
Abstract
Characterization of spatial variability in earth science commonly requires random fields which are stationary within delineated domains. This contribution presents an alternative approach for simulating attributes in combination with a non-stationary first-order moment. A new procedure is presented to unambiguously decompose the observed behaviour into a deterministic trend and a stochastic residual, while explicitly controlling the modelled uncertainty. The practicality of the approach resides in a straightforward and objective inference of the variogram model and neighborhood parameters. This method does not require a prior removal of the trend. The inference principle is based on minimizing the deviation between empirical and theoretical errors calculated for increasingly distant neighborhood shells. Further, the inference is integrated into a systematic simulation framework and accompanying validation guidelines are formulated. The effort results in a characterization of the resource uncertainty of an existing heavy mineral sand deposit.
Similar content being viewed by others

1 Introduction
The development of a mineral resource is inherently connected with a substantial amount of risk due to large financial investments required at times when geological knowledge is rather limited. During the last two decades, it was found that risk can be mitigated by considering a probabilistic resource model instead of a single deterministic one (Dowd 1994; Dimitrakopoulos 1998; Dimitrakopoulos et al. 2002; Rendu 2002; Botin et al. 2015). The main objective of a probabilistic resource model is the characterization of geological uncertainty.
The reliability of the modelled uncertainty depends on the ability to correctly characterize the spatial structure via a selection of geostatistical model parameters. Despite the improvements made in the field of orebody simulation, it remains challenging to model attributes with non-stationary first-order moments. Traditionally, semi-stationary residuals are obtained either by delineation of domains or by explicit modelling of a trend. Once obtained, the residuals are used to condition simulations (Rossi and Deutsch 2014). In practice, it is usually not possible to unambiguously identify and separate the smoothly varying trend from the more erratic residuals (Journel and Rossi 1989; Cressie 1991; Zimmerman and Stein 2010). Nevertheless, the inference of the trend model is critical due to its direct influence on the remaining residuals (Leuangthong and Deutsch 2004). A misfit could result in a severe bias during the assessment of uncertainty. Common estimation algorithms such as Universal or Dual Kriging (UK/DK) can be applied to model both components simultaneously (Isaaks and Srivastava 1989; Goovaerts 1997; Webster and Oliver 2007). At data locations, DK can be used to decompose the observed attribute into a deterministic trend and a stochastic residual. Yet, these algorithms require that the underlying covariance function of the residuals is known a priori. Reliable inference of the model parameters remains an issue. Armstrong (1984) pointed out that this is merely a chicken-and-egg problem. The underlying covariance model of the residuals is needed to solve the kriging equations. To calculate the residuals, a trend model should be available. Back to square one, since the trend model results from the solution of the kriging equations, which requires a covariance model.
Recently, Benndorf and Menz (2014) introduced a new approach to infer covariance model parameters without prior trend removal. The new approach extends the traditional cross-validation methodologies in two ways. First, the evaluation of the model quality is not only limited to sample data locations. It can be performed at any prediction location in the domain. Secondly, the use of error curves further enhances the single point replacement measures used in traditional cross validation. The curves relate prediction errors to different lag distances and allow for distinguishing between the influence of several model parameters on the overall algorithm performance. A tailored back-fitting procedure permits the derivation of optimal model parameters under the assumption of a given trend function. The work of Benndorf and Menz (2014) was limited to the inference of variogram parameters in the presence of a trend and discussed future research to integrate this approach into a simulation framework.
This contribution extends previous work by integrating the inference method into a simulation and validation framework for a reliable characterization of uncertainty in the presence of a trend. Practical aspects and implementation issues concerning the application of the error-curve based inference method are discussed. It is demonstrated that the modelled uncertainty matches characteristics of the data by comparing results to an alternative cross-validation approach which assesses the validity of the uncertainty model (Olea 2012).
First, the method is reviewed in the light of alternative documented methods for inferring geostatistical model parameters in the presence of a trend. Next, the main equations as presented in Benndorf and Menz (2014) are reviewed briefly, practical aspects are discussed and insights into the implementation are given. The method is further integrated into a simulation framework. Several validation steps are added to ensure a correct quantification of the uncertainty according to a transparent process. It will be shown that once the error curves are matched, only some fine tuning of algorithm parameters is needed to obtain satisfactory validation statistics. The performance of the framework in a full-scale three-dimensional environment is illustrated through a case study in heavy mineral sands. The simulation results are validated against an alternative approach of extended cross validation, comparing empirical and theoretical probabilities.
2 Inference of Geostatistical Model Parameters in the Presence of a Trend—A Brief Review
Trend modelling in mineral resource applications is performed when a trend has been detected and is assumed to be well understood. Furthermore, it might be an appropriate modelling strategy when facing the following domaining issues. (1) In some deposits, the interaction between different geological processes obscures the exact locations of ‘hard’ boundaries. The outcome of geological domaining is subjective. (2) Mineralization domains are commonly constructed based on selected cutoff values. As such, assumptions and constraints are implicitly imposed on the exploitation strategy still to be developed (Whittle 2014). A high cutoff grade implies a more selective mining operation, excluding the possibility of a more cost-effective bulk approach. Although it is common practice in the mineral industry, grade domaining may increase the dispersion of estimation errors and cause a conditional bias in the resource estimation (Emery and Ortiz 2005).
Both issues can potentially be solved through the use of a trend model across ‘soft’ boundaries. The non-stationary mean is dealt with by a single continuous trend model instead of a piecewise constant function. In geostatistical terms, the attribute under study \(Z({\varvec{x}})\) is modelled as a combination of a weakly stationary random function \(S({\varvec{x}})\) and a deterministic trend component \(m({\varvec{x}})\) (Journel and Huijbregts 1978; Goovaerts 1997). This results in
with expectations
The first step is to establish an attribute \(S({\varvec{x}})\) that is stationary over the domain considered. At the data locations, the trend \(m({\varvec{x}})\) needs to be removed prior to variogram modelling and geostatistical simulation (Gringarten and Deutsch 2001).
A variety of trend modelling approaches exist. Data in geological sections can be manually or automatically contoured (Rossi and Deutsch 2014). Trend surface analysis, a form of multiple regression, fits a low-order polynomial of the spatial coordinates to the observations using the method of least squares (Knotters et al. 1995; Webster and Oliver 2007). In densely sampled areas, moving window averages can be calculated (Benndorf and Menz 2014). A three-dimensional trend model can be constructed by rescaling and combining a two-dimensional and one-dimensional vertical trend (Deutsch 2002). As pointed out in the introduction, the trend model and residuals are inherently connected. To correctly map spatial uncertainty, one component should not be modelled without consideration of the other. Estimation algorithms such as UK or DK can be applied to estimate both components simultaneously (Isaaks and Srivastava 1989; Goovaerts 1997; Webster and Oliver 2007).
An iterative adjustment of the covariance model parameters has been tried to match the calculated empirical covariances of the residuals with those of the model. This is merely a trial and error exercise since it is unclear how the parameters need to be adjusted to improve the fit. Moreover, research has shown that such an approach results in a biased characterization of the spatial variability (Chauvet and Galli 1982; Cressie 1991; Lark et al. 2006). However, this bias is considered to be negligible when the scales of variation of the trend and residual components are significantly different (Beckers and Bogaert 1998). Furthermore, Diggle and Ribieiro (2007) argue that the discrepancy between the observed and true residual would be smaller in a larger data set. A reliable variogram can be calculated by selecting data pairs which are unaffected by the trend (Olea 2006). This assumes that the pattern of spatial variation can be derived correctly while excluding certain directions from the analysis (Journel and Rossi 1989; Goovaerts 1997). A more complicated technique consists of filtering out the particular trend model assumed by linear combinations of available data (theory of Intrinsic Random Functions of order k). These high-order differences are not readily available in the case of non-gridded data and may typically result in very large nugget effects (Delfiner 1976). Others have suggested to infer all model parameters simultaneously (including the trend), either through the maximization of a likelihood function or the calculation of posterior distributions. The former is conducted using gradient descent algorithms (Zimmerman 2010). The latter generally relies on iterative and approximate Markov Chain Monte Carlo methods (Diggle et al. 1998; Christensen and Waagepetersen 2002). The application of both techniques is generally limited to small-scale two-dimensional data sets due to obstacles regarding practical implementation, computational efficiency and convergence of the algorithms (Diggle and Ribieiro 2007; Christensen 2004).
Benndorf and Menz (2014) presented the theory behind a new method to infer best model parameters in the presence of a trend. The method utilizes mean errors of empirical and theoretical differences between UK and a trend prediction by general least squares (GLS). Empirical and theoretical differences are computed for a set of m grid nodes based on data within a nested family of spherical or elliptical rings. Mean errors are thus defined as functions of the radii of the shells. The curves relate prediction errors to different lag distances and allow for distinguishing between the separate influence of different covariance model parameters on the overall fit. An informed incremental variation of model parameters finally results in matched error curves. The practical application of the method will be discussed in the next section. Further, it will be shown that this new approach can be integrated in a robust and transparent simulation framework.
3 Inference of Geostatistical Modelling Parameters Under the Presence of a Trend
3.1 Concept and Theory
This section reviews a new approach for the inference of covariance model parameters without the need of prior trend removal. The major results are provided here, for more detail the reader is referred to Benndorf and Menz (2014).
The principle is based on the comparison of the average empirical and theoretical differences between two methods of prediction. For a good performance in fitting model parameters, it can be shown that the differences between the two methods of prediction should be potentially large (Menz 2012). Sufficiently large differences are obtained using UK as prediction method one and GLS as prediction method two. Note that GLS is performed under the assumption that the covariance parameters are the same as in UK. The derivation of the method is briefly outlined. The following evaluates the differences \(\Delta ({\varvec{x}})\) between both methods
UK can be written as the sum of a GLS estimate of the trend and a simple kriging (SK) estimate of centered data (Chilès and Delfiner 2012; Matheron 1970; Dubrule 1983; Cressie 1991)
where \(\varvec{C}\) is a covariance matrix of the sampling locations, \({\varvec{c}}_0\) is a covariance vector describing the relationship between the current point of interest \({\varvec{x}}_0\) and the data points in the selected neighborhood, the matrix \({\varvec{F}}\) is the so-called design matrix and contains trend functions \({\varvec{f}}\) evaluated at the sampling locations, \({\varvec{z}}({\varvec{x}})\) is a vector containing the sampling data and \({\hat{\varvec{\mu }}}\) is a vector of trend parameters. After some algebraic manipulations, the trend parameters can be obtained via
Once the trend parameters are calculated, the empirical difference between both methods of prediction can be assessed, that is the second term of Eq. (4) is evaluated.
The application of geostatistical prediction or simulation requires a regular grid containing m grid nodes. Estimating the signal at each grid node, m empirical differences can be calculated. The empirical root mean square error is obtained by
The subscript \({\varvec{R}}\) in Eq. (6) denotes the parameter set that describes the geometry of neighborhood rings. Only data points inside a local neighborhood are used to construct the sampling vector \({\varvec{z}}({\varvec{x}})\), the design matrix \({\varvec{F}}\) and the covariance matrix \({\varvec{C}}\).
Since the second term of Eq. (4) can be regarded as a linear combination of random variables, the theoretical variance for estimating the signal can be written as:
The theoretical error of differences finally results from the squared average signal variance calculated at the m grid nodes. The theoretical root mean square error can be formulated analogously to Eq. (6)
3.2 Software Implementation
When evaluating theoretical and empirical errors using traditional cross-validation techniques, it is implicitly assumed that a single neighborhood is centered around each grid node. Such an approach results in one empirical and one theoretical error and only allows for an evaluation of the overall goodness-of-fit of the covariance structure. A fine tuning to improve model parameters is hardly possible. To assess the fit at different variogram lags, the so-called error curves are constructed. At each of the m grid nodes, a sequence of errors is calculated corresponding to different neighborhood rings. Non-overlapping neighborhood rings are used to prevent masking of remote samples by closer ones and to investigate the influence of separate variogram lags.
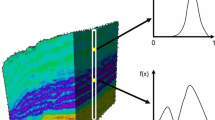
For a regularly distributed sampling pattern in a two-dimensional space, the set of neighborhood rings is best defined as a set of circular disks of increasing mean radius. Figure 1 shows one such neighborhood or ring of influence centered around a specific grid node. In a three-dimensional space, the rings of influence become spherical shells. In case of anisotropy, ellipsoidal shells might be more appropriate. The parameter set \({\varvec{R}}\) in Eqs. (6) and (8), thus, defines the geometry of a single ellipsoidal shell.

The concept of the ring of influence. The empirical and theoretical differences are calculated with data located in a particular ring of influence (reproduced after Benndorf and Menz 2014)
The computation of error curves, using Eqs. (6) and (8), requires the evaluation of \(n_{r}\) Kriging systems per grid node, where \(n_{r}\) is the number of rings (ellipsoids) of influence. This increases the computational burden and affects computing times negatively. Therefore, the algorithm is implemented with an option to randomly visit a subset m of the total number of grid nodes M. Here, m should be sufficiently large so that the nodes form a representative sample. Experimental studies have shown that in the two-dimensional case, m should be in the order of 100 and about 2,000 in the three dimensional case. Once optimal model parameters are found, the estimation or simulation can be performed for all M grid nodes.
Following pseudo-code gives some insight into the algorithm:

3.3 Practical Application
Figure 4 displays the average empirical and theoretical error as functions of the increasingly distant neighborhood shells. The left hand side of Fig. 4 shows a case where both error curves are not matched. The right hand side of Fig. 4 illustrates the error curves for the case of a “good model fit”. For a quantitative comparison of the empirical and theoretical error curves, the maximum absolute deviation and the sum of the vertical deviations are calculated and displayed on the graph.
3.3.1 Initialization
Before proceeding, some considerations regarding the initialization of the algorithm are provided. As discussed before, m grid nodes are randomly selected from the total number of grid nodes. A few test runs are performed with an increasing number of randomly selected nodes. The lowest number which does not cause any further significant changes in the error curves is selected.
The initialization of (ellipsoidal) neighborhood rings aims for a consistent distribution of nodes in all the rings. On average, each ring should contain about six sampling points, two along each direction on opposite sides of the rings. Following steps provide some guidelines through the initialization process. First, align the radii of the ellipsoidal neighborhood rings along the main directions of the sampling pattern. Second, determine the ratios of the sampling intervals along these directions. For example, Fig. 3 displays a sampling grid with a x/y ratio of one to five. The ratios describe the ‘geometry’ of the ellipsoidal neighborhood rings, that is they are chosen such that the ratio between the radii of the ellipsoid approximates the sampling ratios. Third, select the outermost limit of the ellipsoidal rings as the one for which test runs have indicated that both error curves approximate zero. Fourth, the mean radius of the outermost ring is used to construct a sequence of ellipsoidal rings of equal thickness. This number is obtained through a careful analysis of the amount of sampling points inside each neighborhood ring.
3.3.2 Shape of the Curves
The distinctive shape of the error curves results from the difference between both methods of prediction. In the first few ellipsoidal shells, results from both methods of prediction start to diverge as the distance between the grid node and the allocated data points increases, hence a sharp increase in the error curve. Initially, UK outperforms GLS due to the additional signal component capable of characterizing short scale variability. At some moment, the difference between both methods of prediction reaches a maximum. From thereon, the empirical and theoretical differences gradually converge towards zero. The more distant samples are not informative enough to maintain the advantage of UK over GLS. At larger distances, the signal component reduces to zero. Both methods of prediction are essentially estimating the same larger scale trend. The outer limit of the shell at which the error curve approximates zero yields the most optimal boundary of the neighborhood used during estimation or simulation.
3.3.3 Fitting Procedure
To achieve a good model fit, the more sensitive theoretical error curve has to be adjusted to match the empirical error curve using an iterative back-fitting approach (more sensitive in the sense that a change in model parameters results in a more remarkable adjustment of the theoretical compared to the empirical error curve). This is done by systematically changing the model parameters of the covariance function. Horizontal deviations between mismatched curves (differences parallel to x axis) can mainly be influenced by adjusting the range of the covariance function; vertical deviations (differences parallel to y axis) are controlled using the variances (Fig. 4).
From experience, it is known that the last segments of the error curves are relatively easy to match by choosing a correct sill value. The vertical deviation around the maximum is minimized by selecting a proper ratio between the different sill components of the covariance model. The horizontal deviations around the maximum are the most challenging to reduce. Adjusting the range parameters, while closing in on the actual but unknown values, ‘drapes’ the theoretical error curve nicely around the peak of the empirical one. The right hand side of Fig. 4 shows the result of the described back-fitting approach. A simulated annealing approach can be applied to automate this trial and error procedure.
4 A practical Simulation Approach
The error-curve-based inference method ensures that the use of GLS results in a realistic trend model, that is a trend model that is neither over-fitting nor under-fitting the data. The residual or signal simulations, conditioned on the difference between observed data and trend, now should yield a level of uncertainty which is consistent with the modelling assumption used. The following discusses how the error-curve-based inference method is integrated with GLS and sequential Gaussian simulation (SGS) into a practical workflow to simulate orebody realizations with trends.
4.1 Simulation Objectives and Procedure
The general objectives of a geostatistical simulation study are (i) the correct representation of the spatial variability, (ii) the detection of patterns of spatial extremes, such as zones rich in metal or zones of high rock strength, (iii) a realistic characterization of the geological uncertainty.
The success of a geostatistical simulation study depends on the degree of compliance with the formulated objectives. Neglecting to validate the simulation results can lead to errors (Nowak and Verly 2005). Calibration and validation steps are explicitly documented in the flowchart to safeguard the quality of the entire study. The flowchart contains two types of components: (i) the main operations, all numbered and located in a vertical sequential path and (ii) the validation procedures, indicated by five roman numerals. The validation procedures are designed to safeguard the representativeness of the simulation results. Final or intermediate results indicated by the same roman numeral are compared using a set of global and spatial statistics.

Practical approach to simulate and validate orebody realizations with trends
The following discussion gives a concise overview of the eight main operations (Fig. 2).
-
1.
A declustering algorithm is used to remove any bias due to preferential sampling. Representative data statistics for the area under investigation are calculated.
-
2.
A primary normal score transformation is performed using the declustering weights computed during the previous step. The transformation to normal scores at this stage enables the use of a single covariance model throughout. That is for the estimation of the trend as well as for the simulation of residuals. Even though a second normal score transformation is applied later on.
-
3.
Empirical and theoretical error curves are calculated and matched to calibrate the covariance and the neighborhood parameters. The covariance model implicitly specifies the layout of the trend. Due to the previous transformation, the obtained covariance model can be used both in the GLS and signal simulation step.
-
4.
Equation 4 is used to split the observed attributes into a deterministic trend component and a stochastic residual. At the grid nodes, a full three-dimensional trend model is constructed.
-
5.
The subsequent simulation step assumes normally distributed residuals with a mean of zero and variance approximating the one inferred by fitting the error curves. However, due to the trend removal, the shape of the tails might deviate from those of a normal distribution. Using the residuals as such would result in an incorrect reproduction of spatial extremes.
-
6.
To overcome this issue, a tail-correcting transformation is applied. The quantiles of the residual distribution are mapped onto those of a normal distribution with a variance equal to the inferred one (i.e. a rescaled normal score transformation). Figure 6 illustrates the effect of such a tail-correcting transformation.
-
7.
Several signal realizations representing the spatial variability are generated using SGS. The simulation is performed based on the tail-corrected residual scores and the previously inferred covariance model.
-
8.
A back transformation is applied to map the simulated signal values back onto the distribution of the initially obtained residuals (Fig. 7c–e). This back transformation ensures that the resulting signal distribution reproduces the “unusual” tail shape of the initially obtained residuals.
-
9.
The trend is added back onto the signal realizations and the resulting realizations are back transformed into the original domain. The simulation results now need to be validated.
4.2 Validation Procedure
The proposed approach contains two main validation procedures. The first procedure is displayed in Fig. 2 and is built up from five different validation steps. Derived data and calculated results, indicated by the same roman numeral, are compared through a set of global and spatial statistics. These five validation steps are designed to ensure that each simulated orebody realization complies with the first two simulation objectives.
The fifth validation step is the most critical one and should be tested first. To approve a deposit realization, its average, variance, histogram, qq-plot and semi-variogram should match those of the exploration data. The semi-variogram and the variance mainly control whether the spatial variability is correctly reproduced. The qq-plot and histogram are used to check whether the proportion of extreme values is correct. The four remaining validation steps are added to the process for troubleshooting purposes and to aid a quicker completion of the fifth test. Results from intermediate operations are used to identify which calibration parameters need to be adjusted.
To assess the reliability of the mapped uncertainty, a second validation procedure was performed. An extended cross-validation approach is used to identify conditional bias and to ensure a proper assessment of uncertainty (Olea 2012). Below a brief summary is presented.
Similar to traditional cross validation, each sampling location is left out of the data set and the remaining observations are used to model the cumulative distribution function at that location. The previously described simulation approach is used to construct this conditional distribution. A series of probabilities is defined (e.g. 0.01 to 0.99) and their corresponding quantiles are retrieved from the modelled conditional distribution. Each quantile is compared to the ignored observation. After all the sampling points have been visited, the proportion of observations not exceeding a certain quantile is calculated. The calculated proportions can now be plotted against the probabilities of their corresponding quantiles.
Ideally, every proportion–probability set should be equal, resulting in a straight line along the bisector. This would for example imply that in 5 % of the locations, the true value is lower than the corresponding 5 % quantile. If the computed empirical probability would be higher, this would indicate that the possible occurrence of low values is underestimated. Obviously, when the empirical probability is lower than the specified 5 %, the possible occurrence of low values is overestimated. On the other hand, when the computed empirical probability of the 95 % quantile would be higher, this would indicate that the possible occurrence of high values is overestimated. An empirical probability lower than 95 % corresponds to an underestimation of high values.
The bisector thus acts as a reference for optimal performance indicating perfect global agreement between the modelling of uncertainty and the limited amount of information provided by the samples (Olea 2012). These cross-validation statistics are more sensitive to variations in the input parameters than those solely based on estimation errors. The deviations from the bisector are particularly useful for comparing the quality of the uncertainty modelling for different sets of realizations. The interested reader is referred to Olea (2012) for more information about the approach.
5 A Case Study in Heavy Mineral Sands
The practical approach in a full-scale three-dimensional environment is illustrated through a case study in heavy mineral sands.
A resource efficient evaluation of a heavy mineral sand deposit calls for a proper characterization of the uncertainty in the properties impacting the profitability, extractability and processability of the raw material in place (Ferrara et al. 1993; Vallee 2000; Dominy et al. 2002). The total heavy mineral grade impacts the economic value. The slime content and oversize both influence the extractability and processability of the mineral sand.
5.1 Geology
Modelling the relevant attributes requires a sound understanding of the geological processes involved in the formation of the deposit (Jones 2009). During periods of fair weather, sediments are brought down by rivers and accumulated in beaches. Enrichment occurs when large volumes of lighter components are winnowed out and carried offshore. The heavier mineral grains tend to lag and are concentrated. The ongoing winnowing and supply of new sediments obscure the exact location of the geological boundaries. Due to these complex interactions, the properties of interest exhibit a transitional behaviour across the soft boundaries. A trend is potentially the best modelling strategy to account for such a non-stationary behaviour.
The project area lies within the Swan Coastal Plain and contains beach deposits which were formed during a Quaternary cyclic regression phase. The beach deposits overlie Mesozoic fluvial deposits which form the basement in many regions along this paleocoastline. The Quaternary sediments contain two episodes of mineralization. The ‘upper-level’ mineralization originates from a partially preserved strand zone and is located close to or at the surface. The ‘mid-level’ mineralization refers to a well-preserved and more extensive sheet-like structure just above the basement. Incised into the Mesozoic clay basement, a third mineralization zone occurs in a channel. The channel predates the quaternary sediments and contains large volumes of low grade material.
5.2 Drill Hole Database
The case study is based on a publically available data set which was obtained during a co-funded drilling project under the incentives of the Australian government (Image Resources 2011; WAMEX 2014). The Rhea target has an area of 1.5 km\(^{2}\) and is located in Western Australia, about 160 km north-north-west of Perth and 25 km east of the coastal community of Cervantes. A total of 401 aircore holes were drilled for a total depth of 11,155 m. The drill holes were positioned along parallel lines forming a 20 m \(\times \) 100 m sampling grid. Drilling stopped when the Mesozoic basement was intersected. Therefore, the depth of the holes varies from 20 m to 100 m. The slime content, the oversize and the total heavy mineral grade were recorded every 1 m. The sampling grid of the Rhea target is displayed in Fig. 3.

Sampling grid Rhea target. The exploration campaign resulted in 401 aircore holes with a total length of 11.155 m. The drill holes were positioned along parallel lines forming a 100 m \(\times \) 20 m sampling grid
5.3 Simulation Results
The sand body was subdivided into sixty-four thousand grid nodes with a spacing of 20 m \(\times \) 20 m \(\times \) 1 m, considering the data density and selectivity of wet mining equipment. Subsequently, the method of fitting the empirical and theoretical error curves was used to infer the model parameters of the underlying signal (Fig. 4). Then, the combination of GLS and sequential Gaussian simulation was used to generate twenty orebody realizations. This subsection presents the final simulation results for all three attributes.

Assessment of theoretical and empirical error curves for a case with model parameters which were not carefully chosen (left) and for a good model fit (right)

Geometallurgical model of the Rhea target. Single realization of the slime content (a), oversize (b) and total heavy mineral content (c). Block size is 20 m \(\times \) 20 m \(\times \) 1 m. All block models are displayed with a vertical exaggeration of 5
A single realization of the slime content, the oversize and the heavy mineral grade is displayed in Fig. 5. All models reproduce the geological patterns well as described by the field geologist (Image Resources 2011). The cross section through the west side of the realization indicates an increase in slime content just below the surface and above the basement (Fig. 5a). The realization picks up the increase in slime content at the east bank in the southern part of the channel (section B-B’, Fig. 5a). The general trend of a larger amount of oversized particles between the middle sheet and upper level mineralization is reproduced (Fig. 5b). The mid-level mineralization appears as a continuous well-preserved sheet, just above the basement as described by the field geologist (Fig. 5c). The realization also displays remnants of parallel elongated ellipsoidal structures (Fig. 5c). However, the outline of these structures is not clearly observed since they are only partially preserved. Although the channel is generally considered to be of low grade, locally high grade zones can occur (Fig. 5c). In the west part of the deposit, the upper strand zone seems to merge with the middle sheet around the second quarter of section A-A’ (Fig. 5c). This event more or less coincides with a decrease in oversize.
These results illustrate that the proposed approach can be successfully used without the conventional, rather arbitrary delineation of different geological zones. The complex features, observed in the boreholes of this particular mineral sand deposit, are reproduced throughout the entire sand body in a realistic manner.
5.4 Simulation and Validation Approach
To illustrate the different steps embedded in the proposed workflow a more detailed discussion regarding the construction of the slime content model is presented. Figure 6a displays a histogram of the declustered original data (step 1). The final declustering weights were obtained through the execution of a cell declustering algorithm with a cell size of 80m \(\times \) 80m \(\times \) 1m. Different cell geometries were tested. The one resulting in the lowest declustered mean was retained. Based on the declustering weights, a cumulative distribution function is constructed. The resulting distribution is used to map the original data onto the normal score domain (step 2). Figure 6b shows the histogram of the normal score transformed slime content.

Histograms of intermediate results at data locations (step 1 to 5 of the workflow); a histogram of sampled slime content (step 1), b histogram after first normal score transformation (step 2), c histogram of computed residual at data locations (step 4), d histogram of computed trend at data locations (step 4), e histogram of tail-corrected residual
In the next step, theoretical and empirical error curves are to be matched to infer the covariance model parameters and neighborhood geometry. The search ellipsoid was defined with major axes oriented along the sampling directions (which are parallel to the grid axes). The outer shell has a x radius of 400 m, a y radius of 100 m and a z radius of 10 m. This ellipsoid was further subdivided into ten ellipsoidal shells of equal thickness (Ref Sect. 3.3.1). The left hand side of Fig. 4 displays the error curves obtained after a few iterations and corresponds to a spherical covariance model with a sill of 0.45, and ranges of 130 m in the x direction, 75 m in the y direction and 3.5 m in the z direction. Both error curves approach zero near the tenth shell indicating the suitability of the outer shell as the neighborhood boundary. Furthermore, the absence of significant horizontal deviations results in the approval of the proposed range parameters. Since the last segments of both error curves match, the total sill value is chosen correctly. The observed vertical deviations between the initial segments of both curves, however, indicate a mismatch between the different sill components of the covariance model. The right hand side of Fig. 4 illustrates a case of matched curves corresponding to a covariance model with a sill of 0.35, a nugget of 0.10 and ranges of 130 m in the x direction, 75 m in the y direction and 3.5 m in the z direction (step 3).
Once the covariance model and the neighborhood parameters are obtained, the observed attribute values are split into a deterministic trend component and a stochastic residual using a DK algorithm (step 4). The trend component is computed at the observation locations (Fig. 6d) and the grid nodes (Fig. 7d). Figure 6c displays the histogram of the residual component calculated at the observation locations.

Histograms of intermediate results at grid nodes (step 6 to 8 in workflow). In order to allow for an easy comparison with the intermediate results at the data location, the histograms are displayed in reverse order of appearance; a histogram of slime content realization (step 9), b histogram of realization in normal score domain (before step 8), c histogram of trend model at grid node locations (step 4), d histogram of inverse tail-corrected residuals (step 7), e histogram of simulated residuals (step 6)
The shape of the histogram of the residual component deviates slightly from one of an optimal normal distribution. Hence the necessity to apply the proposed tail-correcting transformation (step 5). Figure 6e displays the results of this tail correction. Afterwards, an SGS simulation is performed. The tail-corrected residuals are inserted as conditioning data together with the inferred covariance model and neighborhood geometry. Figure 7e displays a histogram of one resulting realization (step 6). Subsequently, the first back-transformation is performed (step 7). Figure 7c displays the histogram of the inverse tail-corrected realization. The trend at the grid nodes (Fig. 7d) has already been computed during step 4. The signal realizations (after the inverse tail correction) are combined with the computed trend model. Figure 7b displays the histogram of one such addition. Note that the mean value approximates 0 (0.02) and the standard deviation is close to 1 (0.97). A final back-transformation is performed to map the normal score realizations onto the original domain. Figure 7a displays a histogram of a back transformed realization.
A simulated realization can be approved as soon as its global and spatial statistics match those of the exploration data. Figures 6a and 7a show, respectively, the histograms of the sampled slime content and simulated values. There is a good agreement between both distributions. The mean value and standard deviation of the simulated values differ by less than 1 % from those of the sampled values.
To check for compliance with the first simulation objective, semi-variograms of different simulated realizations are calculated and compared with those of the exploration data. Figure 8 illustrates that the spatial continuity of the realizations in the east–west and north–south direction matches well with the one observed in the sample data.

Semi-variograms of different slime content realizations are compared with the ones observed in the initial data. The green color indicates the north–south direction, the red color indicates the east–west direction
The second simulation objective focusses on a correct detection of spatial extremes. Interactive three-dimensional visualization software was used to check whether the location of zones with extreme lows or highs overlap sampled locations with similar values. Moreover, a quantile–quantile plot (QQ) was constructed to assess whether the proportion of extreme and intermediate values is correctly reproduced in the simulated realizations. A qq-plot is particularly useful to check for discrepancies in the tails of both distributions. Figure 9 illustrates that a satisfactory agreement has been obtained between the distribution of the original data and the simulated slime content. From the 97 % quantile onwards, a small but negligible difference can be observed (the 6 most upper points in the graph).

QQ-plot comparing the distribution of the original data (after declustering) with that of a single simulated slime content realization, as displayed in Fig. 5a. A straight line along the main diagonal acts as a reference for optimal performance
The third simulation objective checks whether the modelled uncertainty, that is the variability between realizations, is realistic. The left hand side of Fig. 10 shows the probability plot corresponding to a case where the empirical and theoretical error curves are not matched (left hand side of Fig. 4). The right hand side of Fig. 10 shows the probability plot of a cross-validation simulation corresponding to a case of optimally inferred model parameters (right hand side of Fig. 4). The probability plot indicates that the modelled uncertainty is in global agreement with the limited amount of information provided by the samples. The improvement mainly results from a better characterization of the lower and upper tails of the spatial distribution, thereby better capturing the ‘true’ uncertainty.

Olea cross-validation plot. Cross-validation probabilities calculated for non-optimal model parameters (left). Cross-validation probabilities calculated for optimally inferred model parameters (right)
6 Conclusions and Further Recommendations
This contribution presents a new procedure to simulate resource attributes in the presence of a trend. The practicality of the proposed method resides in a straightforward and objective inference of model parameters, which does not require a prior removal of the complex trend. Practical aspects and implementation issues behind the theory of error-curve-based inference are discussed. The inference method is further integrated into a systematic simulation framework based on GLS and sequential Gaussian simulation. Accompanying validation guidelines were formulated to ensure a reliable characterization of uncertainty in the presence of a trend.
A case study demonstrates the applicability and validity of the presented simulation methodology. The added value and strength of the error-curve-based inference approach are illustrated. The case study was intended to test if the combination of a complex trend and a simulated residual field would result in a geologically realistic image of the deposit. Results show that the simulations are capable of reproducing complex features described by the field geologists. A validation study indicated that all simulation objective were met, that is the uncertainty and spatial variability were correctly characterized.
The current research was performed under the assumption that only the mean of the spatial random variables is non-stationary and that the residuals are stochastically independent of the trend (homoscedasticity). Solutions exist to independently deal with non-stationary two-point statistics (Machuca-Mory and Deutsch 2013) and effects of heteroscedasticity (Leuangthong and Deutsch 2004). However, these solutions already (implicitly) assume that the trend has been correctly and unambiguously removed from the data.
The proposed method does not allow for a complete elimination of the identified circularity related to non-stationarity. The application of a normal score transformation implicitly assumes global stationarity. Since stationarity is scale dependent, it is not unreasonable to assume that all measured attributes originate from the same global distribution while the local variability is modelled as a non-stationary phenomena. Figure 6e indicates that this was a valid assumption during the modelling of the studied heavy mineral sand deposit.
Future research needs to focus on the integration of a correct decomposition into a trend and a stochastic residual, based on model parameters which are correctly inferred under conditions of non-stationary 1-point, 2-point or multiple-point statistics. Subsequently, spatial variability can be characterized through non-stationary residual field simulations.
References
Armstrong M (1984) Problems with universal kriging. Math Geol 16(1):101–108
Beckers F, Bogaert P (1998) Nonstationarity of the mean and unbiased variogram estimation: extension of the weighted least-squares method. Math Geol 30(2):223–240
Benndorf J, Menz J (2014) Improving the assessment of uncertainty and risk in the spatial prediction of environmental impacts: a new approach for fitting geostatistical model parameters based on dual kriging in the presence of a trend. Stoch Environ Res Risk Assess 28(3):627–637
Botin JA, Valenzuela F, Guzman R, Monreal C (2015) A methodology for the management of risk related to uncertainty on the grade of the ore resources. Int J Min Reclam Environ 29(1):19–23 doi:10.1080/17480930.2013.852824
Chauvet P and Galli A (1982) Universal Kriging, CGMM Internal report no. 96
Chilès JP (2012) Delfiner P (2012) Geostatistics: modeling spatial uncertainty, 2nd edn. Wiley, New York
Christensen OF, Waagepetersen R (2002) Bayesian prediction of spatial count data using generalized linear mixed models. Biometrics 58(1):280–286
Christensen OF (2004) Monte Carlo maximum likelihood in model-based geostatistics. J Comput Graph Stat 13(3):702–718
Cressie NAC (1991) Statistics of spatial data. Wiley, New York, p 900
Delfiner P (1976) Linear estimation of nonstationary phenomena. In: Guarascio M, David M, Huijbregts CJ (eds) Advanced geostatistics in the mining industry. Reidel Publishing, Dordrecht, pp 49–68
Deutsch CV (2002) Geostatistical reservoir modeling. Oxford University Press, New York, p 376
Diggle PJ, Tawn JA, Moyeed RA (1998) Model-based geostatistics (with discussion). Appl Statistics 47(1):299–350
Diggle PJ, Ribieiro PJ (2007) Model-based geostatistics. Springer series in statistics, Springer, New York, p 228
Dominy SC, Noppé MA, Annels AE (2002) Errors and uncertainty in mineral resource and ore reserve estimation: the importance of getting it right. J Explor Min Geol 11(4):77–98
Dowd PA (1994) Risk assessment in reserve estimation and open-pit planning. Trans Inst Min Metall Sect A Min Technol 103(1):148–154
Dimitrakopoulos R (1998) Conditional simulation algorithms for modelling orebody uncertainty in open pit optimisation. Int J Surf Min Reclam Environ 12(4):173–179
Dimitrakopoulos R, Farelly CT, Godoy M (2002) Moving forward from traditional optimization: grade uncertainty and risk effects in open-pit design. Trans Inst Min Metall Sect A Min Technol 111(1):82–88
Dubrule O (1983) Two methods with different objectives: spline and kriging. Math Geol 11(4):77–98
Emery X, Ortiz JM (2005) Estimation of mineral resources using grade domains: critical analysis and a suggested methodology. J South Afr Inst Min Metall 105(1):247–256
Ferrara G, Guarascio M, Massacci P (1993) Mineral processing design and simulation using geostatistical modelling of ore characteristics. XVIII international mineral processing congress 1993. International mineral and processing council, Sydney, pp 497–504
Goovaerts P (1997) Geostatistics for Natural Resources Evaluation. Applied Geostatistics Series. Oxford University Press, New York, p 483
Gringarten E, Deutsch CV (2001) Teacher’s aide, variogam interpretation and modeling. Math Geol 33(4):507–534
Isaaks EH, Srivastava RM (1989) An introduction to applied geostatistics. Oxford University Press, New York, p 561
Image Resources (2011) EIS co-funded drilling, Cooljarloo Project E70/2898 North Perth Basin, Western Australia, Department of Mines and Petroleum, Perth, p 35
Jones G (2009) Mineral sands: an overview of the industry, Iluka Resources. Available from http://www.iluka.com. 29 May 2014
Journel AG, Huijbregts C (1978) Mining geostatistics. Blackburn Press, London, pp 600
Journel AG, Rossi ME (1989) When do we need a trend model in kriging? Math Geol 21(7):715–739
Knotters M, Brus DJ, Voshaar JH (1995) A comparison of kriging, co-kriging and kriging combined with regression for spatial interpolation of horizon depth with censored. Geoderma 67(3):227–246
Lark RM, Cullis BR, Welham SJ (2006) On spatial prediction of soil properties in the presence of a spatial trend: the empirical best linear unbiased predictor (E-BLUP) with REML. Eur J Soil Sci 57(6):787–799
Leuangthong O, Deutsch CV (2004) Transformation of residuals to avoid artifacts in geostatistical modelling with a trend. Math Geol 36(3):287–305
Machuca-Mory DF, Deutsch CV (2013) Non-stationary Geostatistical modelling based on distance weighted statistics and distributions. Math Geosci 45(1):31–48
Matheron G (1970) La théorie des variables régionalisées et ses applications, Cahiers du centre de morphologie mathématique de Fontainebleau, Ecole des Mines, Paris, p 220 (Translation (1971): The theory of regionalised variables and its applications)
Menz J (2012) Signalgesteuerte Kollokation—ein Verfahren zur Ableitung der Modellparameter für die geostatistische Vorhersage un Simulation. In: Sammelband 13 Geokinematischer Tag, Instituts für Markscheidewesen und Geodäsie der TU Bergakademie, eds. Sroka A, Freiberg, pp 333–342
Nowak M, Verly G (2005) The practice of sequential Gaussian simulation. In: Leuangthong O, Deutsch CV (eds) Geostatistics Banff 2004. Springer, Dordrecht, pp 387–398
Olea RA (2006) A six-step practical approach to semivrariogram modeling. Stoch Environ Res Risk Assess 20(5):307–318
Olea RA (2012) Building on crossvalidation for increasing the quality of geostatistical modeling. Stoch Environ Res Risk Assess 26(1):73–82
Rendu JM (2002) Geostatistical simulation for risk assessment and decision making: the mining industry perspective. Int J Surf Mining, Reclam Environ 16(2):122–133
Rossi ME, Deutsch CV (2014) Mineral resource estimation. Springer, Dordrecht, p 372
Vallee M (2000) Mineral resource + engineering, economic and legal feasibility = ore reserve. CIM Bull 93(1):53–61
WAMEX (2014) Western Australia mineral exploration index, Department of Mines and Petroleum, Available from http://www.dmp.wa.gov.au. 20 May 2014
Webster R, Oliver MA (2007) Geostatistics for environmental scientists. Wiley, Chichester, p 315
Whittle J (2014) Not for the faint-hearted. In: Dimitrakopoulos R (ed) Orebody modelling and strategy mine planning. The Australian Institute of Mining and Metallurgy, Perth, pp 3–6
Zimmerman DL (2010) Likelihood-based methods. In: Gelfand AE, Diggle PJ, Fuentes M, Guttorp P (eds) Handbook of spatial statistics. CRC Press, New York, pp 29–44
Zimmerman DL, Stein M (2010) Classical geostatistical methods. In: Gelfand AE, Diggle PJ, Fuentes M, Guttorp P (eds) Handbook of spatial statistics. CRC Press, New York, pp 29–44
Acknowledgments
The findings of this investigation are consequent of a research project at Delft University of Technology and is sponsored by “Royal IHC” whose assistance and support are gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Wambeke, T., Benndorf, J. An Integrated Approach to Simulate and Validate Orebody Realizations with Complex Trends: A Case Study in Heavy Mineral Sands. Math Geosci 48, 767–789 (2016). https://doi.org/10.1007/s11004-016-9639-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11004-016-9639-9