
Abstract
Validation and interpretation are the two last steps of a clustering process. Generally these steps are processed separately since the existing validity measures are not intended to express the interpretability or the non interpretability of clusters. We propose in this paper to merge the validation and interpretation steps by using a new supervised measure that we call Homogeneity degree and which is based on the criterion of interpretability to validate clusters. We also present an extended version of this measure in order to improve its use as a relative measure.










Similar content being viewed by others


Notes
\(H(P)=-\sum_{i=1}^{k}\frac{\parallel C_i \parallel}{n}log\frac{\parallel C_i \parallel}{n}\), \(H(L)=-\sum_{j=1}^{r}\frac{\parallel l_j \parallel}{n}log\frac{\parallel l_j \parallel}{n}\)
The overall Purity of the partition in such situation is equal to 1
The Section 7.4 presents a discussion about α and β
The two values of DP α, β are close to each other according to the two closeness techniques
The complexity of the algorithm depends on the complexity of CLUSTERING method.
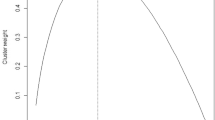
The use of graph is suggested only if the measure exhibits an increasing or a decreasing when the number of clusters increases. In this case, we select the value of k that generates a significant local change that has the shape of “knee”.
References
Amigo, E., Gonzalo, J., Artiles, J., & Verdejo, F. (2009). A comparison of extrinsic clustreing evaluation metrics based on formal constraints. Information Retrieval, 12(4), 461–486.
Chinchor, N. (1992). Muc-4 evaluation metrics. In Proceedings of the 4th conference on Message understanding (MUC4 ’92) (pp. 22–29). http://www.aclweb.org/anthology-new/M/M92/M92-1002.pdf.
Davies, D. L., & Bouldin, D. W. (1979). Cluster separation measure. IEEE Transactions on Pattern Analysis and Machine Intelligence, 4(2), 224–227.
Dom, E. B. (2001). An information-theoretic external cluster-validity measure. Tech. rep., RJ10219, IBM.
Dongen, S. (2000). Performance criteria for graph clustering and markov cluster experiments. Tech. rep., Amsterdam, The Netherlands.
Dunn, J. C. (1974). Well separated clusters and optimal fuzzy partitions. Journal of Cybernetica, 4, 95–104.
Fowlkes, E. B., & Mallows, C. L. (1983). A method for comparing two hierarchical clusterings. Journal of the American Statistical Association, 78(383), 553–569.
Halkidi, M., Batistakis, Y., & Vazirgiannis, M. (2001). On clustering validation techniques. Journal of Intelligent Information Systems, 17(2), 107–145.
Kaufman, L., & Rousseeuw, P. (1990). Finding groups in data: An introduction to cluster analysis. John Wiley & Sons.
Larsen, B., & Aone, C. (1999). Fast and effective text mining using linear-time document clustering. In Proceedings of the fifth International Conference on Knowledge discovery and data mining (KDD’99) (pp. 16–22). New York, NY, USA. doi:10.1145/312129.312186.
Mcqueen, J. (1967). some methods for classification and analysis of multivariate observations. In 5th Berkeley Symp. on Math. Statistics and Probability (pp. 281–298). Berkley, USA.
Meilă, M. (2005). Comparing clusterings: an axiomatic view. In Proceedings of the 22nd International Conference on Machine Learning (ICML ’05) (pp. 577–584). Bonn, Germany.
Meilă, M. (2007). Comparing clusterings - an information based distance. Journal of Multivariate Analysis, 98(5), 873–895.
Meilă, M., & Heckerman, D. (2001). An experimental comparison of model-based clustering methods. Machine Learning, 42(1–2), 9–29. doi:10.1023/A:1007648401407.
Milligan, G. W., Soon, S. C., & Sokol, L. M. (1983). The effect of cluster size, dimensionality and the number of clusters on recovery of true cluster structure. IEEE Transactions on Pattern Analysis and Machine Intelligence, 5, 40–47.
Mirkin, G. B. (1990). Mathematical classification and clustering. Kluwer Academic Press.
Naija, Y., & Sinaoui Blibech, K. (2009). A novel measure for validating clustering results applied to road traffic. In 3rd International Workshop on Knowledge Discovery from Sensor Data (SensorKDD-2009) (pp. 105–113). Paris, France.
Ng, R. T., & Han, J. (1994). Efficient and effective clustering methods for spatial data mining. In 20th Int. Conf. on Very Large DataBases (VLDB) (pp. 144–155). Santiago, Chile.
Rand, M. W. (1971). Objective criteria for the evaluation of clustering methods. Journal of the American Statistical Association, 66(336), 846–850.
van Rijsbergen, C. J. (1979). Information Retrieval (2nd ed.). Butterworth, URL: http://www.dcs.gla.ac.uk/Keith/Preface.html.
Rosenberg, A., Hirschberg, J. (2007). V-measure: A conditional entropy-based external cluster evaluation measure. In Proceedings of of the 2007 Joint Conference on Empirical Methods in NLP and Computational Natural Language Learning (pp. 410–420). Prague.
Shannon, C. (1948). A mathematical theory of communication. Bell System Technical Journal, 27, 379–423, 623–656.
Tan, P. N., Steinbach, M., & Kumar, K. (2005). Introduction to Data Mining. Pearson Addison Wesley.
Wallace, L. D. (1983). A method for comparing two hierarchical clusterings: comment. Journal of the American Statistical Association, 78(383), 569–576.
Zhao, Y., Karypis, & G. (2001). Criterion functions for document clustering: Experiments and analysis. Tech. rep., TR 01-40, Department of Computer Science, University of Minnesota, Minneapolis.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Naïja, Y., Sinaoui, K.B. Interpretability-based validity methods for clustering results evaluation. J Intell Inf Syst 39, 109–139 (2012). https://doi.org/10.1007/s10844-011-0185-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10844-011-0185-0