
Abstract
This paper addresses the nontrivial task of Twitter financial disambiguation (TFD), which is relevant to filter financial domain tweets (e.g., alloy steel or coffee prices) when no unique identifiers (e.g., cashtags) are adopted. To automate TFD, we propose a transfer learning approach that uses freely labeled news titles to train diverse one-class and two-class classification methods. These include different text handling transforms, adaptations of statistical measures and modern machine learning methods, including support vector machines (SVM), deep autoencoders and multilayer perceptrons. As a case study, we analyzed the domain of alloy steel prices, collecting a recent Twitter dataset. Overall, the best results were achieved by a two-class SVM fed with TFD statistical measures and topic model features, obtaining an 80% and 71% discrimination level when tested with 11,081 and 3000 manually labeled tweets. The best one-class performance (78% and 69% for the same test tweets) was obtained by a term frequency-inverse document frequency classifier (TF-IDFC). These models were further used to generate a Financial User Relevance rank (FUR) score, aiming to filter relevant users. The SVM and TF-IDFC FUR models obtained a predictive user discrimination level of 80% and 75% when tested with a manually labeled test sample of 418 users. These results confirm the proposed joint TFD-FUR approach as a valuable tool for the selection of Twitter texts and users for financial social media analytics (e.g., sentiment analysis, detection of influential users).




Similar content being viewed by others
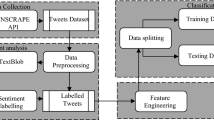

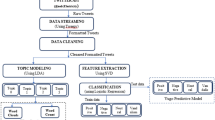
Notes
References
Awwalu J, Bakar AA, Yaakub MR (2019) Hybrid n-gram model using naïve bayes for classification of political sentiments on twitter. Neural Comput Appl 1:1–14
Zola P, Cortez P, Carpita M (2019) Twitter user geolocation using web country noun searches. Decis Support Syst 120:50–59
Oliveira N, Cortez P, Areal N (2017) The impact of microblogging data for stock market prediction: using twitter to predict returns, volatility, trading volume and survey sentiment indices. Expert Syst Appl 73:125–144
Groß-Klußmann A, König S, Ebner M (2019) Buzzwords build momentum: global financial twitter sentiment and the aggregate stock market. Expert Syst Appl 136(1):171–186
Pagolu VS, Reddy KN, Panda G, Majhi B (2016) Sentiment analysis of twitter data for predicting stock market movements. In: International conference on signal processing, communication, power and embedded system (SCOPES). IEEE, pp 1345–1350
Lechthaler F, Leinert L (2012) Moody oil: What is driving the crude oil price? Empirical Economics 1:1–32
Li J, Xu Z, Yu L, Tang L (2016) Forecasting oil price trends with sentiment of online news articles. Procedia Comput Sci 91:1081–1087
Bollen J, Mao H, Zeng X (2011) Twitter mood predicts the stock market. J Comput Sci 2(1):1–8
Feuerriegel S, Neumann D (2013) News or noise? how news drives commodity prices. In: Proceedings of the international conference on information systems, ICIS, Milano, Italy, December 15–18
Rao T, Srivastava S (2013) Modeling movements in oil, gold, forex and market indices using search volume index and twitter sentiments. In: Proceedings of the 5th annual ACM web science conference. ACM, pp 336–345
Pröllochs N, Feuerriegel S, Neumann D (2015) Enhancing sentiment analysis of financial news by detecting negation scopes. In: 48th Hawaii international conference on system sciences. IEEE, pp 959–968
Nguyen TH, Shirai K, Velcin J (2015) Sentiment analysis on social media for stock movement prediction. Expert Syst Appl 42(24):9603–9611
Daniel M, Neves RF, Horta N (2017) Company event popularity for financial markets using twitter and sentiment analysis. Expert Syst Appl 71:111–124
Maslyuk-Escobedo S, Rotaru K, Dokumentov A (2017) News sentiment and jumps in energy spot and futures markets. Pac-Basin Financ J 45:186–210
Huang D, Lehkonen H, Pukthuanthong K, Zhou G (2018) Sentiment across asset markets. SSRN 3185140. https://doi.org/10.2139/ssrn.3185140
Mudinas A, Zhang D, Levene M (2019) Market trend prediction using sentiment analysis: lessons learned and paths forward. CoRR arXiv:abs/1903.05440
Banerjee S, Pedersen T (2002) An adapted lesk algorithm for word sense disambiguation using wordnet. In: International conference on intelligent text processing and computational linguistics. Springer, pp 136–145
Zola P, Carpita M (2016) Forecasting the steel product prices with the arima model. Statistica and Applicazioni 14(1):1
Wei W, Xia X, Wozniak M, Fan X, Damaševičius R, Li Y (2019) Multi-sink distributed power control algorithm for cyber-physical-systems in coal mine tunnels. Comput Netw 161:210–219
Lee C, Won J, Lee E-B (2019) Method for predicting raw material prices for product production over long periods. J Constr Eng Manag 145(1):05018017
Wei W, Song H, Li W, Shen P, Vasilakos A (2017) Gradient-driven parking navigation using a continuous information potential field based on wireless sensor network. Inf Sci 408:100–114
Pan S, Yang Q (2010) A survey on transfer learning. IEEE Trans Knowl Data Eng 22(10):1345–1359
Liu X, Zhou Y, Zheng R (2007) Sentence similarity based on dynamic time warping. In: Proceedings of the 1st IEEE international conference on semantic computing (ICSC), Irvine, California, USA, pp 250–256
Yan X, Guo J, Lan Y, Cheng X (2013) A biterm topic model for short texts. In: Proceedings of the 22nd international conference on World Wide Web, ACM, pp 1445–1456
Iosif E, Potamianos A (2015) Similarity computation using semantic networks created from web-harvested data. Nat Lang Eng 21(1):49–79
Kenter T, De Rijke M (2015) Short text similarity with word embeddings. In: Proceedings of the 24th ACM international on conference on information and knowledge management, ACM, pp 1411–1420
Song Y, Roth D (2015) Unsupervised sparse vector densification for short text similarity. In: Proceedings of the 2015 conference of the North American chapter of the association for computational linguistics: human language technologies, pp 1275–1280
Lee MD, Pincombe B, Welsh M (2005) An empirical evaluation of models of text document similarity. In: Proceedings of the annual meeting of the cognitive science society, pp 1254–1259
Chang M-W, Ratinov L-A, Roth D, Srikumar V (2008) Importance of semantic representation: dataless classification. AAAI 2:830–835
Zhang H, Yang K, Jacob E (2015) Topic level disambiguation for weak queries. CoRR arXiv:abs/1502.04823
Amiri H, Resnik P, Boyd-Graber J, Daumé III H (2016) Learning text pair similarity with context-sensitive autoencoders. In: Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: Long Papers), vol 1, pp 1882–1892
Neculoiu P, Versteegh M, Rotaru M (2016) Learning text similarity with SIAMESE recurrent networks. In: Proceedings of the 1st workshop on representation learning for NLP, pp 148–157
Lim KH, Karunasekera S, Harwood A (2017) Clustop: A clustering-based topic modelling algorithm for twitter using word networks. In: IEEE international conference on big data (big data). IEEE, pp. 2009–2018
Chaplot DS, Salakhutdinov R (2018) Knowledge-based word sense disambiguation using topic models. In: Proceedings of the 32nd AAAI conference on artificial intelligence. (AAAI-18), pp 5062–5069
Li X, Zhang A, Li C, Ouyang J, Cai Y (2018) Exploring coherent topics by topic modeling with term weighting. Inf Process Manag 54(6):1345–1358
Lin Y-S, Jiang J-Y, Lee S-J (2014) A similarity measure for text classification and clustering. IEEE Trans Knowl Data Eng 26(7):1575–1590
Blei DM, Ng AY, Jordan MI (2003) Latent dirichlet allocation. J Mach Learn Res 3:993–1022
Sanborn A, Skryzalin J (2015) Deep learning for semantic similarity, CS224d: deep learning for natural language processing. Stanford University, Stanford
Zola P, Cortez P, Ragno C, Brentari E (2019) Social media cross-source and cross-domain sentiment classification. Int J Inf Technol Decis Mak 18(15):1469–1499
Tashman L (2000) Out-of-sample tests of forecasting accuracy: an analysis and review. Int Forecast J 16(4):437–450
Yamaguchi Y, Takahashi T, Amagasa T, Kitagawa H (2010) Turank: Twitter user ranking based on user-tweet graph analysis. In: International conference on web information systems engineering. Springer, pp 240–253
Castillo C, Mendoza M, Poblete B (2011) Information credibility on twitter. In: Proceedings of the 20th international conference on World wide web. ACM, pp 675–684
Pal A, Counts S (2011) Identifying topical authorities in microblogs. In: Proceedings of the 4th ACM international conference on Web search and data mining. ACM, pp 45–54
Gayo-Avello D (2013) Nepotistic relationships in twitter and their impact on rank prestige algorithms. Inf Process Manag 49(6):1250–1280
Ito J, Song J, Toda H, Koike H, Oyama S (2015) Assessment of tweet credibility with LDA features. In: Proceedings of the 24th international conference on world wide web. ACM, pp 953–958
Cortez P, Oliveira N, Ferreira JP (2016) Measuring user influence in financial microblogs: experiments using stocktwits data. In: Proceedings of the 6th international conference on web intelligence, mining and semantics. ACM, p 23
Eliacik AB, Erdogan N (2018) Influential user weighted sentiment analysis on topic based microblogging community. Expert Syst Appl 92:403–418
Alsmadi I, Hoon GK (2019) Term weighting scheme for short-text classification: Twitter corpuses. Neural Comput Appl 31(8):3819–3831
Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J (2013) Distributed representations of words and phrases and their compositionality. In: Advances in neural information processing systems, pp 3111–3119
Wood-Doughty Z, Andrews N, Dredze M (2018) Convolutions are all you need (for classifying character sequences). In: Proceedings of the 4th workshop on noisy user-generated text, NUT@EMNLP 2018, Brussels, Belgium, November, pp 208–213
Manevitz LM, Yousef M (2001) One-class SVMs for document classification. J Mach Learn Res 2:139–154
Senin P (2008) Dynamic time warping algorithm review. Information and Computer Science Department University of Hawaii at Manoa Honolulu, USA 855:1–23
Utkin LV, Zaborovsky VS, Lukashin AA, Popov SG, Podolskaja AV (2017) A siamese autoencoder preserving distances for anomaly detection in multi-robot systems. In: International conference on control, artificial intelligence, robotics & optimization (ICCAIRO). IEEE, pp 39–44
Xu Y, Jones GJ, Li J, Wang B, Sun C (2007) A study on mutual information-based feature selection for text categorization. J Comput Inf Syst 3(3):1007–1012
Oliveira N, Cortez P, Areal N (2016) Stock market sentiment lexicon acquisition using microblogging data and statistical measures. Decis Support Syst 85:62–73
Hastie T, Tibshirani R, Friedman J (2008) The elements of statistical learning: data mining, inference, and prediction, 2nd edn. Springer, New York
Goodfellow I, Bengio Y, Courville A, Bengio Y (2016) Deep learning, vol 1. MIT Press, Cambridge
Costa J, Silva C, Antunes M, Ribeiro B (2019) Boosting dynamic ensemble’s performance in twitter. Neural Comput Appl 1–13
Batista GE, Prati RC, Monard MC (2004) A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor Newsl 6(1):20–29
Cai J, Lee WS, Teh YW (2007) Improving word sense disambiguation using topic features. In: EMNLP-CoNLL 2007, proceedings of the joint conference on empirical methods in natural language processing and computational natural language learning, Prague, Czech Republic, pp 1015–1023
Griffiths TL, Steyvers M (2004) Finding scientific topics. Proc Nat Acad Sci 101(suppl 1):5228–5235
Hollander M, Wolfe DA (1999) Nonparametric statistical methods. Wiley, Hoboken
Fawcett T (2006) An introduction to ROC analysis. Pattern Recogn Lett 27(8):861–874
Gonçalves S, Cortez P, Moro S (2019) A deep learning classifier for sentence classification in biomedical and computer science abstracts, Neural Computing and Applications. https://doi.org/10.1007/s00521-019-04334-2
Kulkarni R (2018) A million news headlines, Tech. rep., Harvard Dataverse, V2. https://doi.org/10.7910/DVN/SYBGZL
Wei Wei, Fan X, Song H, Fan X, Yang J (2018) Imperfect information dynamic stackelberg game based resource allocation using hidden markov for cloud computing. IEEE Trans Serv Comput 11(1):78–89. https://doi.org/10.1109/TSC.2016.2528246
Acknowledgements
Research carried out with the support of resources of Big and Open Data Innovation Laboratory (BODaI-Lab), University of Brescia, granted by Fondazione Cariplo and Regione Lombardia. We would also like to thank the anonymous reviewers for their helpful suggestions.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zola, P., Cortez, P. & Brentari, E. Twitter alloy steel disambiguation and user relevance via one-class and two-class news titles classifiers. Neural Comput & Applic 33, 1245–1260 (2021). https://doi.org/10.1007/s00521-020-04991-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-020-04991-8