
Abstract
Flood risk models capture a variety of processes and are associated with large uncertainties. In this paper, the uncertainties due to alternative model assumptions are analysed for various components of a probabilistic flood risk model in the study area of Vorarlberg (Austria). The effect of different model assumptions for five aspects is compared to a reference simulation. This includes: (I, II) the selection of two model thresholds controlling the generation of large sets of possible flood events; (III) the selection of a distribution function for the flood frequency analysis; (IV) the building representation and water level derivation for the exposure analysis and (V) the selection of an appropriate damage function. The analysis shows that each of the tested aspects has the potential to alter the modelling results considerably. The results range from a factor of 1.2 to 3, from the lowest to highest value, whereby the selection of the damage function has the largest effect on the overall modelling results.
Similar content being viewed by others


1 Introduction
Flood risk assessment is an essential part of risk management. Practical applications of flood risk models are, for example, cost-benefit analysis of flood mitigation measures or solvency considerations in the (re)insurance business. Various recent studies showed that results are associated with considerable uncertainties (Merz and Thieken 2009; Beven and Hall 2014; Wagenaar et al. 2016). Hence, the topic of uncertainty analysis in flood risk modelling is gaining greater attention (Beven et al. 2015). In this regard, the present work focuses on the uncertainties within a Probabilistic Flood Risk Analysis Model (PRAMo), introduced by Schneeberger (2015). The objective of the study is to evaluate and compare the uncertainties in different components of the complex model chain.
Uncertainties can be defined as the degree to which a value is unknown (IPCC 2012). It is common to distinguish between aleatoric and epistemic uncertainty, whereas aleatoric uncertainty refers to an inherent or natural variability over space and time, epistemic uncertainty is the result of incomplete knowledge about the process, system or object under study (Apel et al. 2004; Hall and Solomatine 2008; Merz and Thieken 2009; Beven et al. 2015).
Traditionally, models are validated by comparing simulated and observed data. There is, however, often little to no information to validate flood risk models (Merz and Thieken 2009; Thieken et al. 2014). Hence, many uncertainty studies focus on the description of sensitivities either for specific parts of the model chain or for overall risk model outputs. For example, the uncertainties related to inundation mapping are studied by Merwade et al. (2008) and Bales and Wagner (2009). Both studies conclude that, due to the uncertainties, the use and communication of uncertainty zones for inundation mapping are recommended. Koivumäki et al. (2010) investigated the uncertainties of hydraulic modelling, the effect on subsequent exposure analysis and damage estimation. Besides inundation modelling, they identified building representation as point or ground plan as a relevant source of uncertainty for damage modelling. Merz and Thieken (2009) showed the contribution of flood frequency analysis, inundation mapping and damage estimation to the total uncertainty using the concept of parallel modelling. They identified flood frequency analysis as the most important source of uncertainty, especially considering high return periods (RP). In contrast, De Moel and Aerts (2011) stated, that the most important source of uncertainty in their risk model results from damage estimation. By introducing Monte Carlo methods to sample the model parameters of interest, the distribution of possible model outcomes can be created empirically. This technique was used for example by Wagenaar et al. (2016) to investigate the influence of different assumptions in the damage estimation process. They showed that the associated uncertainties have a significant effect on investment decisions for flood protection measures. Another study using Monte Carlo sampling for various parameters and different model structures, including levee failures, was conducted by Apel et al. (2004). Again, the results reveal large uncertainties in the damage estimation process and in the extreme value statistics of the flood frequency analysis (Apel et al. 2004). A subsequent study highlighted the importance of their imposed transformation process, from discharge to water stages. Still, the study also confirmed the initial results with damage estimation and frequency statistics are important sources of uncertainty in the flood risk model application (Apel et al. 2008).
While different model structures and procedures are used in the studies outlined, they have in common that considerable uncertainties are identified in various parts of flood risk modelling. The aim of this study is to analyse the effect of different aspects of the Probabilistic Flood Risk Analysis Model in comparison with a reference model setting in the study area of Vorarlberg.
The paper is organised as follows: first, the study area is briefly described, to give an overview of the hydrologic and geographic conditions. Second, the basic concepts and structures of the risk model are described. Third, all model components associated with uncertainties are identified, and five specific aspects, included in the further analysis, are explained in more detail. In the fourth chapter, the results are presented and discussed. The paper ends with a short summary and conclusion of the findings.
2 Study area
The study is conducted in Vorarlberg, the westernmost Federal Province of Austria. Vorarlberg spans from the Rhine valley at Lake Constance (approx. 400 m a.s.l.) up to the high mountains with an altitude above 3300 m a.s.l. Besides the river Rhine, the main rivers of the study area are the river Ill (1280 km2), the river Dornbirnerache (230 km2) and the river Bregenzerache (830 km2). Due to the location at the northern reaches of the Alps, Vorarlberg is characterised by high precipitation amounts up to 3000 mm year−1 in the Bregenzer Wald area (Bundesministerium für Land- und Forstwirtschaft, Umwelt- und Wasserwirtschaft 2007). The runoff is characterised by strong seasonality with most floods in the summer period. Severe flood events have affected Vorarlberg in 1999, 2002, 2005 and 2013. Due to the high settlement concentration in the valley floors, they are vulnerable to flooding. The highest reported damage was in 2005, estimated at approximately €180 million covering infrastructure, industries and private property (Habersack and Krapesch 2006). Figure 1 provides an overview of the study area, the river network and the location of settlement areas.

Study area Vorarlberg
3 Model description and investigated components
In the present study, “flood risk” is defined as a combination of the probability of a flood event and its potential negative consequences (European Union 2007). The study focuses on flood exposure and direct monetary damage to residential buildings. Other direct and indirect adverse consequences of flooding such as agricultural and infrastructural damages or business interruption costs are not considered.
3.1 Flood risk model
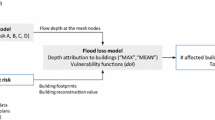
The risk model is structured in three modules: a Hazard Module, generating a set of heterogeneous flood events; an Impact Module, analysing the negative consequences; and finally a Risk Assessment Module, combining the results of the first two modules in order to evaluate the probability of flood impacts. Figure 2 shows a flowchart of the three modules, including input variables, parameters, module results and interlinking of the different components. In the present study, the model is applied for the aforementioned study area of Vorarlberg. In general, however, PRAMo is a generic concept which can be transferred to other locations under the premise of suitable input data.

Flowchart of the PRAMo model chain, including module inputs (grey) and module outputs (green) (based on Schneeberger 2015)
3.1.1 Hazard Module
The Hazard Module generates a large set of possible heterogeneous flood events based on observed discharge data at river gauges. A flood event is defined as discharge that corresponds with a return period equal to or greater than 30 years at one or multiple locations. For the event definition, the peak discharge which occurs in a time interval with a length of 3 days is used.
The event generation is realised with the multivariate conditional model (henceforth the HT model) introduced by Heffernan and Tawn (2004), which is able to reproduce the dependence structure between multiple gauging sites. The HT model consists of a marginal model and a conditional dependence model (Heffernan and Tawn 2004; Keef et al. 2013a, b). For the two parts of the mathematical model, the thresholds \(q_{{p_{GP} }}\) and \(q_{{p_{sim} }}\) have to be selected above which the marginal model and the conditional dependence model, respectively, are valid. In order to account for the special characteristics of the study area (i.e. a strong seasonality), a distinction between summer and winter seasons is made (Schneeberger 2015). The HT model generates a set of flood events in real scale (i.e. discharge in m3/s). The next step is to convert these synthetic flood events into a probability scale. For this purpose, a flood frequency analysis (FFA) is applied.
Up to this point, all steps have been executed on a point scale at the river gauges. For the subsequent risk analysis, information about the flood characteristic is needed for the entire study area. Hence, the geostatistical interpolation approach top-kriging (Skøien et al. 2006), which considers the nested structure of rivers, is applied to transfer the information on a point scale to the entire river network. The results of the Hazard Module are sets of spatially heterogeneous flood events where each set represents 1000 years of simulation.
3.1.2 Impact Module
The Impact Module derives the possible negative consequences associated with flood events. This step addresses the exposure and susceptibility analysis. Flooded areas and corresponding water levels are taken from inundation maps representing homogeneous flood scenarios of certain return periods (i.e. RP = 30, 50, 100, 200 and 300 years). These inundation maps are based on 1D hydrodynamic modelling in rural areas and full 2D modelling in urban areas (IAWG 2010). The hydrologic boundary conditions of the hydraulic calculations underlie the considerations of the project HORA (Flood risk zones in Austria). They are based on a flood frequency analysis in gauged catchments and a further regionalisation (Top-kriging) in ungauged catchments with manual adjustment to the local flood characteristics by different feedback loops with the Hydrographic Services (Merz et al. 2008). To meet the requirements of the hydrodynamic models, the regionalisation was extended to a denser river network and additionally estimated for the 50- and 300-year return periods (IAWG 2010).
The susceptibility analysis is conducted on a single object level, i.e. individual buildings. The building values are derived by calculating mean cubature values from local insurance data and transferred to the entire building stock of the study area. As the values are based on insurance data with a pay-out perspective (Jongman et al. 2012), the corresponding building stock values are predefined as replacement values and are consequently higher than depreciated values. For more details on the building stock values, see Huttenlau et al (2015).
For the estimation of direct damages to buildings, the concept of damage functions is applied. A damage function describes the relation between one or multiple damage-inflicting parameters and the relative or absolute damage to assets (Merz et al. 2010; Meyer et al. 2013). In the present model, only one-parametric (water depth) and relative damage functions are used to estimate the damage to the exposed buildings. In the present study, six different damage functions are tested (see Table 2).
Following the damage estimation, the corresponding loss for each probability of flooding is aggregated at a community level. A linear interpolation is applied between the known values of given return periods, resulting in continuous loss probability relations for each community. The linear interpolation is a simplified assumption as flood damage is likely to increase rapidly at certain (here unknown) thresholds, for example due to overtopping of flood defences. The loss probability relations serve as input for the subsequent risk analysis.
3.1.3 Risk Assessment Module
The Risk Assessment Module combines the results of the Hazard and Impact Module for further statistical evaluation. Therefore, each community has a representative point on the river network to combine the modelled return period of a generated heterogeneous flood event with the loss probability relations of the specific community. To estimate the expected damage for the event and entire study area, the losses of all communities are accumulated. In contrast to the inundation maps utilised in the Impact Module, each event is characterised by the combined probability considering the spatial dependence between different parts of the study area. The loss derivation is repeated for the entire set of flood events generated in the Hazard Module and results in a time series of damages.
The time series of damages is analysed to derive the expected annual damage (EAD). Additionally, the losses associated with certain probabilities of occurrence are calculated for the entire study (e.g. flood defence planning 100 years; solvency consideration of insurers 200 years.) (Schneeberger et al. 2015, 2017). In contrast to the methodology of risk curves (e.g. Ward et al. 2011), the losses are calculated directly from the time series of damages (here 100 × 1000 years.). This concept was for instance used in the study of Falter et al. (2015), analysing a damage series of 10,000 years.
3.2 Sources of uncertainty
In the scope of the uncertainty analysis, different assumptions are evaluated for multiple aspects of the risk model. The effect of model assumptions is presented as final results of the model chain (monetary damages). First, all aspects that are expected to influence the model output are identified, as suggested by Hall and Solomatine (2008). Both the Hazard and the Impact Module consist of multiple submodels and therefore contain many possible sources of uncertainty. In contrast, the Risk Assessment Module only encompasses the combination of the former outputs and a following statistical evaluation. Thus, no relevant source of uncertainty is identified here. Table 1 presents a list and short description of possible sources of uncertainty, while five of the listed aspects are evaluated in more detail.
All aspects can be classified as epistemic uncertainty as they fall within the definition of “incomplete knowledge”. The epistemic or knowledge uncertainty can be subdivided into their sources as model structure and parameter value uncertainty, including the boundary conditions (Loucks and Beek 2005). Similarly, Apel et al. (2008) divides the epistemic uncertainties into model, parameter and input data uncertainties. The model structure uncertainty might not only result from lack of knowledge, but could also result from imprecisions due to the simplification of the real-world processes (Loucks and Beek 2005).
The detailed analysis contains the selection of two HT Model thresholds and the choice of the distribution function for the flood frequency analysis in the Hazard Module. Other spatial interpolation methods are not considered since recent studies showed that the implemented top-kriging approach outperforms other regionalization techniques for spatial predictions on river networks (Skøien et al. 2006; Castiglioni et al. 2011; Laaha et al. 2014; Archfield et al. 2013; Vormoor et al. 2011). Concerning the Impact Module, the effect of different geometries to represent the buildings and the definition of the water depth as part of the exposure analysis are analysed. Finally, the influence of different damage functions is assessed. The inundation maps and building stock values are not calculated explicitly in the risk model and serve only as input data. Even when not considered here, several studies showed that both components are associated with uncertainties (Merwade et al. 2008; Bales and Wagner 2009; Wagenaar et al. 2016). In addition to each variation in the Hazard and Flood Impact Module, the uncertainty associated with the random process in the HT Model is reflected by the 5th and 95th percentiles of multiple model runs.
3.2.1 HT model aleatory uncertainty
In essence, the Hazard Module generates a large set of plausible synthetic flood events by application of the HT model. Each simulation run generates a certain amount of flood events representing possible flood situations within a specified time period. By repeating the simulation procedure, sets of flood events are produced, which reflects a part of the natural variability. A robust mean value is created by repeating the procedure a hundred times. The bandwidth of the 5th and 95th percentiles is used to describe the upper and lower margin of possible model outcomes. These boundaries of the HT model are calculated for all tested aspects.
3.2.2 Selection of HT model thresholds
The application of the HT model requires the selection of two different thresholds for a marginal and a conditional dependence model. When applying the marginal model, a threshold \(q_{{p_{\text{GP}} }}\) is selected above which the General Pareto distribution is used for data transformation (Keef et al. 2013a). This threshold \(q_{{p_{\text{GP}} }}\) is defined by the quantile value p GP. A second threshold \(q_{{p_{\text{sim}} }}\) defined by p sim has to be selected, above which the dependence model is valid (Heffernan and Tawn 2004). In theory, the threshold should be very high; however, the threshold \(q_{{p_{\text{sim}} }}\) limits the number of observations for the estimation of parameter of the regression model (Schneeberger 2015). By comparing simulated and observed spatial dependence measures and the comparison of simulated and observed annual maximum series, suitable ranges of threshold values are identified. The range of thresholds is determined such that the test criteria have a probability of at least 0.75 to be in accordance with observed data (cf. Schneeberger 2015). However, the thresholds may not be selected perfectly as there is no general goodness-of-fit test for the HT model available. Hence, the effect of threshold selection to the overall results of the risk model is investigated for a range of plausible thresholds of p GP (\(p_{\text{GP}} = 0.9,0.95,0.99,\) and 0.995) and p sim (\(p_{\text{sim}} = 0.9875,0.99,0.9925,\) and 0.995).
3.2.3 Flood frequency analysis
For further processing of the modelled flood peaks, the physical magnitude (m3/s) at each site has to be transferred to probability scale. This is necessary in order to link the modelled discharge of the synthetic events to a return period and a corresponding loss for each community. Therefore, a flood frequency analysis is applied at each site. However, several distribution functions can agree well with observations and still result in strongly differing extrapolation values (Merz and Thieken 2009). To evaluate the effect of different distribution functions on the estimated monetary risk, four functions are tested in the hazard model. This includes the two-parametric Gumbel (E1) and Lognormal (LN) distribution and the three-parametric Pearson 3 (P3) and Generalised Extreme Value (GEV) distribution.
3.2.4 Geometric representation and water depth derivation
Flood damage estimation is either based on object values of individual elements or on aggregated information, such as land use data, depending on the scale of investigation (e.g. Jongman et al. 2012; Cammerer et al. 2013). The building stock values in the present study are represented as individual buildings; however, their geometry can be characterised in different ways. One option is the definition of buildings as address point, representing the total value of the object. A second option is the geometric definition of the building´s ground plan. Additionally, a third category was investigated, in which the ground plan is buffered by the inundation grid resolution to ensure that inundated cells only partly within or alongside the building are considered as exposed as well.
If address points are used to define the location of objects, a distinct definition of the water level is possible. These points correspond to an unambiguous water depth, independent of the spatial resolution of inundation data. However, if the geometric representation of building ground plans is used and combined with an inundation map with finer resolution, the water depth is likely to be defined over multiple grid cells. Boettle et al. (2011) suggested the definition of water depth as the minimum, maximum or mean value of all inundated cells within the building representation. The maximum value represents the worst case scenario; the minimum value, however, would classify all buildings only partly flooded as the lowest present inundation depth and will not be considered. Figure 3 displays an example of how the choices of methods lead to different results for the flood exposure and water depth derivation at the objects.

Example of different building representations and their influence on the water level derivation as minimum, mean and maximum values of all inundated grid cells within the defined geometry, ground plan and ground plan buffered
3.2.5 Selection of damages function
Due to the lack of systematic loss data, there is no possibility to derive local stage damage functions in the study area. As a result, damage functions are transferred to conduct the loss assessment. Based on public availability, geographic location and relative definition, a set of six loss models was chosen for further investigation. The functions are summarised in Table 2.
3.3 Model setting of the reference run
The intention of defining a reference setting is to compare the individual aspects of the complex risk model chain while keeping other aspects unchanged. This enables an easier interpretation of the alternative assumptions for each analysed aspect. As there are limited objective criteria and no national standards for the study area, other model configurations could be selected as well. Hence, the following definition of a reference run is neither intended nor suited to function as a general standard; however, the selection is based on fixed and transparent criteria, as described below and reflects the author´s experiences over the past years.
For the reference model, quantile values p GP and p sim of 0.95 and 0.99, respectively, are used to defined the thresholds of the HT model (\(q_{{p_{\text{GP}} }}\) and \(q_{{p_{\text{sim}} }}\)). The selection of these non-exceedance probabilities is based on the best match of observed and simulated data, applying the test criteria described in Sect. 3.2.2 (Schneeberger 2015). The GEV distribution was selected for the flood frequency analysis of the reference run. Several researchers stated that the GEV distribution is a suitable distribution function within the geographic region (Merz and Blöschl 2005; Petrow et al. 2007). In addition, the χ 2 goodness-of-fit test is never rejected at the significance level of 95% at any station. In the reference configuration, buildings are represented by their buffered ground plans. The water level is thereby defined as the maximum depth inside the geometry. Both assumptions are the worst possible selections among the options discussed. Finally, the BUWAL damage function is used for the reference run. First, the function originates from Switzerland, with similar process and building structures. Second, BUWAL is a simple step function, which makes the results easier to interpret. Third, BUWAL belongs to the low to moderate damage models which were identified to deliver the most appropriate results in an ex-post analysis of the flood event in 2005, comparing the model results with documented insurance claims (Huttenlau et al. 2015).
4 Results and discussion
In the following, all aspects described in the previous section are compared to the reference run. Hence, the effect of the different assumptions on the overall risk estimation can be evaluated. Figure 4 shows the estimated monetary damage against the return period of the reference run configuration. The uncertainty due to the random process in the HT model is shown in the spaghetti plot (grey), which represents a hundred repetitions of the HT model. The mean value of the modelling result is illustrated in solid red and the 5th and 95th percentiles of the hundred repetitions as dashed red lines. The mean value and the percentiles are identical to the reference run (red) and shaded bandwidth (red) in Fig. 5a–e.

Damages associated with certain return periods for the reference model configuration

Estimated monetary damage versus the return period for all tested aspects with the reference setting in red. Aspects of the Hazard Module: a HT model threshold \(q_{{p_{\text{GP}} }}\); b HT model threshold \(q_{{p_{\text{sim}} }}\); c distribution function for the flood frequency analysis. Aspects of the Impact Module: d building geometry and method to derive the water level, for details of the methods see Fig. 3; e damage functions, see Table 2 for abbreviations
Figure 5 shows the estimated monetary damage against the return period for all tested combinations. Each of the analysed aspects has the potential to alter the absolute modelling results considerably. The factor from the lowest to the highest possible result is on average 1.4 and 1.3 for the HT model thresholds \(q_{{p_{\text{GP}} }}\) and \(q_{{p_{\text{sim}} }}\), 1.4 for the flood frequency distributions, 1.7 for the building geometry and water level derivation and 3.0 for the selection of different damage functions. The range of selections of the individual aspect is smaller than the uncertainty arising from 100 model repetitions, depicted as shaded areas in Fig. 5. This does not hold for the selection of the damage function. For a RP of 30 years, the range is 50 million, and for the most extreme RP of 300 years it is EUR 230 million. The effect of the selection of damage functions is more than double the effect of the random process in the HT model.
A closer look at the individual aspects of the Hazard Module reveals that both threshold definitions and the selection of a distribution function are all in a comparable order of magnitude (see Fig. 5a–c). In several studies, the selection of an appropriate flood frequency distribution function is found to be a major source of uncertainty in flood risk analysis (Apel et al. 2004, 2008; Merz and Thieken 2009). Merz and Thieken (2009) emphasised that the total uncertainty was even dominated by the flood frequency analysis for higher return periods. In contrast to these findings, the present study shows that the selection of the distribution function has no larger effects than other aspects. However, two reasons that the effects of the distribution function are less important are (I) fewer functions were considered and (II) the selection is not directly connected to the inundation extent in the present model structure.
The effects of the individual components of the Impact Module are larger than the effects of components of the Hazard Module. Focusing on the geometric representations of flood-exposed buildings, as expected, the usage of address points leads to the lowest and buffered ground plans to the highest monetary damage. Additionally, address points result in substantially lower numbers of flood-exposed buildings in comparison with ground plans (not shown here). The difference between the numbers of elements at risk between ground plans and buffered ground plans is less than 5%. However, the number drops about one third for address points. These findings are in accordance with Koivumäki et al. (2010), who showed in a post-event analysis that applying address points underestimated the number of exposed buildings and concluded that the usage of ground plans outperforms point representations in the damage estimation exercise. While the difference between building ground plans to an additional buffered ground plan is comparably low, the method to define the water level as maximum or mean value of all wet cells has a large effect on the risk estimation. For buffered ground plans, the estimated damage increases by approx. 30% if maximum water levels are used instead of mean water levels. As illustrated in Fig. 5d, the results are the lowest for point representations, which are related to the reduced number of exposed buildings for point data. Nevertheless, the effects of different building geometries and water level definitions are strongly dependent on the spatial resolution of the inundation maps. If information about the inundated areas is only available in coarse resolution, there may be no significant differences between the model selections. However, in times of fast-improving spatial resolution of digital elevation models and advanced computational resources, inundation maps with higher spatial resolution are more widely available.
Finally, the by far largest bandwidths of all investigated model components are shown for several damage functions. Thus, the selection of an appropriate damage model has the comparably highest effect on the final model results. This is in accordance with other studies, which also point out that especially the damage functions are a major source of uncertainty in flood risk modelling (Wagenaar et al. 2016; Apel et al. 2008; Achleitner et al. 2016; De Moel and Aerts 2011). The findings of De Moel and Aerts (2011) show an even larger range with a factor of four in damage modelling. A possible way to cope with this large uncertainty is to further reduce the ensemble of damage functions, as suggested by Cammerer et al. (2013). However, without a database to derive site-specific damage functions in order to avoid the transfer of damage functions and reliable validation data, it is not possible to reduce the ensemble based on objective criteria. Hence, the results of different damage functions have to be considered as possible model outputs. By the communication of intermediate results, such as the number of exposed buildings, the modelling results at least become more transparent.
5 Conclusion
In this paper, the uncertainties due to alternative model assumptions within a probabilistic flood risk model were analysed. In total, five model aspects were investigated. Namely, the selection of two HT model thresholds, the selection of the distribution function for the flood frequency analysis, different geometries to represent the buildings for the exposure analysis as well as the method to define the water level at the geometries and finally the selection of the damage function. Alternative model selections were compared to a reference simulation. Furthermore, the uncertainty associated with the random process by the generation of a large set of flood events is taken into account, as the 5th and 95th percentiles for a hundred repetitions of each configuration.
The main findings are (I) all analysed components are sensitive to the overall damage estimation. (II) The results range from a factor of 1.2–3, from the lowest to the highest value. (III) Different assumptions in the damages estimation process (i.e. selection of a damage model) are associated with the highest uncertainties compared to the other options investigated.
The study presented focuses only on the effect of varied model assumptions; nonetheless, it demonstrates that the complex structure of the flood risk model is associated with large uncertainties. Furthermore, it can be assumed that the input data, for example the discharge time series, inundation maps or building values, is uncertain as well. The results identify the most relevant components, reduce the over-confidence of a single best guess estimate and show the range of possible alternative model outcomes. The findings support the need for robust decision making in flood risk management to cover a large range of possible alternative model outcomes.
References
Achleitner S, Huttenlau M, Winter B, Reiss J, Plörer M, Hofer M (2016) Temporal development of flood risk considering settlement dynamics and local flood protection measures on catchment scale: an Austrian case study. Int J River Basin Manag. https://doi.org/10.1080/15715124.2016.1167061
Apel H, Thieken AH, Merz B, Blöschl G (2004) Flood risk assessment and associated uncertainty. Nat Hazards Earth Syst Sci 4(2):295–308. https://doi.org/10.5194/nhess-4-295-2004
Apel H, Merz B, Thieken A (2008) Quantification of uncertainties in flood risk assesment. Int J River Basin Manag 2(6):149–162
Archfield SA, Pugliese A, Castellarin A, Skøien JO, Kiang JE (2013) Topological and canonical kriging for design flood prediction in ungauged catchments: an improvement over a traditional regional regression approach? Hydrol Earth Syst Sci 17(4):1575–1588. https://doi.org/10.5194/hess-17-1575-2013
Bales JD, Wagner CR (2009) Sources of uncertainty in flood inundation maps. J Flood Risk Manag 2(2):139–147. https://doi.org/10.1111/j.1753-318X.2009.01029.x
Beven KJ, Hall J (eds) (2014) Applied uncertainty analysis for flood risk management. Imperial College Press, London
Beven KJ, Aspinall WP, Bates PD, Borgomeo E, Goda K, Hall JW, Page T, Phillips JC, Rougier JT, Simpson M, Stephenson DB, Smith PJ, Wagener T, Watson M (2015) Epistemic uncertainties and natural hazard risk assessment—part 1: a review of the issues. Nat Hazards Earth Syst Sci Discuss 3(12):7333–7377. https://doi.org/10.5194/nhessd-3-7333-2015
Boettle M, Kropp JP, Reiber L, Roithmeier O, Rybski D, Walther C (2011) About the influence of elevation model quality and small-scale damage functions on flood damage estimation. Nat Hazards Earth Syst Sci 11(12):3327–3334. https://doi.org/10.5194/nhess-11-3327-2011
Borter P (1999) Umwelt-Materialien Nr.107/II: Naturgefahren. Bundesamt für Umwelt, Waldund Landschaft, Bern
Büchele B, Kreibich H, Kron A, Thieken A, Ihringer J, Oberle P, Merz B, Nestmann F (2006) Flood-risk mapping: contributions towards an enhanced assessment of extreme events and associated risks. Nat Hazards Earth Syst Sci 6(4):485–503. https://doi.org/10.5194/nhess-6-485-2006
Bundesministerium für Land- und Forstwirtschaft, Umwelt- und Wasserwirtschaft (2007) Hydrologischer Atlas Österreich
Cammerer H, Thieken AH, Lammel J (2013) Adaptability and transferability of flood loss functions in residential areas. Nat Hazards Earth Syst Sci 13(11):3063–3081. https://doi.org/10.5194/nhess-13-3063-2013
Castiglioni S, Castellarin A, Montanari A, Skøien JO, Laaha G, Blöschl G (2011) Smooth regional estimation of low-flow indices: physiographical space based interpolation and top-kriging. Hydrol Earth Syst Sci 15(3):715–727. https://doi.org/10.5194/hess-15-715-2011
de Moel H, Aerts JCJH (2011) Effect of uncertainty in land use, damage models and inundation depth on flood damage estimates. Nat Hazards 58(1):407–425. https://doi.org/10.1007/s11069-010-9675-6
European Union (2007) European Union on the assessment and management of flood risks: Directive 2007/60/EC of the European Parliament and the Council
Falter D, Schröter K, Dung NV, Vorogushyn S, Kreibich H, Hundecha Y, Apel H, Merz B (2015) Spatially coherent flood risk assessment based on long-term continuous simulation with a coupled model chain. J Hydrol 524:182–193. https://doi.org/10.1016/j.jhydrol.2015.02.021
Habersack H, Krapesch G (2006) Hochwasser 2005 - Ereignisdokumentation: der Bundeswasserbauverwaltung, des Forsttechnischen Dienstes für Wildbach- und Lawinenverbauung und des Hydrographischen Dienstes
Hall J, Solomatine D (2008) A framework for uncertainty analysis in flood risk management decisions. Int J River Basin Manag 2(6):85–98
Heffernan JE, Tawn JA (2004) A conditional approach for multivariate extreme values (with discussion). J R Stat Soc B 66(3):497–546. https://doi.org/10.1111/j.1467-9868.2004.02050.x
Huttenlau M, Schneeberger K, Winter B, Reiss J, Stötter J (2015) Analysis of loss probability relation on community level: a contribution to a comprehensive flood risk assessment. In: Sener SM, Brebbia CA (eds) Disaster management and human health risk IV, Istanbul, Turkey, 20–22 May 2015, vol 150. WIT Transactions on the Built Environment, pp 171–182
IAWG (2010) HORA/Vorarlberg: Hydraulische Neuberechnung für Vorarlberg (unpublished)
IKSE (2003) Aktionsplan Hochwasserschutz Elbe
IKSR (2001) Atlas der Überschwemmungsgefährdung und möglichen Schäden bei Extremhochwasser am Rhein, Koblenz
IPCC (2012) Glossary of terms. In: IPCC (ed) Managing the risks of extreme events and disasters to advance climate change adaption. Special report of the intergovernmental panel on climate change. Cambridge Univ. Press, Cambridgee
Jongman B, Kreibich H, Apel H, Barredo JI, Bates PD, Feyen L, Gericke A, Neal J, Aerts JCJH, Ward PJ (2012) Comparative flood damage model assessment: towards a European approach. Nat Hazards Earth Syst Sci 12(12):3733–3752. https://doi.org/10.5194/nhess-12-3733-2012
Keef C, Papastathopoulos I, Tawn JA (2013a) Estimation of the conditional distribution of a multivariate variable given that one of its components is large: additional constraints for the Heffernan and Tawn model. J Multivar Anal 115:396–404. https://doi.org/10.1016/j.jmva.2012.10.012
Keef C, Tawn JA, Lamb R (2013b) Estimating the probability of widespread flood events. Environmetrics 24(1):13–21. https://doi.org/10.1002/env.2190
Klijn F, Baan P, Bruijn K de, Kwadijk J (2007) Overstromingsrisico’s in Nederland in een veranderend klimaat
Koivumäki L, Alho P, Lotsari E, Käyhkö J, Saari A, Hyyppä H (2010) Uncertainties in flood risk mapping: a case study on estimating building damages for a river flood in Finland. J Flood Risk Manag 3(2):166–183. https://doi.org/10.1111/j.1753-318X.2010.01064.x
Laaha G, Skøien JO, Blöschl G (2014) Spatial prediction on river networks: comparison of top-kriging with regional regression. Hydrol Process 28(2):315–324. https://doi.org/10.1002/hyp.9578
Loucks DP, Van Beek E (2005) Water resources systems planning and management: an introduction to methods, models and applications. Unesco, Paris
Merwade V, Olivera F, Arabi M, Edleman S (2008) Uncertainty in flood inundation mapping: current issues and future directions. J Hydrol Eng 13(7):608–620. https://doi.org/10.1061/(ASCE)1084-0699(2008)13:7(608)
Merz R, Blöschl G (2005) Flood frequency regionalisation—spatial proximity vs. catchment attributes. J Hydrol 302(1–4):283–306. https://doi.org/10.1016/j.jhydrol.2004.07.018
Merz B, Thieken AH (2009) Flood risk curves and uncertainty bounds. Nat Hazards 51(3):437–458. https://doi.org/10.1007/s11069-009-9452-6
Merz R, Blöschl G, Humer G (2008) National flood discharge mapping in Austria. Nat Hazards 46(1):53–72. https://doi.org/10.1007/s11069-007-9181-7
Merz B, Kreibich H, Schwarze R, Thieken A (2010) Assessment of economic flood damage. Nat Hazards Earth Syst Sci 10(8):1697–1724. https://doi.org/10.5194/nhess-10-1697-2010
Meyer V, Becker N, Markantonis V, Schwarze R, van den Bergh JCJM, Bouwer LM, Bubeck P, Ciavola P, Genovese E, Green C, Hallegatte S, Kreibich H, Lequeux Q, Logar I, Papyrakis E, Pfurtscheller C, Poussin J, Przyluski V, Thieken AH, Viavattene C (2013) Review article: assessing the costs of natural hazards—state of the art and knowledge gaps. Nat Hazards Earth Syst Sci 13(5):1351–1373. https://doi.org/10.5194/nhess-13-1351-2013
MURL (2000) Hochwasserschadenspotentiale am Rhein in Nordrhein-Westfalen
Petrow T, Merz B, Lindenschmidt K-E, Thieken AH (2007) Aspects of seasonality and flood generating circulation patterns in a mountainous catchment in south-eastern Germany. Hydrol Earth Syst Sci 11(4):1455–1468. https://doi.org/10.5194/hess-11-1455-2007
Schneeberger K (2015) Flood risk analysis in a meso-scale mountain catchment: development and application of a probabilistic analysis framework. Ph.D. thesis. URL: http://diglib.uibk.ac.at/ulbtirolhs/download/pdf/813196
Schneeberger K, Huttenlau M, Stötter J (2015) Probabilistisches Modell zur Analyse des räumlich differenzierten Hochwasserrisikos. HyWa 59(5):271–277. https://doi.org/10.5675/HyWa_2015,5_8
Schneeberger K, Huttenlau M, Winter B, Steinberger T, Achleitner S, Stötter J (2017) A probabilistic framework for risk analysis of widespread flood events: a proof-of-concept study. Risk Anal. https://doi.org/10.1111/risa.12863
Skøien JO, Merz R, Blöschl G (2006) Top-kriging—geostatistics on stream networks. Hydrol Earth Syst Sci 10:277–287
Thieken AH, Olschweski A, Kreibich H, Kobsch S, Merz B (2008) Development and evaluation of FLEMOps—a new Flood Loss Estimation MOdel for the private sector. In: Proverbs DG, Brebbia CA, Penning-Rowsell EC (eds) Flood recovery, innovation and response. WIT, Southampton, pp 315–324
Thieken AH, Apel H, Merz B (2014) Assessing the probability of large-scale flood loss events: a case study for the river Rhine, Germany. J Flood Risk Manag. https://doi.org/10.1111/jfr3.12091
Vormoor K, Skaugen T, Langsholt E, Diekkrüger B, Skøien JO (2011) Geostatistical regionalization of daily runoff forecasts in Norway. Int J River Basin Manag 9(1):3–15. https://doi.org/10.1080/15715124.2010.543905
Wagenaar DJ, de Bruijn KM, Bouwer LM, de Moel H (2016) Uncertainty in flood damage estimates and its potential effect on investment decisions. Nat Hazards Earth Syst Sci 16(1):1–14. https://doi.org/10.5194/nhessd-3-607-2015
Ward PJ, de Moel H, Aerts JCJH (2011) How are flood risk estimates affected by the choice of return-periods? Nat Hazards Earth Syst Sci 11(12):3181–3195. https://doi.org/10.5194/nhess-11-3181-2011
Acknowledgements
Open access funding provided by University of Innsbruck and Medical University of Innsbruck. This work results from the research project InsuRE II, funded by the Austrian Research Promotion Agency (FFG), within the scope of the programme COMET, co-funded by the Vorarlberger Landes-Versicherung VaG and the project HiFlow-CMA (KR15AC8K12522) funded by the Austrian Climate and Energy Fund (ACRP 8th call). We would like to thank all the institutions that provided data, particularly the Vorarlberger Landes-Versicherung VaG and the Hydrographic Service of Vorarlberg.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Winter, B., Schneeberger, K., Huttenlau, M. et al. Sources of uncertainty in a probabilistic flood risk model. Nat Hazards 91, 431–446 (2018). https://doi.org/10.1007/s11069-017-3135-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-017-3135-5