
Abstract
The MPS is a particle method developed to simulate incompressible flows with free surfaces that has several applications in nonlinear hydrodynamics. Much effort has been done to handle the large amount of particles required for simulating practical problems with desired refinement. However, the efficient use of the currently available computational resources, such as computer cluster, remains as a challenge. The present paper proposes a new strategy to parallelize the MPS method for fully distributed computing in cluster, which enables to simulate models with hundreds of millions of particles and keeps the required runtime within reasonable limits, as shown by the analysis of scalability and performance. The proposed strategy uses a non-geometric dynamic domain decomposition method that provides homogeneous load balancing and for very large models the scalability is supra-linear. Also, the domain decomposition (DD) is carried out only in the initial setup. As a result, the DD method is based on renumbering of particles using an original fully distributed sorting algorithm. Moreover, unlike the usual strategies, none of the processors require access to global data of the particles on any time step. Therefore, the limit for the maximum size of the model depends more on the total memory of the allocated nodes than the quantity of the local memory of each node. Thus, by extending the application of MPS method to very large models, this study contributes to consolidating the method as a practical tool to investigate complex engineering problems.
















Similar content being viewed by others
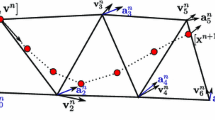
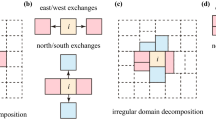

Notes
The difference between the amount of particles in the subdomains is at most 1.
References
Koshizuka, S., Tamako, H., Oka, Y.: A particle method for incompressible viscous flow with fluid fragmentation. CFD J. 4(1), 29–46 (1995)
Iwashita, T., Shimasaki, M.: Parallel processing of 3-D eddy current analysis with moving conductor using parallelized ICCG solver with renumbering process. IEEE Trans. Magn. 36(4), 1504–1509 (2000)
Motezuki, F.K., Cheng, L.Y., Tsukamoto, M.M.: A study on parallelized solvers for moving particle semi-implicit method (MPS). In: Proceedings of the 20th International Congress of Mechanical Engineering (COBEM2009). Gramado, Brazil (2009)
Yao, Z., Wang, J.S., Cheng, M.: Improved o(n) neighbor list method using domain decomposition and data sorting. High Perform. Comput. Eng. Syst. (HPCES) 161(1–2), 27–35 (2004)
Nyland, L., Prins, J., Yun, R.H., Hermans, J., Kum, H., Wang, L.: Achieving scalable parallel molecular dynamics using dynamic spatial domain decomposition techniques. J. Parallel Distrib. Comput. 47, 125–138 (1997)
Gotoh, H., Khayyer, A., Ikari, H., Chiemi, H.: 3D-CMPS method for improvement of water surface tracking in breaking waves. In: 4th SPHERIC Workshop, pp. 265–272. Nantes, France (2009)
Iribe, T., Fujisawa, T., Koshizuka, S.: Reduction of communication in parallel computing of particle method for flow simulation of seaside areas. Cost Eng. 52(4), 287–304 (2010)
Gotoh, H., Sakai, T.: Key issues in the particle method for computation of wave breaking. Cost Eng. 53(2–3), 171–179 (2006)
Ikeda, H., Koshizuka, S., Oka, Y.: Numerical analysis of jet injection behavior for fuel-coolant interaction using particle method. J. Nucl. Sci. Tech. 38(3), 174–182 (2001)
Formaggia, L., Sala, M., Saleri, F.: Domain decomposition techniques. Tech. rep, Sandia National Laboratories, Albuquerque, USA (2005)
Knuth, D.E.: The Art of Computer Programming. Sorting and Searching, vol. 3. Addison Wesley Longman Publishing Co., Inc., Redwood City (1998)
Meloni, S., Rosati, M., Colombo, L.: Efficiently particle labeling in atomistic simulations. J. Chem. Phys. 126, 121102 (2007)
The OpenMP API specification for parallel programming. http://openmp.org/wp/
Message passing interface (MPI). https://computing.llnl.gov/tutorials/mpi/
VTK, Visualization toolkit. http://www.vtk.org/
Issa, R., Violeau, D.: Test case 2: 3D-dambreaking. Tech. rep, SPH European Research Interest Community—SPHERIC ERCOFTAC, Rome, Italy (2006)
Issa, R., Violeau, D.: SPHERIC Test2, 3D schematic dam break and evolution of the free surface. https://wiki.manchester.ac.uk/spheric/index.php/Test2
Ganglia monitoring system—scalable distributed monitoring system for high-performance computing systems. http://ganglia.sourceforge.net/
Marr, D.T., Binns, F., Hill, D.L., Hinton, G., Koufaty, D.A., Miller, J.A., Upton, M.: Hyper-threading technology architecture and microarchitecture. Intel Technol. J. 6–1, 4–15 (2002)
Grama, A., Gupta, A., Karypis, G., Kumar, V.: Introduction to Parallel Computing, 2nd edn. Addison Wesley, Boston (2003)
Ogino, M., Shioya, R., Kawai, H., Yoshimura, S.: Seismic response analysis of nuclear pressure vessel model with ADVENTRUE system on the Earth Simulator. J. Earth Simul. 2, 41–54 (2005)
Ihmsen, M., Akinci, N., Becker, M., Teschner, M.: A parallel SPH implementation on multi-core CPUs. Comput. Graph. Forum. 30(1), 99–112 (2011)
Hori, C., Gotoh, H., Ikari, H., Khayyer, A.: GPU-acceleration for Moving Particle Semi-implicit Method. Comput. Fluids 51, 174 (2011)
Ovaysi, S., Piri, M.: Multi-GPU acceleration of direct pore-scale modeling of fluid flow in natural porous media. Comput. Phys. Commun. 183, 1890–1898 (2012)
Bellezi, C.A., Cheng, L.Y.: Particle based numerical analysis of green water on FSOP deck. In: 32nd International Conference on Ocean, Offshore and Arctic Engineering, OMAE2013-11553, Nantes, France (2013)
Murotani, K., Koshizuka, S., Tamai, T., Shibata, K., Mitsume, N., Yoshimura, S., Tanaka, S., Hasegawa, K., Nagai, E., Fujisawa, T.: Development of hierarchical domain decomposition explicit MPS method and application to large-scale tsunami analysis with floating objects. J. Adv. Simul. Sci. Eng. (JASSE) 1(1), 16–35 (2014)
Duan, G., Chen, B.: Comparison of parallel solvers for Moving Particle Semi-Implicit method. Eng. Comput. 32(3), 834–862 (2015)
Taniguchi, D., Sato, L.M., Cheng, L.Y.: Explicit moving particle simulation method on GPU clusters. Blucher Mech. Eng. Proc. 1(1), 1155 (2014)
Acknowledgments
The authors would like to express their gratitude to PETROBRAS S.A for the financial support to present research.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Fernandes, D.T., Cheng, LY., Favero, E.H. et al. A domain decomposition strategy for hybrid parallelization of moving particle semi-implicit (MPS) method for computer cluster. Cluster Comput 18, 1363–1377 (2015). https://doi.org/10.1007/s10586-015-0483-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10586-015-0483-3