
Abstract
We propose Hessian Approximated Multiple Subsets Iteration (HAMSI), which is a generic second order incremental algorithm for solving large-scale partially separable convex and nonconvex optimization problems. The algorithm is based on a local quadratic approximation, and hence, allows incorporating curvature information to speed-up the convergence. HAMSI is inherently parallel and it scales nicely with the number of processors. We prove the convergence properties of our algorithm when the subset selection step is deterministic. Combined with techniques for effectively utilizing modern parallel computer architectures, we illustrate that a particular implementation of the proposed method based on L-BFGS updates converges more rapidly than a parallel gradient descent when both methods are used to solve large-scale matrix factorization problems. This performance gain comes only at the expense of using memory that scales linearly with the total size of the optimization variables. We conclude that HAMSI may be considered as a viable alternative in many large scale problems, where first order methods based on variants of gradient descent are applicable.









Similar content being viewed by others


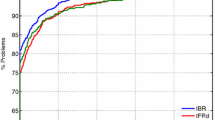
Notes
An already used random color is chosen if possible, otherwise, a new color is chosen.
References
Berahas, A.S., Nocedal, J., Takáč, M.: A multi-batch L-BFGS method for machine learning. In: Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5–10, 2016, Barcelona, Spain, pp. 1055–1063 (2016)
Bertsekas, D.P.: Incremental least squares methods and the extended Kalman filter. SIAM J. Optim. 6(3), 807–822 (1996)
Bertsekas, D.P.: Incremental gradient, subgradient, and proximal methods for convex optimization: a survey. Optim. Mach. Learn. 1–38, 2011 (2010)
Blatt, D., Hero, A.O., Gauchman, H.: A convergent incremental gradient method with a constant step size. SIAM J. Optim. 18(1), 29–51 (2007)
Bozdağ, D., Çatalyürek, Ü.V., Gebremedhin, A.H., Manne, F., Boman, E.G., Özgüner, F.: Distributed-memory parallel algorithms for distance-2 coloring and related problems in derivative computation. SIAM J. Sci. Comput. 32(4), 2418–2446 (2010)
Byrd, R.H., Hansen, S.L., Nocedal, J., Singer, Y.: A stochastic quasi-Newton method for large-scale optimization. SIAM J. Optim. 26(2), 1008–1031 (2016)
Byrd, R.H., Nocedal, J., Schnabel, R.B.: Representations of quasi-Newton matrices and their use in limited memory methods. Math. Program. 63(1–3), 129–156 (1994)
Cichocki, A., Zdunek, R., Phan, A.H., Amari, S.: Nonnegative Matrix and Tensor Factorization. Wiley, New York (2009)
Daneshmand, A., Facchinei, F., Kungurtsev, V., Scutari, G.: Hybrid random/deterministic parallel algorithms for convex and nonconvex big data optimization. IEEE Trans. Signal Process. 63(15), 3914–3929 (2015)
Facchinei, F., Scutari, G., Sagratella, S.: Parallel selective algorithms for nonconvex big data optimization. IEEE Trans. Signal Process. 63(7), 1874–1889 (2015)
Gebremedhin, A.H., Manne, F., Pothen, A.: Parallel distance-k coloring algorithms for numerical optimization. In: Euro-Par 2002 Parallel Processing—8th International Conference, pp. 912–921 (2002)
Gebremedhin, A.H., Manne, F., Pothen, A.: What color is your Jacobian? Graph coloring for computing derivatives. SIAM Rev. 47(4), 629–705 (2005)
Gebremedhin, A.H., Nguyen, D., Patwary, MdMA, Pothen, A.: ColPack: software for graph coloring and related problems in scientific computing. ACM Trans. Math. Softw. 40(1), 1:1–1:31 (2013)
Gemulla, R., Nijkamp, E., Haas, P.J., Sismanis, Y.: Large-scale matrix factorization with distributed stochastic gradient descent. In: ACM SIGKDD (2011)
Gower, R.M., Goldfarb, D., Richtárik, P.: Stochastic block BFGS: squeezing more curvature out of data. In: Balcan, M.F., Weinberger, K.Q. (eds.) Proceedings of the 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, New York, USA, 20–22 June 2016. PMLR, pp. 1869–1878
Gürbüzbalaban, M., Ozdaglar, A., Parrilo, P.: A globally convergent incremental Newton method. Math. Program. 151(1), 283–313 (2015)
Harper, F.M., Konstan, J.A.: The movielens datasets: history and context. ACM Trans. Interact. Intell. Syst. 5(4), 19:1–19:19 (2015)
Kschischang, F.R., Frey, B.J., Loeliger, H.-A.: Factor graphs and the sum–product algorithm. IEEE Trans. Inf. Theory 47(2), 498–519 (2001)
Lian, X., Huang, Y., Li, Y., Liu, J.: Asynchronous parallel stochastic gradient for nonconvex optimization. In: Advances in Neural Information Processing Systems, pp. 2737–2745 (2015)
Liu, J., Wright, S.J., Ré, C., Bittorf, V., Sridhar, S.: An asynchronous parallel stochastic coordinate descent algorithm. J. Mach. Learn. Res. 16(1), 285–322 (2015)
Mangasarian, O.L., Solodov, M.V.: Serial and parallel backpropation convergence via nonmonotone perturbed minimization. Optim. Methods Softw. 4, 103–116 (1994)
Mareček, J., Richtárik, P., Takáč, M.: Distributed block coordinate descent for minimizing partially separable functions. In: Al-Baali, M., Grandinetti, L., Purnama, A. (eds.) Numerical Analysis and Optimization, pp. 261–288. Springer, Berlin (2015)
Matula, D.W.: A min-max theorem for graphs with application to graph coloring. SIAM Rev. 10, 481–482 (1968)
Mokhtari, A., Eisen, M., Ribeiro, A.: IQN: an incremental quasi-Newton method with local superlinear convergence rate. arXiv preprint arXiv:1702.00709 (2017)
Moritz, P., Nishihara, R., Jordan, M.I.: A linearly-convergent stochastic L-BFGS algorithm. In: Artificial Intelligence and Statistics, pp. 249–258 (2016)
Mota, J.F.C., Xavier, J.M.F., Aguiar, P.M.Q., Püschel, M.: D-ADMM: a communication-efficient distributed algorithm for separable optimization. IEEE Trans. Signal Process. 61(10), 2718–2723 (2013)
Pan, X., Lam, M., Tu, S., Papailiopoulos, D., Zhang, S., Jordan, M.I., Ramchandran, K., Ré, C.: Cyclades: conflict-free asynchronous machine learning. In: Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R. (eds.) Advances in Neural Information Processing Systems, vol. 29, pp. 2568–2576. Curran Associates Inc, Red Hook (2016)
Recht, B., Re, C., Wright, S., Feng, N.: HOGWILD: a lock-free approach to parallelizing stochastic gradient descent. In: Shawe-Taylor, J., Zemel, R.S., Bartlett, P.L., Pereira, F., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems, vol. 24, pp. 693–701. Curran Associates Inc., Red Hook (2011)
Richtárik, P., Takáč, M.: Parallel coordinate descent methods for big data optimization. Math. Program. 156(1–2), 433–484 (2016)
Roux, N.L., Schmidt, M., Bach, F.R.: A stochastic gradient method with an exponential convergence\_rate for finite training sets. In: Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems, pp. 2663–2671. Curran Associates Inc., Red Hook (2012)
Scherrer, C., Halappanavar, M., Tewari, A., Haglin, D.: Scaling up coordinate descent algorithms for large \(\ell _1\) regularization problems. In: Proceedings of the 29th International Conference on Machine Learning, ICML 2012, Edinburgh, Scotland, UK, June 26–July 1 (2012)
Schraudolph, N.N., Yu, J., Gunter, S.: A stochastic quasi-Newton method for online convex optimization. In: Proceedings of the 11th International Conference Artificial Intelligence and Statistics (AISTATS), pp. 433–440 (2007)
Shamir, O., Srebro, N., Zhang, T.: Communication efficient distributed optimization using an approximate Newton-type method. In: International Conference on Machine Learning (ICML) (2014)
Singh, A.P., Gordon, G.J.: A unified view of matrix factorization models. In: European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, Part II, number 5212, pp. 358–373. Springer, Berlin (2008)
Sohl-Dickstein, J., Poole, B., Ganguli, S.: Fast large-scale optimization by unifying stochastic gradient and quasi-Newton methods. In: Proceedings of the 31th International Conference on Machine Learning (ICML), pp. 604–612 (2014)
Solodov, M.V.: Incremental gradient algorithms with stepsizes bounded away from zero. Comput. Optim. Appl. 11(1), 23–35 (1998)
Tseng, P.: An incremental gradient (-projection) method with momentum term and adaptive stepsize rule. SIAM J. Optim. 8(2), 506–531 (1998)
Wang, X., Ma, S., Goldfarb, D., Liu, W.: Stochastic quasi-Newton methods for nonconvex stochastic optimization. SIAM J. Optim. 27(2), 927–956 (2017)
Yousefian, F., Nedić, A., Shanbhag, U.V.: Stochastic quasi-Newton methods for non-strongly convex problems: convergence and rate analysis. In: 2016 IEEE 55th Conference on Decision and Control (CDC), pp. 4496–4503. IEEE (2016)
Zuckerman, D.: Linear degree extractors and the inapproximability of max clique and chromatic number. Theory Comput. 3, 103–128 (2007)
Acknowledgements
This work is supported by the Scientific and Technological Research Council of Turkey (TUBITAK) Grant No. 113M492.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: Omitted proofs
Appendix A: Omitted proofs
1.1 Proof of Lemma 1
By using Assumption A.2, we have
Note for \(j=1, \dots , \ell -1\) that
where the last inequality holds by Assumption A.4. Therefore, we have
1.2 Proof of Lemma 2
At iteration \(t + 1\), we have
This shows that
where
Using now (9) implies
Then, we obtain
1.3 Proof of Theorem 3
As f is a twice differentiable function, we have
Using now Lemma 2 along with (11) and (12), we obtain
where \(\bar{B} \equiv CB + \frac{LK}{2}\left( \frac{B + C(M+1)}{M+1}\right) ^2\). Due to Assumption A.1, we can write \(\inf _{x \in \mathbb {R}^n} f(x) = f^* > -\infty \). Thus, we obtain
Relation (10) and Lemma 2.2 in Mangasarian and Solodov [21] together show that the sequence \(\{f(x^{(t)})\}\) converges. By using (13), we further have
Let now \(t \rightarrow \infty \), then
Using again Assumption A.1 and conditon (10), we obtain
Now, suppose for contradiction that the sequence \(\{\nabla f(x^{(t)})\}\) does not converge to zero. Then, there exists an increasing sequence of integers such that for some \(\varepsilon > 0\), we have \(\Vert \nabla f(x^{(t_\tau )})\Vert \ge \varepsilon \) for all \(\tau \). On the other hand, the relation (15) implies that there exist some \(j > t_\tau \) such that \(\Vert \nabla f(x^{(j)})\Vert \le \frac{\varepsilon }{2}\). Let \(j_\tau \) be the least integer for each \(\tau \) satisfying these inequalities. Then, we have
where the last inequality follows from Lemma 2. Since \(0 < M \le U\), there exists \(\zeta \le \frac{M}{U} \le 1\) such that
Thus, we obtain
Then, using together with inequality (13), we obtain
Since the left-hand-side of the inequality converges and the condition (10) holds, we have
But our choice of \(t_\tau \) and \(j_\tau \) guarantees \(\Vert \nabla f(x^{(k)})\Vert > \frac{\varepsilon }{2}\) for all \(t_\tau \le k \le j_\tau \), and hence, we arrive at a contradiction with (16). Therefore, \({\nabla f(x^{(t)})}\) converges, and with the continuity of the gradient, we conclude for each accumulation point \(x^*\) of the sequence \(\{x^{(t)}\}\) that \(\nabla f(x^*) = 0\) holds.
Rights and permissions
About this article

Cite this article
Kaya, K., Öztoprak, F., Birbil, Ş.İ. et al. A framework for parallel second order incremental optimization algorithms for solving partially separable problems. Comput Optim Appl 72, 675–705 (2019). https://doi.org/10.1007/s10589-018-00057-7
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-018-00057-7