
Abstract
Multimedia content analysis and understanding, such as action recognition and image classification, is a fundamental research problem. One effective strategy to improve the performance is designing discriminative visual representation, for example combining multiple feature sets for representation. However, simply combing these features may cause high dimensionality and lead to noises. Feature selection and fusion are common choices for multiple feature representation. At the same time, multi-task feature learning has been proven to be an effective method by many researches. In this paper, we propose a multi-task multi-view feature selection and fusion method which chooses and fuses discriminative features. For discriminative feature selection, we learn the selection matrix W by the minimization of the trace ratio objective function. For multiple tasks measurement, we employ the ℓ 2,1-norm regularization to solve single task and share information among tasks. For multiple feature fusion, we incorporate local structures of each view in the Laplacian matrix. Since the Laplacian matrix is constructed in unsupervised manner and scaled category indicator matrix is solved iteratively, our work is fully unsupervised. Experimental results on four action recognition datasets and five image classification datasets demonstrate the effectiveness of multi-task multi-view feature selection and fusion.









Similar content being viewed by others
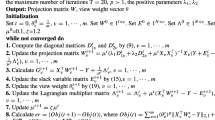


References
Argyriou A, Evgeniou T, Pontil M (2008) Convex multi-task feature learning. Mach Learn 73(3):243–272
Blum A, Mitchell T (1998) Combining labeled and unlabeled data with co-training. In: Proceedings of the annual conference on computational learning theory, ACM, pp 92–100
Cai X, Nie F, Huang H, Ding C (2011) Multi-class l2, 1-norm support vector machine. In: IEEE international conference on data mining (ICDM), IEEE, pp 91–100
Chang X, Yu YL, Yang Y, Xing EP (2016) Semantic pooling for complex event analysis in untrimmed videos. IEEE Transactions on Pattern Analysis and Machine Intelligence. https://doi.org/10.1109/TPAMI.2016.2608901
Chang X, Ma Z, Lin M, Yang Y, Hauptmann AG (2017) Feature interaction augmented sparse learning for fast kinect motion detection. IEEE Trans Image Process 26 (8):3911–3920. https://doi.org/10.1109/TIP.2017.2708506
Chang X, Ma Z, Yang Y, Zeng Z, Hauptmann AG (2017) Bi-level semantic representation analysis for multimedia event detection. IEEE Trans Cybern 47(5):1180–1197. https://doi.org/10.1109/TCYB.2016.2539546
Chen X, Lin Q, Kim S, Carbonell JG, Xing EP et al (2012) Smoothing proximal gradient method for general structured sparse regression. Ann Appl Stat 6 (2):719–752
Delaitre V, Laptev I, Sivic J (2010) Recognizing human actions in still images: a study of bag-of-features and part-based representations. In: BMVC
Duda RO, Hart PE, Stork DG (2012) Pattern classification. Wiley, Hoboken
Evgeniou A, Pontil M (2007) Multi-task feature learning. Advances in Neural Information Processing Systems
Feng Y, Xiao J, Zhuang Y, Liu X (2013) Adaptive unsupervised multi-view feature selection for visual concept recognition. In: ACCV, Springer, pp 343–357
Gong Y, Ke Q, Isard M, Lazebnik S (2014) A multi-view embedding space for modeling internet images, tags, and their semantics. Int J Comput Vis 106 (2):210–233
Gupta A, Kembhavi A, Davis LS (2009) Observing human-object interactions: Using spatial and functional compatibility for recognition. IEEE Trans Pattern Anal Mach Intell 31(10):1775–1789
Han Y, Wu F, Tao D, Shao J, Zhuang Y, Jiang J (2012) Sparse unsupervised dimensionality reduction for multiple view data. IEEE Trans Circuits Syst Video Technol 22(10):1485–1496
Han Y, Zhang J, Xu Z, Yu SI (2013) Discriminative multi-task feature selection. In: AAAI, pp 41–43
Han Y, Yang Y, Wu F, Hong R (2015) Compact and discriminative descriptor inference using multi-cues. IEEE Trans Image Process 24(12):5114–5126
Han Y, Yang Y, Yan Y, Ma Z, Sebe N, Zhou X (2015) Semisupervised feature selection via spline regression for video semantic recognition. IEEE Trans Neural Netw Learn Syst 26(2):252–264
Hardoon DR, Szedmak S, Shawe-Taylor J (2004) Canonical correlation analysis: An overview with application to learning methods. Neural Comput 16(12):2639–2664
Huiskes MJ, Lew MS (2008) The mir flickr retrieval evaluation. In: Proceedings of the ACM international conference on multimedia information retrieval. ACM, pp 39–43
Ikizler N, Cinbis RG, Pehlivan S, Duygulu P (2008) Recognizing actions from still images. In: International conference on pattern recognition. IEEE, pp 8–11
Jin X, Zhuang F, Wang S, He Q, Shi Z (2013) Shared structure learning for multiple tasks with multiple views. In: Machine learning and knowledge discovery in databases. Springer, pp 353–368
Kan M, Shan S, Zhang H, Lao S, Chen X (2012) Multi-view discriminant analysis. In: ECCV, Springer, pp 808–821
Li H, Wang M, Hua XS (2009) Msra-mm 2.0: A large-scale web multimedia dataset. In: IEEE international conference on data mining workshops (ICDMW), IEEE, pp 164–169
Liu J, Ji S, Ye J (2009) Multi-task feature learning via efficient l 2, 1-norm minimization. In: Proceedings of the conference on uncertainty in artificial intelligence. AUAI Press, pp 339–348
Liu Y, Nie F, Wu J, Chen L (2013) Efficient semi-supervised feature selection with noise insensitive trace ratio criterion. Neurocomputing 105:12–18
Liu Y, Liao B, Han Y (2015) Discriminative multi-view feature selection and fusion. In: ICME, pp 1–6
Loui A, Luo J, Chang SF, Ellis D, Jiang W, Kennedy L, Lee K, Yanagawa A (2007) Kodak’s consumer video benchmark data set: concept definition and annotation. In: Proceedings of the international workshop on multimedia information retrieval. ACM, pp 245–254
Ma Z, Yang Y, Nie F, Uijlings J, Sebe N (2011) Exploiting the entire feature space with sparsity for automatic image annotation. In: Proceedings of the ACM international conference on multimedia. ACM, pp 283–292
Nie F, Huang H, Cai X, Ding CH (2010) Efficient and robust feature selection via joint 2, 1-norms minimization. In: Advances in neural information processing systems, pp 1813–1821
Nie L, Zhang L, Yang Y, Wang M, Hong R, Chua TS (2015) Beyond doctors: future health prediction from multimedia and multimodal observations. In: Proceedings of the ACM international conference on multimedia. ACM, pp 591–600
Nie L, Song X, Chua TS (2016) Learning from multiple social networks. Morgan & Claypool, San Rafael
Parameswaran S, Weinberger KQ (2010) Large margin multi-task metric learning. In: Advances in neural information processing systems, pp 1867–1875
Peng Y, Zhai X, Zhao Y, Huang X (2016) Semi-supervised cross-media feature learning with unified patch graph regularization. IEEE Trans Circuits Syst Video Technol 26(3):583–596
Sharma A, Kumar A, Daume H, Jacobs DW (2012) Generalized multiview analysis: A discriminative latent space. In: IEEE conference on computer vision and pattern recognition (CVPR). IEEE, pp 2160–2167
Solorio-Fernández S, Carrasco-Ochoa JA, Martínez-Trinidad JF (2016) A new hybrid filter–wrapper feature selection method for clustering based on ranking. Neurocomputing 214:866–880
Song X, Nie L, Zhang L, Liu M, Chua TS (2015) Interest inference via structure-constrained multi-source multi-task learning. In: International joint conference on artificial intelligence (IJCAI), pp 2371–2377
Wang D, Nie F, Huang H (2014) Unsupervised feature selection via unified trace ratio formulation and k-means clustering (track). In: Machine learning and knowledge discovery in databases. Springer, pp 306–321
Wang H, Yan S, Xu D, Tang X, Huang T (2007) Trace ratio vs. ratio trace for dimensionality reduction. In: IEEE conference on computer vision and pattern recognition (CVPR). IEEE, pp 1–8
Wen X, Shao L, Fang W, Xue Y (2015) Efficient feature selection and classification for vehicle detection. IEEE Trans Circuits Syst Video Technol 25 (3):508–517
Wu M, Schölkopf B (2006) A local learning approach for clustering. In: Advances in neural information processing systems, pp 1529–1536
Wu X, Yu K, Ding W, Wang H, Zhu X (2013) Online feature selection with streaming features. IEEE Trans Pattern Anal Mach Intell 35(5):1178–1192
Xia T, Tao D, Mei T, Zhang Y (2010) Multiview spectral embedding. IEEE Trans Syst Man Cybern B Cybern 40(6):1438–1446
Xie L, Zhu L, Cheng Z (2017) Multi-task multi-modal semantic hashing for web image retrieval with limited supervision. In: International conference on multimedia modeling. Springer, pp 465–477
Yang Y, Shen HT, Ma Z, Huang Z, Zhou X (2011) l2, 1-norm regularized discriminative feature selection for unsupervised learning. In: International joint conference on artificial intelligence (IJCAI), Citeseer, vol 22, pp 1589–1594
Yang Y, Shen HT, Nie F, Ji R, Zhou X (2011) Nonnegative spectral clustering with discriminative regularization. In: AAAI, pp 555–560
Yang Y, Nie F, Xu D, Luo J, Zhuang Y, Pan Y (2012) A multimedia retrieval framework based on semi-supervised ranking and relevance feedback. IEEE Trans Pattern Anal Mach Intell 34(4):723–742
Yang Y, Ma Z, Hauptmann A G, Sebe N (2013) Feature selection for multimedia analysis by sharing information among multiple tasks. IEEE Trans Multimedia 15(3):661–669
Yang Y, Song J, Huang Z, Ma Z, Sebe N, Hauptmann A G (2013) Multi-feature fusion via hierarchical regression for multimedia analysis. IEEE Trans Multimedia 15(3):572–581
Yao B, Fei-Fei L (2010) Grouplet: A structured image representation for recognizing human and object interactions. In: IEEE conference on computer vision and pattern recognition (CVPR). IEEE, pp 9–16
Zhang X, Hu W, Bao H, Maybank S (2013) Robust head tracking based on multiple cues fusion in the kernel-bayesian framework. IEEE Trans Circuits Syst Video Technol 23(7):1197–1208
Zhao H, Wang Z, Nie F (2016) Orthogonal least squares regression for feature extraction. Neurocomputing 216:200–207
Zhao Z, Liu H (2007) Semi-supervised feature selection via spectral analysis. In: SDM, SIAM, pp 641–646
Zhou ZH, Zhang ML, Huang SJ, Li YF (2012) Multi-instance multi-label learning. Artif Intell 176(1):2291–2320
Zhu L, Shen J, Xie L, Cheng Z (2017) Unsupervised visual hashing with semantic assistant for content-based image retrieval. IEEE Trans Knowl Data Eng 29 (2):472–486
Acknowledgements
This work is supported by the NSFC (under Grant U1509206,61472276).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Yang, Z., Wang, H., Han, Y. et al. Discriminative multi-task multi-view feature selection and fusion for multimedia analysis. Multimed Tools Appl 77, 3431–3453 (2018). https://doi.org/10.1007/s11042-017-5165-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-5165-0