
Abstract
In the recent environmental protection the reverse logistics of the used product is one of the most important research topics. The reverse logistics is the process flow of used-products that are collected to be reproduced so that they can be sold again to customers after some processing. We propose a multi-objective hybrid genetic algorithm (mo-hGA) combined with Fuzzy Logic Controller (FLC) for efficiently dealing with multi-objective reverse logistics network (mo-RLN) problem. The aim of this paper is firstly to formulate mo-RLN model, and secondly to optimize it by mo-hGA method proposed with reusable system configuration. In particular two objective functions to be minimized total costs of mo-RLN, (i.e. fixed opening cost, transportation cost and inventory cost) and also minimized delivery tardiness in all periods are considered in the model. We will clear each objective function (i.e. total costs and total delivery tardiness), computational time and number of Pareto solutions with LINGO, pri-awGA (priority-based GA with adaptive weight approach) and mo-hGA proposed with numerical examples. For demonstrating the effectiveness of the proposed model, we evaluate with the numerical examples and simulate it with a bottles distilling/sale company as a case study in Busan, Korea.
Similar content being viewed by others


1 Introduction
Reverse logistics (RL) is now the focus of attention in logistics field to realize resources recycling and low carbon society. The target of the reverse logistics is the flow from recovered end-of-life products to their reusable products. Increasing the environment regulation, the reverse logistics has been emphasized by the following reasons: the economic effect resulted from the cost reduction of raw materials in manufacturing process, the propensity to consume changed to environment-friendly products, and the business strategy tried to improve a corporate image.
However, the reverse logistics is different from the traditional forward logistics in which new materials or parts are produced and sold to customers. In the reverse logistics, it is not only hard to predict the appearing time or amount of arrivals by a period of use or conditions of recovered products, but also their recovery routes are complex as a large number of recovery centers. Moreover, even though the recovery products are environment-friendly, its market is not large yet because of the stereotype of customers who regard the recovery product as the used goods. Also, the reverse logistics costs more than the traditional forward logistics to construct and operate the system.
Logistics network design is one of the most important strategic decisions in supply chain management. Decisions on the number of facilities, their locations and capacities and the quantity of flow among then affect both costs and customer service levels. As such, effective and efficient supply chain design can constitute a sustainable competitive advantage for firms [27]. The application of reverse logistics network design problem ranges widely from the linear model to the complex non-linear model and from the minimization of delivery cost for single product to the complex multi-objective optimization problem [1]. Almost every important real world problem involves more than one objective. Hence, considering the multiple objectives concurrently is a favourable option for most decision makers. The strategic issue of reverse logistic network design may affect both a company’s profitability and the customer service level [6].
For solving the logistics problem, the concepts of delivery lead time and inventory as well as cost and the customer satisfaction are important. In a supply chain, key variables that have to be considered for each activity are its activity level and timing, the inventory level and lead times and other delays [4]. Defined as the time that elapses between the placement of an order and the receipt of the order into inventory, time may influence customer service and impact inventory costs [14]. Lead times and integrative dynamics make the inventory control task harder. Therefore, they play an important role in the design of the inventory replenishment strategies [8].
The multi-objective optimization problem to optimize many objects simultaneously arises over various areas from management economy to engineering. To solve the multi-objective problem, lots of theories and methods have developed for the 50 years. Due to the complexity and diversity, the problem has been researched lively until the present. Since the objective functions of multi-objective problem conflict each other generally, the sacrifice of other objects is required for raising one object. To decide which object is raised up and which object is sacrificed, the preference of decision maker for each object should be reflected. In other words, among the various efficient or non-dominated values, to find the most preferred value is the solving process of multi-objective problem [24].
Since the majority of logistics network design problems can be categorized as NP-hard, many powerful heuristics, meta-heuristics and Lagrangian relaxation (LR)-based methods have been developed for solving these models [27]. Real-size problems of the resulting multi-objective mixed-integer programming (mo-MIP) cannot be solved using exact methods. Therefore, a multi-objective genetic algorithm is designed to solve the large-size problems its results for small-size problems are compared with the results obtained from LINGO optimization software, in order to verify the performance of the proposed GA [7]. The evolutionary algorithm has the merit that various values can be considered by managing the population comprised of many values [30].
In this paper, the multi-objective reverse logistics network design problem has considering minimization of total cost and minimization of total delivery tardiness, that thus it becomes even more complex. Ko and Evans [16] argued that the genetic algorithm (GA) can be used to effectively solve the reverse logistics. Sha and Che [29], Altiparmak et al. [1], and Xu et al. [34] had applied GA slightly to deal with supply chain problems. Hence, this paper presents the mo-hGA based on pri-awGA (priority-based GA with adaptive weight approach) for solving the multi-objective optimization mathematical model in reverse logistics.
The main purposes of the paper are described as follows: (1) formulating a mathematical model of multi-objective optimization for reverse logistics. This model considers minimization of total cost and minimization of total delivery tardiness. This paper explores the tradeoffs associated with these two objectives in the reverse logistics network design. Namely, the different of this paper from other studies in literature is that it considers cost in reverse logistics field and time concept in delivery tardiness in multi-time period, simultaneously. This problem is combined with three reverse processes, i.e., retuning, processing and manufacturing, (2) proposing a multi-objective hybrid GA (mo-hGA) model for solving the multi-objective optimization model. Principally, mo-hGA based on pri-awGA (priority-based encoding GA method with adaptive weight approach) is improved the searching ability of GA through adjusting the parameter appropriately in each generation using FLC and making a suitable situation by the optimal solution search and (3) demonstrating the solving efficiency between mo-hGA and pri-awGA to verify that mo-hGA is superior in calculation capabilities.
This paper is organized as follows: in Section 2 begins with a literature review. in Section 3, the problem is defined more concretely and the mathematical model of the multi-objective reverse logistics network is introduced; in Section 4, the priority-based encoding method and adaptive weight approach (AWA) are explained in order to solve this problem; in Section 5, numerical experiments are presented to demonstrate the efficiency of the proposed method; finally, in Section 6, concluding remarks and future research are outlined.
2 Literature review
2.1 Delivery lead time and inventory
Ulku and Bookbinderm [32] investigated the effects of different pricing schemes for a Third Party Logistics (3PL) provider. In a price and time-sensitive logistics market, they derived the optimal quotations that should be made for price and delivery-time, with the objective of maximizing the profit rate of the 3PL provider. They proposed four easy-to-use temporal pricing schemes, and derive the corresponding optimal length of shipment consolidation cycles and the prices. Barnes-Schuster et al. [3] examined delivery lead time and its impact on the costs of a two-stage serial and an arborescent supply chain. They demonstrated the link between delivery lead time and the location of system safety stock. Xu [33] studied a single-product, multi-period, stochastic inventory model that imposes the lower and upper bounds on the cumulative order quantity during a planning horizon and includes two delivery lead times. They also developed an algorithm to calculate the optimal capacity when the minimum cumulative order quantity commitment was a certain percentage of the capacity. Ray and Jewkes [28] modeled an operating system consisting of a firm and its customers, where the mean demand rate was a function of the guaranteed delivery time offered to the customers and of market price, where price itself was determined by the length of the delivery time. Keren [15] considered single-period inventory problem (newsvendor problem) with a known demand and stochastic supply. Two types of yield risks were considered: additive and multiplicative. The model was then extended for achieving supply chain coordination and integration. They showed that the distributor’s problem can be formulated as a mathematical programming problem, where the optimum solution of the producer was a constraint. de Brito and van der Laan [5] investigated the impact of imperfect information on performance with respect to inventory related costs. They showed that in the case of imperfect information the most informed method does not necessarily lead to best performance. The results had relevant implications regarding investments in product return information systems. Tempelmeier [31] considered a single-item inventory system where two demand classes with different service requirements were satisfied from a common inventory.
2.2 Multi-objective reverse logistics
Du and Evans [6] developed a bi-objective optimization model involving a manufacturer outsourcing to a third-party logistics (3PLs) provider for its post-sale services. Authors were developed a bi-objective MIP optimization model for the reverse logistics network problem, with one objective related to the overall costs and the other related to customer satisfaction. And, they minimized tardiness and total costs for location and capacity decisions in a closed-loop logistics network operated by third party logistics (3PL) providers. To solve the bi-objective MIP model, they developed three algorithms; scatter search, the constraint method and the dual simplex method. Pati et al. [25] studied the inter-relationship among multiple objectives of a recycled paper distribution network. The paper considered a mixed integer goal programming (MIGP) model which is consists of three objective/goals; reverse logistics cost, non-relevant wastepaper target, Wastepaper recovery target. The proposed model assisted in determining the facility location, route and flow of difference varieties of recyclable wastepaper in the multi-item, multi-echelon and multi-facility environment. Alumur et al. [2] proposed a profit maximization modeling framework for reverse logistics network design problems. They focused on return streams with profit potential for the original equipment manufacturers (OEM). Pishvaee et al. [26] presented a bi-objective mixed integer non-linear programming (MINLP) model for integrated forward/reverse logistics network design. To solve the MINLP model, a multi-objective memetic algorithm (MOMA) with dynamic local search mechanism was designed to find the non-dominated set of solutions. The numerical results showed that the proposed MOMA algorithm outperformed the existing MOGA in terms of average ratio of Pareto-optimal solutions obtained.
3 Problem definition and mathematical model
3.1 Problem definition
When a retailer places replenishment orders on products, cost and delivery are the two key factors. Logistic costs constitute the major part of a supply chain’s costs. Inventory control and distribution planning, as fundamental logistical processes, affect the total costs of the supply chain to a great on the customers’ service level [7].
This paper considers the multi-objective reverse logistics network problem (mo-RLN) with the concepts of costs and time according to tardiness principles. A mathematical model is formed to determine the amount of each product, which should be shipped between two locations in each time period of, during a planning horizon. Besides, the objective function is to minimize the total costs of the reverse logistics including fixed opening, transportation and inventory costs. Another objective function is considered, namely “delivery tardiness”. In the reverse logistics, to meet the due date of customer is more difficult than the general forward logistics because of the uncertain recovery amount of end-of-life products. Therefore, the breakaway of consumer resulted from complain of delay can be prevented by minimizing the waiting time through considering the delivery tardiness, second objective function.
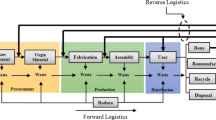
As shown in Fig. 1, there are customer zones, several returning centers, several processing centers, and one manufacturer in this network where the reverse logistics recover products to the customers.

Network model of revese logistics
It is assumed that within a certain delivery time customers are satisfied with the service; and beyond that expected delivery time customers to some extent are unsatisfied with the service. Thus, in this paper, the total delivery tardiness is used to measure the customer’s satisfaction level.
The reverse logistic network design may involve a trade-off relationship between the total costs and the total delivery tardiness. For example, in some cases, the companies may need to open more facility locations in order to decrease the total delivery tardiness and fulfill higher customer satisfaction, which may lead to a greater fixed opening cost.
3.2 Mathematical model for mo-RLN
The following assumptions are made in the development of the model:
-
A1:
The safety inventory in processing center is eliminated.
-
A2:
Only one product is treated in reverse logistics network model.
-
A3:
The inventory factor is existed over finite planning horizons.
-
A4:
The requirement by manufacturer and the quantity of collected products is known in advanced.
-
A5:
The maximum capacities about two echelons are known: returning centers and processing centers.
-
A6:
All of inventory holding costs of processing centers are same.
The parameters, decision variables, objective functions, and restrictions in this closed-loop supply chain model are as follows.
- i :
-
index of returning center (i = 1,2,…, I)
- j :
-
index of processing center (j = 1,2,…, J)
- t :
-
index of time period (t = 1,2,…, T)
- I :
-
number of returning centers
- J :
-
number of processing centers
- M :
-
number of manufacturers
- T :
-
planning horizons
- a i :
-
capacity of returning center i
- b j :
-
capacity of processing center j
- d M (t):
-
demand in manufacturer M in period t
- r i (t):
-
the amount of end-of-life product recovered to returning center i in period t
- c ij :
-
unit cost of transportation from returning center i to processing center j
- c jM :
-
unit cost of transportation from processing center j to manufacturer M
- c j op :
-
the fixed opening cost for processing center j
- c j H :
-
unit holding cost of inventory per period at processing center j
- d ij :
-
delivery time from returning center i to processing center j
- d jM :
-
delivery time from processing center j to manufacturer M
- p j :
-
processing time for reusable product in processing center j
- t E :
-
expected delivery time by customers
- x ij (t):
-
amount shipped from returning center i to processing center j in time period t
- x jM(t):
-
amount shipped from processing center j to manufacturer M in time period t
- y j H(t):
-
inventory amount delivered to processing center j in time period t
The first objective function f 1 of the total cost consists of the fixed opening cost of installing processing centers, the transportation cost of returning centers, processing centers and manufacturer and inventory cost of processing centers:
The second objective function f 2 of the total delivery tardiness is represented by the total delivery tardiness
3.3 Model formulation
minimize {f 1, f 2}
subject to the following constraints:
Equations (1) and (2) give the objectives. Constraint (3) represents the recovered amount of end-of-life product. Constraints (4) and (5) represent the capacity of processing center and manufacturer respectively. Constraint (6) represents the inventory amount of processing center. Constraint (7) imposes the non-negativity of decision variables x ij (t), x jM (t) and y j H(t). Constraint (8) assures the binary integrality of decision variables z j .
4 Solution approach
4.1 Optimization algorithm by pri-awGA
4.1.1 Chromosome representation
We expanded the priority-based encoding method developed Gen and Cheng [10] as a double priority-based chromosome. Although this encoding had been successfully applied on shortest path problem and project scheduling problem [10], the difference of our approach comes from the facts that of special decoding and encoding procedures for transportation trees. The priority-based encoding method is an indirect approach. In this method, a gene in chromosome contains two kinds of information: the locus, the position of the gene within the structure of a chromosome, and the allele, the value the gene takes. The position of a gene is used to represent a node (source depot), and the value is used to represent the priority of the node for constructing a tree among candidates. For a transportation problem, a chromosome consists of priorities of sources and depots to obtain transportation tree and its length is equal to total number of sources m and depots n, i.e. m + n. The transportation tree corresponding with a given chromosome is generated by sequential arc appending between sources and depots. At each step, only one arc is added to tree selecting a source (depot) with the highest priority and connecting it to a depot (source) considering minimum cost [11].
The chromosome consists of two stages, in which each stage is related to one stage of the mo-RLN (Fig. 2).

An illustration of mo-RLN model chromosome
4.1.2 Adaptive weight approach (AWA)
While we consider multi-objective problem, a key issue is to determine the weight of each objective. Gen et al. [12] proposed an Adaptive Weight Approach (AWA) that utilizes some useful information from the current population to readjust weights for obtaining a search pressure toward a positive ideal point [34]. In this study, we are using the following objectives:
-
(1)
Minimization of total cost (c T )
-
(2)
Minimization of total delivery tardiness (t D )
-
Min f 1 = total cost
-
Min f 2 = total delivery tardiness
For the solutions at each generation, z q max and z q min are the maximal and minimal values for the qth objective as defined by the following equations:
The adaptive weights are calculated as
The weighted-sum objective function for a given chromosome is then given by the following equation
4.2 Optimization by mo-hGA (multi-objective hybrid genetic algorithm)
Fuzzy logic is mathematical formal multi-valued logic concept which uses fuzzy set theory. Its goal is to formalize the mechanisms of approximate reasoning. Fuzzy logic has widely been applied in various areas. Fuzzy control is one prominent example. In fuzzy control, data is characterized by linguistic variables and expert knowledge (if-then-rules) using these variables are mapped into rule vases [17].
For improving disadvantage of simple GA approach to the reverse logistics problem, this paper advocates modifying some components of GAs, such as chromosome representation to meet the reverse logistics network problem; combine Fuzzy logic Controller to updating probability of the crossover and mutation with considering changes of average fitness in the GA population of two continuous generations [13].
4.3 Genetic operators
4.3.1 Crossover operator
WMX can be viewed as an extension of one-cut point crossover for permutation representation. As one-point crossover, two chromosomes (parents) would be chose a random cut-point and generate the offspring by using segment of own parent to the left of the cut-point, then remapping the right segment that base on the weight of other parent of right segment. In the study, Weight Mapping Crossover (WMX) proposed by Gen et al. [12] is adopted.
4.3.2 Mutation operator
Mutation is a background operator which produces spontaneous random changes in various chromosomes. Similar to crossover, mutation is done to prevent the premature convergence and explores new solution space. However, unlike crossover, mutation is usually done by modifying gene within a chromosome. This swap mutation is adopted to generate offspring in this study. The swap mutation selects randomly the pairs of the gene exchanged in eight genes and exchanges the selected genes.
4.3.3 Immigration operator
The trade-off between exploration and exploitation in serial GAs for function optimization is a fundamental issue. If a GA is biased towards exploitation, highly tit members are repeatedly selected for recombination. Although this quickly promotes better members, the population can prematurely converge to a local optimum of the function. Moed et al. [23] proposed an immigration operator which, for certain types of functions, allows increased exploration while maintaining nearly the same level of exploitation for given population size. It is an example of a random strategy which explores the search space ignoring the exploitation of the promising regions of the search space. The algorithm is modified to (1) include immigration routine, in each generation, (2) generate and (3) evaluate popSize•p I random members, and (4) replace the popSize•p I worst members of the population with the popSize•p I random members (pI, called the immigration probability) [20].
4.3.4 Selection operator
Selection operator is intended to improve the average quality of the population by giving the high-quality chromosomes a better chance to get copied into the next generation. In this paper, binary tournament selection is adopted. Binary tournament selection strategy is the selecting operation based on the fitness, which organizes K tournament groups randomly, generates U{0,1} random numbers, selects the gene with highest fitness when it is smaller than critical value, and reproduces it until being included in population of next generation. The selecting operation is repeated till the genes are selected as size for the population and forms the population of next generation.
The overall procedure of proposed mo-hGA;

5 Computational results
To evaluate the performance of mo-hGA proposed for solving multi-objective reverse logistics network (mo-RLN) design problem, mo-hGA is compared with the pri-awGA (priority-based encoding GA with adaptive weight approach). Also, we compared with a percentage gap of LINGO [21]. The reason for selecting pri-awGA as a basis of comparison is its similarity to mo-hGA in using a priority-based encoding method and adaptive weight approach.
5.1 Data generation
The sizes of the test problems considered by some researchers are lists in Table 1.
As it is seen in the Table 2, while the number of returning centers changes between 5 and 6233 on these problems, number of processing center changes between 3 and 59.
The data in test problems such as transportation costs, demand of products, capacitates of retailers, recovery centers and plant were also randomly generated to provide realistic scenarios.
All the test problems are solved on a Pentium 4, 3.20GHz clock pulse with 1GB memory. We ran the procedure for 30 times for each problem considering the following parameters:
-
Population size, popSize = 100;
-
Maximum generations, maxGen = 1000;
-
Initial crossover probability, p C = 0.7;
-
Initial mutation probability, p M = 0.3
5.2 Case study
The problem of optimizing the bottle distilling and sales company in Busan, Korea was simulated with a case study of the company’s real data. Illustration of this case study is shown in Fig. 3. In the reverse logistics flow, the empty bottle collected in the retailer is delivered to the manufacturing plant through the returning center and after processing process, reused. The empty bottle to be collected is a Soju bottle and it collects every day. The collected bottles are reusable until about 10 times. Specifically, the recovery rate of empty bottle and reusable rate are high, and it is around 97 % in the company in 2007. The empty bottles collected in retailers are delivered to a manufacturing plant through recovery centers of three kinds: shopping center, farming store, and recycle dealer. The recovery center is assumed to 188 minimum administrative areas. Figure 3 shows the location of 188 retailers, 59 recovery centers, and 1 plant of this company. The signs in Fig. 3 show plant (P), recovery center (RC), and retailer (R), respectively.

Illustration of a case study
The 59 returning centers are divided as shown Table 3.
On the other hand, it assumes the truckload quantity to be the same, 120 boxes per one truck and 30 empty bottles per one box to be loaded. Moreover, each transportation cost from the retailer to the recovery center and plant will be based on the fuel charge corresponding in 2008. And, also the recovered amount of empty bottle will be based on the January and February in 2008.
5.3 Numerical results
As soon as multiple objectives are considered in the evaluation of a solution, the notion of optimality is not straightforward and various options are available in the literature on decision theory and multi-objective analysis to characterize the most-preferred solutions. Among them, the concept of Pareto optimality is one of the most widely used [9]. Let S j be a solution set for each solution method (j = 1, 2, …, J). In order to evaluate the efficiency of the different fitness assignment approaches, we have to explicitly define measures evaluating closeness of S j form a known set of performance measures are considered. Evaluate each solution set depending on the number of obtained solutions |S j | [12]. A quality criterion, the percentage of optimality gap, is defined to show the percentage of deviation of the values of the GA solutions from the values of LINGO, according to the following equation [7]:
In Table 4, we report the summary of results for 6 problems with 30 instances in each. We use the percentage gap between optimum solution and heuristic solutions, which are pri-awGA and mo-hGA.
When the solutions f 1 are compared with respect to average gap over all 6 problems, it is seen that the mo-hGA exhibits the best performance with the average gap of each function of 0.22 % and 8.79 %. Also, when the solutions f 2 are compared with respect to average gap over all 6 problems, it is seen that the mo-hGA exhibits the best performance with the average gap of each function of 0.20 % and 5.08 %.
The computational results of the test problems are shown in Table 5, including computation time, number of Pareto solutions and improvement rate of the best solutions obtained by 30 runs of each program correspondingly. The comparison is first done according to the computation time and it is seen that the computation time needed for mo-hGA is less than pri-awGA in all problems. Next, according to the number of Pareto solutions, both methods found the same number for problem 1, and they are slightly same for problem 2. But for problem 3 ~ 6, the number of Pareto solutions found by pri-awGA are less than that found by mo-hGA. The average number of Pareto solutions ranges in pri-awGA between 3.0 and 17.2 for mo-hGA this change to between 3.0 and 25.4. These results could be explained by pri-awGA’s limited search intensification, causing it to find more Pareto solutions of a lower quality. On the other hand, being equipped with fuzzy logic control, mo-hGA appears to have sufficient capability to intensify the search and explore the neighborhood of high-quality solutions more carefully, leading to higher quality solutions. Finally the improvement rate according to each time period is shown in the last column of Table 5.
Figures 4 and 5 represents Pareto optimal solutions obtained from pri-awGA and mo-hGA for test problems. In this figure, the corresponding solutions on pri-awGA and mo-hGA Pareto optimal.

Pareto solutions (Problem 5)

Pareto solutions (case study)
In this paper, we focused on the design of multi-objective reverse logistics network model with delivery tardiness. Almost optimization problems involve more than one objective in a real world. Hence, considering the multiple objectives concurrently is a favorable option for almost decision makers. For designing practical optimization problems many decision variables arise. The impact of decisions on mutual interactions and performance might be difficult to predict. It might be hard to decide on one thing without considering other decision variables. This model of reverse logistics has simplexes decision variables with considering almost reverse logistics problem’s constraints (i.e. transportation cost, fixed opening cost and inventory cost).
6 Conclusions
In the environmental protection the reverse logistics of the used product is one of the most important research topics. The problem considered in this study is a single product and two stage reverse logistics network problem. Besides, we considered various costs in reverse logistics field and time concept of delivery tardiness in multi-time period, simultaneously.
Two objectives were considered: (1) minimization of the total transportation cost of reverse logistics network problem and (2) minimization of total delivery tardiness in all time periods.
Firstly, we formulated the mathematical model of the reverse logistics network problem by a multi-objective 0–1 mixed integer linear programming model. In this paper, we proposed a multi-objective hybrid genetic algorithm (mo-hGA) that is using a priority-based chromosome and adaptive weight approach for solving reverse logistics network problem. In order to enhancing the evolutionary process, we applied hybridization by fuzzy logic controller (FLC).
In this paper, we compared percentage gap of LINGO, priority-based encoding method with adaptive weight approach (pri-awGA) and multi-objective hybrid genetic algorithm (mo-hGA). We also use the percentage gap between optimum solution and heuristic solutions, which are pri-awGA and mo-hGA. And we also compared LINGO f1 and GAs f1 and Pareto solutions (f1, f2) at the same time. Besides, we demonstrated the effectiveness of mo-hGA such as shortness of computational time and better solutions.
Future research work may include the following: (1) using more practical data to further test and improve the approach; (2) trying to compare Simulated Annealing and Tabu Search that is the optimization technique; (3) considering reverse logistics and forward logistics, simultaneously.
References
Altiparmak F, Gen M, Lin L, Paksoy T (2006) A genetic algorithm approach for multi-objective optimization of supply chain networks. Comput Ind Eng 51(1):197–216
Alumur SA, Nickel S, Saldanha-da-Gama F, Verter V (2012) Multi-period reverse logistics network design. Eur J Oper Res 220:67–78
Barnes-Schuster D, Bassok Y, Anupindi R (2006) Optimizing delivery lead time/inventory placement in a two-stage production/distribution system. Eur J Oper Res 174:1664–1684
Bogataj M, Grubbström RW (2011) Transportation delays in reverse logistics. Int J Prod Econ 143(2):395–402
de Brito MP, van der Laan EA (2009) Inventory control with product returns: the impact of imperfect information. Eur J Oper Res 194:85–101
Du F, Evans GW (2008) A bi-objective reverse logistics network analysis for post-sale service. Comput Oper Res 35:2617–2634
Farahani RZ, Elahipanah M (2008) A genetic algorithm to optimize the total cost and service level for just-in-time distribution in a supply chain. Int J Prod Econ 111(2):229–243
Galand L, Perny P, Spanjaard O (2010) Choquet-based optimisation in multiobjective shortest path and spanning tree problems. Eur J Oper Res 204:303–315
Garcia Salcedo CA, Hernandez AI, Vilanova R, Cuartas JH (2013) Inventory control of supply chains: mitigating the bullwhip effect by centralized and decentralized internal model control approaches. Eur J Oper Res 224:261–272
Gen M, Cheng R (1997) Genetic Algorithm and Engineering Design. John Wiley & Sons, New York
Gen M, Cheng R (2000) Genetic Algorithms and Engineering Optimization. John Wiley & Sons, New York
Gen M, Cheng R, Lin L (2008) Network Models and Optimization: Multiobjective Genetic Algorithm Approach. Springer, London
Gen M, Lin L (2005) Multi-objective hybrid genetic algorithm for bicriteria network design problem. Complex Int 11:73–82
Glock CH (2012) Lead time reduction strategies in a single-vendor–single-buyer integrated inventory model with lot size-dependent lead times and stochastic demand. Int J Prod Econ 136:37–44
Keren B (2009) The single-period inventory problem: extension to random yield from the perspective of the supply chain. OMEGA Int J Manag Sci 37:801–810
Ko HJ, Evans GW (2007) A genetic algorithm-based heuristic for the dynamic integrated forward/reverse logsitics network for 3PLs. Comput Oper Res 34(2):346–366
Ko M, Tiwari A, Mehnen J (2010) A review of soft computing applications in supply chain management. Appl Soft Comput 10(3):661–674
Lee DH, Dong M (2009) Dynamic network design for reverse logistics operations under uncertainty. Transportation Research Part E: Logistics and Transportation Review 45(1):61–71
Lee JE, Gen M, Rhee KG (2009) Network model and optimization of reverse logistics by hybrid genetic algorithm. Comput Ind Eng 56(3):951–964
Lin L, Gen M (2009) Auto-turning strategy for evolutionary algorithms: balancing between explorations and exploitation. Soft Comput 13(2):157–168
LINDO Systems Inc. (2003) LINGO: The Modeling Language and Optimizer. Chicago IL
Min H, Ko HJ (2008) The dynamic design of a reverse logistics network from the perspective of third-party logitics service providers. Int J Prod Econ 113(1):176–192
Moed MC, Stewart CV and Kelly RB (1991) Peducing the search time of a steady state genetic algorithm using the immigration operator, Proceedings of IEEE International Conference Tools for AI pp. 500–501
Park KS, Shin DE (2009) An interactive multiple objective optimization method and its application to opening branch’s operational design and target setting. Korean Acad Soc Bus Adm 38(5):1251–1271
Pati RK, Vrat P, Kumar P (2008) A goal programming model for paper recycling system. OMEGA Int J Manag Sci 36:405–417
Pishvaee MS, Farahani RZ, Dullaert W (2010) A memetic algorithm for bi-objective integrated forward/reverse logistics network design. Comput Oper Res 37:1100–1112
Pishvaee MS, Torabi SA (2010) A possibilistic programming approach for closed-loop supply chain network design under uncertainty. Fuzzy Set Syst 161(20):2668–2683
Ray S, Jewkes EM (2004) Customer lead time management when both demand and price are lead time sensitive. Eur J Oper Res 153:769–781
Sha DY, Che ZH (2006) Supply chain network design: partner selection and production/distribution planning using a systematic model. J Oper Res Soc 57(1):52–62
Shin KS, Kim YK (2005) A multiobjective process planning of flexible assembly systems with evolutionary algorithms. J Korean Inst Ind Eng 31(3):180–193
Tempelmeier H (2006) Supply chain inventory optimization with two customer classes in discrete time. Eur J Oper Res 174:600–621
Ulku MA, Bookbinderm JH (2012) Optimal quoting of delivery time by a third party logistics provider: the impact of shipment consolidation and temporal pricing schemes. Eur J Oper Res 221:110–117
Xu N (2011) Myopic optimal policy for a multi-period, two-delivery-lead-times, stochastic inventory problem with minimum cumulative commitment and capacity. Int J Prod Econ 133:719–727
Xu J, Liu Q, Wang R (2008) A class of multi-objective supply chain networks optimal model under random fuzzy environment and its application to the industry of Chinese liquor. Inf Sci 178:2022–2043
Acknowledgments
This work was partly supported by the Yonsei University Research Fund of 2012, by the Grant-in-Aid for Scientific Research (C) (No.245102190001) of the Japan Society of Promotion of Science (JSPS) and Taiwan National Science Council (NSC 101-2811-E-007-004).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Lee, JE., Chung, KY., Lee, KD. et al. A multi-objective hybrid genetic algorithm to minimize the total cost and delivery tardiness in a reverse logistics. Multimed Tools Appl 74, 9067–9085 (2015). https://doi.org/10.1007/s11042-013-1594-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-013-1594-6