
Abstract
Australia has a low to moderate seismicity by world standards. However, the seismic risk is significant due to the legacy of older buildings constructed prior to the national implementation of an earthquake building standard in Australia. The 1989 Newcastle and the 2010 Kalgoorlie earthquakes are the most recent Australian earthquakes to cause significant damage to unreinforced masonry (URM) and light timber frame structures and have provided the best opportunities to examine the earthquake vulnerability of these building types. This paper describes the two above-mentioned building types with a differentiation of older legacy buildings constructed prior to 1945 to the relatively newer ones constructed after 1945. Furthermore, the paper presents method to utilise the large damage and loss-related data (14,000 insurance claims in Newcastle and 400 surveyed buildings in Kalgoorlie) collected from these events to develop empirical vulnerability functions. The method adopted here followed the GEM empirical vulnerability assessment guidelines which involve preparing a loss database, selecting an appropriate intensity measure, selecting and applying a suitable statistical approach to develop vulnerability functions and the identification of optimum functions. The adopted method uses a rigorous statistical approach to quantify uncertainty in vulnerability functions and provides an optimum solution based on goodness-of-fit tests. The analysis shows that the URM structures built before 1945 are the most vulnerable to earthquake with post-1945 URM structures being the next most vulnerable. Timber structures appear to be the least vulnerable, with little difference observed in the vulnerability of timber buildings built before or after 1945. Moreover, the older structures (both URM and timber) exhibit more scatter in results reflecting greater variation in building vulnerability and performance during earthquakes. The analysis also highlights the importance of collecting high-quality damage and loss data which is not only a fundamental requirement for developing empirical vulnerability functions, but is also useful in validating analytically derived vulnerability functions. The vulnerability functions developed herein are the first publically available functions for Australian URM and timber structures. They can be used for seismic risk assessment and to focus the development of retrofit strategies to reduce the existing earthquake risk.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In seismic risk assessments, the vulnerability of buildings provides a relationship between the loss caused by earthquakes and a measure of the ground motion intensity. Loss is generally expressed as a Damage Index (DI) which is a ratio of repair to replacement cost for a building population of a given type. The ground motion intensity measure is a measure of ground shaking severity at a site where buildings are located (Rossetto et al. 2014). Ground motion intensity is generally represented by peak ground acceleration, spectral displacement or based on macroseismic intensity scales such as the Modified Mercalli Intensity Scale (Wood and Neumann 1931), European Macroseismic Scale (Grünthal 1998), and others.
The vulnerability of a building class can be assessed directly by developing vulnerability curves, i.e. continuous ground motion intensity-to-loss functions for the studied building class, either empirically by post-earthquake loss and ground motion intensity data or by using expert elicitation.
With regard to the empirical vulnerability assessment, loss can be expressed in the form of repair and replacement costs for damaged buildings or insurance claims and the policy cover. The empirical vulnerability curves are considered to be the best option as they are based on real data (Jaiswal et al. 2013). However, there are also significant uncertainties in this approach which are associated with data quality, and estimation of ground-shaking intensity (Rossetto et al. 2014). Further, this option is necessarily restricted to building types for which adequate loss data are available (Edwards et al. 2004).
The expert judgment-based approach is generally utilised in a workshop environment where a group of experts build a consensus on building vulnerability based on their past experience. This approach was first introduced in ATC-13 (ATC 1985) in which expert earthquake engineers were asked to provide their judgment on the building vulnerability found in California along with their confidence level for selected building types. More recently, Cooke’s (1991) elicitation process has been adopted in the 2015 UN global risk assessment report (UNISDR 2015) for which vulnerability functions were developed for the Asia–Pacific region (Maqsood et al. 2014). In general, this approach is associated with significant uncertainties arising from the selection of experts and their experience and also from the weighting schemas used to combine the judgments from various experts. Nevertheless, this approach remains valid in the absence of statistically significant post-earthquake data and analytical studies (Jaiswal et al. 2013).
Vulnerability curves for a building class can also be obtained indirectly by coupling the fragility of the studies class (i.e. ground motion intensity-to-damage function) with an appropriate damage-to-loss function. In this case, the fragility of a building class can be assessed analytically, empirically, using expert judgement or a combination of at least two of the aforementioned approaches. The analytical approach results in the construction of fragility curves, which express the probability that the damage sustained by a building for a given intensity level will reach or exceed a given state. This approach utilises software applications to analyse building response to earthquakes by using representative building models, a characterisation of seismic hazard and the selection of nonlinear analysis type, damage model, and damage threshold criteria (Calvi et al. 2006). The reliability of the analytical approach is significantly affected by the uncertainties associated with the various input parameters mentioned above. However, the models developed through the analytical approach are not considered to be region-specific but can be applied globally if sufficient sensitivity analysis and calibration is carried out (D’Ayala and Meslem 2012). With regard to the empirical fragility assessment, post-earthquake damage data have been used for the construction of fragility curves (Calvi et al. 2006; Rossetto et al. 2013) or damage probability matrices, which express in a discrete form the probability of a building sustaining a given damage state for a given ground motion intensity level (Whitman et al. 1973; Gulkan et al. 1992; Giovinazzi and Lagomarsino 2004) and vulnerability/fragility curves (Rossetto and Elnashai 2003; Rota et al. 2008). With regard to expert elicitation, to within a Global Earthquake Model Foundation project (GEM), Cooke’s (1991) elicitation process was applied in soliciting expert judgment on collapse fragility for selected building types (Jaiswal et al. 2014).
Australia has a relatively low seismicity and has not experienced frequent damaging earthquakes (Dhu and Jones 2002). Therefore, there has been little data available to assess the seismic vulnerability of the Australian building stock, and hence, only a few Australian studies have been conducted in the past. Some of the studies conducted after the Newcastle earthquake are Walker (1991), Page (1991), Blackie (1991), and Gohil et al. (1991). More recently, the Canterbury earthquake sequence from 2010 to 2012 in New Zealand provided opportunities to document building performance and assess factors which affect building vulnerability. As the building typologies and construction practices in New Zealand have similarities to the ones in Australia, the lessons learnt during these events are mostly applicable in Australia (Griffith et al. 2013; Turner et al. 2012; Griffith et al. 2010; Russell and Ingham 2008). Several studies have been conducted after these events which record building performance and failure mechanisms for typical URM and retrofitted structures (Cattari et al. 2015; Dizhur et al. 2010, 2015; Moon et al. 2012, 2014 Ingham et al. 2012; Turner et al. 2012; Griffith et al. 2010). A few studies also researched the performance of timber frame structures during the Canterbury earthquakes (Dizhur et al. 2013; Ingham et al. 2011). All these above-mentioned studies primarily focused on documenting the observed damage, the factors contributing to the damage and the building performance during the earthquakes. However, they did not aim to develop vulnerability curves for use in seismic risk assessment. Moreover, there is a national programme in New Zealand to upgrade older earthquake-prone structures to achieve a greater compliance to the current building code (Russell and Ingham 2010). This has significantly reduced the damage to retrofitted buildings during the Canterbury earthquakes (Ingham et al. 2012). This type of initiative has not been taken in Australia despite having a greater likelihood of damage if an earthquake similar to the 2011 Christchurch main event struck in Adelaide (Griffith et al. 2013).
One effort to develop vulnerability curves for buildings in Australia was carried out by Edwards et al. 2004 where a limited data set was used. Later, a study by Lumantarna et al. 2006 was conducted on URM wall specimens to develop fragility curves for URM based on experiments. In the light of low seismicity and the scarcity of building damage data, this study aims to utilise the best available information in Australia which has been collected during the last two major earthquakes (1989 Newcastle earthquake and 2010 Kalgoorlie).
This study uses a significantly large loss database (14,000 insurance claims in Newcastle as a result of 1989 earthquake and 400 surveyed buildings in Kalgoorlie following the 2010 earthquake) and follows the GEM empirical vulnerability assessment guidelines developed by Rossetto et al. 2014 within a Global Earthquake Model Foundation project (GEM 2015) to develop empirical vulnerability functions for URM and timber frame structures. Further, the two building classes are subdivided into two age categories, i.e. pre- and post-1945, to distinguish the vulnerability of the older legacy building stock to relatively newer buildings. The steps involved in developing the vulnerability functions are as follows: preparing a loss database, selecting an appropriate intensity measure, selecting and applying a suitable statistical approach to develop vulnerability curves, and identifying the optimum curves based on goodness-of-fit tests. The developed curves are the first publically available curves based on Australian building data. These curves can be applied in seismic risk assessment studies in Australia which involve URM and timber structures. The calculated risk can inform appropriate mitigation strategies development.
2 Definition of loss and intensity measure
Australia’s low seismicity is due to its geographical location towards the centre of the Indo-Australian Tectonic Plate. Australian earthquakes are termed as intraplate because of their distance from active tectonic plate boundaries. Australian seismicity was considered to be small enough to be largely ignored in building design prior to the 1989 Newcastle earthquake due to limited experience with major damaging events. However, the Newcastle earthquake prompted a re-examination of earthquake hazard in the region and its significance for infrastructure design (Dhu and Jones 2002). Table 1 presents a list of major earthquakes from 1950 to 2010 which resulted in building damage, with the Newcastle and Kalgoorlie events causing the most earthquake-related loss in Australia to date. More details of earthquake history in Australia can be found in Dhu and Jones (2002).
2.1 Newcastle earthquake
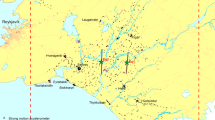
On 28 December 1989, a magnitude M L = 5.6 earthquake occurred in Newcastle which caused extensive damage and the loss of 13 lives (Dhu and Jones 2002). Due to a lack of strong motion recordings, the seismic intensity available for this event is expressed in terms of the MMI scale. Rynn et al. (1992) produced a local intensity map for the Newcastle and Lake Macquarie area with MMI ranging from VI to VIII. For this study, each suburb in the study area is assigned an MMI value from the intensity map prepared by Rynn et al. 1992. An averaged intensity is assigned where a suburb has two or more isoseismal contours according to the intensity map and number of claims within the suburb. Figure 1 shows the MMI values for each suburb within the study area.

Study area and intensity map of the 1989 Newcastle earthquake
Insurance claims settled by the Insurance Australia Group (IAG) were obtained from the Newcastle City Council to estimate the cost of damage to buildings due to this seismic event. There are approximately 14,000 insurance claims in total for building damage including contents. Each claim includes the suburb, the value insured, the payout and whether the claim concerns a brick building, a timber building or contents. However, for this study, the claims for contents are excluded with a focus on building loss only to derive vulnerability functions for the building structure.
For the study region, the insurance data include total building claims of approximately $86 million (1989 US dollars) and a total insured value for buildings of $8981 million (1989 US dollars). However, these data represent an incomplete sample of building loss as it does not include the damaged buildings for which claims were made but to other insurers. Furthermore, there is uncertainty regarding the percentage of buildings in the study region which were insured by IAG but did not claim, as well as the level of underinsurance and the deductible (excess) applied to each claim.
To address these issues and make optimal use of the loss database, the authors consulted the IAG. The consultation involved the estimation of the claim rates for URM and timber structures for each intensity level as well as the evaluation of the underinsurance factor and the typical deductible value. Demand surge (or post-event inflation), which could have distorted the claims, is believed to have been minor given that the 1989 Newcastle Earthquake occurred at a time of softening demand in the building industry. For this reason, the demand surge is neglected in the analysis.
It should be noted that the insurance claim data do not provide the street addresses for each claim. Thus, the claims are aggregated at the suburb level (114 suburbs). Only the suburbs having 20 or more claims are included in the further research. By using the outcomes of an exposure survey of more than 6000 properties conducted by Geoscience Australia in Newcastle in 1999, an indicative age (pre-1945 and post-1945) is attributed to each suburb to differentiate the older building stock from the relatively newer one. The year 1945 was not a pivotal year in building regulation or enforcement but is chosen as a demarcation line between the two vintages. The older building stock (pre-1945) is considered to have deteriorated more with time (e.g. corrosion of ties and degradation of mortar) and been constructed with poorer building practices with limited building controls to monitor the construction quality. The post-1945 building stock is relatively newer built with better construction practices, materials, and quality control.
For each suburb, the claims are subsampled based on the construction material (i.e. brick or timber) and age category (i.e. pre-1945 and post-1945). The number of buildings and total cover in the suburb is then expanded to a notional portfolio by using an agreed claim rate for each of the four categories and intensity levels. Then, adjustments are made for underinsurance and deductibles. In the final step, the DI is calculated as the ratio of adjusted claim to adjusted cover for the building type in each suburb. Figure 2 presents the loss distribution due to the 1989 Newcastle earthquake for the four building categories in terms of DI for each suburb within the study area.

Loss distribution in the 1989 Newcastle earthquake
2.2 Kalgoorie earthquake
On the 20 April 2010, a magnitude M L = 5.0 earthquake shook Kalgoorlie-Boulder and neighbouring areas in western Australia. The resultant ground motion was found to vary markedly across the town due to the shallow focus of the event (Edwards et al. 2010). Figure 3 shows the locations of surveyed building and the MMI values within the study area which were derived from interviews with residents. The estimated MMI in Kalgoorlie and Boulder were V and VI, respectively.

Location and intensity map of the 2010 Kalgoorlie earthquake
Geoscience Australia conducted an initial reconnaissance and captured street-view imagery of 12,000 buildings within Kalgoorlie by using a vehicle-mounted camera system. The subsequent foot survey collected detailed information from nearly 400 URM structures in Kalgoorlie and Boulder. The survey template consisted of 290 data fields to characterise the surveyed buildings and the severity and extent of earthquake damage. The survey included parameters such as address, building usage, built year, wall material, roof material, number of storeys, level, and type of damage. The shaking caused widespread damage to pre-World War I unreinforced masonry buildings. More modern masonry buildings also experienced some damage in the vicinity of Boulder.
In Kalgoorlie, damage to brick veneer structure was observed to be minor. Timber clad framed structures were not surveyed, but anecdotal discussions with owners indicated that no discernible damage was sustained by this type of structure other than to masonry components such as chimneys (Edwards et al. 2010).
The DI for each surveyed building is calculated by firstly recording damage to different building elements and assigning a damage state in terms of none, slight, moderate, extensive, and complete to match the HAZUS damage states (FEMA 2003). Secondly, a percentage damage is assigned to each element, and lastly, the percentage loss for each building is determined as the sum over all building elements: (% of building cost contributed by the element) × (% damage) × (% of element so damaged). The Kalgoorlie data set provides estimate of average DI for older URM (pre-1945) at two macroseismic intensities (MMI V and MMI VI) and for post-1945 URM at a single intensity (MMI VI).
3 Building classes
The buildings in the database are classified according to their primary structural system (URM and timber frame) and the year of construction (pre- and post-1945). A brief description of the four building classes and their structural performance during the two events are provided below.
3.1 Unreinforced masonry structures
URM structures can be found in all parts of Australia. This type of structure was the most common building type in Newcastle until the 1960s after which its usage declined sharply in Newcastle and the rest of eastern Australia (Dhu and Jones 2002). However, it is still used as the primary residential construction form in western parts of the country. URM structures are typically one to three storeys high and used for a wide range of building purposes including residential, commercial, government, and administration (Walker 1991). Figure 4 presents photographs of a typical old and newer URM structure.

Example of unreinforced masonry (URM) structures. a An example of pre-1945 brick commercial building. b An example of post-1945 brick residential building
URM structures can perform poorly during earthquakes if not well designed and constructed according to good building standards (Maqsood and Schwarz 2008; Russell and Ingham 2008). During the Newcastle and Kalgoorlie earthquakes, older masonry (pre1945) performed poorly and most of the damage (structural and non-structural) occurred in this type of structure. The most common factors which contributed to damage were identified to be bad quality of workmanship, lack of supervision, use of unsuitable materials, general building deterioration, poor building layout, excessive diaphragm deflection, poor design, and poor detailing of components (Page 1991; Blackie 1991; Page 2002). Another common deficiency in this type of structure was the lack of effective ties between the two leaves of double-brick cavity wall construction (Page 1991; Pedersen 1991; Gohil et al. 1991; Melchers 1990). This deficiency may be a result of corrosion or simply the lack of or incorrect placement of ties (Dhu and Jones 2002). Poorly graded sand was commonly used in brick mortar, resulting in a harsh mix requiring plasticisers to improve its workability. The excessive use of these additives results in low bond strength of mortar which contributes to structural weakness (Page 1991; Pedersen 1991). These deficiencies commonly manifest themselves in the failure of parapets, gable roof ends, corners, chimneys, and the out-of-plane failure of walls (Edwards et al. 2010; Page 1991). Similar damage mechanism and failure modes have also been observed in New Zealand for older URM structures during the Canterbury earthquakes (Moon et al. 2014; Senaldi et al. 2014; Ingham et al. 2011; Dizhur et al. 2010).
Compared to older buildings, better performance has been observed in newer construction (post-1945). Damage to these buildings during both seismic events was considered to be mostly non-structural. Internal damage in the form of minor wall cracking and cornice damage associated with relative movement between the roof and the internal wall was observed (Edwards et al. 2010). This demonstrates that URM buildings are capable of resisting a moderate level of earthquake shaking (Walker 1991). Table 2 provides an overview of the characteristics of pre- and post-1945 URM structures.
3.2 Timber frame structures
In Australia, timber frame housing is typically clad with brick veneer, timber, and sometimes fibreboard cladding (Dhu and Jones 2002). Light timber frame buildings in northern Australia are supported on both short (low-set) and tall (high-set) piers. The latter is often poorly braced and can exhibit a soft storey failure mechanism during ground shaking. Brick veneer clad buildings, which have a light timber frame as the load-bearing system, can easily be confused with unreinforced masonry buildings. These are more common for residential construction since the 1960s in eastern and southern Australia though URM construction is still common in western Australia. Veneers are non-structural elements that rely on wall ties to support timber frame for its out-of-plane stability. Although these are non-load-bearing elements, their seismic performance is important to consider due to its widespread use and high cost of repair (Page 2002). Figure 5 presents photographs of typical old and newer timber residential structure.

Examples of timber structure. a An example of pre-1945 timber frame building. b An example of post-1945 timber frame building (brick veneer)
Timber frame buildings have traditionally performed well in earthquakes, although non-structural damage has widely been observed. Brick veneer cladding, chimneys, plasterboard linings, and cornices are commonly damaged by earthquake shaking. Serious structural damage can also occur in the foundations, particularly where brick pier or soft storey-type foundations are used or where there is a lack of continuity in the structural system (Dhu and Jones 2002).
Timber frame buildings suffered non-structural damage during the 1989 Newcastle earthquake. However, little difference was noted in the severity of damage for timber structures of different construction age due to the inherent resilience of this form of construction to earthquake. The improvements which have been made recently relate to the performance of wall ties and reducing the mass of clay brick by introducing hollow cores and reducing the size of brick (Dizhur et al. 2013). The only factors observed to contribute to damage in older timber structures in Newcastle were corrosion of fasteners and termite problems. Although the Kalgoorlie survey did not focus on timber frame buildings, no significant seismic damage was observed as these buildings resisted the moderate level of earthquake shaking well (Edwards et al. 2010).
Table 3 provides a description of light frame timber structure with an overview of the typical characteristics of pre- and post-1945 structures.
4 Direct vulnerability assessment methodology
After preparing the loss database, the framework of the direct empirical vulnerability assessment consists of four steps (see Rossetto et al. 2014), depicted in Fig. 6. Firstly, a statistical model is developed based on the exploratory analysis. Then, the model is fitted to the loss data, its goodness of fit is assessed, and finally, for the best-fitted model, the 90 % prediction intervals are constructed by bootstrap analysis. The proposed procedure is based on the assumptions that the loss data are of high quality, and the measurement error of the explanatory variables (i.e. the intensity measure levels, construction material, and year of construction) is negligible. Such assumptions are common in the vulnerability literature.

Direct vulnerability assessment framework (Rossetto et al. 2014)
4.1 Exploratory analysis
A single database is produced by merging the two data sets (i.e. the 1989 Newcastle and the 2010 Kalgoorlie database). Inherent in this is the assumption is that the data in the 1989 Newcastle database would be reproduced if the sampling technique used to collect the 2010 Kalgoorlie data is adopted. This is a common assumption in studies focused on empirical fragility assessment using multiple databases (Rossetto and Elnashai 2003; Rota et al. 2008). The single database included a total of 109 data points, which included information for four variables, namely loss, intensity measure, construction material, and year of construction, summarised in Table 4.
This study aims to construct a statistical model, which best fits the available data. Such a model should be able to capture the relationships among the four variables. (What is the relationship between one of the four aforementioned variables against the others?) Figure 7 shows a matrix of plots of one variable against the other three, aiming to assist in the construction of a statistical model which fits well the available database. It can be noted that most data points are concentrated at MMI VII.

Matrix of plots for the four variables, namely loss, IM, material, and year
4.2 Selection of statistical model
In general, a statistical model consists of a random and a systematic component. The random component defines the probability distribution of the response variable (i.e. a loss measure). Then, the parameters of that probability distribution are linked to a systematic component which is typically a function of explanatory variables (e.g. intensity measure, construction material). In the framework of direct empirical vulnerability assessment, the systematic component is used to control the relationship of the vulnerability curve to the explanatory variables. This curve is a continuous function which relates the mean loss measure with the intensity measure, and in this study, its shape is also influenced by two additional explanatory variables, i.e. the construction material and the year of construction.
4.2.1 Selection of random component
The identification of suitable random components depends on the properties of the response variable. In this study, economic loss, L, is expressed in terms of DI. This loss measure is a continuous variable that is bounded in the unit interval (0, 1), and given the remarks in the exploratory analysis, for the purposes of this work the loss is assumed to follow a beta distribution \((L\sim\beta (\mu ,\varphi ))\). In order to link the loss with given observed values of explanatory variables, the beta distribution of the loss is first parameterised in terms of its mean μ and its precision φ (Ferrari and Cribari-Neto 2004), i.e. it is assumed that the probability density function, expected value, and variance of L given μ and φ are:
For fixed μ, it can be noted that the larger the value of the precision φ is, the smaller is the variance of loss. Then, a beta regression model links μ and possibly φ with a systematic component that is a function of a vector of explanatory variables. The explanatory variables that are available for the current analysis are the intensity measure, IM; the construction material, M; and the year of construction, Y.
Then, for N loss observations, \(l_{1} , \ldots , l_{n}\), and corresponding vectors \(\varvec{x}_{1} , \ldots ,\varvec{x}_{n}\) of explanatory variables, we assume that
Equation (2) provides a model which allows the dispersion parameter to vary with the observations, which may be helpful given the observations in the exploratory analysis regarding the variability in the scatter of the loss given the explanatory variables.
4.2.2 Definition of systematic component for the mean
The systematic component for the mean is defined as a real-valued linear predictor η 1i which is a linear combination of regression parameters and explanatory variables. Because the mean of the beta distribution takes values on the unit interval and η 1i is typically linked to μ i via a link function g 1 from the real line to the unit interval,
A standard link function that is used in the beta regression literature, and the one that is used in this work, is the logit link:
The reason for its widespread use is the direct interpretation it offers to the regression parameters (see Ferrari and Cribari-Neto 2004 for a detailed explanation).
As far as the linear predictor is concerned, the explanatory analysis showed that all three explanatory variables (i.e. IM, M, and Y) appear to influence the loss. For this reason, all three variables should be included in the linear predictor. This yields the question as to whether these variables should be simply added or their interaction should also be taken into account. A plot of the marginal relationships of L with IM, M, and Y is later used to identify the best combinations for the available data (see Fig. 8).

Marginal relationships of L with IM, M, and Y
4.2.3 Definition of the systematic component for the precision
The variable precision φ i can also be considered to be a function of linear predictor η 2i :
where g 2(·) is the link function, taken here to be the log function:
and η 2i is the linear predictor.
4.3 Statistical model fitting technique
The aforementioned statistical models are then fitted to the field data. This involves the estimation of their unknown parameters by maximising the log-likelihood function via the ‘betareg’ package (Cribari-Neto and Zeilesis 2010; Gruen et al. 2012) in ‘R’ (R Core Team 2014) as:
where N is the total number of data points.
It has been shown (Gruen et al. 2012; Kosmidis and Firth 2010) that when maximum likelihood is used, the parameters in the systematic component for the mean are estimated in an almost unbiased way. Nonetheless, the maximum likelihood estimator of the precision parameter usually suffers from significant bias, which in turn causes the underestimation of the estimated standard errors of the beta regression model. This can potentially have a big impact on the reported significance of the explanatory variables. In order to get more realistic estimates of the standard errors of the model parameters, we use the bias reduction method that is supplied in the ‘betareg’ package (Firth 1993; Kosmidis and Firth 2009).
The 90 % point-wise prediction intervals for the vulnerability functions are calculated using the bootstrap procedure in Espinheira et al. (2014).
4.4 Goodness-of-fit assessment
The proposed procedure is based on developing a number of realistic statistical models, which are then fitted to the available data. Which one provides the best fit? To answer this question, the relative as well as the absolute goodness of fit of the proposed models is assessed. The model comparison tools aim to identify the model that provides the best fit compared to the available alternatives. The model checking tools aim to explore whether the modelling assumptions are violated, and in doing so it provides hints towards improving the model.
4.4.1 Model comparison tools
The likelihood ratio test can be used to compare the fit of a complex model relative to that of a simpler, nested model. The nested model results by fixing some of the parameters of the complex model to follow given relationships (e.g. fixing a few regression parameters to zero). Generally, the more complex model will fit the data better given that it has more parameters. This raises the question as to whether the difference between the two models is statistically significant. The likelihood ratio test is used to test the hypothesis that the simpler model fits the data as well as the complex model does. It can be shown that asymptotically, under that hypothesis the difference \(D = - 2\left( {\log (L_{{{\text{simple}}\,{\text{model}}}} ) - \log \left( {L_{{{\text{complex}}\,{\text{model}}}} } \right)} \right)\) follows a Chi-square distribution with degrees of freedom df = df simple model − df complex model. This is used to calculate p values, and in this study, it is considered that the evidence against the hypothesis is significant if the p value is less than 0.05. In this case, the complex model is considered a better fit for the given data.
4.4.2 Model checking tools
The goodness of fit of the model to the given database can be assessed by informal graphical tools. For beta regressions, the adequacy of the assumptions for the random and systematic component can be checked through the behaviour of the residuals, termed ‘standardised weighted residuals 2’ (Espinheira et al. 2008). For example, under the model assumptions, these residuals should be between −3 and 3 with high probability, the scatterplots of the residuals against the observation index number or against the linear predictor should reveal a random scatter around the zero line. For the goodness-of-fit assessment of the models in this study, the latter scatterplots are adopted as well as a half-normal plot of these residuals with simulated envelopes and a plot of the observed loss against the predicted one. The expected behaviour on the two latter scatterplots is that the points line around a 45°.
5 Results and discussion
The vulnerability of selected Australian building types for various intensity measure levels, ranging from MMI VI to VIII, is empirically assessed by fitting statistical models to the total number of data points (i.e. total of 109 data points) from two seismic events.
The first model that is examined (termed ‘Model 1’ in what follows) assumes that the loss for each level of the three explanatory variables (IM, M, and Y) follows a beta distribution (according to Eq. 1). This distribution is characterised by the mean, μ i , and the dispersion, φ. The mean, μ i , is related to the three explanatory variables through a logit link function (see Eq. 4), and the precision parameter is assumed constant, i.e. φ i = φ. The exploratory analysis showed that all three explanatory variables, i.e. IM, M, and Y, affect the loss. For this reason, they are added in the linear predictor η 1i . To examine the need to add an interaction between the explanatory variables in η 1i, the marginal relationships of the logit of L with IM, M, and Y are plotted in Fig. 8. Figure 8 shows that IM seems to influence the logit of L differently depending on values of M and Y. This indicates that the interaction between IM and M, as well as IM and Y, should also be taken into account, at least initially. Similarly, from the right-most plot in Fig. 8, there appears to be a marked change in the distribution of the logit loss across building types for the two construction periods. For this reason, the interaction between M and Y is also taken into account in the model. Thus, the linear predictor, η 1i, for ‘Model 1’ can be written in the form:
‘Model 1’ is then fitted to the 109 points via the ‘betareg’ package in ‘R’. The absolute goodness of fit of the model is assessed by the four informal graphical tools described in Sect. 4.4.2 and presented in Fig. 9. The points on the scatterplot of the observed versus the predicted losses lie roughly around the 45° line, but with a marked increase in variability as the observed responses increase in value. The apparent heteroscedasticity is also detected on the scatterplot of residuals versus the observation order and versus the linear predictor and can be attributed to the inability of the selected model to fully capture the differences in the variability of loss for the two structure types and years of construction.

Diagnostic plots for ‘Model 1’: a Residuals versus indices of observations, b residuals versus linear predictor, c half-normal plot of residuals, d predicted versus observed values
These issues of ‘Model 1’ can be addressed by relaxing the assumption of the constant precision φ. The updated model, termed ‘Model 2’, considers that the dispersion is a log function of the construction material and the year of construction (see Sect. 4.2.3):
‘Model 2’ is then fitted to the 109 data points. The diagnostic plots in Fig. 10 show no direct evidence against the model assumptions.

Diagnostic plots for ‘Model 2’ a residuals versus indices of observations, b residuals versus linear predictor, c half-normal plot of residuals, d predicted versus observed values
The next question that we consider is whether we can further simplify the mean specification of ‘Model 2’ without compromising its good fit. For answering this question, we examine whether any of the interaction terms can be dropped from the model.
Using log-likelihood ratio tests, the p value from dropping the interaction between M and IM is less than 0.001 (Chi-squared statistic of 21.323 on one degree of freedom), the p value from dropping the interaction between M and Y is 0.992 (Chi-squared statistic of 0.001 on one degree of freedom) and that of dropping the interaction between Y and IM is 0.013 (Chi-squared value of 6.168 on one degree of freedom). For this reason, the interaction of M and Y is removed from ‘Model 2’, giving rise to ‘Model 3’ with linear predictor:
Residual analysis and the scatterplot of predicted versus fitted values (not shown here) give that the fit of ‘Model 3’ is of the same quality as that of ‘Model 2’. Table 5 gives the reduced-bias estimates for the parameters of this simpler model and their associated estimated standard errors, z statistics, and Wald test p values (see Sect. 4.3 for justification on the use of bias reduction). Both the residual analysis and the reported significance of the coefficients in Table 5 indicate that ‘Model 3’ provides a good fit to the data.
Figure 11 displays the mean vulnerability curves using ‘Model 3’ along with 90 % point-wise predictive bootstrap intervals. It should be noted that the bootstrap analysis involved 9999 iterations. The URM buildings built before 1945 appear to be the most vulnerable, followed by the post-1945 URM buildings. Timber buildings appear to be the least vulnerable, with little difference observed in the vulnerability of timber buildings built before or after 1945. The selected statistical model fits well to the observed damage data collected in the aftermath of the Newcastle and the Kalgoorlie earthquakes, where most of the damage occurred to URM buildings in terms loss of chimneys, gable and parapet failures, and extensive cracking of walls (Page 1991; Blackie 1991). Timber buildings generally suffered slight non-structural damage such as cracks in wall linings and cornices (Edwards et al. 2010). The vulnerability curves developed in this study can be used to predict future losses for the four building classes, not only in Newcastle and Kalgoorlie, but for similar building types Australia wide as construction practices are similar throughout the country. The differentiation of building material (masonry and timber) offers better predictability of losses as the resistance to earthquake of both types is quite different. The severity and nature of damage sustained by these types is also different, thus necessitating the differentiation. Furthermore, the vintage of the building helps to differentiate the more vulnerable older building stock that has been deteriorated, influenced by poor material quality, poor construction practices, and non-conformance with earthquake standards, from the newer ones that have not.

Vulnerability functions and their 90 % prediction intervals (90 % CI) for the four building classes based on the best-fitted model ‘Model 3’ are compared with existing vulnerability curves from New Zealand buildings (Uma, personal communication)
Although the selected model fits the damage data well, the moderate quality of the damage and intensity data raises concerns regarding the reliability of the loss predictions. The moderate quality of the data is characterised by the lack of ground motion intensity measurements, by the use of aggregated data points in the regression, and by attempts to reduce the bias of the largest Newcastle database. The impact of the first two on the shape of the fragility, rather than vulnerability curves, has been studied in the literature (e.g. Ioannou et al. 2015). Thus, the reliability of empirical vulnerability curves could be improved with the improvement of the data quality. This could be achieved by a relatively small sample of buildings capable to capture the variability in the building stock as well as represent the impact of the earthquake to these buildings.
The reliability of the predictions of the vulnerability curves constructed herein could be assessed by using cross-validation procedures with independent post-earthquake data that have not been used in the construction of these curves. In the absence of these data, an effort is made to compare the resultant vulnerability curves with existing curves in the region. Unfortunately, there are no publically available curves in Australia due to a paucity of vulnerability studies; however, a few vulnerability curves have been developed in New Zealand based on observed damages from New Zealand and overseas earthquakes (Dowrick 1991; Dowrick and Rhoades 1993; Dowrick et al. 2001; Dowrick and Rhoades 2002) as well as expert judgement (Uma, personal communication, 2015). These curves include the observations from the 1942 Wairarapa, 1968 Inangahua, and 1987 Edgecumbe earthquakes but do not include the data obtained from the Canterbury earthquakes. In comparison with the functions from New Zealand (see Fig. 11), it is noticed that the New Zealand building types seem to be less vulnerable than the Australian counterparts. This means that the use of the curves constructed herein produces conservative estimates of the loss. It is, however, anticipated that the difference might reduce when the data from the 2010 Canterbury earthquake are used to update the New Zealand curves.
6 Conclusions
This study describes the two most common building types (URM and timber frame structures) in Australia and provides typical characteristics of older legacy buildings (pre-1945) and relatively newer ones constructed after 1945. This study also provides an overview of the building performance in the 1989 Newcastle and the 2010 Kalgoorlie earthquakes along with common failure modes and the factors which contributed to the damage.
This study utilises a large body of empirical data from the two earthquakes mentioned above and develops the first publically available empirical vulnerability curves using the best available Australian data sets. The curves provide mean building population losses and their uncertainties for four Australian building classes. This study adopts the latest research in following a novel methodology presented in the GEM empirical vulnerability assessment guidelines to develop the empirical functions for Australian building types.
From the vulnerability functions developed, it is concluded that the URM structures are more vulnerable than the timber structures. Moreover, the analysis showed that the uncertainty is higher in the loss for structures built before 1945 and, in particular, of URM structures. The functions not only represent the vulnerability of buildings in Newcastle and the Kalgoorlie building stock but more generally can be used to quantify the vulnerability of buildings throughout Australia given the common construction practices used across the country. The curves and associated uncertainties can be improved by using a richer data set when available including data from any future damaging event. The study can also be extended to consider a wider variation in building types and age categories.
Nevertheless, the developed curves can be applied in any seismic risk assessment study in Australia involving low-rise URM and timber structures, provided that the required intensity is within the MMI V to VIII range. Based on the risk studies, retrofit strategies can be developed to reduce the future risk associated with the more vulnerable of these building types. Building on this research and utilising support from the Australian Government, Geoscience Australia is collaborating in a mitigation strategy development project within the Bushfire and Natural Hazards Cooperative Research Centre (BNHCRC 2015) to provide an evidence base for strengthening more vulnerable building types in the existing Australian building stock.
References
ATC (1985) Earthquake damage evaluation data for California. Report ATC-13, Applied Technology Council, Redwood City, California, USA
Blackie R (1991) The lessons that have been learnt construction—the builders viewpoint for the future. In: Rynn JMW (ed) Proceedings of the what we have learnt from the Newcastle earthquake conference. The University of Queensland, Australia, 24–25 October 1991
BNHCRC (2015) Cost-effective mitigation strategy development for building related earthquake risk. Bushfire and Natural Hazards Cooperative Research Centre, Melbourne, Australia. http://www.bnhcrc.com.au/research/resilient-people-infrastructure-and-institutions/244
Calvi GM, Pinho R, Magenes G, Bommer JJ, Restrepo-Velez LF, Crowley H (2006) Development of seismic vulnerability assessment over the past 30 years. ISET J Earthq Technol 43:75–104
Cattari S, Ottonelli D, Pinna M, Lagomarsino S, Clark W, Giovinazzi S, Ingham J, Marotta A, Liberatore D, Sorrentino L, Leite J, Lourenco P, Goded T (2015) Preliminary results from damage and vulnerability analysis of URM churches after the Canterbury earthquake sequence 2010–2011. In: Proceeding of the New Zealand Society for Earthquake Engineering Conference, Rotorua, New Zealand
Cooke R (1991) Experts in uncertainty-opinion and subjective probability in science. In: Environmental ethics and science policy series. Oxford University Press, New York 1016. ISBN:0-19-506465-8
Cribari-Neto F, Zeileis A (2010) Beta regression in R. J Stat Softw 34:1–24
D’Ayala D, Meslem A (2012) Guide for selection of existing analytical fragility curves and compilation of the database. GEM Technical Report 2012, GEM Foundation, Pavia, Italy
Dhu T, Jones T (eds) (2002) Earthquake risk in Newcastle and Lake Macquarie. Geoscience Australia Record 2002/15, Geoscience Australia, Canberra
Dizhur D, Ismail N, Knox C, Lumantarna R, Ingham J (2010) Performance of unreinforced and retrofitted masonry buildings during the 2010 Darfield earthquake. Bull N Z Soc Earthq Eng 43:321–339
Dizhur D, Moon L, Ingham J (2013) Observed performance of residential masonry veneer construction in the 2010/2011 Canterbury earthquake sequence. Earthq Spectra 29:1255–1274
Dizhur D, Bailey S, Griffith M, Ingham J (2015) Earthquake performance of two vintage URM buildings retrofitted using surface bonded GFRP: case study. J Compos Constr. doi:10.1061/(ASCE)CC.1943-5614.0000561
Dowrick D (1991) Damage costs for houses and farms as a function of intensity in the 1987 Edgecumbe earthquake. Earthq Eng Struct Dyn 20:455–469
Dowrick D, Rhoades D (1993) Damage costs for commercial and industrial property as a function of intensity in the 1987 Edgecumbe earthquake. Earthq Eng Struct Dyn 22:869–884
Dowrick D, Rhoades D (2002) Damage ratios for low-rise non-domestic brick buildings in the magnitude 7.1 Wairarapa, New Zealand, earthquake of 24 June 1942. Bull N Z Soc Earthq Eng 35:135–148
Dowrick D, Rhoades D, Davenport P (2001) Damage ratios for domestic property in the magnitude 7.2 1968 Inangahua, New Zealand, earthquake. Bull N Z Soc Earthq Eng 34:191–213
Edwards M, Robinson D, McAneney K, Schneider J (2004) Vulnerability of residential structures in Australia. In: Proceedings of 13th World conference on earthquake engineering. Vancouver, Canada
Edwards M, Griffith M, Wehner M, Lam N, Corby N, Jakab M, Habili N (2010) The Kalgoorlie earthquake of the 20th April 2010: preliminary damage survey outcomes. In: Proceedings of Australian Earthquake Engineering Society Conference, Perth, Australia
Espinheira P, Ferrari SP, Cribari-Neto F (2008) On beta regression residuals. J Appl Stat 35:407–419
Espinheira P, Ferrari SP, Cribari-Neto F (2014) Bootstrap prediction intervals in beta regressions. Comput Stat 29:1263–1277
FEMA (2003) Multi-hazard loss estimation methodology, earthquake model. HAZUS®MH MR3. Technical Manual, Federal Emergency Management Agency, Washington, DC, USA
Ferrari S, Cribari-Neto F (2004) Beta regression for modelling rates and proportions. J Appl Stat 31:799–815
Firth D (1993) Bias reduction of maximum likelihood estimates. Biometrika 80:27–38
GEM (2015) Physical vulnerability project. Global Earthquake Model Foundation, Pavia, Italy. http://www.globalquakemodel.org/what/physical-integrated-risk/physical-vulnerability/
Giovinazzi S, Lagomarsino (2004) A macroseismic method for the vulnerability assessment of buildings. In: Proceedings of 13th world conference on earthquake engineering, Vancouver, Canada
Gohil H, Abbs C, Loke J (1991) The assessment, repair and strengtheing of public buildings damaged by the 1989 Newcastle earthquake. In: Rynn JMW (ed) Proceedings of the what we have learnt from the Newcastle earthquake conference. The University of Queensland, Australia, 24–25 October 1991
Griffith M, Ingham J, Moon L (2010) Implications of the 2010 Darfield (Christchurch, NZ) earthquake for Australia—are we ready? In: Proceeding of the Australian Earthquake Engineering Society Conference, Perth, Australia
Griffith M, Moon L, Ingham J, Derakhsham H (2013) Implications of the Canterbury earthquake sequence for Adelaide. In: Proceeding of the 12th Canadian Masonry Symposium, Vancouver, Canada
Gruen B, Kosmidis I, Zeileis A (2012) Extended beta regression in R: shaken, stirred, mixed, and partitioned. J Stat Softw 48:1–25
Grünthal G (ed), Musson R, Schwarz J, Stucchi M (1998) European Macroseismic Scale 1998. Cahiers du Centre Européen de Géodynamique et de Séismologie: 15—European Center for Geodynamics and Seismology, Luxembourg
Gulkan P, Sucuoglu H, Ergunay O (1992) Earthquake vulnerability, loss and risk assessment in Turkey. In: Proceedings of 10th World Conference on Earthquake Engineering, Madrid, Spain
Ingham J, Biggs D, Moon L (2011) How did unreinforced masonry buildings perform in the February 2011 Christchurch earthquake? Struct Eng 89(6):12
Ingham J, Dizhur D, Moon L, Griffith M (2012) Performance of earthquake strengthened URM buildings in the 2010/2011 Christchurch earthquake sequence. In: Proceeding of the 15th International Brick and Block Masonry Conference, Florianópolis, Brazil
Ioannou I, Douglas J, Rossetto T (2015) Assessing the impact of ground-motion variability and uncertainty on empirical fragility curves. Soil Dyn Earthq Eng 69:83–92
Jaiswal K, Wald DJ, Perkins D, Aspinall WP, Kiremidjian AS (2013) Estimating structural collapse fragility of generic building typologies using expert judgement. In: Proceedings of 11th international conference on structural safety and reliability, New York, USA
Jaiswal K, Wald DJ, Perkins D, Aspinall WP, Kiremidjian AS (2014) Application of structured elicitation process to estimate seismic collapse fragility of generic construction types. In: Proceedings of 2nd European Conference on Earthquake Engineering and Seismology, Istanbul, Turkey
Kosmidis I, Firth D (2009) Bias reduction in exponential family nonlinear models. Biometrika 96:793–807
Kosmidis I, Firth D (2010) A generic algorithm for reducing bias in parametric estimation. Electron J Stat 4:1097–1112
Lumantarna E, Vaculik J, Griffith M, Lam N, Wilson J (2006) Seismic fragility curves for un-reinforced masonry walls. In: Earthquake Engineering in Australia, proceeding of the Australian Earthquake Engineering Society Conference, Canberra, Australia
Maqsood ST, Schwarz J (2008) Analysis of building damage during the 8 October 2005 eartqhuake in Pakistan. Seismol Res Lett 79:163–177
Maqsood ST, Wehner M, Ryu H, Edwards M, Dale K, Miller V (2014) GAR15 Vulnerability functions: reporting on the UNISDR/GA SE Asian regional workshop on structural vulnerability models for the GAR global risk assessment, 11–14 November, 2013, Geoscience Australia, Canberra, Australia. Record 2014/38. Geoscience Australia: Canberra, Australia. http://dx.doi.org/10.11636/Record.2014.038
Melchers R (ed) (1990) Newcastle earthquake study. The Institution of Engineers, Canberra, Australia. ISBN:85825 516 2
Moon L, Dizhur D, Ingham J, Griffith M (2012) Seismic performance of masonry buildings in the Christchurch earthquakes 2010–2011: a progress report. In: Proceeding of the Australian Earthquake Engineering Society Conference, Gold Coast, Australia
Moon L, Dizhur D, Ingham J, Griffith M (2014) The demise of the URM building stock in Christchurch during the 2010–2011 Canterbury earthquake sequence. Earthq Spectra 30:1–24
Page A (1991) Quality control in masonry construction—the lessons from the Newcastle Earthquake. In: Rynn JMW (ed) Proceedings of the what we have learnt from the Newcastle earthquake conference. The University of Quuensland, Australia, 24–25 October 1991
Page A (2002) Unreinforced masonry structures—an Australian overview. Clay Brick and Paver Institute. Research Paper 15. Baulkham Hills, Australia
Pedersen I (1991) Engineering-quality and standards of construction. In: Rynn JMW (ed) Proceedings of the what we have learnt from the Newcastle earthquake conference. The University of Quuensland, Australia, 24–25 October 1991
R Core Team (2014) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org/
Rossetto T, Elnashai A (2003) Derivation of vulnerability functions for European-type RC structures based on observational data. Eng Struct 25:1241–1263
Rossetto T, Ioannou I, Grant D (2013) Existing empirical fragility and vulnerability functions: compendium and guide for selection. GEM Technical Report 2013, 65, GEM Foundation, Pavia, Italy
Rossetto T, Ioannou I, Grant D, Maqsood T (2014) Guidelines for empirical vulnerability assessment. GEM Technical Report 2014-08 V1.0.0, 140, GEM Foundation, Pavia, Italy, 10.13117/GEM.VULN-MOD.TR2014.11
Rota M, Penna A, Strobbia C (2008) Processing Italian damage data to derive typological fragility curves. Soil Dyn Earthq Eng 28:933–947
Russell A, Ingham J (2008) Trends in the architectural characterisation of unreinforced masonry in New Zealand. In: Proceeding of the 14th international brick and block masonry conference, Sydney, Australia
Russell A, Ingham J (2010) Prevalence of New Zealand’s unreinforced masonry buildings. Bull N Z Soc Earthq Eng 43:182–201
Rynn J, Brennan E, Hughes P, Pedersen I, Stuart H (1992) The 1989 Newcastle, Australia, earthquake: the facts and misconceptions. Bull N Z Natl Soc Earthq Eng 25:77–144
Senaldi I, Magenes G, Ingham J (2014) Damage assessment of unreinforced stone masonry buildings after the 2010–2011 Canterbury earthquakes. Int J Archit Herit Conserv Anal Restor. doi:10.1080/15583058.2013.840688
Turner F, Elwood K, Griffith M, Ingham J, Marshall J (2012) Performance of retrofitted unreinforced masonry buildings during the Christchurch earthquake sequence. In: Proceeding of the structures Congress. Chicago, USA, pp 1092–1103. doi:10.1061/9780784412367.097
Uma S (personal communication, 2015) Vulnerability functions for typical timber and URM structures in New Zealand. GNS Science, Lower Hutt, New Zealand
UNISDR (2015) Global assessment report on disaster risk reduction: making development sustainable: the future of disaster risk management. United Nations International Strategy for Disaster Reduction, Geneva
Walker G (1991) Lessons from the 1989 Newcastle earthquake. In: Rynn JMW (ed) Proceedings of the what we have learnt from the Newcastle earthquake conference. The University of Quuensland, Australia, 24–25 October 1991
Whitman R, Reed JW, Hong ST (1973) Earthquake damage probability matrices. In: Proceedings of 5th world conference on earthquake engineering, Rome, Italy
Wood H, Neumann F (1931) Modified Mercalli intensity scale of 1931. Bull Seismol Soc Am 21:277–283
Acknowledgments
The authors acknowledge the support of the residents of Newcastle and Kalgoorlie who made their time available to answer questions during the field surveys. The authors also acknowledge the Newcastle City Council and the Insurance Australia Group for their research support. Two anonymous referees are gratefully acknowledged for reviewing the manuscript and providing their useful comments on an earlier version of this manuscript as part of journal review process. This work was partially supported by the Global Earthquake Model Foundation. The contributions of Ioanna Ioannou and Tiziana Rossetto were funded by the EPSRC Project ‘Challenging RISK’ (EP/K022377/1). This paper is published with the permission of the CEO, Geoscience Australia.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Maqsood, T., Edwards, M., Ioannou, I. et al. Seismic vulnerability functions for Australian buildings by using GEM empirical vulnerability assessment guidelines. Nat Hazards 80, 1625–1650 (2016). https://doi.org/10.1007/s11069-015-2042-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-015-2042-x