
Abstract
We deal with the following scheduling problem: an infinite number of tasks must be scheduled for processing on a finite number of heterogeneous machines, such as all tasks are sent to execution with a minimum delay. The tasks have causal dependencies and are generated in the context of biomedical applications, and produce results relevant for the medical domain, such as diagnosis support or drug dose adjust measures. The proposed scheduling model had a starting point in two known bounded number of processors algorithms: Modified Critical Path and Highest Level First With Estimated Times. Several steps were added to the original implementation along with a merge stage in order to combine the results obtained for each of the previously scheduled tasks. Regarding the implementation, a simulator was used to analyze and design the scheduling algorithms.










Similar content being viewed by others

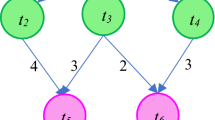

Notes
As the preprocessing stage produced only one hash in the case of these simulations, the algorithm has been modified by suppressing the step in which the hashes containing partial results were merged, without loss of generality with respect to the purposes of the simulation.
References
Achim, O.M., Pop, F., Cristea, V.: Reputation based selection for services in cloud environments. In: 2011 14th International Conference on Network-Based Information Systems (NBiS), pp. 268–273. IEEE (2011)
Adam, T.L., Chandy, K.M., Dickson, J.R.: A comparison of list schedules for parallel processing systems. Commun. ACM 17(12), 685–690 (1974). doi:10.1145/361604.361619
Ahmad, I., Kwok, Y.K.: On exploiting task duplication in parallel program scheduling. IEEE Trans. Parallel Distrib. Syst. 9(9), 872–892 (1998). doi:10.1109/71.722221
Baxter, J., Patel, J.H.: The last algorithm: a heuristic-based static task allocation algorithm. In: ICPP (1989)
Bessis, N., Sotiriadis, S., Cristea, V., Pop, F.: Modelling requirements for enabling meta-scheduling in inter-clouds and inter-enterprises. In: 2011 Third International Conference on Intelligent Networking and Collaborative Systems (INCoS), pp. 149–156. IEEE (2011)
Chen, H., Shirazi, B., Marquis, J.: Performance evaluation of a novel scheduling method: linear clustering with task duplication. In: Proceedings of the 2nd International Conference on Parallel and Distributed Systems, pp. 270–275 (1993)
Chung, Y.C., Ranka, S.: Applications and performance analysis of a compile-time optimization approach for list scheduling algorithms on distributed memory multiprocessors. In: Proceedings Supercomputing ’92, pp. 512–521 (1992). doi:10.1109/SUPERC.1992.236653
Coffman, E.G., Graham, R.L.: Optimal scheduling for two-processor systems. Acta Inform. 1(3), 200–213 (1972). doi:10.1007/BF00288685
Colin, J.Y., Chrtienne, P.: C.p.m. scheduling with small communication delays and task duplication. Oper. Res. 39(4), 680–684 (1991). doi:10.1287/opre.39.4.680
El-Rewini, H., Lewis, T.: Scheduling parallel program tasks onto arbitrary target machines. J. Parallel Distrib. Comput. 9(2), 138–153 (1990). doi:10.1016/0743-7315(90)90042-N. http://www.sciencedirect.com/science/article/pii/074373159090042N
Farina, R., Cuomo, S., De Michele, P., Piccialli, F.: A smart GPU implementation of an elliptic kernel for an ocean global circulation model. Appl. Math. Sci. 7(61–64), 3007–3021 (2013)
Farina, R., Cuomo, S., Michele, P.D.: A CUBLASCUDA implementation of PCG method of an ocean circulation model. In: AIP Conference Proceedings, vol. 1389, no. 1, pp. 1923–1926 (2011)
Forti, A., Bavikadi, S., Bigongiari, C., Cabras, G., De Angelis, A., De Lotto, B., Frailis, M., Hardt, M., Kornmayer, H., Kunze, M., et al.: Grid services for the magic experiment. In: Sidharth, B., Honsell, F., De Angelis, A. (eds.) Frontiers of Fundamental Physics. Springer, Dordrecht (2006)
Hagras, T., Janecek, J.: A high performance, low complexity algorithm for compile-time task scheduling in heterogeneous systems. In: Proceedings of 18th International Parallel and Distributed Processing Symposium, 2004, pp. 107– (2004). doi:10.1109/IPDPS.2004.1303056
Hu, T.C.: Parallel sequencing and assembly line problems. Oper. Res. 9(6), 841–848 (1961). doi:10.1287/opre.9.6.841
Hwang, J.J., Chow, Y.C., Anger, F.D., Lee, C.Y.: Scheduling precedence graphs in systems with interprocessor communication times. SIAM J. Comput. 18(2), 244–257 (1989). doi:10.1137/0218016
Kim, S., Browne, J.: General approach to mapping of parallel computations upon multiprocessor architectures. In: Proceedings of International Conference on Parallel Processing vol. 3, pp. 1–8 (1988)
Korver, M., Lucas, P.J.F.: Converting a rule-based expert system into a belief network. Med. Inform. 18, 219–241 (1993)
Kruatrachue, B., Lewis, T.: Duplication Scheduling Heuristics (DSH): A New Precedence Task Scheduler for Parallel Processor Systems. Oregon State University, Corvallis (1987)
Kruatrachue, B., Lewis, T.: Grain size determination for parallel processing. IEEE Softw. 5(1), 23–32 (1988). doi:10.1109/52.1991
Kwok, Y.K., Ahmad, I.: Bubble scheduling: a quasi dynamic algorithm for static allocation of tasks to parallel architectures. In: Proceedings of Seventh IEEE Symposium on Parallel and Distributed Processing, pp. 36–43 (1995). doi:10.1109/SPDP.1995.530662
Kwok, Y.K., Ahmad, I.: Dynamic critical-path scheduling: an effective technique for allocating task graphs to multiprocessors. IEEE Trans. Parallel Distrib. Syst. 7(5), 506–521 (1996). doi:10.1109/71.503776
Kwok, Y.K., Ahmad, I.: Static scheduling algorithms for allocating directed task graphs to multiprocessors. ACM Comput. Surv. 31(4), 406–471 (1999). doi:10.1145/344588.344618
Liou, J.C., Palis, M.A.: An efficient task clustering heuristic for scheduling dags on multiprocessors. In: Proceedings of the Workshop on Scheduling and Resource Management for Parallel and Distributed Processing, pp. 152–156 (1996)
Lucas, P.J.F., Segaar, R.W., Janssens, A.R.: Hepar: an expert system for the diagnosis of disorders of the liver and biliary tract. Liver 9(5), 266–275 (1989). doi:10.1111/j.1600-0676.1989.tb00410.x
Maheswaran, M., Siegel, H.J.: A dynamic matching and scheduling algorithm for heterogeneous computing systems. In: Proceedings of the Seventh Heterogeneous Computing Workshop, HCW ’98, pp. 57. IEEE Computer Society, Washington, DC, USA (1998). http://dl.acm.org/citation.cfm?id=795689.797882
Mehdiratta, N., Ghose, K.: A bottom-up approach to task scheduling on distributed memory multiprocessors. In: 1994 International Conference on Parallel Processing, vol. 2, pp. 151–154 (1994). doi:10.1109/ICPP.1994.14
Onisko, A., Druzdzel, M.J., Wasyluk, H.: A probabilistic causal model for diagnosis of liver disorders. In: In Proceedings of the Seventh International Symposium on Intelligent Information Systems (IIS–98), pp. 379–387 (1998)
Papadimitriou, C.H., Yannakakis, M.: Scheduling interval-ordered tasks. SIAM J. Comput. 8(3), 405–409 (1979). doi:10.1137/0208031
Papadimitriou, C.H., Yannakakis, M.: Towards an architecture-independent analysis of parallel algorithms. SIAM J. Comput. 19(2), 322–328 (1990). doi:10.1137/0219021
Radulescu, A., van Gemund, A.J.C.: FLB: Fast load balancing for distributed-memory machines. In: Proceedings of the 1999 International Conference on Parallel Processing, pp. 534–541 (1999). doi:10.1109/ICPP.1999.797442
Sarkar, V.: Partitioning and Scheduling Parallel Programs for Multiprocessors. MIT Press, Cambridge (1989)
Sfrent, A., Pop, F.: Asymptotic scheduling for many task computing in big data platforms. Inf. Sci. 319, 71–91 (2015)
Sih, G.C., Lee, E.A.: A compile-time scheduling heuristic for interconnection-constrained heterogeneous processor architectures. IEEE Trans. Parallel Distrib. Syst. 4(2), 175–187 (1993). doi:10.1109/71.207593
Simion, B., Leordeanu, C., Pop, F., Cristea, V.: A hybrid algorithm for scheduling workflow applications in grid environments (icpdp). In: Proceedings of the 2007 OTM Confederated International Conference on On the Move to Meaningful Internet Systems: CoopIS, DOA, ODBASE, GADA, and IS—Volume Part II, OTM’07, pp. 1331–1348. Springer, Berlin (2007). http://dl.acm.org/citation.cfm?id=1784707.1784728
Stratulat, A., Oncioiu, R., Pop, F., Dobre, C.: MTS2: Many task scheduling simulator. In: ECMS, pp. 586–593 (2015)
Stratulat, A., Oncioiu, R., Pop, F., Dobre, C.: MTS2: Many task scheduling simulator. In: Mladenov, V.M., Spasov, G., Georgieva, P., Petrova, G. (eds.) ECMS, pp. 586–593. European Council for Modeling and Simulation (2015)
Vasile, M.A., Pop, F., Tutueanu, R.I., Cristea, V., Kołodziej, J.: Resource-aware hybrid scheduling algorithm in heterogeneous distributed computing. Future Gener. Comput. Syst. 51, 61–71 (2015)
Wu, M.Y., Gajski, D.D.: Hypertool: a programming aid for message-passing systems. IEEE Trans. Parallel Distrib. Syst. 1(3), 330–343 (1990). doi:10.1109/71.80160
Yang, T., Gerasoulis, A.: DSC: scheduling parallel tasks on an unbounded number of processors. IEEE Trans. Parallel Distrib. Syst. 5(9), 951–967 (1994). doi:10.1109/71.308533
Acknowledgements
This article is based upon work from COST Action IC1406 High-Performance Modelling and Simulation for Big Data Applications (cHiPSet), supported by COST (European Cooperation in Science and Technology). Work has been partially supported by project DataWay - Real-time Data Processing Platform for Smart Cities: Making sense of Big Data (Platform de Procesare n Timp Real pentru Big Data n Orae Intelligent), with a grant of the Romanian National Authority for Scientific Research and Innovation, CNCS UEFISCDI, Project Number PN-II-RU-TE-2014-4-2731.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Popa, E., Iacono, M. & Pop, F. Adapting MCP and HLFET Algorithms to Multiple Simultaneous Scheduling. Int J Parallel Prog 46, 607–629 (2018). https://doi.org/10.1007/s10766-017-0516-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10766-017-0516-z