
Abstract
This study proposes a reversible data hiding (RDH) algorithm for 3D mesh models based on the optimal three-dimensional prediction-error histogram (PEH) modification with recursive construction coding (RCC). Firstly, we design a double-layered prediction scheme to divide all the vertices of 3D mesh model into the “embedded” set and the “referenced” set, according to the odd-even property of indices into the vertex list. Thanks to the geometrical similarity among neighboring vertices, we obtain the prediction errors (PEs) with a sharp histogram. Then we combine every three adjacent PEs into one prediction-error triplet (PET) and construct the three-dimensional PEH with smaller entropy than one-dimensional PEH by utilizing the correlation among PEs. Next we project the three-dimensional PEH into one-dimensional space for scalar PET sequence which is suitable for using RCC. And also, we define the distortion metrics for 3D mesh models, by which we can estimate the optimal probability transition matrix (OTPM) indicating the optimal PEH modification manner. After that, we modify the PET sequence and embed data by RCC according to OTPM. The experimental results show that our method is superior to two state-of-the-art spatial-domain RDH algorithms for 3D mesh models a lot.
Similar content being viewed by others

1 Introduction
Data hiding is applied extensively in the community of signal processing, such as ownership protection, fingerprinting, authentication and secret communication, but the most classical data hiding technique will lead to permanent distortions. In the last decades, reversible data hiding (RDH) [1, 3, 4, 8, 9, 14, 16, 18–20, 23, 24] as a new type of information hiding technique, has received much attention. RDH provides not only extracting embedded data precisely, but also restoring the original cover image without any distortion. This special property has been found much useful in many sensitive fields, such as medical imagery, military imagery and law forensics, where any change on the host signal is not allowed. There are two important metrics to evaluate the performance of an RDH algorithm: the embedding capacity and the distortion. In fact, we always keep the balance between such two metrics, because a higher embedding capacity often cause more distortion and decreasing the distortion will result in a lower embedding capacity (EC). The Peak-Signal-to-Noise-Ratio (PSNR) value is usually used to evaluate the performance of RDH algorithm.
The classic RDH algorithms mainly fall into three categories, lossless compression [3], difference expansion (DE) [18] and histogram shifting (HS) [14]. Recently, many researchers apply DE or HS to more centrally distributed prediction error [PE] to achieve better performance because it exploits the correlation between neighboring pixels [1, 4, 8, 9, 16, 19, 20]. This extended method is called prediction-error expansion (PEE), which has been proved to be the most powerful technique of RDH.
Almost all state-of-the-art PEE algorithms consist of two steps. The first step generates a PE sequence with small entropy which can be realized by utilizing kinds of pixel prediction strategies combined with the sorting or pixel selection technique. The second step reversibly embeds the message into the PE sequence by modifying its histogram with methods like HS and DE, and recursive construction coding (RCC) is proved to be the optimized histogram modification in this process.
The research of RDH for digital image has last for many years and the algorithm performance has already approached to the theoretical optimal solution, but for other digital multimedia, such as audio, video, especial for 3D models, it is still at the starting stage. With the rapid development of 3D related applications, 3D models have been widely used on the internet, no matter mesh models or point cloud models, so researchers gradually try to adopt 3D models as the cover media for RDH. The former RDH for 3D models can be classified into three domains: spatial-domain, compressed-domain and transform-domain [2, 11–13, 17, 21, 22]. Spatial-domain-based RDH [2, 21, 22] just modifies the vertex coordinates thus it has low computational complexity. Compressed-domain-based RDH [11, 17] is proposed in the predictive vector quantization (VQ) domain to embed data into a mesh stream. Transform-domain-based RDH [12, 13] transforms the original models into a certain transform domain and then embed data into the transform coefficients. Objectively, there exists much space to improve the performance for 3D model RDH.
In this paper, we design a double-layered prediction scheme to obtain the PEs with sharp histogram and then propose an optimal three-dimensional PEH modification method using RCC, the purpose is to maximize the EC for the same distortion or minimize the distortion for the same EC for 3D mesh model RDH. Firstly, we divide all the vertices of the input models into the “embedded” set and the “referenced” set according to the odd-even property of their indices into the vertex list, then select vertices on the “embedded” set for data embedding, and use their neighboring vertices on the “referenced” set to estimate the predicted position. By calculating the difference between the real position and the predicted position, we obtain PEs. Because of the geometric similarity among neighboring vertices, the PEH describing the distribution of PEs will be very steep, which is beneficial for RDH. Secondly, by exploiting the correlation among PEs, through combining every three adjacent PEs into one prediction-errors triplet (PET), we construct 3D PEH, and then use an injective mapping function to project 3D PEH into the 1D space for scalar PET sequence. In addition, we define the distortion metrics for 3D models so as to estimate the OTPM which means the optimal PEH modification manner. Next, we modify the PET sequence and embed data using RCC to achieve OTPM. Finally we modify the coordinate for the vertices on the “embedded” set without changing the topology, and at the same time, the vertices on the “referenced” set keep unchanged for sake of data extraction and recovery completely. It should be mentioned that the prediction and embedding procedure can be operated on the “embedded” set and the “referenced” set alternatively for several rounds so as to increase the EC if the distortion is under the limit. Compared to two existing RDH algorithms for 3D mesh models, we can decrease the distortion for the same EC and increase the EC for the same distortion restriction. Experimental results prove that our proposed method has superior performance and it is feasible for 3D mesh model RDH considering the capacity and distortion.
The rest of this paper is organized as follows. Section 2 briefly introduces the RCC for reversible data hiding. The proposed 3D PEH modification method is presented in Section 3. The experimental results and some discussion are demonstrated in Section 4. And finally, the conclusion is drawn in Section 5.
2 Overview for RDH by recursive construction coding
As mentioned above, the PE based RDH methods embed messages by modifying the prediction errors with sharp histogram. Many schemes have been proposed to chase a better balance between the embedding capacity and the distortion. Actually, for a given PE sequence, with a distortion constraint, the upper bound of the payload is given by Kalker and Willems in [7]. They formulated the RDH as a special rate-distortion problem, and obtained the rate-distortion function, i.e., the upper bound of the embedding rate under a given distortion constraint Δ, as follows:
Where X and Y denote the random variables of host sequence and marked sequence respectively. The maximum entropy is over all transition probability matrices P Y|X (y|x) satisfying the distortion constraint \({\sum }_{x,y}P_{X}(x)P_{Y|X}(y|x)D(x,y)\leq {\Delta }\). The distortion metric D(x,y) is usually defined as the square error distortion, D(x,y) = (x−y)2.
Therefore, instead of using expanding and shifting technique for the given PEs, Lin et al [10] proposed a pixel by pixel recursive code construction (RCC) to approach the rate distortion bound for square error distortion. And alternatively, by improving RCC, Zhang et al. [24] obtain the optimal embedding method for general gray-scale PE sequence, which performs in a bin by bin manner respectively.
Assume that the input PE sequence is a single probability distribution histogram, we briefly elaborate the optimal PEH modification procedure to embed data with RCC.
-
Firstly, using the prediction strategy such as rhombus prediction [16] or two dimensional prediction [15], a PE sequence is obtained, which acts as the host signal X in (1).
-
Secondly, in order to minimize the embedding distortion for a fixed length of message payload, use the fast algorithm in [5] to estimate the optimal marginal distribution P Y ( y) of the marked signal Y.
-
Finally, according to the estimated marginal distribution P Y ( y), by modifying the host PE sequence X to the marked PE sequence Y, messages can be optimally embedded through Lin et al’.s code construction [10].
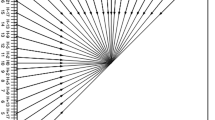
Zhang et al. propose another optimal PEH modification scheme by a bin by bin manner, which is shown in Fig. 1. And the data extraction and cover restoration are executed in a backward manner. For more detail about RCC method, we refer readers to [10].

Illustration of recursive construction coding with a bin by bin manner
It is proved that, for a given host signal and defining the distortion restriction, RCC can approach the rate-distortion bound of RDH for digital images. However, if we want to apply RCC for our 3D case, there exists some problems needed be solved.
-
Firstly, how to construct a host signal (PE sequence) with small entropy? Observing from the rate-distortion formulation (1), a small value of H(X) means more capacity exists in the difference between the two entropies H(Y)−H(X), thus better embedding performance can be achieved.
-
Secondly, if three-dimensional PEH with the smaller entropy than one-dimensional PEH by utilizing the correlation about PEs, how to project the three-dimensional PEH into one-dimensional space to get a scalar sequence which is suitable for RCC?
-
Finally, what is the distortion metrics for 3D mesh models by which we can estimate the optimal transition probability matrix (OTPM) indicating the optimal PEH modification manner?
3 Proposed method
As for the problems we mentioned in Section 2, we propose the solution scheme in this section so as to apply RCC for 3D mesh model RDH. Basically, our proposed RDH scheme is based on three-dimensional PEH modification. Firstly, we design a double-layered prediction method to construct the prediction errors with shape histogram. Then we combine the adjacent three PEs as a prediction-error triplet (PET) and manipulate the three-dimensional PEH which has the smaller entropy than one-dimensional PEH. With an injective mapping function, we project the three-dimensional PEH into one-dimensional PET sequence which is suitable for RCC. At last, we define the distortion metrics which is also significant for guiding the optimal histogram modification manner.
3.1 Prediction scheme
A 3D model represents a 3D object using a collection of points in the 3D space, connected by various geometric entities such as triangles, lines, curved surfaces, etc. Among various of representations for 3D model, polygonal meshes are the most popular by far, thus we use polygonal mesh models in .ply format as our experimental model. For a .ply file, it consists of a header followed by a list of vertices and then a list of polygons, the header specified how many vertices and polygons are in the file, and also states what properties are associated with each vertex, such as (x, y, z) coordinates, normals and color. The vertex list contains the indices of vertices, x-axis coordinate, y-axis coordinate, and z-axis coordinate, and the face list defines the polygon faces which are simply lists of indices into the vertex list, and each face begins with a count of the number of elements in each list.
A polygonal mesh models consists of a set of vertices, as denoted by V = {v 1, v 2,...v N } and a vertex position v i specifies the coordinates {v i x , v i y , v i z } in R 3. The mesh topology means the connectivity between vertices. Two vertices are termed neighbors if one edge connects them so that the vertices in the same face are co-neighbors, thus we can record the neighbors for each vertex efficiently by traversing the face list in order to find the faces which contain the given vertex. Based on this file format property, we design the double-layered prediction scheme for 3D mesh models. It should be noted that, this prediction method is also significant for 3D models in .obj format which is another popular file format for 3D mesh models.
Depending on the odd-even property of indices into the vertex list, we divide the vertices into two sets: the “embedded” set and the “referenced” set. The “embedded” set is used for embedding data and the “referenced” set is used for prediction, and if needed, we can use the “referenced” set to embed data and use the modified “embedded” set for prediction at the second round. This alternative procedure can be operated several rounds to increase the EC if the distortion is under the limited. It should be mentioned here, without loss of generality, these two sets are independent with each other, which means changing the coordinates of vertices on the “embedded” set do not affect vertices on the “referenced” set, and vice versa. With the use of this independent property, we make sure the coordinates of predicted vertices keep unchanged, for sake of extracting data and restoring cover losslessly.
Since the multi-round prediction and data embedding process are similar, we only use the first-round procedure for illustration, which is shown in Fig. 2, and Table 1 shows the file format for this local region. In Fig. 2, the labeled numbers are vertex indices into the vertex list, and the vertices with odd index are defined as the “embedded” set for embedding (square point), while the vertices with even index belong to the “referenced” set for prediction (circle point). We traverse all the vertices on the “embedded” set in ascending order by their indices and find their neighbors on the “referenced” set. Through calculating the difference between the real position and predicted position, we construct the PEs sequence. For example, 1 is firstly traversed, we traverse the face list to find the faces containing 1, by this we record 2, 3, 4, 5, 6, 13 as its neighboring vertices, and then we select the neighboring vertices belong to the “referenced” set, which are 2, 4, 6, to predict the position of 1, because they will not be changed in the first-round embedding process for sake of reversibility. Similarly, we use 2, 4, 8 to predict 3, and, 4, 6, 10 for 5, keep this way until all the vertices on the “embedded” set have been predicted.

The illustration of the prediction method
It should be mentioned here, we predict the position of the vertices on the “embedded” set by calculating the average coordinate value of their neighboring vertices belonging to the “referenced” set. Just taking vertex 1 as an example, the real coordinate of v 1 = {v 1x , v 1y , v 1z }, and the predicted coordinate of \({{v}_{1}^{\prime }}\) =\(\{{{v}_{1x}^{\prime }},{{v}_{1y}^{\prime }},{{v}_{1z}^{\prime }}\}\), the prediction-error e 1 can be represented by:
In previous work [6], the distance difference between real position and predicted position was usually used for embedding data so that it only embedded one data by per target vertex. However, in our proposed algorithm, through modifying {e i x , e i y , e i z }, we can embed three bits of data with the use of e i , in this way, we can improve EC three times if the number of target vertices is the same. Therefore, we calculate the difference for traversing all the vertices on the “embedded” set and then obtain the prediction errors which contain {e 1x , e 1y , e 1z , e 3x , e 3y , e 3y ...e (N−1)x , e (N−1)y , e (N−1)z } if there is N vertices in the mesh models and N is even. Because of the geometric similarity of neighboring vertices, the prediction is accurate so that the PE sequence obeys a Laplacian-like distribution centered at 0 or close to 0, which is shown in Fig. 3. Due to the restriction for showing composite 3D PEH in the paper, we only give the separated PEH for x-axis, y-axis and z-axis respectively.

Prediction-Error Histogram
It should be noted that, followed by [21], we also use truncation function to truncate the part under the precision level. If the coordinates in the original mesh are at the precision level of 10−n, before our prediction, all the coordinates of vertices multiply by 10m and truncate the decimal part, where m ≤ n and m is usually set to 3 or 4. By this, we operate the embedding algorithm on integer arithmetic, thus we need to divide the coordinate of vertices by 10m after data embedding to reconstruct the marked mesh models.
For the PE sequence obtained by our prediction scheme, we can generate one-dimensional PEH by counting the frequencies of PEs, then embed data by modifying the PEH through expansion, shifting, even RCC which has been proved the optimal histogram modification manner in Section 2. But intuitively, it is not the best choice to rudely manipulate the one-dimensional PEH because it has not exploited the spatial correlation for 3D models. In our 3D case, the PE sequence {e 1x , e 1y , e 1z , e 3x , e 3y , e 3z ...} is not independently distributed. In fact, adjacent PEs are usually highly correlated, especially for {e i x , e i y , e i z }, because the difference between real position and predicted position for v i is:
One words to remark, there also exits the correlation between {e i x , e i y , e i z } and {e j x , e j y , e j z }, but it is beyond the scope of this paper and would be done in our future work. Thanks to the correlation property, we propose to construct a three-dimensional PEH where the correlations within PET can be exploited, in order to achieve a better performance for RDH by decreasing the entropy of host signal X. By considering every three adjacent PEs together, the sequence {e 1x , e 1y , e 1z , e 3x , e 3y , e 3z ...} can be transformed into a new PET sequence {e 1, e 3,...e N−1} with {e i = e i x , e i y , e i z , i = 1,3...N−1}, and the associated 3D PEH is
Where # denotes the cardinal number of a set. For simplicity, the sequence {e 1x , e 1y , e 1z , e 3x , e 3y , e 3z ,...,e (N−1)x , e (N−1)y , e (N−1)z } is denoted as (X,Y,Z) and {e 1x , e 3x ,...,e (N−1)x }, {e 1y , e 3y ,...,e (N−1)y }, {e 1z , e 3z ,...,e (N−1)z } are denoted as X, Y, Z, respectively. The function H calculates the entropy of a distribution and we can clearly get the inequation as follows
It demonstrates that three-dimensional PEH utilizes the correlation among PEs compared to one-dimensional PEH and has a potential to yield an improved RDH, so it is significant to combine every three adjacent PEs into one PET, from the beginning to the end of the PE sequence.
3.2 3D PEH to 1D PET sequence
To apply RCC for our 3D case, we project the 3D PEH into the 1D space to get a scalar sequence by using an injective mapping function P r o j e c t() defined by
For simplicity, we set T = 1 and use Fig. 4 to show the injective mapping relationship.

Mapping relationship
For the PE sequence, we set a threshold parameter T to avoid modifying the PEs with too large magnitude so that the selected PET meets |e i x | ≤ T, |e i y | ≤ T and |e i z | ≤ T. And also, Euclidean distance between the real position and predicted position measures the prediction accuracy, thus it is reasonable to utilize the Euclidean of {e i x , e i y , e i z } as our sorting method and we set the threshold T E D for selecting PET. The sorting technique benefits RCC, because a sharper histogram has a smaller entropy so that better rate distortion performance is gained, and also, the sorting technique shortens the bit length of the compressed PEH since the number of PEs is decreased. It should be noted that the amplitude threshold T and sorting threshold T E D can be tuned to achieve different results, for the given embedding rate. How to find the best values for these threshold parameters in the proposed method remains a problem to be researched in the subsequent work.
3.3 The distortion matrix
For one-dimensional PE sequence, D(x,y) is usually defined as the square error distortion, D(x,y) = (x−y)2, because the algorithm performance for RDH is evaluated by:
In our 3D case, the geometrical distortion of a mesh model including N vertices after adding some noise to the mesh content can be measured by SNR which is defined as follows:
Where \(\{{{\bar {v}}_{x}},{{\bar {v}}_{y}},{{\bar {v}}_{z}}\}\) is the mean coordinates of models, {v i x , v i y , v i z } is the original coordinates of v i , {g i x , g i y , g i z } is the modified coordinates of v i . Clearly, from (10), the distortion metric \(D(e_{i},e_{i}^{\prime })\) should be defined by the Euclidean distance between the corresponding PET e i and \(e_{i}^{\prime }\):
As mentioned above, the distortion metric is significant when using RCC for data embedding, because it is related to the OTPM. For example, as for the PET (e 1x , e 1y , e 1z ) = (0, 0, 0), by embedding data, it could be changed to (0, 0, 0), (0, 0, 1), (0, 1, 0), (1,0,0), (0, 1, 1), (1, 0, 1), (1, 1, 0), (1, 1, 1), as shown in Fig. 5a, but the distortion with these eight situations are different, with the guidance of distortion metrics, we hope to modify (0, 0, 0) to (0, 0, 0), (0, 0, 1), (0, 1, 0), (1, 0, 0) with high probability, but not (0, 1, 1), (1, 0, 1), (1, 1, 0), (1, 1, 1), as shown in Fig. 5b, unless the available EC provided by (0, 0, 0), (0, 0, 1), (0, 1, 0) and (1, 0, 0) is insufficient. In summary, after selecting the PET with higher prediction accuracy, we also want to embed data with less distortion.

adaptively modification with less distortion
3.4 Procedure of proposed algorithm
With double-layered prediction scheme, we obtain the PE sequence, and using (6), we project the 3D PEH into 1D space for scalar PET sequence which is suitable for RCC. After defining the distortion metric, we can estimate the optimal P Y|X (y|x) for the given restriction by using a two-stage scheme described in [15]. Firstly, we use the fast algorithm in [5] to get the marginal distribution P Y (y) and the corresponding dual variable. Secondly, we use the solution for linear program in [25] to finally estimate the OTPM, which indicates the optimal modification manner. After that, we can modify the host sequence into the marked sequence and optimally embed data through RCC. Finally, by adding the marked PE sequence to the prediction position and refreshing the vertex coordinate, we can get the marked 3D mesh model.
Figure 6 is the framework of our proposed method. Even though the prediction and embedding processing can be operated on the “embedded” set and the “referenced” set alternatively for several rounds in order to increase EC, without loss of generality, we only introduce the embedding and extraction procedure on the “embedded” set at the first round. The detail is listed in Algorithm 1.

Procedure of our proposed RDH algorithm

4 Experimental result
Our proposed method processes 3D model and operates reversible data hiding with the experimental environment of MATLAB R2014 and OpenGL under windows 7, and we download 3D mesh models with .ply format and .obj format from Stanford University library, including “Bunny”, “Dragon”, “Armadillo”, “horse”, “lion”, “hand”, “happy” and so on. Compared to the algorithm proposed by Wu in [21] and Huang in [6], by embedding randomly generated 0/1 bit strings within the same models and setting the same parameter, we want to show that our algorithm is superior to the others.
Firstly, we present the experimental results of our proposed algorithm. Table 2 lists the SNR values by different embedding rates for kinds of 3D models, here we use bits per vertex (bpv) to measure the embedding capacity which equals to the length of embedded bits dividing the amounts of vertex. There are two things needed to be mentioned:
-
The results on the table is derived from the first round embedding procedure. We can increase the embedding capacity by several rounds if the distortion is accepted.
-
For one round, the embedding performance for different models is not the same, as shown in Fig. 8. Especially for “Hand” and“Dragon”, the performance is totally different.
We firstly compare the mesh traversing strategy analogy with the raster-scan order for digital images in [21], the PEH got by Wu et al.’s method is listed in Fig. 7a, and that of the proposed method is listed in Fig. 7b. Obviously, the PEH in our proposed method is more centered distributed, which means it will achieve better performance for reversible data hiding, because it has a smaller entropy.

Prediction-Error Histogram for “bunny” got by Wu’s method and ours

PSNR-Payload curve for “horse” model with 48485 vertices and 96966 faces
We define the complexity of models according to the 3D object shape and surface roughness, “Dragon” belongs to complex models and “Hand” belongs to simple models. It seems that the complex model is weaker for data embedding compared to the simple model, probably because the complex surface makes the prediction worse, which leads to the PEs within the threshold are limited (Fig. 8). We will analysis the influence caused by model shape and surface roughness on data embedding in our subsequence work.
Table 3 shows the SNR value with different embedding rate for “bunny” and “horse”, and it proves that our algorithm can achieve a large embedding rate. Figures 9 and 10 show their visual effect with different embedding rate, if the embedded message is not too much, we can keep the distortion under the acceptable limit. Compared to the prediction-error expansion algorithm proposed by Wu et al. in [21], setting the same parameter, our proposed method is obviously better than theirs and the results for “bunny” and “horse” are shown on Fig. 11.

Visual effect for bunny with different embedding capacity

Visual effect for horse with different embedding capacity

SNR-Capacity curve for “bunny” and “horse”
Compared to the histogram shifting algorithm which was described as the best of histogram-based algorithm for 3D models proposed by Huang in [6], we use Table 4 to support our benefits. Due to the reason that Huang et al. do not give the SNR value for model distortion in his paper, we just put emphasis on the maximal embedding capacity within the same distortion percentage. For “VenusHead”,“Dragon”, “Armadillo” and “Golfball” which appeared in his paper, we give our results. From the comparison, we prove that our method can increase the embedding capacity with the same distortion. In Huang’s method, the histogram construction is based on the geometric similarity between neighboring vertices. But the geometric similarity they proposed is not able to generate a sharply distributed histogram. As a result the distortion caused by histogram shifting is large. Only by decreasing the embedding capacity can their method achieve a satisfactory visual effect of the stego model with the secret message embedded. Thus their embedding capacity is small.
In this paper, we proposed several improved steps in order to apply RCC for 3D mesh models and by this we hope to realize the optimal 3D mesh model RDH. From the results in the section, we proved that our algorithm can decrease the distortion which is measured by SNR for the same embedding rate, and increase the embedding capacity with the same embedding distortion. Thus, our algorithm is better than the state-of-the-art spatial-domain RDH algorithms for 3D models, and our superiority is mainly thanks to projecting the three-dimensional PEH into one-dimensional space by utilizing the correlation among PEs and defining suitable distortion matrix for RCC.
5 Conclusion
In this paper, we propose 3D mesh model RDH with the optimal three-dimensional PEH modification using RCC. We firstly design a double-layered prediction scheme to obtain PEs with a shape histogram by utilizing the geometrical similarity among neighbouring vertices. Next we combine every three PEs into one PET in order to construct the 3D PEH with smaller entropy than 1D PEH by exploiting the correlation among PEs, and then project the 3D PEH into 1D space for scalar PET sequence which is suitable for RCC. And also, we define the distortion metrics for 3D models, by which we estimate the OTPM by two-step strategy. Finally, we modify the PET sequence and optimally embed data through RCC in order to achieve the optimal PEH modification. Without changing the topology and keep the vertices for prediction unchanged in the embedding process, we guarantee the reversibility of our method. As a result, we can operate the prediction and embedding procedure for several rounds in order to increase EC if the distortion is under the limit. Compared to two state-of-the-art spatial-domain RDH for 3D models, experimental results show that our proposed algorithm is significantly better than others.
The proposed framework shows its generalizing ability and good performance for 3D mesh model RDH. But as mentioned in our paper, how to design a better prediction scheme to maximally exploit the geometrical similarity of 3D models, how to greatly explore the correlation between PETs, and how to adaptively select the threshold for RDH based on the model shape and surface roughness, will be our future work.
References
Coltuc D (2012) Low distortion transform for reversible watermarking. IEEE Trans Image Process 21(1):412–417
Chou D, Jhou CY, Chu SC (2009) Reversible watermark for 3D vertices based on data hiding in mesh formation. Int J Innov Comput Inf Control 5(7):1893–1901
Fridrich J, Goljan M, Du R (2002) Lossless data embedding for all image formats. In: International Society for Optics and Photonics, pp 572-583
Hu Y, Lee HK, Li J (2009) DE-based reversible data hiding with improved overflow location map. IEEE Trans Circ Syst Vid Technol 19(2):250–260
Hu X, Zhang W, Hu X et al (2013) Fast estimation of optimal marked-signal distribution for reversible data hiding. IEEE Trans Inf Forensic Secur 8(5):779–788
Huang YH, Tsai YY (2015) A reversible data hiding scheme for 3D polygonal models based on histogram shifting with high embedding capacity. 3D Res 6(2):1–12
Kalker T, Willems FMJ (2003) Capacity bounds and constructions for reversible data-hiding. In: International Society for Optics and Photonics, Electronic Imaging, pp 604–611
Luo L, Chen Z, Chen M (2010) Reversible image watermarking using interpolation technique. IEEE Trans Inf Forensic Secur 5(1):187–193
Li X, Yang B, Zeng T (2011) Efficient reversible watermarking based on adaptive prediction-error expansion and pixel selection. IEEE Trans Image Process 20(12):3524–3533
Lin SJ, Chung WH (2012) The scalar scheme for reversible information-embedding in gray-scale signals: Capacity evaluation and code constructions. IEEE Trans Inf Forensic Secur 7(4):1155–1167
Lu ZM, Li Z (2007) High capacity reversible data hiding for 3D meshes in the PVQ domain. In: Digital Watermarking, Springer Berlin Heidelberg, pp 233–243
Luo H, Lu ZM, Pan JS (2006) A reversible data hiding scheme for 3D point cloud model. In: IEEE International Symposium on Signal Processing and Information Technology, pp 863–867
Luo H, Pan JS, Lu ZM (2006) Reversible data hiding for 3D point cloud model. In: IEEE International Conference on Intelligent Information Hiding and Multimedia Signal Processing(IIH-MSP), pp 487–490
Ni Z, Shi YQ, Ansari N (2006) Reversible data hiding. IEEE Trans Circ Syst Video Technol 16(3):354–362
Ou B, Li X, Zhao Y (2013) Pairwise prediction-error expansion for efficient reversible data hiding. IEEE Trans Image Process 22(12):5010–5021
Sachnev V, Kim HJ, Nam J (2009) Reversible watermarking algorithm using sorting and prediction. IEEE Trans Circ Syst Video Technol 19(7):989–999
Sun Z, Lu ZM, Li Z (2006) Reversible data hiding for 3D meshes in the PVQ-compressed domain. In: IEEE International Conference on Intelligent Information Hiding and Multimedia Signal Processing(IIH-MSP), pp 593–596
Tian J (2003) Reversible data embedding using a difference expansion. IEEE Trans Circ Syst Vid Technol 13(8):890–896
Thodi DM, Rodrguez JJ (2007) Expansion embedding techniques for reversible watermarking. IEEE Trans Image Process 16(3):721–730
Tsai P, Hu YC, Yeh HL (2009) Reversible image hiding scheme using predictive coding and histogram shifting. Signal Process 89(6):1129–1143
Wu H, Dugelay JL (2008) Reversible watermarking of 3D mesh models by prediction-error expansion. In: IEEE 10th Workshop on Multimedia Signal Processing, pp 797–802
Wu H, Cheung Y (2005) A reversible data hiding approach to mesh authenticationWeb Intelligence. In: The 2005 IEEE/WIC/ACM International Conference on Proceedings, pp 774–777
Zhang W, Chen B, Yu N (2012) Improving various reversible data hiding schemes via optimal codes for binary covers. IEEE Trans Image Process 21(6):2991–3003
Zhang W, Hu X, Li X et al (2013) Recursive histogram modification: establishing equivalency between reversible data hiding and lossless data compression. IEEE Trans Image Process 22(7):2775–2785
Zhang W, Hu X, Li X, et al (2015) Optimal transition probability of reversible data hiding for general distortion metrics and its applications. IEEE Trans Image Process 24(1):294–304
Acknowledgments
This work was supported in part by the Natural Science Foundation of China under Grant U1636201, 61572452, 61502007, and in part by the China Postdoctoral Science Foundation under Grant 2015M582015.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Jiang, R., Zhang, W., Hou, D. et al. Reversible data hiding for 3D mesh models with three-dimensional prediction-error histogram modification. Multimed Tools Appl 77, 5263–5280 (2018). https://doi.org/10.1007/s11042-017-4430-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-4430-6