
Abstract
While many application papers involving time series data report about the beneficial application of filters, filtering (and preprocessing in general) plays at best a minor role in the proposals of similarity measures for time series or the studies that compare them. We investigate the performance of basic Euclidean distance with an integrated preprocessing (filtering with automatically derived filters (supervised or unsupervised) and rescaling) and demonstrate that such measures can better respond to typical problems in time series similarity. By accounting for differences in both domains (time and value) we overcome some limitations of elastic measures that focus on time only. Using the proposed measure on real datasets we can achieve performance gains comparable to those of switching from a lock-step measure (Euclidean) to an elastic measure (DTW).










Similar content being viewed by others



Notes
Only the artificial data can be shared: http://public.ostfalia.de/~hoeppnef/tsfilter.html.
We found no reference for the type of the Car dataset, but assume it to be a shape dataset due to its similarity to other datasets of this type, e.g. FISH.
Fig. 7 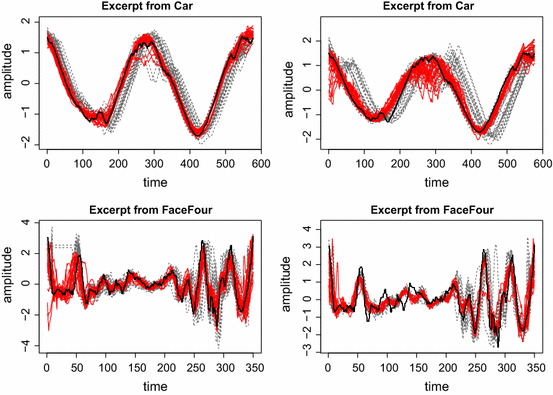
Car (top) and FaceFour (bottom) dataset. For a given reference series (black) several other series (dashed gray) from the same class (left) and another class (right) are filtered and rescaled by LFD (red series) to obtain a higher correspondence with the reference (Color figure online)

References
Agrawal R, Faloutsos C, Swami A (1993) Efficient similarity search in sequence databases. In: 4th international conference foundations of data organization and algorithms, Chicago, pp 69–84
Argyros T, Ermopoulos C (2003) Efficient subsequence matching in time series databases under time and amplitude transformations. In: IEEE data mining, IEEE computing in society, pp 481–484
Batista G, Wang X, Keogh E (2011) A complexity-invariant distance measure for time series. In: Proceedings of international conference on data mining, pp 699–710
Berndt DJ, Clifford J (1996) Finding patterns in time series: a dynamic programming approach. In: Advances in knowledge discovery and data mining, MITP, pp 229–248
Casacuberta F, Vidal E, Rulot H (1987) On the metric properties of dynamic time warping. IEEE Trans Acoust Speech Signal Process 35(11):1631–1633
Chen Y, Keogh E, Hu B, Begum N, Bagnall A, Mueen A, Batista G (2011) The UCR time series classification archive. www.cs.ucr.edu/~eamonn/time_series_data
Chen L, Ng R (2004) On the marriage of Lp-norms and edit distance. In: International conference on very large databases, pp 792–803
Chen L, Özsu M, Oria V (2005) Robust and fast similarity search for moving object trajectories. In: Proceedings of ACM SIGMOD, pp 491–502
Cleveland WS (1979) Robust locally weighted regression and smoothing scatterplots. J Am Stat Assoc 74(368):829–836. doi:10.2307/2286407
Dallachiesa M, Nushi B (2012) Uncertain time-series similarity: return to the basics. Proc VLDB 5(11):1662–1673
Das G, Gunopulos D, Mannila H (1997) Finding similar time series. In: Proceedings of the conference on principles of knowledge discovery and data mining
Elboher E, Werman M (2013) Asymmetric correlation: a noise robust similarity measure for template matching. IEEE Trans Image Process 22(8):3062–3073
Fu TC (2011) A review on time series data mining. Eng Appl Artif Intell 24(1):164–181
Górecki T, Łuczak M (2013) Using derivatives in time series classification. Data Min Knowl Discov 26(2):310–331
Höppner F (2014) Less is more: similarity of time series under linear transformations. In: Proceedings of SIAM international conference data mining (SDM), pp 560–568
Höppner F (2015) Optimal filtering for time series classification. In: Proceedings of 16th internatinal conference intelligent data engineering and automated learning, pp 26–35
Höppner F, Klawonn F (2009) Compensation of translational displacement in time series clustering using cross correlation. In: Proceedings of 8th international symposium intelligent data analysis, no. 5772 in LNCS, pp 71–82
Itakura F (1975) Minimum prediction residual principle to speech recognition applied. IEEE Trans Acoust Speech Signal Process 23(1):67–72
Kay SM (1993) Fundamentals of statistical signal processing. Prentice-Hall, Englewood Cliffs
Keogh E (2003) Efficiently finding arbitrarily scaled patterns in massive time series databases. In: Knowledge discovery in databases (PKDD), pp 253–265
Keogh E, Kasetty S (2003) On the need for time series data mining benchmarks: a survey and empirical demonstration. Data Min Knowl Discov 7(4):349–371. doi:10.1023/A:1024988512476
Keogh E, Pazzani M (2001) Derivative dynamic time warping. In: SDM, pp 5–7
Kullback S, Leibler RA (1951) On information and sufficiency. Ann Math Stat 22(1):79–86
Last M, Klein Y, Kandel A (2001) Knowledge discovery in time series databases. IEEE Trans Syst Man Cybern 31(01):160–169
Marteau PF (2009) Time warp edit distance with stiffness adjustment for time series matching. IEEE Trans Pattern Anal Mach Intell 31(2):306–318
Müller M (2007) Information retrieval for music and motion. Springer, New York
Navarro G (2001) A guided tour to approximate string matching. ACM Comput Surv 33(1):31–88
Ramsay JO, Silverman BW (1997) Functional data analysis. Springer series in statistics. Springer, New York
Ratanamahatana C, Keogh E (2004) Everything you know about dynamic time warping is wrong. In: Third workshop on mining temporal and sequential data
Sakoe H, Chiba S (1978) Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans Acoust Speech Signal Process 26(1):43–49
Schäfer P (2014) The BOSS is concerned with time series classification in the presence of noise. Data Min Knowl Discov 29(6):1505–1530
Serrà J, Arcos JL (2014) An empirical evaluation of similarity measures for time series classification. Knowl Based Syst 67:305–314
Taylor JR (1997) An introduction to error analysis. University Science Books, New York
Tversky A (1977) Features of similarity. Psychol Rev 84(4):327–352
Wang X, Mueen A, Ding H, Trajcevski G, Scheuermann P, Keogh E (2012) Experimental comparison of representation methods and distance measures for time series data. Data Min Knowl Discov 26(2):275–309
Ye L, Keogh E (2010) Time series shapelets: a novel technique that allows accurate, interpretable and fast classification. Data Min Knowl Discov 22(1–2):149–182
Acknowledgements
I would like to thank the reviewers for their useful comments.
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible editor: Eamonn Keogh.
Rights and permissions
About this article

Cite this article
Höppner, F. Improving time series similarity measures by integrating preprocessing steps. Data Min Knowl Disc 31, 851–878 (2017). https://doi.org/10.1007/s10618-016-0490-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10618-016-0490-x