
Abstract
With the progressive increase in the number of existing ontologies, ontology matching became a challenging task. Ontology matching is a crucial step in the ontology integration process and its goal is to find correspondent elements in heterogeneous ontologies. A trend of clustering-based solutions for ontology matching has evolved, based on a divide-and-conquer strategy, which partitions ontologies, clusters similar partitions and restricts the matching to ontology elements of similar partitions. Nevertheless, most of these solutions considered solely the terminological aspect, ignoring other ontology aspects that can contribute to the final matching results. In this work, we developed a novel solution for ontology matching based on a consensus clustering of multiple aspects of ontology partitons. We partitioned the ontologies applying Community Detection techniques and applied Bayesian Cluster Ensembles (BCE) to find a consensus clustering among the terminological, topological and extensional aspects of ontology partitions. The matching results of our experimental study indicated that a BCE-based solution with three clusters best captured the contributions of the aspects, in comparison to other consensual solutions. The results corroborated the benefits of the synergy between the ontology aspects to the ontology alignment. We also verified that the BCE-based solution for three clusters yielded higher matching scores than other state-of-the-art solutions. Besides, our proposed methods structurize a configurable framework, which allows adding other ontology aspects and also other techniques.









Similar content being viewed by others

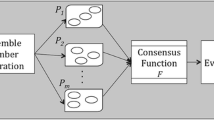
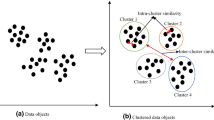
References
Algergawy, A., Massmann, S., Rahm, E. (2011). A clustering-based approach for large-scale ontology matching. ADBIS, 6909, 415–428.
Algergawy, A., Moawed, S., Sarhan, A., Eldosouky, A., Saake, G. (2014). Improving clustering-based schema matching using latent semantic indexing. Trans Large-Scale Data- and Knowledge-Centered Systems, 15, 102–123.
Blei, D., Ng, A., Jordan, M. (2003). Latent dirichlet allocation. Journal of Machine learning Research (3) 993–1022.
Blondel, V.D., Guillaume, J.L., Lambiotte, R., Lefebvre, E. (2008). Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment, 2008(10), P10,008.
Brandes, U., Delling, D., Gaertler, M., Gorke, R., Hoefer, M., Nikoloski, Z., Wagner, D. (2008). On modularity clustering. IEEE Transactions on Knowledge and Data Engineering, 20(2), 172–188.
Clauset, A., Newman, M.E.J., Moore, C. (2004). Finding community structure in very large networks. Physical Review E, 70, 066,111.
Coskun, G, Rothe, M, Teymourian, K, Paschke, A. (2011). Applying community detection algorithms on ontologies for identifying concept groups, Frontiers in Artificial Intelligence and Applications, vol 230. IOS Press Books.
Euzenat, J, & Shvaiko, P. (2013). Ontology matching. Springer.
Ferrara, A., Genta, L., Montanelli, S., Castano, S. (2015). Dimensional clustering of linked data: techniques and applications. Trans Large-Scale Data- and Knowledge-Centered Systems, 19, 55–86.
Fortunato, S. (2009). Community detection in graphs. arXiv:0906.
Ghosh, J, & Acharya, A. (2013). Cluster ensembles: theory and applications. In: Data Clustering: Algorithms and Applications, pp 551–570.
Harary, F. (1969). Graph theory. Addison-Wesley.
Honkela, T., Hyvärinen, A, Väyrynen, JJ. (2010). Wordica - emergence of linguistic representations for words by independent component analysis. Natural Language Engineering, 16(3), 277–308.
Hu, B., Kalfoglou, Y., Alani, H., Dupplaw, D., Lewis, P.H., Shadbolt, N. (2006). Semantic metrics. In Staab, S., & Svátek, V. (Eds.) EKAW, (Vol. 4248 pp. 166–181). Berlin: Springer, Lecture Notes in Computer Science.
Hyvärinen, A, Karhunen, J, Oja, E. (2001). Independent component analysis. John Wiley and Sons.
Ippolito, A., & de Almeida Junior, J.R. (2016). Ontology matching based on multi-aspect consensus clustering of communities. In Hammoudi, S., Maciaszek, L.A., Missikoff, M., Camp, O., Cordeiro, J. (Eds.) ICEIS 2016 - Proceedings of the 18th International Conference on Enterprise Information Systems, Volume 2, SciTePress (pp. 321–326).
Jain, A.K. (2010). Data clustering: 50 years beyond k-means. Pattern Recognition Letters, 31(8), 651–666.
Jain, A.K., Murty, M.N., Flynn, P.J. (1999). Data clustering: a review. ACM Computing Surveys, 31(3), 264–323.
Karpis, G., & Kumar, V. (1998). A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM Journal on Scientific Computing, 20(1), 359–392.
Karypis, G., Aggarwal, R., Kumar, V., Shekhar, S. (1999). Multilevel hypergraph partitioning: applications in vlsi domain. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 7(1), 69–79.
Kaufman, L., & Rousseeuw, P.J. (1990). Finding groups in data: an introduction to cluster analysis. John Wiley.
Kondrak, G. (2005). N-gram similarity and distance. In Consens, M.P., & Navarro, G. (Eds.) 12Th International Conference String Processing and Information Retrieval (SPIRE), (Vol. 3772 pp. 115–126). Berlin: Springer, Lecture Notes in Computer Science.
Kullback, S., & Leibler, R.A. (1951). On information and sufficiency. Annals of Mathematical Statistics, 22(1), 79–86.
Landauer, T.K., Foltz, P.W., Laham, D. (1998). Introduction to latent semantic analysis. Discourse Processes, 25, 259–284.
Levenshtein, V. (1966). Binary codes capable of correcting deletions and insertions and reversals. Soviet Physics Doklady, 10, 707–710.
Manning, C.D., Raghavan, P, Schütze, H. (2008). Introduction to information retrieval. Cambridge University Press.
Miller, G.A. (1995). WordNet: a lexical database for english. Communications of the ACM, pp. 39–45.
Pons, P., & Latapy, M. (2006). Computing communities in large networks using random walks. Journal of Graph Algorithms and Applications, 10(2), 191–218.
Reichardt, J., & Bornholdt, S. (2006). Statistical mechanics of community detection. Physical Review E, 74, 016,110.
Rousseeuw, P. (1987). Silhouette: a graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, 20, 53–65.
Sokal, R.R., & Michener, C.D. (1958). A statistical method for evaluating systematic relationships. University of Kansas Science Bulletin, 38, 1409–1438.
Strehl, A., & Ghosh, J. (2003). Cluster ensembles: a knowledge reuse framework for combining multiple partitions. Journal of Machine Learning Research, 3, 583–617.
Tran, T., Wang, H., Haase, P. (2009). Hermes: Data web search on a pay-as-you-go integration infrastructure. Web Semantics: Science, Services and Agents on the World Wide Web, 7(3), 189–203.
Wang, H., Shan, H., Banerjee, A. (2011). Bayesian cluster ensembles. Statistical Analysis and Data Mining, 4(1), 54–70.
Ward, J. (1963). Hierarchical grouping to optimize an objective function. Journal of the American Statistical Association, 58, 236–244.
Wasserman, S., & Faust, K. (1994). Social network analysis: methods and applications. Cambridge University Press.
West, D.B. (2001). Introduction to graph theory, 2nd edn. Prentice Hall.
Zhang, H., Hu, W., Qu, Y. (2012). Vdoc+: a virtual document based approach for matching large ontologies using mapreduce. Journal of Zhejiang University - Science C, 13(4), 257–267.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ippolito, A., de Almeida Junior, J.R. A multi-aspect approach to ontology matching based on Bayesian cluster ensembles. J Intell Inf Syst 55, 95–118 (2020). https://doi.org/10.1007/s10844-019-00583-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10844-019-00583-8