
Abstract
The estimation of probability densities based on available data is a central task in many statistical applications. Especially in the case of large ensembles with many samples or high-dimensional sample spaces, computationally efficient methods are needed. We propose a new method that is based on a decomposition of the unknown distribution in terms of so-called distribution elements (DEs). These elements enable an adaptive and hierarchical discretization of the sample space with small or large elements in regions with smoothly or highly variable densities, respectively. The novel refinement strategy that we propose is based on statistical goodness-of-fit and pairwise (as an approximation to mutual) independence tests that evaluate the local approximation of the distribution in terms of DEs. The capabilities of our new method are inspected based on several examples of different dimensionality and successfully compared with other state-of-the-art density estimators.
























Similar content being viewed by others


Notes
Fixing the domain bounds based on the data range leads to bounds that are almost certainly too narrow. Accordingly, the resulting density estimates will display a bias toward too high values.
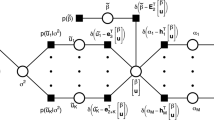
In the singular case of linearly dependent components \(x_1\) and \(x_2\), many small DEs, resolving the probability peak along the diagonal of the \(x_1\)-\(x_2\)-space, result from a DET estimator.
References
Achilleos, A., Delaigle, A.: Local bandwidth selectors for deconvolution kernel density estimation. Stat. Comput. 22(2), 563–577 (2012)
Bagnato, L., Punzo, A., Nicolis, O.: The autodependogram: a graphical device to investigate serial dependences. J. Time Ser. Anal. 33(2), 233–254 (2012)
Botev, Z.: Spectral implementation of adaptive kernel density estimator via diffusion. https://ch.mathworks.com/matlabcentral/fileexchange/14034-kernel-density-estimator (2007). Accessed 01 Sep 2016
Botev, Z.: Implementation of adaptive kernel density estimator for high dimensions via diffusion. https://ch.mathworks.com/matlabcentral/fileexchange/58312-kernel-density-estimator-for-high-dimensions (2016). Accessed 10 Jan 2017
Botev, Z.I., Grotowski, J.F., Kroese, D.P.: Kernel density estimation via diffusion. Ann. Stat. 38(5), 2916–2957 (2010)
Breiman, L., Friedman, J., Stone, C.J., Olshen, R.: Classification and Regression Trees. Wadsworth Statistics/Probability. Chapman and Hall/CRC, Boca Raton (1984)
Cao, R., Cuevas, A., Gonzalez Manteiga, W.: A comparative study of several smoothing methods in density estimation. Comput. Stat. Data Anal. 17(2), 153–176 (1994)
Cochran, W.G.: The chi square test of goodness of fit. Ann. Math. Stat. 23(3), 315–345 (1952)
Curtin, R.R., Cline, J.R., Slagle, N.P., March, W.B., Ram, P., Mehta, N.A., Gray, A.G.: Mlpack: a scalable C++ machine learning library. J. Mach. Learn. Res. 14, 801–805 (2013)
Ferguson, T.S.: A bayesian analysis of some nonparametric problems. Ann. Stat. 1(2), 209–230 (1973)
Fix, E., Hodges, J.: Discriminatory analysis, nonparametric estimation: consistency properties. Report 4, Project No. 21-49-004, USAF School of Aviation Medicine (1951)
Härdle, W., Werwatz, A., Müller, M., Sperlich, S.: Nonparametric and Semiparametric Models. Springer Series in Statistics, 1st edn. Springer, Berlin (2004)
Jiang, H., Mu, J.C., Yang, K., Du, C., Lu, L., Wong, W.H.: Computational aspects of optional Pólya tree. J. Comput. Graph. Stat. 25(1), 301–320 (2016)
Jing, J., Koch, I., Naito, K.: Polynomial histograms for multivariate density and mode estimation. Scand. J. Stat. 39(1), 75–96 (2012)
Jones, M.C., Marron, J.S., Sheather, S.J.: A brief survey of bandwidth selection for density estimation. J. Am. Stat. Assoc. 91(433), 401–407 (1996)
Kendall, M.G.: A new measure of rank correlation. Biometrika 30(1–2), 81–93 (1938)
Kogure, A.: Asymptotically optimal cells for a historgram. Ann. Stat. 15(3), 1023–1030 (1987)
Kooperberg, C., Stone, C.J.: A study of logspline density estimation. Comput. Stat. Data Anal. 12(3), 327–347 (1991)
Loftsgaarden, D.O., Quesenberry, C.P.: A nonparametric estimate of a multivariate density function. Ann. Math. Stat. 36(3), 1049–1051 (1965)
Ma, L., Wong, W.H.: Coupling optional Pólya trees and the two sample problem. J. Am. Stat. Assoc. 106(496), 1553–1565 (2011)
Mann, H.B., Wald, A.: On the choice of the number of class intervals in the application of the chi square test. Ann. Math. Stat. 13(3), 306–317 (1942)
Marron, J.S., Wand, M.P.: Exact mean integrated squared error. Ann. Stat. 20(2), 712–736 (1992)
Neal, R.M.: Markov chain sampling methods for Dirichlet process mixture models. J. Comput. Graph. Stat. 9(2), 249–265 (2000)
Nelsen, R.B., Ubeda-Flores, M.: How close are pairwise and mutual independence? Stat. Probab. Lett. 82(10), 1823–1828 (2012)
O’Brien, T.A., Kashinath, K., Cavanaugh, N.R., Collins, W.D., O’Brien, J.P.: A fast and objective multidimensional kernel density estimation method: fastKDE. Comput. Stat. Data Anal. 101, 148–160 (2016)
Papoulis, A.: Probability, Random Variables, and Stochastic Processes. McGraw-Hill Series in Electrical Engineering, 3rd edn. McGraw-Hill Inc., New York (1991)
Park, B.U., Marron, J.S.: Comparison of data-driven bandwidth selectors. J. Am. Stat. Assoc. 85(409), 66–72 (1990)
Park, B., Turlach, B.: Practical performance of several data driven bandwidth selectors. Report, Université Catholique de Louvain, Center for Operations Research and Econometrics (CORE) (1992)
Pearson, K.: On the criterion that a given system of deviations from the probable in the case of correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. Philos. Mag. 50, 157–175 (1900)
Petersen, A., Müller, H.G.: Functional data analysis for density functions by transformation to a Hilbert space. Ann. Stat. 44(1), 183–218 (2016)
Ram, P., Gray, A.G.: Density estimation trees. In: Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Association for Computing Machinery, pp. 627–635 (2011)
Rosenblatt, M.: Remarks on some nonparametric estimates of a density function. Ann. Math. Stat. 27(3), 832–837 (1956)
Scott, D.W.: Multivariate Density Estimation Theory, Practice, and Visualization. Wiley Series in Probability and Statistics, 2nd edn. Wiley, Hoboken (2015)
Scott, D.W., Sagae, M.: Adaptive density estimation with massive data sets. In: Proceedings of the Statistical Computing Section, pp. 104–108. ASA, American Statistical Association (1997)
Shampine, L.F.: Matlab program for quadrature in 2d. Appl. Math. Comput. 202(1), 266–274 (2008a)
Shampine, L.F.: Vectorized adaptive quadrature in matlab. J. Comput. Appl. Math. 211(2), 131–140 (2008b)
Sheather, S.J.: Density estimation. Stat. Sci. 19(4), 588–597 (2004)
Shorack, G.R.: Probability for Statisticians. Springer Texts in Statistics. Springer, Berlin (2000)
Silverman, B.W.: Density Estimation for Statistics and Data Analysis. Monographs on Statistics and Applied Probability. Chapman and Hall, CRC, Boca Raton (1998)
Smirnov, N.: Table for estimating the goodness of fit of empirical distributions. Ann. Math. Stat. 19(2), 279–281 (1948)
Sriperumbudur, B., Fukumizu, K., Kumar, R., Gretton, A., Hyvaerinen, A.: Density estimation in infinite dimensional exponential families. arXiv:1509.04348v2 p. 42 (2013)
Steele, M., Chaseling, J.: Powers of discrete goodness-of-fit test statistics for a uniform null against a selection of alternative distributions. Commun. Stat. Simul. Comput. 35(4), 1067–1075 (2006)
Wang, X., Wang, Y.: Nonparametric multivariate density estimation using mixtures. Stat. Comput. 25(2), 349–364 (2015)
Wong, W.H., Ma, L.: Optional Pólya tree and Bayesian inference. Ann. Stat. 38(3), 1433–1459 (2010)
Yang, Y.: Penalized semiparametric density estimation. Stat. Comput. 19(4), 355 (2008)
Zaunders, J., Jing, J., Leipold, M., Maecker, H., Kelleher, A.D., Koch, I.: Computationally efficient multidimensional analysis of complex flow cytometry data using second order polynomial histograms. Cytom. Part A 89(1), 44–58 (2016)
Author information
Authors and Affiliations
Corresponding author
Additional information
The author is grateful to Marco Weibel for his help during the preparation of this manuscript. Very valuable feedback from an associate editor and two reviewers and helpful input from Oliver Brenner and Florian Müller are gratefully acknowledged. Moreover, the author acknowledges helpful comments from Nina Roth and feedback on the initial version of this manuscript from Patrick Jenny, both from ETH Zürich. The author has been financially supported by ETH Zürich.
Appendix: Derivation of MMSE slope estimator
Appendix: Derivation of MMSE slope estimator
Writing without loss of generality the linear marginal PDF (4) in a simpler form with \(x_i\in [0,1]\) and the subscripts skipped, we obtain
By calculating the mean of random variable X based on this PDF, we obtain \(\langle X\rangle = \frac{1}{12}(6 + \theta )\), and therefore, can express the slope parameter in terms of this mean as
In the case of a finite ensemble, we estimate the mean with \(\langle X\rangle _n = \frac{1}{n}\sum _{j = 1}^n x_j\) and the slope by
Here, c is a correction factor that is determined by minimizing the mean square error (MSE) expressed as
To determine the minimum MSE, we set
which leads for the correction factor to
For \(n\rightarrow \infty \) the correction factor c goes to one.
Rights and permissions
About this article

Cite this article
Meyer, D.W. Density estimation with distribution element trees. Stat Comput 28, 609–632 (2018). https://doi.org/10.1007/s11222-017-9751-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11222-017-9751-9
Keywords
- Nonparametric density estimation
- Adaptive histogram
- Kernel density estimation
- Adaptive binning
- Polynomial histogram
- Curse of dimensionality
- High dimensional
- Big data
- Pólya tree
- Density estimation tree