
Abstract
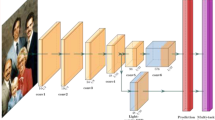
In this work, we describe a single-shot scale-aware convolutional neural network based face detector (SFDet). In comparison with the state-of-the-art anchor-based face detection methods, the main advantages of our method are summarized in four aspects. (1) We propose a scale-aware detection network using a wide scale range of layers associated with appropriate scales of anchors to handle faces with various scales, and describe a new equal density principle to ensure anchors with different scales to be evenly distributed on the image. (2) To improve the recall rates of faces with certain scales (e.g., the scales of the faces are quite different from the scales of designed anchors), we design a new anchor matching strategy with scale compensation. (3) We introduce an IoU-aware weighting scheme for each training sample in classification loss calculation to encode samples accurately in training process. (4) Considering the class imbalance issue, a max-out background strategy is used to reduce false positives. Several experiments are conducted on public challenging face detection datasets, i.e., WIDER FACE, AFW, PASCAL Face, FDDB, and MAFA, to demonstrate that the proposed method achieves the state-of-the-art results and runs at 82.1 FPS for the VGA-resolution images.
























Similar content being viewed by others


Notes
We denote the very tiny faces or some faces with the certain scales located around the middle of two scales of designed anchors as the outlier faces.
The Jaccard overlap (Erhan et al. 2014) is also known as intersection-over-union, which is used to measure the overlap rate between two regions here.
Since the ratio between positive and negative anchors is set to 1:3, we use \(\lambda =4\) to balance the classification and regression losses in training.
Empirically, we set \(C=3\) in our experiments.
The negative anchor indicates that the anchor is not matched to any ground truth bounding box.
For example, in our FPN architecture, there are mainly five steps, i.e., (1) input low-level features L (\(15\times 15\)), (2) use operation with stride 2 to get high-level features H (\(8\times 8\)), (3) upsample H to H-up (\(16\times 16\)), (4) crop H-up to H-up-crop (\(15\times 15\)), and (5) add L and H-up-Crop.
References
Barbu, A., Lay, N., & Gramajo, G. (2014). Face detection with a 3d model. CoRR arXiv:abs/1404.35968.
Bell, S., Zitnick, C. L., Bala, K., & Girshick, R. B. (2016). Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 2874–2883).
Brubaker, S. C., Wu, J., Sun, J., Mullin, M. D., & Rehg, J. M. (2008). On the design of cascades of boosted ensembles for face detection. International Journal of Computer Vision, 77(1–3), 65–86.
Cai, Z., Fan, Q., Feris, R. S., & Vasconcelos, N. (2016). A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of European conference on computer vision (pp. 354–370).
Chen, D., Hua, G., Wen, F., & Sun, J. (2016). Supervised transformer network for efficient face detection. In Proceedings of European conference on computer vision (pp. 122–138).
Chen, L., Papandreou, G., Kokkinos, I., Murphy, K., & Yuille, A. L. (2015). Semantic image segmentation with deep convolutional nets and fully connected crfs. In International conference on learning representations .
Chen, Y., Song, L., & He, R. (2017). Masquer hunter: Adversarial occlusion-aware face detection. CoRR arXiv:abs/1709.05188.
Dai, J., Li, Y., He, K., & Sun, J. (2016). R-FCN: Object detection via region-based fully convolutional networks. In D. D. Lee, M. Sugiyama, V. von Luxburg, I. Guyon, & R. Garnett (Eds.), Advances in neural information processing systems, Barcelona, Spain (pp. 379–387).
Dalal, N., & Triggs, B. (2005). Histograms of oriented gradients for human detection. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 886–893).
Erhan, D., Szegedy, C., Toshev, A., & Anguelov, D. (2014). Scalable object detection using deep neural networks. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 2155–2162).
Farfade, S. S., Saberian, M. J., & Li, L. (2015). Multi-view face detection using deep convolutional neural networks. In ACM on international conference on multimedia retrieval (pp. 643–650).
Felzenszwalb, P. F., Girshick, R. B., McAllester, D. A., & Ramanan, D. (2010). Object detection with discriminatively trained part-based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9), 1627–1645.
Freund, Y., & Schapire, R. E. (1997). A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences, 55(1), 119–139.
Fu, C., Liu, W., Ranga, A., Tyagi, A., & Berg, A. C. (2017). DSSD : Deconvolutional single shot detector. CoRR arXiv:abs/1701.06659.
Ge, S., Li, J., Ye, Q., & Luo, Z. (2017). Detecting masked faces in the wild with lle-cnns. CVPR (pp. 426–434).
Ghiasi, G., & Fowlkes, C. C. (2015). Occlusion coherence: Detecting and localizing occluded faces. CoRR arXiv:abs/1506.08347.
Gidaris, S., & Komodakis, N. (2015). Object detection via a multi-region and semantic segmentation-aware CNN model. In Proceedings of IEEE international conference on computer vision (pp. 1134–1142).
Girshick, R. B. (2015). Fast R-CNN. In Proceedings of IEEE international conference on computer vision (pp. 1440–1448).
Girshick, R. B., Donahue, J., Darrell, T., Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 580–587).
Glorot, X., & Bengio, Y. (2010). Understanding the difficulty of training deep feedforward neural networks. In International conference on artificial intelligence and statistics (pp. 249–256).
He, K., Zhang, X., Ren, S., & Sun, J. (2014). Spatial pyramid pooling in deep convolutional networks for visual recognition. In Proceedings of European conference on computer vision (pp. 346–361).
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 770–778).
Hoiem, D., Chodpathumwan, Y., & Dai, Q. (2012). Diagnosing error in object detectors. In ECCV (pp. 340–353).
Howard, A. G. (2013). Some improvements on deep convolutional neural network based image classification. CoRR arXiv:abs/1312.5402.
Hu, P., & Ramanan, D. (2017). Finding tiny faces. In CVPR (pp. 1522–1530).
Huang, J., Rathod, V., Sun, C., Zhu, M., Korattikara, A., Fathi, A., et al. (2016). Speed/accuracy trade-offs for modern convolutional object detectors. CoRR arXiv:abs/1611.10012.
Jain, V., & Learned-Miller, E. (2010). Fddb: A benchmark for face detection in unconstrained settings. Technical Report UM-CS-2010-009, University of Massachusetts, Amherst.
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R. B., et al. (2014). Caffe: Convolutional architecture for fast feature embedding. In ACM international conference on multimedia (pp. 675–678).
Jiang, H., & Learned-Miller, E. (2016). Face detection with the faster r-cnn. CoRR arXiv:abs/1606.03473.
Jiang, H., & Learned-Miller, E. G. (2017). Face detection with the faster R-CNN. In Proceedings of IEEE international conference on automatic face and gesture recognition (pp. 650–657).
Kalal, Z., Matas, J., & Mikolajczyk, K. (2008). Weighted sampling for large-scale boosting. In Proceedings of British machine vision conference (pp. 1–10).
Kong, T., Sun, F., Yao, A., Liu, H., Lu, M., & Chen, Y. (2017). RON: Reverse connection with objectness prior networks for object detection. In Proceedings of IEEE conference on computer vision and pattern recognition.
Kong, T., Yao, A., Chen, Y., & Sun, F. (2016). Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of IEEE conference on computer vision and pattern recognition.
Kumar, V., Namboodiri, A. M., & Jawahar, C. V. (2015). Visual phrases for exemplar face detection. In Proceedings of IEEE international conference on computer vision (pp. 1994–2002).
Lee, H., Eum, S., & Kwon, H. (2017). ME R-CNN: Multi-expert region-based CNN for object detection. In Proceedings of IEEE international conference on computer vision.
Li, H., Lin, Z., Brandt, J., Shen, X., & Hua, G. (2014). Efficient boosted exemplar-based face detection. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 1843–1850).
Li, H., Lin, Z., Shen, X., Brandt, J., & Hua, G. (2015). A convolutional neural network cascade for face detection. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 5325–5334).
Li, J., & Zhang, Y. (2013). Learning SURF cascade for fast and accurate object detection. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 3468–3475).
Li, Y., Sun, B., Wu, T., & Wang, Y. (2016). Face detection with end-to-end integration of a convnet and a 3d model. In Proceedings of European conference on computer vision (pp. 420–436).
Liao, S., Jain, A. K., & Li, S. Z. (2016). A fast and accurate unconstrained face detector. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(2), 211–223.
Lin, T., Dollár, P., Girshick, R. B., He, K., Hariharan, B., & Belongie, S. J. (2017a). Feature pyramid networks for object detection. In Proceedings of IEEE conference on computer vision and pattern recognition.
Lin, T., Goyal, P., Girshick, R. B., He, K., & Dollár, P. (2017b). Focal loss for dense object detection. In Proceedings of IEEE international conference on computer vision.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S.E., Fu, C., et al. (2016). SSD: Single shot multibox detector. In Proceedings of European conference on computer vision (pp. 21–37).
Liu, W., Rabinovich, A., & Berg, A. C. (2015). Parsenet: Looking wider to see better. CoRR arXiv:abs/1506.04579.
Liu, Y., Li, H., Yan, J., Wei, F., Wang, X., & Tang, X. (2017). Recurrent scale approximation for object detection in CNN. In ICCV.
Lowe, D. G. (2004). Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 60(2), 91–110.
Luo, W., Li, Y., Urtasun, R., & Zemel, R. S. (2016). Understanding the effective receptive field in deep convolutional neural networks. In Advances in neural information processing systems (pp. 4898–4906).
Mathias, M., Benenson, R., Pedersoli, M., & Gool, L. J. V. (2014). Face detection without bells and whistles. In Proceedings of European conference on computer vision.
Najibi, M., Samangouei, P., Chellappa, R., & Davis, L. S. (2017). SSH: Single stage headless face detector. In ICCV.
Ohn-Bar, E., & Trivedi, M. M. (2016). To boost or not to boost? On the limits of boosted trees for object detection. In International conference on pattern recognition.
Pham, M., & Cham, T. (2007). Fast training and selection of haar features using statistics in boosting-based face detection. In Proceedings of IEEE international conference on computer vision (pp. 1–7).
Qin, H., Yan, J., Li, X., & Hu, X. (2016). Joint training of cascaded CNN for face detection. In Proceedings of IEEE conference on computer vision and pattern recognition.
Ranjan, R., Patel, V. M., & Chellappa, R. (2015). A deep pyramid deformable part model for face detection. In: IEEE International conference on biometrics theory, applications and systems (pp. 1–8).
Ranjan, R., Patel, V. M., & Chellappa, R. (2016). Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition. CoRR arXiv:abs/1603.01249.
Redmon, J., Divvala, S. K., Girshick, R. B., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 779–788).
Redmon, J., & Farhadi, A. (2016). YOLO9000: Better, faster, stronger. CoRR arXiv:abs/1612.08242.
Ren, S., He, K., Girshick, R. B., & Sun, J. (2017). Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6), 1137–1149.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al. (2015). Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115(3), 211–252.
Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R., & LeCun, Y. (2014). Overfeat: Integrated recognition, localization and detection using convolutional networks. In International conference on learning representations.
Shen, X., Lin, Z., Brandt, J., & Wu, Y. (2013). Detecting and aligning faces by image retrieval. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 3460–3467).
Shen, Z., Liu, Z., Li, J., Jiang, Y., Chen, Y., & Xue, X. (2017). DSOD: Learning deeply supervised object detectors from scratch. In Proceedings of IEEE international conference on computer vision.
Shrivastava, A., & Gupta, A. (2016). Contextual priming and feedback for faster R-CNN. In Proceedings of European conference on computer vision (pp. 330–348).
Shrivastava, A., Gupta, A., & Girshick, R. B. (2016a). Training region-based object detectors with online hard example mining. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 761–769).
Shrivastava, A., Sukthankar, R., Malik, J., & Gupta, A. (2016b). Beyond skip connections: Top-down modulation for object detection. CoRR arXiv:abs/1612.06851.
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. CoRR arXiv:abs/1409.1556.
Sun, X., Wu, P., & Hoi, S. C. H. (2017). Face detection using deep learning: An improved faster RCNN approach. CoRR arXiv:abs/1701.08289.
Triantafyllidou, D., & Tefas, A. (2016). A fast deep convolutional neural network for face detection in big visual data. In INNS conference on big data (pp. 61–70).
Uijlings, J. R. R., van de Sande, K. E. A., Gevers, T., & Smeulders, A. W. M. (2013). Selective search for object recognition. International Journal of Computer Vision, 104(2), 154–171.
Viola, P. A., & Jones, M. J. (2004). Robust real-time face detection. International Journal of Computer Vision, 57(2), 137–154.
Wan, S., Chen, Z., Zhang, T., Zhang, B., & Wong, K. (2016). Bootstrapping face detection with hard negative examples. CoRR arXiv:abs/1608.02236.
Wang, H., Li, Z., Ji, X., & Wang, Y. (2017a). Face R-CNN. CoRR arXiv:abs/1706.01061.
Wang, J., Yuan, Y., & Yu, G. (2017b). Face attention network: An effective face detector for the occluded faces. CoRR arXiv:abs/1711.07246.
Wang, X., Shrivastava, A., & Gupta, A. (2017c). A-fast-rcnn: Hard positive generation via adversary for object detection. In Proceedings of IEEE conference on computer vision and pattern recognition.
Wang, X., Zhang, S., Lei, Z., Liu, S., Guo, X., & Li, S. Z. (2018). Ensemble soft-margin softmax loss for image classification. In IJCAI (pp. 992–998).
Wang, Y., Ji, X., Zhou, Z., Wang, H., & Li, Z. (2017d). Detecting faces using region-based fully convolutional networks. CoRR arXiv:abs/1709.05256.
Yan, J., Lei, Z., Wen, L. & Li, S. Z. (2014a). The fastest deformable part model for object detection. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 2497–2504).
Yan, J., Zhang, X., Lei, Z., & Li, S. Z. (2014b). Face detection by structural models. Image Vision Computing, 32(10), 790–799.
Yang, B., Yan, J., Lei, Z., & Li, S. Z. (2014). Aggregate channel features for multi-view face detection. In International joint conference on biometrics (pp. 1–8).
Yang, B., Yan, J., Lei, Z., & Li, S. Z. (2015a). Convolutional channel features. In Proceedings of IEEE international conference on computer vision (pp. 82–90).
Yang, S., Luo, P., Loy, C. C., & Tang, X. (2015b). From facial parts responses to face detection: A deep learning approach. In Proceedings of IEEE international conference on computer vision (pp. 3676–3684).
Yang, S., Luo, P., Loy, C. C., & Tang, X. (2016). WIDER FACE: A face detection benchmark. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 5525–5533).
Yang, S., Xiong, Y., Loy, C. C., & Tang, X. (2017). Face detection through scale-friendly deep convolutional networks. CoRR arXiv:abs/1706.02863.
Yu, J., Jiang, Y., Wang, Z., Cao, Z., & Huang, T. S. (2016). Unitbox: An advanced object detection network. In ACM conference on multimedia conference (pp. 516–520).
Zeng, X., Ouyang, W., Yang, B., Yan, J., & Wang, X. (2016). Gated bi-directional CNN for object detection. In Proceedings of European conference on computer vision (pp. 354–369).
Zhang, K., Zhang, Z., Li, Z., & Qiao, Y. (2016). Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Letters, 23(10), 1499–1503.
Zhang, K., Zhang, Z., Wang, H., Li, Z., Qiao, Y., & Liu, W. (2017a). Detecting faces using inside cascaded contextual cnn. In ICCV.
Zhang, S., Wen, L., Bian, X., Lei, Z., & Li, S. Z. (2017b). Single-shot refinement neural network for object detection. CoRR arXiv:abs/1711.06897.
Zhang, S., Zhu, X., Lei, Z., Shi, H., Wang, X., & Li, S. Z. (2017c). Faceboxes: A CPU real-time face detector with high accuracy. In International joint conference on biometrics.
Zhang, S., Zhu, X., Lei, Z., Shi, H., Wang, X., & Li, S. Z.(2017d). S\({}^{{3}}\)FD: Single shot scale-invariant face detector. In Proceedings of IEEE international conference on computer vision.
Zhu, C., Zheng, Y., Luu, K., & Savvides, M. (2016). CMS-RCNN: Contextual multi-scale region-based CNN for unconstrained face detection. CoRR arXiv:abs/1606.05413.
Zhu, X., & Ramanan, D. (2012). Face detection, pose estimation, and landmark localization in the wild. In Proceedings of IEEE conference on computer vision and pattern recognition (pp. 2879–2886).
Zhu, Y., Zhao, C., Wang, J., Zhao, X., Wu, Y., & Lu, H. (2017). Couplenet: Coupling global structure with local parts for object detection. In Proceedings of IEEE international conference on computer vision.
Zitnick, C. L., & Dollár, P. (2014). Edge boxes: Locating object proposals from edges. In Proceedings of European conference on computer vision (pp. 391–405).
Acknowledgements
This work was supported by the Chinese National Natural Science Foundation Projects #61876178, #61473291, #61806196, the National Key Research and Development Plan (Grant No. 2016YFC0801002), JD Grapevine Plan and AuthenMetric R&D Funds.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Xiaoou Tang.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was done when Hailin Shi worked in CBSR, CASIA.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary material 1 (mp4 24401 KB)
Rights and permissions
About this article

Cite this article
Zhang, S., Wen, L., Shi, H. et al. Single-Shot Scale-Aware Network for Real-Time Face Detection. Int J Comput Vis 127, 537–559 (2019). https://doi.org/10.1007/s11263-019-01159-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-019-01159-3