
Abstract
The advent of new static analysis tools has automated the searching for code clones, which are duplicated or similar code fragments in a program. However, clone detection tools can report many clones if the source code that is being searched is large. Programmers may have difficulty comprehending the extensive results from the detection tool, which may inhibit the ability to maintain the identified clones. Latent Semantic Indexing (LSI) is an information retrieval technique that attempts to find relationships in a corpus based on the analysis of the documents in the corpus and the terms in the documents. In this paper, LSI is used to cluster clone classes that have been identified initially by a clone detection tool. The goal of this paper is to detect trends and associations among the clustered clone classes and determine if they provide further comprehension to assist in the maintenance of clones. Experimental evaluation of the approach is reported from a sequence of tools that are chained together to perform an analysis of clones detected in the Microsoft Windows NT kernel source code.




Similar content being viewed by others


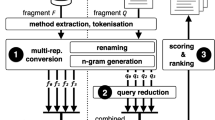
Notes
Clone Detection Literature web site, http://www.cis.uab.edu/tairasr/clones/literature
Windows Research Kernel, http://www.microsoft.com/resources/sharedsource/Licensing/researchkernel.mspx
CCFinder, http://www.ccfinder.net
Project web site, http://www.cis.uab.edu/tairasr/ir4pc
Apache Derby, http://db.apache.org/derby
References
Antoniol G, Villano U, Merlo E, Penta M (2002) Analyzing Cloning Evolution in the Linux Kernel. Inf Softw Technol 44(13):755–765
Balazinska M, Merlo E, Dagenais M, Lague B, Kontogiannis K (1999) Measuring Clone Based Re-engineering Opportunities. Proceedings of the International Software Metrics Symposium. Boca Raton, FL, 292–303
Baxter I, Yahin A, Moura L, Sant’Anna M, Bier L (1998) Clone Detection using Abstract Syntax Trees. Proceedings of the International Conference on Software Maintenance. Bethesda, MD, 368–377
Bellon S, Koschke R, Antoniol G, Krinke J, Merlo E (2007) Comparison and Evaluation of Clone Detection Tools. IEEE Trans Softw Eng 33(9):577–591
Collard M, Maletic J (2004) Document-Oriented Source Code Transformation using XML. Proceedings of the International Workshop on Software Evolution Transformation. Delft, The Netherlands, 11–14
Deerwester S, Dumais S, Furnas G, Landauer T, Harshman R (1990) Indexing by Latent Semantic Analysis. J Am Soc Inf Sci 41(6):391–407
Han J, Kamber M (2006) Data Mining: Concepts and Techniques, 2nd edn. Morgan Kaufman, San Fransisco
Jiang L, Misherghi G, Su Z, Glondu S (2007) DECKARD: Scalable and Accurate Tree-based Detection of Code Clones. Proceedings of the International Conference on Software Engineering. Minneapolis, MN, 96–105
Jiang Z, Hassan A (2007) A Framework for Studying Clones in Large Software Systems. Proceedings of the International Working Conference on Source Code Analysis and Manipulation. Paris, France, 203–212
Kamiya T, Kusumoto S, Inoue K (2002) CCFinder: A Multilinguistic Token-Based Code Clone Detection System for Large Scale Source Code. IEEE Trans Softw Eng 28(7):654–670
Kapser C, Godfrey M (2004) Aiding Comprehension of Cloning Through Categorization. Proceedings of the International Workshop on Principles of Software Evolution. Kyoto, Japan, 85–94
Koni-N’Sapu G (2001) A Scenario-Based Approach for Refactoring Duplicated Code in Object-Oriented Systems. Diploma Thesis. University of Bern, Bern, Switzerland
Kuhn A, Ducasse S, Gîrba T (2007) Semantic Clustering: Identifying Topics in Source Code. Inf Softw Technol 49(3):230–243
Li Z, Lu S, Myagmar S, Zhou Y (2006) CP-Miner: Finding Copy-Paste and Related Bugs in Large-Scale Software Code. IEEE Trans Softw Eng 32(3):176–192
Livieri S, Higo Y, Matsushita M, Inoue K (2007a) Very-Large Scale Code Clone Analysis and Visualization of Open Source Programs Using Distributed CCFinder: D-CCFinder. Proceedings of the International Conference on Software Engineering. Minneapolis, MN, 106–115
Livieri S, Higo Y, Matsushita M, Inoue K (2007b) Analysis of the Linux Kernel Evolution Using Code Clone Coverage. Proceedings of the International Workshop on Mining Software Repositories. Minneapolis, MN
Marcus A, Maletic J (2001) Identification of High-Level Concept Clones in Source Code. Proceedings of the International Conference on Automated Software Engineering. San Diego, CA, 107–114
Rieger M, Ducasse S (1998) Visual Detection of Duplicated Code. Proceedings of the ECOOP Workshop on Experiences in Object-Oriented Re-Engineering. Brussels, Belgium, 75–76
Rieger M, Ducasse S, Lanza M (2004) Insights into System-Wide Code Duplication. Proceedings of the Working Conference on Reverse Engineering. Delft, The Netherlands, 100–109
Russinovich M, Solomon D (2005) Microsoft Windows Internals: Microsoft Windows Server 2003, Windows XP, and Windows 2000. Redmond: Microsoft
Tairas R, Gray J, Baxter I (2006) Visualization of Clone Detection Results. Proceedings of the OOPSLA Workshop on Eclipse Technology Exchange. Portland, OR, 50–54
Zhao Y, Karypis G (2005) Topic-Driven Clustering for Document Datasets. Proceedings of the SIAM International Conference on Data Mining. Newport Beach, CA, 358–369
Acknowledgements
We thank the anonymous reviewers who provided many helpful suggestions that assisted in improving the content and presentation of this paper.
This project is supported by National Science Foundation grant CPA-0702764.
Author information
Authors and Affiliations
Corresponding author
Additional information
Editors: Tim Menzies and Letha Etzkorn
Rights and permissions
About this article
Cite this article
Tairas, R., Gray, J. An information retrieval process to aid in the analysis of code clones. Empir Software Eng 14, 33–56 (2009). https://doi.org/10.1007/s10664-008-9089-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10664-008-9089-1