
Abstract
We design and analyse the performance of a multilevel ensemble Kalman filter method (MLEnKF) for filtering settings where the underlying state-space model is an infinite-dimensional spatio-temporal process. We consider underlying models that needs to be simulated by numerical methods, with discretization in both space and time. The multilevel Monte Carlo sampling strategy, achieving variance reduction through pairwise coupling of ensemble particles on neighboring resolutions, is used in the sample-moment step of MLEnKF to produce an efficent hierarchical filtering method for spatio-temporal models. Under sufficent regularity, MLEnKF is proven to be more efficient for weak approximations than EnKF, asymptotically in the large-ensemble and fine-numerical-resolution limit. Numerical examples support our theoretical findings.
Similar content being viewed by others

1 Introduction
Filtering refers to the sequential estimation of the state u and/or parameters of a system through sequential incorporation of online data y. The most complete estimation of the state \(u_n\) at time n is given by its probability distribution conditional on the observations up to the given time \(\mathbb {P}(du_n|y_1,\ldots , y_n)\) [2, 27]. For linear Gaussian systems, the analytical solution may be given in closed form via update formulae for the mean and covariance known as the Kalman filter [31]. More generally, however, closed form solutions typically are not known. One must therefore resort to either algorithms which approximate the probabilistic solution by leveraging ideas from control theory in the data assimilation community [27, 32], or Monte Carlo methods to approximate the filtering distribution itself [2, 11, 15]. The ensemble Kalman filter (EnKF) [9, 17, 35] combines elements of both approaches. In the linear Gaussian case it converges to the Kalman filter solution in the large-ensemble limit [41], and even in the nonlinear case, under suitable assumptions it converges [36, 37] to a limit which is optimal among those which incorporate the data linearly and use a single update iteration [36, 40, 44]. In the case of spatially extended models approximated on a numerical grid, the state space itself may become very high-dimensional and even the linear solves may become intractable, due to the cost of computing the covariance matrix. Therefore, one may be inclined to use the EnKF filter even for linear Gaussian problems in which the solution is computationally intractable despite being given in closed form by the Kalman filter.
The Multilevel Monte Carlo method (MLMC) is a hierarchical and variance-reduction based approximation method initially developed for weak approximations of random fields and stochastic differential equations [18, 19, 21]. Recently, a number of works have emerged which extend the MLMC framework to the setting of Monte Carlo algorithms designed for Bayesian inference. Examples include Markov chain Monte Carlo [14, 22], sequential Monte Carlo samplers [6, 26, 42], particle filters [20, 25], and EnKF [23]. The filtering papers thus far [20, 23, 25] consider only finite-dimensional SDE forward models. In this work, we develop a new multilevel ensemble Kalman filtering method (MLEnKF) for the setting of infinite-dimensional state-space models with evolution in continuous-time. The method consists of a hierarchy of pairwise coupled EnKF-like ensembles on different finite-resolution levels of the underlying infinite-dimensional evolution model that all depend on the same Kalman gain in the update step. The method presented in this work may be viewed as an extension of the finite-dimensional-state-space MLEnKF method [23], which only considered a hierarchy of time-discretization resolution levels.
Under sufficient regularity, the large-ensemble limit of EnKF is equal in distribution to the so-called mean-field EnKF (MFEnKF), cf. [34, 36, 37]. In nonlinear settings, however, MFEnKF is not equal in distribution to the Bayes filter, which is the exact filter distribution. More precisely, the error of EnKF approximating the Bayes filter may be decomposed into a statistical error, due to the finite ensemble size, and a Gaussian bias that is introduced by the Kalman-filter-like update step in EnKF. While the update-step bias error in EnKF is difficult both to quantify and deal with, the statistical error can, in theory, be reduced to arbitrary magnitude. However, the high computational cost of simulations in high-dimensional state space often imposes small ensemble size as a practical constraint. By making use of hierarchical variance-reduction techniques, the MLEnKF method developed in this work is capable of obtaining a much smaller statistical error than EnKF at the same fixed cost.
In addition to design an MLEnKF method for spatio-temporal processes, we provide an asymptotic performance analysis of the method that is applicable under sufficient regularity of the filtering problem and \(L^p\)-strong convergence of the numerical method approximating the underlying model dynamics. Sections 5 and 6 are devoted to a detailed analysis and practical implementation of MLEnKF applied to linear and semilinear stochastic reaction–diffusion equations. In particular, we describe how the pairwise coupling of EnKF-like hierarchies should be implemented for one specific numerical solver (the exponential-Euler method), and provide numerical evidence for the efficiency gains of MLEnKF over EnKF.
Since particle filters are known to often perform better than EnKF, we also include a few remarks on how we believe such methods would compare to MLEnKF in filtering settings with spatial processes. Due to the poor scaling of particle ensemble size in high dimensions, which can even be exponential [7, 38], particle filters are typically not used for spatial processes, or even modestly high-dimensional processes. There has been some work in the past few years which overcomes this issue either for particular examples [5] or by allowing for some bias [4, 45, 48, 49]. But particle filters cannot yet be considered practically applicable for general spatial processes. If there is a well-defined limit of the model as the state-space dimension d grows such that the effective dimension of the target density with respect to the proposal remains finite or even small, then useful particle filters can be developed [33, 39]. As noted in [10], the key criterion which needs to be satisfied is that the proposal and the target are not mutually singular in the limit. MLMC has been applied recently to particle filters, in the context where the approximation arises due to time discretization of a finite-dimensional SDE [20, 25]. It is an interesting open problem to design multilevel particle filters for spatial processes: Both the range of applicability and the asymptotic performance of such a method versus MLEnKF when applied to spatial processes are topics that remain to be studied.
The rest of the paper is organized as follows. Section 2 introduces the filtering problem and notation. The design of the MLEnKF method is presented in Sect. 3. Section 4 studies the weak approximation of MFEnKF by MLEnKF, and shows that in this setting, MLEnKF inherits almost the same favorable asymptotic “cost-to-accuracy” performance as standard MLMC applied to weak approximations of stochastic spatio-temporal processes. Section 5 presents a detailed analysis and description of the implementation of MLEnKF for a family of stochastic reaction–diffusion models. Section 6 provides numerical studies of filtering problems with linear and semilinear stochastic reaction–diffusion models that corroborate our theoretical findings. Conclusions and future directions are presented in Sect. 7, and auxiliary theoretical results and technical proofs are provided in “Appendices A, B and C”.
2 Set-up and single level algorithm
2.1 General set-up
Let \((\Omega ,\mathcal {F}, \mathbb {P})\) be a complete probability space, where \(\mathbb {P}\) is a probability measure on the measurable space \((\Omega , \mathcal {F})\). Let \(\mathcal {V}\) be a separable Hilbert space with inner product \(\langle \cdot ,\cdot \rangle _{\mathcal {V}}\) and norm \(\Vert \cdot \Vert _{\mathcal {V}} = \sqrt{\langle \cdot ,\cdot \rangle _{\mathcal {V}}}\). Let V denote a subspace of \(\mathcal {V}\) which is closed in the topology induced by the norm \(\Vert \cdot \Vert _{V} = \sqrt{\langle \cdot ,\cdot \rangle _{V}}\), which is assumed to be a stronger norm than \(\Vert \cdot \Vert _{\mathcal {V}}\). For an arbitrary separable Hilbert space \((\mathcal {K}, \Vert \cdot \Vert _{\mathcal {K}})\), we denote the associated \(L^p\)-Bochner space by

where  , or the shorthand \(\Vert u \Vert _p\) whenever confusion is not possible. For an arbitrary pair of Hilbert spaces \(\mathcal {K}_1\) and \(\mathcal {K}_2\), the space of bounded linear mappings from the former space into the latter is denoted by
, or the shorthand \(\Vert u \Vert _p\) whenever confusion is not possible. For an arbitrary pair of Hilbert spaces \(\mathcal {K}_1\) and \(\mathcal {K}_2\), the space of bounded linear mappings from the former space into the latter is denoted by

where
In finite dimensions, \((\mathbb {R}^m, \langle \cdot , \cdot \rangle )\) represents the m-dimensional Euclidean vector space with norm \(| \cdot | \mathrel {\mathop :}=\sqrt{\langle \cdot , \cdot \rangle }\), and for matrices \(A \in L(\mathbb {R}^{m_1},\mathbb {R}^{m_2})\), \(|A| := \Vert A\Vert _{L(\mathbb {R}^{m_1},\mathbb {R}^{m_2})}\).
2.1.1 The filtering problem
Given \(u_0 \in \cap _{p\ge 2} L^p(\Omega ,V)\) and the mapping \(\Psi : L^p(\Omega ,V) \times \Omega \rightarrow L^p(\Omega ,V)\), we consider the discrete-time dynamics
and the sequence of observations
Here, \(H \in L(\mathcal {V}, \mathbb {R}^{m})\) and the sequence \(\{\eta _n\}\) consists of independent and identically \(N(0,\Gamma )-\)distributed random variables with \(\Gamma \in \mathbb {R}^{m\times m}\) positive definite. In the sequel, the explicit dependence on \(\omega \) will be suppressed where confusion is not possible. A general filtering objective is to track the signal \(u_n\) given a fixed sequence of observations \(Y_n := (y_1,y_2, \ldots , y_n)\), i.e., to track the distribution of \(u_n|Y_n\) for \(n=1,\ldots \). In this work, however, we restrict ourselves to considering the more specific objective of approximating  for a given quantity of interest (QoI) \(\varphi : \mathcal {V}\rightarrow \mathbb {R}\). The index n will be referred to as time, whether the actual time between observations is 1 or not (in the examples in Sect. 5 and beyond it will be called T), but this will not cause confusion since time is relative.
for a given quantity of interest (QoI) \(\varphi : \mathcal {V}\rightarrow \mathbb {R}\). The index n will be referred to as time, whether the actual time between observations is 1 or not (in the examples in Sect. 5 and beyond it will be called T), but this will not cause confusion since time is relative.
2.1.2 The dynamics
We consider problems in which \(\Psi \) is the finite-time evolution of an SPDE, e.g. (35), and we will assume that \(\Psi \) cannot be evaluated exactly, but that there exists a sequence \(\{\Psi ^{\ell }:L^p(\Omega ,\mathcal {V})\times \Omega \rightarrow L^p(\Omega ,\mathcal {V}) \}_{\ell =0}^\infty \) of approximations to the solution \(\Psi :=\Psi ^{\infty }\) satisfying the following uniform-in-\(\ell \) stability properties
Assumption 1
For every \(p \ge 2\), it holds that \(\Psi : L^p(\Omega ,V)\times \Omega \rightarrow L^p(\Omega ,V)\), and for all \(u,v \in L^p(\Omega , \mathcal {V})\), the solution operators \(\{\Psi ^{\ell }\}_{\ell =0}^\infty \) satisfy the following conditions: there exists a constant \(0<c_\Psi <\infty \) depending on p such that
-
(i)
\(\Vert \Psi ^{\ell }(u) -\Psi ^{\ell }(v) \Vert _{L^p(\Omega ,\mathcal {V})} {\le } c_{\Psi } \Vert u-v\Vert _{L^p(\Omega ,\mathcal {V})} \) , and
-
(ii)
\(\Vert \Psi ^{\ell }(u)\Vert _{L^p(\Omega ,\mathcal {V})} \le c_{\Psi } (1+\Vert u\Vert _{L^p(\Omega ,\mathcal {V})})\).
For notational simplicity, we restrict ourselves to settings in which the map \(\Psi (\cdot )\) does not depend on n, but the results in this work do of course extend easily to non-autonomous settings when the assumptions on \(\{\Psi _n\}_{n=1}^N\) are uniform with respect to n.
Remark 1
The two approximation spaces \(V\subset \mathcal {V}\) are introduced in order to obtain convergence rates for numerical simulation methods \(\Psi ^\ell \) that are discretized in physical or state space. See Assumption 2(i)–(ii) and inequality (41) for an example of how this may be obtained in practice.
2.1.3 The Bayes filter
The pair of discrete-time stochastic processes \((u_n, y_n)\) constitutes a hidden Markov model, and the exact (Bayes-filter) distribution of \(u_n|Y_n\) may in theory be determined iteratively through the system of prediction-update equations
When the state space is infinite-dimensional and the dynamics cannot be evaluated exactly, however, this is an extremely challenging problem. Consequently, we will here restrict ourselves to constructing weak approximation methods of the mean-field EnKF, cf. Sect. 2.4.
2.2 Some details on Hilbert spaces, Hilbert–Schmidt operators, and Cameron–Martin spaces
For two arbitrary separable Hilbert spaces \(\mathcal {K}_1 \) and \(\mathcal {K}_2\), the tensor product \(\mathcal {K}_1 \otimes \mathcal {K}_2\) is also a Hilbert space. For rank-1 tensors, its inner product is defined by
which extends by linearity to any tensor of finite rank. The Hilbert space \(\mathcal {K}_1\otimes \mathcal {K}_2\) is the completion of this set with respect to the induced norm
Let \(\{e_k\}\) and \(\{{\hat{e}}_k\}\) be orthonormal bases for \(\mathcal {K}_1\) and \(\mathcal {K}_2\), respectively, and observe that finite sums of rank-1 tensors of the form \(X \mathrel {\mathop :}=\sum _{i,j} \alpha _{ij} e_i \otimes {\hat{e}}_j \in \mathcal {K}_1 \otimes \mathcal {K}_2\) can be identified with a bounded linear mapping
For two bounded linear operators \(A,B: \mathcal {K}_2^* \rightarrow \mathcal {K}_1\) we recall the definition of the Hilbert-Schmidt inner product and norm
where \(\{{\hat{e}}^*_k\}\) is the orthonormal basis of \(\mathcal {K}_2^*\) satisfying \({\hat{e}}^*_k({\hat{e}}_j) = \delta _{jk}\) for all j, k in the considered index set. A bounded linear operator \(A:\mathcal {K}_2^* \rightarrow \mathcal {K}_1\) is called a Hilbert-Schmidt operator if \(|A|_{HS} < \infty \) and \(HS(\mathcal {K}_2^*, \mathcal {K}_1)\) is the space of all such operators. In view of (4),
By completion, the space \(\mathcal {K}_1 \otimes \mathcal {K}_2\) is isometrically isomorphic to \(HS(\mathcal {K}_2^*,\mathcal {K}_1)\) (and also to \(HS(\mathcal {K}_2,\mathcal {K}_1)\) by the Riesz representation theorem). For an element \(A \in \mathcal {K}_1\otimes \mathcal {K}_2\) we identify the norms
and such elements will interchangeably be considered either as members of \(\mathcal {K}_1\otimes \mathcal {K}_2\) or of \(HS(\mathcal {K}_2^*,\mathcal {K}_1)\). When viewed as \(A \in HS(\mathcal {K}_2^*,\mathcal {K}_1)\), the mapping \(A: \mathcal {K}_2^* \rightarrow \mathcal {K}_1\) is defined by
where \(A_{ij} \mathrel {\mathop :}=\langle e_i, A {\hat{e}}_j^* \rangle _{\mathcal {K}_1}\), and when viewed as \(A \in \mathcal {K}_1\otimes \mathcal {K}_2\), we use tensor-basis representation
The covariance operator for a pair of random variables \(Z, X \in L^2(\Omega , V)\) is denoted by

and whenever \(Z=X\), we employ the shorthand \({\mathrm {Cov}}[Z] \mathrel {\mathop :}={\mathrm {Cov}}[Z,Z]\). For completeness and later reference, let us prove that said covariance belongs to \(V\otimes V\).
Proposition 1
If \(u\in L^2(\Omega ,V)\), then \(C:={\mathrm {Cov}}[u] \in V\otimes V\).
Proof
By Jensen’s inequality,

\(\square \)
2.3 Ensemble Kalman filtering
EnKF is an ensemble-based extension of Kalman filtering to nonlinear settings. Let \(\{ \hat{v}_{0,i}\}_{i=1}^M\) denote an ensemble of M i.i.d. particles with \(\hat{v}_{0,i} {\mathop {=}\limits ^{D}} u_0\). The initial distribution \(\mathbb {P}_{u_0}\) can thus be approximated by the empirical measure of \(\{ \hat{v}_{0,i}\}_{i=1}^M\). By extension, let \(\{ \hat{v}_{n,i}\}_{i=1}^M\) denote the ensemble-based approximation of the updated distribution \(u_n|Y_n\) (at \(n=0\) we employ the convention \(Y_0=\emptyset \), so that \(u_0=u_0|Y_0\)). Given an updated ensemble \(\{ \hat{v}_{n,i}\}_{i=1}^M\), the ensemble-based approximation of the prediction distribution \(u_{n+1}|Y_n\) is obtained through simulating each particle one observation time ahead:
We will refer to \(\{\hat{v}_{n+1,i}\}_{i=1}^M\) as the prediction ensemble at time \(n+1\), and we also note that in many settings, the exact dynamics \(\Psi \) in (5) have to be approximated by a numerical solver.
Next, given \(\{\hat{v}_{n+1,i}\}_{i=1}^M\) and a new observation \(y_{n+1}\), the ensemble-based approximation of the updated distribution \(u_{n+1}|Y_{n+1}\) is obtained through updating each particle path
where \(\{ \eta _{n+1,i} \}_{i=1}^M\) is an independent and identically \(N(0, \Gamma )-\hbox {distributed}\) sequence, the Kalman gain
is a function of
the adjoint observation operator \(H^* \in L(\mathbb {R}^{m}, \mathcal {V}^*)\), defined by
and the prediction covariance
with
and the shorthand \(\mathrm {Cov}_M[u_n] \mathrel {\mathop :}=\mathrm {Cov}_M[u_n,u_n]\).
We introduce the following notation for the empirical measure of the updated ensemble \(\{\hat{v}_{n,i}\}_{i=1}^{M}\):
and for any QoI \(\varphi : \mathcal {V}\rightarrow \mathbb {R}\), let
Due to the update formula (6), all ensemble particles are correlated to one another after the first update. Even in the linear Gaussian case, the ensemble will not remain Gaussian after the first update. Nonetheless, it has been shown that in the large-ensemble limit, EnKF converges in \(L^p(\Omega )\) to the correct (Bayes-filter) Gaussian in the linear and finite-dimensional case [37, 41], with the rate \(\mathcal {O}(M^{-1/2})\) for Lipschitz-functional QoI with polynomial growth at infinity. Furthermore, in the nonlinear cases admitted by Assumption 1, EnKF converges in the same sense and with the same rate to a mean-field limiting distribution described below.
Remark 2
The perturbed observations \({\tilde{y}}_{n,i}\) were originally introduced in [9] to correct the variance-deflation-type error that appeared in its absence in implementations following the original formulation of EnKF [16]. It has become known as the perturbed observation implementation.
2.4 Mean-field ensemble Kalman filtering
In order to describe and study convergence properties of EnKF in the large-ensemble limit, we now introduce the mean-field EnKF (MFEnKF) [36]: Let \(\hat{\bar{ v}}_0 \sim \mathbb {P}_{u_0}\) and


Here \(\eta _n\) are i.i.d. draws from \(N(0,\Gamma ).\) In the finite-dimensional state-space setting, it was shown in [36, 37] that for nonlinear state-space models and nonlinear models with additive Gaussian noise, respectively, EnKF converges to MFEnKF with the \(L^p(\Omega )\) convergence rate \(\mathcal {O}(M^{-1/2})\), as long as the models satisfy a Lipschitz criterion, similar to (but stronger than) Assumption 1. And in [23], we showed for that MLEnKF converges toward MFEnKF with a higher rate than EnKF does in said finite-dimensional setting. The work [34] extended convergence results to infinite-dimensional state space for square-root filters. In this work, the aim is to prove convergence of the MLEnKF for infinite-dimensional state space, with the same favorable asymptotic cost-to-accuracy performance as in [23].
The following \(L^p\)-boundedness properties ensures the existence of the MFEnKF-process and its mean-field Kalman gain, and they will be needed when studying the properties of MLEnKF:
Proposition 2
Assume the initial data of the hidden Markov model (1) and (2) satisfies \(u_0 \in \cap _{p\ge 2} L^p(\Omega ,V)\). Then the MFEnKF process (9) and (10) satisfies \(\bar{v}_n, \hat{\bar{v}}_n \in \cap _{p \ge 2} L^p(\Omega ,V)\) and \(\Vert \bar{K}_n\Vert _{L(\mathbb {R}^{m},V)} < \infty \) for all \(n \in \mathbb {N}\).
Proof
Since \(\hat{\bar{v}}_0 = u_0\), the property clearly holds for \(n=0\). Given \(\hat{\bar{v}}_n\in L^p(\Omega ,V)\), Assumption 1 guarantees \(\bar{v}_{n+1} \in L^p(\Omega ,V)\). By Proposition 1, \(\bar{C}_{n+1} \in V\otimes V\). Since \(H\bar{C}_{n+1}H^* \ge 0\) and \(\Gamma >0\), it follows that \(H^*{\bar{S}}_{n+1}^{-1} \in L(\mathbb {R}^{m}, \mathcal {V}^*)\) as
Furthermore, since \(\mathcal {V}^* \subset V^*\) it also holds that \(\Vert H^* {\bar{S}}_{n+1}^{-1}\Vert _{L(\mathbb {R}^{m},V^*)} < \infty \) and
The result follows by recalling that \(V\subset \mathcal {V}\) and by the triangle inequality:
\(\square \)
We conclude this section with some remarks on tensorized representations of the Kalman gain and related auxiliary operators that will be useful when developing MLEnKF algorithms in Sect. 3.3.
2.4.1 The Kalman gain and auxiliary operators
Introducing complete orthonormal bases \(\{e_i\}_{i=1}^m\) for \(\mathbb {R}^{m}\), and \(\{\phi _j\}\) for \(\mathcal {V}\), it follows that \(H \in L(\mathcal {V}, \mathbb {R}^{m})\) can be written
with \(H_{ij} \mathrel {\mathop :}=\langle e_i , H \phi _j\rangle \). And since \(\Vert H\Vert _{L(\mathcal {V},\mathbb {R}^{m})} < \infty \), it holds that
For the covariance matrix, it holds almost surely that \({C}^{\mathrm {MC}}_{n+1} \in V\otimes V\subset \mathcal {V}\otimes \mathcal {V}\), so it may be represented by
For the auxiliary operator, it holds almost surely that
so it can be represented by
Lastly, since \((S^{\mathrm{MC}})^{-1} \in L(\mathbb {R}^{m},\mathbb {R}^{m})\) and \(K^{\mathrm{MC}} \in L(\mathbb {R}^{m},V)\) almost surely, it holds that
3 Multilevel EnKF
3.1 Notation and assumptions
Recall that \(\{\phi _k\}_{k=1}^{\infty }\) represents a complete orthonormal basis for \(\mathcal {V}\) and consider the hierarchy of subspaces \(\mathcal {V}_\ell = \mathrm{span} \{\phi _k\}_{k=1}^{N_\ell }\), where \(\{N_\ell \}\) is an exponentially increasing sequence of natural numbers further described below in Assumption 2. By construction, \(\mathcal {V}_0 \subset \mathcal {V}_1 \subset \dots \subset \mathcal {V}\). We define a sequence of orthogonal projection operators \(\{\mathcal {P}_\ell : \mathcal {V}\rightarrow \mathcal {V}_\ell \}\) by
It trivially follows that \(\mathcal {V}_\ell \) is isometrically isomorphic to \(\mathbb {R}^{N_\ell }\), so that any element \(v^\ell \in \mathcal {V}_\ell \) will, when convenient, be viewed as the unique corresponding element of \(\mathbb {R}^{N_\ell }\) whose kth component is given by \(\langle \phi _k, v^\ell \rangle _{\mathcal {V}}\) for \(k \in \{1,2,\ldots ,N_\ell \}\). For the practical construction of numerical methods, we also introduce a second sequence of projection operators \(\{\Pi _\ell : \mathcal {V}\rightarrow \mathcal {V}_\ell \}\), e.g., interpolant operators, which are assumed to be close to the corresponding orthogonal projectors and to satisfy the constraint \(\Pi _\ell \mathcal {V}= \mathcal {P}_\ell \mathcal {V}= \mathcal {V}_\ell \). This framework can accommodate spectral methods, for which typically \(\Pi _\ell = \mathcal {P}_\ell \), as well as finite element type approximations, for which \(\Pi _\ell \) more commonly will be taken as an interpolant operator. In the latter case, the basis \(\{\phi _j\}\) will be a hierarchical finite element basis, cf. [8, 47].
We now introduce two additional assumptions on the hierarchy of dynamics and two assumptions on the projection operators that will be needed in order to prove the convergence of MLEnKF and its superior efficiency compared to EnKF. For two non-negative sequences \(\{f_\ell \}\) and \(\{g_\ell \}\), the notation \(f_\ell \lesssim g_\ell \) means there exist a constant \(c>0\) such that \(f_\ell \le c g_\ell \) holds for all \(\ell \in {\mathbb {N}} \cup \{0\}\), and the notation \(f_\ell \eqsim g_\ell \) means that both \(f_\ell \lesssim g_\ell \) and \(g_\ell \lesssim f_\ell \) are true.
Assumption 2
Assume the initial data of the hidden Markov model (1) and (2) satisfies \(u_0 \in \cap _{p\ge 2}L^p(\Omega ,V)\). Consider a hierarchy of solution operators \(\{\Psi ^{\ell }: L^p(\Omega ,\mathcal {V})\times \Omega \rightarrow L^p(\Omega ,\mathcal {V}_\ell ) \}\) for which Assumption 1 holds that are associated to a hierarchy of subspaces \(\{\mathcal {V}_\ell \}\) with resolution dimension \(N_\ell \eqsim \kappa ^\ell \) for some \(\kappa >1\). Let \(h_\ell \eqsim N_\ell ^{-1/d}\) and \(\Delta t_\ell \eqsim h_\ell ^{\gamma _t}\), for some \(\gamma _t>0\), respectively denote the spatial and the temporal resolution parameter on level \(\ell \). For a given set of exponent rates \(\beta , \gamma _x, \gamma _t>0\), the following conditions are fulfilled:
-
(i)
\(\Vert \Psi ^{\ell }(u) - \Psi (u) \Vert _{L^p(\Omega , \mathcal {V})} \lesssim (1+\Vert u\Vert _{L^p(\Omega , V)}) h_\ell ^{\beta /2}\), for all \(p\ge 2\) and \(u\in \cap _{p\ge 2}L^p(\Omega , V)\),
-
(ii)
for all \(u \in V\),
$$\begin{aligned} \Vert (I- \mathcal {P}_\ell ) u \Vert _{\mathcal {V}} \lesssim \Vert u\Vert _{V} h_\ell ^{\beta /2} \quad \text {and} \quad \Vert (\Pi _\ell - \mathcal {P}_\ell )u\Vert _{\mathcal {V}} \lesssim \Vert u\Vert _{V} h^{\beta /2}_\ell , \end{aligned}$$ -
(iii)
the computational cost of applying \(\Pi _\ell \) to any element of \(\mathcal {V}\) is \(\mathcal {O}(N_\ell )\) and that of applying \(\Psi ^{\ell }\) to any element of \(\mathcal {V}\) is
$$\begin{aligned} \text {Cost}(\Psi ^{\ell }) \eqsim h_\ell ^{-(d\gamma _x + \gamma _t)}, \end{aligned}$$where d denotes the dimension of the spatial domain of elements in \(\mathcal {V}\), and \(d\gamma _x + \gamma _t \ge d\).
3.2 The MLEnKF method
MLEnKF computes particle paths on a hierarchy of finite-dimensional function spaces with accuracy levels determined by the solvers \(\{\Psi ^{\ell }: L^p(\Omega ,\mathcal {V})\times \Omega \rightarrow L^p(\Omega ,\mathcal {V}_\ell ) \}\). Let \(v^{\ell }_{n}\) and \(\hat{v}^\ell _{n}\) respectively represent prediction and updated ensemble state at time n of a particle on resolution level \(\ell \), i.e., with dynamics governed by \(\Psi ^\ell \). For an ensemble-size sequence \(\{M_\ell \}_{\ell =0}^L \subset \mathbb {N}\setminus \{1\}\) that is further described in (18), the initial setup for MLEnKF consists of a hierarchy of ensembles \(\{\hat{v}^{0}_{0,i}\}_{i=1}^{M_0}\) and \(\{(\hat{v}^{\ell -1}_{0,i}, \hat{v}^{\ell }_{0,i})_{i=1}^{M_\ell }\}_{\ell =1}^L\). For \(\ell =0\), \(\{\hat{v}^{0}_{0,i}\}_{i=1}^{M_0}\) is a sequence of i.i.d. random variables with \(\hat{v}^{0}_{0,i} \sim \mathbb {P}_{\Pi _0 u_0}\), and for \(\ell \ge 1\), \(\{(\hat{v}^{\ell }_{0,i}, \hat{v}^{\ell -1}_{0,i})\}_{i=1}^{M_\ell }\) is a sequence of i.i.d. random variable 2-tuples with \(\hat{v}^{\ell }_{0,i} \sim \mathbb {P}_{\Pi _\ell u_0}\) and pairwise coupling through \(\hat{v}^{\ell -1}_{0,i} = \Pi _{\ell -1} \hat{v}^{\ell }_{0,i}\). MLEnKF approximates the initial reference distribution \(\mathbb {P}_{u_0|Y_0}\) (recalling the convention \(Y_0 = \emptyset \), so that \(u_0|Y_0 = u_0\)) by the multilevel-Monte-Carlo-based and signed empirical measure
Similar to EnKF, the mapping
represents the transition of the MLEnKF hierarchy of ensembles over one prediction-update step and
represents the empirical distribution of the updated MLEnKF at time n. The MLEnKF prediction step consists of simulating all particle paths on all resolution one observation-time forward:
for \(\ell =0\) and \(i=1,2,\ldots , M_0\), and the pairwise coupling
for \(\ell =1,\ldots ,L\) and \(i = 1,2, \ldots , M_\ell \). Note here that the driving noise in the second argument of the dynamics \(\Psi ^{\ell -1}\) and \(\Psi ^{\ell }\) is pairwise coupled, and otherwise independent. For the update step, the MLEnKF prediction covariance matrix is given by the following multilevel sample-covariance estimator
and the multilevel Kalman gain is defined by
where
with \((\lambda _j,q_j)_{j=1}^m\) denoting the eigenpairs of \(H C^{\mathrm {ML}}_{n+1} H^* \in \mathbb {R}^{m\times m}\). The new observation \(y_{n+1}\) is assimilated into the hierarchy of ensembles by the following multilevel extension of EnKF at the zeroth level:
for \(i=1,2,\ldots , M_0\) with \(\{\eta ^0_{n+1,i}\}_{i=1}^{M_0}\) , and for each of the higher levels, \(\ell =1,\ldots ,L\), the pairwise coupling of perturbed observations
for \(i=1,\ldots ,M_\ell \), with the sequence \(\{\eta ^{\ell }_{n+1,i}\}_{i,\ell }\) being independent and identically \(N(0, \Gamma )-\)distributed. It is precisely the multiplication with the Kalman gain in the update step that correlates all the MLEnKF particles. In comparison to standard MLMC where all samples except the pairwise coupled ones are independent, this global correlation in MLEnKF substantially complicates the convergence analysis of the method.
Remark 3
Although unlikely, the multilevel sample prediction covariance \(C^{\mathrm {ML}}_{n+1}\) may have negative eigenvalues and, worst case, this could lead to \(S^{\mathrm{ML}}_{n+1}= H C^{\mathrm {ML}}_{n+1} H^* + \Gamma \) becoming a singular matrix. The impetus for replacing the matrix \((H C^{\mathrm {ML}}_{n+1} H^*)\) with its positive semidefinite “counterpart” \((H C^{\mathrm {ML}}_{n+1} H^*)^+\) in the Kalman gain formula (13) is to ensure that \(S^{\mathrm{ML}}_{n+1}\) is invertible and to obtain the bound \(|(S^{\mathrm{ML}}_{n+1})^{-1}| \le |\Gamma ^{-1}|\).
The following notation denotes the (signed) empirical measure of the multilevel ensemble \(\{(\hat{v}^{\ell -1}_{n,i},\hat{v}^{\ell }_{n,i})_{i=1}^{M_\ell }\}_{\ell =0}^L\):
and for any QoI \(\varphi : \mathcal {V}\rightarrow \mathbb {R}\), let
We conclude this section with an estimate that relates to the computational cost of one MLEnKF update step.
Proposition 3
Given an MLEnKF hierarchy of prediction ensembles
the cost of constructing the multilevel Kalman gain \(K^{\mathrm {ML}}_{n+1}\) is proportional to \(\sum _{\ell =0}^L m N_\ell M_\ell \). And if Assumption 2(iii) holds, then the cost of updating the \(\ell \)th level ensemble
by (15) is proportional to \(m N_\ell M_\ell \).
Proof
Notice that it is not required to compute the full multilevel prediction covariance \(C^{\mathrm{ML}}_{n+1}\) in order to build the MLEnKF Kalman gain, but rather only
(The advantage of storing \(R^{\mathrm{ML}}_{n+1} \in \mathbb {R}^{N_L \times m}\) rather than \(C^{\mathrm{ML}}_{n+1} \in \mathbb {R}^{N_L \times N_L}\) is the dimensional reduction obtained for large L, since then \(N_L \gg m\).)
For the Kalman gain, the cost of computing \(\mathrm {Cov}_{M_\ell }[ v^{\ell }_{n+1}, H v^{\ell }_{n+1}] \in \mathbb {R}^{N_\ell \times m}\) is proportional to \(m N_\ell M_\ell \). There are also the insignificant one-time costs of constructing and inverting \(S^{\mathrm{ML}}_{n+1}\), and the matrix multiplication \(R^{\mathrm{ML}}_{n+1}(S^{\mathrm{ML}}_{n+1})^{-1}\). In total, these costs are proportional to \(N_Lm^2\).
The cost of updating the \(\ell \)th level ensemble by (15) contains the one-time cost of the matrix multiplications \(\Pi _\ell K^{\mathrm {ML}}_{n+1}\) which by Assumption 2(iii) is proportional to \(mN_\ell \). For each particle, the cost of computing \(H {v}^{\ell }_{n+1,i} \) is proportional to \(N_\ell \), since \({v}^{\ell }_{n+1,i} \in \mathcal {V}_\ell \), and the cost of computing \((\Pi _\ell K^{\mathrm {ML}}_{n+1})(H {v}^{\ell }_{n+1,i} )\) and \((\Pi _\ell K^{\mathrm {ML}}_{n+1})\tilde{y}^{\ell }_{n+1,i}\) are both proportional to \(mN_\ell \). \(\square \)
3.3 MLEnKF algorithms
A subtlety with computing (17) efficiently is that the summands will be elements of different sized tensor spaces since
for \(\ell =1,2,\ldots ,L\). The algorithm presented below efficiently computes (17) through performing all arithmetic operations in the tensor space of lowest possible dimension available at the current stage of computations. When Proposition 3 applies, the computational cost of the algorithm is \(\mathcal {O}(m\sum _{\ell =0}^L M_\ell N_\ell )\). For ease of exposition, we will in the sequel employ the convention \(v^{-1}_{n,i} = \hat{v}^{-1}_{n,i} =0\) for all n, i.

In Algorithm 2, we summarize the main steps for one predict-update iteration of the MLEnKF method.

4 Theoretical results
In this section we derive theoretical results on the approximation error and computational cost of weakly approximating the MFEnKF filtering distribution by MLEnKF. We begin by stating the main theorem of this paper. It gives an upper bound for the computational cost of achieving a sought accuracy in \(L^p(\Omega )\)-norm when using the MLEnKF method to approximate the expectation of a QoI. The theorem may be considered an extension to spatially extended models of the earlier work [23].
Theorem 1
(MLEnKF accuracy vs. cost) Consider a Lipschitz continuous QoI \(\varphi :\mathcal {V}\rightarrow \mathbb {R}\) and suppose Assumption 2 holds. For a given \(\varepsilon >0\), let L and \(\{M_\ell \}_{\ell =0}^L\) be defined under the constraints \(L = \lceil 2{d}\log _\kappa (\varepsilon ^{-1})/\beta \rceil \) and
Then, for any \(p\ge 2\) and \(n \in \mathbb {N}\),
where we recall that \({\hat{\mu }}^{\mathrm{ML}}_n\) denotes the MLEnKF empirical measure (16), and \({\hat{\bar{\mu }}}_n\) denotes the mean-field EnKF distribution at time n (meaning \(\hat{\bar{ v}}_{n} \sim {\hat{\bar{\mu }}}_n\)).
The computational cost of the MLEnKF estimator
satisfies
The proof of this theorem is presented at the end of this section, and it depends upon the intermediary results presented prior to the proof.
Remark 4
The constraint \(d\gamma _x +\gamma _t \ge d\) in Assumption 2(iii) was imposed to ensure that the computational cost of the forward simulation, Cost\((\Psi ^\ell ) \eqsim h_\ell ^{-(d\gamma _x +\gamma _t) }\), is either linear or superlinear in \(N_\ell \). In view of Proposition 3, the share of the total cost of a single predict and update step assigned to level \(\ell \) is proportional to \(M_\ell \text {Cost}(\Psi ^\ell )\). This cost estimate is used as input in the standard-MLMC-constrained-optimization approach to determining \(M_\ell \), cf. (18). However, it is important to observe that in settings with high dimensional observations, \(m \ge N_0\), the input in said optimization problem needs to be modified accordingly, as then the cost on the lower levels will be dominated by m rather than \(\hbox {Cost}(\Psi ^\ell )\).
The first result we present is a collection of direct consequences of Assumption 2:
Proposition 4
If Assumption 2 holds, then for all \(u,v \in \cap _{p \ge 2} L^p(\Omega , V)\), and globally Lipschitz QoI \(\varphi :\mathcal {V}\rightarrow {\mathbb {R}}\),
-
(i)
\(\Vert \Psi ^{\ell }(v) - \Psi ^{\ell -1}(v) \Vert _{L^p(\Omega , \mathcal {V})} \lesssim (1+\Vert v\Vert _{L^p(\Omega , V)}) h_\ell ^{\beta /2}\), for all \(p\ge 2\),
-
(ii)
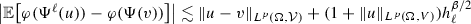 , for all \(p \ge 2\),
, for all \(p \ge 2\), -
(iii)
and for all \(n\ge 1\), the MFEnKF prediction covariance (9) satisfies
$$\begin{aligned} \Vert (I- \Pi _\ell ) {\bar{C}}_n \Vert _{\mathcal {V}\otimes \mathcal {V}} \lesssim \Vert \Psi (\hat{{\bar{v}}}_{n-1}) \Vert _{L^2(\Omega , V)} h_\ell ^{\beta /2}. \end{aligned}$$
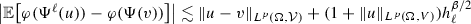 , for all
, for all Proof
Property (i) follows from Assumption 2(i) and the triangle inequality. Property (ii) follows from the Lipschitz continuity of \(\varphi \) followed by the triangle inequality, Assumption 1(i), and Assumption 2(i). For property (iii), Proposition 2, Jensen’s inequality, definition (3), and Hölder’s inequality implies that

Since \((I-\mathcal {P}_\ell ) \bar{v}_n =(I-\mathcal {P}_\ell )\Psi (\hat{\bar{v}}_{n-1})\), Assumption 2(ii) implies that
\(\square \)
Similar to the analysis in [23, 36, 37, 41], we next introduce an auxiliary mean-field multilevel ensemble \(\{(\bar{v}^{\ell -1}_{n,i}, \bar{v}^{\ell }_{n,i})_{i=1}^{M_\ell }\}_{\ell =0}^L\), where every particle pair \((\bar{v}^{\ell -1}_{n,i},\bar{v}^{\ell }_{n,i})\) evolves by the respective forward mappings \(\Psi ^{\ell -1}\) and \(\Psi ^{\ell }\) using the same driving noise realization as the corresponding MLEnKF particle pair \((v^{\ell -1}_{n,i},v^{\ell }_{n,i})\). Note however that in the update of the mean-field multilevel ensemble, the limiting form MFEnKF covariance \(\bar{C}_n\) and Kalman gain \(\bar{K}_n\) from Eqs. (9) and (10) are used rather than corresponding ones based on sample moments of the multilevel ensemble itself. That is, the initial condition for each coupled particle pair is identical to that of MLEnKF
and one prediction-update iteration is given by
for \(\ell =0,1,\ldots , L\) and \(i = 1,2,\ldots , M_\ell \) (similar to before, we employ the convention \(\bar{v}^{-1} = \hat{\bar{ v}}^{-1} \mathrel {\mathop :}=0\)). By similar reasoning as in Proposition 2, it can be shown that also \(\bar{v}^{\ell }_n\), \(\hat{\bar{ v}}^{\ell }_n \in \cap _{p \ge 2} L^p(\Omega , V)\) for any \(\ell ,n \in \mathbb {N}\cup \{0\}\). One may think of the auxiliary mean-field multilevel ensemble as “shadowing” the MLEnKF ensemble.
Before bounding the difference between the multilevel and mean-field Kalman gains by the two next lemmas, let us recall that they respectively are given by
Lemma 1
For the matrix \((H C^{\mathrm{ML}}_n H^*)^+:\mathbb {R}^{m\times m}\) defined by (14) with the spectral decomposition eigenpairs \((\lambda _j, q_j)_{j=1}^m\) it holds that
Proof
Since \((H C^{\mathrm{ML}}_n H^*)^+ - H {\bar{C}}_n H^*\) is self-adjoint and positive semi-definite,
It remains to verify the lemma when  . Let the normalized eigenvector associated to the eigenvalue \( \min _{\{j; \lambda _j< 0\}} \lambda _j\) be denoted \(q_{\max }\). Then, since \((HR^{\mathrm{ML}}_n)^+ q_{\max }= 0\) and the mean-field covariance \({\bar{C}}_n\) is self-adjoint and positive semi-definite,
. Let the normalized eigenvector associated to the eigenvalue \( \min _{\{j; \lambda _j< 0\}} \lambda _j\) be denoted \(q_{\max }\). Then, since \((HR^{\mathrm{ML}}_n)^+ q_{\max }= 0\) and the mean-field covariance \({\bar{C}}_n\) is self-adjoint and positive semi-definite,
\(\square \)
The next step is to bound the Kalman gain error in terms of the covariance error.
Lemma 2
There exists a positive constant \({\tilde{c}}_n<\infty \), depending on \(\left\| H\right\| _{L(\mathcal {V},\mathbb {R}^{m})}\), \(|\Gamma ^{-1}|\), and \(\left\| \bar{K}_n \right\| _{L(\mathbb {R}^{m},\mathcal {V})}\), such that
Proof
The proof of this lemma as is similar to that of [23, Lemma 3.4]. For completeness, we have included a proof in “Appendix C”. \(\square \)
The next lemma bounds the distance between the prediction covariance matrices of MLEnKF and MFEnKF. For that purpose, let us first recall that the dynamics for the mean-field multilevel ensemble \(\{(\bar{v}^{\ell -1}_{n,i}, \bar{v}^{\ell }_{n,i})_{i=1}^{M_\ell }\}_{\ell =0}^L\) is described in Eqs. (21) and (22), and introduce the auxiliary matrix
Lemma 3
For any \(\varepsilon >0\), let L and \(\{M_\ell \}_{\ell =0}^L\) be defined as in Theorem 1. If Assumption 2 holds, then for any \(p\ge 2\) and \(n \in \mathbb {N}\),
Proof
Introducing the auxiliary covariance matrix
and using the triangle inequality,
The result follows by Lemmas 4 and 5. \(\square \)
Lemma 4
For any \(\varepsilon >0\), let L be defined as in Theorem 1. If Assumption 2 holds, then for any \(n\in \mathbb {N}\) and \(p\ge 2\),
Proof
Recall that initial data of the limit mean-field methods is given by \(\hat{\bar{ v}}_0\sim {\hat{\mu }}_0\) and that \(\hat{\bar{ v}}^\ell _0 =\Pi _\ell \hat{\bar{ v}}_0\), so that by Assumption 2(ii),
and by Proposition 4(iii),
Inequality (26) consequently holds by induction, and thus also (27) by the triangle inequality. To prove inequality (28),

\(\square \)
We complete the proof of Lemma 3 by deriving the following bound for \(\Vert \bar{C}^{\mathrm{ML}}_n - \bar{C}^L_n\Vert _p\) :
Lemma 5
(Multilevel i.i.d. sample covariance error) For any \(\varepsilon >0\), let L and \(\{M_\ell \}_{\ell =0}^L\) be defined as in Theorem 1. If Assumption 2 holds, then for any \(p\ge 2\) and \(n \in \mathbb {N}\),
where we recall that \(\bar{C}^L_n \mathrel {\mathop :}=\mathrm {Cov}[\bar{v}^L_n]\).
Proof
Since the sample covariances in (24) are unbiased,

and therefore

Next, introduce the linear centering operator \(\Upsilon :L^1(\Omega ,\mathcal {V}\otimes \mathcal {V}) \rightarrow L^1(\Omega ,\mathcal {V}\otimes \mathcal {V})\), defined by  . Then, by Eq. (24),
. Then, by Eq. (24),

where \(\Delta _\ell \bar{v}_n := \bar{v}_n^\ell - \bar{v}_n^{\ell -1}\) with the convention \(\bar{v}_n^{-1}=0\), and
By Lemmas 4 and 10 (the latter lemma is located in “Appendix A)”,

\(\square \)
We now turn to bounding the last term of the right-hand side of inequality (25).
Lemma 6
For any \(\varepsilon >0\), let L and \(\{M_\ell \}_{\ell =0}^L\) be defined as in Theorem 1. If Assumption 2 holds, then for any \(p\ge 2\) and \(n \in \mathbb {N}\),
Proof
From the definitions of the sample covariance (7) and multilevel sample covariance (12), one obtains the bounds
and
The bilinearity of the sample covariance yields that
and
For bounding \(I_1\) we use Jensen’s and Hölder’s inequalities:

The second summand of inequality (30) is bounded similarly, and we obtain
The \(I_2\) term can also be bounded with similar steps as in the preceding argument so that also
The proof is finished by summing the contributions of \(I_1\) and \(I_2\) over all levels. \(\square \)
The propagation of error in update steps of MLEnKF is governed by the magnitude \(\Vert {\bar{C}}_n - C_n^{\mathrm{ML}}\Vert _p\), i.e., the distance between the MFEnKF prediction covariance and the MLEnKF prediction covariance. The next lemma makes use of Lemma 6 to bound the distance between the mean-field multilevel ensemble \(\{(\hat{\bar{ v}}^{\ell -1}_{n,i},\hat{\bar{ v}}^{\ell }_{n,i})_{i=1}^{M_\ell }\}_{\ell =0}^L\) and the MLEnKF ensemble \(\{(\hat{v}^{\ell -1}_{n,i}, \hat{v}^{\ell }_{n,i})_{i=1}^{M_\ell }\}_{\ell =0}^L\).
Lemma 7
(Distance between ensembles) For any \(\varepsilon >0\), let L and \(\{M_\ell \}_{\ell =0}^L\) be defined as in Theorem 1. If Assumption 2 holds, then for any \(p\ge 2\) and \(n \in \mathbb {N}\),
Proof
The proof is similar to that of [23, Lemma 3.10]. For completeness, a proof is given in “Appendix C”. \(\square \)
With the bound between MLEnKF and its multilevel MFEnKF shadow, that conveniently for analysis consists of independent particles, we are finally ready to prove the main result.
Proof of Theorem 1
By the triangle inequality,
where \({\hat{\bar{\mu }}}^{\mathrm{ML}}_n\) denotes the empirical measure associated to the mean-field multilevel ensemble \(\{(\hat{\bar{ v}}^{\ell -1}_{n,i}, \hat{\bar{ v}}^{\ell }_{n,i}))_{i=1}^{M_\ell }\}_{\ell =0}^L\), and \({\hat{\bar{\mu }}}^L_n\) denotes the probability measure associated to \(\hat{\bar{ v}}^L\). The two first summands on the right-hand side above relate to the statistical error, whereas the last relates to the bias.
By the Lipschitz continuity of the QoI \(\varphi \), the triangle inequality, Lemma 7, and using the conventions \(\varphi (\hat{v}_n^{-1})=0\) and \(\varphi (\hat{\bar{ v}}_n^{-1})=0\), the first term satisfies the following bound
For the second summand of (32), we employ the telescoping property


Finally, the bias term in (32) satisfies

where the last step follows from the Lipschitz continuity of the QoI and Lemma 4. \(\square \)
Remark 5
Theorem 1 shows the cost-to-accuracy performance of MLEnKF with a disconcerting logarithmic penalty factor in (19) that grows geometrically in n. The same penalty appears in the work [23], yet the numerical experiments there indicate a rate of convergence that is uniform in n. The discrepancy between theory and practice may be an artifact of conservative bounds used in the proof of said theorem. By imposing further regularity constraints on the dynamics and the QoI, we were able to obtain an error bound without said logarithmic penalty factor for an alternative finite-dimensional-state-space MLEnKF method with local-level Kalman gains [24]. As an alternative to imposing further regularity constraints, we also suspect that ergodicity of the MFEnKF process may be used to avoid the geometrically growing the logarithmic penalty factor. Recently, there has been much work on the stability of EnKF [12, 13, 46].
We conclude this section with a result on the cost-to-accuracy performance of EnKF. It shows that MLEnKF generally outperforms EnKF.
Theorem 2
(EnKF accuracy vs. cost) Consider a Lipschitz continuous QoI \(\varphi :\mathcal {V}\rightarrow \mathbb {R}\), and suppose Assumption 2 holds. For a given \(\varepsilon >0\), let L and M be defined under the respective constraints \(L = \lceil 2{d} \log _\kappa (\varepsilon ^{-1})/\beta \rceil \) and \( M \eqsim \varepsilon ^{-2}\). Then, for any \(n \in \mathbb {N}\) and \(p \ge 2\),
where \(\hat{\mu }^{\mathrm{MC}}_n\) denotes the EnKF empirical measure, cf. Eq. (8), with particle evolution given by the EnKF predict and update formulae at resolution level L (i.e., using the numerical approximation \(\Psi ^L\) in the prediction and the projection operator \(\Pi _L\) in the update).
The computational cost of the EnKF estimator
satisfies
Sketch of proof
By the triangle inequality,
where \(\hat{\bar{\mu }}_n^{\mathrm{MC}}\) denotes the empirical measure associated to the EnKF ensemble \(\{\hat{\bar{ v}}^L_{n,i} \}_{i=1}^M\) and \(\hat{\bar{\mu }}^{L}_n\) denotes the empirical measure associated to \(\hat{\bar{ v}}^L_n\). It follows by inequality (33) that \(I \lesssim \varepsilon \).
For the second term, the Lipschitz continuity of the QoI \(\varphi \) implies there exists a positive scalar \(c_\varphi \) such that \(|\varphi (x)| \le c_\varphi (1+\left\| x \right\| _{\mathcal {V}})\). Since \(\hat{\bar{v}}_n^L \in L^p(\Omega , V)\) for any \(n \in \mathbb {N}\) and \(p\ge 2\), it follows by Lemma 9 (on the Hilbert space \(\mathbb {R}\)) that

For the last term, let us first assume that for any \(p \ge 2\) and \(n \in \mathbb {N}\),
for the single particle dynamics \(\hat{v}_{n,1}^L\) and \(\hat{\bar{ v}}_{n,1}^L\) respectively associated to the EnKF ensemble \(\{\hat{v}_{n,i}^L \}_{i=1}^M\) and the mean-field EnKF ensemble \(\{\hat{\bar{ v}}_{n,i}^L\}_{i=1}^M\). Then the Lipschitz continuity of \(\varphi \), the fact that \(\hat{v}_{n,1}^L, \hat{\bar{ v}}_{n,1}^L \in L^p(\Omega , V)\) for any \(n\in \mathbb {N}\) and \(p\ge 2\) holds (when assuming (34)), and the triangle inequality yield that
All that remains is to verify (34), but we omit this as it can be done by similar steps as for the proof of inequality (31). \(\square \)
5 MLEnKF-adapted numerical methods for a class of stochastic partial differential equations
In this section we develop an MLEnKF-adapted version of the exponential Euler method, for the purpose of solving a family of stochastic reaction–diffusion equations. For a relatively large class of problems, we derive an \(L^p(\Omega , \mathcal {V})\)-convergence rate \(\beta \) for pairwise coupled numerical solutions, cf. Assumption 2, which will needed when implementing MLEnKF.
5.1 The stochastic reaction–diffusion equation
We consider the following stochastic partial differential equation (SPDE)

where \(T>0\), and the reaction f, the cylindrical Wiener process W and the linear smoothing operator B will be described below. Our base-space is \(\mathcal {K}= L^2(0,1)\), we denote by \(A: D(A) =H^2(0,1) \cap H^1_0(0,1)\rightarrow \mathcal {K}\) the Laplace operator \(\Delta \) with homogeneous Dirichlet boundary conditions and \(H^k(0,1)\) denotes the Sobolev space of order \(k \in \mathbb {N}\). A spectral decomposition of \(-A\) yields the sequence of eigenpairs \(\{(\lambda _j, \phi _j)\}_{j \in \mathbb {N}}\) where \(-A \phi _j = \lambda _j \phi _j\) with \(\phi _j \mathrel {\mathop :}=\sqrt{2} \sin (j\pi x)\) and \(\lambda _j =\pi ^2 j^2\). \(\mathcal {K}= \overline{\text {span}\{\phi _j\}}\), it follows that
and eigenpairs of the spectral decomposition give rise to the following family of Hilbert spaces parametrized over \(r \in \mathbb {R}\):
with norm \(\Vert \cdot \Vert _{\mathcal {K}_r} \mathrel {\mathop :}=\Vert (-A)^{r}(\cdot )\Vert _{\mathcal {K}}\). Associated with the probability space \((\Omega , \mathcal {F}, \mathbb {P})\) and normal filtration \(\{\mathcal {F}_t\}_{t \in [0,T]}\), the \(I_{\mathcal {K}}\)-cylindrical Wiener process is defined by
where \(\{W_j : [0,T] \times \Omega \rightarrow \mathbb {R}\}_{j \in \mathbb {N}}\) is a sequence of independent \(\mathcal {F}_t /\mathcal {B}(\mathbb {R})\)-adapted standard Wiener processes. The smoothing operator is defined by
with the smoothing paramter \(b \ge 0\). It may be shown that \(B \mathcal {K}_r = \mathcal {K}_{r+b}\), and this implies that B becomes progressively more smoothing the higher the value of b.
In the remaining part of this section, we assume the following conditions on the nested Hilbert spaces \(V\subset \mathcal {V}\) and regularity conditions on the initial data \(u_0\) and the reaction term f hold:
Assumption 3
The Hilbert spaces \(V \subset \mathcal {V}\) are of the form \(\mathcal {V}= \mathcal {K}_{r_1}\) and \(V = \mathcal {K}_{r_2}\) for a pair of parameters \(r_1,r_2 \in \mathbb {R}\) satisfying
the initial data \(u_0\) is \(\mathcal {F}_0 /\mathcal {B}(V)\)-measurable and \( u_0\in \cap _{p\ge 2} L^p(\Omega , V)\), and the reaction satisfies
Under Assumption 3 there exists an up to modifications unique \((\Omega , \mathcal {F}, \mathbb {P}, \{\mathcal {F}_t\}_{t \in [0,T]})\)-mild solution of (35), which in this setting corresponds to a mapping \(u:[0,T]\times [0,1] \times \Omega \rightarrow \mathbb {R}\) that is an \(\mathcal {F}_t/\mathcal {B}(\mathcal {K}_{r_2})\)-predictable stochastic process satisfying
\(\mathbb {P}\)-almost surely for all \(t\in [0,T]\). Moreover, for any \(p \ge 2\) and \(r \in [r_1,r_2]\), it holds that
where \(C>0\) depends on p, r, and T, cf. [28].
Remark 6
The Dirichlet homogeneous boundary conditions imposed in (35) only make pointwise sense provided \(u(t,\cdot ) \in \mathcal {K}_{1/2+\delta }\) for some \(\delta >0\) and all \(t \in (0,T]\), \(\mathbb {P}\)-almost surely. In lower-reglarity settings, e.g., when \(u(t,\cdot ) \notin C(0,1)\), said boundary condition should be interpreted in mild rather than pointwise sense.
5.2 The filtering problem
We consider a discrete-time filtering problem of the form (1) and (2) with the above SPDE as underlying model with \(\Psi (u_n)\) denoting the mild solution of (35) at \(T>0\) given the initial data \(u_n \in \cap _{p \ge 2} L^p(\Omega , V)\). The underlying dynamics at observation times \(0,T,2T, \ldots \) is thus described by the dynamics
and the finite-dimensional partial observation of \(u_n\) at time nT is given by
where \(H u = [H_1(u), \dots , H_m(u)]^{\mathsf {T}}\in \mathbb {R}^m\) with \(H_i \in \mathcal {V}^*\) for \(i=1,2,\ldots , m\). Note further that Assumption 3 implies that \(V\subset \mathcal {K}_0=\mathcal {K}\), so we may represent the mild solution in the basis \(\{\phi _j\}\) at any observation time nT:
5.3 Spatial truncation
Before introducing a fully discrete MLEnKF approximation method for the filtering problem, let us warm up by having a quick look at an exact-in-time-truncated-in-space approximation method. It consists of the hierarchy of subspaces \(\mathcal {V}_\ell = \mathcal {P}_\ell \mathcal {V}= \text {span}(\{\phi _{k}\}_{k=1}^{N_\ell })\), \(\Pi _\ell = \mathcal {P}_\ell \) and
To verify that this approximation method can be used in the MLEnKF framework, it remains to verify Assumptions 1 and 2(i)–(ii), and to determine the rate parameter \(\beta >0\). The Eq. (37), the regularity \(f \in {\mathrm{Lip}}(\mathcal {K}_{r_1})\), the inequality
and Jensen’s inequality imply that for any \(p\ge 2\), there exists a \(C>0\) such that
Hence by Gronwall’s inequality,
which verifies Assumption 1(i). Assumption 1(ii) follows from (38). To verify that Assumption 2(i) holds with rate \(\beta = 4(r_2-r_1)\), observe that for any \(p\ge 2\),
where the last inequality follows from (38) and \(h_\ell \eqsim N_\ell ^{-1}\). Assumption 2(ii) follows by a similar shift-space argument. (Relating to Assumption 2(iii), we leave the question of the computational cost of this method open for the time being, but see Sect. 6.2 for treatment in one example.)
5.4 A fully-discrete approximation method
The fully-discrete approximation method consists of Galerkin approximation in space and numerical integration in time by the exponential Euler scheme, cf. [29, 30]. Given a timestep \(\Delta t_\ell = T/J_\ell \), let \(\{U_{\ell , k} \}_{k=0}^{J_\ell } \subset \mathcal {V}_\ell \) with \(U_{\ell ,0} = \mathcal {P}_\ell u_0\) denote the numerical approximation SPDE (35) on level \(\ell \). It is given by the scheme
where \(A_\ell \mathrel {\mathop :}=\mathcal {P}_\ell A\) and \(f_\ell \mathrel {\mathop :}=\mathcal {P}_\ell f\). The jth mode of the scheme \(U^{(j)}_{\ell ,k} \mathrel {\mathop :}=\langle U_{\ell , k}, \phi _j\rangle _{\mathcal {K}}\) for \(j =1,2,\ldots , N_\ell \), is given by
for \(k=0,1,\ldots , J_\ell -1\) with i.i.d.
for \(j \in \{1,2,\ldots , N_\ell \}\), \(k \in \{0,1,\ldots , J_\ell -1\}\) and \(\ell = 0,1, \ldots \) In view of the mode-wise numerical solution, the \(\ell \)th level solution operator for the fully-discrete approximation method is defined by
5.4.1 Coupling of levels
For a hierarchy of temporal resolutions \(\{\Delta t_\ell = T/J_\ell \}\) with \(J_\ell = 2^\ell J_0\), pairwise correlated solutions \(({\widetilde{\Psi }}^{\ell -1}(u_0), \widetilde{\Psi }^\ell (u_0))\) are obtained through first generating the fine-level driving noise \(\{R_{\ell ,k}\}_{k}\) and the solution \(\widetilde{\Psi }^\ell (u_0)\) by (42) and thereafter computing the coarse level solution conditioned on \(\{R_{\ell ,k}\}_{k}\). Since \(J_\ell = 2J_{\ell -1}\), it follows that
Consequently
and the conditional coarse-level solution \({\widetilde{\Psi }}^{\ell -1}(u_0) |\{R_{\ell ,k}\}_{k}\) is of the form
for \(k= 0,1,\ldots ,J_{\ell -1}-1\), and with the initial condition \(U_{\ell -1,0} = \mathcal {P}_{\ell -1} u_0\). In other words, the scheme for the jth mode of the coarse level solution is given by
for \(j =1,2,\ldots ,N_{\ell -1}\) and \(k= 0,1,\ldots ,J_{\ell -1}-1\), and the coarse level solution takes the form
This coupling approach may be viewed as an extension of the multilevel coupling of Ornstein–Uhlenbeck processes for stochastic differential equations [43].
5.4.2 Assumptions and convergence rates
To show that the fully-discrete numerical method may be used in MLEnKF, it remains to verify that Assumptions 1 and 2(i)–(ii) hold.
Assumption 1(i): Let \(U_{\ell , k}\) and \({\bar{U}}_{\ell , k}\) denote solutions at time \(t=k\Delta t_\ell \) of the scheme (42) with respective initial data \(U_{\ell , 0} = \mathcal {P}_\ell u_0\) and \({\bar{U}}_{\ell , 0} = \mathcal {P}_\ell v_0\) fpr some \(u_0,v_0 \in L^p(\Omega , \mathcal {V})\). Then, by (40), and the properties: (a) for all \(\ell \ge 0\) and \(v \in \mathcal {V}_\ell \)
and (b) \(f \in {\mathrm{Lip}}(\mathcal {V},\mathcal {V})\); there exists a \(C>0\) such that
Consequently, for every \(p \ge 2\), there exists a \(c_{\Psi }>0\) such that
holds for all \(\ell \ge 0\) and \(u_0,v_0 \in L^p(\Omega ,\mathcal {V})\).
Assumption 1(ii): Under the regularity constraints imposed by Assumption 3, it holds for all \(\ell \in \mathbb {N}\) and \(U_{\ell ,k} = \sum _{j=1}^{N_\ell } U^{(j)}_{\ell ,k} \phi _k\) that
where \(C>0\) depends on r and p, but not on \(\ell \), cf. [28, Lemma 8.2.21].
Assumption 2(i): We begin by introducing the auxiliary \(\ell \)th level exact-in-time Galerkin approximation
and the notation \({\widehat{\Psi }}^\ell (u_0) \mathrel {\mathop :}=u^\ell (T)\). Assumption 3 and [28, Corollary 8.1.12] imply that for any \(p \ge 2\) and \(r \in [r_1, r_2]\)
The triangle inequality and (41) yield that
and by [28, Corollary 8.1.11-12 and Theorem 8.2.25],Footnote 1 it respectively holds that for any \(p\ge 2\)
and
This verifies Assumption 2(i) as it leads to the following bound: for any \(p\ge 2\),
Assumption 2(ii) only depends on the projection operator, and thus follows from (41).
5.5 Linear forcing
For the remaining part of this section consider the linear case \(f(u)=u\) of the filtering problem in Sect. 5.2. We derive explicit values for the rate exponents \(\beta \), \(\gamma _x\) and \(\gamma _t\) when applying MLEnKF with either the exact-in-time-truncated-in-space approximation method in Sect. 5.3 or the fully-discrete approximation method in Sect. 5.4.
The exact solution of the jth mode for this linear case is
Although we see that the underlying dynamics can be solved exactly, the filtering problem is still non-trivial since correlations between the modes \(\{u_{n+1}^{(j)}\}_j\) will arise from the assimilation of observations (39), unless the observation operator is of the special form \(H(\cdot ) = [H_1(\cdot ), \ldots , H_m(\cdot )]^{\mathsf {T}}\) with all operator components of the form \(H_i=\phi _j^*\) for some \(j\in \mathbb {N}\).
Since the Galerkin and spatial approximation methods coincide in the linear setting, meaning \(\Psi ^\ell = {\widehat{\Psi }}^\ell \), it holds by (41) that for any \(p \ge 2\),
Let us next show that the time discretization convergence rate (45) is improved from \(r_1-r_2\) in the above nonlinear setting to 1 in the linear setting. We begin by studying the properties of the sequence \(\{\mathcal {P}_\ell {\widetilde{\Psi }}^{m}(u_0)\}_{m=\ell }^\infty \) for a fixed \(\ell \in \mathbb {N}\). The jth mode projected difference of coupled solutions for \(m>\ell \) is given by
and the difference can be bounded as follows:
Lemma 8
Consider the SPDE (35) with \(f(u)=u\), and other assumptions as stated in Sect. 5.1. Then for any \({\bar{u}}_0 \in L^2(\Omega , \mathcal {V})\) and \(m \in \mathbb {N}\), the sequence
can be split into three parts
where \(I_{m,j,1}, I_{m,j,2},\) and \(I_{m,j,3}\) for every \(j=1,2,\ldots \) is a triplet of mutually independent random variables and \(I_{m,j,1} = I_{m,j,2} = I_{m,j,3}=0\) for all \(j> N_{m-1}\). Furthermore, there exists a constant \(c>0\) that depends on \(T>0\) and \(\lambda _1>1\) such that for any \(m \in \mathbb {N}\) and all \(j \le N_{m-1}\),
and \(I_{m,j,2}\) and \(I_{m,j,3}\) are mean zero Gaussians with variance bounded by

Proof
See “Appendix B”. \(\square \)
By Lemma 8 and Assumption 3, there exists a \(C>0\) depending on p, T, \(\lambda _1\) and \(b +1/4-r_1\) such that for any \(m > \ell \) and \(u_0 \in \cap _{p\ge 2} L(\Omega , V)\),
Here, the sixth inequality follows from \(I_{m,j,2}\) and \(I_{m,j,3}\) being mean zero Gaussians with variance bounded by (47), which implies that for any \(p\ge 2\), there exists a constant \(C>0\) depending on p such that
holds for all \(j \in \mathbb {N}\). And the last inequality follows from the assumption \(r_1<b+1/4\), which implies that \(2(r_1-b)-1<-1/2\) and hence
From inequality (48) we deduce that \(\{\mathcal {P}_\ell {\widetilde{\Psi }}^{m}(u_0)\}_{m=\ell }^\infty \) is \(L^p(\Omega , \mathcal {V})\)-Cauchy and that there exists a constant \(C>0\) depending on p, T, \(\lambda _1\) and \(b +1/4-r_1\) such that
In view of the preceding inequality and (46) we obtain the following \(L^p\)-strong convergence rate for the fully discrete scheme:
Theorem 3
Consider the SPDE (35) with \(f(u)=u\) and other assumptions as stated in Sect. 5.1. Then for all \(p\ge 2\) and \(\ell \in \mathbb {N}\cup \{0\}\), there exists a \(C>0\) such that
where C depends on \(r_1,r_2\) and p, but not on \(\ell \).
Remark 7
To the best of our knowledge, the \(L^p\)-strong time-discretization convergence rate (49) is an improvement of the literature in two ways. First, for \(p=2\), it is slightly higher than \(\mathcal {O}(\log (\Delta t^{-1}) \Delta t)\), which is the best rate in the literature, cf. [29]. And second, this is the first proof of order 1 \(L^p\)-strong time-discretization convergence rate for any \(p\ge 2\).
5.5.1 Error equilibration
The temporal and spatial discretization errors of (50) are equlibrated through determining the base \(\kappa >1\) that induces a sequence \(\{N_\ell = N_0 \kappa ^\ell \}\) such that \(N_\ell ^{2(r_1-r_2)} \eqsim J_\ell ^{-1} \eqsim 2^{-\ell }\). The solution is \(\kappa = 2^{(r_2-r_1)/2}\), which yields the following \(L^p\)-strong convergence rate in (50):
In view of Assumption 2, MLEnKF with the fully-discrete approximation method yields the convergence rate \(\beta = 4(r_2-r_1)\) and the computational cost rates \(\gamma _x = 1\) and \(\gamma _t = 2(r_2-r_1)\) in the considered linear setting.
Remark 8
(MLEnKF time) Note that one could consider applying the SDE version of [23] to a fixed finite approximation of the SPDE. However, in this case we would be incurring a fixed baseline cost associated to that discretization. In comparison to using a single level method, there would be a gain in efficiency, as a result of using the multilevel identity with respect to the time discretization. But this would be still substantially less efficient than accounting also for the spatial approximation in the multilevel method, as we do in the method considered here.
6 Numerical examples
In this section we present numerical performance studies of EnKF and MLEnKF applied to two different filtering problems with underlying dynamics given by the SPDE (35). In the first example, the reaction term of the SPDE is linear, and in the second example we consider a nonlinear, and thus more challenging, reaction term.
6.1 Discretization parameters and the relationship between computational cost and accuracy
If we neglect the logarithmic factor in (19), as is motivated by Remark 5, then Theorems 1 and 2 respectively imply the following relations between mean squared error (MSE) and computational cost
and
In other words,
and
For all test problems, we use the observation-time interval \(T=1/2\), \(N = 40\) observation times, \(N_\ell = 2^{\ell +2}\), and, when relevant \(J_\ell = 2^{\ell +2}\) (i.e., for the fully-discrete numerical method). The approximation error, which we refer to as the mean squared error (MSE), is defined as the sum of the squared QoI error over the observation times and averaged over 100 realizations of the respective filtering methods. That is,
where \(\{{\hat{\mu }}^{\mathrm{ML}}_{\cdot ,i} [\varphi ]\}_{i=1}^{100}\) is a sequence of i.i.d. QoI evaluations induced from i.i.d. realizations of the MLEnKF. And similarly,
In the examples below we numerically verify that the considered numerical methods respectively fulfill (51) and (52), when the above computational cost expressions are replaced/approximated by the wall-clock runtime of the computer implementations of the respective methods. More precisely, we numerically verify that the following approximate asymptotic inequalities hold:
and
6.2 Linear filtering problems
We consider the filtering problem in Sect. 5.2 with the linear forcing \(f(u)=u\) in the underlying dynamics (35), smoothing parameter \(b=1/2\), approximation space parameters \(r_1=1/4+\upsilon \) and \(r_2 = 3/4-\upsilon \) with \(\upsilon = 10^{-4}\), observation functional
observation noise parameter \(\Gamma =0.5\), QoI
and initial data
We note that \(H, \varphi \in \mathcal {V}^*\) and \(u_0 \in V\). Figure 1 illustrates one exact-in-time simulation of the SPDE.

Exact-in-time simulation of the SPDE in Sect. 6.2 over one observation-time interval with spatial resolution \(N_{10}=2^{12}\)
By the approximation \(\beta = 2(r_2-r_1) \approx 2\), application of the error equilibration in Sect. 5.5.1 yields (\(d\gamma _x = 1\),\(\gamma _t = 1\)) for the fully-discrete method and (\(d\gamma _x = 1\), \(\gamma _t = 0\)) for the spatially-discrete method. Figure 2 and the left subfigure of Fig. 3 display the runtime-to-MSE performance for the spatially-discrete and fully-discrete methods, respectively.

Runtime-to-MSE comparison for the filtering problem in Sect. 6.2 using the spatially-discrete method
The right subfigure of Fig. 3 displays the graph of
(where \(\text {MSE(MLEnKF)}\) in the second argument denotes the “MSE” obtained for a given “Runtime”). The numerical observations are consistent with the approximate theoretical predictions (53) and (54).

Left: Runtime-to-MSE comparison for the filtering problem in Sect. 6.2 using the fully-discrete numerical method. Right: Graph of \((\text {Runtime(MLEnKF)}, \, \text {MSE(MLEnKF)}\times \text {Runtime(MLEnKF)}/L^3)\) for the fully-discrete numerical method. Note the y-axis here, and in future such plots, has linear scaling
The reference-solution sequence \(\{{\hat{\bar{\mu }}}_n [\varphi ] \}_{n=1}^N\) that is needed to estimate the MSE in the above figures, is approximated by Kalman filtering the subspace \(\mathcal {V}_{12} \subset \mathcal {V}\), which is an \(N_{12} = 2^{14}\)-dimensional subspace. This yields an accurate approximation, since when the underlying dynamics (35) is linear with Gaussian additive noise, the full-space Kalman filter distribution equals the reference MFEnKF distribution \({\hat{\bar{\mu }}}\). Furthermore, EnKF and MLEnKF solutions are computed with ensemble particles at no higher spatial resolution than \(\mathcal {V}_{9}\) in the cost-to-accuracy studies.
6.3 A nonlinear filtering problem
We seek the mild solution to the following nonlinear SPDE with periodic boundary conditions

where W and B are described below. Here, the operator \(-A = (I-\Delta )\) is defined as a mapping \(A: H^2(0,1) \cap H^1_{\text {per}}(0,1)\rightarrow \mathcal {K}= L^2(0,1)\), where \(H^1_{\text {per}}(0,1) := \{f \in H(0,1) \mid (f-f(0)) \in H^1_0(0,1) \}\). The periodic boundary condition is different from the zero-valued boundary condition in (35), and, in order to spectrally decompose \(-A\), we now express the base-space \(\mathcal {K}=L^2(0,1)\) by the closure of the span of the Fourier basis
The operator \(-A\) is spectrally decomposed by
with
As in Sect. 5.1, we introduce the family of Hilbert spaces parametrized in \(r\in \mathbb {R}\)
with norm \(\Vert \cdot \Vert _{\mathcal {K}_r} \mathrel {\mathop :}=\Vert (-A)^{r}(\cdot )\Vert _{\mathcal {K}}\). As smoothing operator B, we consider (36) with parameter \(b=1/4\), where W denotes an \(I_{\mathcal {K}}\)-cylindrical Wiener process [both B and W are of course expanded in the currently considered basis (57)]. We consider the approximation spaces
where \(\nu =10^{-4}\), the QoI (55) and the observation operator
The spectral representation of the initial data
implies that \(u(0,\cdot ) \in \mathcal {K}_{(1-\nu )/2}\). Figure 4 illustrates one simulation of the SPDE by the numerical scheme described below.

By the Lipschitz-continuity of the reaction term, it follows that Assumption 3 is fulfilled. Moreover, the well-posedness theory for the zero-valued boundary condition for the SPDE (35) extends to the current setting, and so does the theory for the fully-discrete exponential Euler method in Sect. 5.4, cf. [28].
6.3.1 Numerical scheme
We apply the coupled fully discrete approximation method described in Sect. 5.4, but, due to the nonlinearity of the reaction term \(f(u)=\sin (\pi u)\), the spectral representation in the coupled scheme (42) and (44) needs to be approximated. Namely, the approximation of \([(f_\ell (U_{\ell ,k}))^{(1)}, \ldots , (f_\ell (U_{\ell ,k}))^{(N_\ell )}]\) is obtained by application of the fast Fourier transform (FFT) as follows:
-
1.
Given the spectral representation \([U_{\ell , k}^{(1)}, \ldots , U_{\ell , k}^{(N_\ell )}]\) compute the physical-space-on-uniform-mesh representation by the inverse FFT
$$\begin{aligned}{}[U_{\ell , k}(0), U_{\ell , k}(1/N_\ell ), \ldots , U_{\ell , k}(1 - N_\ell ^{-1})] = \text {IFFT}[U_{\ell , k}^{(1)}, \ldots , U_{\ell , k}^{(N_\ell )}]. \end{aligned}$$ -
2.
Evaluate the nonlinear reaction term in physical space and approximate the spectral representation by FFT
$$\begin{aligned}&[(f_\ell (U_{\ell ,k}))^{(1)}, \ldots , (f_\ell (U_{\ell ,k}))^{(N_\ell )}]\\&\quad \approx \text {FFT}[f(U_{\ell , k}(0)), f(U_{\ell , k}(1/N_\ell )), \ldots , f(U_{\ell , k}(1 - N_\ell ^{-1}))]. \end{aligned}$$
The spectral approximation of the coarse-level reaction term is obtained analogously. Due to the FFT approximation error in step 2. above, we cannot directly obtain the rate parameter \(\beta \) from the analysis in Sect. 5.4. To infer \(\beta \), we instead perform numerical studies of the \(L^p(\Omega ,\mathcal {V})\)-convergence rate of the coupled-level difference of the FFT-based fully-discrete method \({\widetilde{\Psi }}^\ell (u) - {\widetilde{\Psi }}^{\ell -1}(u)\) towards 0, where the expectation is estimated with the Monte Carlo method with \(M=10^5\) samples:
Recalling that \(h_\ell ^{-1} \eqsim N_\ell \eqsim J_\ell = 2^{2+\ell }\) for the numerical solver \({\widetilde{\Psi }}^\ell \), we infer from the results of the numerical study (58), which is provided in Fig. 5, that
with \(\beta =2\). Further numerical studies, which we do not include here, indicate that the right hand side of (59) may be decomposed into \(\mathcal {O}(N_\ell ^{-1} + J_\ell ^{-1})\). On the basis of these observations, the configuration of discretization parameters for this problem, \(N_\ell \eqsim J_\ell \), is in alignment with the efficiency-optimized error equilibration strategy in Sect. 5.5.1.

Numerical estimates of the error \(\Vert {\widetilde{\Psi }}^\ell (u_0) - {\widetilde{\Psi }}^{\ell -1}(u_0)\Vert _p\) by the Monte Carlo method (58) for \(p=2\) (dash-dot), \(p=4\) (solid-circle), and \(p=8\) (dash-diamond). The solid line represents the reference function \(f(\ell ) = 2^{-(\ell +1)}\)
The left subfigure in Fig. 6 displays the results of the runtime-to-MSE studies of EnKF and MLEnKF.

Left: Runtime-to-MSE for the nonlinear filtering problem in Sect. 6.3.1 using the fully-discrete method. Right: Graph of \((\text {Runtime(MLEnKF)}, \, \text {MSE(MLEnKF)}\times \text {Runtime(MLEnKF)}/L^3)\) for the fully-discrete method
As pseudo-reference solution, we use the approximation
with the MLEnKF estimator \(\mu ^{\mathrm{{ML}}}_{n,i}[\varphi ]\) here being computed on a finer resolution than all those considered in the runtime-to-MSE study. The right subfigure in Fig. 6 displays the graph of
Once again, the numerical observations are consistent with the theoretical asymptotical behavior predicted by (53) and (54).
Remark 9
(MLEnKF versus Multilevel particle filters) To the best of our knowledge, there does not exist a general multilevel particle filter for SPDE to this date. When the effective dimension on level \(\ell \) is \(N_\ell \), the general requirement for particle filters is that the ensemble size on that level is bounded from below by \(ce^{N_\ell }\) particles, for some constant \(c>0\). Effective dimension refers to the dimension of the space over which importance sampling needs to be performed [1, 3, 10]. For example, in the case of full observations, the effective dimension can be equal to the state-space dimension. For MLEnKF, on the other hand, the level \(\ell \) ensemble size is always bounded from above by \(\mathcal {O}(L^2 N_\ell ^{(\beta -d\gamma _x-\gamma _t)/(2d)} )\), even with full observations. The set of MLEnKF-tractable problems is therefore substantially larger than the set of problems tractable by particle filters.
7 Conclusion
We have presented the design and analysis of a multilevel EnKF method for infinite-dimensional spatio-temporal processes depending on a hierarchical decomposition of both the spatial and the temporal parameters. We have proved theoretically and provided numerical evidence that under suitable assumptions, a similar asymptotic cost-to-accuracy is obtained for MLEnKF as that one obtains for standard multilevel Monte Carlo methods. This result has potential for broad impact across application areas in which there has been a recent explosion of interest in EnKF, for example weather prediction and subsurface exploration.
Notes
In the notation of the lecture notes [28], the parameters \(\gamma \), \(\beta \) and \(\eta \), which describe different properties than in this paper, take the values \(\gamma =r_1\), \(\beta =b-1/4\) and \(\eta =2(\gamma -\beta )\).
References
Agapiou, S., Papaspiliopoulos, O., Sanz-Alonso, D., Stuart, A., et al.: Importance sampling: intrinsic dimension and computational cost. Stat. Sci. 32, 405–431 (2017)
Bain, A., Crisan, D.: Fundamentals of Stochastic Filtering, vol. 60. Springer, Berlin (2008)
Bengtsson, T., Bickel, P., Li, B., et al.: Curse-of-Dimensionality Revisited: Collapse of the Particle Filter in Very Large Scale Systems, in Probability and statistics: Essays in Honor of David A, pp. 316–334. Institute of Mathematical Statistics, Freedman (2008)
Beskos, A., Crisan, D., Jasra, A., et al.: On the stability of sequential Monte Carlo methods in high dimensions. Ann. Appl. Probab. 24, 1396–1445 (2014)
Beskos, A., Crisan, D., Jasra, A., Kamatani, K., Zhou, Y.: A stable particle filter for a class of high-dimensional state-space models. Adv. Appl. Probab. 49, 24–48 (2017)
Beskos, A., Jasra, A., Law, K., Tempone, R., Zhou, Y.: Multilevel sequential Monte Carlo samplers. Stoch. Process. Appl. 127, 1417–1440 (2017)
Bickel, P., Li, B., Bengtsson, T., et al.: Sharp failure rates for the bootstrap particle filter in high dimensions, in pushing the limits of contemporary statistics: contributions in honor of Jayanta K, pp. 318–329. Institute of Mathematical Statistics, Ghosh (2008)
Brenner, S.C., Scott, L.R.: The Mathematical Theory of Finite Element Methods. Texts in Applied Mathematics, vol. 15, 3rd edn. Springer, New York (2008)
Burgers, G., Jan van Leeuwen, P., Evensen, G.: Analysis scheme in the ensemble Kalman filter. Mon. Weather Rev. 126, 1719–1724 (1998)
Chatterjee, S., Diaconis, P., et al.: The sample size required in importance sampling. Ann. Appl. Probab. 28, 1099–1135 (2018)
Del Moral, P.: Feynman-Kac Formulae: Genealogical and Interacting Particle Systems with Applications. Springer, Berlin (2004)
Del Moral, P., Kurtzmann, A., Tugaut, J.: On the stability and the uniform propagation of chaos of a class of extended ensemble Kalman-Bucy filters. SIAM J. Control Optim. 55, 119–155 (2017)
Del Moral, P., Tugaut, J.: On the stability and the uniform propagation of chaos properties of ensemble Kalman-Bucy filters. arXiv:1605.09329 (2016)
Dodwell, T.J., Ketelsen, C., Scheichl, R., Teckentrup, A.L.: A hierarchical multilevel Markov chain Monte Carlo algorithm with applications to uncertainty quantification in subsurface flow. SIAM/ASA J. Uncertain. Quantif. 3, 1075–1108 (2015)
Doucet, A., Godsill, S., Andrieu, C.: On sequential Monte Carlo sampling methods for Bayesian filtering. Stat. Comput. 10, 197–208 (2000)
Evensen, G.: Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. J. Geophys. Res. Oceans (1978–2012) 99, 10143–10162 (1994)
Evensen, G.: The ensemble Kalman filter: theoretical formulation and practical implementation. Ocean Dyn. 53, 343–367 (2003)
Giles, M.B.: Multilevel Monte Carlo path simulation. Oper. Res. 56, 607–617 (2008)
Giles, M.B., Szpruch, L.: Antithetic multilevel Monte Carlo estimation for multi-dimensional SDEs without Lévy area simulation. Ann. Appl. Probab. 24, 1585–1620 (2014)
Gregory, A., Cotter, C., Reich, S.: Multilevel ensemble transform particle filtering. SIAM J. Sci. Comput. 38, A1317–A1338 (2016)
Heinrich, S.: Multilevel Monte Carlo methods. In: Large-Scale Scientific Computing. Springer, pp. 58–67 (2001)
Hoang, V.H., Schwab, C., Stuart, A.M.: Complexity analysis of accelerated MCMC methods for Bayesian inversion. Inverse Probl. 29, 085010 (2013)
Hoel, H., Law, K., Tempone, R.: Multilevel ensemble Kalman filter. SIAM J. Numer. Anal. 54, 1813–1839 (2016)
Hoel, H., Shaimerdenova, G., Tempone, R.: Multilevel ensemble Kalman filtering with local-level Kalman gains. arXiv:2002.00480 (2020)
Jasra, A., Kamatani, K., Law, K.J., Zhou, Y.: Multilevel particle filters. SIAM J. Numer. Anal. 55, 3068–3096 (2017)
Jasra, A., Law, K.J., Zhou, Y.: Forward and inverse uncertainty quantification using multilevel Monte Carlo algorithms for an elliptic nonlocal equation. Int. J. Uncertain. Quantif. 6, 501–514 (2016)
Jazwinski, A.: Stochastic Processes and Filtering Theory, vol. 63. Academic Press, Cambridge (1970)
Jentzen, A.: Stochastic partial differential equations: analysis and numerical approximations. Lecture notes, ETH Zurich, summer semester (2016)
Jentzen, A., Kloeden, P.E.: Overcoming the order barrier in the numerical approximation of stochastic partial differential equations with additive space-time noise. Proc. R. Soc. A Math. Phys. Eng. Sci. 465, 649–667 (2009)
Jentzen, A., Kloeden, P.E.: Taylor Approximations for Stochastic Partial Differential Equations. SIAM, Philadelphia (2011)
Kalman, R.E., et al.: A new approach to linear filtering and prediction problems. J. Basic Eng. 82, 35–45 (1960)
Kalnay, E.: Atmospheric Modeling, Data Assimilation and Predictability. Cambridge University Press, Cambridge (2003)
Kantas, N., Beskos, A., Jasra, A.: Sequential Monte Carlo methods for high-dimensional inverse problems: a case study for the Navier–Stokes equations. SIAM/ASA J. Uncertain. Quantif. 2, 464–489 (2014)
Kwiatkowski, E., Mandel, J.: Convergence of the square root ensemble Kalman filter in the large ensemble limit. SIAM/ASA J. Uncertain. Quantif. 3, 1–17 (2015)
Law, K., Stuart, A., Zygalakis, K.: Data Assimilation: A Mathematical Introduction. Springer Texts in Applied Mathematics. Springer, Berlin (2015)
Law, K.J., Tembine, H., Tempone, R.: Deterministic mean-field ensemble Kalman filtering. SIAM J. Sci. Comput. 38, A1251–A1279 (2016)
Le Gland, F., Monbet, V., Tran, V.-D., et al.: Large sample asymptotics for the ensemble Kalman filter. The Oxford Handbook of Nonlinear Filtering, pp. 598–631 (2011)
Li, B., Bengtsson, T., Bickel, P.: Curse of dimensionality revisited: the collapse of importance sampling in very large scale systems. IMS Collect. Probab. Stat. Essays Honor David Freedman 2, 316–334 (2008)
Llopis, F.P., Kantas, N., Beskos, A., Jasra, A.: Particle filtering for stochastic Navier–Stokes signal observed with linear additive noise. SIAM J. Sci. Comput. 40, A1544–A1565 (2018)
Luenberger, D.G.: Optimization by Vector Space Methods. Wiley, Hoboken (1968)
Mandel, J., Cobb, L., Beezley, J.D.: On the convergence of the ensemble Kalman filter. Appl. Math. 56, 533–541 (2011)
Moral, P.D., Jasra, A., Law, K.J., Zhou, Y.: Multilevel sequential Monte Carlo samplers for normalizing constants. ACM Trans. Model. Comput. Simul. (TOMACS) 27, 20 (2017)
Müller, E.H., Scheichl, R., Shardlow, T.: Improving multilevel Monte Carlo for stochastic differential equations with application to the Langevin equation. Proc. R. Soc. A Math. Phys. Eng. Sci. 471, 20140679 (2015)
Pajonk, O., Rosić, B.V., Litvinenko, A., Matthies, H.G.: A deterministic filter for non-Gaussian Bayesian estimation-applications to dynamical system estimation with noisy measurements. Phys. D Nonlinear Phenom. 241, 775–788 (2012)
Rebeschini, P., Van Handel, R., et al.: Can local particle filters beat the curse of dimensionality? Ann. Appl. Probab. 25, 2809–2866 (2015)
Tong, X.T., Majda, A.J., Kelly, D.: Nonlinear stability and ergodicity of ensemble based Kalman filters. Nonlinearity 29, 657 (2016)
Urban, K.: Wavelets in numerical simulation: problem adapted construction and applications, vol. 22. Springer, Berlin (2012)
van Leeuwen, P.: Nonlinear data assimilation in geosciences: an extremely efficient particle filter. Q. J. R. Meteorol. Soc. 136, 1991–1999 (2010)
Weare, J.: Particle filtering with path sampling and an application to a bimodal ocean current model. J. Comput. Phys. 228, 4312–4331 (2009)
Woyczyński, W.A.: On Marcinkiewicz-Zygmund laws of large numbers in Banach spaces and related rates of convergence. Probab. Math. Stat. 1(1980), 117–131 (1981)
Acknowledgements
Research reported in this publication received support from the Alexander von Humboldt Foundation, KAUST CRG4 Award Ref:2584. HH acknowledges support by RWTH Aachen University and by Norges Forskningsråd, research Project 214495 LIQCRY. RT is a member of the KAUST SRI Center for Uncertainty Quantification in Computational Science and Engineering. KJHL was supported by The Alan Turing Institute under the EPSRC grant EP/N510129/1. KJHL was a staff scientist in the Computer Science and Mathematics Division at Oak Ridge National Laboratory (ORNL) while much of this research was done and was additionally supported by ORNL Laboratory Directed Research and Development Strategic Hire and Seed grants. We thank two referees for their comments which have greatly improved the article.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Inquires about this work should be directed to Håkon Hoel (hoel@uq.rwth-aachen.de).
Appendices
Appendix A: Marcinkiewicz–Zygmund inequalities for separable Hilbert spaces
In order to prove Lemma 5, we will need the following two lemmas for extending the Marcinkiewicz–Zygmund inequality from finite-dimensional state-spaces to separable Hilbert spaces.
Lemma 9
[34, Theorem 5.2] Let \(2 \le p < \infty \) and \(X_i \in L^p(\Omega ,\mathcal {V})\) be i.i.d. samples of \(X \in L^p(\Omega ,\mathcal {V})\). Then

where \(c_p\) only depends on p.
Proof
Let \(r_1, r_2, \ldots \) denote a sequence of real-valued i.i.d. random variables with \(P(r_i= \pm 1) = 1/2\). A Banach space \(\mathcal {K}\) is said to be of R-type q if there exists a \(c>0\) such that for every \({\bar{n}} \in \mathbb {N}\) and for all (deterministic) \(x_1, x_2, \ldots , x_{{\bar{n}}} \in \mathcal {K}\),

It is clear that all Hilbert spaces (and for our interest \(\mathcal {V}\), in particular) are of R-type 2, since their norms are induced by an inner product. Following the proofs of [50, Proposition 2.1 and Corollary 2.1], let \(\{X_i'\}\) denote an additional sequence of i.i.d. samples of \(X\in L^p(\Omega ,\mathcal {V})\) for which the collection of r.v. \(\{X_i\} \cup \{X_i'\}\) also is i.i.d. Introducing the symmetrization \({\widetilde{X}}_i \mathrel {\mathop :}=(X_i - X_i')\), and noting that

we derive by the conditional Jensen’s inequality that

And by another application of Hölder’s inequality,

\(\square \)
Lemma 10
Let \(X,Y \in L^p(\Omega ,\mathcal {V})\), for some \(p \ge 2\). Then, for any \(1 \le r,s \le \infty \) satisfying \(1/r + 1/s = 1\), it holds that
where the upper bound for the constant \(c = \dfrac{M}{M-1}\bigg (2c_p + \dfrac{c_{pr}c_{ps}+1}{\sqrt{M}}\bigg )\) only depends on r, s and p.
Proof
Since  and
and  , cf. (7), we may without loss of generality assume that
, cf. (7), we may without loss of generality assume that  . Using the triangle inequality,
. Using the triangle inequality,

Estimate (60) and Hölder’s inequality yield

Similarly, since  by assumption, we obtain by (60) and Hölder’s inequality
by assumption, we obtain by (60) and Hölder’s inequality
And, finally, for the last term

\(\square \)
Appendix B: Proof of Lemma 8
Proof
Introducing the function \(g:(1,\infty ) \times (0,\infty ) \rightarrow \mathbb {R}\) defined by
consecutive iterations of the scheme (42) for \(j \le N_m\) yield
where we recall that the initial data is given by \(U_{m,0} = \mathcal {P}_m {\bar{u}}_0\) with \({\bar{u}}_0 \in L^2(\Omega ,\mathcal {V})\). And since \(J_{m} = 2J_{m-1}\), consecutive iterations of the coupled coarse scheme (44) for \(j \le N_{m-1}\) yield
The jth mode final time difference of the coupled solutions for \( j\le N_{m-1}\) thus becomes
For bounding these three terms, we need to estimate the difference between powers of \(\left( g(\lambda _j,\Delta t_m)\right) ^2\) and \(g(\lambda _j,\Delta t_{m-1})\). Note first that
Remark 10
Equations (61) and (62) show that to leading order, the additive noise from two consecutive iterations of the fine scheme equals the additive noise from one corresponding iteration of the coupled coarse scheme. The strong coupling of the coarse and fine schemes is crucial for achieving the order 1 a priori time discretization convergence rate.
Since \(\inf _{j \in \mathbb {N}}\lambda _j = \lambda _1 >1\), it holds for all \(j\in \mathbb {N}\) that
and
By the mean value theorem, it holds for any \(j,k \ge 1\) that
Furthermore,
By (63), (64), (65), and the mean value theorem, and recalling that \(\Delta t_{m-1} = 2 \Delta t_m\), it holds for any \(1<k \le J_{m-1}\) and \(j\ge 1\) and some \(\theta _{jk} \in [0,1]\) that
From (66), we conclude that for \(j\le N_{m-1}\),
For bounding the terms \(I_{m,j,2}\) and \(I_{m,j,3}\), note by (61) that both terms are linear combinations of i.i.d. Gaussians from the sequence
cf. (43), and hence, both terms mean zero Gaussians. Furthermore, \(I_{m,j,2}\) and \(I_{m,j,3}\) are mutually independent as any summand of the former term is independent of any summand from the latter. Consequently, \(I_{m,j,2}+I_{m,j,3}\) is a mean zero Gaussian with variance

By the mutual independence of all terms in \(I_{m,j,2}\), it holds for \(j \le N_{m-1}\) that

By the strict inequality (63), we are dealing with three sums of geometric series:
and
By applying \(g(\lambda _j,\Delta t_{m})< g(\lambda _j,\Delta t_{m-1}) <1\) and the mean value theorem,
where the second summand in the last inequality follows from (62). By (67), we obtain that for all \(j \le N_{m-1}\),

The last term is bounded by a similar argument: For all \(j \le N_{m-1}\),

Here, the last inequality follows by observing that as for  ,
,
and
\(\square \)
Appendix C: Additional proofs for completeness
Proof of Lemma 2
Recalling the notation \(R_n^{\mathrm{ML}} = C^{\mathrm{ML}}_nH^*\) and introducing the auxiliary operator \({\bar{R}}_n \mathrel {\mathop :}={\bar{C}}_n H^*\), we have
Using the equality
we further obtain
Next, since \((H R^{\mathrm{ML}}_{n})^+\) and \(\Gamma \) respectively are positive semi-definite and positive definite,
and it follows by inequality (23) and
that
\(\square \)
Proof of Lemma 7
We will use an induction argument to show that for arbitrary fixed \(N \in \mathbb {N}\) and \(p \ge 2\), it holds for all \(n \le N\) that
The result then follows by the arbitrariness of N and p.
By (20), we have that \(\hat{v}_{0}^{\ell } = \hat{\bar{ v}}_{0}^{\ell }\), so that for any \(p' \ge 2\),
Fix \(p\ge 2\) and \(N \in \mathbb {N}\), and assume that
Then, by Assumption 1(i),
Furthermore, by Lemma 2,
for all \(\ell =0, \ldots , L\). Hölder’s inequality then implies
Plugging (70) into the right-hand side of (29) and using Lemma 3, we obtain that for all \(p' \le 4^{N-n} p\)
Summing over the levels in (71), it holds for all \(p' \le 4^{N-n} p\) that
\(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chernov, A., Hoel, H., Law, K.J.H. et al. Multilevel ensemble Kalman filtering for spatio-temporal processes. Numer. Math. 147, 71–125 (2021). https://doi.org/10.1007/s00211-020-01159-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00211-020-01159-3