
Abstract
The dominant pole approximation (DPA) is a classical analytic method to obtain from a generating function asymptotic estimates for its underlying coefficients. We apply DPA to a discrete queue in a critical many-sources regime, in order to obtain tail asymptotics for the stationary queue length. As it turns out, this regime leads to a clustering of the poles of the generating function, which renders the classical DPA useless, since the dominant pole is not sufficiently dominant. To resolve this, we design a new DPA method, which might also find application in other areas of mathematics, like combinatorics, particularly when Gaussian scalings related to the central limit theorem are involved.
Similar content being viewed by others


1 Introduction
Probability generating functions (PGFs) encode the distributions of discrete random variables. When PGFs are considered analytic objects, their singularities or poles contain crucial information about the underlying distributions. Asymptotic expressions for the tail distributions, related to large deviations events, can typically be obtained in terms of the so-called dominant singularities, or dominant poles. The dominant pole approximation (DPA) for the tail distribution is then derived from the partial fraction expansion of the PGF and maintaining from this expansion the dominant fraction related to the dominant pole. Dominant pole approximations have been applied in many branches of mathematics, including analytic combinatorics [7] and queueing theory [19]. We apply DPA to a discrete queue that has an explicit expression for the PGF of the stationary queue length. Additionally, this queue is considered in a many-sources regime, a heavy-traffic regime in which both the demand on and the capacity of the systems grow large, while their ratio approaches one. This many-sources regime combines high system utilization and short delays, due to economies of scale. The regime is similar in flavor to the QED (quality and efficiency driven) regime for many-server systems [8], although an important difference is that our discrete queue fed by many-sources falls in the class of single-server systems and therefore leads to a manageable closed form expression for the PGF of the stationary queue length Q. Denote this PGF by \(Q(z)=\mathbb {E}(z^Q)\).
PGFs can be represented as power series around \(z=0\) with non-negative coefficients (related to the probabilities). We assume that the radius of convergence of Q(z) is larger than one (in which case all moments of Q exist). This radius of convergence is in fact determined by the dominant singularity \(Z_{0}\), the singularity in \(|z|>1\) closest to the origin. For PGFs, due to Pringsheim’s theorem [7], \(Z_{0}\) is always a positive real number larger than one. Then DPA leads to the approximation
with \(c_0=\lim _{z\rightarrow Z_{0}}(z-Z_{0})Q(z)\). In many cases, the approximation (1.1) can be turned into a more rigorous asymptotic expansion (for N large) for the tail probabilities \(\mathbb {P}(Q> N)\). We shall now explain in more detail the many-sources regime, the discrete queue, and when combining both, the mathematical challenges that arise when applying DPA.
1.1 Many sources and a discrete queue
Consider a stochastic system in which demand per period is given by some random variable A, with mean \(\mu _A\) and variance \(\sigma ^2_A\). For systems facing large demand, one can set the capacity according to the rule \(s=\mu _A+\beta \sigma _A\), which consists of a minimally required part \(\mu _A\) and a variability hedge \(\beta \sigma _A\). Such a rule can lead to economies of scale, as we will now describe in terms of a setting in which the demand per period is generated by many sources. Consider a system serving n independent sources and let X denote the generic random variable that describes the demand per source per period, with mean \(\mu \) and variance \(\sigma ^2\). Denote the service capacity by \(s_n\), so that the system utilization is given by \(\rho _n=n\mu /s_n\), where the index n expresses the dependence on the scale at which the system operates. The traditional capacity sizing rule would then be
with \(\beta \) some positive constant. The standard heavy-traffic paradigm [11, 15, 16], which builds on the central limit theorem, then prescribes considering a sequence of systems indexed by n with associated loads \(\rho _n\) such that (also using that \(s=s_n\sim n\mu \))
where \(\gamma =\beta \sigma /\sqrt{\mu }\). We shall apply the many-sources regime given by (1.2) and (1.3) to a discrete queue, in which we divide time into periods of equal length and model the net input in consecutive periods as i.i.d. samples from the distribution of A, with mean \(n\mu \) and variance \(n\sigma ^2\). The capacity per period \(s_n\) is fixed and integer valued. The scaling rule in (1.3) thus specifies how the mean and variance of the demand per period, and simultaneously \(s_n\), will all grow to infinity as functions of n. Many-sources scaling became popular through the Anick–Mitra–Sondhi model [1], as one of the canonical models for modern telecommunications networks, in which a switch may have hundreds of different input flows. But apart from communication networks, the concept of many sources can apply to any service system in which demand can be regarded as coming from many different inputs (see, for example, [4, 6, 13, 17, 18] for specific applications).
1.2 How to adapt classical DPA?
As it turns out, the many-sources regime changes drastically the nature of the DPA. When the queue is pushed into the many-sources regime for \(n\rightarrow \infty \), the dominant pole becomes barely dominant, in the sense that all the other poles (the dominated ones) of the PGF are approaching the dominant pole. For the partial fraction expansion of the PGF, this means that it becomes hard, or impossible even, to simply discard the contributions of the fractions corresponding to what we call dominated poles: all poles other than the dominant pole. Moreover, the dominant pole itself approaches 1 according to
This implies that in (1.1) the factor \(c_0/(1-Z_{0})\) potentially explodes, while without imposing further conditions on N, the factor \(Z_{0}^{-N-1}\) goes to the degenerate value 1. The many-sources regime thus has a fascinating effect on the location of the poles that renders a standard DPA useless for multiple reasons. We shall therefore adapt the DPA in order to make it suitable to deal with the complications that arise in the many-sources regime, with the goal to again obtain an asymptotic expansion for the tail distribution. First observe that the term \(Z_{0}^{-N-1}\) in (1.1) becomes non-degenerate when we impose that \(N\sim K\sqrt{n\sigma ^2}\), with K some positive constant, in which case
The condition \(N\sim K\sqrt{n\sigma ^2}\) is natural, because the fluctuations of our stochastic system are of the order \(\sqrt{n\sigma ^2}\). Of course, there are many ways in which N and n can be coupled, but due to (1.4), only couplings for which N is proportional to \(\sqrt{n}\) lead to a non-degenerate limit for \(Z_{0}^{-N-1}\). Now let us turn to the other two remaining issues: the fact that \(c_0/(1-Z_{0})\) potentially explodes and that the dominated poles converge to the dominant pole.
The approach in this paper to deal with these two issues uses the integral representation of the tail probabilities involving the PGF Q(z) of Q along a circle \(|z|=1+\varepsilon <Z_0\). By Cauchy’s theorem, the tail probabilities can be written as a residue \(c_0/(1-Z_0)Z_0^{N+1}\) at \(z=Z_0\) and an integral along a contour shifted beyond \(Z_0\). Using the product expansion of Q(z), involving the zeros of a characteristic equation in \(|z|\le 1\), the quantity \(c_0/(1-Z_0)\) can be approximated in terms of an integral of the Pollaczek type that has been considered in [11]. In [11], a dedicated saddle point method has been developed to approximate Pollaczek-type integrals for the mass at zero, the mean, and the variance of Q in the many-sources regime. This dedicated saddle point method can also be used to find a many-sources approximation for \(c_0/(1-Z_0)\). The remaining challenge is then to bound the contribution of the contour integral shifted beyond the dominant pole \(Z_0\). This depends on how far the integration path can be shifted, and this is determined by the positions of the first dominated poles. It turns out that, in the many-sources regime, the dominated poles have approximations of the type (1.4) as well. The integration path is then chosen, roughly, as the circle that passes halfway between \(Z_0\) and the first dominated pole. This, together with the dedicated saddle point method to approximate \(c_0/(1-Z_0)\), then provides a fully rigorous derivation of the asymptotic expression for \(\mathbb {P}(Q> N)\) that is of the form
The function \(h(\beta )\) in this asymptotic expression involves infinite series and Riemann zeta functions that are reminiscent of the reflected Gaussian random walk [5, 9, 10]. Indeed, it follows from [16, Theorem 3] that our rescaled discrete queue converges under (1.3) to a reflected Gaussian random walk. Hence, the tail distribution of our system in the regime (1.3) should for large n be well approximated by the tail distribution of the reflected Gaussian random walk. We return to this connection in Sect. 5.
Our approach thus relies on detailed knowledge about the distribution of all the poles of the PGF of Q, and in particular how this distribution scales with the asymptotic regime (1.2)–(1.3). As it turns out, in contrast with classical DPA, this many-sources regime means that all poles contribute to the asymptotic characterization of the tail behavior. Our saddle point method leads to an asymptotic expansion for the tail probabilities, of which the limiting form corresponds to the heavy-traffic limit, and pre-limit forms present refined approximations for pre-limit systems (\(n<\infty \)) in heavy traffic. Such refinements to heavy-traffic limits are commonly referred to as corrected diffusion approximations [2, 3, 14]. Compared with the studies that directly analyzed the Gaussian random walk [5, 9, 10], which is the scaling limit of our queue in the many-sources regime, we start from the pre-limit process description and establish an asymptotic result which is valuable for a queue with a finite yet large number of sources. Starting this asymptotic analysis from the actual pre-limit process description is mathematically more challenging than directly analyzing the process limit, but in return gives valuable insights into the manner and speed at which the system starts displaying its limiting behavior.
1.3 Outline of the paper
In Sect. 2 we describe the discrete queue in more detail and present some preliminary results for its stationary queue length distribution. In Sect. 3 we give an overview of the results and the contour integration representation for the tail distribution. In Sect. 4 we give a rigorous proof of the main result for the leading-order term using the dedicated saddle point method (Subsect. 4.1), and we bound the contour integral with integration path shifted beyond the dominant pole (Subsect. 4.2). In Sect. 5 we elaborate on the connection between the discrete queue and the Gaussian random walk, and we present an asymptotic series for \(\mathbb {P}(Q >N)\) comprising not only the dominant poles but also the dominated poles.
2 Model description and preliminaries
We consider a discrete stochastic model in which time is divided into periods of equal length. At the beginning of each period \(k=1,2,3,...\) new demand \(A_k\) arrives to the system. The demands per period \(A_1,A_2,...\) are assumed independent and equal in distribution to some non-negative integer-valued random variable A. The system has a service capacity \(s\in \mathbb {N}\) per period, so that the recursion
assuming \(Q_1=0\), gives rise to a Markov chain \((Q_k)_{k\ge 1}\) that describes the congestion in the system over time. The PGF
is assumed analytic in a disk \(|z|<r\) with \(r>1\), which implies that all moments of A exist.
We assume that \(A_k\) is in distribution equal to the sum of work generated by n sources, \(X_{1,k}+...+X_{n,k}\), where the \(X_{i,k}\) are, for all i and k, i.i.d. copies of a random variable X, of which the PGF \(X(z)=\sum _{j=0}^{\infty }\mathbb {P}(X=j)z^j\) has radius of convergence \(r>1\), and
Under the assumption (2.3), the stationary distribution \(\lim _{k\rightarrow \infty }\mathbb {P}(Q_k=j)=\mathbb {P}(Q=j)\), \(j=0,1,\ldots \) exists, with the random variable Q defined as having this stationary distribution. We let
be the PGF of the stationary distribution.
It is a well-known consequence of Rouché’s theorem that under (2.3) \(z^s-A(z)\) has precisely s zeros in \(|z|\le 1\), one of them being \(z_0=1\). We proceed in this paper under the same assumptions as in [11]. Thus, we assume that \(|X(z)|<X(r_1)\), \(|z|=r_1\), \(z\ne r_1\), for any \(r_1\in (0,r)\); see [11], end of Sect. 2 for a discussion of this condition. Finally, we assume that the degree of X(z) is larger than s / n. Under these conditions, \(z_0\) is the only zero of \(z^s-A(z)\) on \(|z|=1\), and all others in \(|z|\le 1\), denoted by \(z_1,z_2,...,z_{s-1}\), lie in \(|z|<1\). Furthermore, there are at most countably many zeros \(Z_k\) of \(z^s-A(z)\) in \(1<|z|<r\), and there is precisely one, denoted by \(Z_0\), with minimum modulus. The zeros \(Z_k\) are indexed using integer k; they come in conjugate pairs and we let \(Z_k=Z_{-k}^*\) where \(Z_k\) is in the (closed) lower half plane for non-negative k. For our analysis, it is crucial that \(r>1\), and so certain heavy-tailed distributions for X (with \(r=1\)) are excluded.
There is the product form representation [4, 17]
that gives the analytic extension of Q(z) to all z, \(|z|<r\) and z not a zero of \(z^s-A(z)\), where the right-hand side of (2.5) is analytic in \(|z|<Z_0\) and has a first-order pole at \(z=Z_0\). We have, for the tail probability (using that \(Q(1)=1\)), for \(N=0,1,...\)
where \(C_{z^N}[f(z)]\) denotes the coefficient of \(z^N\) of the function f(z). By contour integration, Cauchy’s theorem and \(Q(1)=1\), we then get for \(0<\varepsilon <Z_0-1\)
where \(c_0=\mathrm{Res}_{z=Z_0}[Q(z)]\) and R is any number between \(Z_0\) and \(\min _{k\ne 0}|Z_k|\). When n and s are fixed, we have that the integral on the second line of (2.7) is \(O(R^{-N})\), and so there is the DPA
In this paper we consider the heavy-traffic setting described by (1.2) and (1.3) with \(n\rightarrow \infty .\) In this setting R and \(Z_0\) in (2.7) tend to 1, and thus both terms on the second line of (2.7) need special attention. The second term here is approximated, using the product form expansion in (2.5), in terms of a contour integral of the Pollaczek type to which the dedicated saddle point method of [11], Sect. 3, can be applied. The method has been developed in [11] from Pollaczek’s integral representation of the PGF of Q,
which holds when \(|w|<1+\varepsilon <Z_0\), to get limiting expressions for moments of Q in the generalized heavy-traffic regimes \(n/s=1-\gamma n^{-\alpha }\), \(\alpha >0\), and \(n\rightarrow \infty \). To this end, the contour integrals are deformed so as to pass through the saddle point \(z_\mathrm{sp}\in (1,Z_0)\) given as the zero z of \(g'(z)\), where \(g(z)=-\ln z +\frac{1}{s}\ln A(z)={-\ln z+\frac{n}{s}\ln X(z)}\). A crucial ingredient here is the substitution \(z=z(v)\), \(-\frac{1}{2} \delta \le v \le \frac{1}{2} \delta \) for some \(\delta >0\), such that
where \(B=\mathrm{exp} (s g(z_\mathrm{sp}))\) and \(\eta =g''(z_\mathrm{sp})\). It is shown in [11], p. 796, using Lagrange’s inversion theorem, that in the heavy-traffic regime \(n/s=1-\gamma /\sqrt{n}\), for a \(\delta >0\) independent of s one has
with real coefficients \(c_j\), while (2.10) holds with B positive and bounded away from 0 and 1, and \(\eta \) positive and bounded away from 0.
3 Overview and results
In order to force the discrete queue to operate in the critical many-sources regime, we shall assume throughout the paper the following relation between the number of sources n and the capacity \(s=s_n(\gamma )\):
with \(\gamma >0\) bounded away from 0 and \(\infty \) as \(s\rightarrow \infty \). In this scaling regime, the zeros \(z_j\) and \(Z_k\) of \(z^s-A(z)=0\) start clustering near \(z=1\), as described in the next lemma (proved in the appendix). Let \(z_j^*\) and \(Z_k^*\) denote the complex conjugates of \(z_j\) and \(Z_k\), respectively.
Lemma 3.1
For finite \(j,k=1,2,...\) and \(s\rightarrow \infty \),
with
and principal roots in (3.3)–(3.5).
Due to this clustering phenomenon, the main reasoning that underpins classical DPA cannot be carried over. Starting from the expression (2.8), we need to investigate what becomes of the term \(c_0/(1-Z_0)\), and moreover, the validity of the exponentially small phrase in (2.8) and the actual N-range both become delicate matters that need detailed information about the distribution of the zeros as in Lemma 3.1.
Let us first present a result that identifies the relevant N-range:
Proposition 3.2
when \(N+1=L\sqrt{s}\) with \(L>0\) bounded away from 0 and \(\infty \).
Proof
We have from (3.2) and (3.5) that \(Z_0=1+\frac{2\gamma \mu }{\sigma ^2\sqrt{s}}+O\left( \frac{1}{s}\right) \). Hence
when L is bounded away from 0 and \(\infty \), and this gives the result. \(\square \)
From (2.5), we obtain the representation
The next result will be proved in Sect. 4.
Lemma 3.3
We thus get from (3.8) and Lemma 3.3
where
for \(Z\in {\mathbb {C}}\), \(|Z|\ge 1\) (principal logarithm). To handle the product P(z), in Lemma 3.4 below we evaluate \(\ln P(Z)\) for \(|Z|\ge 1\) in terms of the contour integral
where \(\varepsilon >0\) is such that \(1<1+\varepsilon <Z_0\).
Lemma 3.4
Let \(\varepsilon >0\), \(1<1+\varepsilon <Z_0\) and \(|Z|\ge 1\). Then
The dedicated saddle point method, as considered in [11], applied to I(Z), with saddle point \(z_\mathrm{sp}=1+\varepsilon \) of the function \(g(z)={-}\ln z+\frac{n}{s} \ln (X(Z))\), yields
Combining (3.21), (3.5), (3.8), (3.9), and (3.14) then gives one of our main results:
Proposition 3.5
The next step consists of bounding the integral on the second line of (2.7) that can be written as
by choosing R appropriately. To do this, we consider the product representation (2.5) of Q(z), and we want to choose R such that \(|z^s-A(z)|\ge C |z|^s\), \(|z|=R\), for some \(C>0\) independent of s. It will be shown in Sect. 4 that this is achieved by taking R such that the curve \(|z^s|=|A(z)|\), on which \(Z_0\) and \(Z_{\pm 1}\)(\(=Z_{+1},Z_{-1}\)) lie, is crossed near a point z (also referred to as \(Z_{\pm 1/2}\)) where \(z^s\) and A(z) have opposite sign. A further analysis, using again the dedicated saddle point method to bound the product \(\prod _{j=1}^{s-1}\) in (2.5), then yields that the integral in (3.16) decays as \(R^{-N}\). Finally, using the asymptotic information in (3.2)–(3.4) for \(Z_0\) and \(Z_{\pm 1}\), with \(Z_{\pm 1/2}\) lying midway between \(Z_0\) and \(Z_{\pm 1}\), the integral on the second line of (2.7) can be shown to have relative order \(\exp ({-}DN/\sqrt{s})\), for some \(D>0\) independent of s, compared to the dominant pole term in (2.8).
To summarize, we have now that
for some \(D>0\) independent of s, \(N=1,2,\ldots \). The DPA \(c_0/(1-Z_{0})^{-1}Z_{0}^{-N-1}\) of \(\mathbb {P}(Q> N)\) thus has a relative error that decays exponentially fast.
In Subsect. 5.1, the stationary queue length Q, considered in the many-sources regime, is shown to be connected to the Gaussian random walk. This connection will imply that the front factor of the DPA in (3.17) satisfies
where \(\ln H(b_0)\) has a power series in \(b_0\) with coefficients that can be expressed in terms of the Riemann zeta function. Combining this with Propositions 3.2 and 3.17 yields
when \(N+1=L\sqrt{s}\) with L bounded away from 0 and \(\infty \). The leading term in (3.19) agrees with (1.6) when we identify
and \(H(b_0)=h(\beta )\).
In Subsect. 5.2, we extend for a fixed \(M=1,2,\ldots \) the approach in Sect. 4 by increasing the radius R of the integration contour in (3.16) to \(R_M\) such that the poles \(Z_0, Z_{\pm 1},\ldots ,Z_{\pm M}\) are inside \(|z|=R_M\). This leads to
The front factors \(c_k/(1-Z_k)\) in the series in (3.21) satisfy
with \(H_k(b_0)\) some explicitly defined integral. When \(N+1=L\sqrt{s}\) with L bounded away from 0 and \(\infty \), we find from (3.22) and Proposition 3.2 that
compare with (3.18), and it can be shown that this gives rise to an \(\exp (-DL/\sqrt{k})\) decay of the right-hand side of (3.23). The results in (3.19), (3.21) and (3.23) together give precise information as to how the DPA arises, with leading behavior from the dominant pole, and lower order refinements coming from the dominated poles.
4 DPA through contour integration
In this section we present the details of getting approximations of the tail probabilities using a contour integration approach as outlined in Sect. 3. In Subsect. 4.1 we concentrate on approximation of the front factor \(c_0/(1-Z_0)\) and the dominant pole \(Z_0\), and combine these to obtain an approximation of the leading-order term in (2.8). This gives Lemmas 3.3 and 3.4, and Proposition 3.5.
In Subsect. 4.2 we assess and bound the integral on the second line of (2.7) and thereby make precise what exponentially small in (2.8) means in the present setting.
4.1 Approximation of the leading-order term
4.1.1 Proof of Lemma 3.3
From
we compute
With the approximation (3.2), written as
we get
and
Hence, by (4.3–4.5) and (5.32),
where we have used \(d_0\) of (4.3) in the last step. This gives (3.9). \(\square \)
4.1.2 Proof of Lemma 3.4
We have \(|A(z)|<|z^s|\) when \(z\ne 1\), \(1<|z|<Z_0\), and so \(\ln (1-A(z)/z^s)\) is analytic in \(z\ne 1\), \(1<|z|<Z_0\). When \(|Z|>1+\varepsilon \), we have by partial integration, using that \(d[\ln (1-z/Z)]=-dz/(Z-z)\) and Cauchy’s theorem,
This gives the upper-case formula in (3.13), and the middle case follows in a similar manner by taking the residue at \(z=Z\) inside \(|z|=1+\varepsilon \) into account. For the lower case in (3.13), we use the result of the middle case, in which we take \(1<Z<1+\varepsilon \), \(Z\downarrow 1\). We have \(I(Z)\rightarrow I(1)\) as \(Z\downarrow 1\), and
and this completes the proof. \(\square \)
4.1.3 Proof of Proposition 3.5
By (3.10) and Lemma 3.4, we have
From (3.2), it follows that
and so
Next, we consider the integral representation (3.12) of I(Z), where we take \(\varepsilon \) such that
with \(z_\mathrm{sp}\), see [11, Sect. 3], the unique point \(z\in (1,Z_0)\) such that \(g'(z)=0\), where
We have \(g(1)=0=g(Z_0)\), and so \(z=z_\mathrm{sp}\) for which \(g'(z)=0\) lies about midway between 1 and \(Z_0\). More specifically, by expanding \(g'(z)=g'(1)+(z-1) g''(1)+O(s^{-1})\), \(1\le z\le Z_0\), and expressing \(g'(1)\), \(g''(1)\) in terms of \(\gamma , \mu , \sigma , s\), while using (4.3), it follows that
This suggests that \(I(Z_0)\approx {-}I(1)\), a statement made precise below, since the main contribution to I(Z) comes from the z’s in (3.12) close to \(z_\mathrm{sp}\).
We have, see [11],
Now
and
see [11, Subsect. 5.3]. Hence,
As for \(I(Z_0)\), we observe that, see (4.14),
Thus,
We next estimate the remaining integral in (4.20). With the substitution \(z=z(v)\), \(-\frac{1}{2} \delta \le v\le \frac{1}{2} \delta \), as explained at the end of Sect. 3, we have \(A(z(v))/z^s(v)=B \exp ({-}\frac{1}{2} s\eta v^2)\) with \(0<B<1\) and \(\eta >0\) bounded away from 1 and 0, respectively, and
where \(c_j\) are real. Then we get with exponentially small error
Now we get from (4.14) and (4.21) that
Furthermore,
Thus
Inserting this into the integral on the second line of (4.22), we see that the \(-v\) in (4.25) cancels upon integration. Also
and this finally shows that the integral in (4.22) is \(O(s^{-1/2})\). Then combining (4.11), (4.18), and (4.20), we get the result. \(\square \)
4.2 Bounding the remaining integral
We have from (2.7)
where \(R\in (Z_0,|Z_{\pm 1}|)\), and we intend to bound the integral on the right-hand side of (4.27). We use in (4.27) the Q(z) as represented by the right-hand side of (2.5) which is defined and analytic in z, \(|z|<r\), \(z\ne Z_k\). We write for \(|z|<r\), \(z\ne Z_k\)
Now \(s-\mu _A=\gamma \sqrt{s}\), and by Lemma 3.4 and (4.18), we have \(\prod _{j=1}^{s-1} (1-z_j)=P(1)\ge C \gamma \sqrt{s}\) for some \(C>0\) independent of s. Hence \((s-\mu _A)/\prod _{j=1}^{s-1} (1-z_j)\) is bounded in s. Next, for \(|z|\ge Z_0\), we have by Lemma 3.4
with I(z) given by (3.12) and admitting an estimate
since \(\sqrt{s}|z-z_\mathrm{sp}|\), \(B\in (0,1)\) and \(\eta >0\) are all bounded away from 0. Therefore, there remains to be considered \((z^s-A(z))^{-1}\). We show below that there is a \(C>0\), independent of s, such that
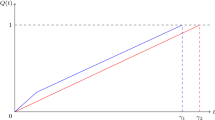
when z is on a contour K as in Fig. 1, consisting of a straight line segment
and a portion of the circle
that are joined at the points \((\mathrm{Re}\left[ \hat{Z}(\pm \tfrac{1}{2})\right] ,{\pm }\frac{1}{\sqrt{s}} y_0)\). Here
with \(a_0,b_0>0\) given in (5.36) and independent of s, approximates the solution \(z=Z(t)\), for real t small compared to s, of the equation
outside the unit disk, according to
Thus on K, we have from (4.31)
and we estimate
Here we have used that \(|z-1|\ge \mathrm{Re} \left[ \hat{Z}({\pm }\tfrac{1}{2})\right] -1\ge E/\sqrt{s}\), \(z\in K\), for some \(E>0\) independent of s. Observing that
we see that
for some \(\hat{D}>0\) independent of s. Hence, by (4.36), we see that the relative error in (4.27) due to ignoring the integral on the right-hand side is of order \(\exp ({-}DN/\sqrt{s})\) with some \(D>0\), independent of s.
We show the inequality (4.31) for \(z\in K\) using the following property of X: there is a \(\delta >0\) and a \(\vartheta _1\in (0,\pi /2)\) such that for any \(R\in [1,1+\delta ]\) the function \(|X(R e^{i\vartheta })|\) is decreasing in \(|\vartheta |\in [0,\vartheta _1]\) while
This property follows from strict maximality of \(|X(e^{i\vartheta })|\) in \(\vartheta \in [{-}\pi ,\pi ]\) at \(\vartheta =0\) and analyticity of X(z) in the disk \(|z|<r\) (with \(r>1\)).
For the construction of the contour K in (4.31–4.32), we consider the quantity
where v is of the form
with \(x_0>0\) fixed and varying \(y\in {\mathbb {R}}\). We choose \(x_0\) such that the outer curve Z(t) is crossed by \(z=1+v\) near the points \(Z({\pm }\frac{1}{2})\), where \(z^s-A(z)\) equals \(2z^s\). Thus, we choose
We have, as in the analysis in the appendix, that
With \(x_0>0\) fixed and independent of s, see (4.45), the leading part of the right-hand side in (4.46) is independent of s and describes, as a function of the real variable y, a parabola in the complex plane with real part bounded from above by its real value at \(y=0\) and that passes the imaginary axis at the points \(\pm \pi i\). Therefore, this leading part has a positive distance to all points \(2\pi ik\), integer k. Now take \(y_0\) such that
In Fig. 1, we show the curve K (bold), the approximation \(\hat{Z}(t)\) of the outer curve, and the choice \(y_0=\eta _0\sqrt{s}\) for the case that \(\gamma =1\), \(\mu /\sigma ^2=2\), \(s=100\).
It follows from the above analysis, with v as in (4.44), that
is bounded away from 0 and has a value \(1-c,1-c^{*}\) at \(y={\pm } y_0\), where c is bounded away from 1 and \(|c|<1\). Now write
When s is large enough, we have that \(R\in [1,1+\delta ]\) and \(0\le \vartheta _0\le \vartheta _1\), where \(\delta \) and \(\vartheta _1\) are as above in (4.42). We have
and by (4.42) and monotonicity of \(|X(R e^{i\vartheta })|\), \(\vartheta _0\le |\vartheta |\le \vartheta _1\),
Therefore, (4.31) holds on K with
positive and bounded away from 0 as s gets large.

Integration curve K (bold) consisting of line segment \(z=\xi +i\eta \), \(-\eta _0\le \eta \le \eta _0\), where \(\xi =\mathrm{Re}[\hat{Z}(\pm \tfrac{1}{2})]\) and \(\eta _0=y_0/\sqrt{s}\), and portion of the circle \(|z|=R\) with \(R=(\xi ^2+\eta _0^2)^{1/2}\). Choice of parameters: \(\gamma =1\), \(\mu /\sigma ^2=2\), \(s=100\)
5 Correction terms and asymptotic expansion
In this section, we give a series expansion for the leading term in (3.15) involving the Riemann zeta function. We also show how to find an asymptotic series for \(P(Q>N)\) as \(N\rightarrow \infty \) of which the term involving the dominant pole is the leading term. Before we do so, we first discuss how this leading term is related to the Gaussian random walk and a result of Chang and Peres [5].
5.1 Connection with Gaussian random walk
We know from [16, Theorem 3] that under the critical many-sources scaling, the rescaled queueing process converges to a reflected Gaussian random walk. The latter is defined as \((S_\beta (k))_{k\ge 0}\) with \(S_\beta (0)=0\) and
with \(Y_1,Y_2,\ldots \) i.i.d. copies of a normal random variable with mean \(-\beta \) and variance 1. Assume \(\beta >0\) (negative drift), and denote the all-time maximum of this random walk by \({M}_\beta \).
Denote by \(Q^{(s)}\) the stationary congestion level for a fixed s [that arises from taking \(k\rightarrow \infty \) in (2.1)]. Then, using \(\rho _s=1-\gamma /\sqrt{s}\), with
the spatially scaled stationary queue length reaches the limit \(Q^{(s)}/(\sigma \sqrt{n}) \mathop {\rightarrow }\limits ^{d} {M}_\beta \) as \(s,n\rightarrow \infty \) (see [12, 15, 16]).
The random variable \({M}_\beta \) was studied in [5, 9, 10]. In particular, [9, Theorem 1] yields, for \(\beta <2\sqrt{\pi }\),
and from [5], we have \(\mathbb {P}({M}_\beta > K)=h(\beta ,K) e^{-2\beta K}\) with
exponentially fast as \(K\rightarrow \infty \).
Hence, there are the approximations
where the second approximation holds for small values of \(\beta \). We will now show how this second approximation in (5.5) follows from our leading term in the expansion.
Proposition 5.1
Proof
It is shown in [11, Subsect. 5.3] that
in which we take the drift parameter \(\beta \) according to
From [10], we have
Then from Proposition 3.5, (5.7) and (5.9), we get the results in (5.6). \(\square \)
5.2 Asymptotic series for \(P(Q>N)\) as \(N\rightarrow \infty \)
When inspecting the argument that leads to (2.7), it is obvious that one can increase the radius R of the integration contour to values \(R_M\) between \(|Z({\pm }M)|\) and \(|Z({\pm }(M+1))|\) when \(M=1,2,...\) is fixed. Here it must be assumed that s is so large that \(|Z_k|\) increases in \(k=0,1,...,M+1\). Then, the poles of Q(z) at \(z=Z_{\pm k}\), \(k=0,1,...,M \), are inside \(|z|=R_M\), and we get
As in Subsect. 4.2, one can argue that the integral on the second line of (5.10) is relatively small compared to \(|Z_M|^{-N-1}\) when \(R_M\) is chosen between but away from \(|Z_M|\) and \(|Z_{M+1}|\).
We now need the following result.
Lemma 5.2
when \(k=o(s)\).
Proof
This follows from the appendix with a similar argument to the proof of Lemma 3.3. \(\square \)
As to the terms in the series in (5.10), we have for bounded k, see Lemma 5.2,
Furthermore, according to Lemma 3.4,
Thus, we get the following result.
Proposition 5.3
For bounded \(k\in {\mathbb {Z}}\),
We aim at approximating \(I(Z_k)\), showing, in particular, that \(c_k/(1-Z_k)\ne 0\) is bounded away from 0 for bounded k and large s. To that end, we conduct the dedicated saddle point analysis for \(I(Z_k)\). We have for \(|Z|\ge Z_0\), \(\mathrm{Re}(Z)>z_\mathrm{sp}\),
with exponentially small error in the last identity as \(s\rightarrow \infty \). With \(g(z)={-}\ln z+\frac{n}{s} \ln X(z)\), we let
and z(v) as in (4.21) and defined implicitly by \(g(z(v))=g(z_\mathrm{sp})-\frac{1}{2} v^2g''(z_\mathrm{sp})\). We then find, by using \(z(v)=z_\mathrm{sp}+iv+O(v^2)\) and \(z'(v)=i+O(v)\), that
where in the last step the substitution \(t=v \sqrt{s\eta /2}\) has been made. Combining in the last integrand in (5.17) the values at t and \(-t\) for \(t\ge 0\), we get the following result.
Proposition 5.4
For \(|Z|\ge Z_0\), \(\mathrm{Re}(Z)>z_\mathrm{sp}\),
where \(d=(Z-z_\mathrm{sp}) \sqrt{s\eta /2}\), and
In the context of Proposition 5.3, we consider
with
Using the definitions of \(a_0\), \(b_0\) in (5.36) and \(\eta \) in (5.16), we get
We have that
Since for \(t\ge 0\) and \(\mathrm{arg}(d)\in ({-}\frac{1}{4} \pi ,\tfrac{1}{4} \pi )\) we have
we see that we have complete control on the quantities \(J(\hat{d}_k)\) (also note (5.16) for this purpose). Using that \(-I(1)=I(Z_0)+O(s^{-1/2})\), see (4.20), we get the following result.
Proposition 5.5
For bounded \(k\in {\mathbb {Z}}\),
where the leading quantity in (5.25) \(\ne 0,\infty \), \(\hat{d}_k\) is given in (5.22) with \(\hat{d}_0=b_0\), and J is given in (5.19).
Theorem 5.6
There is the asymptotic series
where the ratio of the terms in the series with index M and \(M-1\) is \(O(|Z_{M-1}/Z_M|^N)\).
Proof
This follows from (5.10), in which the integral is \(o(|Z_M|^{-N})\) and the term with \(k=M\) is \(O(|Z_M|^{-N})\), while the reciprocal of the term with \(k=M-1\) is \(O(|Z_{M-1}|^{-N})\) by Proposition 5.5. In the consideration of the terms with \(k=M-1,M \), it is tacitly assumed that s is so large that \(|Z_k|\), \(k=0,1,...,M\) is a strictly increasing sequence. \(\square \)
References
Anick, D., Mitra, D., Sondhi, M.M.: Stochastic theory of a data-handling system with multiple sources. Bell Syst. Tech. J. 61(8), 1871–1894 (1982)
Asmussen, S.: Applied Probability and Queues, 2nd edn. Springer, New York (2003)
Blanchet, J., Glynn, P.: Complete corrected diffusion approximations for the maximum of a random walk. Ann. Appl. Probab. 16(2), 951–983 (2006)
Bruneel, H., Kim, B.G.: Discrete-Time Models for Communication Systems Including ATM. Kluwer Academic Publishers, Boston (1993)
Chang, J.T., Peres, Y.: Ladder heights, Gaussian random walks and the Riemann zeta function. Ann. Probab. 25(2), 787–802 (1997)
Dai, J.G., Shi, P.: A two-time-scale approach to time-varying queues for hospital inpatient flow management. Soc. Sci. Res. Network (2015). doi:10.2139/ssrn.2489533
Flajolet, P., Sedgewick, R.: Analytic Combinatorics, 1st edn. Cambridge University Press, New York (2009)
Halfin, S., Whitt, W.: Heavy-traffic limits for queues with many exponential servers. Oper. Res. 29, 567–588 (1981)
Janssen, A.J.E.M., van Leeuwaarden, J.S.H.: On Lerch’s transcendent and the Gaussian random walk. Ann. Appl. Probab. 17, 421–439 (2006)
Janssen, A.J.E.M., van Leeuwaarden, J.S.H.: Cumulants of the maximum of the Gaussian random walk. Stoch. Process. Appl. 117(12), 1928–1959 (2007)
Janssen, A.J.E.M., van Leeuwaarden, J.S.H., Mathijsen, B.W.J.: Novel heavy-traffic regimes for large-scale service systems. SIAM J. Appl. Math. 75, 212–787 (2015)
Jelenković, P., Mandelbaum, A., Momčilovic, P.: Heavy traffic limits for queues with many deterministic servers. Queueing Syst. 47, 53–69 (2004)
Newell, G.F.: Queues for a fixed-cycle traffic light. Ann. Math. Stat. 31, 589–597 (1960)
Siegmund, D.: Sequential Analysis. Springer Series in Statistics. Springer, New York (1985)
Sigman, K., Whitt, W.: Heavy-traffic limits for nearly deterministic queues. J. Appl. Probab. 48(3), 657–678 (2011)
Sigman, K., Whitt, W.: Heavy-traffic limits for nearly deterministic queues: stationary distributions. Queueing Syst. Theory Appl. 69(2), 145–173 (2011)
van Leeuwaarden, J.S.H.: Queueing models for cable access networks. Ph.D. thesis, Eindhoven University of Technology (2005)
van Leeuwaarden, J.S.H.: Delay analysis for the fixed-cycle traffic light queue. Transp. Sci. 40, 189–199 (2006)
Van Mieghem, P.: The asymptotic behavior of queueing systems: large deviations theory and dominant pole approximation. Queueing Syst. Theory Appl. 23(1–4), 27–55 (1996)
Acknowledgments
This work was financially supported by The Netherlands Organization for Scientific Research (NWO) and by an ERC Starting Grant.
Author information
Authors and Affiliations
Corresponding author
Appendix: Proof of Lemma 3.1
Appendix: Proof of Lemma 3.1
We consider the zeros \(z_j\), \(j=0,1,...,s-1 \), and \(Z_k\), \(k\in {\mathbb {Z}}\), of the function \(z^s-A(z)\) in the unit disk \(|z|\le 1\) and in the annulus \(1<|z|<r\), respectively, in particular those that are relatively close to 1. These zeros are elements of the set \(S_{A,s}=\{z\in {\mathbb {C}}| |z|<r,~|z^s|=|A(z)|\}\). For \(z\in S_{A,s}\), we have that \(\ln (z^s X^{-n}(z))\) is purely imaginary. We thus consider the equation
with z near 1 and t small compared to s. Writing
we get by Taylor expansion around \(z=1\) the equation
Dividing by s and using that \(\frac{n}{s} X'(1)=1-\gamma /\sqrt{s}\) yields
i.e.,
where we have used that
Dividing in (5.31) by \(\sigma ^2/2\mu \) and completing a square, we get
Taking square roots on both sides of (5.33) and using that the leading term on the right-hand side of (5.33) has order \((1+|u|)/s\), we get
Irrespective of the ±-sign, the leading part of the right-hand side of (5.34) has order \(((1+|u|)/s)^{1/2}\) (and even \((|u|/s)^{1/2}\) in the case of the −-sign), and the O-term has order \((1+|u|)/s\) which is \(o(((1+|u|)/s)^{1/2})\) as long as \(|u|/s=o(1)\). Thus, in that regime of u, we have
where we have inserted
In the case of the minus sign in (5.35), the O-term may be replaced by O(|u| / s). Choosing \(u=2\pi j\) with \(j=0,1,...,\) and \(j=o(s)\), we get from (5.35) with the minus sign, (3.3). Choosing \(u=2\pi k\) with \(k\in {\mathbb {Z}}\) and \(k=o(s)\), we get from (5.35) with the plus sign, (3.4).
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Janssen, A.J.E.M., van Leeuwaarden, J.S.H. Dominant poles and tail asymptotics in the critical Gaussian many-sources regime. Queueing Syst 84, 211–236 (2016). https://doi.org/10.1007/s11134-016-9499-5
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11134-016-9499-5