
Abstract
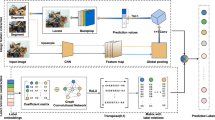
With the rapid growth of various media data, how to effectively manage and retrieve multimedia data has become an urgent problem to be solved. Due to semantic gap, overcoming the semantic gap has become a difficult problem for image semantic annotation. In this paper, a hybrid approach is proposed to learn automatically semantic concepts of images, which is called CNN-ECC. It’s divided into two processes generative feature learning and discriminative semantic learning. In feature learning phase, the redesigned convolutional neural network (CNN) is utilized for feature learning, instead of traditional methods of feature learning. Besides the reconstructed CNN model has the ability to learn multi-instance feature, which can enhance the image features’ representation when extracting features from images containing multiple instances. In semantic learning phase, the ensembles of classifier chains (ECC) are trained based on obtained visual feature for semantic learning. In addition, the ensembles of classifier chains can learn semantic association between different labels, which can effectively avoid generating redundant labels when resolving multi-label classification task. Furthermore, the experimental results confirm that proposed approach performs more effectively and accurately than state-of-the-art for image semantic annotation.




Similar content being viewed by others


References
Chang E, Goh K, Sychay G, Wu G (2003) Cbsa: content-based soft annotation for multimodal image retrieval using bayes point machines. IEEE Trans Circuits Syst Video Technol 13(1):26–38
Cusano C, Ciocca G, Schettini R (2003) Image annotation using svm. In: Proceedings of SPIE - the international society for optical engineering, vol 5304, pp 330–338
Deng J, Dong W, Socher R, Li LJ (2009) Imagenet: a large-scale hierarchical image database. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 248–255
Dong J, Xia W, Chen Q, Feng J, Huang Z, Yan S (2013) Subcategory-aware object classification. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 827–834
Duygulu P, Barnard K, de Freitas J F G, Forsyth D A (2002) Object recognition as machine translation: learning a lexicon for a fixed image vocabulary. In: Proceedings of the european conference on computer vision (ECCV), pp 97–112
Escalante HJ, Montes M, Sucar LE (2012) Multi-class particle swarm model selection for automatic image annotation. Expert Syst Appl 39(12):11011–11021
Everingham M, Gool L, Williams CK, Winn J, Zisserman A (2010) The pascal visual object classes (voc) challenge. Int J Comput Vis 88(2):303–338
Goh KS, Chang EY, Li B (2005) Using one-class and two-class svms for multiclass image annotation. IEEE Trans Knowl Data Eng 17(10):1333–1346
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Hwang SJ, Grauman K (2010) Accounting for the relative importance of objects in image retrieval. In: Proceedings of the British machine vision conference, pp 1–12
Jacobs DW, Daume H, Kumar A, Sharma A (2012) Generalized multiview analysis: a discriminative latent space. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2160–2167
Jia Y, Shelhamer E, Donahue J, Karayev S, Long J, Girshick R, Guadarrama S, Darrell T (2014) Caffe: convolutional architecture for fast feature embedding. In: Proceedings of the 22nd ACM international conference on multimedia, pp 675–678
Joachims T (1998) Making large-scale svm learning practical. Technical report, Universitat Dortmund
Krizhevsky A, Sutskever I, Hinton G E (2012) Imagenet classification with deep convolutional neural networks. In: Proceedings of the advances in neural information processing systems (NIPS), pp 1106–1114
Li G, Yu Y (2015) Visual saliency based on multiscale deep features. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5455–5463
Li J, Wang JZ (2003) Automatic linguistic indexing of pictures by a statistical modeling approach. IEEE Trans Pattern Anal Mach Intell 25(9):1075–1088
Li Z, Shi Z, Zhao W, Li Z, Tang Z (2013) Learning semantic concepts from image database with hybrid generative/discriminative approach. Eng Appl Artif Intell 26(9):2143–2152
Liu Y, Zhang D, Lu G, Ma WY (2007) A survey of content-based image retrieval with high-level semantics. Pattern Recogn 40(1):262–282
Mahendran A, Vedaldi A (2015) Understanding deep image representations by inverting them. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5188–5196
Mnih V, Kavukcuoglu K, Silver D, Rusu AA, Veness J, Bellemare MG, Graves A, Riedmiller M, Fidjeland AK, Ostrovski G, et al. (2015) Human-level control through deep reinforcement learning. Nature 518(7540):529–533
Monay F, Gatica-Perez D (2007) Modeling semantic aspects for cross-media image indexing. IEEE Trans Pattern Anal Mach Intell 29(10):1802–1817
Parkhi OM, Vedaldi A, Zisserman A (2015) Deep face recognition Proceedings of the British machine vision conference, pp 6–18
Paulin M, Mairal J, Douze M, Harchaoui Z, Perronnin F, Schmid C (2017) Convolutional patch representations for image retrieval: an unsupervised approach. Int J Comput Vis 121(1):149– 168
Prechelt L (1998) Early stopping—but when? In Lecture Notes in Computer Science 1524:55–69
Razavian AS, Azizpour H, Sullivan J, Carlsson S (2014) Cnn features off-the-shelf: an astounding baseline for recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 806–813
Read J, Pfahringer B, Holmes G, Frank E (2009) Classifier chains for multi-label classification. Mach Learn 85(3):254–269
Sermanet P, Eigen D, Zhang X, Mathieu M, Fergus R, LeCun Y (2014) Overfeat: integrated recognition, localization and detection using convolutional networks. In: Proceedings of international conference on learning representations, pp 1–16
Smeulders AWM, Worring M, Santini S, Gupta A, Jain R (2000) Content-based image retrieval at the end of the early years. IEEE Trans Pattern Anal Mach Intell 22(12):1349–1380
Song Z, Chen Q, Huang Z, Hua Y, Yan S (2011) Contextualizing object detection and classification. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1585– 1592
Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R (2014) Dropout: a simple way to prevent neural networks from overfitting. J Mach Learn Res 15(1):1929–1958
Yan S, Huang Z, Hua Y, Song Z, Chen Q (2012) Hierarchical matching with side information for image classification. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3426–3433
Zhang L, Ma J (2011) Image annotation by incorporating word correlations into multi-class svm. Soft Comput 15(5):917–927
Zhang ML, Zhou ZH (2014) A review on multi-label learning algorithms. IEEE Trans Knowl Data Eng 26(8):1819–1837
Acknowledgements
This work is supported by the National Natural Science Foundation of China (Nos. 61663004, 61363035, 61365009), the Guangxi Natural Science Foundation (Nos. 2016GXNSFAA380146, 2014GXNSFAA118368), the Director Fund of Guangxi Key Lab of Multi-source Information Mining and Security (16-A-03-02), the Guangxi “Bagui Scholar” Teams for Innovation and Research Project, Guangxi Collaborative Innovation Center of Multi-source Information Integration and Intelligent Processing.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zheng, Y., Li, Z. & Zhang, C. A hybrid architecture based on CNN for cross-modal semantic instance annotation. Multimed Tools Appl 77, 8695–8710 (2018). https://doi.org/10.1007/s11042-017-4764-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-4764-0