
Abstract
This paper suggests a new method to search main path, as a knowledge trajectory, in the citation network. To enhance the performance and remedy the problems suggested by other researchers for main path analysis (Hummon and Doreian, Social Networks 11(1): 39–63, 1989), we applied two techniques, the aggregative approach and the stochastic approach. The first technique is used to offer improvement of link count methods, such as SPC, SPLC, SPNP, and NPPC, which have a potential problem of making a mistaken picture since they calculate link weights based on a individual topology of a citation link; the other technique, the second-order Markov chains, is used for path dependent search to improve the Hummon and Doreian’s priority first search method. The case study on graphene that tested the performance of our new method showed promising results, assuring us that our new method can be an improved alternative of main path analysis. Our method’s beneficial effects are summed up in eight aspects: (1) path dependent search, (2) basic research search rather than applied research, (3) path merge and split, (4) multiple main paths, (5) backward search for knowledge origin identification, (6) robustness for indiscriminately selected citations, (7) availability in an acyclic network, (8) completely automated search.










Similar content being viewed by others

Notes
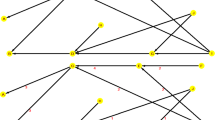
Sink nodes are defined as those nodes that are not cited by other nodes but only cite other nodes in the network.
NPPC of 10 is: 3–12, 3–15, 3–20, 3–21, 3–22, 5–12, 5–15, 5–20, 5–21, and 5–22.
SPLC of 6 is: 3–22 via 15, 3–22 via 21, 3–22 via 20 without 21, 5–22 via 15, 5–22 via 21, and 5–22 via 20 without 21.
SPNP of 14 is: 3–12, 3–15, 3–22 via 15, 3–20, 3–21 via 20, 3–22 via 21, 3–22 via 20 without 21, 5–12, 5–15, 5–22 via 15, 5–20, 5–21 via 20, 5–22 via 21, and 5–22 via 20 without 21.
Source nodes are defined as those nodes that are cited by other nodes but do not cite any nodes in the network.
For an example of SPC, the link from node 5 to node 12 in Fig. 2 has the SPC value of 3, and the paths is: 3–22 via 15, 3–22 via 21, 3–22 via 20 without 21.
References
Batagelj, V. (2003). Efficient algorithms for citation network analysis. Retrieved from http://arxiv.org/abs/cs.DL/0309023
Bhupatiraju, S., Verspagen, H. H. G., Nomaler, Z. O., & Triulzi, G. (2012). Knowledge flows-analyzing the core literature of innovation, entrepreneurship and science and technology studies. Research Policy, 41(7), 1121–1282.
Brenner, C. (1999). An elementary textbook of psychoanalysis. New York: International Universities Press.
Carley, K. M., Hummon, N. P., & Harty, M. (1993). Scientific influence: An analysis of the main path structure in the Journal of Conflict Resolution. Knowledge: Creation, Diffusion, Utilization, 14(4), 417–447.
Demaine, J. (2009). A main path domain map as digital library interface. In Proceedings of SPIE—The International Society for Optical Engineering, 7243, article number 72430G.
Gao, X., & Guan, J. (2012). The influence of the applicants’ gender on the modeling of a peer review process by using latent Markov models. Scientometrics, 90(3), 749–762.
Garfield, E. (1965). Can citation indexing be automated? In M. E. Stevens (Ed.), Statistical association methods for mechanized documentation (pp. 189–192). Washington, DC: National Bureau of Standards.
Garfield, E., Sher, I. H., & Torpie, R. J. (1964). The use of citation data in writing the history of science. Philadelphia: Institute for Scientific Information.
Harris, J. K., Beatty, K. E., Lecy, J. D., Cyr, J. M., & Shapiro, R. M, I. I. (2011). Mapping the multidisciplinary field of public health services and systems research. American Journal of Preventive Medicine, 41(1), 105–111.
Hummon, N. P., & Doreian, P. (1989). Connectivity in a citation network: The development of DNA theory. Social Networks, 11(1), 39–63.
Kullback, S., & Leibler, R. A. (1951). On information and sufficiency. The Annals of Mathematical Statistics, 22, 79–86.
Liu, J. S., & Lu, L. Y. Y. (2012). An integrated approach for main path analysis: The development of the Hirsch index as an example. Journal of the American Society for Information Science and Technology, 63(3), 528–542.
Lucio-Arias, D., & Leydesdorff, L. (2008). Main-path analysis and pathdependent transitions in HistCite-based historiograms. Journal of the American Society for Information Science and Technology, 59(12), 1948–1962.
Narin, F., Pinski, G., & Gee, H. H. (1976). Structure of the biomedical literature. Journal of the American Society for Information Science and Technology, 27(1), 25–45.
Nederhof, A. J., & Van Raan, A. F. J. (1987). Citation theory and the Ortega hypothesis. Scientometrics, 12, 325–328.
Novoselov, K. S., Geim, A. K., Morozov, S. V., Jiang, D., Zhang, Y., Dubonos, S. V., et al. (2004). Electric field effect in atomically thin carbon films. Science, 306(5696), 666–669.
Raftery, A. E. (1985). A model for high-order Markov chains. Journal of the Royal Statistical Society: Series B, 47, 528–539.
Roll-Hansen, N. (2009). Why the distinction between basic (theoretical) and applied (practical) research is important in the politics of science. London: Centre for Philosophy of Natural and Social Science.
Simkin, M. V., & Roychowdhury, V. P. (2003). Read before you cite! Complex Systems, 14, 269.
Small, H. G. (1977). A co-citation model of a scientific specialty: A longitudinal study of collagen research. Social Studies of Science, 7, 139–166.
Small, H. G. (1982). Citation context analysis. In B. Dervin & M. J. Voigt (Eds.), Progress in communication sciences (Vol. 3, pp. 287–310). Norwood: Ablex Publishing.
Verspagen, B. (2005). Mapping technological trajectories as patent citations networks. A study on the history of fuel cell research. Ecis Working Paper 2005–11.
White, H. D. (2001). Authors as citers over time. Journal of the American Society for Information Science and Technology, 52(2), 87–108.
Zhang, Z., & Nasraoui, O. (2007). Efficient hybrid web re-commendations based on Markov click stream models and implicit search. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (pp. 621–627).
Acknowledgments
We, the authors of this paper, wish to record our thanks to Professor Sungyoul Choi, the director of the graphene research center at Korea Advanced Institute of Science and Technology (KAIST), who was willing to give us technical assistance related to the historical characteristics of graphene research and to the comparative analysis of the results of experiments. This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIP) (2012R1A2A2A01014729) and the Next-Generation Information Computing Development Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science, ICT & Future Planning (2012M3C4A7033341).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Yeo, W., Kim, S., Lee, JM. et al. Aggregative and stochastic model of main path identification: a case study on graphene. Scientometrics 98, 633–655 (2014). https://doi.org/10.1007/s11192-013-1140-3
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-013-1140-3