) and \(S_2\).
3 Mathematical reformulations
3.1 Reformulating \(\lfloor \frac{2S_2}{S_1}\rfloor \)
Lemma 1
For any feasible solution to model (1), the condition \( S_1 \ge \frac{2}{{|T| -1}} S_2\) holds true.
Proof
See equation (6.2.13) of [9]. \(\square \)
Lemma 2
Let \(a,b, A,B \in \mathbb {Z^+}\), where \(a \le A, b \le B\). Then, \({{\varvec{frac}}}\{\frac{a}{b}\} \) is no more than \(1 -\frac{1}{B}\).
Proof
Clearly, \( \mathbf{frac}\{\frac{a}{b}\} \in \{ 0, \frac{1}{b}, \frac{2}{b}, \ldots , ... \frac{b-1}{b} \}\). The maximum of these is \(\frac{b-1}{b}\), which is at most \(1 -\frac{1}{B}\). \(\square \)
Remark 4
In any optimal solution to model (1) with positive coefficients R and B we always have \(S_1>0\). To see this, first we note that if \(S_1=0\) then all of \(u,v,S_2\) are zero, and also \({{\mathbb {P}}}(\bigcup _{t \in T} A_t) =0\); see, e.g., [9]. Thus, the objective function value always improves when at least one of the u variables is one, or \(S_1>0\). Hence, the ratio \(\frac{S_2}{S_1}\) is well-defined.
This background brings us to our main result of this section.
Theorem 1
For model (1), we have
Proof
From Lemma 1, equation (6a) directly holds. Next, from the definitions of \(S_1, S_2\) we observe that Lemma 2 is applicable. Let \( a \leftarrow 2 N S_2, b \leftarrow N S_1, A \leftarrow N |T|(|T|-1), B \leftarrow N |T| \). Then, equation (6b) holds. \(\square \)
In general, to model a floor function exactly we require a strict inequality because the feasible region is an open set; see, e.g., [6]. However, as optimization solvers can only model non-strict inequalities, strict inequalities are approximated with a finite tolerance; see, e.g., [7]. Having an upper bound on the fractional part of a decision variable, such as that provided by Theorem 1, allows an exact reformulation. That being said, if the quantity N|T| is very large the above result can have little practical relevance as this could potentially cause the model to be (i) poorly scaled, or (ii) the quantity \(\frac{1}{N|T|}\) could be lower than the feasibility tolerance of the optimization solver. The following corollary to Theorem 1 summarizes this discussion.
Corollary 1
\(\lfloor \frac{2S_2}{S_1}\rfloor \le \frac{2S_2}{S_1} \le \lfloor \frac{2S_2}{S_1}\rfloor + \alpha \) holds true for all \(\alpha \in (1- \frac{1}{N|T|},1)\).
3.2 Linearizing equation (3): inequality by Dawson and Sankoff [4]
In this section, we linearize the constraint \((z^2 -z ) \varepsilon \ge 2 S_1 z - 2S_1 -2S_2\) of equation (3). Unlike the piecewise linear approximation used in [13], or a finite tolerance approximation of the floor function, here we provide an exact linearization. Consider the following equations:
Proposition 1
Equation (7) is an exact reformulation of equation (3) for all \(\alpha \in (1- \frac{1}{N|T|},1)\).
Proof
From Theorem 1, \(z \in \{ 2,3,\ldots , |T|+1 \}\). We introduce |T| binary variables, \(\kappa _t\), to indicate z takes the value \(t+1\) for \(t=1,2,\ldots , |T|\).
We observe from equation (7d) and (7g) that exactly one of the \(\kappa \) variables is one; i.e., \(\kappa \) is a so-called SOS1 variable, see, e.g. [1]. Then, z and \(z^2-z\) can be represented by the quantities \(\sum _{t=1}^{|T|} (t+1) \kappa _t\) and \(\sum _{t=1}^{|T|} (t^2+t) \kappa _t\), respectively. Next, we note that \(S_1 \le |T|\). From constraints (7b)-(7d) and (7g)-(7h) we observe that if \(\kappa _{t^*}=1\) then \(\delta _{t^*} = S_1\) and \(\delta _t = 0, t \ne t^*\). Thus, the quantity \(\sum _{t=1}^{|T|} (t+1) \delta _t\) correctly models \(S_1 z\). From Corollary 1, we have \(z \le 2 + \frac{2S_2}{S_1} \le z + \alpha , \forall \alpha \in (1- \frac{1}{N|T|},1)\). This is ensured by constraints (7e)-(7f). Then constraint (7a) correctly captures \((z^2 -z ) \varepsilon \ge 2 S_1 z - 2(S_1 +S_2)\). \(\square \)
In the Electronic Supplementary Material, we present the complete reformulation of model (1) approximated by equation (3).
4 Computational experiments
In this section, we compare the reduction of the upper bounds for model (1), with the new inequalities proposed in Sect. 3 as opposed to inequalities (2a) and (5) used by Singh and Watson [13]. To validate the new inequality, we use the same system as [13], with two exceptions. First, we re-run all computations on a newer version of GAMS—30.1 as opposed to the originally used 24.8.5 since the newer version contains Gurobi 9.0.0 with significantly improved features [7]. Second, to strictly compare the improvement of the new inequality with the original ones, we do not use the so-called mixing set of Remark 2 of Singh and Watson [13], and neither do we use a piecewise linearization. Thus, we re-compute the optimal objective function values for both of these inequalities, as well as the true optimal objective function (i.e., using an exact representation of the JCC). We do this for all the eight tables reported in Singh and Watson [13], with a maximum time limit of 2100 seconds for each instance. Further details on the data, representation and modeling are available in [13].
In Tables 1a and 1b, we summarize our two sets of computational results using the ARMA and Gaussian sampling methods of [13]. The bottom halves of both the tables have samples containing half the mean and variances as the top halves; see, [13] for details. Here, the constraints “Original 1” and “Original 2” refer to inequalities (2a) and (5) used by Singh and Watson, while constraint “New” refers to inequality (3) with the exact reformulation of Sect. 3.2. The “MIP gap” column denotes the percentage optimality gap reported by GAMS/Gurobi while solving the optimization model with the respective constraint. The “Gap” column denotes the optimality gap between the true objective function value and the objective function value of the approximating model. In the same spirit as Singh and Watson, we use a conservative estimate of the GapFootnote 1; thus, our results are worst-case estimates. The “Improvement” column denotes the percentage reduction in the (conservative) upper bounds of the New inequality from the Original inequalities. We recall two facts presented above: (i) inequalities (3) and (4) are exactly the same, and (ii) the linearization in Sect. 3.2 is exact. Thus, the empirical quantification of the improvement in bounds results strictly from two sources: (i) a tightened approximation of the JCC, and (ii) a better reformulation of the mathematical model of the approximating constraint.
In the 32 instances of Table 1, the New inequality results in an average MIP gap of only 2.9% as opposed to 20.6% of the Original 1 inequality. This significantly lower MIP gap suggests the new formulation is much more efficient to solve for a MIP solver than the original formulation. The Gap from the optimal in the New inequality is on average 4.4% — a dramatic reduction from the 44.7% average Gap in the Original 1 inequality. Since our Gap estimate is the worst-case estimate, in reality these gaps could be even smaller. The upper bounds of the approximating model with the New inequality improve on average by 43.2% from the Original 1 inequality.
In contrast, the Original 2 inequality could always be solved in under 30 seconds to a MIP gap of 0%. This shows the effectiveness of Gurobi 9.0.0 for quadratic optimization models. However, the bounds obtained from it are even farther off than the Original 1 inequality; the average Gap from the optimal in the Original 2 inequality is 68.2%. The upper bounds of the approximating model with the New inequality improve on average by 66.8% from the Original 2 inequality.
We end this section with a discussion on the size of the approximating problems. Representing \(S_1\) and \(S_2\) requires N|T| and \(N \frac{|T||T-1|}{2}\) variables, respectively. The constraint matrix given by equation (7) requires \({\mathcal {O}}(|T|)\) number of constraints and variables. Further, we note that the optimization models corresponding to the New, Original 1 and Original 2 inequalities change only in the representation of the JCC. Thus, if \(N \gg |T|\), as in [13], the ballpark size of problem remains the same for all three inequalities. For \(N=250\), our optimization models have an order of 81K continuous variables, 6K binary variables, and 213K constraints; these values approximately double when N doubles to 500.
5 Conclusions
In this work, we extended and improved upon the previous work of Singh and Watson by utilizing an improved version of the Dawson and Sankoff union bound. We showed how the previously used version of this bound is a restrictive special case whose apriori assumptions might not hold true. We provided linear reformulations of non-linear combinations of \(S_1\) and \(S_2\), as well as an exact reformulation of the floor function.
Our computational results show significant promise; thus, there seems scope in this direction of work. Future work could examine developing a better upper bound on \(\lfloor \frac{2 S_2}{S_1}\rfloor \), as well as on \(\mathbf{frac}\{\frac{2 S_2}{S_1}\}\). The former would reduce the number of binary variables in the resulting mathematical model. Future research could also examine quantifying the analytical gap between the approximations.
Notes
The Gap is defined as follows: \(\frac{\text {Bound}-z^*_{LB}}{\text {Bound}}\), where “Bound” is the maximum possible value of the objective function value of the relevant approximation and \(z^*_{LB}\) is the lower bound on the true optimal value reported by Gurobi. For the numbers above the dashed lines in the two tables the true model is solved to optimality; but for the numbers below the dashed lines in the two tables the true model could not be solved to optimality. See [13] for details.
References
Beale, E., Tomlin, J.: Special facilities in a general mathematical programming system for non-convex problems using ordered sets of variables. In: J. Lawrence (ed.) Proceedings of the 5th International Conference on Operations Research, Tavistock, London (1969)
Bertsimas, D., Popescu, I.: Optimal inequalities in probability theory: a convex optimization approach. SIAM J. Optim. 15(3), 780–804 (2005)
Bukszár, J., Prékopa, A.: Probability bounds with cherry trees. Math. Op. Res. 26(1), 174–192 (2001)
Dawson, D., Sankoff, D.: An inequality for probabilities. Proc. Am. Math. Soc. 18(3), 504–507 (1967)
Dohmen, K.: Bonferroni-type inequalities via chordal graphs. Comb. Probab. Comput. 11(4), 349–351 (2002)
Graham, R., Knuth, D., Patashnik, O., Liu, S.: Concrete mathematics: A foundation for computer science. Comput. Phys. 3(5), 106–107 (1989)
Gurobi Optimization LLC: Documentation. Available at https://www.gurobi.com/documentation/9.0 (2019). [Online; accessed February 2, 2020]
Kwerel, S.M.: Most stringent bounds on aggregated probabilities of partially specified dependent probability systems. J. Am. Stat. Assoc. 70(350), 472–479 (1975)
Prékopa, A.: Stochastic programming, vol. 324. Kluwer Academic Publishers, New York (1995)
Prékopa, A., Gao, L.: Bounding the probability of the union of events by aggregation and disaggregation in linear programs. Discrete Appl. Math. 145(3), 444–454 (2005)
Sathe, Y., Pradhan, M., Shah, S.: Inequalities for the probability of the occurrence of at least \(m\) out of \(n\) events. J. Appl. Prob. 17(4), 1127–1132 (1980)
Scozzari, A., Tardella, F.: Complexity of some graph-based bounds on the probability of a union of events. Discrete Appl. Math. 244, 186–197 (2018)
Singh, B., Watson, J.: Approximating two-stage chance-constrained programs with classical probability bounds. Optim. Lett. 13, 1403–1416 (2019). https://doi.org/10.1007/s11590-019-01387-z
Acknowledgements
Open Access funding provided by Projekt DEAL. I sincerely thank the anonymous referee for pointing out an error in an earlier version of a theorem in this article.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Singh, B. Tighter reformulations using classical Dawson and Sankoff bounds for approximating two-stage chance-constrained programs. Optim Lett 15, 327–336 (2021). https://doi.org/10.1007/s11590-020-01592-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11590-020-01592-1