
Abstract
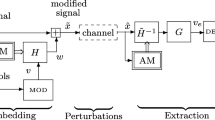
In this paper, a new perceptual spread spectrum audio watermarking scheme is discussed. The watermark embedding process is performed in the Empirical Mode Decomposition (EMD) domain, and the hybrid watermark extraction process is based on the combination of EMD and ISA (Independent Subspace Analysis) techniques, followed by the generic detection system, i.e. inverse perceptual filter, predictor filter and correlation based detector. Since the EMD decomposes the audio signal into several oscillating components–the intrinsic mode functions (IMF)–the watermark information can be inserted in more than one IMF, using spread spectrum modulation, allowing hence the increase of the insertion capacity. The imperceptibility of the inserted data is ensured by the use of a psychoacoustical model. The blind extraction of the watermark signal, from the received watermarked audio, consists in the separation of the watermark from the IMFs of the received audio signal. The separation is achieved by a new proposed under-determined ISA method, here referred to as UISA. The proposed hybrid watermarking system was applied to the SQAM (Sound Quality Assessment Material) audio database (Available at http://sound.media.mit.edu/mpeg4/audio/sqam/) and proved to have efficient detection performances in terms of Bit Error Rate (BER) compared to a generic perceptual spread spectrum watermarking system. The perceptual quality of the watermarked audio was objectively assessed using the PEMO-Q (Tool for objective perceptual assessment of audio quality) algorithm. Also, using our technique, we can extract the different watermarks without using any information of original signal or the inserted watermark. Experimental results exhibit that the transparency and high robustness of the watermarked audio can be achieved simultaneously with a substantial increase of the amount of information transmitted. A reliability of 1.8 10 − 4 (against 1.5 10 − 2 for the generic system), for a bit rate of 400 bits/s, can be achieved when the channel is not disturbed.











Similar content being viewed by others


References
Adib A, Aboutajdine D (2005) Reference-based blind source separation using a deflation approach. Signal Process 85(10):1943–1949
Baras C, Moreau N (2006) Controlling the inaudibility and maximizing the robustness in an audio annotation watermarking system. IEEE Trans on Audio, Speech and Language Process 14(5):1772–1782
Bas P, Lienard J, Chassery JM, Beautemps D, Bailly G (2004) Artus: animation réaliste par tatouage audiovisuel à l’usage des sourds. J3eA 3 (Hors série 1, 16)
Bhat V, Sengupta I, Das A (2010) An audio watermarking scheme using singular value decomposition and dither-modulation quantization. Multimed Tools Appl 52(2–3):369–383
Boney L, Tewfik AH, Hamdy KN (1996) Digital watermarks for audio signals. In: IEEE International conference on multimedia computing and systems. Hiroshima, pp 473–480
Casey M, Westner A (2000) Separation of mixed audio sources by independent subspace analysis. In: ICMC 2000. Berlin, Germany, pp 154–161
Flandrin P (2010) An empirical model for electronic submissions to conferences. Adv Complex Systems 13(3):1–11
Frank I, Todeschini R (1994) The data analysis handbook. Elsevier, Sci Pub Co
Guerrero L (2004) Etude de techniques de tatouage audio pour la transmission de données. Master’s thesis, Ecole Doctorale Electronique, Electrotechnique, Automatique, Télécommunications, Signal
Hamdouni NE, Adib A (2010) Single mixture audio sources separation using ISA technique in EMD domain. In: ISIVC’10
Hamdouni NE, Adib A, Turki M, Aboutajdine D (2008) Combined emd/ica for digital audiowatermarking: a potentially craft to increase the embedded binary flow. In: ISIVC, Spain
Hamdouni NE, Adib A, Larbi SD, Turki M (2010) Hybrid embedding strategy for a blind audio watermarking system using EMD and ISA technique. In: ISCCSP’10. Limassol, Cyprus
Huang NE, Shen Z, Long SR, Wu MC, Shih HH, Zheng Q, Yen NC, Tung CC, Liu HH (1998) The empirical mode decomposition and Hilbert spectrum for nonlinear and non-stationary time series analysis. R Soc London A 454:903–995
Huber R, Kollmeier, B (2006) PEMO-Q—a new method for objective audio quality assessment using a model of auditory perception. IEEE Trans on Audio, Speech and Language Process 14(6):1902–1911
Larbi SD (2005) Structures d’égalisation en tatouage audionumérique. Thèse de doctorat, Ecole Nationale d’Ingénieurs de Tunis (ENIT) et Télécom Paris (ENST)
Larbi S, Jaïdane M, Moreau N (2004) A new Wiener filtering based detection scheme for time domain perceptual audio watermarking. In: IEEE Int Conf Acoust, Speech, Signal Process, vol 5. Montreal, QC, Canada, pp 949–952
Lei BY, Soon IY, Li Z (2011) Blind and robust audio watermarking scheme based on svd−dct. Signal Process 91(8):1973–1984
Liénard J (2001) Transmission d’un message numérique caché dans un signal audio. In: Gretsi Toulouse France, pp 473–480
Lin WH, Horng SJ, Kao TW, Fan P, Lee CL, Pan Y (2008) An efficient watermarking method based on significant difference of wavelet coefficient quantization. IEEE Trans Multimedia 10(5):746–757
Lin WH, Horng SJ, Kao TW, Chen RJ, Chen YH, Lee CL, Terano T (2009) Image copyright protection with forward error correction. Expert Syst Appl 36(9):11,888–11,894
Lin WH, Wang YR, Horng SJ (2009) A wavelet-tree-based watermarking method using distance vector of binary cluster. Expert Syst Appl 36(6):9869–9878
Lin WH, Wang YR, Horng SJ, Pan Y (2009) A blind watermarking method using maximum wavelet coefficient quantization. Expert Syst Appl 36(9):11,509–11,516
Liu YW (2007) Sound source segregation assisted by audio watermarking. In: IEEE Int Conf Multimedia and Expo, pp 200–203
Malik H (2009) Blind watermark estimation attack for spread spectrum watermarking. Informatica 33(1):49–68
Parvaix M, Girin L, Brossier J (2010) A watermarking-based method for informed source separation of audio signals with a single sensor. IEEE Trans on Audio, Speech and Language Process 18(6):1464–1475
Rilling G, Flandrin P, Goncalvès P (2003) Empirical mode decomposition and its algorithms. In: IEEE-EURASIP, Workshop on nonlinear signal and image processing, NSIP ’03, Grado (I)
Taoufiki M, Adib A, Aboutajdine D (2010) A new behavior of higher order blind source separation methods for convolutive mixture. Digit Signal Process 20:269–275
Uhle C, Dittmar C, Sporer T (2003) Extraction of drum tracks from polyphonic music using independent subspace analysis. In: Int Symp Independent Compon Anal Blind Signal Separation (ICA2003), pp 843–848
Author information
Authors and Affiliations
Corresponding author
Appendix: Empirical mode decomposition
Appendix: Empirical mode decomposition
The EMD technique was firstly developed by Huang et al. [13] to decompose any nonstationary and nonlinear signal into oscillating components obeying some basic properties. The key benefit of using the EMD technique is that an automatic decomposition and fully data adaptive. This method makes it possible to decompose the audio signal x(n), to a set of \(\textsf{IMF}\) components, as follows:
where N represents the number of the \(\textsf{IMF}_i(n)\), and r N (n) is the final residue. The EMD technique can decompose the host signal from the highest frequency components to the residue r N (n), which represents the lowest frequency component. An audio signal example (Harpsichord sound) and some selected \(\textsf{IMF}\)s components are shown in Fig. 12.

EMD of an audio signal (Harpsichord sound) showing selected \(\textsf{IMF}\) components
The \(\textsf{IMF}\)s are the bases for representing the time series data. Being data adaptive, the basis usually offers a physically meaningful representation of the underlying processes. There is no need of considering the signal as a stack of harmonics and, therefore, EMD is ideal for analyzing nonstationary and nonlinear data [13]. The EMD process can also be considered as dyadic filter-bank especially for white noise and the \(\textsf{IMF}_i(n)\) components are all normally distributed [13].
The EMD technique has also many interesting features [13]: it is characterized by its completeness, that is x(n) can be exactly reconstructed by linear superposition of all the components. It generates roughly orthogonal components, because the \(\textsf{IMF}\)s have different local frequencies at the same time. Each \(\textsf{IMF}_i(n)\) has a well defined Hilbert transform from which the instantaneous frequencies can be calculated.
Rights and permissions
About this article
Cite this article
El Hamdouni, N., Adib, A., Larbi, S.D. et al. A blind digital audio watermarking scheme based on EMD and UISA techniques. Multimed Tools Appl 64, 809–829 (2013). https://doi.org/10.1007/s11042-012-0988-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-012-0988-1