
Abstract
Coronavirus disease (COVID-19) is an inflammation disease from a new virus. The disease causes respiratory ailment (like influenza) with manifestations, for example, cold, cough and fever, and in progressively serious cases, the problem in breathing. COVID-2019 has been perceived as a worldwide pandemic and a few examinations are being led utilizing different numerical models to anticipate the likely advancement of this pestilence. These numerical models dependent on different factors and investigations are dependent upon potential inclination. Here, we presented a model that could be useful to predict the spread of COVID-2019. We have performed linear regression, Multilayer perceptron and Vector autoregression method for desire on the COVID-19 Kaggle data to anticipate the epidemiological example of the ailment and pace of COVID-2019 cases in India. Anticipated the potential patterns of COVID-19 effects in India dependent on data gathered from Kaggle. With the common data about confirmed, death and recovered cases across India for over the time length helps in anticipating and estimating the not so distant future. For extra assessment or future perspective, case definition and data combination must be kept up persistently.
Similar content being viewed by others
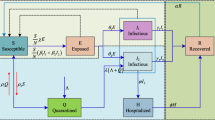

1 Introduction
As of date confirmed COVID-19 casesFootnote 1 across the globe are 1,498,833 and mortality approximately 5.8%. Gradually the mortality rate is increasing and it’s an alarming factor for the whole world. Transmission is categorized into 4 stages based on the mode of spread and time. Every nation imposed different methodologies starting from staying in-home, using masks, travel restrictions, avoiding social gatherings, frequently washing hands and sanitizing the places often in the case of a common effort to combat the outbreak of this disease. Many countries imposed a lockdown state that prevents the movement of the citizens unnecessarily. Due to this social distancing factor and movement restrictions, the wellbeing and economy of the various nations are being under jeopardy. GPD of the entire world dropped drastically. When the person is found infected, he is isolated and treatment is given for recovery. But based on the severity it will cause death and also people left with a higher level of depression.
In India, the outbreak of coronavirus as disturbed the functioning of life as a whole. all were pushed to stay back to safeguard from the dreadful transmission. In the initial stages, the confirmed cases are those returned from oversees followed by transmission via local transmission. More caution is given to the elderly and immunity fewer people. The demographic of the infected people in India indicates that 39 years is the median. Comparatively, people between 21 and 40 years are being affected more. The everyday predominance information of COVID-2019 from January 22, 2020, to April 10, 2020, was gathered from the website of Kaggle.Footnote 2 Weka 3.8.4Footnote 3 and OrangeFootnote 4 is utilized to decipher the information. LR, MLP, and VAR are applied on the Kaggle dataset having 80 instances for anticipating the future effects of COVID-19 pandemic in India. Forecasting is the need of an hour that helps to device a better strategy to tackle this crucial hour across the globe because of this infectious disease. As mentioned by the visual capitalist, the human race as crossed several outbreaks because of the several microbes that were invisible and invincible. COVID-19 is the current threat in the highly sophisticated twenty-first century. Figure 1 is a snapshot of the visual capitalist.Footnote 5

History of pandemic
Artificial intelligence (AI) can assist us in handling the problems that need to be addressed raised by the COVID-19Footnote 6 pandemic. It isn't simply the innovation, however, that will affect yet rather the information and inventiveness of the people who use it. Without a doubt, the COVID-19 emergency will probably uncover a portion of the key shortages of AI. Machine learning (ML), the present type of AI, works by recognizing designs in chronicled training information. People have a preferred position over AI. We can take in exercises from one situation and apply them to novel circumstances, drawing on our dynamic information to make the best speculations on what may work or what may occur. Computer-based intelligence frameworks, conversely, need to gain without any preparation at whatever point the setting or assignment changes even marginally.
The COVID-19 emergency, hence, will feature something that has consistently been valid about AI: it is a device, and the estimation of its utilization in any circumstance is dictated by the people who structure it and use it. In the present emergency, human activity and development will be especially basic in utilizing the intensity of what AI can do. One way to deal with the novel circumstance issue is to assemble new training information under current conditions. For both human leaders and AI frameworks the same, each new snippet of data about our present circumstance is especially significant in advising our choices going ahead. The more viable we are at sharing data, the more rapidly our circumstance is not, at this point novel and we can start to see a way ahead. AI can assist us in handling the problems that need to be addressed raised by the COVID-19 pandemic. It isn't simply the innovation, however, that will affect yet rather the information and imagination of the people who use it. To be sure, the COVID-19 emergency will probably uncover a portion of the key setbacks of AI. Machine learning, the present type of AI, works by recognizing designs in verifiable training information. People have a preferred position over AI. We can take in exercises from one setting and apply them to novel circumstances, drawing on our theoretical information to make the best theories on what may work or what may occur. Simulated intelligence frameworks, interestingly, need to gain without any preparation at whatever point the setting or undertaking changes even somewhat. The COVID-19 emergency, along these lines, will feature something that has consistently been valid about AI: it is an apparatus, and the estimation of its utilization in any circumstance is dictated by the people who plan it and use it. In the present emergency, human activity and development will be especially basic in utilizing the intensity of what AI can do. One way to deal with the novel circumstance issue is to accumulate new training information under current conditions. For both human chiefs and AI frameworks the same, each new snippet of data about our present circumstance is especially important in illuminating our choices going ahead. The more compelling we are at sharing data, the more rapidly our circumstance is not, at this point novel and we can start to see a way ahead.
2 Related work
Sujatha and Chatterjee (2020) proposed a model that could be useful to foresee the spread of COVID-2019 by using linear regression, Multilayer perceptron and Vector autoregression model on the COVID-19 kaggle data to envision the epidemiological example of the malady and pace of COVID-2019 cases in India. Yang et al. (2020) introduced dynamic SEIR model for anticipating the COVID-19 pestilence pinnacles and sizes. They utilized an AI model prepared with respect to past SARS dataset additionally shows guarantee for future expectation of the scourges. Barstugan et al. (2020) presented early stage location of COVID-19, which is named by World Health Organization (WHO), by machine learning strategies actualized on stomach Computed Tomography pictures. Elmousalami and Hassanien (2020) presents a correlation of day level guaging models on COVID-19 influenced cases utilizing time series models and numerical detailing. Rizk-Allah and Hassanien (2020) acquainted another guaging model with examine and gauge the CS of COVID-19 for the coming days dependent on the announced data since 22 Jan 2020. Rezaee et al. (2020) introduced a mixture approach dependent on the Linguistic FMEA, Fuzzy Inference System and Fuzzy Data Envelopment Analysis model to ascertain a novel score for covering some RPN inadequacies and the prioritization of HSE dangers. Navares et al. (2018) introduced an answer for the issue of anticipating every day medical clinic confirmations in Madrid because of circulatory and respiratory cases dependent on biometeorological markers. Cui and Singh (2017) created and applied the MRE hypothesis for month to month streamflow prediction withspectral power as a random variable. Torky and Hassanien (2020) introduced a blockchain incorporated structure which research the chance of using peer-to peer, time stepping and decentralized storage points of interest of blockchain to construct another framework for confirming and distinguishing the obscure contaminated instances of COVID-19 infection. Ezzat and Ella (2020) a novel methodology called GSA-DenseNet121-COVID-19 dependent on a hybrid CNN structure is proposed utilizing an optimization strategy.
3 Methods and materials
In statistics, Linear RegressionFootnote 7 (LR) is a direct way to deal with demonstrating the connection between a dependent variable and at least one independent variable. LR was the main kind of regression analysis to be concentrated thoroughly and to be utilized widely in useful applications (Yan and Su 2009). LR shows the connection between two variables by fitting a straight condition to based information. One variable is viewed as an independent and the other is viewed as a dependent. An LR1 line has a condition of the structure:
here X is the independent and Y is the dependent variable. The slope of the line is b and a is the intercept (the value of y when x = 0).
A multilayer perceptronFootnote 8 (MLP) is a type of feedforward artificial neural network (FANN). The term MLP is utilized vaguely, now and then freely to indicate any FANN, now and then carefully to allude to systems made out of various layers of the perceptron. An MLPFootnote 9 is a perceptron that is generally used for complex issues. The formula for MLP2 is:
here w is for the vector of weights, x is for the vector of inputs, b is for bias and phi are the non-linear activation function.
A Vector AutoregressionFootnote 10 (VAR) is a prediction calculation which is utilized when at least two-time series impact one another, i.e., the connection between the time arrangements included is bi-directional. The formula for VAR is:
where α is the intercept, a constant and β1, β2 till βp are the coefficients of the lags of Y till order p.
Order ‘p’ means, up to p-lags of Y is utilized and they are the predictors in the equation. The εt is the error considered as white noise.
4 Experimental results
The structure of data based on date, confirmed, recovered and death are shown in Fig. 2 with the boxplots, and it's very clear that several cases are in so primitive stages. As mentioned by WHO, right now India is in the second phase indicating very few cases and forecast of this same is the potential work that is required at this juncture (Tareen et al. 2019).

Boxplot of India COVID-19
Sieve diagram provides the visualization of the dataset along with that showing the sieve rank. Figure 3 illustrates attributes that have a strong relationship with the dark shades. The interestingness of the pair of attributes is represented via this contingency table. It's a very graphical way of frequency visualization.

Sieve diagram for INDIA COVID-19
Correlation plays a great role in finding the dependency among the features of the dataset. Our dataset revolves around the confirmed, recovered, and death of cases because of the COVID-19 outbreak over the time frame of around 2 months in India. From the Spearman correlation, it's very evident that based on progressive of the day (date) the possibility of getting prone to sickness is very high and that is given with thE+0.949 correlation value. Figure 4 provides a glance at the correlation between Pearson and the spearman process. Appreciably the date attribute is holding a higher level of importance and that's is reason globally the measures have been taken for social distancing (Mu et al. 2018; Gautheir 2001). Normally the spread happens just in contact with the person by a handshake is the big brother in case of COVID-19. Correlation provides the signal about the impact and necessary countermeasures to be taken into consideration. Across the globe, leaders of the nation are carrying out various trial and error methods to combat the seriousness of the disease.

Pearson and spearman correlation
Forecasting gives pertinent and consistent input about the past, present, and future happenings with certain statistical and scientific approaches. Helps in string decision making in all perspectives. Broadly classified into qualitative and quantitative approaches. Steps involved in forecasting is the deciding factor of the task. Initial understanding of the problem with complete analysis, making a strong foundation, collecting data based on the previous two steps followed by future estimation. Comparison between actual and estimated with followup actions. Various applications like economic and sales prediction, budget, census and stock market analysis, yield projections and many more fields. The medical field also a potential area to deploy the forecast and predication to serve the number of people in need (Hajirahimi and Khashei 2019; Yamana and Shaman 2019). Our work carried out with linear regression, multilayer perceptron, and VAR model over the time series dataset to provide the forecast.
VAR model is a more suitable analysis model in the multivariate time series. It helps in inferencing and analysis of policy. It is used more in a practical forecasting scenario but it is hading superior forecasting performance. Technically narrating about the VAR, it is an m-equation, m-variable model in which individual variable explains on its own based on current, past values. Various parameters of VAR begins with maximum auto-regression order. Various information criteria that help in optimize autoregressive order are Akaike's information criterion (AIC), Bayesian information criterion (BIC), Hann-Quinn and Final prediction error (FPE). By adding and varying trends from constant, linear, and quadratic with forecast steps ahead and confidence intervals (Billio et al. 2019; Portet 2020; Zhang and Krieger 1993). The formula for calculating AIC, BIC and HQ is as follows:
where n is the number of attributes in the system, X is the sample size, and \(\Sigma \mathrm{^{\prime}}\) is an estimate of the covariance matrix \(\Sigma\).
5 Sitational forcast in India
In our forecast work the maximum auto-regression order of 6 followed by an average of information criterion is used for visualization. The trend of constant, linear, and quadratic along with 1 step ahead and 95% confidence interval (CI) is introduced (Tapia 2020). In Figs. 5, 6, 7, 8 and 10, 11, 12, 13 and 14) the X-axis shows the days and the Y-axis shows the number of cases.

Prediction of confirmed, deaths and recovered case of COVID-19 in India

Prediction of confirmed, deaths and recovered case of COVID-19 in India

Prediction of confirmed case of COVID-19 in India

Prediction of confirmed cases of COVID-19 in India
Figure 5 shows the COVID-19 predicted confirmed cases; death cases and recovered cases based on actual confirmed, death and recovered data with a 95% CI with LR.The graph can be interpreted that cases are going to be increased in future as per the existing case data.
Figure 6 shows the COVID-19 predicted confirmed cases; death cases and recovered cases based on actual confirmed, death and recovered data with a 95% CI with MLP. The graph using MLP can be interpreted that cases are going to be increased in future as per the existing case data.
Figure 7 shows the predicted confirmed cases based on the actual confirmed case data with a 95% CI with LR. The graph using can be interpreted that confirmed cases are going to be increased in future as per the existing case data by utilizing LR.
Figure 8 shows the predicted confirmed cases based on the actual confirmed case data with a 95% CI with MLP. The graph using MLP shows prediction of confirmed cases in a incremental range based on the existing data of 80 days.
Figure 9 shows the predicted impacts of COVID-19 based on the actual data of confirmed, death and recovered cases with 95% CI via LR. In this figure also it is showing that the confirmed cases will be increasing day by day based on the input data, system shows this prediction.

Prediction of confirmed, deaths and recovered case of COVID-19 in India
Figure 10 predicts the impacts of COVID-19 based on the actual data of confirmed, death and recovered cases with 95% CI through MLP. This graph shows the confirmed cases will go down with a very slow rate and the recovered and death records will fluctuate (i.e. some times more some times less) as per prediction with MLP.

Prediction of confirmed, deaths and recovered case of COVID-19 in India
Figure 11 shows the predicted impacts of COVID-19 death based on the actual data of death cases with 95% CI through LR. The graph can be interpreted that cases are going to be increased in future as per the existing case data.

Prediction of deaths case of COVID-19 in India
Figure 12 shows the predicted impacts of COVID-19 death based on the actual data of death cases with 95% CI through MLP. The Fig. 12 can be interpreted that cases are going to be increased in future as per the existing case data.

Prediction of deaths case of COVID-19 in India
Figure 13 shows the predicted impacts of COVID-19 recovered based on the actual data of recovered cases with 95% CI through LR. By analyzing the Figs. 13 and 14 we can understand the cases are going to increase in future.

Prediction of recovered case of COVID-19 in India

Prediction of recovered case of COVID-19 in India
Figure 14 shows the predicted impacts of COVID-19 recovered based on the actual data of recovered cases with 95% CI with MLP.
Figure 15 shows the forecast of next 69 days in the VAR model, where auto regression order is 10, with AIC optimize information criteria with constant and linear trend vectors and CI of 95% for the confirmed, recovered and death cases are illustrated in perfect manner.

Forecast of confirmed, deaths and recovered cases of COVID-19 using VAR model
We have given data of cases till the 80th day i.e. 10th April 2020. Table 1 shows the predicted values of cases (confirmed, death, recovered) by using the LR method from the 81st day i.e. 11th April 2020 for the next 69 days, i.e. 18th June 2020.These are the predicted values as per the actual values given in the system as an input. The Figs. 5,7,9,11,13 are generated based on the predicted values of Table 1.
We have given data of cases till the 80th day i.e. 10th April 2020. Table 2 shows the predicted values of cases (confirmed, death, recovered) by using MLP method from the 81st day i.e. 11th April 2020 for the next 69 days, i.e. 18th June 2020. These are the system predicted values as per the actual values given as an input.
Figure 15 gets its waves of the different cases from the Table 3 values for the next 69 days. It depends on the various parameters mentioned in the VAR model part.
6 Conclusion
Information and communication technology help in the decision-making process based on the past data with the data analytics and data mining perspective. The size of data available is huge and gathering information and getting an interesting pattern out of the cumulated data is a challenging task. With the prevailing data about confirmed, recovered and death across India for over the time duration helps in predicting and forecasting the near future. The correctness of the model could be increased by introducing related attributes like several hospitals, the immune system of the infected person, age of the patient, gender of the patient, steps taken to combat the proliferation of the virus, and so on to make it completely informative. As of now, it's very prudent that yards to carry needs to be stringent and vigil in nature to handle this crucial situation by social distancing, lockdown, curfew, quarantine, and isolation to prevent the transmission. By seeing the predicted values and matching with cases from John Hopkins UniversityFootnote 11 data we can conclude that the MLP method is giving good prediction results than that of the LR and VAR method using WEKA and Orange. In future we can work with some deep learning methods for forcasting time series data for getting better predictions.
Change history
27 July 2020
The original article can be found online at.
Notes
References
Barstugan M, Ozkaya U, Ozturk S (2020) Coronavirus (covid-19) classification using ct images by machine learning methods. arXiv preprint arXiv:2003.09424
Billio M, Casarin R, Rossini L (2019) Bayesian nonparametric sparse VAR models. J Econ 212(1):97–115
Cui H, Singh VP (2017) Application of minimum relative entropy theory for streamflow forecasting. Stoch Env Res Risk Assess 31(3):587–608
Elmousalami HH, Hassanien AE (2020) Day level forecasting for Coronavirus Disease (COVID-19) spread: analysis, modeling and recommendations. arXiv preprint arXiv:2003.07778
Ezzat D, Ella HA (2020) GSA-DenseNet121-COVID-19: a hybrid deep learning architecture for the diagnosis of COVID-19 disease based on gravitational search optimization algorithm. arXiv preprint arXiv:2004.05084
Gautheir TD (2001) Detecting trends using Spearman's rank correlation coefficient. Environ Forens 2(4):359–362
Hajirahimi Z, Khashei M (2019) Hybrid structures in time series modeling and forecasting: A review. Eng Appl Artif Intell 86:83–106
Mu Y, Liu X, Wang L (2018) A Pearson’s correlation coefficient-based decision tree and its parallel implementation. Inf Sci 435:40–58
Navares R, Díaz J, Linares C, Aznarte JL (2018) Comparing ARIMA and computational intelligence methods to forecast daily hospital admissions due to circulatory and respiratory causes in Madrid. Stoch Env Res Risk Assess 32(10):2849–2859
Portet S (2020) A primer on the model selection using the Akaike information criterion. Infect Dis Modell 5:111–128
Rezaee MJ, Yousefi S, Eshkevari M, Valipour M, Saberi M (2020) Risk analysis of health, safety and environment in chemical industry integrating linguistic FMEA, fuzzy inference system and fuzzy DEA. Stoch Env Res Risk Assess 34(1):201–218
Rizk-Allah RM, Hassanien AE (2020) COVID-19 forecasting based on an improved interior search algorithm and multi-layer feed forward neural network. arXiv preprint arXiv:2004.05960
Sujatha R, Chatterjee J (2020) A machine learning methodology for forecasting of the COVID-19 cases in India
Tapia JA, Salvador B, Rodríguez JM (2020) Data envelopment analysis with estimated output data: confidence intervals efficiency. Measurement 152:107364
Tareen ADK, Nadeem MSA, Kearfott KJ, Abbas K, Khawaja MA, Rafique M (2019) Descriptive analysis and earthquake prediction using boxplot interpretation of soil radon time-series data. Appl Radiat Isot 154:108861
Torky M, Hassanien AE (2020) COVID-19 blockchain framework: innovative approach. arXiv preprint arXiv:2004.06081
Yamana TK, Shaman J (2019) A framework for evaluating the effects of observational type and quality on vector-borne disease forecast. Epidemics 100359
Yan X, Su X (2009) Linear regression analysis: theory and computing. World Scientific, New York
Yang Z, Zeng Z, Wang K, Wong SS, Liang W, Zanin M, Liu P, Cao X, Gao Z, Mai Z, Liang J (2020) Modified SEIR and AI prediction of the epidemics trend of COVID-19 in China under public health interventions. J Thorac Dis 12(3):165
Zhang P, Krieger AM (1993) Appropriate penalties in the final prediction error criterion: a decision-theoretic approach. Stat Probab Lett 18(3):169–177
Author information
Authors and Affiliations
Contributions
All the authors have made substantive contributions to the article and assume full responsibility for its content.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that we don’t have any conflict of Interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Sujath, R., Chatterjee, J.M. & Hassanien, A.E. A machine learning forecasting model for COVID-19 pandemic in India. Stoch Environ Res Risk Assess 34, 959–972 (2020). https://doi.org/10.1007/s00477-020-01827-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-020-01827-8